
درک مفهوم «توکن» یکی از مهمترین پیشنیازها برای کار با مدلهای زبانی بزرگ (LLMها) و استفاده حرفهای از APIهای هوش مصنوعی است. اما چیزی که اهمیت بیشتری دارد شناخت دقیق «حداکثر توکن» است. تقریبا هر عملیاتی که با یک مدل انجام میدهید، از نوشتن یک پرامپت ساده گرفته تا تحلیل اسناد طولانی، تولید کد یا اجرای جریانهای چندمرحلهای، مستقیما به تعداد توکنها وابسته است.
توکنها علاوهبر اینکه ساختار اصلی ورودی و خروجی مدل را تشکیل میدهند، نقش تعیینکنندهای در هزینه، سرعت پاسخگویی و کیفیت خروجی دارند. از طرف دیگر، رشد سریع مدلهای مدرن باعث شده مفهوم Context Window اهمیت بیشتری پیدا کند؛ ویژگیای که مشخص میکند یک مدل تا چه اندازه میتواند متن، کد یا دادهی چندوجهی را در یک نوبت پردازش کند.
در این مقاله، ابتدا مفاهیم پایه مانند توکن و توکنیزهسازی را توضیح میدهیم، سپس به سراغ مدلهایی میرویم که در سال ۲۰۲۵ بزرگترین پنجرههای کانتکست را ارائه میدهند و بررسی میکنیم هر کدام برای چه کاربردهایی مناسبتر هستند.
توکن چیست؟
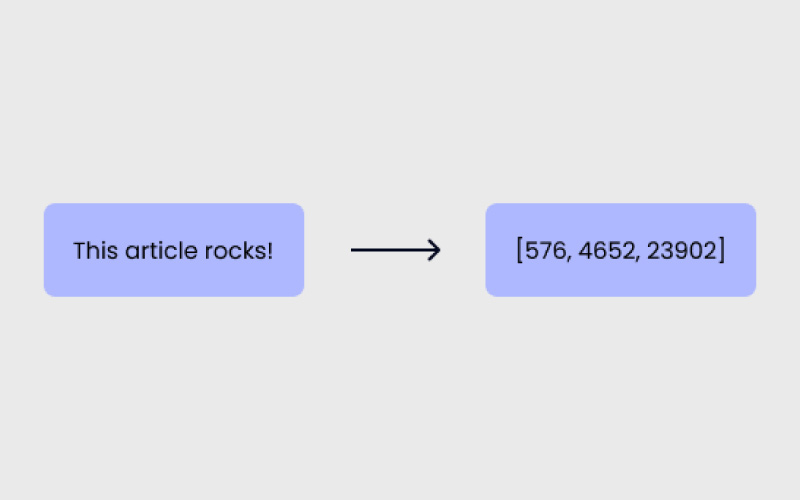
توکن کوچکترین واحد اطلاعاتی است که یک مدل زبانی برای درک و تولید متن از آن استفاده میکند. یک توکن میتواند یک حرف، یک کلمه کامل، یا حتی بخشی از یک کلمه باشد؛ همانطور که در مثال زیر میبینید.

عبارت Evergreen به دو بخش تقسیم میشود. عبارت It’s هم به دو توکن شکسته میشود: «it» و «s».
چرا مدلها از توکنها استفاده میکنند؟
زمانی که یک پرامپت مینویسید، مدل آن را بلافاصله به توکنها تقسیم میکند. دلیل این کار این است که LLMها زبان را مانند انسانها درک نمیکنند. این مدلها بر پایه حجم عظیمی از دادههای متنی آموزش دیدهاند و از این دادهها برای یادگیری الگوهای زبانی استفاده میکنند. فرایند توکنیزه شدن (Tokenization) متن انگلیسی (یا هر زبان دیگری) را به فرمی قابلپردازش برای مدل تبدیل میکند. نحوه شکستن متن به توکنها به زبان و الگوریتم خاصی که برای توکنیزه کردن استفاده میشود، بستگی دارد.
