
OpenAI Vision API قابلیتی است که به مدلهای هوش مصنوعی اجازه میدهد تصاویر را تحلیل کنند، محتوای بصری را بفهمند و بر اساس تصویر استدلال انجام دهند. با استفاده از Vision API، مدل دیگر محدود به ورودی متنی نیست و میتواند تصویر را بهعنوان بخشی از ورودی درک کند؛ از تشخیص اشیا و متن داخل تصویر گرفته تا تحلیل نمودارها و پاسخ به سوالهای مفهومی درباره تصویر.
در این مقاله ابتدا توضیح میدهیم Vision API چیست و چه تفاوتی با روشهای سنتی پردازش تصویر دارد. سپس کاربردهای رایج آن را بررسی میکنیم و نحوه کار Vision API را بهصورت مفهومی توضیح میدهیم. بعد از آن وارد مثالهای عملی و کدنویسی میشویم، روشهای مختلف ارسال تصویر به API را بررسی میکنیم، محدودیتها و نکات مهم را توضیح میدهیم.
Vision API چیست؟
Vision API بخشی از قابلیتهای چندوجهی (Multimodal) OpenAI است. این API به مدل اجازه میدهد تصویر را همراه با متن دریافت کند و بر اساس ترکیب این دو، پاسخ تولید کند. به بیان ساده، مدل میتواند «ببیند» و درباره آنچه میبیند توضیح دهد یا استدلال کند.
نکته مهم این است که Vision API فقط یک ابزار تشخیص تصویر یا OCR نیست. مدل تلاش میکند محتوای تصویر را بفهمد؛ یعنی بتواند روابط بین اشیا، مفهوم یک نمودار یا معنای کلی یک صحنه را درک کند. این ویژگی Vision API را از ابزارهای کلاسیک پردازش تصویر متمایز میکند.
Vision API چه تفاوتی با OCR و ابزارهای کلاسیک دارد؟
در ابزارهای سنتی پردازش تصویر، هر سیستم معمولا برای یک وظیفه خاص طراحی میشود؛ مثلا:
- OCR برای استخراج متن
- Object Detection برای تشخیص اشیا
- Image Classification برای دستهبندی تصویر
Vision API همه این قابلیتها را در قالب یک مدل زبانی-تصویری ارائه میدهد. خروجی آن فقط داده خام نیست، بلکه تحلیل متنی همراه با استدلال است. برای مثال:
- OCR فقط متن داخل تصویر را برمیگرداند.
- Vision API میتواند توضیح دهد این متن مربوط به چیست و چه نقشی در تصویر دارد.

چرا مدلهای بینایی (Vision Models) اهمیت دارند؟
مدلهای بینایی افقهای جدیدی را برای اتوماسیون، خلاقیت و تعاملات چندوجهی در هوش مصنوعی باز میکنند. این مدلها به هوش مصنوعی اجازه میدهند فراتر از متن عمل کرده و با دنیای بصری ارتباط برقرار کند.
گسترش دامنه کاربرد هوش مصنوعی
قابلیت بینایی، هوش مصنوعی را وارد حوزههایی میکند که دادههای تصویری در آنها نقش اصلی دارند؛ حوزههایی مانند سلامت، خردهفروشی، صنعت و هنرهای خلاقانه. برای مثال، در پزشکی، سیستمهای مبتنی بر بینایی میتوانند ناهنجاریها را در تصاویر رادیولوژی یا MRI شناسایی کنند و به تشخیص سریعتر بیماریها کمک کنند.
امکان تعاملات چندوجهی (Multimodal)
با ترکیب ورودیهای متنی و تصویری، میتوان سیستمهایی ساخت که توصیف تصویر تولید کنند، به سوالهایی درباره یک عکس پاسخ دهند یا تجربههای چت غنیتری ارائه دهند. این رویکرد باعث میشود تعامل با هوش مصنوعی طبیعیتر و شبیهتر به تعامل انسانی باشد.
مثال: یک دستیار مجازی میتواند تصویر یک محصول را تحلیل کند و توضیحات دقیق یا پیشنهادهای شخصیسازیشده به کاربر ارائه دهد.

تقویت اتوماسیون
از فروشگاههای بدون صندوقدار گرفته تا خودروهای خودران، تشخیص تصویر در زمان واقعی نقش کلیدی در ایجاد فرایندهای خودکار جدید دارد. مدلهای بینایی میتوانند محیط اطراف را تحلیل کنند و تصمیمهای سریع و دقیق بگیرند.
