
حجم دادههایی که هر روز تولید میکنیم سرسامآور است و بخش بزرگی از ارزشآفرینی امروزِ نرمافزار، به توان ما در استخراج معنا از داده وابسته است. «دستهبندی یا Classification دادهها با هوش مصنوعی» دقیقا در همین نقطه به کمکمان میآید: مدلی میسازیم که با تکیه بر الگوهای آموختهشده، نمونههای جدید را در کلاسهای مشخص قرار دهد؛ از تشخیص اسپم و تحلیل احساسات گرفته تا توصیهگرها و بینایی ماشین.
در این مقاله از بلاگ آسا، ابتدا انواع رایج دستهبندی را مرور میکنیم: از دودویی و چندکلاسه تا چندبرچسبی و سناریوهای نامتوازن و بعد سراغ شیوهی آموزش و ارزیابی مدل میرویم. سپس با مروری بر الگوریتمهای مهم (مانند Logistic Regression، Decision Tree، Random Forest، SVM، Neural Networks، KNN و Naive Bayes) نقاط قوت و کاربردهای هر کدام را میبینیم تا برای پیادهسازی در پروژههای واقعی آماده شویم.
دستهبندی دادهها در هوش مصنوعی چیست؟
«دستهبندی دادهها با هوش مصنوعی» یا به اختصار AI Classification، فرایندی است که طی آن دادهها در دستههای از پیش تعیینشده سازماندهی میشوند. در این روش، مدل هوش مصنوعی آموزش میبیند که ویژگیها و الگوهای موجود در دادهها را تشخیص دهد تا بتواند همان الگوها را در مجموعه دادههای جدید نیز شناسایی کند.
این نوع دستهبندی بهویژه برای درک دادههای ساختارنیافته کاربرد زیادی دارد که دور از ذهن هم نیست؛ چون دادههای ساختاریافته عملا نیاز چندانی به دستهبندی ندارند؛ همانطور که از نامشان پیداست، ساختار آنها از قبل مشخص است. اما ارزش واقعی زمانی نمایان میشود که بتوانیم اطلاعات پنهان در دادههای ساختارنیافته را استخراج کنیم. این دادهها میتوانند در کاربردهایی مثل تحلیل پیشبینانه، فیلتر کردن اسپم، تولید پیشنهادها (Recommendations) و تشخیص تصویر به کار گرفته شوند.
انواع دستهبندی در هوش مصنوعی
دادههای ساختارنیافته فقط یک نوع ندارند؛ بنابراین مدلهای هوش مصنوعی بسته به هدف موردنظر، به الگوریتمهای متفاوتی نیاز دارند. هر الگوریتم متناسب با نوع مسئلهای طراحی میشود که قصد حل آن را داریم و همچنین با توجه به دادههایی که در دسترس داریم.
در ادامه به رایجترین انواع دستهبندی در هوش مصنوعی اشاره میکنیم:
۱- دستهبندی دودویی (Binary Classification)
در برخی موارد، الگوریتم دستهبندی تنها کافی است دادهها را در یکی از دو دسته قرار دهد. حالتها میتوانند «بله/خیر»، «درست/نادرست»، «فعال/غیرفعال» و مانند اینها باشند. به این نوع دستهبندی، دودویی گفته میشود.
کجا میتوان از این دستهبندی استفاده کرد؟
- تشخیص اسپم در ایمیلها: ایمیلها یا اسپم هستند یا نیستند.
- شناسایی تراکنشهای مشکوک: آیا یک تراکنش مالی کلاهبرداری است یا خیر؟
- تصمیمگیری درباره وام: با توجه به سوابق مالی و شرایط فعلی متقاضی، آیا وام باید تایید شود یا رد؟
در همه این مثالها، تنها دو نتیجه ممکن وجود دارد و الگوریتم هوش مصنوعی دقیقا برای گرفتن چنین تصمیمهایی طراحی میشود.
