
این روزها شاهد رشد چشمگیر مدلهای پایه چندوجهی (Multi-modality Foundation Models) هستیم. این مدلها قادرند انواع داده مثل متن، تصویر، ویدیو و صدا را درک کنند و وظایفی را انجام دهند که نیاز به ترکیب دانش از چند نوع داده دارند. اما تا حالا فکر کردهاید این مدلها دقیقا چطور کار میکنند؟ کلید درک یک مدل چندوجهی تصویر-متن این است که بفهمیم چطور بین دادههای مختلف نوعی همترازی یا «همراستاسازی» ایجاد میکند.
در این مقاله با استفاده از یک مدل ساده دووجهی متن–تصویر به نام CoCa، سازوکار درونی این مدلها را بررسی میکنیم. مدل CoCa طراحی شهودی و سادهای دارد و ایدههایش را از چند مدل چندوجهی دیگر وام گرفته است؛ به همین دلیل مثال خوبی برای درک مفاهیم اصلی به شمار میآید.
چرا به مدلهای متن–تصویر نیاز داریم؟
پیش از آنکه به این بپردازیم که چرا به مدلهای چندوجهی متن–تصویر نیاز داریم، بهتر است نگاهی بیندازیم به اینکه یک مدل تکوجهی چه کارهایی میتواند و چه کارهایی نمیتواند انجام دهد.
مدل مبتنی بر تصویر
مدلی که فقط با دادههای تصویری آموزش دیده، مثل ResNet، تنها از تصویر یاد میگیرد و میتواند وظایف پایهای درک تصویر را انجام دهد؛ مثلا در دستهبندی تصویر (Image Classification)، یک تصویر را در یکی از کلاسهای از پیش تعریفشده مثل «گربه» یا «سگ» طبقهبندی میکند.
مدل مبتنی بر متن
مدلی که فقط با دادههای متنی آموزش دیده، مثل Transformer، تنها از متن یاد میگیرد و میتواند وظایفی مثل پیشبینی کلمه بعدی بر اساس کلمات قبلی را انجام دهد.

کاربردهایی که مدلهای تکوجهی از پس آن برنمیآیند
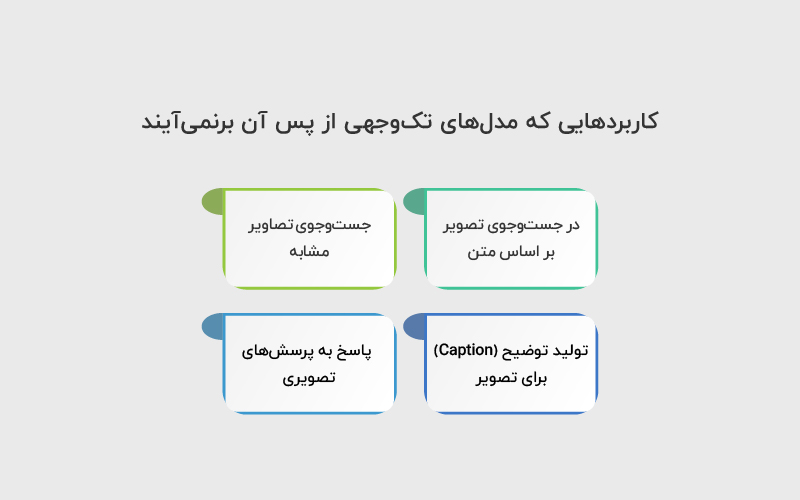
دو مدل تکوجهی بالا (یکی مخصوص تصویر و دیگری مخصوص متن) نمیتوانند از پس بعضی از وظایف برآیند. برای مثال، فرض کنید تصویری از دو سگ در حال دویدن داریم.
- در جستوجوی تصویر بر اساس متن
فرض کنید میخواهید تصاویری پیدا کنید که با عبارت «سگهایی که در حال دویدن هستند» مطابقت دارند. مدل مبتنی بر تصویر مثل ResNet فقط میتواند این تصویر را در دسته «سگ» قرار دهد اما اصلا ورودی متنی نمیپذیرد. بنابراین نمیتواند به پرسوجوی متنی پاسخ دهد یا تصاویر مرتبط با عبارت شما را پیدا کند.
