
تصور کنید یک مدل هوش مصنوعی قدرتمند مثل ChatGPT دارید که میتواند به هزاران سوال پاسخ دهد، متنهای طولانی تولید کند و حتی در نوشتن کد به شما کمک کند. اما مشکل اینجاست که این مدل، عمومی طراحی شده و همیشه دقیقا مطابق نیاز شما عمل نمیکند. مثلا اگر در یک شرکت حقوقی کار میکنید، شاید بخواهید هوش مصنوعی طوری آموزش ببیند که به زبان تخصصی قوانین پاسخ دهد، یا اگر در یک فروشگاه آنلاین هستید، دوست دارید مدل دقیقا با لحن برند شما با مشتریان صحبت کند. اینجاست که فاین تیونینگ (Fine-tuning) وارد ماجرا میشود.
فاینتیونینگ یعنی آموزش دوباره یک مدل هوش مصنوعی آماده، با دادههای مخصوص شما، تا رفتارش دقیقتر، حرفهایتر و متناسب با نیازتان شود. در این مقاله، قدمبهقدم بررسی میکنیم که فاینتیونینگ دقیقا چیست، چرا اهمیت دارد، چه مراحلی دارد و چطور میتوان آن را روی مدلهای مختلف بهویژه مدلهای OpenAI پیادهسازی کرد.
فاین تیونینگ چیست؟
فاین تیونینگ (Fine-tuning) فرایندی است که در آن یک مدل از پیش آموزشدیده (pre-trained model) با مجموعهای از دادههای جدید و خاص، دوباره آموزش داده میشود تا بهتر با نیازها یا دامنه مشخصی هماهنگ شود. به زبان ساده، شما به جای اینکه از صفر یک مدل هوش مصنوعی بسازید، از یک مدل آماده استفاده میکنید و آن را دقیقا مطابق زمینه کاری خودتان تنظیم میکنید.
فاینتیونینگ را نباید با pre-training یا prompt engineering اشتباه گرفت:
- Pre-training به آموزش اولیه مدل روی حجم عظیمی از دادههای عمومی گفته میشود. این مرحله بسیار پرهزینه و زمانبر است و توسط سازمانهای بزرگ مثل OpenAI یا Google انجام میشود.
- Prompt engineering یعنی طراحی پرسشها یا دستورات بهینه برای هدایت مدل، بدون تغییر در ساختار یا پارامترهای آن.
اما تنظیم دقیق یک گام میانی است: مدل تغییریافته همچنان از پایه pre-trained استفاده میکند، اما با دادههای جدید شما دوباره تنظیم میشود تا خروجی دقیقتری بدهد.
مزایای اصلی فاین تیون عبارتند از:
- افزایش دقت: مدل بهتر میتواند به نیازهای خاص شما پاسخ دهد و خطاها کمتر میشود.
- صرفهجویی در زمان: به جای ساخت مدل از صفر، تنها با تغییرات هدفمند، مدل آماده میشود.
- بهبود تجربه کاربر: خروجیها شخصیتر و متناسبتر میشوند، مثلا لحن پاسخها یا سبک نوشتن دقیقا با برند یا حوزه تخصصی شما هماهنگ خواهد بود.

چرا فاینتیونینگ مهم است؟
اهمیت فاین تیونینگ را میتوان از دو جنبه درک کرد: یکی نیاز سازمانها به مدلهای دقیقتر و دیگری محدودیت مدلهای عمومی.
فاینتیونینگ در کاربردهای سازمانی نقش کلیدی دارد. مدلهای زبانی بزرگ بهطور کلی بسیار قدرتمند هستند، اما همیشه پاسخهایشان برای همه صنایع یا حوزهها مناسب نیست. بهعنوان مثال، یک بانک یا یک شرکت دارویی نیاز دارد که مدل درک عمیقی از اصطلاحات و فرایندهای تخصصی همان صنعت داشته باشد. در چنین شرایطی، فاین تیونینگ کمک میکند تا مدل بهطور ویژه روی دادههای همان سازمان تنظیم شود و خروجیهایش دقیقتر، سازگارتر و قابل اعتمادتر شود.