۲- دستهبندی چندکلاسه (Multiclass Classification)
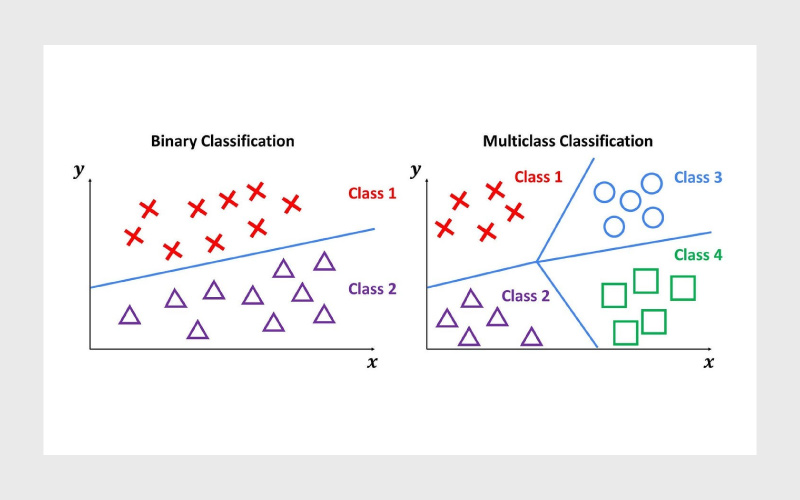
برخلاف دستهبندی دودویی که فقط با دو برچسب سروکار دارد، در دستهبندی چندکلاسه تعداد برچسبها بیشتر است. برای مثال، علاوهبر تشخیص «اسپم» یا «غیراسپم»، یک سرویس ایمیل ممکن است پیامها را در دستههای دیگری مثل «تبلیغاتی»، «شبکههای اجتماعی»، «مهم» و غیره هم طبقهبندی کند.
نمونه دیگر زمانی است که یک مدل یادگیری ماشین برای «خواندن» اعداد در تصاویر استفاده میشود؛ مثل شماره تلفن یا کدهای پستی دستنویس روی پاکتها. در این حالت، هر نماد باید در یکی از ۱۰ کلاس قرار بگیرد که مربوط به ارقام ۰ تا ۹ هستند.
به طور خلاصه، دستهبندی چندکلاسه شباهت زیادی به دستهبندی دودویی دارد، با این تفاوت که بیش از دو دسته ممکن وجود دارد. نکته مهم این است که با وجود چندکلاسه بودن، هر داده فقط میتواند به یک کلاس تعلق داشته باشد. مثلا یک ایمیل میتواند «تبلیغاتی» باشد یا «اعلان شبکه اجتماعی»؛ نه هر دو. یک رقم هم میتواند ۱ باشد یا ۷ اما نمیتواند همزمان هر دو باشد.
۳- دستهبندی چندبرچسبی (Multilabel Classification)
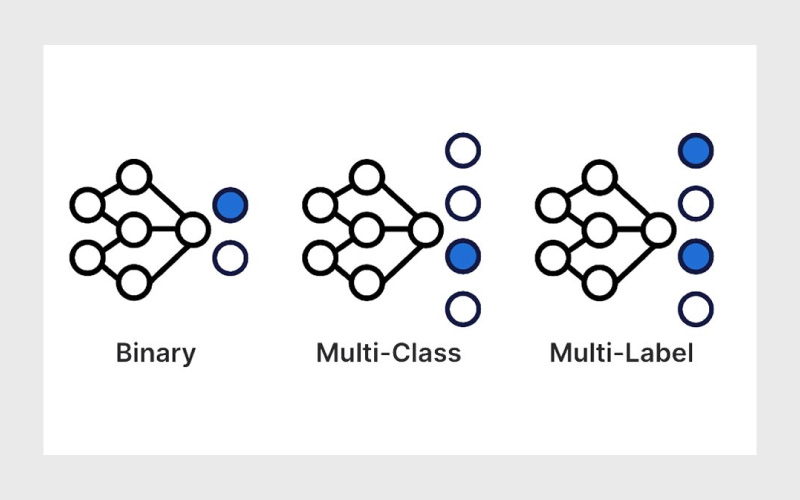
در دستهبندیهای قبلی، هر داده فقط میتوانست در یک کلاس قرار بگیرد؛ چه در دو دسته (دودویی) و چه در چند دسته (چندکلاسه). اما در دستهبندی چندبرچسبی، شرایط پیچیدهتر میشود، چون یک داده میتواند همزمان به بیش از یک دسته تعلق داشته باشد.
