
این مقاله رایجترین سناریوهایی را که هنگام کار با کتابخانه Transformers از Hugging Face با آنها سروکار دارید، نشان میدهد. مدلهای موجود انواع تنظیمات را پوشش میدهند و برای طیف وسیعی از کاربردها قابل استفادهاند. در اینجا سادهترین نمونهها را میبینید؛ از جمله پرسشوپاسخ، طبقهبندی دنبالهها، شناسایی موجودیتهای نامدار و موارد دیگر.
این مثالها از auto-modelها استفاده میکنند؛ کلاسهایی که براساس یک چکپوینت مشخص، معماری درست مدل را بهطور خودکار انتخاب و نمونهسازی میکنند. برای اطلاعات بیشتر میتوانید مستندات AutoModel را بررسی کنید. همچنین میتوانید کدها را مطابق نیاز خود تغییر دهید تا دقیقتر با مسئلهتان هماهنگ شوند.
برای اینکه یک مدل در یک وظیفه عملکرد خوبی داشته باشد، باید از چکپوینتی بارگذاری شود که مخصوص همان وظیفه آموزش دیده باشد. معمولا این چکپوینتها ابتدا روی یک دیتاست بزرگ پیشآموزش داده میشوند و سپس روی وظیفهای خاص فاینتیون میشوند. بنابراین:
- همه مدلها برای همه وظایف فاینتیون نشدهاند. اگر میخواهید مدلی را برای یک وظیفه خاص فاینتیون کنید، میتوانید از اسکریپتهای run_$TASK.py در دایرکتوری examples استفاده کنید.
- مدلهای فاینتیونشده روی یک دیتاست مشخص آموزش دیدهاند. این دیتاست ممکن است با نیازهای شما همپوشانی داشته باشد یا نداشته باشد. همانطور که گفته شد، میتوانید از اسکریپتهای نمونه برای فاینتیون استفاده کنید یا اسکریپت آموزشی اختصاصی خودتان را بنویسید.
برای انجام استنتاج (Inference) در یک وظیفه، کتابخانه دو سازوکار اصلی در اختیار شما قرار میدهد:
- Pipelineها: سادهترین روش با حداقل دو خط کد.
- استفاده مستقیم از مدل: سطح انتزاع کمتر، اما انعطاف و کنترل بیشتر؛ شامل کار با tokenizer و دسترسی کامل به فرایند استنتاج (در PyTorch یا TensorFlow).
طبقهبندی دنباله (Sequence Classification)
طبقهبندی دنباله وظیفهای است که در آن یک ورودی متنی را در میان چند کلاس از پیش تعیینشده دستهبندی میکنیم. یکی از شناختهشدهترین نمونههای این نوع وظایف، مجموعهداده GLUE است که کاملا بر پایه همین مسئله طراحی شده است. اگر قصد دارید مدلی را برای یکی از وظایف طبقهبندی دنباله در GLUE فاینتیون کنید، میتوانید از اسکریپتهای زیر استفاده کنید:
- run_glue.py
- run_tf_glue.py
- run_tf_text_classification.py
- run_xnli.py
در ادامه یک نمونه ساده از استفاده pipelineها برای تحلیل احساسات آورده شده است؛ یعنی تشخیص اینکه یک جمله مثبت است یا منفی. در این مثال از مدلی استفاده میشود که روی sst2 (یکی از وظایف GLUE) فاینتیون شده است. خروجی این پردازش شامل یک label (مثلا «POSITIVE» یا «NEGATIVE») همراه با یک امتیاز است، مشابه نمونه زیر:
|
1 2 3 4 5 6 7 8 9 10 11 |
from transformers import pipeline classifier = pipeline(“sentiment-analysis”) result = classifier(“I hate you”)[0] print(f“label: {result[‘label’]}, with score: {round(result[‘score’], 4)}”) label: NEGATIVE, with score: 0.9991 result = classifier(“I love you”)[0] print(f“label: {result[‘label’]}, with score: {round(result[‘score’], 4)}”) label: POSITIVE, with score: 0.9999 |
در این مثال، یک مدل برای طبقهبندی دنباله استفاده میشود تا مشخص کند آیا دو متن، بازنویسی (Paraphrase) یکدیگر هستند یا خیر. روند کار به این صورت است:
- ابتدا یک tokenizer و یک model با استفاده از نام چکپوینت نمونهسازی میشوند. در اینجا مدل از نوع BERT تشخیص داده میشود و وزنهای ذخیرهشده در چکپوینت مربوطه بارگذاری میشود.
- سپس دو جمله ورودی با در نظر گرفتن جداکنندههای مخصوص مدل، token type idها و attention maskها به یک دنباله واحد تبدیل میشوند (این موارد بهصورت خودکار توسط tokenizer ساخته میشوند).
- این دنباله به مدل داده میشود تا در یکی از دو کلاس موجود دستهبندی شود:
- ۰: این دو متن بازنویسی یکدیگر نیستند
- ۱: این دو متن بازنویسی یکدیگر هستند
- در ادامه، روی خروجی مدل تابع softmax اعمال میشود تا احتمال هر کلاس به دست آید.