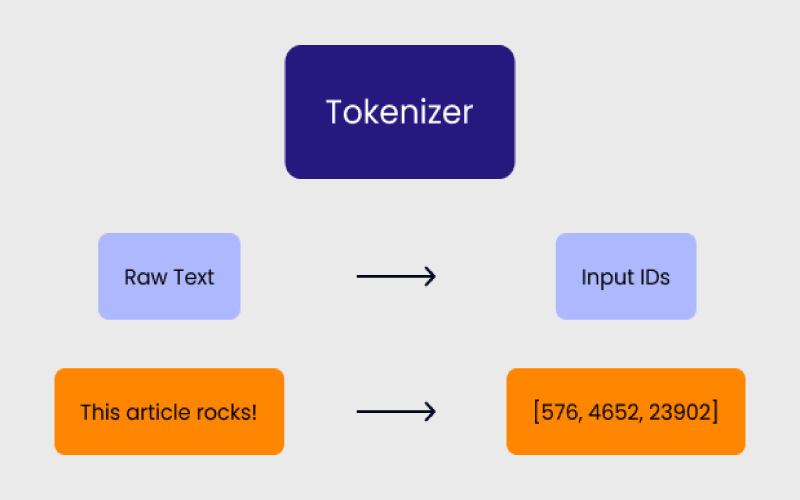
توکنیزه شدن چیست؟
توکنیزه شدن (Tokenization) فرایند شکستن متن به بخشهای کوچکتر یا همان توکنها است. برای مثال، همانطور که کلمه Evergreen به دو توکن تقسیم شد، در این فرایند نیز متن شما به اجزای قابلدرک برای مدل شکسته میشود.
بهطور کلی، سه روش اصلی برای توکنیزه کردن وجود دارد:
۱. روش مبتنی بر کلمه (Word-based)
در این روش، هر کلمه یک توکن محسوب میشود.
بهعنوان مثال:
Evergreen = یک توکن
مزیتها:
با این روش میتوانید تمام واژههای موجود در یک زبان را در مدل بگنجانید.
معایب:
از آنجایی که دایره واژگان مدل بسیار بزرگ میشود، حافظه بیشتری مصرف میشود و پیچیدگی زمانی در آموزش یا اجرای مدل افزایش پیدا میکند.
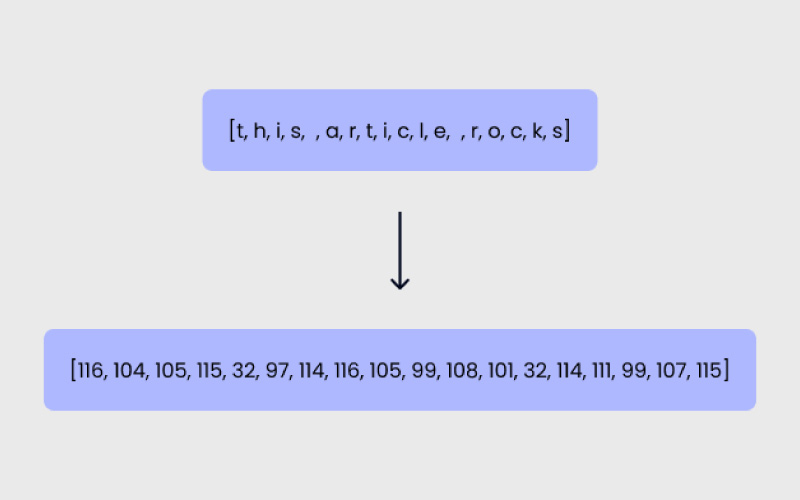
۲. روش مبتنی بر کاراکتر (Character-based)
در این روش، هر کاراکتر یک توکن محسوب میشود.
بهعنوان مثال:
Evergreen = ۹ توکن
مزیتها:
در این حالت تعداد کل توکنها کمتر است، بنابراین مدیریت حافظه و پیچیدگی زمانی سادهتر میشود.