برای مثال، یک سگ میتواند همزمان در دستههای «حیوان»، «لابرادور»، «سیاه» و «سگ شکاری» قرار بگیرد.
این رویکرد شبیه برچسبهایی است که روی مقالات خبری یا پستهای وبلاگی میبینید. مثلا یک مطلب درباره امنیت داده ممکن است همزمان با برچسبهای «امنیت»، «داده»، «رخدادهای امنیتی» و «اتوماسیون امنیت داده» منتشر شود. یا در یک پلتفرم استریم فیلم، یک اثر میتواند همزمان در دسته «کمدی» و «عاشقانه» قرار بگیرد.
۴- دستهبندی نامتوازن (Imbalanced Classification)
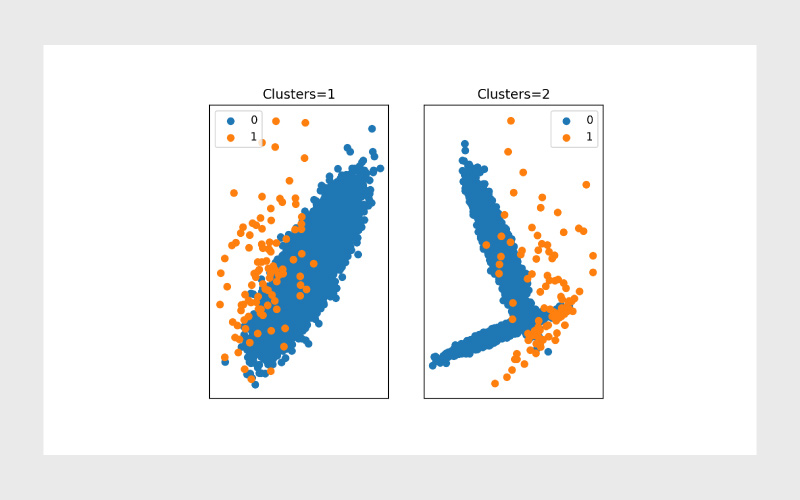
این نوع دستهبندی از بقیه پیچیدهتر است. همانطور که از نامش پیداست، دستهبندی نامتوازن به مجموعه دادههایی مربوط میشود که در آنها یک کلاس بهطور قابل توجهی بیشتر از کلاس دیگر است.
برای مثال صدها هزار نفر ممکن است آزمایش شوند اما فقط تعداد کمی مبتلا به سرطان تشخیص داده میشوند یا در میان میلیونها تراکنش کارت اعتباری، تنها تعداد کمی از آنها کلاهبرداری هستند و بقیه کاملا معتبرند. همچنین، هر سال تنها تعداد کمی از دانشجویان ترک تحصیل میکنند و اکثریت باقی میمانند.
در همه این نمونهها، هدف شما شناسایی یا پیشبینی یک رویداد نادر است. اما دادههایی که مدل روی آن آموزش میبیند بهطور طبیعی به سمت کلاس غالب (برعکس آن رویداد نادر) تمایل دارد.
مدلهای هوش مصنوعی اغلب بر اساس احتمال تصمیمگیری میکنند. اگر رخدادی احتمال بسیار کمی (مثلا ۰.۰۰۱٪) داشته باشد، مدل معمولا آن را نادیده میگیرد و روی احتمال بالای رخ ندادن آن (۹۹.۹۹۹٪) تمرکز میکند.
اما در این موارد، داشتن یک مثبت کاذب (False Positive) بسیار بهتر از داشتن یک منفی کاذب (False Negative) است. اگر حتی احتمال اندکی وجود داشته باشد که نتیجه نشاندهنده سرطان باشد، تراکنش مشکوک به کلاهبرداری باشد یا دانشجویی در معرض ترک تحصیل قرار گرفته باشد، باید مطلع شوید تا بتوانید مداخله کنید. ترجیح داده میشود این موارد بهعنوان هشدار علامتگذاری شوند تا یک متخصص انسانی بررسی کند، نه اینکه صرفا بهدلیل «احتمال کم» از دست بروند.