- جستوجوی تصاویر مشابه
فرض کنید میخواهید با دادن همین تصویر، تصاویر مشابهی بیابید. بهترین کاری که یک مدل تکوجهی تصویر میتواند بکند این است که تصاویری از همان کلاس «سگ» را نمایش دهد اما نمیتواند دقیقتر عمل کند و تصاویری از «سگهای در حال دویدن» را پیدا کند.
- تولید توضیح (Caption) برای تصویر
اگر از مدل بخواهید بر اساس این تصویر جملهای توضیحی تولید کند مثلا «دو سگ در حال دویدن کنار هم روی شن»، هیچیک از مدلهای بالا از عهدهاش برنمیآیند. مدل تصویری فقط میتواند بگوید «سگ» و مدل متنی هم چون ورودیاش فقط متن است، تصویر را درک نمیکند.
- پاسخ به پرسشهای تصویری
در این حالت مدل باید با دریافت یک تصویر و یک پرسش متنی، پاسخ دهد. مثلا اگر تصویر بالا را به همراه سوال «چه کسی کنار سگ سمت چپ در حال دویدن است؟» بدهیم، پاسخ درست «سگ دیگر» است. اما هیچیک از مدلهای تکوجهی نمیتوانند چنین کاری کنند، چون نه مدل تصویری ورودی متنی میپذیرد و نه مدل متنی میتواند تصویر را تفسیر کند.
برای انجام چنین وظایفی، مدل باید هم تصویر و هم متن را بفهمد و بتواند این دو نوع داده را در یک فضای مشترک همتراز کند. به عبارت دیگر، مدل باید بداند که تصویر و توضیح متنی مربوط به آن، درباره یک مفهوم واحد هستند؛ مثلا «دو سگ در حال دویدن کنار هم».
این همراستاسازی باید در دو سطح انجام شود:
- سطح کلان (Global level): یعنی درک مفهوم کلی تصویر و متن، مثلا همان «دو سگ در حال دویدن کنار هم».
- سطح خرد (Local level): یعنی مدل بتواند بفهمد هر بخش از تصویر به چه چیزی اشاره دارد؛ مثلا این بخش مربوط به سگ اول است، آن بخش مربوط به سگ دوم و بخشی دیگر نشان میدهد که آنها در حال دویدناند. در متن هم باید درک کند که کلمات مربوط به چند سگ و فعل دویدن هستند.
چطور اطلاعات کلی (Global) تصویر و متن همتراز میشوند
نمودار زیر نشان میدهد که چطور میتوان اطلاعات سطح کلان و خرد (Global و Local) را هم برای تصویر و هم برای متن نمایش داد و چطور در سطح کلان میتوان بین تصویر و متن همترازی برقرار کرد. در ادامه، دقیقتر خواهیم دید منظور از این همترازی چیست.
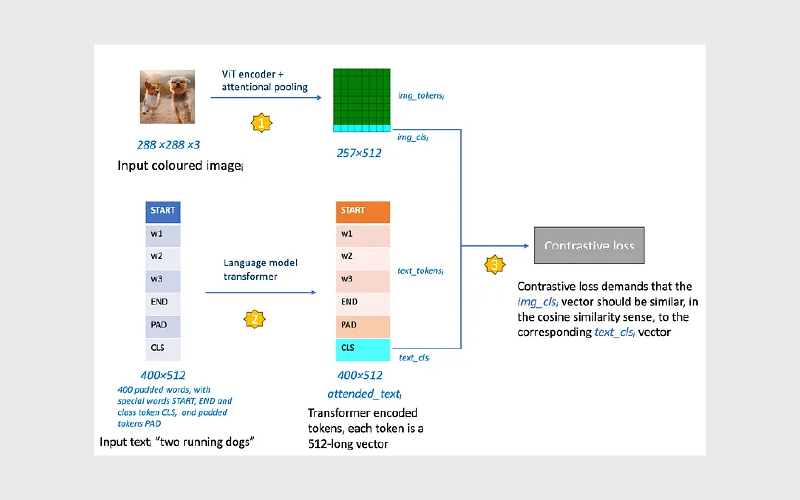
نمودار بالا نشان میدهد که در زمان آموزش، وقتی مدل یک جفت ورودی شامل تصویر و متن (imageᵢ, textᵢ) دریافت میکند، چه اتفاقی میافتد.
