در دنیای امروز که تصمیمگیریها بیش از هر زمان دیگری دادهمحور شده، جستوجو در حجم عظیمی از دادهها برای پیدا کردن آیتمهای مشابه، یکی از عملیاتهای پایه و پرکاربرد است؛ عملیاتی که از پایگاههای داده گرفته تا موتورهای جستوجو و سیستمهای پیشنهاددهنده، نقش کلیدی دارد. به این فرایند جستوجوی شباهت (Similarity Search) میگویند؛ یعنی پیدا کردن مواردی که بر اساس یک یا چند معیار، «شبیه» هم هستند.
اگر جستوجوهای سنتی در دیتابیس را در نظر بگیریم، مثلا پیدا کردن کارمندانی که حقوقشان در یک بازه مشخص قرار دارد، همهچیز روشن و سرراست است، چون معیارها عددی و دقیقاند. اما جستوجوی شباهت با پرسوجوهای پیچیدهتری سروکار دارد. برای مثال، کاربر ممکن است عبارتهایی مثل «کفش»، «کفش مشکی» یا حتی یک مدل مشخص مثل «Nike AF-1 LV8» را جستوجو کند. این نوع درخواستها میتوانند مبهم و متنوع باشند و از سیستم میخواهند که مفهومها را بفهمد و تفاوت بین چیزهایی مثل انواع مختلف کفش را تشخیص دهد.
اهمیت و کاربردهای جستجوی شباهت
جستوجوی شباهت در حوزههای زیادی نقش حیاتی دارد، از جمله:
- تجارت الکترونیک: پیشنهاد محصولاتی شبیه به چیزهایی که کاربر دیده یا خریده است.
- جستوجوی تصویر و ویدئو: پیدا کردن تصاویر یا ویدئوهای از نظر بصری مشابه در دیتابیسهای بزرگ.
- پردازش زبان طبیعی (NLP): تطبیق اسناد متنی مشابه مثل ایمیلها، مقالهها یا فایلهای متنی.
- سلامت و پزشکی: شناسایی پروندههای پزشکی مشابه یا بررسی شباهت بین توالیهای ژنتیکی.
چالش اصلی در جستوجوی شباهت این است که باید همزمان با مقیاس بسیار بزرگ دادهها کنار بیاییم و در عین حال بتوانیم معنای عمیقتر و مفهومی آیتمها را درست درک کنیم. پایگاههای داده سنتی که به نمایشهای نمادین (Symbolic) از اشیا متکی هستند، معمولا در این سناریوها کم میآورند. در عوض، به تکنیکهای پیشرفتهتری نیاز داریم که بتوانند داده را به شکل معنایی (Semantic) نمایش دهند و حتی در مقیاسهای بزرگ هم جستوجو را کارآمد انجام دهند.
جستوجوی شباهت کمک میکند پرسوجوهای پیچیده و انتزاعی را به نتایج قابل استفاده تبدیل کنیم؛ همین موضوع باعث میشود در دامنههای مختلف، یک ابزار قدرتمند باشد. در بخشهای بعدی، دقیقتر وارد سازوکار این نوع جستوجو میشویم و روی نقش نمایشهای برداری (Vector Representations)، معیارهای فاصله (Distance Metrics) و الگوریتمهای مختلف جستوجو تمرکز میکنیم.