در نتیجه، هرچند دادههای آموزشی به سمت منفی متمایلاند، الگوریتم یادگیری ماشین باید این موضوع را در نظر بگیرد. در غیر این صورت، مدل شما رویدادهای مهم را فقط به این دلیل که از نظر آماری غیرمحتمل هستند، نادیده خواهد گرفت.
الگوریتمهای دستهبندی داده در هوش مصنوعی چطور آموزش داده میشوند؟
حالا که با انواع دستهبندیها آشنا شدیم، بیایید ببینیم مدلهای هوش مصنوعی چگونه برای انجام آنها آموزش داده میشوند. این فرایند چندان متفاوت از آموزش دادن یک کودک نیست.
برای مثال، فرض کنید میخواهید به یک کودک یاد بدهید حیوانات، پرندگان و میوهها را تشخیص دهد. شما تصاویر را به او نشان میدهید و ویژگیهای مشخصه هرکدام را توضیح میدهید: یک سیب قرمز و گرد است و یک موز زرد و کشیده است. اگر حیوانی راهراه سیاه و سفید داشته باشد، گورخر است و اگر راهراه زرد و سیاه داشته باشد، ببر است.
مدل دستهبندی داده در هوش مصنوعی هم در یادگیری نظارتشده (Supervised Learning) رویکرد مشابهی دارد و این فرایند معمولا در دو مرحله انجام میشود:
مرحله اول: یادگیری مدل (Model Learning)
در این مرحله، مدل با دادههای آموزشی تغذیه میشود. این دادهها بهصورت سیستماتیک برچسبگذاری شدهاند و هر نمونه در کلاس درست خود قرار گرفته است. با مشاهده این دادههای سازمانیافته، سیستم هوش مصنوعی میتواند شروع به درک الگوها کند.
برای مثال، یک ابزار هوش مصنوعی که برای مرتبسازی نامهها استفاده میشود، ممکن است با تعداد زیادی آدرس دستنویس آموزش ببیند. از آنجایی که همه این آدرسها بهدرستی برچسبگذاری شدهاند، سیستم میتواند یاد بگیرد که انسانها حروف را چگونه مینویسند؛ چیزی که برای دستهبندی موثر در یادگیری ماشین حیاتی است. به این ترتیب، مدل قادر خواهد بود آدرسها روی پاکتها را اسکن کند و آنها را بر اساس کد پستی دستهبندی کند.
مرحله دوم: ارزیابی مدل (Model Evaluation)
پس از آموزش مدل، گام بعدی این است که بررسی کنیم مدل تا چه حد بهدرستی یاد گرفته است. برای این کار، یک مجموعه دادهی دیگر در اختیار مدل قرار میگیرد؛ مجموعهای متفاوت از دادههای آموزشی اما همچنان بهدرستی برچسبگذاریشده. با این تفاوت که این بار مدل برچسبها را نمیبیند و باید صرفا بر اساس آموختههای قبلی خودش پیشبینی کند. سپس خروجیهای مدل با برچسبهای واقعی مقایسه میشوند تا میزان دقت آن محاسبه شود.
برای بازگشت به مثال مرتبسازی نامهها: در این مرحله، مدل یک دسته جدید از آدرسهای دستنویس دریافت میکند و باید خودش کدهای پستی را بخواند و دستهبندی کند. سپس خروجیهایش با کدهای پستی واقعی مقایسه میشوند و عملکرد مدل با استفاده از معیارهایی مثل موارد زیر سنجیده خواهد شد:
- دقت (Accuracy): درصد پاسخهای درست.
- دقت مثبت یا صحت (Precision): اگر مدل بگوید یک نماد عدد ۷ است، چند بار درست گفته است؟
- بازخوانی (Recall): از تمام دفعاتی که عدد ۷ ظاهر شده، مدل چند بار آن را شناسایی کرده است؟
- امتیاز F1 (F1 Score): معیاری متوازن که دقت (Precision) و بازخوانی (Recall) را با هم ترکیب میکند و برای دادههای نامتوازن یا دستهبندیهای دشوار کاربرد زیادی دارد.
