در سالهای اخیر، مدلهای زبانی بزرگ توانستهاند نحوهی تعامل انسان و ماشین را متحول کنند اما محدودیت آنها در دسترسی به دانش روز، چالشی جدی در کاربردهای واقعی ایجاد کرده است. معماری Retrieval-Augmented Generation پاسخی هوشمند به این چالش است. در این ساختار، بهجای آموزش مجدد مدل با دادههای جدید، اطلاعات مرتبط از یک منبع بیرونی واکشی و به مدل تزریق میشود تا خروجی نهایی هم دقیقتر باشد و هم قابل استناد. همین ویژگی باعث شده روشهای پیادهسازی RAG به یکی از داغترین مباحث میان توسعهدهندگان سیستمهای هوش مصنوعی تبدیل شود.
در این مقاله، ابتدا معماری کلی RAG و اجزای کلیدی آن را مرور میکنیم و سپس به معرفی و مقایسه روشهای مختلف پیادهسازی آن میپردازیم. در ادامه، فریمورکهای پرکاربردی مانند LangChain، Haystack، LlamaIndex و Amazon Bedrock را بررسی خواهیم کرد و در پایان یک چکلیست عملی برای ساخت و استقرار سیستم RAG در محیط تولید ارائه میدهیم.
RAG چیست؟

RAG (Retrieval-Augmented Generation) یک معماری ترکیبی است که توانایی درک و تولید زبان طبیعی مدلهای زبانی بزرگ را با قابلیت جستوجو و بازیابی اطلاعات واقعی ترکیب میکند. بهجای تکیهی کامل بر دادههای مدل از پیش آموزشدیده، RAG در لحظهی پاسخگویی، دادههای مرتبط را از یک منبع خارجی – مثل پایگاه دانش، اسناد داخلی یا ایندکس برداریشده – استخراج کرده و آنها را به ورودی مدل تزریق میکند.
این رویکرد باعث میشود مدل بتواند پاسخهایی بهروز، مستند و منطبق با دادههای واقعی تولید کند. در عمل، RAG شامل دو مولفهی اصلی است:
- بازیاب (Retriever): مسئول یافتن قطعات متنی مرتبط از میان دادههای ذخیرهشده است.
- مولد (Generator): وظیفه دارد با استفاده از این اطلاعات، پاسخی منسجم و طبیعی تولید کند.
اهمیت RAG در حل دو چالش بزرگ مدلهای زبانی نهفته است:
- بهروزرسانی مداوم دانش: بدون نیاز به بازآموزی کامل مدل میتوان دادههای جدید را به سیستم افزود.
- کاهش توهم مدل و افزایش اعتمادپذیری: چون پاسخها مستقیما از منابع واقعی استخراج میشوند، احتمال تولید اطلاعات نادرست بهشدت کاهش پیدا میکند.
در نتیجه، RAG بستری ایجاد میکند که هوش مصنوعی را از یک «تولیدکننده عمومی متن» به یک دستیار دادهمحور و قابل اعتماد تبدیل میکند؛ رویکردی که امروز در بسیاری از سامانههای سازمانی، موتورهای جستوجوی هوشمند و ابزارهای پرسشوپاسخ مبتنی بر دانش بهکار گرفته میشود.
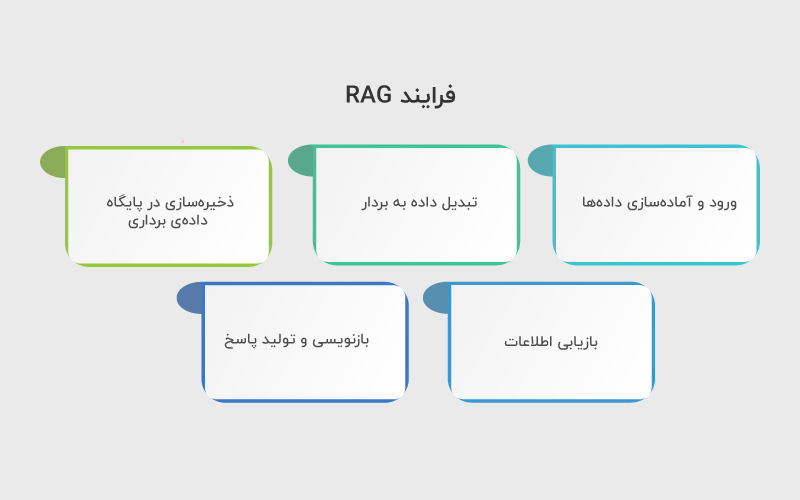
فرایند RAG
به بیان سادهتر، RAG پلی میان دو جهان است: جهان زبان (Language) و جهان دانش (Knowledge).