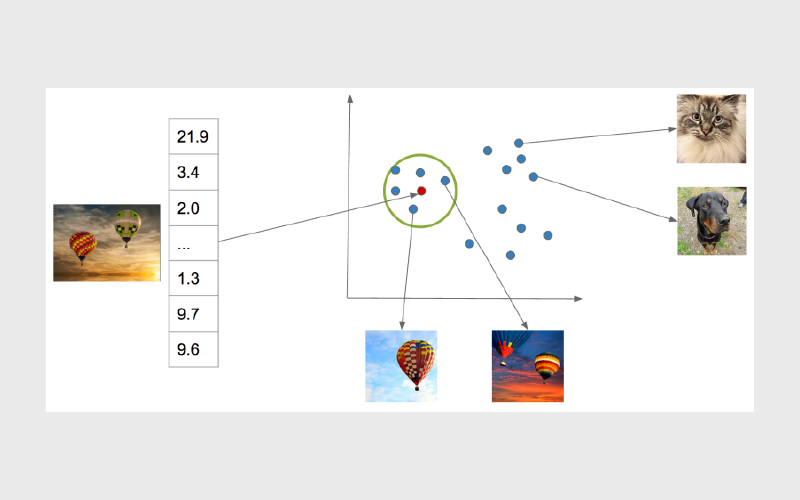
نمایشهای برداری: امبدینگهای برداری چیستند؟
در یادگیری ماشین، برای اینکه بتوانیم با اشیا و مفاهیم دنیای واقعی به شکل قابلمحاسبه کار کنیم، آنها را به صورت بردار نمایش میدهیم؛ یعنی مجموعهای از عددهای پیوسته که به آن امبدینگ (Embedding) میگویند. این روش کمک میکند معنای عمیقتر و مفهومی آیتمها در یک نمایش عددی فشرده ثبت شود.
وقتی چیزهایی مثل تصویر یا متن به امبدینگ برداری تبدیل میشوند، میتوانیم میزان شباهتشان را با اندازهگیری فاصله بین بردارها در یک فضای با ابعاد بالا محاسبه کنیم.
برای مثال، در یک فضای برداری، تصاویر مشابه معمولا بردارهایی دارند که به هم نزدیکتر هستند و تصاویر نامشابه بردارهایی دارند که دورتر قرار میگیرند. همین ویژگی باعث میشود بتوانیم با عملیاتهای ریاضی، آیتمهای مشابه را به شکل کارآمد پیدا کنیم و با هم مقایسه کنیم.
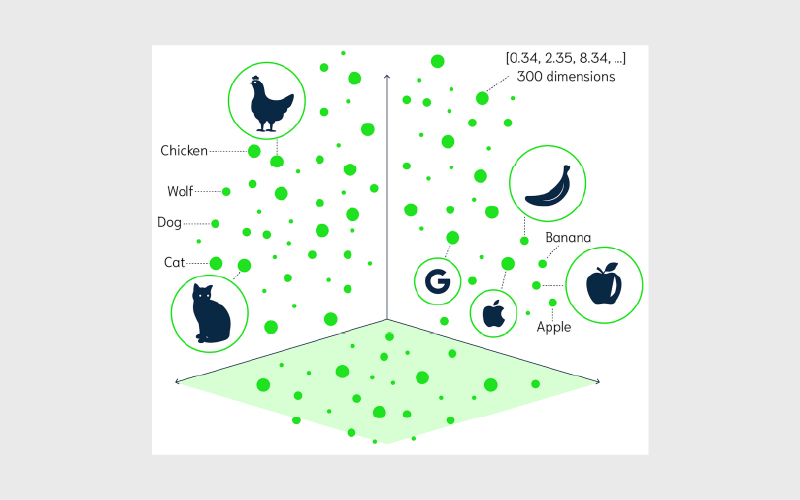
نمونههایی از مدلهای امبدینگ
برای تولید این امبدینگهای برداری، از مدلهای مختلفی استفاده میشود؛ از جمله:
- Word2Vec: کلمات را به بردار تبدیل میکند و روابط معنایی بین آنها را یاد میگیرد.
- GloVe (Global Vectors for Word Representation): مدلی دیگر برای تبدیل متن به بردار که بیشتر روی «زمینه و هموقوعی سراسری» کلمات در کل دادهها تکیه دارد.
- Universal Sentence Encoder (USE): برای کل جمله امبدینگ میسازد و معنا را فراتر از تککلمهها مدل میکند.
- شبکههای عصبی کانولوشنی (CNN) مثل VGG: برای تولید امبدینگ تصویر استفاده میشوند و شباهتهای بصری را در قالب بردار ثبت میکنند.
این مدلها معمولا روی دادههای بسیار بزرگ و با اهداف آموزشی مختلف آموزش میبینند؛ به همین دلیل میتوانند امبدینگهایی تولید کنند که محتوای معنایی آیتمها را به شکل موثری نمایندگی میکند.