اندیس «i» نشان میدهد که این جفت، یکی از چندین جفت تصویر–متن موجود در یک mini-batch است که مدل در هر مرحله آموزش با آنها کار میکند.
گام ۱: پردازش تصویر
ورودی imageᵢ یک تصویر رنگی با اندازه ثابت ۲۸۸×۲۸۸ پیکسل و سه کانال رنگی RGB است.
این تصویر ابتدا وارد یک کدگذار Vision Transformer (ViT) میشود و سپس از یک بخش attention pooling عبور میکند. خروجی این دو مرحله، یک تنسور با ابعاد ۲۵۷×۵۱۲ است.
در ادامه مقاله جزئیات این تبدیل توضیح داده میشود اما فعلا کافی است بدانیم که این فرایند، تصویر را به ۲۵۶ پچ کوچک (Patch) تقسیم میکند، سپس یک پچ مخصوص کلاس (Class Patch) به انتهای فهرست اضافه میکند.
سپس، با استفاده از مکانیزم Attention، اطلاعات بین تمام پچها ترکیب میشود تا مدل بتواند درکی یکپارچه از تصویر پیدا کند.
مدل خروجی ۲۵۷×۵۱۲ را به دو بخش تقسیم میکند:
۱. img_tokensᵢ (ابعاد ۲۵۶×۵۱۲)
شامل ۲۵۶ پچ رمزگذاریشده تصویر است و بیانگر اطلاعات سطح خرد (Local) تصویر محسوب میشود.
۲. img_clsᵢ (ابعاد ۱×۵۱۲)
این ردیف آخر، همان پچ اضافهشده کلاس است و نماینده اطلاعات سطح کلان (Global) تصویر است. اهمیت این بردار در آن است که خلاصهای فشرده از کل تصویر ارائه میدهد؛ فارغ از اینکه تصویر به چند پچ تقسیم شده باشد.
در این مدل، تعداد پچها همیشه ۲۵۶ است اما اگر در آینده اندازه ورودی یا تعداد پچها تغییر کند، این بردار ثابت (img_clsᵢ) همچنان نقش خلاصه تصویر را حفظ خواهد کرد.
۳. چرا از ردیف آخر برای سطح کلان استفاده میشود؟
این انتخاب صرفا به دلیل سادگی در پیادهسازی انجام شده است. از نظر مفهومی، هر ردیفی میتواند نماینده اطلاعات سطح کلان باشد اما انتخاب ردیف آخر باعث میشود کار با دادهها در PyTorch سادهتر شود. در PyTorch، انتخاب یا حذف آخرین ردیف از یک تنسور، عملی بسیار متداول و سریع است؛ بنابراین این تصمیم جنبه عملیاتی و بهینهسازی در کدنویسی دارد، نه مفهومی.
گام ۲: پردازش متن
ورودی متنی textᵢ یک جمله پد شده (padded) است که حداکثر شامل ۳۹۷ کلمه میشود. عدد ۳۹۷ در اینجا یک مقدار دلخواه است و نشاندهنده حداکثر طول متنی است که مدل ما از آن پشتیبانی میکند. برای متونی که کمتر از ۳۹۷ کلمه دارند، کلمات پدینگ با نماد PAD در انتهای متن اصلی اضافه میشوند. سه کلمه خاص START، END و CLS نیز به جمله افزوده میشوند. توجه داشته باشید که این کلمات خاص دقیقا مانند سایر کلمات موجود در واژگان مدل در نظر گرفته میشوند.
برای مثال، پس از اضافه شدن کلمات خاص ذکرشده، جمله
“w₁ w₂ w₃”
به شکل زیر درمیآید:
“START w₁ w₂ w₃ PAD PAD … END CLS”.
در نتیجه، ورودی متنی دارای ۴۰۰ کلمه خواهد بود:
- کلمه START نشاندهنده آغاز متن است.
- کلمه END نشاندهنده پایان متن است.
- کلمه CLS نماینده اطلاعات کلی (global textual information) متن است.
توجه داشته باشید که ورودی متنی textᵢ یک تنسور با ابعاد ۴۰۰×۵۱۲ است، بنابراین یک جمله انگلیسی معمولی نیست. هر سطر از این تنسور، امبدینگ یک کلمه را نمایش میدهد. یک مدل امبدکننده واژه (word embedder) که بهصورت جداگانه آموزش دیده است، این امبدینگها را تولید میکند.
