
با گسترش استفاده از هوش مصنوعی در سازمانها، نیاز به پردازش و تحلیل انواع گوناگون دادهها از جمله متن، تصویر، صوت و ویدیو بیش از پیش احساس میشود. رویکرد تولید تقویتشده با بازیابی چندوجهی (Multi-Modal RAG) دقیقا برای پاسخ به همین نیاز طراحی شده است؛ این روش با ترکیب و پردازش دادهها از مدالیتههای مختلف در چارچوب RAG، امکان تولید پاسخهایی غنیتر و آگاهتر از بستر و زمینه را فراهم میکند که بر پایه منابع متنوعی از داده بنا شدهاند.
در این راهنما، معماریهای مرجع، الگوهای طراحی، و مراحل عملی پیادهسازی و مقیاسپذیری سیستمهای Multi-Modal RAG برای معماران نرمافزار، سرپرستان تیمهای مهندسی و توسعهدهندگان ارشد بهصورت گامبهگام تشریح شده است.
مفاهیم اصلی در Multi-Modal RAG
Multi-Modal RAG نسخه پیشرفتهای از معماری کلاسیک بازیابی، استدلال و تولید است که قابلیت کار با چند نوع داده را به آن اضافه میکند. در کنار ماژول متنی سنتی (Retrieval Module)، امکانات جدیدی برای پردازش تصویر، صدا و ویدیو نیز در این معماری گنجانده شده است.
۱- ماژول بازیابی: اطلاعات مرتبط را از منابع ایندکسشده مختلف (مثل اسناد متنی، پایگاه داده تصاویر یا بردارهای نهفته تصویر و صوت) بازیابی میکند.
۲- یکپارچهسازی مدالیتهها: دادههای مختلف را به فرم قابل مقایسه و درک برای مدل تبدیل میکند؛ برای نمونه، تصاویر به embedding تبدیل میشوند یا محتوای صوتی به متن پیادهسازی میشود تا در نهایت یک فضای معنایی یکپارچه ساخته شود.
۳- ماژول استدلال: اطلاعات چندوجهی را با هم ترکیب میکند تا درک عمیقتر و دقیقتری از زمینه و موضوع به دست آورد.
۴. ماژول تولید: خروجیهایی منسجم و آگاه از بستر تولید میکند که میتوانند دادههای متنی، تصویری یا صوتی را توصیف، ارجاع یا با هم ترکیب کنند.
با بهرهگیری از منابع متنوع داده، Multi-Modal RAG قادر است پاسخهایی جامعتر و هوشمندانهتر ارائه دهد. به عنوان مثال، یک دستیار بازاریابی محصول میتواند تصاویر محصولات، راهنمای برند، دفترچههای کاربر (متن)، ویدیوهای تبلیغاتی و سایر منابع را بازیابی کند و سپس یک استراتژی محتوایی تولید کند که در عین ارجاع بصری به تصاویر محصول، با لحن و روایت برند در متون نیز همخوانی داشته باشد.

الگوهای معماری و جریان داده
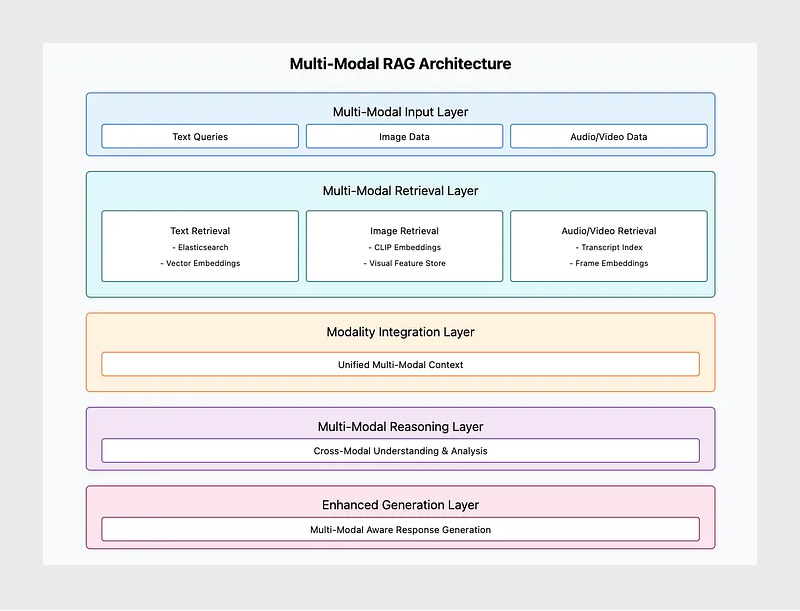
سیستمهای چندوجهی برای پردازش و پاسخدهی به درخواستهای کاربران، به معماری منظمی نیاز دارند که جریان دادهها را از دریافت پرسش تا ارائه خروجی مدیریت کند.