سنجش شباهت: معیارهای فاصله
بعد از اینکه دادهها را به شکل امبدینگهای برداری درآوردیم، سوال اصلی این است: «چطور شباهت دو بردار را اندازه بگیریم؟» پاسخ این سوال با معیارهای فاصله (Distance Metrics) داده میشود. این معیارها تعیین میکنند دو بردار در فضای برداری چقدر به هم نزدیکاند یا چقدر از هم فاصله دارند؛ و همین انتخاب، مستقیما روی کیفیت نتایج جستوجوی شباهت اثر میگذارد. بسته به نوع داده و هدف مسئله، ممکن است یک معیار (مثل اقلیدسی) مناسبتر باشد و در سناریوی دیگر معیار دیگری (مثل کسینوسی) نتیجه دقیقتری بدهد.
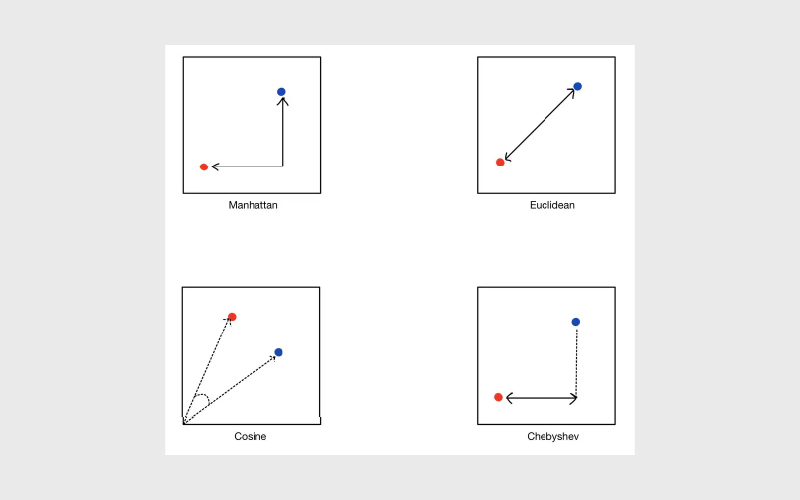
مرور کلی معیارهای فاصله
برای اینکه مشخص کنیم دو امبدینگ برداری چقدر به هم شبیهاند، از معیارهای فاصله (Distance Metrics) استفاده میکنیم. این معیارها «فاصله» بین دو بردار را در فضای برداری حساب میکنند؛ هرچه فاصله کمتر باشد، شباهت بیشتر در نظر گرفته میشود.
فاصله اقلیدسی (Euclidean Distance)
فاصله اقلیدسی، فاصله «خط مستقیم» بین دو نقطه را در یک فضای چندبعدی اندازه میگیرد. این معیار، شهودیترین شکل سنجش فاصله است؛ مشابه همان فاصله هندسی که در دنیای واقعی با خطکش اندازه میگیرید. معمولا وقتی دادهها متراکم هستند و مفهوم فاصله فیزیکی یا هندسی معنا دارد، این معیار انتخاب مناسبی است.
\( d(x, y) = \sqrt{\sum_{i=1}^{n} (x_i – y_i)^2} \)
فاصله منهتن (Manhattan Distance)
فاصله منهتن که با نام فاصله L1 هم شناخته میشود، مجموع قدر مطلق اختلاف مولفههای متناظر دو بردار را حساب میکند. این معیار برای دادههایی با ساختار شبکهای (Grid-like) مناسب است و میشود آن را مثل فاصلهای تصور کرد که در یک شهر با خیابانهای شطرنجی باید طی کنید؛ یعنی به جای حرکت مستقیم، مجبورید در امتداد خیابانها (بلوکهای شهری) جلو بروید.
\( d(x, y) = \sum_{i=1}^{n} \left| x_i – y_i \right| \)
شباهت کسینوسی (Cosine Similarity)
شباهت کسینوسی، کسینوس زاویه بین دو بردار را محاسبه میکند و بیشتر از اینکه روی اندازه بردارها (Magnitude) حساس باشد، روی جهت آنها تمرکز دارد. این معیار بهخصوص برای دادههای متنی خیلی کاربردی است؛ چون ممکن است اندازه بردارها (مثلا بهخاطر طول متن یا فراوانی کلمات) متفاوت باشد اما آنچه اهمیت دارد الگوی استفاده از کلمات و جهت کلی بردار است.