- در نهایت، نتایج چاپ میشوند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
from transformers import AutoTokenizer, AutoModelForSequenceClassification import torch tokenizer = AutoTokenizer.from_pretrained(“bert-base-cased-finetuned-mrpc”) model = AutoModelForSequenceClassification.from_pretrained(“bert-base-cased-finetuned-mrpc”) classes = [“not paraphrase”, “is paraphrase”] sequence_0 = “The company HuggingFace is based in New York City” sequence_1 = “Apples are especially bad for your health” sequence_2 = “HuggingFace’s headquarters are situated in Manhattan” # The tokenizer will automatically add any model specific separators (i.e. <CLS> and <SEP>) and tokens to # the sequence, as well as compute the attention masks. paraphrase = tokenizer(sequence_0, sequence_2, return_tensors=“pt”) not_paraphrase = tokenizer(sequence_0, sequence_1, return_tensors=“pt”) paraphrase_classification_logits = model(**paraphrase).logits not_paraphrase_classification_logits = model(**not_paraphrase).logits paraphrase_results = torch.softmax(paraphrase_classification_logits, dim=1).tolist()[0] not_paraphrase_results = torch.softmax(not_paraphrase_classification_logits, dim=1).tolist()[0] # Should be paraphrase for i in range(len(classes)): print(f“{classes[i]}: {int(round(paraphrase_results[i] * 100))}%”) not paraphrase: 10% is paraphrase: 90% # Should not be paraphrase for i in range(len(classes)): print(f“{classes[i]}: {int(round(not_paraphrase_results[i] * 100))}%”) not paraphrase: 94% is paraphrase: 6% |
پرسشوپاسخ استخراجی (Extractive Question Answering)
پرسشوپاسخ استخراجی وظیفهای است که در آن، با داشتن یک سوال و یک متن مرجع، پاسخ مستقیما از داخل همان متن استخراج میشود. یکی از شناختهشدهترین مجموعهدادهها در این حوزه، SQuAD است که بهطور کامل بر پایه همین نوع وظیفه طراحی شده. اگر قصد دارید مدلی را برای یک وظیفه پرسشوپاسخ مبتنی بر SQuAD فاینتیون کنید، میتوانید از اسکریپتهای زیر استفاده کنید:
در ادامه، نمونهای از استفاده pipelineها برای انجام پرسشوپاسخ آورده شده است؛ فرایندی که در آن، با دریافت یک سوال و یک متن، پاسخ از دل متن استخراج میشود. این مثال از مدلی استفاده میکند که روی دیتاست SQuAD فاینتیون شده است.
|
1 2 3 4 5 6 7 8 9 |
from transformers import pipeline question_answerer = pipeline(“question-answering”) context = r“”“ Extractive Question Answering is the task of extracting an answer from a text given a question. An example of a question answering dataset is the SQuAD dataset, which is entirely based on that task. If you would like to fine-tune a model on a SQuAD task, you may leverage the examples/pytorch/question-answering/run_squad.py script. ““” |
خروجی این پردازش شامل پاسخی استخراجشده از متن، یک امتیاز اطمینان (confidence score) و همچنین مقادیر start و end است که موقعیت شروع و پایان پاسخ استخراجشده را در متن نشان میدهند.
|
1 2 3 4 5 6 7 |
result = question_answerer(question=“What is extractive question answering?”, context=context) print(f“Answer: ‘{result[‘answer’]}’, score: {round(result[‘score’], 4)}, start: {result[‘start’]}, end: {result[‘end’]}”) Answer: ‘the task of extracting an answer from a text given a question’, score: 0.6177, start: 34, end: 95 result = question_answerer(question=“What is a good example of a question answering dataset?”, context=context) print(f“Answer: ‘{result[‘answer’]}’, score: {round(result[‘score’], 4)}, start: {result[‘start’]}, end: {result[‘end’]}”) Answer: ‘SQuAD dataset’, score: 0.5152, start: 147, end: 160 |
در این مثال، از یک model و یک tokenizer برای انجام پرسشوپاسخ استفاده میشود. روند کار به این صورت است:
- ابتدا یک tokenizer و یک model با استفاده از نام چکپوینت نمونهسازی میشوند. در اینجا مدل بهعنوان یک مدل BERT شناسایی شده و وزنهای ذخیرهشده در چکپوینت مربوطه بارگذاری میشوند.
- سپس یک متن و چند سوال تعریف میشوند.
- در ادامه، روی سوالها پیمایش میشود و برای هر سوال، یک دنباله شامل متن و سوال ساخته میشود؛ با در نظر گرفتن جداکنندههای مخصوص مدل، token type idها و attention maskها.
- این دنباله به مدل داده میشود. خروجی مدل شامل یک بازه از امتیازها برای تمام توکنهای دنباله (هم متن و هم سوال) است؛ بهصورت جداگانه برای موقعیت شروع (start) و پایان (end) پاسخ.
- سپس روی خروجی مدل تابع softmax اعمال میشود تا احتمال هر توکن محاسبه شود.
- بر اساس مقادیر start و end تشخیصدادهشده، توکنهای متناظر استخراج و به رشته متنی تبدیل میشوند.
- در نهایت، نتایج چاپ میشوند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
from transformers import AutoTokenizer, AutoModelForQuestionAnswering import torch tokenizer = AutoTokenizer.from_pretrained(“bert-large-uncased-whole-word-masking-finetuned-squad”) model = AutoModelForQuestionAnswering.from_pretrained(“bert-large-uncased-whole-word-masking-finetuned-squad”) text = r“”“ 🤗 Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained models in 100+ languages and deep interoperability between TensorFlow 2.0 and PyTorch. ““” questions = [ “How many pretrained models are available in 🤗 Transformers?”, “What does 🤗 Transformers provide?”, “🤗 Transformers provides interoperability between which frameworks?”, ] for question in questions: inputs = tokenizer(question, text, add_special_tokens=True, return_tensors=“pt”) input_ids = inputs[“input_ids”].tolist()[0] ... outputs = model(**inputs) answer_start_scores = outputs.start_logits answer_end_scores = outputs.end_logits ... # Get the most likely beginning of answer with the argmax of the score answer_start = torch.argmax(answer_start_scores) # Get the most likely end of answer with the argmax of the score answer_end = torch.argmax(answer_end_scores) + 1 ... answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])) ... print(f“Question: {question}”) print(f“Answer: {answer}”) Question: How many pretrained models are available in 🤗 Transformers? Answer: over 32 + Question: What does 🤗 Transformers provide? Answer: general – purpose architectures Question: 🤗 Transformers provides interoperability between which frameworks? Answer: tensorflow 2. 0 and pytorch |
مدلسازی زبان (Language Modeling)

مدلسازی زبان وظیفهای است که در آن، یک مدل روی یک پیکره متنی (Corpus) آموزش داده میشود؛ پیکرهای که میتواند عمومی یا مختص یک دامنه خاص باشد. تمام مدلهای محبوب مبتنی بر ترنسفورمر با یکی از گونههای مدلسازی زبان آموزش میبینند؛ برای مثال، BERT از masked language modeling استفاده میکند و GPT-2 بر پایه causal language modeling آموزش داده شده است.