فرایند کار RAG معمولا در چند گام پیادهسازی میشود:
۱. ورود و آمادهسازی دادهها (Ingestion & Preprocessing):
در این مرحله، اسناد از منابع مختلف (فایلها، پایگاه داده، صفحات وب و…) گردآوری و به قطعات کوچکتر تقسیم میشوند (chunking). این کار باعث میشود سیستم بتواند در مرحله بازیابی، بخشهای دقیقتر و مرتبطتری را پیدا کند.
۲. تبدیل داده به بردار (Embedding):
هر قطعه متنی به یک نمایش عددی (embedding) تبدیل میشود که معنا و مفهوم جمله را در یک فضای چندبُعدی حفظ میکند. این مرحله پایه اصلی جستوجوی معنایی در RAG است.
۳. ذخیرهسازی در پایگاه دادهی برداری (Vector Database):
امبدینگها در دیتابیسهایی مثل FAISS، Pinecone، Milvus یا Weaviate ذخیره میشوند. این پایگاهها امکان جستوجوی سریع و دقیق بر اساس شباهت معنایی را فراهم میکنند.

۴. بازیابی اطلاعات (Retrieval):
زمانی که کاربر پرسشی مطرح میکند، متن ورودی نیز به بردار تبدیل و با دادههای ذخیرهشده مقایسه میشود تا نزدیکترین بخشهای مرتبط شناسایی گردند. این قسمت میتواند بر پایه جستوجوی dense (برداری)، sparse (کلیدواژهای) یا ترکیبی از هر دو باشد.
۵. بازنویسی و تولید پاسخ (Generation):
قطعات بازیابیشده همراه با پرسش کاربر در قالب یک prompt به مدل زبانی (مثل GPT، Claude یا Llama) داده میشوند. مدل با ترکیب اطلاعات بیرونی و دانش زبانی خود، پاسخ نهایی را تولید میکند.
در برخی پیادهسازیها، مرحلهای به نام Reranking نیز بین Retrieval و Generation اضافه میشود تا نتایج دقیقتر شوند. این کار بهویژه در محیطهای تولیدی برای کنترل کیفیت و کاهش هالوسینیشن بسیار موثر است.
روشهای بازیابی و ترکیب
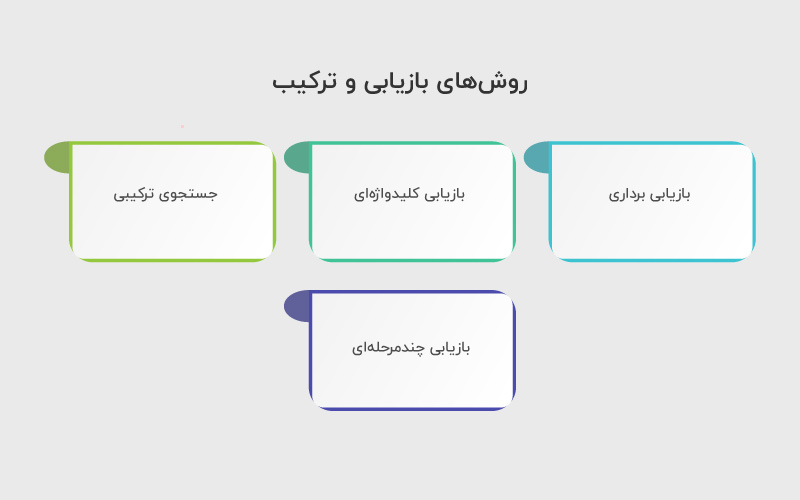
در سیستمهای RAG، انتخاب روشهای بازیابی (Retrieval Patterns) یکی از تعیینکنندهترین مراحل است؛ زیرا کیفیت دادههای بازیابیشده مستقیما بر دقت و واقعگرایی پاسخ نهایی اثر میگذارد. چهار الگوی اصلی برای این مرحله وجود دارد که هرکدام مزایا، محدودیتها و کاربردهای خاص خود را دارند.