به بیان ساده: اگر دو متن از نظر معنایی نزدیک باشند، بردارهایشان معمولا در یک جهت قرار میگیرند، حتی اگر طول/مقیاسشان یکسان نباشد.
\( \mathrm{similarity}(A, B) = \cos(\theta) = \frac{A \cdot B}{\|A\| \, \|B\|} = \frac{\sum_{i=1}^{n} A_i B_i}{\sqrt{\left(\sum_{i=1}^{n} A_i^2\right)\left(\sum_{i=1}^{n} B_i^2\right)}} \)
فاصله چبیشف (Chebyshev Distance)
فاصله چبیشف، بزرگترین اختلاف بین مولفههای متناظر دو بردار را به عنوان فاصله در نظر میگیرد؛ یعنی بهجای جمع کردن اختلافها، فقط بیشترین فاصله در یک بُعد را معیار قرار میدهد. این معیار معمولا در سناریوهای شبکهای شبیه صفحه شطرنج بهکار میرود؛ جایی که حرکت میتواند در همه جهتها، از جمله قطری هم انجام شود.
به زبان ساده، فاصله چبیشف میگوید: «برای رسیدن از این نقطه به آن نقطه، بیشترین مقدار جابهجایی لازم در بین همه محورها چقدر است؟»
\( D_{\mathrm{Chebyshev}}(x, y) := \max_i \left( |x_i – y_i| \right). \)
انتخاب معیار مناسب
انتخاب معیار فاصله درست، کاملا به ویژگیهای داده و نیازهای همان کاربرد بستگی دارد. چند راهنمای عملی برای انتخاب معیار مناسب:
فاصله اقلیدسی (Euclidean Distance)
- کاربرد: مناسب برای دادههای پیوسته و متراکم که مفهوم فاصلهی هندسی در آنها معنا دارد.
- مزایا: محاسبه و تفسیر ساده؛ در فضاهای کمبعد معمولا خوب جواب میدهد.
- محدودیتها: در ابعاد بالا ممکن است کاراییاش افت کند (بهدلیل نفرین ابعاد).
- مثالها: شباهت تصویر، محاسبات فاصلههای فیزیکی.
فاصله منهتن (Manhattan / L1)
- کاربرد: مناسب برای ساختارهای شبکهای و سناریوهایی که حرکت فقط در راستاهای عمود بر هم انجام میشود.
- مزایا: در برخی دادهها نسبت به دادههای پرت (Outlier) مقاومتر از اقلیدسی است.
- محدودیتها: برای دادههای غیرشبکهای کمتر شهودی است؛ به مقیاسبندی ویژگیها (Feature Scaling) حساس میشود.
- مثالها: الگوریتمهای مسیریابی روی گرید (مثل A*)، مدلسازی مسیر و چیدمان شهری.
شباهت کسینوسی (Cosine Similarity)
- کاربرد: ایدئال برای دادههای متنی و دادههای کمتراکمِ پُربُعد (Sparse) که جهت بردار مهمتر از اندازه آن است.
- مزایا: جهتگیری بردارها را خوب ثبت میکند و از تغییر مقیاس/طول بردارها کمتر اثر میگیرد.
- محدودیتها: اگر بردارها نرمالسازی نشده باشند، ممکن است نتیجهها پایدار نباشند.
- مثالها: شباهت بین اسناد، سیستمهای پیشنهاددهنده مبتنی بر متن.
فاصله چبیشف (Chebyshev Distance)
- کاربرد: وقتی «بزرگترین اختلاف در یک بُعد» تعیینکننده است؛ مثلا در برخی مدلهای حرکت روی صفحههای شبیه بازی.
- مزایا: محاسبه ساده؛ در مسیریابی گریدی که حرکت قطری مجاز است میتواند مفید باشد.
- محدودیتها: در دادههای طبیعی کمتر رایج است و برای دادههای پیوسته همیشه شهودی نیست.
- مثالها: الگوریتمهای شطرنج، ناوبری رباتها در محیطهای شبکهای.