مدلسازی زبان فقط به مرحله پیشآموزش محدود نمیشود و در مراحل بعدی هم کاربرد دارد. یکی از کاربردهای رایج آن، دامنهمحور کردن مدل است؛ به این معنا که یک مدل زبانی آموزشدیده روی یک پیکره بسیار بزرگ را روی دادههای تخصصیتر مثلا اخبار یا مقالات علمی، فاینتیون کنیم. بهعنوان نمونه میتوان به مدلهایی اشاره کرد که روی مقالات arXiv آموزش دیدهاند، مانند LysandreJik/arxiv-nlp.
مدلسازی زبان با ماسک (Masked Language Modeling)
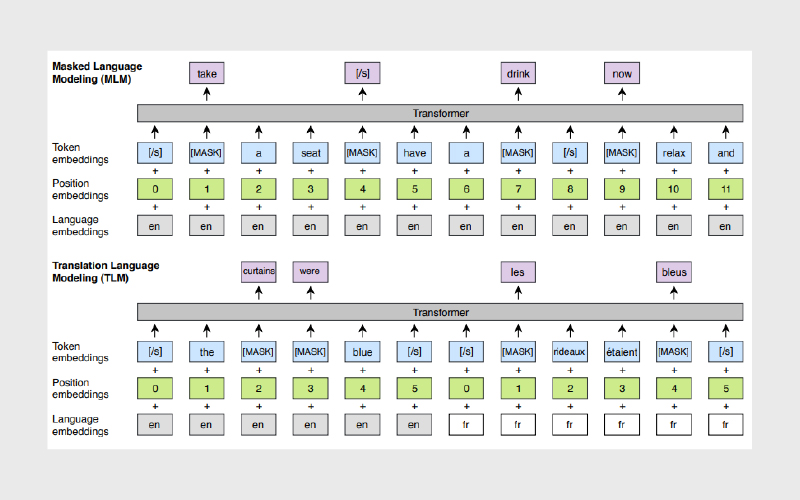
در مدلسازی زبان با ماسک، برخی از توکنهای یک دنباله با یک توکن ماسک جایگزین میشوند و از مدل خواسته میشود توکن مناسب را برای آن جای خالی پیشبینی کند. این روش به مدل اجازه میدهد هم به کانتکست سمت راست و هم به کانتکست سمت چپ توکن ماسکشده توجه کند.
چنین شیوهای از آموزش، پایهای قدرتمند برای وظایف پاییندستیای فراهم میکند که به کانتکست دوطرفه نیاز دارند؛ مانند SQuAD در مسئله پرسشوپاسخ. اگر قصد دارید مدلی را برای یک وظیفه masked language modeling فاینتیون کنید، میتوانید از اسکریپت run_mlm.py استفاده کنید.
در ادامه، نمونهای از استفاده pipelineها برای جایگزینی یک ماسک در یک دنباله متنی آورده شده است:
|
1 2 3 |
from transformers import pipeline unmasker = pipeline(“fill-mask”) |
خروجی این پردازش شامل دنبالههایی است که توکن ماسکشده در آنها جایگزین شده، بههمراه امتیاز اطمینان (confidence score) و شناسه توکن (token id) در واژگان tokenizer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
from pprint import pprint pprint(unmasker(f“HuggingFace is creating a {unmasker.tokenizer.mask_token} that the community uses to solve NLP tasks.”)) [{‘score’: 0.1793, ‘sequence’: ‘HuggingFace is creating a tool that the community uses to solve ‘ ‘NLP tasks.’, ‘token’: 3944, ‘token_str’: ‘ tool’}, {‘score’: 0.1135, ‘sequence’: ‘HuggingFace is creating a framework that the community uses to ‘ ‘solve NLP tasks.’, ‘token’: 7208, ‘token_str’: ‘ framework’}, {‘score’: 0.0524, ‘sequence’: ‘HuggingFace is creating a library that the community uses to ‘ ‘solve NLP tasks.’, ‘token’: 5560, ‘token_str’: ‘ library’}, {‘score’: 0.0349, ‘sequence’: ‘HuggingFace is creating a database that the community uses to ‘ ‘solve NLP tasks.’, ‘token’: 8503, ‘token_str’: ‘ database’}, {‘score’: 0.0286, ‘sequence’: ‘HuggingFace is creating a prototype that the community uses to ‘ ‘solve NLP tasks.’, ‘token’: 17715, ‘token_str’: ‘ prototype’}] |
در این مثال، از یک model و یک tokenizer برای انجام masked language modeling استفاده میشود. روند کار به این صورت است:
۱. ابتدا یک tokenizer و یک model با استفاده از نام چکپوینت نمونهسازی میشوند. در اینجا مدل بهعنوان یک مدل DistilBERT شناسایی شده و وزنهای ذخیرهشده در چکپوینت مربوطه بارگذاری میشوند.
۲. سپس یک دنباله متنی تعریف میشود که در آن، بهجای یکی از کلمات از tokenizer.mask_token استفاده شده است.