معایب:
درک معنا برای مدل سختتر است، چون هر کاراکتر بهتنهایی اطلاعات معنایی کمی دارد. برای نمونه، حرف «t» بهمراتب کمتر از کلمه «tree» معنا منتقل میکند.
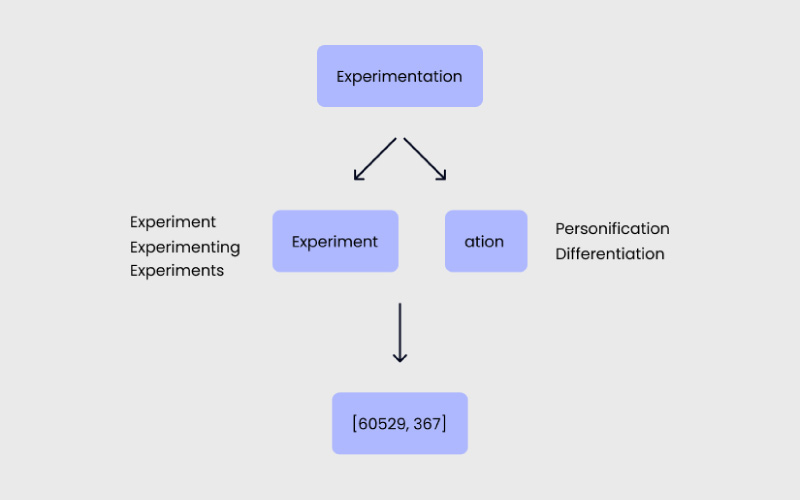
۳. روش مبتنی بر زیرواژه (Subword-based)
در این روش، زیرواژهها یا بخشهای رایج کلمات بهعنوان توکنهای جداگانه در نظر گرفته میشوند.
بهعنوان مثال:
Evergreen = ۲ توکن
مزیتها:
با این روش میتوانید دایره واژگان بزرگی را با تعداد توکن کمتر پوشش دهید، چون مدل قادر است شکلهای مختلف یک واژه را انعطافپذیرتر مدیریت کند.
معایب:
پیچیدگی حافظه و زمان در این روش نسبت به حالت کاراکترمحور بیشتر است، چون هر توکن معمولا شامل چند حرف و معنای جزئی است.
توکنیزه شدن در مدلهای OpenAI
OpenAI از نوعی توکنیزهسازی مبتنی بر زیرواژه استفاده میکند که به آن Byte Pair Encoding (BPE) گفته میشود. این روش یکی از دلایل اصلی دقت بالای مدلهای زبانی در درک متون و تولید پاسخهای ظریف و هوشمندانه است. در این روش، بخشهای پرتکرار کلمات (زیرواژهها) بهصورت ترکیبی ذخیره میشوند تا مدل بتواند هم با واژههای آشنا و هم با واژههای جدید یا ترکیبی به شکلی موثرتر کار کند.
نقش توکنها در هزینه و عملکرد API
توکنها یکی از مهمترین عوامل تاثیرگذار بر هزینه، زمان پاسخگویی و عملکرد در هنگام استفاده از APIهای OpenAI (و تقریبا همه ارائهدهندگان مشابه) هستند.
درک رابطه بین توکنها و این شاخصها به شما کمک میکند که پرامپتهای بهینهتر بنویسید، هزینهها را کاهش دهید و تجربه کاربری بهتری ارائه کنید. OpenAI برای مدلهای مختلف، تعرفههای متفاوتی در نظر گرفته و این ارقام را بهصورت دورهای بهروزرسانی میکند. بهطور کلی، هرچه پرامپت طولانیتر باشد، تعداد توکنهای بیشتری مصرف میکند و در نتیجه هزینه بیشتری خواهد داشت.
مدلهای برتر با بزرگترین پنجرههای کانتکست در سال ۲۰۲۵
در سالهای اخیر، رقابت میان مدلهای زبانی بزرگ بهسمت افزایش ظرفیت Context Window حرکت کرده است؛ ویژگیای که تعیین میکند یک مدل تا چه اندازه میتواند متن، کد یا دادههای چندوجهی را بهصورت یکپارچه پردازش کند.