۱. بازیابی برداری (Dense Retrieval):
در این روش، متنها و پرسشها با استفاده از مدلهای تعبیه یا Embedding به بردارهایی در فضای معنایی تبدیل میشوند. سپس با مقایسهی فاصلهی این بردارها (مثلا با معیارهایی مانند cosine similarity)، نزدیکترین اسناد به پرسش کاربر انتخاب میشوند. مزیت اصلی Dense Retrieval در درک مفاهیم نهفته و شباهتهای معنایی است؛ حتی اگر کلمات دقیق یکسان نباشند. ابزارهایی مانند FAISS و Pinecone برای پیادهسازی این نوع جستجو کاربرد زیادی دارند.
۲. بازیابی کلیدواژهای (Sparse Retrieval):
در مقابل، روش Sparse بر پایهی تطابق صریح واژهها است. سیستمهایی مانند Elasticsearch یا OpenSearch با الگوریتمهایی نظیر BM25 کار میکنند که بسامد و اهمیت واژهها را در متن میسنجند. هرچند این رویکرد نمیتواند مشابهتهای معنایی را تشخیص دهد اما برای دادههای ساختارمند یا متون تخصصی که دقت واژگانی اهمیت دارد، گزینهای سریع و موثر است.
۳. جستجوی ترکیبی (Hybrid Search):
در بسیاری از پروژهها، استفاده همزمان از دو روش بالا بهترین نتیجه را میدهد. در جستجوی ترکیبی، امتیازات حاصل از مدل برداری و مدل کلیدواژهای با وزنهای مشخص ترکیب میشوند. بهعنوان مثال، اگر دادهها شامل متون فنی و توضیحات عمومی باشند، میتوان وزن بیشتری به بخش معنایی داد اما همچنان از دقت کلیدواژهها برای اصطلاحات تخصصی بهره برد. این روش توازنی میان دقت و پوشش اطلاعات ایجاد میکند.
۴. بازیابی چندمرحلهای (Multi-stage Retrieval):
در این الگو، فرایند بازیابی در دو گام انجام میشود: ابتدا مرحله کاندیدسازی سریع با استفاده از جستجوی برداری و سپس بازچینی (Re-ranking) اسناد برتر با مدلهای قویتر مانند cross-encoder. این روش دقتی بسیار بالا دارد اما هزینه محاسباتی بیشتری نیز به همراه میآورد. از آن برای کاربردهایی که کیفیت پاسخ حیاتی است (مثل جستجوی علمی یا پشتیبانی سازمانی) استفاده میشود.
بهطور کلی، انتخاب میان این روشها به بودجهی محاسباتی، نوع داده و حساسیت کاربرد بستگی دارد. در بسیاری از سیستمهای مدرن RAG، ترکیبی از این الگوها برای دستیابی به تعادل میان سرعت و دقت بهکار گرفته میشود.