از سوی دیگر، استفاده صرف از مدلهای آماده (pre-trained models) بدون فاینتیونینگ، هرچند سریع و ارزان است اما محدودیتهایی دارد. مدل عمومی معمولا در طیف وسیعی از موضوعات آموزش دیده و همین باعث میشود نتواند در حوزههای تخصصی عملکردی در حد انتظار داشته باشد.
برای روشنتر شدن این موضوع، تصور کنید دو مدل مختلف در حوزه پزشکی و حقوق:
- مدل عمومی: میتواند پاسخهای کلی درباره سلامتی یا قوانین بدهد اما دقت کافی در اصطلاحات تخصصی ندارد و ممکن است خطاهای جدی ایجاد کند.
- مدل تخصصی (فاینتیونشده): پس از آموزش با دادههای پزشکی یا حقوقی، توانایی درک بهتر اصطلاحات تخصصی و ارائه پاسخهای دقیقتر پیدا میکند.
به همین دلیل، فاین تیونینگ نهتنها دقت مدل را افزایش میدهد بلکه باعث میشود هوش مصنوعی به ابزاری قابلاعتماد برای صنایع حساس و پرخطر مانند پزشکی، حقوق و مالی تبدیل شود.
کاربردهای فاین تیونینگ
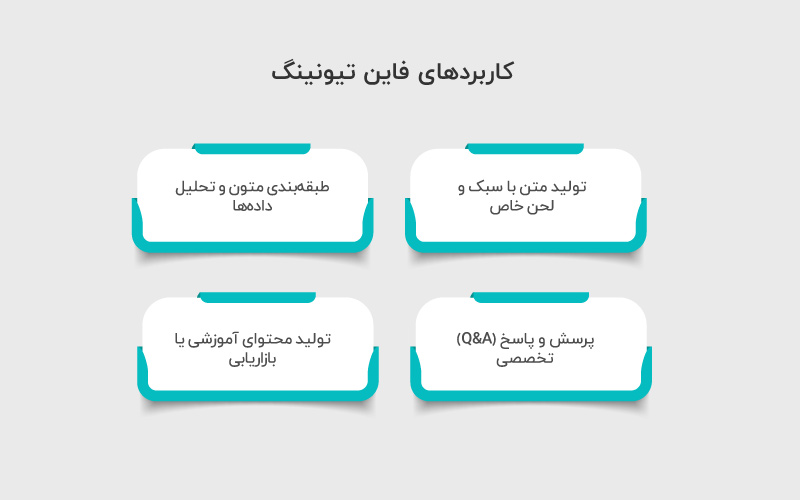
فاینتیونینگ تنها محدود به بهبود دقت مدل نیست، بلکه آن را به ابزاری انعطافپذیر برای حل نیازهای متنوع کسبوکارها تبدیل میکند. با استفاده درست از این روش، میتوان مدلهای عمومی را به متخصصانی در حوزههای خاص بدل کرد. برخی از مهمترین کاربردهای فاین تیونینگ عبارتاند از:
- تولید متن با سبک و لحن خاص: میتوان مدل را طوری آموزش داد که همیشه با لحنی رسمی، دوستانه یا حتی خلاقانه پاسخ بدهد. این ویژگی برای برندهایی که بهدنبال حفظ هویت نوشتاری ثابت در محتواهایشان هستند، بسیار ارزشمند است.
- طبقهبندی متون و تحلیل دادهها: از بررسی و دستهبندی ایمیلها گرفته تا تحلیل بازخورد مشتریان، فاینتیونینگ کمک میکند مدل بهطور دقیقتر متنها را شناسایی و طبقهبندی کند.
- پرسش و پاسخ (Q&A) تخصصی: با آموزش مدل روی پایگاههای دانش تخصصی (مثل پزشکی، حقوقی یا مالی)، میتوان آن را به دستیار پرسش و پاسخ دقیقی تبدیل کرد که به جای پاسخهای عمومی، راهکارهای تخصصی ارائه دهد.
- تولید محتوای آموزشی یا بازاریابی: فاینتیونینگ به مدل امکان میدهد محتوایی هدفمند و متناسب با مخاطبان خاص تولید کند؛ چه برای آموزش کارکنان درونسازمانی و چه برای طراحی کمپینهای بازاریابی.