اگر عملکرد مدل بهاندازه کافی خوب نباشد، باید دوباره آموزش داده شود. بر اساس نتایج، ممکن است به دادههای آموزشی بیشتری نیاز داشته باشد، ویژگیهای متفاوتی را بررسی کند یا پارامترهای داخلیاش تنظیم شوند.
انواع رایج الگوریتمهای دستهبندی در مدلهای هوش مصنوعی
تا اینجا درباره فرایند یادگیری مدل صحبت کردیم. اما مدل دقیقا چطور از دادههای آموزشی برای یادگیری استفاده میکند؟ اینجاست که الگوریتمهای آموزشی وارد عمل میشوند.
به طور کلی این الگوریتمها را میتوان به دو دسته تقسیم کرد: یادگیرندههای مشتاق (Eager Learners) و یادگیرندههای تنبل (Lazy Learners).
یادگیرندههای مشتاق مدلهایی هستند که قبل از استقرار (Deployment) آموزش داده میشوند.
یادگیرندههای تنبل برعکس، عملا آموزش نمیبینند. آنها فقط دادههای آموزشی را ذخیره میکنند و وقتی ورودی جدیدی دریافت میکنند، نزدیکترین نمونه مشابه در دادههای آموزشی را پیدا کرده و بر اساس آن تصمیم میگیرند.
در ادامه نگاهی میاندازیم به برخی از این الگوریتمها، ابتدا با دستهی یادگیرندههای مشتاق:
۱- رگرسیون لجستیک (Logistic Regression)
این الگوریتم به مدل کمک میکند تصمیمی دودویی بگیرد؛ یعنی انتخاب بین دو نتیجه ممکن. رگرسیون لجستیک دادههای ورودی را بررسی میکند و احتمال تعلق آنها به هر یک از دو دسته را محاسبه میکند.
برای مثال، ممکن است به سوابق اعتباری یک فرد نگاه کند: تعداد دفعاتی که در گذشته وام بازپرداخت نشده، وضعیت مالی فعلی او و سایر عوامل. سپس بر اساس این اطلاعات، احتمال اینکه آن فرد دوباره وام را نکول کند محاسبه میشود و همین احتمال مبنای تصمیم «بله» یا «خیر» در تایید وام قرار میگیرد.
| ✨توضیح فنی برای توسعهدهندهها
رگرسیون لجستیک از تابع سیگموید (Sigmoid Function) برای نگاشت مقادیر ورودی به احتمالات بین ۰ و ۱ استفاده میکند. خروجی نهایی معمولا با یک آستانه (مثلا ۰.۵) مقایسه میشود تا کلاس نهایی مشخص شود. این الگوریتم بهدلیل سادگی و قابلیت تفسیر آسان، یکی از پرکاربردترین روشها برای دستهبندی دودویی است. |
۲- درخت تصمیم (Decision Trees)
درخت تصمیم شبیه یک فلوچارت (Flowchart) است که در آن هر شاخه نشاندهنده یک شرط یا انتخاب است. احتمالا خودتان هم از چنین منطقی در زندگی روزمره استفاده کردهاید؛ مثلا برای تصمیمگیری در مورد شام. اول تصمیم میگیرید «آشپزی کنم یا بیرون غذا بخورم؟»
اگر انتخاب شما بیرون رفتن باشد، سوال بعدی میشود: «امشب چه نوع غذایی دوست دارم؟»
و سپس: «میخواهم در رستوران غذا بخورم یا بیرونبر بگیرم؟»
مدلهای هوش مصنوعی نیز از درخت تصمیم به شکل مشابهی استفاده میکنند.
برای نمونه، در مسئله درخواست وام، مدل ممکن است ابتدا درآمد متقاضی را بررسی کند. اگر کمتر از یک حد مشخص باشد، درخواست بلافاصله رد میشود. اگر بالاتر باشد، سؤال بعدی مطرح میشود: «آیا قبلا وام نکول کرده است یا خیر؟»
این روند ادامه پیدا میکند تا مدل اطلاعات کافی برای تصمیمگیری نهایی داشته باشد: تایید یا رد درخواست وام.