انواع تکنیکهای پیادهسازی RAG
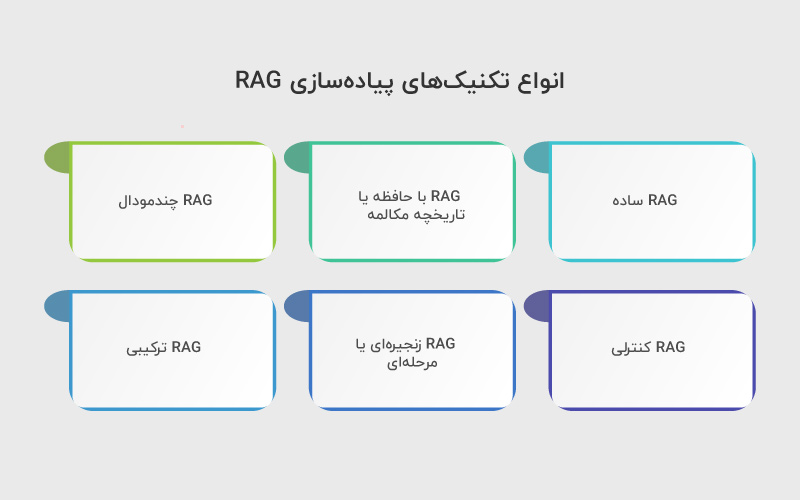
در سالهای اخیر، RAG به شکلهای مختلفی پیادهسازی شده تا نیازهای متنوع پروژهها و کاربردهای زبانی را پوشش دهد. در ادامه، شش روش مرسوم برای اجرای RAG را مرور میکنیم که هر کدام سطح متفاوتی از پیچیدگی، حافظه و کنترل را ارائه میدهند:
۱. RAG ساده (Simple RAG)
این پایهایترین شکل RAG است؛ یک کوئری از کاربر گرفته میشود، سیستم از پایگاه دانش اسناد مرتبط را بازیابی میکند و مدل زبانی بر اساس آن پاسخ تولید میکند. این ساختار برای چتباتهای اطلاعاتی، سیستمهای پرسش و پاسخ و سناریوهای کوچک آزمایشی مناسب است.
۲. RAG با حافظه یا تاریخچه مکالمه (RAG with Memory)
در این روش، مکالمات گذشته کاربر نیز در تصمیمگیری مدل نقش دارند. سیستم علاوهبر بازیابی اطلاعات جدید، به پیامهای پیشین مراجعه میکند تا پاسخها منسجمتر و زمینهمند باشند. این روش برای چتباتهای هوشمند و دستیارهای گفتگو محور (مانند Copilot یا ChatGPT plugins) بسیار موثر است.
۳. RAG چندمودال (Multimodal RAG)
در نسخههای چندمودال، ورودی تنها متن نیست؛ تصاویر، صدا، یا دادههای ساختاریافته نیز بهعنوان منبع دانش به سیستم افزوده میشوند. مثلا در پزشکی یا بینایی کامپیوتر، تصویر اسکن یا چارت میتواند همراه با متن پردازش شود. این نوع RAG برای مدلهای چندوجهی مانند Gemini و GPT-4V کاربرد دارد.
۴. RAG کنترلی (Controlled RAG)
در این الگو، مرحلهی بازیابی یا تولید با فیلترها و کنترلهای اضافی انجام میشود. مثلا با Re-ranking برای مرتبسازی دقیقتر نتایج یا Content Filtering برای حذف دادههای نامناسب. از این نوع در سیستمهای سازمانی و حوزههایی با حساسیت بالا (مانند حقوقی یا پزشکی) استفاده میشود.
۵. RAG زنجیرهای یا مرحلهای (Pipeline/Iterative RAG)
در این ساختار، خروجی هر مرحله بازیابی، ورودی مرحله بعدی است. سیستم بهصورت تدریجی دانش را غنیتر میکند و پاسخ نهایی را در چند مرحله میسازد. این روش برای تحلیلهای عمیق یا ترکیب داده از منابع متعدد مفید است.
۶. RAG ترکیبی (Hybrid/Ensemble RAG)
در این مدل، چند تکنیک RAG بهصورت همزمان استفاده میشوند؛ مثلا ترکیب حافظه بلندمدت با فیلتر کنترلی و چندمودال. این الگو در محیطهای production-grade متداول است، چون انعطاف و دقت بالاتری ایجاد میکند.