مثال: یک خودروی خودران با استفاده از Vision API میتواند علائم راهنمایی، موانع و عابران پیاده را شناسایی کند و مسیر امنتری را انتخاب کند.
افزایش خلاقیت و تولید محتوا
ابزارهایی مانند DALL·E نشان میدهند که مدلهای بینایی فقط برای تحلیل تصویر نیستند، بلکه میتوانند در تولید محتوا نیز نقش مهمی داشته باشند. تبدیل توضیحات متنی به تصاویر بصری، برای نمونهسازی طراحیها، تولید محتوای بازاریابی یا خلق آثار هنری جدید بسیار کاربردی است.
کاربردهای Vision API چیست؟
Vision API کاربردهای متنوعی دارد و به یک سناریوی خاص محدود نمیشود. از جمله کاربردهای رایج آن میتوان به موارد زیر اشاره کرد:
تولید توضیح متنی برای تصویر (Image Captioning)
Image Captioning به معنای تولید توضیح متنی طبیعی برای یک تصویر است. در این کاربرد، مدل با تحلیل محتوای تصویر میتواند یک توصیف انسانی و قابل فهم تولید کند. این قابلیت در سناریوهایی مثل بهبود دسترسپذیری برای افراد کمبینا، بهینهسازی سئو تصاویر و برچسبگذاری خودکار عکسها کاربرد زیادی دارد.
برای مثال، یک سیستم مدیریت محتوا میتواند بهصورت خودکار برای تصاویر آپلودشده توضیح متنی تولید کند یا در یک اپلیکیشن دسترسپذیری، تصویر محیط اطراف را برای کاربر توصیف کند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import openai def caption_image(image_url): response = openai.chat.completions.create( model=“gpt-4-vision”, messages=[{“role”: “user”, “content”: f“Describe this image: {image_url}”}], max_tokens=100 ) return response.choices[0].message.content url = “https://example.com/path/to/image.jpg” print(“Caption:”, caption_image(url)) |
تشخیص و شناسایی اشیا (Object Recognition and Detection)
در این کاربرد، Vision API میتواند اشیا موجود در تصویر را شناسایی کند و حتی موقعیت آنها را مشخص کند. این قابلیت برای تحلیل دادههای تصویری، سیستمهای نظارتی، بازرسی صنعتی و تحلیل ویدئوهای زنده بسیار مفید است.
برای مثال، در یک سیستم نظارتی بلادرنگ میتوان از Vision API برای تشخیص افراد، وسایل نقلیه یا اشیا خاص در تصویر استفاده کرد و بر اساس آن تصمیمگیری انجام داد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import openai def detect_objects(image_url): response = openai.chat.completions.create( model=“gpt-4-vision”, messages=[{“role”: “user”, “content”: f“List all objects in this image and their locations: {image_url}”}], max_tokens=150 ) return response.choices[0].message.content url = “https://example.com/path/to/image.jpg” print(“Objects Detected:”, detect_objects(url)) |
پرسش و پاسخ تصویری (Visual Question Answering – VQA)
Visual Question Answering یا VQA به این معناست که کاربر میتواند درباره محتوای یک تصویر سوال بپرسد و مدل با تحلیل تصویر، پاسخ مناسب ارائه دهد. این قابلیت برای پشتیبانی مشتری، آموزش و ابزارهای دسترسپذیری بسیار کاربردی است.
برای مثال، یک کاربر میتواند تصویری از یک محصول ارسال کند و بپرسد «این چیست؟» یا «این قطعه چه کاربردی دارد؟».
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import openai def visual_question_answering(image_url, question): response = openai.chat.completions.create( model=“gpt-4-vision”, messages=[ {“role”: “user”, “content”: f“Here is an image: {image_url}\nQuestion: {question}”} ], max_tokens=100 ) return response.choices[0].message.content image_url = “https://example.com/path/to/image.jpg” answer = visual_question_answering(image_url, “What is this object?”) print(“Answer:”, answer) |
تولید محتوای چندوجهی (Multimodal Generation)
در این کاربرد، متن و تصویر با هم ترکیب میشوند تا محتوای جدیدی تولید یا ویرایش شود. این قابلیت میتواند برای ویرایش خلاقانه تصاویر، تبدیل طرح اولیه به تصویر نهایی یا ساخت تصاویر سفارشی بر اساس توضیح متنی استفاده شود.