۱- دریافت درخواست (Query):
کاربر درخواستی چندوجهی ارسال میکند؛ برای مثال:
«جدیدترین تصویر محصول را نشان بده و مشخصات فنی آن را خلاصه کن.»
۲- بازیابی چندوجهی:
سیستم دادههای مرتبط را از منابع مختلف شامل اسناد متنی، تصاویر و در صورت وجود، پیادهسازیهای صوت یا ویدیو از ایندکسهای اختصاصی بازیابی میکند.
۳- یکپارچهسازی مدالیتهها:
دادههای متنی، تصویری و صوتی در قالبی یکپارچه و قابلدرک برای مدل ترکیب میشوند (مثل تبدیل تصویر به بردار embedding و صوت به متن).
۴- استدلال زمینهمحور:
ماژول استدلال بر اساس این زمینه چندوجهی، درکی منسجم از موضوع شکل میدهد و ارتباط میان دادهها را تحلیل میکند.
۵- تولید خروجی زمینهمحور:
ماژول تولید، پاسخی منسجم و آگاه از بستر تولید میکند که ممکن است شامل ترکیب چند نوع داده باشد؛ مثلا توضیحی متنی که جزئیاتی از تصویر و مشخصات محصول را هم در بر دارد.
۶- ارسال پاسخ به کاربر:
در نهایت، پاسخ نهایی که بر پایه دادههای چندوجهی ساخته شده است، به کاربر ارائه میشود.

بازیابی چندوجهی: ملاحظات فنی
بازیابی چندوجهی به معنای دسترسی همزمان به انواع مختلف دادهها شامل متن، تصویر، صوت و ویدیو است. هدف اصلی این رویکرد، ارائه پاسخهای دقیق و مرتبط با پرسش کاربر از منابع چندگانه است.
منابع داده:
- متون: اسناد، دفترچههای راهنما و پرسشهای متداول که با استفاده از Elasticsearch یا پایگاههای داده برداری (مانند FAISS) ایندکس میشوند.
- مخازن تصویر: تصاویر محصولات که در فضای ذخیرهسازی ابری (مانند S3 یا GCS) نگهداری و با استفاده از بردارهای تصویری (embedding) حاصل از مدلهایی مثل CLIP یا ViT ایندکس میشوند.
- دادههای صوتی و ویدیویی: متن پیادهسازیشده صدا بهعنوان داده متنی ایندکس میشود و برای دادههای صوتی یا تصویری، embedding تخصصی تولید میشود (برای مثال، مدل OpenAI Whisper برای تبدیل صوت به متن و مدل CLIP برای فریمهای ویدیو).
استراتژیهای ایندکسگذاری:
- تبدیل هر نوع داده (مدالیته) به فضای embedding سازگار و قابل مقایسه
- برای تصاویر، استفاده از encoderهای بینایی مانند CLIP برای تولید embedding و ذخیره آن در پایگاه داده برداری
- برای صدا و ویدیو، تولید متن پیادهسازیشده یا embedding فریمها و ایندکس کردن آنها به روش مشابه
نمونه یکپارچهسازی:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
class MultiModalRetrievalModule: def __init__(self, config: Dict): self.text_index = Elasticsearch(**config[“text_index”]) self.image_vector_store = Pinecone(**config[“image_embeddings”]) self.video_transcript_index = ChromaDB(**config[“video_transcripts”]) async def retrieve_context(self, query: str, product_id: str) -> Dict: # Text retrieval text_docs = await self.text_index.search(query=query, top_k=5) # Image retrieval (using embeddings) image_embedding = self._embed_query_for_images(query) related_images = await self.image_vector_store.similarity_search( vector=image_embedding, top_k=3, filter={“product_id”: product_id} ) # Video transcripts retrieval transcripts = await self.video_transcript_index.query( query, top_k=3, metadata_filters={“product_id”: product_id} ) return { “text_docs”: text_docs, “images”: related_images, “transcripts”: transcripts } |
لایه یکپارچهسازی مدالیتهها
لایه یکپارچهسازی مدالیتهها وظیفه دارد دادههای با فرمتهای مختلف را به یک فضای معنایی مشترک تبدیل و همتراز کند.