راهنمای گامبهگام تنظیم دقیق (Fine-Tuning) یک مدل زبانی بزرگ (LLM)

ما میدانیم که فاین تیون فرایندی است که طی آن یک مدل از پیش آموزشدیده را میگیریم و پارامترهای آن را با دادههای خاص یک وظیفهی جدید، دوباره آموزش میدهیم. برای روشنتر شدن موضوع، بیایید این مفهوم را با یک مثال عملی نشان دهیم.
فرض کنید در حال کار با GPT-2 هستیم اما متوجه میشویم که در تشخیص احساسات توییتها عملکرد ضعیفی دارد. این سوال طبیعی مطرح میشود: آیا میتوانیم کاری کنیم تا عملکردش بهتر شود؟
پاسخ بله است. با استفاده از فاینتیونینگ میتوانیم مدل GPT-2 را روی یک دیتاست شامل توییتها و برچسب احساساتشان (مثبت، خنثی یا منفی) دوباره آموزش دهیم. در ادامه، یک نمونه ساده از فاینتیونینگ برای کلاسبندی دنبالهها (Sequence Classification) را مرور میکنیم.
گام ۱: انتخاب مدل و دیتاست
اولین قدم انتخاب یک مدل پایه است. ما در اینجا از GPT-2 استفاده میکنیم. انتخاب مدل باید متناسب با وظیفه باشد.
|
1 2 3 4 |
# انتخاب دیتاست و مدل پایه from datasets import load_dataset dataset = load_dataset(“mteb/tweet_sentiment_extraction”) |
گام ۲: بارگذاری دادهها
پس از انتخاب مدل، نیاز به دادههای باکیفیت داریم. در اینجا از کتابخانه Hugging Face datasets استفاده میکنیم که توییتها را همراه با برچسب احساساتشان فراهم میکند.
|
1 2 3 4 |
import pandas as pd df = pd.DataFrame(dataset[‘train’]) print(df.head()) |
این دیتاست شامل زیرمجموعهای برای آموزش و زیرمجموعهای برای تست است.
گام ۳: توکنایزر (Tokenizer)
از آنجا که مدلهای زبانی با توکنها کار میکنند، باید دادهها را به فرمت قابلفهم برای مدل تبدیل کنیم. این کار با استفاده از یک توکنایزر انجام میشود.
|
1 2 3 4 5 6 7 8 9 |
from transformers import GPT2Tokenizer tokenizer = GPT2Tokenizer.from_pretrained(“gpt2”) tokenizer.pad_token = tokenizer.eos_token def tokenize_function(examples): return tokenizer(examples[“text”], padding=“max_length”, truncation=True) tokenized_datasets = dataset.map(tokenize_function, batched=True) |
برای صرفهجویی در منابع، میتوان یک زیرمجموعه کوچکتر ایجاد کرد:
|
1 2 |
small_train_dataset = tokenized_datasets[“train”].shuffle(seed=42).select(range(1000)) small_eval_dataset = tokenized_datasets[“test”].shuffle(seed=42).select(range(1000)) |
گام ۴: بارگذاری مدل پایه
حال باید مدل را با تعداد برچسبهای مورد انتظار مقداردهی اولیه کنیم (سه برچسب: مثبت، منفی و خنثی).
|
1 2 3 |
from transformers import GPT2ForSequenceClassification model = GPT2ForSequenceClassification.from_pretrained(“gpt2”, num_labels=3) |
گام ۵: تعریف متد ارزیابی
برای ارزیابی عملکرد مدل، باید یک تابع ارزیابی بسازیم.