برای مثال، میتوان یک طرح ساده (Sketch) را به مدل داد و با یک توضیح متنی، نسخهای کاملتر و واقعیتر از آن تولید کرد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import openai def generate_image_from_sketch(image_url, text_description): response = openai.images.generate( model=“dall-e-3”, prompt=f“Use the following image as a base: {image_url}. Add these details: {text_description}”, size=‘1024×1024’ ) return response.data[0].url image_url = “https://example.com/path/to/sketch.jpg” description = “Add a bright blue sky and detailed buildings in the background.” print(“Generated Image URL:”, generate_image_from_sketch(image_url, description)) |
پایش و فیلتر محتوای تصویری (Content Moderation)
Vision API میتواند برای بررسی و فیلتر خودکار تصاویر ناامن یا مغایر با سیاستهای محتوا استفاده شود. این کاربرد برای پلتفرمهایی که کاربران در آنها تصویر آپلود میکنند (مثل شبکههای اجتماعی یا فرومها) بسیار حیاتی است.
با استفاده از این قابلیت، میتوان تصاویر نامناسب را قبل از نمایش به کاربران شناسایی و مسدود کرد.
توجه: هنگام استفاده از این قابلیت، باید حتما با سیاستهای محتوایی OpenAI مطابقت داشته باشید.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import openai def moderate_image(image_url): response = openai.moderations.create( model=“vision-moderation-latest”, input=image_url ) return response.results[0].flagged url = “https://example.com/path/to/image.jpg” print(“Moderation flagged:”, moderate_image(url)) |
تشخیص و تحلیل چهره (Face Recognition and Analysis)
در این کاربرد، Vision API میتواند چهره افراد را تحلیل کند و اطلاعاتی مانند تخمین سن، جنسیت یا حالت احساسی ارائه دهد. این قابلیت در سیستمهای امنیتی، احراز هویت کاربران و تحلیل رفتار کاربران کاربرد دارد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import openai def analyze_face(image_url): response = openai.chat.completions.create( model=“gpt-4-vision”, messages=[{“role”: “user”, “content”: f“Analyze this image for age, gender, and emotion: {image_url}”}], max_tokens=100 ) return response.choices[0].message.content url = “https://example.com/path/to/face.jpg” print(“Face Analysis:”, analyze_face(url)) |
تبدیل تصویر به تصویر (Image-to-Image Translation)
Image-to-Image Translation به معنای تبدیل یک تصویر به تصویر دیگر با سبک یا ویژگی متفاوت است. برای مثال، میتوان یک طرح دستی را به یک تصویر فتورئال تبدیل کرد یا فیلترهای خاصی روی تصویر اعمال کرد. این کاربرد در طراحی، شبیهسازی و صنعت سرگرمی بسیار پرکاربرد است.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import openai def image_to_image_translation(input_image_url, transformation_description): response = openai.images.generate( model=“dall-e-3”, prompt=f“Transform the image at {input_image_url} by {transformation_description}”, size=‘1024×1024’ ) return response.data[0].url input_image_url = “https://www.example.com/hi.jpg” transformation_description = “convert this sketch into a photorealistic image.” print(“Translated Image URL:”, image_to_image_translation(input_image_url, transformation_description)) |
Vision API چگونه کار میکند؟
در سطح مفهومی، استفاده از Vision API شبیه به کار با مدلهای متنی است. شما یک درخواست به API ارسال میکنید که شامل:
- یک یا چند تصویر
- یک prompt متنی
مدل تصویر را به نمایش داخلی قابل پردازش تبدیل میکند، سپس آن را همراه با متن تحلیل میکند و در نهایت پاسخ متنی تولید میکند. تمام این فرآیند در قالب یک درخواست API انجام میشود.
مثال عملی: توصیف یک تصویر
سادهترین سناریو این است که از مدل بخواهیم تصویر را توصیف کند.
مثال با Python (ارسال تصویر از طریق URL)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from openai import OpenAI client = OpenAI() response = client.responses.create( model=“gpt-4.1”, input=[ { “role”: “user”, “content”: [ {“type”: “input_text”, “text”: “Describe this image.”}, { “type”: “input_image”, “image_url”: “https://upload.wikimedia.org/wikipedia/commons/thumb/3/3f/Fronalpstock_big.jpg/800px-Fronalpstock_big.jpg” } ] } ] ) print(response.output_text) |
در این مثال:
- تصویر از طریق URL ارسال شده است.