این امبدکننده واژه، شاخص واژگانی هر کلمه، چه کلمات معمولی مانند «two» و «dogs» و چه کلمات خاص مانند START، END، PAD و CLS را دریافت میکند و آن را به یک بردار ۵۱۲بعدی تبدیل میکند.
«شاخص واژگانی» یک عدد صحیح است که به هر کلمه در واژگان انگلیسی اختصاص داده شده است.
برای مثال، کلمه «two» شاخص ۱۲۳۴۵ دارد و کلمه «dogs» شاخص ۵۴۳۲۱. واژگان معمول زبان انگلیسی معمولا شامل حدود ۱۰۰هزار کلمه است.
یک کدگذار زبان (Language Model Encoder) این ورودی با ابعاد ۴۰۰×۵۱۲ را به یک خروجی با همان ابعاد ۴۰۰×۵۱۲ تبدیل میکند. توجه داشته باشید که یکسان بودن ابعاد ورودی و خروجی، بهویژه در بُعد ۵۱۲ ویژگی (feature dimension)، کاملا هدفمند است. این طراحی باعث میشود که خروجی این کدگذار بتواند مستقیما به ورودی یک کدگذار زبانی دیگر ارسال شود. در ادامه مقاله خواهید دید که این مدل چگونه از این ساختار زنجیرهای استفاده میکند.
اکنون این تنسور خروجی را attended_textᵢ مینامیم.
این کدگذار زبانی برای هر کلمه ورودی، در همان ترتیب، یک embedding تولید میکند. بنابراین هر سطر در attended_textᵢ نشاندهنده embedding متناظر با همان کلمه در جمله است.
این ماتریس ۴۰۰×۵۱۲ به دو بخش تقسیم میشود:
- ۳۹۹ سطر اول، با نام text_tokenᵢ و ابعاد ۳۹۹×۵۱۲، مربوط به کلمات واقعی جمله هستند و نمایانگر اطلاعات سطح خرد (local level) در متناند.
- سطر آخر، با نام text_clsᵢ و ابعاد ۱×۵۱۲، نشاندهنده اطلاعات سطح کلان (global level) متن است.
باز هم باید بر اهمیت این بردار ثابت تاکید کرد:
text_clsᵢ یک بردار ۵۱۲بعدی است که بدون توجه به طول جمله ورودی، اندازهاش همیشه ثابت میماند.
از آنجا که اندازه این بردار با اندازه بردار اطلاعات کلی تصویر (img_clsᵢ) برابر است، میتوان بهسادگی شباهت میان یک تصویر و یک جمله را با محاسبه حاصلضرب نقطهای (dot product) بین این دو بردار محاسبه کرد؛ همان روشی که میتوان حدس زد API امبدینگ متنی OpenAI نیز از آن استفاده میکند.
در این مدل، برخلاف بسیاری از رویکردها، از یک ترنسفورمر زبانی از پیش آموزشدادهشده و فریزشده (frozen pre-trained model) استفاده نمیشود؛ بلکه پارامترهای درون این ترنسفورمر در طول آموزش بهینهسازی میشوند تا مدل بتواند یاد بگیرد تصویر و متن را بهصورت همزمان همتراز کند.

گام ۳: سنجش شباهت بین تصویر و متن با Dot Product و Contrastive Loss
در این مرحله، تابع زیان کنتراستیو (Contrastive Loss) وظیفه ایجاد همترازی (Alignment) میان تنسور اطلاعات کلی تصویر img_clsᵢ و تنسور اطلاعات کلی متن text_clsᵢ را برعهده دارد.
هر دو این تنسورها بردارهایی با ابعاد ۱×۵۱۲ هستند.
همترازی میان این دو، بهصورت حاصلضرب نقطهای (Dot Product) بین آنها تعریف میشود. حاصلضرب نقطهای معیاری برای سنجش شباهت برداری (Vector Similarity) است؛ به این معنا که هرچه مقدار dot product بزرگتر باشد، دو بردار شباهت و همترازی بیشتری با یکدیگر دارند.