اجرای جستوجوی شباهت
وقتی دادهها را به بردار تبدیل کردیم و معیار فاصله را هم مشخص کردیم، نوبت به مرحله عملی میرسد: چطور در میان میلیونها یا حتی میلیاردها بردار، نزدیکترینها را پیدا کنیم؟ اجرای جستوجوی شباهت دقیقا به همین مسئله میپردازد. در سادهترین حالت میتوان همه بردارها را با کوئری مقایسه کرد اما این روش در مقیاس بزرگ هزینه محاسباتی بالایی دارد. به همین دلیل، الگوریتمها و ساختارهایی مثل k-NN و بهویژه روشهای ANN طراحی شدهاند تا با حفظ کیفیت قابلقبول، جستوجو را در زمان مناسب و در مقیاس بالا ممکن کنند.
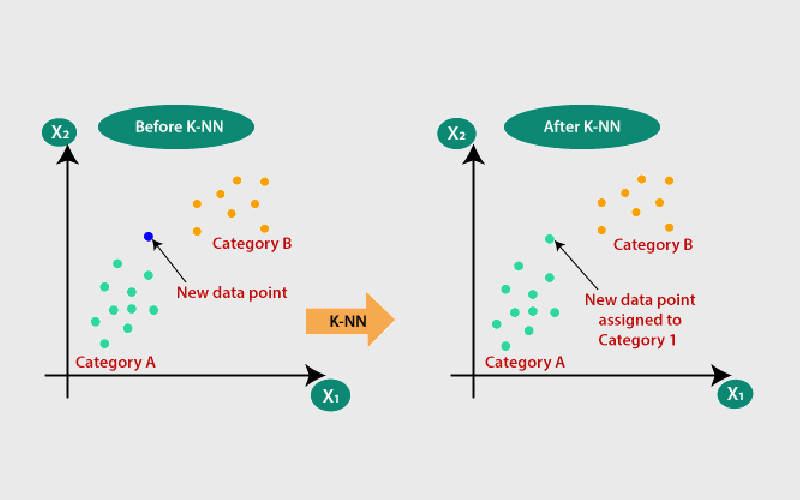
الگوریتم K-Nearest Neighbors (k-NN)
K-Nearest Neighbors یا به اختصار k-NN یکی از الگوریتمهای رایج برای پیدا کردن نزدیکترین بردارها به یک بردارِ کوئری است. ایدهی اصلیاش ساده است: «هر چیزی که به کوئری نزدیکتر باشد، مشابهتر است.»
نحوه کار:
الگوریتم فاصلهی بردار کوئری را با تمام بردارهای موجود در دیتاست محاسبه میکند. سپس بر اساس معیار فاصلهای که انتخاب کردهایم (مثل اقلیدسی، منهتن و …)، k بردار با کمترین فاصله را بهعنوان نزدیکترین همسایهها انتخاب میکند.
مزایا:
- پیادهسازی و درک ساده
- نیازی به فاز آموزش مدل ندارد (Training-free)
معایب:
برای دیتاستهای بزرگ بسیار پرهزینه است، چون باید فاصلهی کوئری با همه بردارها محاسبه شود.
موارد استفاده:
برای دیتاستهای کوچک یا متوسط که همسایههای دقیق (Exact Nearest Neighbors) لازم داریم مناسب است؛ مثلا در برخی سیستمهای پیشنهاددهنده با تعداد کاربران/آیتم محدود.
نزدیکترین همسایه تقریبی (Approximate Nearest Neighbor | ANN)
برای اینکه مشکل ناکارآمدی k-NN در دیتاستهای بزرگ حل شود، روشهای ANN (نزدیکترین همسایهی تقریبی) یک گزینه سریعتر، البته با دقت کمتر ارائه میکنند. ایده ANN این است که بهجای پیدا کردن «دقیقترین» همسایهها، یک حدسِ خوب از نزدیکترینها را پیدا کند و بخشی از دقت را با سرعت معاوضه کند.
تکنیکهای اصلی در ANN:
- روشهای ایندکسگذاری (Indexing): از ساختارهایی مثل KD-Tree، Ball Tree و VP-Tree برای بخشبندی فضای برداری استفاده میشود تا ناحیهی جستوجو محدودتر شود و لازم نباشد کل فضا بررسی شود.