هدف:
- تصاویر بازیابیشده را به embeddingهایی تبدیل کند که با فضای برداری متن همراستا هستند.
- متنهای پیادهسازیشده (از صوت یا ویدیو) و سایر دادههای متنی را نرمالسازی کرده و به قالبی یکنواخت درآورد.
- همه دادهها را در قالب یک شی زمینهای یکپارچه (context object) ترکیب کند تا ماژول استدلال بتواند آن را پردازش کند.
استراتژیهای یکپارچهسازی:
- ترکیب زودهنگام (Early Fusion): تمام مدالیتهها ابتدا به embedding تبدیل میشوند و سپس پیش از مرحله استدلال با هم ترکیب یا ادغام میشوند.
- ترکیب دیرهنگام (Late Fusion): هر مدالیته بهصورت جداگانه پردازش میشود و در نهایت، درست پیش از مرحله استدلال نتایج با هم ادغام میشوند.
|
1 2 3 4 5 6 7 8 9 |
class ModalityIntegrationLayer: def integrate(self, retrieval_results: Dict) -> Dict: # Combine text, image embeddings, and transcript segments unified_context = { “text”: [doc[“content”] for doc in retrieval_results[“text_docs”]], “images”: retrieval_results[“images”], “transcripts”: [t[“snippet”] for t in retrieval_results[“transcripts”]] } return unified_context |
استدلال با زمینه چندوجهی
در این مرحله، ماژول استدلال ورودیای غنیتر و چندبعدیتر دریافت میکند:
- ادغام معنایی (Semantic Fusion): مدلهایی مانند CLIP (برای ارتباط میان تصویر و متن) و مدلهای زبانی بزرگ (LLM) که برای پرسشوپاسخ چندوجهی آموزش داده یا بهینهسازی شدهاند، میتوانند ورودیهای ترکیبی را بهخوبی تحلیل و تفسیر کنند.
- تطبیق با دامنه خاص (Domain Adapters): میتوان مدلهای استدلال را با دادههای تخصصی هر حوزه بازآموزی کرد تا روابط میان embeddingهای متن و تصویر یا میان متن و پیادهسازیهای صوتی را بهتر درک کنند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
class MultiModalReasoningModule: async def process_context(self, unified_context: Dict, user_query: str) -> Dict: # Extract and understand brand guidelines from text brand_guidelines = self._extract_brand_guidelines(unified_context[“text”]) # Analyze images (embeddings) to confirm product identity visual_clues = self._interpret_images(unified_context[“images”]) # Integrate transcripts for additional context (e.g., product demos) performance_insights = self._derive_insights_from_transcripts( unified_context[“transcripts”] ) # Combine all modalities into a coherent understanding reasoning_output = { “brand_guidelines”: brand_guidelines, “visual_clues”: visual_clues, “performance_insights”: performance_insights } return reasoning_output |
ماژول تولید: پاسخهای آگاه از دادههای چندوجهی
ماژول تولید با استفاده از خروجی مرحله استدلال و زمینه چندوجهی، پاسخی غنی و کامل تولید میکند. اگرچه خروجی معمولا بهصورت متنی است اما میتواند به تصاویر ارجاع دهد، ویژگیهای بصری را توصیف کند یا محتوای ویدیویی را خلاصه کند.
قالبهای پرامپت:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
prompt_template = “”“ You have the following context: – Brand guidelines: {brand_guidelines} – Relevant product images identified: {visual_clues} – Performance insights from video transcripts: {performance_insights} Based on this multimodal context, create a compelling product description that references the visual attributes of the product and adheres to the brand voice. ““” پیادهسازی: class MultiModalGenerationModule: async def generate(self, reasoning_output: Dict) -> str: prompt = prompt_template.format( brand_guidelines=reasoning_output[“brand_guidelines”], visual_clues=reasoning_output[“visual_clues”], performance_insights=reasoning_output[“performance_insights”] ) response = await self.llm.generate( prompt=prompt, parameters={“max_length”: 1500, “temperature”: 0.7} ) return response |
عملکرد و مقیاسپذیری
عملکرد و مقیاسپذیری در سیستمهای چندوجهی اهمیت بالایی دارند، زیرا حجم دادهها و درخواستها میتواند بسیار زیاد باشد و پردازش سریع و همزمان دادههای مختلف ضروری است.