|
1 2 3 4 5 6 7 8 9 |
import evaluate import numpy as np metric = evaluate.load(“accuracy”) def compute_metrics(eval_pred): logits, labels = eval_pred predictions = np.argmax(logits, axis=–1) return metric.compute(predictions=predictions, references=labels) |
گام ۶: فاینتیونینگ با استفاده از Trainer
اکنون میتوانیم آموزش مدل را آغاز کنیم. کلاس Trainer در کتابخانه Transformers این کار را ساده میکند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from transformers import TrainingArguments, Trainer training_args = TrainingArguments( output_dir=“test_trainer”, per_device_train_batch_size=1, per_device_eval_batch_size=1, gradient_accumulation_steps=4 ) trainer = Trainer( model=model, args=training_args, train_dataset=small_train_dataset, eval_dataset=small_eval_dataset, compute_metrics=compute_metrics, ) trainer.train() |
پس از اتمام آموزش، میتوان مدل را روی دادههای تست ارزیابی کرد:
|
1 |
trainer.evaluate() |
این مراحل پایهایترین فرایند برای فاین تیونینگ یک مدل زبانی بزرگ هستند. فراموش نکنید که این کار بسیار محاسباتی سنگین است و ممکن است سیستم شخصی شما توان پردازش کافی نداشته باشد. برای مدلهای پیشرفتهتر مثل GPT-3.5 میتوانید مستقیما از رابط OpenAI برای فاینتیونینگ استفاده کنید.
فاین تیونینگ در مدلهای OpenAI
فاینتیونینگ به شما این امکان را میدهد که یک مدل زبانی بزرگ از پیشآموزشدیده را با دادههای خاص خود بهینه کنید تا عملکرد بهتری در حوزه یا کاربرد مورد نظر داشته باشد. این فرایند باعث میشود مدل پاسخهایی دقیقتر، مرتبطتر و متناسب با نیاز شما تولید کند.
مراحل اصلی فاین تیونینگ
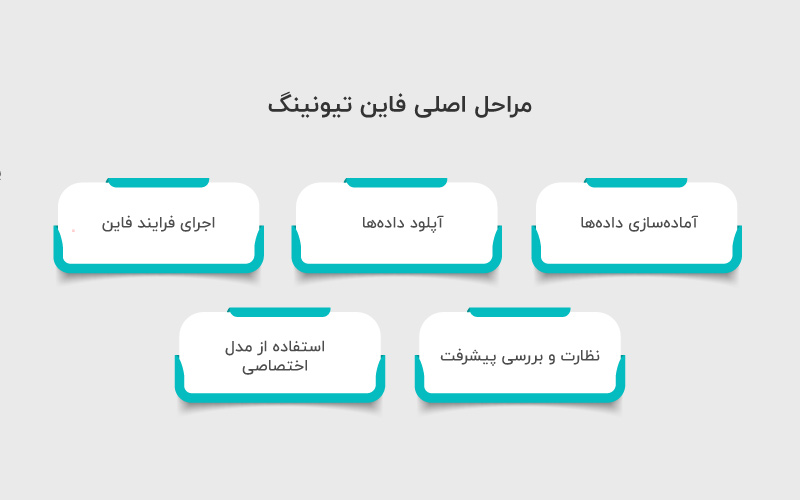
۱. آمادهسازی دادهها
دادهها باید در قالب JSONL باشند، هر نمونه شامل دو بخش: prompt و completion (ورودی و خروجی مورد انتظار).
کیفیت و تنوع دادهها نقش مهمی در موفقیت فاینتیونینگ دارد. دادههای با حجم کافی و متنوع معمولا نتیجه بهتری میدهند.
۲. آپلود دادهها
از CLI یا API OpenAI برای بارگذاری دیتاست استفاده میکنید.
دستور نمونه:
|
1 2 |
openai tools fine_tunes.prepare_data –f your_dataset.jsonl openai api fine_tunes.create –t “prepared_data.jsonl” –m “davinci” |
در این مرحله، دادهها بررسی میشوند و خطاهای قالببندی رفع میشوند.
۳. اجرای فرایند فاینتیونینگ
مدل انتخابی شما بر اساس دادههای آپلود شده آموزش میبیند.
مدت زمان آموزش به حجم داده و مدل انتخابی بستگی دارد.
۴. نظارت و بررسی پیشرفت
OpenAI ابزارهایی برای مشاهده لاگهای آموزش و میزان پیشرفت مدل ارائه میدهد.
میتوان از پارامترهایی مانند learning_rate و تعداد epochs برای بهینهسازی عملکرد مدل استفاده کرد.
۵. استفاده از مدل اختصاصی
پس از پایان آموزش، مدل فاینتیونشده آماده پاسخدهی است.