۳. این دنباله به یک لیست از شناسهها (token IDs) کدگذاری میشود و موقعیت توکن ماسکشده در این لیست مشخص میگردد.
۴. در ادامه، پیشبینیهای مدل در موقعیت توکن ماسکشده استخراج میشوند. این خروجی یک تنسور هماندازه با واژگان مدل است که مقدار هر خانه، امتیاز اختصاصدادهشده به آن توکن را نشان میدهد. مدل به توکنهایی که در آن کانتکست محتملتر هستند، امتیاز بالاتری میدهد.
۵. سپس با استفاده از متدهای topk در PyTorch یا top_k در TensorFlow، پنج توکن با بالاترین امتیاز استخراج میشوند.
۶. در نهایت، توکن ماسکشده با این توکنها جایگزین شده و نتایج چاپ میشوند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from transformers import AutoModelForMaskedLM, AutoTokenizer import torch tokenizer = AutoTokenizer.from_pretrained(“distilbert-base-cased”) model = AutoModelForMaskedLM.from_pretrained(“distilbert-base-cased”) sequence = “Distilled models are smaller than the models they mimic. Using them instead of the large “ \ f“versions would help {tokenizer.mask_token} our carbon footprint.” inputs = tokenizer(sequence, return_tensors=“pt”) mask_token_index = torch.where(inputs[“input_ids”] == tokenizer.mask_token_id)[1] token_logits = model(**inputs).logits mask_token_logits = token_logits[0, mask_token_index, :] top_5_tokens = torch.topk(mask_token_logits, 5, dim=1).indices[0].tolist() for token in top_5_tokens: print(sequence.replace(tokenizer.mask_token, tokenizer.decode([token]))) Distilled models are smaller than the models they mimic. Using them instead of the large versions would help reduce our carbon footprint. Distilled models are smaller than the models they mimic. Using them instead of the large versions would help increase our carbon footprint. Distilled models are smaller than the models they mimic. Using them instead of the large versions would help decrease our carbon footprint. Distilled models are smaller than the models they mimic. Using them instead of the large versions would help offset our carbon footprint. Distilled models are smaller than the models they mimic. Using them instead of the large versions would help improve our carbon footprint. |
در این مثال، پنج دنباله متنی چاپ میشود که هرکدام شامل یکی از ۵ توکن برتر پیشبینیشده توسط مدل هستند.
مدلسازی زبان علّی (Causal Language Modeling)
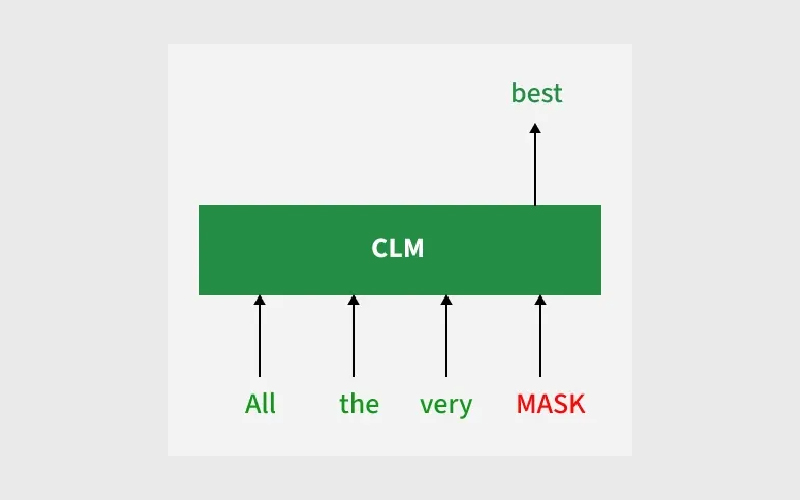
مدلسازی زبان علّی وظیفهای است که در آن، توکن بعدی بر اساس یک دنباله از توکنهای قبلی پیشبینی میشود. در این حالت، مدل فقط به کانتکست سمت چپ توجه میکند؛ یعنی توکنهایی که قبل از موقعیت فعلی قرار دارند. این شیوه آموزش بهطور خاص برای وظایف تولید متن (Generation) بسیار مناسب است. اگر قصد دارید مدلی را برای یک وظیفه causal language modeling فاینتیون کنید، میتوانید از اسکریپت run_clm.py استفاده کنید.
معمولا پیشبینی توکن بعدی با نمونهبرداری (sampling) از روی logitهای آخرین لایه پنهان (last hidden state) که مدل برای دنباله ورودی تولید میکند، انجام میشود.
در ادامه، نمونهای از استفاده همزمان از tokenizer و model آورده شده است که در آن، با کمک متد PreTrainedModel.top_k_top_p_filtering توکن بعدیِ یک دنباله ورودی نمونهبرداری میشود.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
from transformers import AutoModelForCausalLM, AutoTokenizer, top_k_top_p_filtering import torch from torch import nn tokenizer = AutoTokenizer.from_pretrained(“gpt2”) model = AutoModelForCausalLM.from_pretrained(“gpt2”) sequence = f“Hugging Face is based in DUMBO, New York City, and” inputs = tokenizer(sequence, return_tensors=“pt”) input_ids = inputs[“input_ids”] # get logits of last hidden state next_token_logits = model(**inputs).logits[:, –1, :] # filter filtered_next_token_logits = top_k_top_p_filtering(next_token_logits, top_k=50, top_p=1.0) # sample probs = nn.functional.softmax(filtered_next_token_logits, dim=–1) next_token = torch.multinomial(probs, num_samples=1) generated = torch.cat([input_ids, next_token], dim=–1) resulting_string = tokenizer.decode(generated.tolist()[0]) print(resulting_string) Hugging Face is based in DUMBO, New York City, and ... |
خروجی این فرایند، یک توکن بعدی (امیدوارانه) منسجم است که ادامهای از دنباله اولیه محسوب میشود؛ که در مثال ما کلماتی مانند is یا features هستند.