هرچه این پنجره بزرگتر باشد، مدل میتواند اسناد طولانیتر، کدهای پیچیدهتر، یا جریانهای چندمرحلهای وسیعتر را بدون نیاز به تکهتکهسازی تحلیل کند. در بخش پیشرو، مروری داریم بر مهمترین LLMهایی که در سال ۲۰۲۵ بزرگترین کانتکستها را ارائه میدهند و هرکدام برای چه نوع کاربردهایی مناسبتر هستند.
۱- Magic.dev LTM-2-Mini
حداکثر پنجره کانتکست ورودی: تا ۱۰۰میلیون توکن
مدل LTM-2-Mini از شرکت Magic.dev با داشتن پنجره کانتکستی خارقالعاده معادل ۱۰۰میلیون توکن (تقریبا معادل ۱۰ میلیون خط کد یا ۷۵۰ رمان کامل)، بزرگترین ظرفیت پردازش متنی در میان تمام مدلهای زبانی موجود را دارد. این مدل برای مدیریت مجموعهدادههای بسیار بزرگ طراحی شده است؛ مانند پایگاههای کد کامل (codebase) یا آرشیوهای عظیم اسناد و متون.
کاربردهای اصلی:
- درک و بازآرایی (refactor) مجموعهکدهای بسیار بزرگ
- تحلیل قراردادهای حقوقی و سیاستنامهها با هزاران صفحه
- خلاصهسازی کامل کتابها و استخراج دانش از متون بلند
تا این لحظه، هنوز شواهدی از استفاده واقعی از این مدل یا پنجره ۱۰۰ میلیون توکنی آن گزارش نشده است.
۲- Meta Llama 4 Scout
حداکثر پنجره کانتکست ورودی: تا ۱۰میلیون توکن
مدل Llama 4 Scout محصول شرکت Meta، یک مدل MoE (Mixture of Experts) با ۱۰۹میلیارد پارامتر است که از میان آنها ۱۷میلیارد پارامتر فعال و ۱۶ متخصص (expert) دارد. این مدل قادر است تا ۱۰میلیون توکن را تنها با یک GPU از نوع NVIDIA H100 پردازش کند و در بنچمارکها عملکردی بهتر از مدلهایی مانند Google Gemma 3 و Mistral 3.1 از خود نشان داده است.
Llama 4 Scout همچنین از چندوجهی بودن (multimodality) بهصورت بومی پشتیبانی میکند.
کاربردهای اصلی:
- اجرای جریانهای کاری چندوجهی (متنی، صوتی، تصویری) روی دستگاه با نیاز به کانتکستهای بسیار بلند
- درک و بازآرایی خودکار مجموعهکدهای عظیم
- خلاصهسازی کامل کتابها و تحلیل عمیق رونوشتهای ویدیو و صدا

Claude Sonnet 4 -۳
حداکثر پنجره کانتکست ورودی: تا یک میلیون توکن
مدل Claude Sonnet 4 که اخیرا از پنجرهی ۲۰۰هزار توکنی به ۱میلیون توکن ارتقا یافته، در زمینه استدلال ترکیبی (Hybrid Reasoning) و تحلیل دادههای حجیم عملکردی هوشمندانهتر و دقیقتر ارائه میدهد. این ارتقا، Sonnet 4 را در سطح مدلهای پیشرو حوزه پردازش اسناد در مقیاس بسیار بزرگ قرار داده است.
کاربردهای اصلی:
- تحلیل و تلفیق دادهها و اسناد در مقیاس گسترده
- درک ساختار و ارتباط کدها در پروژههای بزرگ و چندمخزن (multi-repo)
- اجرای جریانهای کاری پیچیدهی چندوجهی (متن، کد و تحلیل تصویری)
۴- Google Gemini 2.5 Flash & 2.5 Pro
حداکثر پنجره کانتکست ورودی: تا یک میلیون توکن
در رویداد Google I/O 2025، گوگل نسخه ۲.۵ از مدلهای Gemini Flash و Gemini Pro را با بهبودهایی در زمینه استدلال (reasoning)، پردازش چندوجهی (multimodal throughput) و عملکرد کدنویسی معرفی کرد.