| ✨توضیح فنی برای توسعهدهندهها
درخت تصمیم دادهها را با تقسیمهای متوالی (Splits) بر اساس ویژگیها (Features) طبقهبندی میکند. هر تقسیم بر اساس معیاری مثل Gini Impurity یا Entropy (Information Gain) انتخاب میشود. یکی از مزیتهای اصلی این الگوریتم، قابلیت تفسیرپذیری بالاست اما نقطه ضعفش این است که بهسادگی دچار Overfitting میشود. برای رفع این مشکل معمولا از روشهایی مثل Pruning یا مدلهای ترکیبی مانند Random Forest استفاده میشود. |
۳- جنگل تصادفی (Random Forests)
دلیل نامگذاری این الگوریتم «جنگل» این است که بهجای یک درخت تصمیم، از مجموعهای از درختها استفاده میکند. در جنگل تصادفی، هر درخت تصمیم روی یک عامل متفاوت تمرکز میکند.
برای مثال، در مسئله درخواست وام:
- یک درخت ممکن است روی حقوق متقاضی تمرکز کند،
- درخت دیگر روی سابقه بازپرداخت،
- و درخت دیگری روی ثبات شغلی.
هر درخت بخشی از دادهها را بررسی میکند که بر نتیجه اثر میگذارد. در پایان، مدل نتایج همه درختها را با هم ترکیب میکند تا تصمیمی متعادلتر و قابل اعتمادتر بگیرد.
| ✨توضیح فنی برای توسعهدهندهها
الگوریتم Random Forest با استفاده از Bootstrap Aggregation (Bagging) کار میکند. دادهها بهصورت تصادفی نمونهگیری میشوند و برای هر نمونه یک درخت تصمیم ساخته میشود. سپس پیشبینی نهایی از طریق رایگیری اکثریت (Majority Voting) در مسائل دستهبندی یا میانگینگیری در مسائل رگرسیون به دست میآید. مزیت اصلی این روش کاهش Overfitting و افزایش دقت مدل است، اما نقطه ضعف آن افزایش مصرف منابع و زمان آموزش/پیشبینی نسبت به یک درخت تصمیم ساده است. |
۴- ماشین بردار پشتیبان (Support Vector Machines – SVM)
ماشین بردار پشتیبان یا به اختصار SVM الگوریتمی است که دادهها را به دو یا چند دسته تقسیم میکند، با پیدا کردن بهترین مرز (Boundary) بین آنها. این الگوریتم با استفاده از ویژگیهای ورودی، نقشهای از نقاط داده ایجاد میکند و بر اساس این نقشه مشخص میکند داده جدید در کدام سمت مرز قرار میگیرد.
برای مثال در مسئله درخواست وام، مدل ممکن است ویژگیهایی مانند میزان حقوق، سابقه نکول و سایر عوامل مرتبط را در نظر بگیرد تا الگوی جداکننده بین درخواستهای تاییدشده و ردشده را یاد بگیرد. این خط مجازی جداکننده همان چیزی است که به آن مرز تصمیم SVM (SVM Decision Boundary) گفته میشود. وقتی داده جدیدی وارد میشود، مدل بررسی میکند که آن داده در کدام سمت این مرز قرار دارد و بر اساس آن تصمیمگیری میکند.
| ✨توضیح فنی برای توسعهدهندهها
SVM با استفاده از مفهوم Hyperplane دادهها را از هم جدا میکند و تلاش میکند بیشترین فاصله (Maximum Margin) ممکن را بین کلاسها ایجاد کند. در حالت غیرخطی، با استفاده از Kernel Trick دادهها به یک فضای با ابعاد بالاتر منتقل میشوند تا جداسازی سادهتر شود. این الگوریتم برای مجموعه دادههایی با ابعاد بالا (High-dimensional Data) و زمانی که مرز تصمیمگیری واضح نیست، بسیار موثر است. نقطه ضعف اصلی آن هزینه محاسباتی بالا برای دادههای بزرگ است. |
۵- شبکههای عصبی (Neural Networks)
درختهای تصمیم الگوریتمهایی مبتنی بر قانون هستند که هر تصمیم در آنها بر اساس مراحل مشخصی گرفته میشود. جنگلهای تصادفی هم مبتنی بر قانوناند، با این تفاوت که یک سیستم «رایگیری» میان چند درخت برقرار میکنند. اما شبکههای عصبی بیشترین شباهت را به شیوه یادگیری و پردازش اطلاعات در انسان دارند.