- روشهای هشکردن (Hashing): الگوریتمهایی مثل Locality-Sensitive Hashing (LSH) بردارهای مشابه را به «باکت»های یکسان نگاشت میکنند. نتیجه این است که فضای جستوجو کوچکتر میشود و فقط چند باکت مرتبط بررسی میشوند.
- خوشهبندی (Clustering): روشهایی مثل k-means بردارها را به چند خوشه تقسیم میکنند؛ در زمان جستوجو، بهجای اینکه کل دیتاست پیمایش شود، جستوجو داخل یک یا چند خوشهی مرتبط انجام میگیرد.
مزایا:
- برای دیتاستهای بزرگ، نسبت به k-NN دقیق، به شکل محسوسی سریعتر است
- بهخوبی مقیاسپذیر است و میتواند تا میلیاردها بردار را پوشش دهد
معایب:
- همیشه نزدیکترین همسایه دقیق را پیدا نمیکند
- خروجی به «تعادل سرعت/دقت» که تنظیم میکنید وابسته است
موارد استفاده:
موتورهای جستوجوی وب، سیستمهای پیشنهاددهندهی بزرگمقیاس و کاربردهای جستوجوی شباهتِ بلادرنگ (Real-time).
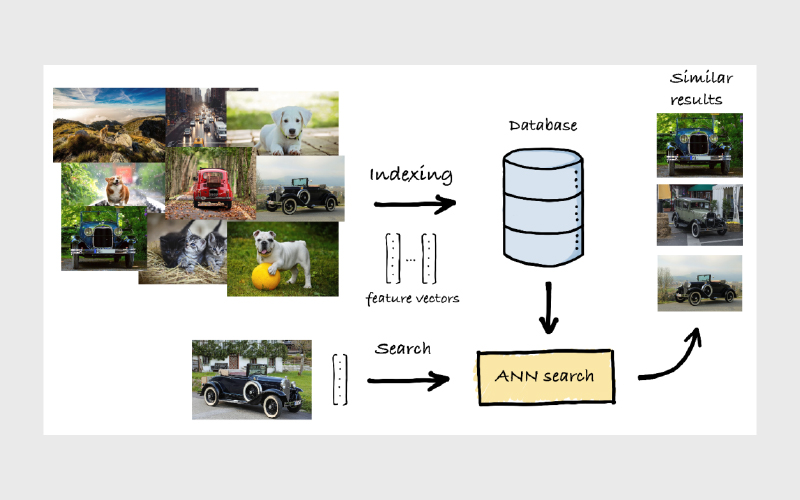
پیادهسازی عملی
در عمل، برای پیادهسازی جستوجوی شباهت لازم نیست همهچیز را از صفر بسازید. چند کتابخانه و فریمورک شناختهشده وجود دارند که این کار را خصوصا روی دیتاستهای بزرگ، سریعتر و قابلاعتمادتر میکنند:
- FAISS: کتابخانهای بهینهشده برای جستوجوی شباهت سریع و کارآمد روی دادههای حجیم.
- Annoy: کتابخانهای نوشتهشده با ++C بههمراه binding برای پایتون که برای جستوجوی سریع و کممصرف از نظر حافظه طراحی شده است.
- HNSW: یک الگوریتم (و معمولا کتابخانههای مبتنی بر آن) برای جستوجوی ANN که با ساختن یک گراف سلسلهمراتبی، امکان پیمایش موثر فضای برداری و پیدا کردن همسایههای نزدیک را فراهم میکند.

کاربردهای جستوجوی شباهت
جستوجوی شباهت به خاطر تواناییاش در پیدا کردن و مقایسه آیتمهای مشابه با سرعت و دقت بالا، در حوزههای مختلف کاربردهای گستردهای دارد. چند مورد مهم:
۱- سیستمهای پیشنهاددهنده
سیستمهای پیشنهاددهنده با تکیه بر جستوجوی شباهت، محصول/محتوا/خدماتی را پیشنهاد میدهند که با سلیقه و رفتار کاربر همخوانی دارد.