هر دو مدل دارای پنجرهی کانتکست ۱میلیون توکنی هستند؛ با این تفاوت که نسخه Pro قابلیت ویژهای به نام Deep Think دارد که به مدل اجازه میدهد پیش از پاسخدهی، چند فرضیه را همزمان بررسی و مقایسه کند.
کاربردهای اصلی:
- اجرای جریانهای کاری چندوجهی پیچیده (ویدیو، صدا و متن بهصورت همزمان)
- دستیارهای هوشمند برنامهنویسی و عاملهای درونمرورگر (AI agents)
- جستوجوی معنایی در مجموعهدادههایی با میلیاردها توکن
۵- Meta Llama 4 Maverick
حداکثر پنجره کانتکست ورودی: تا یک میلیون توکن
مدل Llama 4 Maverick از شرکت Meta یک مدل MoE (Mixture of Experts) با ۴۰۰میلیارد پارامتر است که از میان آنها ۱۷میلیارد پارامتر فعال و ۱۲۸ متخصص (expert) دارد.
Maverick برای کاربردهای سازمانی طراحی شده و ضمن ارائه عملکرد در سطح پرچمدار (flagship-level)، از نظر هزینه نیز بهینه و مقرونبهصرفه است.
کاربردهای اصلی:
- برنامهها و سامانههای چندوجهی در سطح سازمانی
- درک پیشرفته تصویر و متن در بیش از ۱۲ زبان
- چتباتها و دستیارهای هوشمند با کارایی بالا
۶- Qwen3-Next و Qwen3-Max-Preview
حداکثر پنجره کانتکست ورودی: تا یک میلیون توکن
مدل پرچمدار Alibaba با بیش از یک تریلیون پارامتر، بهصورت پیشفرض از یک پنجره کانتکست ۲۵۸هزار توکنی پشتیبانی میکند که قابلافزایش تا ۱میلیون توکن است.
این مدل عملکردی بسیار سریع دارد و در بنچمارکها رقابت نزدیکی با مدلهای پیشرفتهای مانند Claude Opus 4 و دیگر مدلهای نسل جدید نشان میدهد.
کاربردهای اصلی:
- انجام وظایف پیچیده استدلالی و برنامهنویسی
- پردازش دادههای ساختیافته و تولید خروجیهای JSON
- تولید محتوای خلاقانه با درک عمیق از کانتکستهای طولانی
۷- OpenAI GPT-5
حداکثر پنجره کانتکست ورودی: تا ۴۰۰هزار توکن
جدیدترین مدل خانوادهی GPT دارای ۴۰۰هزار توکن ورودی و یک پنجره خروجی بزرگ به اندازه ۱۲۸هزار توکن است.
مدل GPT-5 تواناییهای استدلالی بسیار بهتری دارد و در پردازش متون طولانی عملکردی قابلتوجه ارائه میدهد؛ همچنین نسبت به نسل قبل، ۸۰٪ خطای واقعی کمتر در پاسخها دارد.
کاربردهای اصلی:
- انجام وظایف پیچیده استدلالی و حل مسئله
- تولید و بازآرایی (Refactoring) کد در مقیاس بزرگ
- اجرای جریانهای چندمرحلهای (Agentic Workflows) با تولید خروجیهای طولانی
۸- Anthropic Claude Opus 4.1
حداکثر پنجره کانتکست ورودی: تا ۲۰۰هزار توکن
مدل Opus 4.1 برای ارائه هوش در سطح Frontier طراحی شده و در حوزههایی مانند عاملهای پیچیده (complex agents) و پژوهشهای عمیق عملکردی ممتاز دارد.
این مدل برای وظایف برنامهنویسی و گردشکارهای عاملمحور، تواناییهای استدلال ترکیبی (Hybrid Reasoning) و حافظه تقویتشده ارائه میدهد.