یک شبکه عصبی از چندین لایهی واحدهای تصمیمگیری تشکیل میشود که معمولا «نرون» نامیده میشوند. هر نرون بخشی از ورودی را پردازش کرده و خروجی خود را به لایه بعدی میفرستد.
همانند مغز انسان، هر تصمیم یک فرصت یادگیری به حساب میآید. این ویژگی باعث میشود مدل در پیشبینی نتایج بهمرور دقیقتر شود، حتی زمانی که دادهها مبهم، پیچیده یا نامرتب باشند. به همین دلیل، شبکههای عصبی پایهی اصلی مدلهای یادگیری عمیق (Deep Learning) محسوب میشوند.
| ✨توضیح فنی برای توسعهدهندهها
شبکههای عصبی معمولا شامل سه بخش هستند: لایه ورودی (Input Layer)، لایههای میانی یا پنهان (Hidden Layers) و لایه خروجی (Output Layer). هر اتصال بین نرونها یک وزن (Weight) دارد که در طول آموزش بهروزرسانی میشود. الگوریتمهای Backpropagation و بهینهسازهایی مانند Stochastic Gradient Descent (SGD) یا Adam برای آموزش این وزنها استفاده میشوند. شبکههای عصبی قابلیت پردازش دادههای پیچیده مثل تصاویر، صدا و متن را دارند اما به منابع محاسباتی بالایی نیاز دارند. |
۶- نزدیکترین همسایهها (K-Nearest Neighbors – KNN)
KNN اولین الگوریتم از دستهی «یادگیرندههای تنبل (Lazy Learners)» است. این الگوریتم دادههای ورودی را بر اساس شباهتشان با دادههایی که قبلا دیده دستهبندی میکند. همانطور که از یک یادگیرندهی تنبل انتظار میرود، KNN هیچ مدلی از قبل نمیسازد. در عوض، همه دادههای آموزشی را ذخیره میکند و فقط زمانی که نیاز به تصمیمگیری باشد، از آنها استفاده میکند.
برای مثال، اگر مدل بررسی درخواست وام بر اساس KNN ساخته شده باشد، الگوریتم به درخواستهای مشابه گذشته نگاه میکند. اگر بیشتر آنها تایید شده باشند، این درخواست هم تایید میشود و اگر بیشترشان رد شده باشند، احتمالا این یکی هم رد خواهد شد.
KNN برای مواردی مناسب است که رابطه بین ورودیها و خروجیها پیچیده باشد اما الگوهای محلی (Local Patterns) اهمیت زیادی داشته باشند. این الگوریتم بسیار ساده و شهودی است و به دوره آموزشی طولانی هم نیاز ندارد.
| ✨توضیح فنی برای توسعهدهندهها
در KNN، فاصله بین نقاط داده (Data Points) با معیارهایی مثل Euclidean Distance یا Manhattan Distance اندازهگیری میشود. سپس K نمونه نزدیکتر به ورودی انتخاب میشوند و دستهبندی نهایی بر اساس رای اکثریت آنها تعیین میشود. KNN معمولا در مسائل کوچک و متوسط کارآمد است اما برای دادههای بسیار بزرگ یا با ابعاد بالا (High-dimensional Data) میتواند کند و ناکارآمد شود. |
۷- بیز ساده (Naive Bayes)
یکی دیگر از الگوریتمهای یادگیرنده تنبل (Lazy Learners)، الگوریتم Naive Bayes است که برای پیشبینی از احتمال استفاده میکند. این الگوریتم داده ورودی را بررسی میکند و با استفاده از روشهای علم داده، آن را در محتملترین دسته قرار میدهد. به بیان ساده، احتمال هر خروجی ممکن را محاسبه کرده و بیشترین احتمال را انتخاب میکند.