- prompt از مدل میخواهد محتوای تصویر را توصیف کند.
ارسال تصویر به Vision API (روشها)
ارسال تصویر با URL
سادهترین روش ارسال تصویر است و برای تصاویر عمومی یا ذخیرهشده روی سرور مناسب است.
ارسال تصویر بهصورت Base64
اگر تصویر بهصورت فایل محلی در اختیار دارید، میتوانید آن را به Base64 تبدیل کنید.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import base64 def encode_image(path): with open(path, “rb”) as f: return base64.b64encode(f.read()).decode(“utf-8”) image_base64 = encode_image(“image.jpg”) response = client.responses.create( model=“gpt-4.1”, input=[ { “role”: “user”, “content”: [ {“type”: “input_text”, “text”: “What is shown in this image?”}, { “type”: “input_image”, “image_base64”: image_base64 } ] } ] ) |
پرسیدن سوال مشخص درباره تصویر
قدرت اصلی Vision API زمانی مشخص میشود که بهجای توصیف کلی، سوال دقیق بپرسیم.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
response = client.responses.create( model=“gpt-4.1”, input=[ { “role”: “user”, “content”: [ {“type”: “input_text”, “text”: “How many people are visible in this image?”}, { “type”: “input_image”, “image_url”: “https://example.com/people.jpg” } ] } ] ) print(response.output_text) |
در این حالت، مدل تلاش میکند فقط به همان سوال پاسخ دهد، نه توصیف کلی تصویر.
مثال پیشرفتهتر: تحلیل نمودار
Vision API میتواند نمودارها را نیز تحلیل کند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
response = client.responses.create( model=“gpt-4.1”, input=[ { “role”: “user”, “content”: [ {“type”: “input_text”, “text”: “Which year shows the highest value in this chart?”}, { “type”: “input_image”, “image_url”: “https://example.com/chart.png” } ] } ] ) print(response.output_text) |
این مثال نشان میدهد Vision API فقط تصویر را «نمیبیند»، بلکه درباره آن استدلال میکند.
Vision API در سیستمهای چندوجهی (Multimodal Systems)
Vision API معمولا در کنار قابلیتهای متنی و ابزارهای دیگر استفاده میشود. در سیستمهای پیشرفتهتر، مدل میتواند:
- تصویر را تحلیل کند
- تصمیم بگیرد چه کاری باید انجام شود
- از ابزارها یا APIهای دیگر استفاده کند
این رویکرد پایهی سیستمهای چندوجهی و Agentهای هوشمند آینده است.
محدودیتهای Vision Models
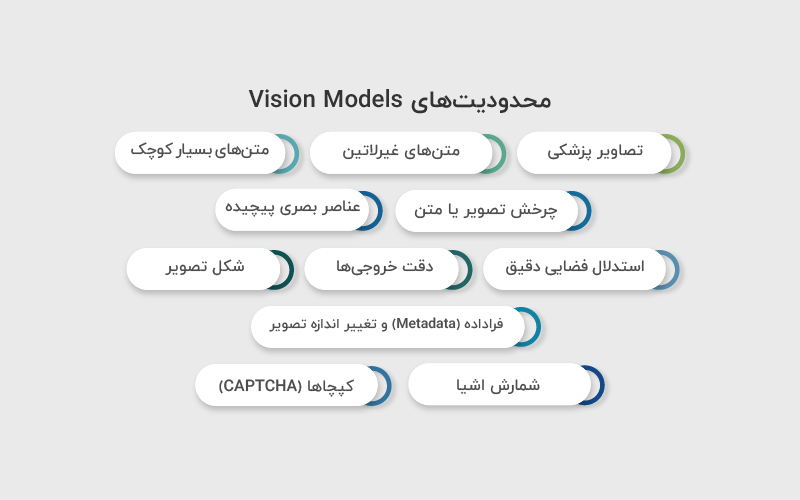
با وجود اینکه مدلهای دارای قابلیت بینایی بسیار قدرتمند هستند و میتوان از آنها در سناریوهای متنوعی استفاده کرد، آگاهی از محدودیتهای آنها اهمیت زیادی دارد. شناخت این محدودیتها کمک میکند از Vision API در جای درست استفاده شود و انتظار واقعبینانهای از خروجی مدل داشته باشیم.