- تجارت الکترونیک: پیشنهاد محصولاتی مشابه آنچه کاربر دیده یا خریده است.
- سرویسهای استریم: پیشنهاد فیلم، سریال یا موسیقی بر اساس تاریخچه تماشا/گوشدادن.
- تبلیغات آنلاین: نمایش تبلیغاتی که با علایق کاربر (بر اساس رفتار مرور وب) مرتبطتر است.
۲- بازیابی تصویر و ویدئو
در دیتابیسهای بزرگ چندرسانهای، جستوجوی شباهت نقش کلیدی در پیدا کردن آیتمهای از نظر بصری مشابه دارد.
- CBIR (بازیابی تصویر مبتنی بر محتوا): پیدا کردن تصاویر مشابه یک تصویر ورودی بر اساس ویژگیهای بصری.
- پیشنهاد ویدئو: پیشنهاد ویدئوهای مشابه با توجه به تحلیل محتوای بصری ویدئوهایی که کاربر دیده است.
۳- پردازش زبان طبیعی (NLP)
در NLP، جستوجوی شباهت برای پیدا کردن متنهای هممعنا یا نزدیک از نظر مفهومی استفاده میشود.
- خوشهبندی اسناد: گروهبندی اسناد مشابه برای موضوعیابی یا دستهبندی.
- جستوجوی معنایی: بهتر کردن نتایج موتور جستوجو با فهم زمینه و معنای کوئری، نه صرفا تطابق کلیدواژه.
- کشف سرقت ادبی: شناسایی متنهای تکراری یا بسیار مشابه بین اسناد.
۴- کشف تقلب
برای شناسایی الگوها و ناهنجاریهایی که از رفتار عادی فاصله دارند، جستوجوی شباهت بسیار کاربردی است.
- تراکنشهای مالی: پیدا کردن تراکنشهای مشکوک که به الگوهای تقلب شناختهشده شباهت دارند.
- سرقت هویت: تشخیص تلاشهای ورود یا فعالیتهایی که مشابه الگوهای تقلب قبلی هستند.
۵- سلامت و ژنومیک
در پزشکی و تحقیقات ژنتیک، مقایسه دادههای بیمار و توالیهای ژنتیکی میتواند به تشخیص و پژوهش کمک کند.
- تصویربرداری پزشکی: مقایسه اسکنهای بیمار با نمونههای مشابه برای کمک به تشخیص.
- پژوهش ژنوم: پیدا کردن توالیهای ژنتیکی مشابه برای بررسی تنوعهای ژنتیکی و اثرات آنها.
چالشهای جستوجوی شباهت
جستوجوی شباهت در ظاهر ساده به نظر میرسد: «نزدیکترین بردارها را پیدا کن». اما در عمل، وقتی با دادههای واقعی و مقیاسهای بزرگ روبهرو میشویم، چالشهای مهمی خودش را نشان میدهد. از یک طرف، کوئریهای کاربران میتوانند مبهم و چندمعنا باشند و سیستم باید فراتر از تطابق سطحی، درک معنایی داشته باشد. از طرف دیگر، حجم دادهها در بسیاری از کاربردها بسیار بالاست و رسیدن به پاسخ سریع، بدون افت شدید دقت، نیازمند روشهای مقیاسپذیر و طراحی درست ایندکسها و الگوریتمهاست.
مدیریت کوئریهای مبهم و متنوع
یکی از چالشهای اصلی جستوجوی شباهت، ماهیت خودِ کوئریهاست. درخواستها میتوانند از عبارتهای بسیار کلی مثل «کفش» شروع شوند و تا آیتمهای بسیار دقیق مثل «Nike AF-1 LV8» پیش بروند. سیستم باید بتواند این ظرافتها را تشخیص دهد و بفهمد آیتمهای مختلف چه نسبتی با هم دارند. اینجا دیگر صرفِ تطابق کلیدواژه کافی نیست و به درک معنایی عمیقتری از کوئری نیاز داریم.