برای فراخوانی مدل میتوان از API مانند نمونه زیر استفاده کرد:
|
1 2 3 4 5 6 7 8 9 10 11 |
import openai openai.api_key = “YOUR_API_KEY” response = openai.Completion.create( model=“fine-tuned-model-id”, prompt=“متنی که میخواهید پاسخ داده شود”, max_tokens=150 ) print(response.choices[0].text.strip()) |
نکات کاربردی و مزایا:
- تولید محتوا با سبک و لحن دلخواه: فاین تیونینگ امکان هماهنگسازی مدل با سبک نوشتاری برند یا فردی را میدهد.
- پاسخدهی تخصصی: مدل میتواند پاسخهای دقیقتر در حوزههای خاص مثل حقوق، پزشکی یا فناوری ارائه دهد.
- کاهش خطا و بهبود دقت: با تمرین روی دادههای واقعی، مدل احتمال خطا را کاهش میدهد و پاسخهای مرتبطتری تولید میکند.
- انعطافپذیری و مقیاسپذیری: پس از فاین تیونینگ، مدل میتواند در اپلیکیشنها و سرویسهای مختلف به کار گرفته شود.
چالشها و آینده فاین تیونینگ
چالشها و نکات مهم در فاینتیونینگ مدلهای زبانی شامل چند جنبه کلیدی است که باید به آنها توجه کرد. اول، دادههای استفادهشده باید باکیفیت و متوازن باشند تا مدل بتواند به درستی یاد بگیرد و عملکرد مناسبی در دامنههای مختلف ارائه دهد.
دوم، هزینهها و منابع محاسباتی موضوع مهمی هستند؛ فاین تیونینگ مدلهای بزرگ به سختافزار قدرتمند و زمان قابل توجه نیاز دارد.
سوم، خطر overfitting همیشه وجود دارد؛ یعنی مدل ممکن است فقط روی دادههای آموزشی خوب عمل کند اما روی دادههای واقعی ضعیف باشد. در نهایت، ملاحظات اخلاقی و بایاس باید در نظر گرفته شوند تا مدل پاسخهای منصفانه و بدون تبعیض تولید کند.

آینده فاین تیونینگ مدلهای زبانی بزرگ به چند روند کلیدی وابسته است:
- اول، ترکیب فاینتیونینگ با روشهایی مثل RAG (Retrieval-Augmented Generation) باعث میشود مدلها بتوانند به دادههای خارجی دسترسی داشته باشند و پاسخهای دقیقتر و بهروزتری تولید کنند.
- دوم، حرکت به سمت مدلهای قابلتنظیمتر و انعطافپذیرتر، به توسعهدهندگان اجازه میدهد با هزینه کمتر، مدلها را برای کاربردهای خاص خود بهینه کنند.
- سوم، روندهای آینده نشان میدهند که فاینتیونینگ در کنار تکنیکهای خودکارسازی و بهبود مدیریت منابع، به سمت کاهش زمان آموزش و مصرف انرژی خواهد رفت تا مقیاسپذیری مدلها افزایش یابد.
نتیجهگیری
فاین تیونینگ مدلهای زبانی بزرگ نشان میدهد که حتی مدلهای پیشرفته نیاز به تنظیم و شخصیسازی برای پاسخگویی دقیق به نیازهای خاص دارند. این فرایند با آموزش مدل روی دادههای ویژه یک حوزه، عملکرد آن را در وظایف مشخص بهبود میدهد و امکان تطبیق با کاربردهای صنعتی و پژوهشی را فراهم میکند.
با وجود چالشهایی مانند مصرف بالای منابع محاسباتی و نیاز به دادههای با کیفیت، تنظیم دقیق (Fine-Tuning) ابزار ارزشمندی برای افزایش دقت و بهرهوری مدلهاست. پیشبینی میشود با توسعه روشهای بهینهسازی، خودکارسازی و ترکیب با فناوریهای نوین، این روند نقش کلیدی در ساخت سیستمهای هوش مصنوعی دقیق، پاسخگو و کاربردی ایفا کند.
منابع


دیدگاهتان را بنویسید