انتخاب فریمورک مناسب برای پیادهسازی RAG
در مرحله انتخاب فریمورک برای پیادهسازی RAG، شناخت تفاوتها و نقاط قوت هر ابزار اهمیت زیادی دارد. هرچند هدف همهی این فریمورکها یکسان است؛ یعنی اتصال موثر مدل زبانی به دادههای خارجی اما مسیر دستیابی به آن متفاوت است.
فریمورکهایی مثل LangChain و Haystack بیشتر روی ساختاردهی pipeline و orchestration تمرکز دارند، در حالی که LlamaIndex بر ایندکسسازی دادهها و ساختارهای پرسوجو متمرکز است. در سمت دیگر، پلتفرمهای ابری مانند Amazon Bedrock رویکردی سازمانیتر و مقیاسپذیر ارائه میدهند که برای پروژههای production-ready مناسبترند.
جدول زیر مقایسهی کوتاه و عملی میان این گزینهها را نشان میدهد:
| فریمورک / پلتفرم | تمرکز اصلی | مزایا | محدودیتها | موارد استفادهی مناسب |
| LangChain | Orchestration، ساخت زنجیرههای منطقی بین مدل، حافظه و پایگاه داده | انعطاف بالا، اکوسیستم گسترده، پشتیبانی از مدلها و دیتابیسهای متعدد | نیاز به تنظیمات زیاد برای production، یادگیری اولیه نسبتا دشوار | پروژههای تحقیق و توسعه، prototype تا سطح production |
| Haystack | جستوجو، بازیابی و ریرنکینگ در مقیاس production | pipelineهای آماده، performance بالا، پشتیبانی از Elasticsearch و FAISS | سفارشیسازی کمتر نسبت به LangChain | سیستمهای جستوجوی سازمانی، پشتیبانی مشتری، FAQ bot |
| LlamaIndex | مدیریت و ایندکسسازی داده برای دسترسی سریع و ساختارمند | معماری ساده، مناسب برای دادههای بزرگ و چندمنبعی | نیاز به ادغام با سایر ابزارها برای orchestration | پروژههایی با دادههای گسترده یا ساختار درختی (مثلا دانش فنی) |
| Amazon Bedrock + LangChain | سرویس ابری برای استقرار RAG با مدلهای آماده | مقیاسپذیر، امنیت سازمانی، یکپارچگی با AWS | هزینه بالا و وابستگی به محیط AWS | سازمانها و استارتاپهایی با نیاز به استقرار سریع و پایدار |
این مقایسه نشان میدهد که انتخاب فریمورک بستگی مستقیم به مقیاس پروژه، نوع داده و سطح کنترل مورد نیاز دارد. LangChain برای توسعهدهندگان منعطفترین گزینه است، Haystack برای پروژههای پایدار، LlamaIndex برای مدیریت دادهی پیچیده و Bedrock برای محیطهای ابری سازمانی.
کنترل کیفیت و عملیاتیسازی RAG در محیط تولید
برای پیادهسازی موفق RAG در محیطهای واقعی، دو محور اصلی اهمیت دارند: کیفیت تولید پاسخها و مقیاسپذیری و مانیتورینگ سیستم.
۱- تضمین کیفیت و کاهش هالوسینیشن
مدلهای زبانی به تنهایی گاهی پاسخهای نادرست یا غیرمستند تولید میکنند. برای کاهش این مشکل، از تکنیکهای prompt engineering، chain-of-thought prompting و source attribution استفاده میشود تا مدل پاسخها را با منابع واقعی تطبیق دهد.
علاوهبر این، به کمک reranker یا cross-encoder میتوان نتایج نامرتبط بازیابیشده را قبل از ارسال به LLM فیلتر کرد و دقت پاسخها را افزایش داد. استفاده از فیلترهای fact-check و بررسی متقابل پاسخها با منابع معتبر، اعتمادپذیری سیستم را بهبود میبخشد.