مشکلات مقیاسپذیری
چالش مهم دیگر، مقیاسپذیری است. در کاربردهای واقعی، معمولا با دیتاستهایی طرف هستیم که ممکن است میلیاردها آیتم داشته باشند. جستوجوی کارآمد در چنین حجمی از داده، به تکنیکهای پیشرفته و منابع محاسباتی قدرتمند نیاز دارد. سیستمهای دیتابیس سنتی که برای تطابق دقیق و نمایشهای نمادین طراحی شدهاند، معمولا در این سناریوها عملکرد خوبی ندارند.
جمعبندی
جستوجوی شباهت که با نام جستوجوی برداری (Vector Search) هم شناخته میشود در بسیاری از کاربردهای مدرن نقش محوری دارد. این رویکرد با تکیه بر امبدینگهای برداری و معیارهای فاصله دقیقتر کمک میکند آیتمها را نه صرفا بر اساس تطابق ظاهری یا کلیدواژه، بلکه بر پایه معنای مفهومی آنها پیدا و مقایسه کنیم.
نکات کلیدی این مقاله:
- درک نمایشهای برداری: تبدیل اشیا و مفاهیم دنیای واقعی به امبدینگ، معنا و ارتباطات عمیقتر را در قالب یک نمایش عددی ثبت میکند و مقایسه شباهت را ممکن میسازد.
- انتخاب معیار مناسب: انتخاب معیار فاصله درست (اقلیدسی، منهتن، کسینوسی، چبیشف) به نوع داده و نیاز سناریو بستگی دارد.
- اجرای جستوجوی شباهت: روشهایی مثل k-NN و ANN امکان پیدا کردن آیتمهای مشابه را در دیتاستهای بزرگ، به شکل دقیق یا تقریبی و کارآمد فراهم میکنند.
- کاربردهای گسترده: از سیستمهای پیشنهاددهنده و بازیابی تصویر/ویدئو گرفته تا NLP، کشف تقلب و حوزه سلامت، جستوجوی شباهت یک جزء کلیدی است.
برای اینکه واقعا از ظرفیت جستوجوی شباهت استفاده کنید، باید اصول پشت آن را بشناسید و بر اساس نیاز پروژه، ابزارها و تکنیکهای درست را انتخاب کنید. چه در حال ساخت یک سیستم پیشنهاددهنده باشید، چه یک سیستم بازیابی مبتنی بر محتوا، یا یک مکانیزم تشخیص تقلب، جستوجوی شباهت میتواند دقت و بهرهوری راهکار شما را به شکل محسوسی بهتر کند.
منابع
سوالات متداول
جستوجوی معمولی دنبال تطابق دقیق است (برابر، بازه، فیلتر). اما جستوجوی شباهت آیتمها را با امبدینگ نمایش میدهد و بر اساس فاصله/شباهت بین بردارها، نزدیکترین نتایج را بهصورت رتبهبندیشده برمیگرداند.
امبدینگ یک نمایش عددیِ فشرده از متن/تصویر/آیتم است که بخش مهمی از معنا و ویژگیها را در خودش نگه میدارد. به کمک امبدینگ میتوان شباهت را «محاسبهپذیر» کرد، چیزی که با کلیدواژه بهتنهایی همیشه قابل اتکا نیست.
به نوع داده و تعریف شما از شباهت بستگی دارد: اقلیدسی برای دادههای متراکم و هندسی، منهتن برای سناریوهای شبکهای یا اختلافهای مولفهای، کسینوسی برای متن و بردارهای پُربعد که جهت مهمتر از اندازه است و چبیشف وقتی بیشترین اختلاف در یک بُعد تعیینکننده باشد.
k-NN دقیق است چون با همهی بردارها مقایسه میکند، اما در دیتاست بزرگ کند میشود. ANN با ایندکسها/ساختارهای خاص، جستوجو را خیلی سریعتر میکند و معمولا کمی دقت را فدای سرعت میکند؛ برای مقیاسهای واقعی اغلب انتخاب عملیتر است.
FAISS برای مقیاس بزرگ و گزینههای متنوع ایندکسگذاری مناسب است. Annoy سادهتر و کممصرفتر است و برای نیازهای سبک جواب میدهد. HNSW (گرافمحور) معمولا تعادل خیلی خوبی بین سرعت و دقت در ANN ارائه میدهد و در بسیاری از پروژهها گزینه محبوبی است.


دیدگاهتان را بنویسید