- تصاویر پزشکی: این مدلها برای تفسیر تصاویر تخصصی پزشکی مانند سیتیاسکن یا MRI طراحی نشدهاند و نباید برای ارائه تشخیص پزشکی یا توصیههای درمانی از آنها استفاده شود.
- متنهای غیرلاتین: عملکرد مدل در تحلیل تصاویری که شامل متنهایی با الفباهای غیرلاتین (مانند ژاپنی یا کرهای) هستند ممکن است بهینه نباشد و دقت کمتری داشته باشد.
- متنهای بسیار کوچک: برای بهبود خوانایی، بهتر است متن داخل تصویر بزرگتر باشد. با این حال، بزرگنمایی نباید باعث حذف یا برش بخشهای مهم تصویر شود.
- چرخش تصویر یا متن: تصاویر یا متنهایی که بهصورت چرخیده یا وارونه هستند ممکن است بهدرستی تفسیر نشوند و باعث برداشت نادرست مدل شوند.
- عناصر بصری پیچیده: درک نمودارها یا متونی که تفاوت آنها بر اساس رنگ، سبک خط (پیوسته، نقطهچین یا خطچین) یا استایلهای بصری ظریف است، میتواند برای مدل چالشبرانگیز باشد.
- استدلال فضایی دقیق: مدل در انجام وظایفی که به دقت بالای فضایی نیاز دارند، مانند تشخیص موقعیت دقیق مهرهها در صفحه شطرنج، عملکرد ضعیفتری دارد.
- دقت خروجیها: در برخی سناریوها، مدل ممکن است توضیحات یا کپشنهایی تولید کند که کاملا دقیق یا مطابق با واقعیت نیستند.
- شکل تصویر: تصاویر پانورامیک یا فیشآی (fisheye) برای مدل چالشبرانگیز هستند و ممکن است بهدرستی تحلیل نشوند.
- فراداده (Metadata) و تغییر اندازه تصویر: مدل نام فایل اصلی یا فراداده تصویر را پردازش نمیکند و تصاویر قبل از تحلیل تغییر اندازه داده میشوند؛ موضوعی که میتواند روی ابعاد و جزئیات اصلی تصویر تاثیر بگذارد.
- شمارش اشیا: شمارش اشیا در تصویر معمولا بهصورت تقریبی انجام میشود و نباید انتظار دقت صددرصدی داشت.
- کپچاها (CAPTCHA): به دلایل امنیتی، ارسال تصاویر کپچا به سیستم مسدود شده است و امکان تحلیل آنها وجود ندارد.
جمعبندی
OpenAI Vision API ابزاری برای «دیدن» تصویر نیست، بلکه ابزاری برای درک و استدلال بصری است. با ترکیب تصویر و متن، میتوان سیستمهایی ساخت که تعامل طبیعیتر و هوشمندانهتری با دنیای واقعی داشته باشند. اگر Vision API بهدرستی طراحی و استفاده شود، میتواند پایهی بسیاری از محصولات هوش مصنوعی نسل جدید باشد.
منابع
notes.kodekloud.com | platform.openai.com
سوالات متداول
بله. OpenAI معمولا برای کاربران جدید اعتبار آزمایشی (Trial Credits) در نظر میگیرد که میتوانید با استفاده از آن، بدون پرداخت هزینه اولیه، API را تست و آزمایش کنید. این اعتبار برای انجام تستهای اولیه و آشنایی با قابلیتها مناسب است.
برای دریافت API Key:
– وارد صفحه مدیریت API Key شوید
– Secret API Key خود را ایجاد یا کپی کنید
تفاوت اصلی این دو در نوع خروجی و کاربرد آنهاست:
Generative AI
محتوای جدید تولید میکند، مانند:
– متن
– تصویر
– ویدیو
– کد
Vision AI
محتوای موجود را تحلیل میکند، بهویژه:
– تصاویر
– ویدیوها
و روی تشخیص، درک و استخراج اطلاعات از آنها تمرکز دارد.
تمرکز اصلی Vision API روی تصاویر است، اما میتواند در سیستمهای چندوجهی در کنار متن و سایر ورودیها استفاده شود تا تحلیل دقیقتری انجام شود.




دیدگاهتان را بنویسید