در بخش بعدی نشان داده میشود که چگونه میتوان بهجای تولید یک توکن در هر مرحله، از متد generation_utils.GenerationMixin.generate() برای تولید چندین توکن تا طول مشخص استفاده کرد.
تولید متن (Text Generation)

در تولید متن (که با نام open-ended text generation هم شناخته میشود)، هدف تولید یک بخش متنی منسجم است که ادامهای طبیعی از کانتکست ورودی باشد. مثال زیر نشان میدهد که چگونه میتوان از GPT-2 در قالب pipelineها برای تولید متن استفاده کرد.
بهصورت پیشفرض، تمام مدلها هنگام استفاده در pipelineها از Top-K sampling بهره میبرند؛ این رفتار در تنظیمات (configuration) هر مدل مشخص شده است (برای نمونه میتوانید تنظیمات GPT-2 را بررسی کنید).
|
1 2 3 4 5 6 |
from transformers import pipeline text_generator = pipeline(“text-generation”) print(text_generator(“As far as I am concerned, I will”, max_length=50, do_sample=False)) [{‘generated_text’: ‘As far as I am concerned, I will be the first to admit that I am not a fan of the idea of a “free market.” I think that the idea of a free market is a bit of a stretch. I think that the idea’}] |
در این مثال، مدل با استفاده از کانتکست «As far as I am concerned, I will» یک متن تصادفی با حداکثر طول ۵۰ توکن تولید میکند. در پشت صحنه، شیء pipeline متد PreTrainedModel.generate() را برای تولید متن فراخوانی میکند.
آرگومانهای پیشفرض این متد را میتوان هنگام استفاده از pipeline بازنویسی کرد؛ همانطور که در مثال بالا، مقادیر مربوط به max_length و do_sample تغییر داده شدهاند.
در ادامه، نمونهای از تولید متن با استفاده از XLNet و tokenizer مربوط به آن آورده شده است که در آن، متد generate() بهصورت مستقیم فراخوانی میشود:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
from transformers import AutoModelForCausalLM, AutoTokenizer model = AutoModelForCausalLM.from_pretrained(“xlnet-base-cased”) tokenizer = AutoTokenizer.from_pretrained(“xlnet-base-cased”) # Padding text helps XLNet with short prompts – proposed by Aman Rusia in https://github.com/rusiaaman/XLNet-gen#methodology PADDING_TEXT = “”“In 1991, the remains of Russian Tsar Nicholas II and his family (except for Alexei and Maria) are discovered. The voice of Nicholas’s young son, Tsarevich Alexei Nikolaevich, narrates the remainder of the story. 1883 Western Siberia, a young Grigori Rasputin is asked by his father and a group of men to perform magic. Rasputin has a vision and denounces one of the men as a horse thief. Although his father initially slaps him for making such an accusation, Rasputin watches as the man is chased outside and beaten. Twenty years later, Rasputin sees a vision of the Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous, with people, even a bishop, begging for his blessing. <eod> </s> <eos>”“” prompt = “Today the weather is really nice and I am planning on “ inputs = tokenizer(PADDING_TEXT + prompt, add_special_tokens=False, return_tensors=“pt”)[“input_ids”] prompt_length = len(tokenizer.decode(inputs[0])) outputs = model.generate(inputs, max_length=250, do_sample=True, top_p=0.95, top_k=60) generated = prompt + tokenizer.decode(outputs[0])[prompt_length+1:] print(generated) Today the weather is really nice and I am planning ... |
در حال حاضر، تولید متن در PyTorch با مدلهای GPT-2، OpenAI-GPT، CTRL، XLNet، Transfo-XL و Reformer امکانپذیر است و در TensorFlow نیز برای اغلب مدلها پشتیبانی میشود. همانطور که در مثال بالا دیده میشود، مدلهایی مانند XLNet و Transfo-XL معمولا برای عملکرد بهتر نیاز به padding دارند. در مقابل، GPT-2 اغلب گزینه مناسبی برای تولید متن باز (open-ended) به شمار میرود؛ چرا که روی میلیونها صفحه وب و با هدف causal language modeling آموزش دیده است.
شناسایی موجودیتهای نامدار (Named Entity Recognition)

شناسایی موجودیتهای نامدار یا NER وظیفهای است که در آن، هر توکن بر اساس یک کلاس مشخص دستهبندی میشود؛ برای مثال تشخیص اینکه یک توکن نام شخص، سازمان یا مکان است. یکی از دیتاستهای شناختهشده در این حوزه، CoNLL-2003 است که بهطور کامل برای همین وظیفه طراحی شده است. اگر قصد دارید مدلی را برای یک وظیفه NER فاینتیون کنید، میتوانید از اسکریپت run_ner.py استفاده کنید.