کش کردن (Caching):
- بردارهای تصویری (image embeddings) یا متنهای پیادهسازیشدهای که زیاد مورد استفاده قرار میگیرند را در حافظه کش نگه دارید.
- نتایج ترکیب چندوجهی را برای درخواستهای تکراری ذخیره کنید تا سرعت پاسخگویی افزایش پیدا کند.
ایندکسگذاری (Indexing):
- برای هر نوع داده، ایندکس جداگانهای داشته باشید که متناسب با ویژگیهای همان داده بهینهسازی شده باشد.
- با تغییر دادهها یا مدلها، پایگاههای برداری (vector stores) را بهصورت منظم بهروزرسانی کنید.
توزیع بار (Load Balancing):
- چند نمونه از سرویسهای بازیابی مخصوص هر مدالیته اجرا کنید.
- با استفاده از load balancer، درخواستها را بین سرویسهای بازیابی و استدلال تقسیم کنید تا سیستم در مقیاس بالا پایدار بماند.
ملاحظات تاخیر:
- embedding دادههای پرکاربرد (مثل تصاویر یا فایلهای صوتی رایج) را از پیش محاسبه کنید.
- از پردازش غیرهمزمان (asynchronous I/O) و اجرای موازی مدالیتهها برای کاهش زمان پاسخ استفاده کنید.
پایش، مشاهدهپذیری و نگهداری
پایش و مشاهدهپذیری بخش حیاتی در مدیریت سیستمهای چندوجهی است تا اطمینان حاصل شود عملکرد سیستم همواره مطلوب و پایدار باقی میماند.
شاخصها:
- پوشش مدالیته (Modality Coverage): درصد درخواستهایی را اندازهگیری کنید که از چند نوع داده بهطور همزمان استفاده میکنند.
- کیفیت embedding: میزان ارتباط دادههای بازیابیشده (مثل تصاویر یا متنهای صوتی) با درخواست کاربر را پایش کنید.
لاگگذاری و ردیابی (Logging & Tracing):
- ثبت کنید که در هر پاسخ از چه مدالیتههایی استفاده شده است.
- از ابزارهایی مانند OpenTelemetry برای ردیابی توزیعشده استفاده کنید تا مسیر و تعامل بین مدالیتههای مختلف قابلمشاهده باشد.
نگهداری خودکار:
- بهصورت دورهای embeddingهای چندوجهی را با ورود دادههای جدید بازآموزی کنید.
- تصاویر، متنهای صوتی یا اسناد قدیمی و منقضیشده را از ایندکسها حذف کنید تا کارایی سیستم حفظ شود.
امنیت و انطباق
امنیت و انطباق بخش حیاتی در مدیریت سیستمهای چندوجهی است، بهخصوص زمانی که دادههای حساس مانند تصاویر، ویدیوها یا متون شخصی پردازش میشوند.
کنترل دسترسی:
در نقاط پایانی بازیابی (retrieval endpoints) برای هر مدالیته، از کنترل دسترسی مبتنی بر نقش یا ویژگی (RBAC/ABAC) استفاده کنید تا فقط افراد مجاز بتوانند به دادههای حساس مانند تصاویر یا ویدیوها دسترسی داشته باشند.
رمزگذاری (Encryption):
تمام embeddingها، متنهای پیادهسازیشده و تصاویر باید در حالت ذخیرهسازی (at rest) و هنگام انتقال (in transit) رمزگذاری شوند.
انطباق:
- چهرهها را در تصاویر ناشناسسازی کنید یا بخشهای حساس ویدیویی را طبق مقررات GDPR یا CCPA حذف کنید.
- از سازوکارهای دریافت و حذف داده به درخواست کاربر و سیستم رضایتمحور استفاده کنید تا الزامات حریم خصوصی رعایت شود.
چالشها و راهحلهای رایج
پیادهسازی سیستمهای چندوجهی با چالشهای فنی متعددی همراه است.
هماهنگی میان مدالیتهها:
- چالش: همتراز کردن embeddingهای مربوط به انواع دادهی متفاوت (مثل متن و تصویر).
- راهحل: استفاده از مدلهایی که برای وظایف میانمدالیتهای آموزش دیدهاند (مانند CLIP)، یا بازآموزی embeddingها برای ایجاد فضای معنایی یکپارچه.