کاربردهای اصلی:
- وظایف چندمرحلهای برنامهنویسی با دقت بالا
- تحلیل اسناد مبتنی بر اصول Constitutional AI و مدیریت دیالوگهای چندمرحلهای امن
- جریانهای عاملمحور (Agentic Workflows) که نیازمند زنجیرهسازی ابزارها و ردگیری حافظه بلندمدت هستند
۹- Claude Sonnet 3.7 و Claude Haiku 3.5
حداکثر پنجره کانتکست ورودی: تا ۲۰۰هزار توکن
هر دو مدل همچنان از طریق API شرکت Anthropic قابل استفاده هستند و یک پنجره کانتکست ۲۰۰هزار توکنی را حفظ کردهاند.
این مدلها برای کار با اسناد حجیم، گفتگوهای ظریف و تحلیلی، و وظایف برنامهنویسی عملکردی پایدار و قابل اعتماد ارائه میدهند.
کاربردهای اصلی:
- پشتیبانی پیشرفته مشتری و پردازش درخواستهای پیچیده
- خودکارسازی گردشکارهای پیچیده
- پردازش دقیق متون و اجرای وظایف برنامهنویسی پیشرفته
۱۰- Mistral Large 2
حداکثر پنجره کانتکست ورودی: تا ۱۲۸هزار توکن
مدل Mistral Large 2 با هزینهای ۸ برابر کمتر نسبت به مدلهای همرده، عملکردی در سطح پیشرفته ارائه میدهد و استقرار آن در سطح سازمانی بسیار سادهتر شده است.
این مدل از استقرار هیبریدی، درونسازمانی (On-premises) و درون VPC پشتیبانی میکند و همچنین امکان پس-آموزش سفارشی (Custom Post-Training) را فراهم میکند تا بتوان آن را عمیقا با سیستمهای سازمانی ادغام کرد.
کاربردهای اصلی:
- جریانهای کاری تخصصی کدنویسی و علوم مهندسی (STEM) که نیازمند دقت بالا هستند
- درک چندوجهی (متن، کد، تصویر) در محیطهای سازمانی
- استقرارهای درونسازمانی و هیبریدی با قابلیت ریزتنظیم پیوسته

OpenAI GPT-4o -۱۱
حداکثر پنجره کانتکست ورودی: تا ۱۲۸هزار توکن
مدل GPT-4o از OpenAI یک پنجره کانتکست ۱۲۸هزار توکنی ارائه میدهد و برای مدیریت اسناد طولانی و پیچیده، تولید کد و پردازش مبتنی بر اسناد عملکردی بسیار کارآمد دارد.
این مدل در ورودیهای طولانی انسجام و ارتباط معنایی را بهخوبی حفظ میکند، هرچند ممکن است در برخی سناریوهای پیچیده استدلالی هنوز چالشهایی مشاهده شود.
کاربردهای اصلی:
- دستیارهای چندوجهی دیداری–زبانی (تشخیص نمودار، دیاگرام و تصویر)
- تحلیل توسعهیافته کد و متن
- عاملهای سازمانی چندوجهی (Multimodal Enterprise Agents)
۱۲- Mistral Large 2
حداکثر پنجره کانتکست ورودی: تا ۱۲۸هزار توکن
مدل Mistral Large 2 با ارائه عملکردی در سطح پیشرفته و هزینهای تا ۸ برابر کمتر، استقرار سازمانی را بهشدت ساده میکند.
این مدل از استقرار هیبریدی، درونسازمانی (On-premises) و درون VPC پشتیبانی میکند و همچنین امکان پسآموزش سفارشی (Custom Post-Training) را برای یکپارچهسازی عمیق با سیستمهای سازمانی فراهم میسازد.