علت اینکه به آن «ساده» (Naive) گفته میشود این است که فرض میکند هر ویژگی ورودی از ویژگیهای دیگر مستقل است. با وجود این فرض سادهساز، عملکرد این الگوریتم بسیار خوب است، بهویژه در کارهایی مانند دستهبندی متون، از جمله تشخیص اسپم یا تحلیل احساسات (Sentiment Analysis).
| ✨توضیح فنی برای توسعهدهندهها
Naive Bayes بر اساس قضیه بیز (Bayes’ Theorem) عمل میکند: P(C∣X)=P(X∣C)⋅P(C) / P(X) که در آن C کلاس و X داده ورودی است. الگوریتم با محاسبه احتمال شرطی، محتملترین کلاس را انتخاب میکند. مزیت اصلی آن سرعت بالا و کارایی عالی در دادههای متنی بزرگ است اما نقطهضعفش این است که فرض استقلال ویژگیها در دنیای واقعی همیشه برقرار نیست. |
نتیجهگیری
دستهبندی در عمل یعنی ترکیب درستِ داده، الگوریتم و معیار ارزیابی. انتخاب بین دودویی، چندکلاسه یا چندبرچسبی باید از دلِ مسئله بیرون بیاید و در سناریوهای نامتوازن، طراحی شما بدون توجه به Precision/Recall و F1 ناقص میماند. از سوی دیگر، هیچ الگوریتمی پاسخ همهچیز نیست:
- وقتی سادگی و تفسیرپذیری مهم است، Logistic Regression و Decision Tree نقطه شروع خوبیاند.
- برای بهبود پایداری و دقت روی دادههای متنوع، Random Forest اغلب نتیجه مطمئنی میدهد.
- اگر مرز تصمیم پیچیده است یا فضا پُربعد شده، SVM و در مسائل مُدرنتر شبکههای عصبی میتوانند بهتر ظاهر شوند.
- وقتی به راهکاری سریع و شهودی نیاز داری یا الگوهای محلی مهماند، KNN انتخاب مناسبی است.
- برای متن و ویژگیهای آماری سادهتر، Naive Bayes همچنان کارآمد و کمهزینه است.
گامهای بعدی برای پیادهسازی در پروژههای واقعی:
۱. آمادهسازی داده و تعریف دقیق مسئله (Binary/Multiclass/Multilabel)،
۲. ساخت خط لولهی آموزش/اعتبارسنجی با معیارهای مناسب و رسیدگی به عدمتوازن،
۳. انتخاب چند مدل پایه بهعنوان Baseline و مقایسهی سیستماتیک،
۴. تنظیم ابرپارامترها و مستندسازی آزمایشها،
۵. استقرار و پایش مداوم با تمرکز بر خطاهای پرریسک.
با چنین رویکردی، خروجی شما صرفا یک مدل نیست؛ بلکه یک راهکار قابل اتکا است که در برابر دادههای واقعی دوام میآورد و برای توسعه و نگهداری در چرخه محصول آماده است.
منابع
bigid.com
سوالات متداول
در دستهبندی (Classification) دادهها در کلاسهای از پیش تعریفشده قرار میگیرند، در حالی که خوشهبندی (Clustering) کلاسها را از قبل نمیداند و خودش الگوها و گروهها را کشف میکند.
زمانی که فقط دو نتیجه ممکن وجود داشته باشد؛ مثل تشخیص اسپم یا غیراسپم، پیشبینی بیماری یا نبود آن، و تایید یا رد درخواست وام.
چون در بسیاری از مسائل واقعی مثل تشخیص تقلب یا شناسایی بیماری، دادههای مثبت بسیار کمتر از دادههای منفی هستند. بدون مدیریت درست، مدل ممکن است رویدادهای مهم را نادیده بگیرد.
با استفاده از معیارهایی مانند Accuracy، Precision، Recall و F1 Score. هر معیار برای شرایط خاصی اهمیت دارد؛ مثلا در دادههای نامتوازن، تمرکز بیشتر روی Precision و Recall منطقیتر است.
از رایجترینها میتوان به Logistic Regression، Decision Trees، Random Forest، SVM، Neural Networks، KNN و Naive Bayes اشاره کرد. هر کدام نقاط قوت و ضعف خاص خود را دارند.
کتابخانههایی مثل scikit-learn برای الگوریتمهای کلاسیک و TensorFlow/Keras یا PyTorch برای مدلهای عمیقتر (Deep Learning) پرکاربرد هستند.


دیدگاهتان را بنویسید