در این مدل، حاصلضرب نقطهای برای محاسبه شباهت میان img_clsᵢ و text_clsᵢ در ورودی (imageᵢ, textᵢ) استفاده میشود. اما علاوه بر تعیین اینکه کدام جفتها باید مشابه باشند، تابع زیان کنتراستیو باید مشخص کند کدام جفتها نباید مشابه باشند:
- بردار اطلاعات کلی تصویر img_clsᵢ مربوط به imageᵢ نباید با تنسورهای اطلاعات کلی متنی سایر جملات در جفتهای دیگر (imageᵢ, textᵢ) شباهت داشته باشد.
- به همین شکل، بردار اطلاعات کلی متن text_clsᵢ مربوط به textᵢ نباید با تنسورهای اطلاعات کلی تصویری سایر تصاویر در جفتهای دیگر (image, text) مشابه باشد.
محاسبه این عدم تشابهات برای تمام جفتهای (image, text) در کل دیتاست آموزشی، از نظر محاسباتی بسیار پرهزینه است. به همین دلیل، در عمل، Contrastive Loss تنها در سطح mini-batch محاسبه میشود.
در هر گام آموزش، یک mini-batch شامل N جفت ورودی است، بهصورت:
(image₁, text₁), (image₂, text₂), …, (image_N, text_N).
فرمول کامل تابع زیان کنتراستیو به شکل زیر است:
\( L_{\text{con}} =
-\frac{1}{N}
\left(
\underbrace{
\sum_{i=1}^{N}
\log
\frac{
\exp(\mathrm{img\_cls}_i \cdot \mathrm{text\_cls}_i / \sigma)
}{
\sum_{j=1}^{N}
\exp(\mathrm{img\_cls}_i \cdot \mathrm{text\_cls}_j / \sigma)
}
}_{\text{image-to-text}}
+
\underbrace{
\sum_{i=1}^{N}
\log
\frac{
\exp(\mathrm{text\_cls}_i \cdot \mathrm{img\_cls}_i / \sigma)
}{
\sum_{j=1}^{N}
\exp(\mathrm{text\_cls}_i \cdot \mathrm{img\_cls}_j / \sigma)
}
}_{\text{text-to-image}}
\right)\)
در فرمول بالا:
- img_clsᵢ بردار اطلاعات سطح کلان تصویر است که از تصویر موجود در جفت (imageᵢ, textᵢ) استخراج میشود.
- text_clsᵢ بردار اطلاعات سطح کلان متن است که از متن موجود در همان جفت (imageᵢ, textᵢ) بهدست میآید.
- “·” عملگر حاصلضرب نقطهای (dot product) بین دو بردار است.
- “exp” تابع نمایی را نشان میدهد.
چرا اینجا از تابع نمایی استفاده میشود؟
تابع نمایی به تغییرات کوچک در ورودی بسیار حساس است.
برای مثال، مقدار exp(5) برابر با ۱۴۸ است، در حالی که exp(5.1) برابر با ۱۶۴ میشود، یعنی فقط با ۰.۱ اختلاف در ورودی، خروجی ۱۶ واحد تغییر میکند. بنابراین، استفاده از تابع نمایی باعث میشود مدل نسبت به تفاوتهای جزئی در میزان شباهت بردارها حساستر شود.
- σ یک فراپارامتر (hyper-parameter) است که معمولا دما (temperature) نامیده میشود. این پارامتر تعیین میکند که مدل تا چه حد نسبت به تفاوتهای شباهت حساس باشد. اگر مقدار σ خیلی بزرگ باشد (نزدیک به بینهایت)، کسر داخل تابع لگاریتم تقریبا به ۱/N میل میکند؛ یعنی تابع زیان، دیگر به شباهت بردارها حساس نخواهد بود. در مقابل، هرچه مقدار σ کوچکتر باشد، مدل به اختلافهای کوچک در شباهت حساستر میشود. در نتیجه، تابع نمایی حساسیت را افزایش میدهد و پارامتر σ شدت این حساسیت را کنترل میکند.
- “log” همان تابع لگاریتم است. از آن برای جلوگیری از سرریز عددی (numeric overflow) استفاده میشود؛ زیرا توابع نمایی تمایل دارند مقادیر بسیار بزرگی تولید کنند و لگاریتم این مقادیر را در مقیاس کوچکتری نگه میدارد.