عدمتعادل میان مدالیتهها (Modal Imbalance):
- چالش: در برخی درخواستها دادهی متنی زیاد است اما تصویر یا متن صوتی وجود ندارد.
- راهحل: طراحی راهکارهای جایگزین (fallback) که در نبود برخی مدالیتهها، پاسخ منطقی و سازگار ارائه دهند.
مقیاسپذیری ایندکسهای چندرسانهای:
- چالش: حجم بالای تصاویر یا ویدیوها ممکن است سرعت بازیابی را کاهش دهد.
- راهحل: استفاده از روشهای sharding، partitioning و پایگاههای داده برداری توزیعشده برای حفظ کارایی سیستم.
مدیریت چرخه عمر و یکپارچهسازی با MLOps
مدیریت چرخه عمر مدلها در سیستمهای چندوجهی اهمیت ویژهای دارد، زیرا مدلها و embeddingهای مختلف بهطور مداوم تغییر و بهروزرسانی میشوند.
نسخهبندی مدلها و رجیستریها:
تغییرات مدلهای مختلف از جمله encoderهای تصویری، مدلهای تولید متن صوت (transcript generation) و مدلهای زبانی استدلال (LLMs) را پیگیری کنید.
برای مدیریت نسخهها میتوان از ابزارهایی مانند MLflow یا SageMaker Model Registry استفاده کرد.
خط لولههای CI/CD:
بهروزرسانی embeddingها، بازسازی ایندکسها و استقرار مدلها را خودکارسازی کنید. با اجرای تستهای یکپارچهسازی (integration tests) که همه مدالیتهها را پوشش میدهند، از حفظ کارایی مدل اطمینان حاصل کنید.
مدیریت مداوم داده و خطوط پردازش:
بهصورت دورهای مجموعهدادههای تصویری جدید را وارد کنید، embeddingها را مجددا بسازید و متنهای پیادهسازیشده را بهروزرسانی کنید. برای حفظ کیفیت داده در مقیاس بالا، از اصول DataOps استفاده کنید.
نمونهکاربردها
سیستمهای چندوجهی امکان استفاده همزمان از دادههای متنی، تصویری و صوتی را فراهم میکنند و میتوانند تجربههای هوشمند و شخصیسازیشده برای کاربران ایجاد کنند. در عمل، این سیستمها در حوزههای مختلف کاربرد دارند:
۱. دستیار بازاریابی محصول
- بازیابی تصاویر محصول، ویدیوهای تبلیغاتی و دفترچههای راهنما.
- تولید محتوای بازاریابی چندوجهی که ویژگیهای متنی و تصویری محصول را با هم ترکیب میکند.
۲. سامانه پیشنهادگر محتوای رسانهای:
- ترکیب تاریخچه تماشای کاربر (متن ویدیوها)، پستهای وبلاگ (متن) و پوسترها (تصویر).
- تولید پیشنهادهای شخصیسازیشده بر اساس تمام انواع دادهی رسانهای مرتبط.
۳. سامانههای آموزشی و یادگیری:
- ترکیب ویدیوهای آموزشی (متن پیادهسازیشده)، کتابهای درسی (متن) و نمودارهای تصویری.
- تولید راهنماهای مطالعهای که بین نظریه (متن) و مثالهای تصویری یا ویدیویی پل میزنند.
جمعبندی
رویکرد Multi-Modal RAG با ترکیب چند نوع داده از جمله متن، تصویر، صوت و ویدیو نسخهای پیشرفتهتر و غنیتر از معماریهای RAG ارائه میدهد. این ساختار با ایجاد درکی جامع و زمینهمحور، به سیستم اجازه میدهد پاسخهایی دقیقتر، طبیعیتر و کاربردیتر تولید کند.
با بهکارگیری الگوهای معماری، استراتژیهای یکپارچهسازی، روشهای بهینهسازی عملکرد و الزامات امنیت و انطباق مطرحشده در این راهنما، تیمهای مهندسی میتوانند سیستمهایی قدرتمند، مقیاسپذیر و منعطف طراحی و پیادهسازی کنند.
چنین سیستمهایی تجربههایی هوشمندتر و عمیقتر از تعامل با هوش مصنوعی را ممکن میسازند؛ تجربههایی که متناسب با تنوع دادهها در سازمانهای امروزی عمل میکنند و ارزش واقعی دادههای چندوجهی را به نمایش میگذارند.
منابع


دیدگاهتان را بنویسید