۲- مقیاسپذیری و عملیاتیسازی
برای محیط تولید، بهینهسازی latency و هزینه محاسباتی ضروری است. تکنیکهایی مانند caching نتایج بازیابی، batching درخواستها و استفاده از auto-scaling برای retriever و LLM، به حفظ عملکرد سیستم کمک میکنند. همچنین، مانیتورینگ دقیق با معیارهایی مانند نرخ بازیابی صحیح (retrieval accuracy)، nDCG، زمان پاسخ (latency) و خطاها (error rate) امکان ارزیابی مداوم کیفیت و کارایی سیستم را فراهم میکند.
۳- امنیت و حریم خصوصی
در محیطهای سازمانی، کنترل دسترسی به دادههای حساس، رمزنگاری اطلاعات و پاکسازی لاگها از اهمیت ویژهای برخوردار است تا هم امنیت دادهها و هم رعایت قوانین حفاظت از اطلاعات تضمین شود.
نمونه پیادهسازی گامبهگام RAG
برای درک عملی RAG، مرور دو نمونه پیادهسازی رایج میتواند مفید باشد: یکی ساده و محلی و دیگری مبتنی بر سرویس ابری سازمانی.
مثال ۱: Pipeline ساده با LangChain + Vector Store محلی
این روش مناسب پروژههای کوچک، نمونهسازی سریع و محیطهای تحقیقاتی است. مراحل اصلی به شرح زیر هستند:
۱. Ingest (ورود داده): ابتدا اسناد متنی از منابع مختلف (PDF، CSV، صفحات وب) جمعآوری و به بخشهای کوچک تقسیم میشوند تا در مرحله بازیابی، قطعات مرتبط سریعتر یافت شوند.
|
1 2 3 4 5 6 |
from langchain.document_loaders import TextLoader # بارگذاری اسناد متنی loader = TextLoader(“my_documents.txt”) # مسیر فایل یا فولدر documents = loader.load() print(f“تعداد اسناد بارگذاری شده: {len(documents)}”) |
۲. Embed (ایجاد بردار معنایی): هر بخش از متن با مدل embedding به یک بردار چندبعدی تبدیل میشود. این بردارها نمایانگر معنی و مفاهیم متن هستند و امکان جستوجوی معنایی را فراهم میکنند.
|
1 2 3 4 5 6 7 8 9 |
from langchain.text_splitter import CharacterTextSplitter from langchain.embeddings import OpenAIEmbeddings # تقسیم متن به بخشهای کوچک برای بازیابی بهتر text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100) docs = text_splitter.split_documents(documents) # ساخت embedding embeddings = OpenAIEmbeddings() # نیاز به OPENAI_API_KEY |
۳. Index (ایندکسسازی): بردارهای ایجاد شده در یک پایگاه دادهی برداری محلی مانند FAISS ذخیره میشوند تا بازیابی سریع انجام شود.
|
1 2 3 4 |
from langchain.vectorstores import FAISS # ایجاد پایگاه داده برداری FAISS vectorstore = FAISS.from_documents(docs, embeddings |
۴. Retrieve (بازیابی اطلاعات): هنگام دریافت پرسش کاربر، متن پرسش نیز به بردار تبدیل شده و نزدیکترین اسناد از پایگاه داده استخراج میشوند. این مرحله تضمین میکند که مدل با دادههای واقعی و مرتبط تغذیه شود.