در ادامه، نمونهای از استفاده pipelineها برای انجام شناسایی موجودیتهای نامدار آورده شده است؛ بهطور مشخص، تلاش میشود توکنها در یکی از ۹ کلاس زیر دستهبندی شوند:
- O: خارج از هر موجودیت نامدار
- B-MIS: آغاز یک موجودیت متفرقه (Miscellaneous) بلافاصله پس از یک موجودیت متفرقه دیگر
- I-MIS: موجودیت متفرقه
- B-PER: آغاز نام یک شخص بلافاصله پس از نام شخص دیگر
- I-PER: نام شخص
- B-ORG: آغاز نام یک سازمان بلافاصله پس از یک سازمان دیگر
- I-ORG: سازمان
- B-LOC: آغاز نام یک مکان بلافاصله پس از یک مکان دیگر
- I-LOC: مکان
در این مثال از مدلی استفاده شده است که روی دیتاست CoNLL-2003 فاینتیون شده و توسط @stefan-it از مجموعه dbmdz آموزش داده شده است.
|
1 2 3 4 5 6 |
from transformers import pipeline ner_pipe = pipeline(“ner”) sequence = “”“Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, therefore very close to the Manhattan Bridge which is visible from the window.”“” |
خروجی این پردازش شامل فهرستی از تمام کلماتی است که بهعنوان یکی از موجودیتها در میان ۹ کلاس تعریفشدهی بالا شناسایی شدهاند. نتایج مورد انتظار بهصورت زیر است:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
for entity in ner_pipe(sequence): print(entity) {‘entity’: ‘I-ORG’, ‘score’: 0.9996, ‘index’: 1, ‘word’: ‘Hu’, ‘start’: 0, ‘end’: 2} {‘entity’: ‘I-ORG’, ‘score’: 0.9910, ‘index’: 2, ‘word’: ‘##gging’, ‘start’: 2, ‘end’: 7} {‘entity’: ‘I-ORG’, ‘score’: 0.9982, ‘index’: 3, ‘word’: ‘Face’, ‘start’: 8, ‘end’: 12} {‘entity’: ‘I-ORG’, ‘score’: 0.9995, ‘index’: 4, ‘word’: ‘Inc’, ‘start’: 13, ‘end’: 16} {‘entity’: ‘I-LOC’, ‘score’: 0.9994, ‘index’: 11, ‘word’: ‘New’, ‘start’: 40, ‘end’: 43} {‘entity’: ‘I-LOC’, ‘score’: 0.9993, ‘index’: 12, ‘word’: ‘York’, ‘start’: 44, ‘end’: 48} {‘entity’: ‘I-LOC’, ‘score’: 0.9994, ‘index’: 13, ‘word’: ‘City’, ‘start’: 49, ‘end’: 53} {‘entity’: ‘I-LOC’, ‘score’: 0.9863, ‘index’: 19, ‘word’: ‘D’, ‘start’: 79, ‘end’: 80} {‘entity’: ‘I-LOC’, ‘score’: 0.9514, ‘index’: 20, ‘word’: ‘##UM’, ‘start’: 80, ‘end’: 82} {‘entity’: ‘I-LOC’, ‘score’: 0.9337, ‘index’: 21, ‘word’: ‘##BO’, ‘start’: 82, ‘end’: 84} {‘entity’: ‘I-LOC’, ‘score’: 0.9762, ‘index’: 28, ‘word’: ‘Manhattan’, ‘start’: 114, ‘end’: 123} {‘entity’: ‘I-LOC’, ‘score’: 0.9915, ‘index’: 29, ‘word’: ‘Bridge’, ‘start’: 124, ‘end’: 130} |
دقت کنید که توکنهای دنباله «Hugging Face» بهعنوان یک سازمان شناسایی شدهاند و «New York City»، «DUMBO» و «Manhattan Bridge» بهعنوان مکان تشخیص داده شدهاند.
در ادامه، نمونهای از انجام شناسایی موجودیتهای نامدار با استفاده از یک model و یک tokenizer آورده شده است. روند کار به این صورت است:
۱. ابتدا یک tokenizer و یک model با استفاده از نام چکپوینت نمونهسازی میشوند. در اینجا مدل بهعنوان یک مدل BERT شناسایی شده و وزنهای ذخیرهشده در چکپوینت مربوطه بارگذاری میشوند.
۲. سپس یک دنباله متنی با موجودیتهای شناختهشده تعریف میشود؛ برای مثال «Hugging Face» بهعنوان یک سازمان و «New York City» بهعنوان یک مکان.
۳. برای اینکه کلمات بتوانند به پیشبینیهای مدل نگاشت شوند، متن به توکنها شکسته میشود. در این مثال، از یک راهکار ساده استفاده شده است: ابتدا دنباله بهطور کامل encode و سپس decode میشود تا در نهایت یک رشته متنی شامل توکنهای ویژه (special tokens) در اختیار داشته باشیم.
۴. این دنباله سپس به شناسهها (token IDs) کدگذاری میشود (توکنهای ویژه بهصورت خودکار اضافه میشوند).
۵. با عبور دادن ورودی از مدل و دریافت اولین خروجی آن، پیشبینیها استخراج میشوند. نتیجه، یک توزیع احتمال روی ۹ کلاس ممکن برای هر توکن است. با اعمال argmax، محتملترین کلاس برای هر توکن انتخاب میشود.
۶. در نهایت، هر توکن با برچسب پیشبینیشده آن جفت شده و چاپ میشود.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from transformers import AutoModelForTokenClassification, AutoTokenizer import torch model = AutoModelForTokenClassification.from_pretrained(“dbmdz/bert-large-cased-finetuned-conll03-english”) tokenizer = AutoTokenizer.from_pretrained(“bert-base-cased”) sequence = “Hugging Face Inc. is a company based in New York City. Its headquarters are in DUMBO, “ \ “therefore very close to the Manhattan Bridge.” inputs = tokenizer(sequence, return_tensors=“pt”) tokens = inputs.tokens() outputs = model(**inputs).logits predictions = torch.argmax(outputs, dim=2) |
خروجی این فرایند شامل فهرستی از توکنهاست که هرکدام به پیشبینی متناظر خود نگاشت شدهاند. برخلاف استفاده از pipeline، در اینجا برای تمام توکنها یک برچسب پیشبینی میشود؛ چرا که کلاس «۰» حذف نشده است. این کلاس نشان میدهد که برای آن توکن، موجودیت خاصی شناسایی نشده است.