تابع زیان کنتراستیو شامل دو بخش است:
- بخش تصویر به متن (image-to-text term)
- در بخش image-to-text، مدل تلاش میکند شباهت بین بردارهای اطلاعات کلی تصویر (img_clsᵢ) و متن (text_clsᵢ) در جفت صحیح (imageᵢ, textᵢ) را بیشتر از مجموع شباهتهای بین همان تصویر (img_clsᵢ) و تمام متون دیگر در mini-batch کند. به عبارت دیگر، مدل باید یاد بگیرد که تصویر و متن مربوط به هم، شباهت بیشتری از سایر ترکیبها داشته باشند.
- هدف نهایی، بیشینه کردن مقدار term تصویر به متن است تا شباهت بین جفتهای درست زیاد و شباهت بین جفتهای نادرست کم شود. بهصورت معادل، میتوان منفی این مقدار را کمینه کرد که دقیقا همان کاری است که در تعریف تابع زیان انجام میشود.
- بخش متن به تصویر (text-to-image term)
- بخش دوم یعنی text-to-image term ساختاری مشابه دارد، با این تفاوت که جهت رابطه برعکس است؛ یعنی شباهت بین متن و تصاویر mini-batch بررسی میشود.
- نکته جالب اینجاست که درون تابع لگاریتم، هر دو بخش (image-to-text و text-to-image) صورت یکسانی دارند، زیرا برای دو بردار a و b، همیشه aᵀb = bᵀa است اما مخرجها (denominators) متفاوت هستند.
چرا دو بخش مجزا برای image-to-text و text-to-image وجود دارد؟
زیرا حتی اگر شباهت بین imageᵢ و textᵢ برابر با شباهت بین textᵢ و imageᵢ باشد (بهدلیل تقارن حاصلضرب نقطهای)، دو رویکرد متفاوت برای سنجش ناشباهتها (dis-similarities) وجود دارد:
- در حالت اول، تصویر imageᵢ ثابت نگه داشته میشود و dot product بین آن و تمام متون موجود در mini-batch محاسبه میشود؛ این همان بخش image-to-text است.
- در حالت دوم، متن textᵢ ثابت نگه داشته میشود و dot product بین آن و تمام تصاویر موجود در mini-batch محاسبه میشود؛ این همان بخش text-to-image است.
این مدل همتراز در سطح کلان (Global) چه کارهایی میتواند انجام دهد؟
مدل متن–تصویر که با استفاده از تابع زیان کنتراستیو (Contrastive Loss) آموزش دیده، میتواند مجموعهای از وظایف زیر را انجام دهد:
۱- جستوجوی تصویر بر اساس متن
برای یک پرسوجوی متنی مانند:
«دو سگ در حال دویدن»
ابتدا مدل زبانی (language-model transformer) را برای تولید تنسور اطلاعات کلی متن (global level text information tensor) به کار میبریم. سپس از این تنسور بهعنوان کلید جستوجو (search key) در یک پایگاه داده شامل تنسورهای اطلاعات کلی تصاویر استفاده میکنیم تا تصاویری را بیابیم که بیشترین شباهت را با متن ورودی دارند. مبنای رتبهبندی نتایج، شباهت حاصلضرب نقطهای (dot-product similarity) بین بردارهای تصویر و متن است.
۲- جستوجوی تصاویر مشابه
برای یک تصویر ورودی (مثلا تصویر دو سگ در حال دویدن)، از بخش ViT + Attention Pooling استفاده میکنیم تا تنسور اطلاعات کلی تصویر را بهدست آوریم. سپس از این بردار به عنوان کلید جستوجو در همان پایگاه داده تصویری استفاده میشود تا تصاویر مشابه از نظر محتوایی بازیابی شوند.
۳- دستهبندی تصویر
در یک مسئله دستهبندی تصویر، مجموعهای از کلاسها از پیش تعریف شدهاند، برای مثال:
“dog”، “cat”، “tennis racket”
برای طبقهبندی یک تصویر ورودی:
- ابتدا با استفاده از مولفه ViT + Attention Pooling، تنسور اطلاعات کلی تصویر مربوط به آن تصویر را تولید میکنیم.
- سپس برای هر کلاس، با استفاده از یک الگوی جمله (template)، جملهای میسازیم.