|
1 2 3 4 5 6 7 |
# ساخت retriever برای بازیابی k سند مرتبط retriever = vectorstore.as_retriever(search_kwargs={“k”: 3}) # بررسی یک پرسش نمونه query = “توضیح کوتاه درباره روشهای پیادهسازی RAG بده.” retrieved_docs = retriever.get_relevant_documents(query) print(f“تعداد اسناد بازیابی شده: {len(retrieved_docs)}”) |
۵. Prompt + Generate (تولید پاسخ): قطعات بازیابیشده همراه با پرسش به مدل زبانی ارسال میشوند تا پاسخ نهایی تولید شود. میتوان از تکنیکهایی مانند prompt chaining و context window management برای بهبود دقت استفاده کرد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from langchain.chains import RetrievalQA from langchain.llms import OpenAI # ساخت RAG chain qa_chain = RetrievalQA.from_chain_type( llm=OpenAI(temperature=0), chain_type=“stuff”, retriever=retriever ) # تولید پاسخ نهایی answer = qa_chain.run(query) print(“پاسخ مدل:\n”, answer) |
مثال ۲: پیادهسازی Bedrock + LangChain
این نمونه برای پروژههای سازمانی و محیطهای ابری بزرگ مناسب است و امکان مقیاسپذیری، امنیت و یکپارچگی با سایر سرویسهای AWS را فراهم میکند:
۱. اتصال و احراز هویت: ابتدا حساب AWS Bedrock ایجاد و دسترسیها با استفاده از IAM و کلیدهای API تنظیم میشوند. LangChain بهعنوان orchestration layer برای مدیریت pipeline مورد استفاده قرار میگیرد.
|
1 2 3 4 5 6 |
import boto3 # ایجاد client برای Bedrock bedrock_client = boto3.client(‘bedrock’, region_name=‘us-east-1’, aws_access_key_id=‘YOUR_ACCESS_KEY’, aws_secret_access_key=‘YOUR_SECRET_KEY’) |
۲. ورود و ایندکسسازی داده: مشابه نمونه محلی، اسناد وارد شده و به بردار تبدیل میشوند. این بردارها میتوانند در پایگاههای برداری ابری مانند Pinecone یا Amazon Kendra ذخیره شوند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import Pinecone import pinecone # اتصال به Pinecone pinecone.init(api_key=“YOUR_PINECONE_API_KEY”, environment=“us-west1-gcp”) index = pinecone.Index(“my-rag-index”) # ایجاد embedding embeddings = OpenAIEmbeddings(openai_api_key=“YOUR_OPENAI_KEY”) documents = [{“text”: “محتوای سند اول”}, {“text”: “محتوای سند دوم”}] # ایندکسسازی بردارها for doc in documents: vector = embeddings.embed_query(doc[“text”]) index.upsert(vectors=[(doc[“text”], vector)]) |
۳. بازیابی و تولید پاسخ: هنگامی که کاربر پرسشی مطرح میکند، LangChain query را به Bedrock ارسال میکند و اسناد مرتبط بازیابی میشوند. سپس مدلهای آماده ابری پاسخ را تولید کرده و به کاربر بازمیگردانند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from langchain.chains import RetrievalQA from langchain.chat_models import BedrockChat # اتصال LangChain به Pinecone و Bedrock retriever = Pinecone(index, embeddings.embed_query, “text”).as_retriever(search_kwargs={“k”: 3}) bedrock = BedrockChat(model_id=“anthropic.claude-v1”) # یا مدل دلخواه qa_chain = RetrievalQA.from_chain_type(llm=bedrock, chain_type=“stuff”, retriever=retriever) # پرسش نمونه query = “روشهای رایج پیادهسازی RAG را توضیح بده.” answer = qa_chain.run(query) print(answer) |
نکات عملی:
- محدودیتها: هزینه استفاده از API، محدودیتهای نرخ درخواست و latency باید مدنظر قرار گیرد.
- بهینهسازی: با caching بردارها و استفاده از re-ranking میتوان دقت را بالا برد و هزینهها را کاهش داد.
- امنیت و compliance: دادههای حساس باید با رمزنگاری و دسترسی محدود محافظت شوند.