کاربردهای اصلی:
- جریانهای کاری تخصصی کدنویسی و حوزههای STEM با نیاز به دقت بسیار بالا
- درک چندوجهی (متن، کد، تصویر) در محیطهای سازمانی
- استقرارهای درونسازمانی و هیبریدی همراه با ریزتنظیم مداوم (Continuous Fine-Tuning)
کاربردهای اصلی مدلهایی با کانتکست طولانی
مدلهایی که از پنجرههای کانتکست بزرگ پشتیبانی میکنند، برای پردازش سناریوهایی مناسباند که در آنها حجم داده بالا، جریان اطلاعات طولانی، یا نیاز به تحلیل چندمرحلهای وجود دارد. این ظرفیت به کسبوکارها اجازه میدهد حجم گستردهای از متن، کد یا دادهی چندرسانهای را بدون تکهتکهسازی در یک مرحله پردازش کنند. در ادامه، مهمترین کاربردهای این مدلها را مرور میکنید.
۱. تحلیل جامع اسناد طولانی
مدلهایی با کانتکست بالا میتوانند کتابها، گزارشهای مالی، قراردادهای حقوقی یا مقالات علمی را بهصورت یکپارچه تحلیل کنند. این ویژگی باعث میشود خلاصهسازی، پرسش و پاسخ و استخراج نکات کلیدی با دقت بیشتری انجام شود زیرا مدل کل سند را همزمان در نظر دارد و نیاز به تقسیمبندی متن از بین میرود.
۲. تحلیل کد و بررسی مخازن نرمافزاری
این مدلها قادرند کل یک ریپازیتوری یا مجموعهای از فایلها را در یک مرحله پردازش کنند. نتیجه، درک بهتر ساختار پروژه، شناسایی باگها، تولید کد منسجم و حتی بازآرایی بخشهای گسترده از کد است. مدلهایی مانند Magic.dev LTM-2-Mini یا نسخههای جدید Claude و Gemini در این حوزه عملکرد قابلتوجهی دارند.
۳. پردازش دادههای چندوجهی
در بسیاری از کسبوکارها دادهها محدود به متن نیستند. مدلهای دارای کانتکست بزرگ میتوانند مجموعههای سنگینی از متن، تصویر و ویدئو را همراه با هم تحلیل کنند. این توانایی برای حوزههایی مانند پزشکی، تحلیل محیطی، یا پردازش رونوشت ویدئوهای طولانی بهخصوص ارزشمند است.
۴. ایجاد عاملهای هوشمند با حافظه بلندمدت
پنجرههای کانتکست بزرگ پایه ساخت Agentهایی هستند که توانایی حفظ اطلاعات در تعاملات طولانی را دارند. چنین Agentهایی میتوانند مکالمههای چندجلسهای را دنبال کنند، سابقه کاربر را حفظ کنند و با مرور تعاملات قبلی تصمیمگیری دقیقتری داشته باشند. استفاده در پشتیبانی مشتری، دستیارهای شخصی و مدیریت پروژه از جمله کاربردهای رایج است.
۵. پژوهش علمی و تحلیل دادههای تخصصی
در حوزه تحقیقاتی، مدلهای دارای کانتکست بزرگ میتوانند چندین مقاله، دیتاست یا گزارش علمی را بهصورت همزمان بخوانند و تحلیل کنند. این ویژگی به پژوهشگران کمک میکند تا راحتتر الگوها را کشف کنند، فرضیه بسازند یا دادههای تاریخی را برای مدلسازی پیشبینی ترکیب کنند.
۶. مکالمات طولانی و چتهای چندمرحلهای
در محصولات گفتوگومحور، مثل چتباتهای سازمانی یا ابزارهای آموزشی، حفظ انسجام مکالمه بسیار مهم است. مدلهایی با کانتکست بزرگ میتوانند جریانهای طولانی گفتگو را بدون از دست دادن ارتباط بخشهای قبلی مدیریت کنند، چه در نقش معلم، چه پشتیبان مشتری یا دستیار کاری.