در مثال بالا، مقدار predictions یک عدد صحیح است که به کلاس پیشبینیشده اشاره میکند. برای بهدست آوردن نام کلاس متناظر با این عدد، میتوان از ویژگی model.config.id2label استفاده کرد؛ همانطور که در مثال زیر نشان داده شده است:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
for token, prediction in zip(tokens, predictions[0].numpy()): print((token, model.config.id2label[prediction])) (‘[CLS]’, ‘O’) (‘Hu’, ‘I-ORG’) (‘##gging’, ‘I-ORG’) (‘Face’, ‘I-ORG’) (‘Inc’, ‘I-ORG’) (‘.’, ‘O’) (‘is’, ‘O’) (‘a’, ‘O’) (‘company’, ‘O’) (‘based’, ‘O’) (‘in’, ‘O’) (‘New’, ‘I-LOC’) (‘York’, ‘I-LOC’) (‘City’, ‘I-LOC’) (‘.’, ‘O’) (‘Its’, ‘O’) (‘headquarters’, ‘O’) (‘are’, ‘O’) (‘in’, ‘O’) (‘D’, ‘I-LOC’) (‘##UM’, ‘I-LOC’) (‘##BO’, ‘I-LOC’) (‘,’, ‘O’) (‘therefore’, ‘O’) (‘very’, ‘O’) (‘close’, ‘O’) (‘to’, ‘O’) (‘the’, ‘O’) (‘Manhattan’, ‘I-LOC’) (‘Bridge’, ‘I-LOC’) (‘.’, ‘O’) (‘[SEP]’, ‘O’) |
خلاصهسازی (Summarization)
خلاصهسازی وظیفهای است که در آن، یک سند یا مقاله به یک متن کوتاهتر و فشردهتر تبدیل میشود. اگر قصد دارید مدلی را برای یک وظیفه خلاصهسازی فاینتیون کنید، میتوانید از اسکریپت run_summarization.py استفاده کنید.
یکی از دیتاستهای شناختهشده در این حوزه، CNN / Daily Mail است که شامل مقالات خبری طولانی بوده و مشخصا برای وظیفه خلاصهسازی طراحی شده است. اگر بخواهید مدلی را برای خلاصهسازی فاینتیون کنید، رویکردهای مختلفی در این مستند توضیح داده شدهاند.
در ادامه، نمونهای از استفاده pipelineها برای انجام خلاصهسازی آورده شده است. در این مثال از یک مدل BART استفاده میشود که روی دیتاست CNN / Daily Mail فاینتیون شده است.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from transformers import pipeline summarizer = pipeline(“summarization”) ARTICLE = “”” New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York. A year later, she got married again in Westchester County, but to a different man and without divorcing her first husband. Only 18 days after that marriage, she got hitched yet again. Then, Barrientos declared “I do” five more times, sometimes only within two weeks of each other. In 2010, she married once more, this time in the Bronx. In an application for a marriage license, she stated it was her “first and only” marriage. Barrientos, now 39, is facing two criminal counts of “offering a false instrument for filing in the first degree,” referring to her false statements on the 2010 marriage license application, according to court documents. Prosecutors said the marriages were part of an immigration scam. On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to her attorney, Christopher Wright, who declined to comment further. After leaving court, Barrientos was arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New York subway through an emergency exit, said Detective Annette Markowski, a police spokeswoman. In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002. All occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be married to four men, and at one time, she was married to eight men at once, prosecutors say. Prosecutors said the immigration scam involved some of her husbands, who filed for permanent residence status shortly after the marriages. Any divorces happened only after such filings were approved. It was unclear whether any of the men will be prosecuted. The case was referred to the Bronx District Attorney\’s Office by Immigration and Customs Enforcement and the Department of Homeland Security\’s Investigation Division. Seven of the men are from so-called “red–flagged” countries, including Egypt, Turkey, Georgia, Pakistan and Mali. Her eighth husband, Rashid Rajput, was deported in 2006 to his native Pakistan after an investigation by the Joint Terrorism Task Force. If convicted, Barrientos faces up to four years in prison. Her next court appearance is scheduled for May 18. ““” |
از آنجا که pipeline مربوط به خلاصهسازی بر متد PreTrainedModel.generate() متکی است، میتوان آرگومانهای پیشفرض این متد—از جمله max_length و min_length—را مستقیماً هنگام استفاده از pipeline بازنویسی کرد؛ همانطور که در مثال زیر نشان داده شده است. خروجی این فرایند، خلاصهای به شکل زیر خواهد بود:
|
1 2 3 4 |
print(summarizer(ARTICLE, max_length=130, min_length=30, do_sample=False)) [{‘summary_text’: ‘ Liana Barrientos, 39, is charged with two counts of “offering a false instrument for filing in the first degree” In total, she has been married 10 times, with nine of her marriages occurring between 1999 and 2002 . At one time, she was married to eight men at once, prosecutors say .’}] |
در این مثال، خلاصهسازی با استفاده از یک model و یک tokenizer انجام میشود. روند کار به این صورت است:
- ابتدا یک tokenizer و یک model با استفاده از نام چکپوینت نمونهسازی میشوند. معمولا خلاصهسازی با مدلهای encoder–decoder مانند BART یا T5 انجام میشود.
- سپس متنی که قرار است خلاصه شود تعریف میگردد.
- در صورت استفاده از T5، پیشوند مخصوص این مدل یعنی “summarize: ” به ابتدای متن اضافه میشود.
- در ادامه، با استفاده از متد PreTrainedModel.generate() خلاصه متن تولید میشود.