چکلیست عملی برای انتشار محصولی RAG
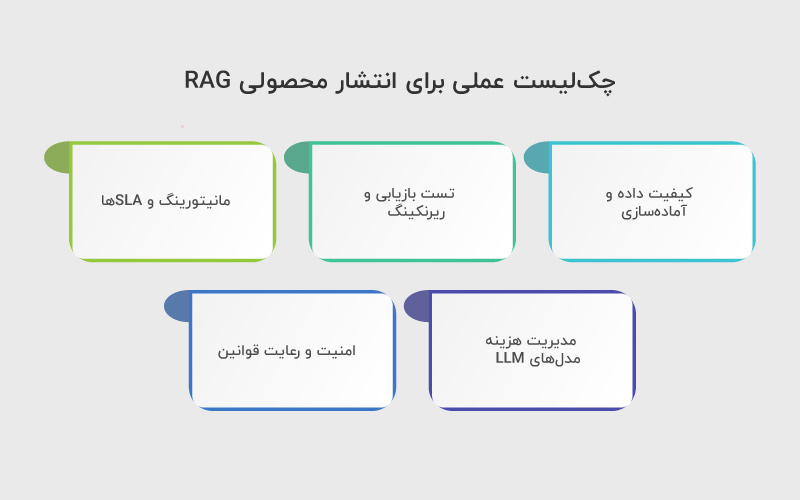
انتشار یک سیستم RAG در محیط تولید نیازمند توجه همزمان به کیفیت داده، عملکرد سیستم و مسائل امنیتی است. در ادامه، چکلیست مرحلهبهمرحله ارائه شده است:
۱. کیفیت داده و آمادهسازی:
- اطمینان از صحت و بهروز بودن اسناد و منابع
- تقسیمبندی دادهها (chunking) به اندازه مناسب برای بازیابی سریع و دقیق
۲. تست بازیابی و ریرنکینگ:
- بررسی دقت retriever با معیارهایی مانند precision@k و nDCG
- اطمینان از عملکرد صحیح re-ranker در مرتبسازی اسناد مرتبط
۳. مانیتورینگ و SLAها:
- پایش زمان پاسخ (latency) و تطبیق با SLAهای تعیین شده
- تست بار (load test) برای اطمینان از عملکرد پایدار در شرایط ترافیک بالا
۴. مدیریت هزینه مدلهای LLM:
- کنترل تعداد tokenها و batchها برای کاهش هزینه محاسباتی
- استفاده از caching و partial generation برای بهینهسازی مصرف منابع
۵. امنیت و رعایت قوانین:
- اعمال سیاستهای دسترسی و رمزنگاری دادهها
- رعایت GDPR و سایر مقررات حفاظت داده در صورت کار با اطلاعات حساس
نتیجهگیری
معماری RAG با ترکیب قدرت مدلهای زبانی و دادههای واقعی، امکان تولید پاسخهای دقیق، بهروز و قابل استناد را فراهم میکند. روشهای پیادهسازی RAG از ساده تا معماریهای چندمرحلهای و ترکیبی، با توجه به نوع داده، حجم پروژه و نیاز به مقیاسپذیری و امنیت انتخاب میشوند. فریمورکهایی مانند LangChain، Haystack، LlamaIndex و Amazon Bedrock هرکدام مزایا و محدودیتهای خود را دارند و انتخاب مناسب آنها، بستگی مستقیم به کاربرد پروژه دارد.
منابع
zenvanriel.nl | digitalocean.com | blog.logrocket.com | homayounsrp.medium.com | tigerdata.com | zenml.io
سوالات متداول
روشهای مرسوم شامل RAG ساده، RAG با حافظه مکالمه، RAG چندمودال، RAG کنترلی، RAG چندمرحلهای و RAG ترکیبی هستند که هر کدام برای نیازها و مقیاسهای متفاوت مناسباند.
LangChain، Haystack، LlamaIndex و Amazon Bedrock از محبوبترین گزینهها هستند. LangChain برای انعطاف و prototyping مناسب است، Haystack برای محیطهای production و سازمانی، LlamaIndex برای دادههای پیچیده و Bedrock برای مقیاسپذیری ابری.
اطمینان از دسترسی محدود به دادهها، رمزگذاری اطلاعات حساس و رعایت قوانین حفاظت از داده (مانند GDPR) برای محیطهای سازمانی ضروری است.

دیدگاهتان را بنویسید