۷. بازیابی و مدیریت دانش در مقیاس بزرگ
برای سازمانهایی که حجم زیادی سند، گزارش، ایمیل، یا دانش داخلی دارند، این مدلها میتوانند بدون نیاز به بخشبندی اسناد، مستقیما از میان کل مجموعه اطلاعات مرتبط را استخراج کنند. این قابلیت برای سامانههای جستوجوی معنایی و ابزارهای مدیریت دانش سازمانی ارزش زیادی دارد.
۸. تحلیل ویدئو و تولید خلاصههای طولانی
مدلهایی با کانتکست بزرگ قادرند رونوشت ویدئوهای طولانی را یکجا تحلیل کنند، بخشهای مهم را تشخیص دهند یا خلاصههای دقیق بسازند. از پلتفرمهای آموزشی و رسانهای گرفته تا بررسی ویدئوهای حقوقی و امنیتی، این ویژگی در بسیاری از صنعتها کاربرد دارد.
نتیجهگیری
افزایش چشمگیر ظرفیت کانتکست در مدلهای زبانی جدید، مسیر تازهای را برای توسعهدهندگان و کسبوکارها باز کرده است. مدلهایی که تا چند سال پیش تنها میتوانستند چند هزار توکن را پردازش کنند، اکنون قادرند کدبیسهای کامل، کتابها، آرشیوهای سازمانی و جریانهای کاری پیچیده را در یک مرحله تحلیل کنند.
این تحول، امکان ساخت سیستمهایی را فراهم کرده که پیش از این غیرممکن یا بسیار پرهزینه بودند: از Agentهای هوشمند با حافظه بلندمدت گرفته تا ابزارهای توسعهای که کل یک ریپازیتوری را همزمان درک میکنند.
بااینحال، انتخاب مدل مناسب همچنان به نیاز پروژه بستگی دارد. مدلهایی مانند Magic.dev LTM-2-Mini ظرفیتهای فوقسنگین ارائه میدهند، درحالیکه گزینههایی مانند GPT-5، Claude Sonnet 4 یا Gemini 2.5 توازن بهتری میان هوشمندی، هزینه و کارایی ایجاد میکنند.
در نهایت، هرچه بیشتر دربارهی توکنها، نحوهی مصرفشان و تاثیر آنها بر عملکرد مدلها بدانید، تصمیمهای دقیقتری هنگام طراحی سیستمهای مبتنی بر هوش مصنوعی خواهید گرفت.
منابع
codingscape.com | prompthub.us
سوالات متداول
مدلها برای فهمیدن الگوهای زبانی، نیازمند ورودی استاندارد و قابلپردازش هستند. زبان طبیعی برای مدلها بیش از حد متنوع و پیچیده است، بنابراین ابتدا به توکن تبدیل میشود تا محاسبات سادهتر، سریعتر و دقیقتر انجام شود.
OpenAI از روش Byte Pair Encoding (BPE) استفاده میکند؛ نوعی توکنیزهسازی مبتنی بر زیرواژه که باعث میشود مدلها در مواجهه با کلمات جدید یا ساختارهای زبانی پیچیده عملکرد دقیقتری داشته باشند.
Context Window مشخص میکند مدل در یک بار پردازش چه تعداد توکن را میتواند تحلیل کند. پنجرههای بزرگتر امکان پردازش اسناد طولانی، کدهای پیچیده و مکالمات مداوم را بدون نیاز به تقسیمبندی فراهم میکنند.
مدلهایی مانند Magic.dev LTM-2-Mini با ۱۰۰ میلیون توکن، Llama 4 Scout با ۱۰ میلیون توکن، و مدلهایی مانند Claude Sonnet 4، Gemini 2.5، Qwen3، GPT-5 و Llama 4 Maverick با پنجرههای ۱ میلیون توکنی در صدر این فهرست قرار دارند.
خیر. برای بسیاری از پروژهها یک پنجرهی ۱۰۰هزار یا ۲۰۰هزار توکنی کاملا کافی است. پنجرههای بسیار بزرگ مخصوص سناریوهایی هستند که در آنها تحلیل کلانداده، کدبیسهای عظیم یا اسناد فوقطولانی مورد نیاز است.


دیدگاهتان را بنویسید