- در این مثال از مدل T5 گوگل استفاده شده است. با اینکه این مدل فقط روی یک دیتاست ترکیبی چندوظیفهای (از جمله CNN / Daily Mail) پیشآموزش دیده، همچنان نتایج بسیار خوبی ارائه میدهد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer model = AutoModelForSeq2SeqLM.from_pretrained(“t5-base”) tokenizer = AutoTokenizer.from_pretrained(“t5-base”) # T5 uses a max_length of 512 so we cut the article to 512 tokens. inputs = tokenizer(“summarize: “ + ARTICLE, return_tensors=“pt”, max_length=512, truncation=True) outputs = model.generate( inputs[“input_ids”], max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True ) print(tokenizer.decode(outputs[0])) <pad> prosecutors say the marriages were part of an immigration scam. if convicted, barrientos faces two criminal counts of “offering a false instrument for filing in the first degree” she has been married 10 times, nine of them between 1999 and 2002.</s> |
ترجمه (Translation)
ترجمه وظیفهای است که در آن، یک متن از یک زبان به زبان دیگر تبدیل میشود. اگر قصد دارید مدلی را برای یک وظیفه ترجمه فاینتیون کنید، میتوانید از اسکریپت run_translation.py استفاده کنید.
یکی از دیتاستهای شناختهشده در این حوزه، WMT (ترجمه انگلیسی به آلمانی) است که در آن، جملات انگلیسی بهعنوان ورودی و معادل آلمانی آنها بهعنوان خروجی (هدف) در نظر گرفته میشود. اگر بخواهید مدلی را برای ترجمه فاینتیون کنید، رویکردهای مختلفی در این مستند توضیح داده شدهاند.
در ادامه، نمونهای از استفاده pipelineها برای انجام ترجمه آورده شده است. در این مثال از یک مدل T5 استفاده میشود که فقط روی یک دیتاست ترکیبی چندوظیفهای (از جمله WMT) پیشآموزش دیده، اما با این حال نتایج ترجمه بسیار قابلتوجهی ارائه میدهد.
|
1 2 3 4 5 |
from transformers import pipeline translator = pipeline(“translation_en_to_de”) print(translator(“Hugging Face is a technology company based in New York and Paris”, max_length=40)) [{‘translation_text’: ‘Hugging Face ist ein Technologieunternehmen mit Sitz in New York und Paris.’}] |
از آنجا که pipeline مربوط به ترجمه بر متد PreTrainedModel.generate() متکی است، میتوان آرگومانهای پیشفرض این متد را مستقیما هنگام استفاده از pipeline بازنویسی کرد؛ همانطور که در مثال بالا برای max_length نشان داده شده است.
در ادامه، نمونهای از انجام ترجمه با استفاده از یک model و یک tokenizer آورده شده است. روند کار به این صورت است:
۱. ابتدا یک tokenizer و یک model با استفاده از نام چکپوینت نمونهسازی میشوند. معمولاً ترجمه (مانند خلاصهسازی) با مدلهای encoder–decoder نظیر BART یا T5 انجام میشود.
۲. سپس متنی که قرار است ترجمه شود تعریف میگردد.
۳. در صورت استفاده از T5، پیشوند مخصوص این مدل یعنی “translate English to German: ” به ابتدای متن اضافه میشود.
۴. در نهایت، با استفاده از متد PreTrainedModel.generate() فرایند ترجمه انجام میشود.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer model = AutoModelForSeq2SeqLM.from_pretrained(“t5-base”) tokenizer = AutoTokenizer.from_pretrained(“t5-base”) inputs = tokenizer( “translate English to German: Hugging Face is a technology company based in New York and Paris”, return_tensors=“pt” ) outputs = model.generate(inputs[“input_ids”], max_length=40, num_beams=4, early_stopping=True) print(tokenizer.decode(outputs[0])) <pad> Hugging Face ist ein Technologieunternehmen mit Sitz in New York und Paris.</s> |
در این حالت، همان ترجمهای به دست میآید که در مثال مبتنی بر pipeline مشاهده کردیم.
نتیجهگیری
Transformers عملا یک جعبهابزار کامل برای اجرای تسکهای متداول NLP است؛ از طبقهبندی دنباله و پرسشوپاسخ استخراجی گرفته تا NER، مدلسازی زبان و تسکهای تولیدی مثل خلاصهسازی و ترجمه. اگر میخواهید سریع به نتیجه برسید، Pipelineها بهترین انتخاباند؛ اما وقتی کنترل دقیقتر روی ورودیها، خروجیها، یا تنظیمات استنتاج لازم دارید، استفاده مستقیم از مدل و tokenizer انعطاف و قدرت بیشتری در اختیارتان میگذارد.
در نهایت، کیفیت خروجی تا حد زیادی به انتخاب چکپوینت مناسب همان تسک و میزان همپوشانی دیتاست فاینتیون با نیاز واقعی شما وابسته است. اگر مدل آماده دقیقا با دامنه مسئله شما همراستا نیست، بهترین مسیر این است که از اسکریپتهای رسمی examples استفاده کنید یا یک روند فاینتیون اختصاصی بسازید تا مدل را به دادهها و کاربرد خودتان نزدیکتر کنید.
منابع
سوالات متداول
Pipeline سادهترین راه اجرای تسکهای NLP است و وقتی سرعت توسعه و سادگی برایتان مهم است، بهترین انتخاب محسوب میشود.
وقتی به کنترل بیشتر روی ورودیها، خروجیها، یا تنظیمات استنتاج نیاز دارید، استفاده مستقیم از مدل و tokenizer گزینه مناسبتری است.
چون هر مدل برای یک تسک و دیتاست خاص فاینتیون شده و استفاده از چکپوینت نامناسب معمولا به خروجی ضعیف منجر میشود.
این کلاسها نوع معماری مدل را بهصورت خودکار از روی چکپوینت تشخیص میدهند و فرایند بارگذاری مدل را سادهتر و امنتر میکنند.


دیدگاهتان را بنویسید