مثلا قالب زیر را در نظر بگیر:
“this is a picture of <class>”
در نتیجه:
- برای کلاس dog جمله “This is a picture of a dog”
- و برای کلاس cat جمله “This is a picture of a cat” ساخته میشود.
حالا برای هر جمله، با کمک مدل زبانی، تنسور اطلاعات کلی متن مربوط به آن تولید میشود.
در نهایت، تصویر ورودی در کلاسی قرار میگیرد که تنسور اطلاعات کلی متنی آن، بیشترین شباهت (در معنای dot product) را با تنسور اطلاعات کلی تصویر داشته باشد.
به این ترتیب، مدل میتواند جستوجوی تصویر با متن، یافتن تصاویر مشابه و حتی دستهبندی تصاویر جدید را تنها بر اساس بردارهای همتراز (aligned embeddings) انجام دهد؛ بدون نیاز به آموزش جداگانه برای هر وظیفه.
چگونه از قابلیت تولید کپشن برای تصویر پشتیبانی کنیم؟
وظیفه توضیحنویسی تصویر (Image Captioning) به این صورت است که مدل تنها با دریافت یک تصویر، بتواند یک توضیح متنی تولید کند. مدل فعلی ما که فقط در سطح کلان (Global) تصویر و متن را همتراز میکند، هنوز قادر به انجام این کار نیست. برای اضافهکردن این قابلیت، باید اطلاعات سطح خرد (Local level) تصویر و متن را نیز با یکدیگر همتراز (align) کنیم.
یک کپشن در واقع یک جمله است. اما مدل چطور میتواند بر اساس تصویر ورودی، این جمله (caption) را پیشبینی کند؟ در این مدل، برای آموزش، به جمله کلمات ویژهای اضافه میکنیم؛ مثلا:
“START two running dogs END”
در این حالت، مدل بهصورت زیر آموزش میبیند:
- با داشتن تصویر و اولین کلمه “START”، مدل کلمه بعدی “two” را پیشبینی میکند.
- مزیت وجود کلمهی ویژه START این است که همیشه در ابتدای جمله وجود دارد و مدل میتواند آن را بهعنوان نقطه شروع پیشبینی در نظر بگیرد.
- سپس با داشتن تصویر و کلمات پیشبینیشده تا این لحظه، یعنی “START two”، مدل کلمه بعدی “running” را پیشبینی میکند.
- در مرحله بعد، با داشتن تصویر و کلمات “START two running”، مدل کلمه بعدی “dogs” را پیشبینی میکند.
- در نهایت، با داشتن تصویر و کلمات “START two running dogs”، مدل کلمه پایانی “END” را پیشبینی میکند.
- به این ترتیب، مدل میآموزد که با استفاده از تصویر و کلمات تولیدشده قبلی، بهصورت گامبهگام جمله کپشن را کامل کند.
پیشبینی احتمال کلمات در واژگان
در یادگیری ماشین، پیشبینی کلمه بعدی معمولا به این صورت انجام میشود که مدل برای تمام کلمات موجود در واژگان، یک آرایه احتمال تولید میکند. در این آرایه، مقدار احتمالِ کلمه درست باید بیشتر از تمام کلمات دیگر باشد.
در وظیفه توضیحنویسی تصویر (image captioning) و برای هر جفت (imageᵢ, textᵢ)، هدف این است که مدل بتواند احتمال کلمه بعدی را بر اساس دو عامل پیشبینی کند:
- تمام کلمات پیشبینیشده قبلی
- و اطلاعات سطح خرد تصویر (local level image information) که از img_tokensᵢ بهدست میآید.
از نظر نمادگذاری، این پیشبینیکننده احتمال کلمه به صورت زیر تعریف میشود:
\( P\left(w_t \mid START, w_1, w_2, \ldots, w_{t-1}, \mathrm{img\_tokens}_i \right)
\quad \text{where } 2 \le t \le T\)
در این رابطه:
- textᵢ همان متن اصلی است که کلمات ویژه START و END به آن اضافه شدهاند، برای مثال:
“START w₁ w₂ w₃ END”
- T طول جمله یا همان تعداد کلمات موجود در textᵢ است.
- img_tokensᵢ تنسور اطلاعات سطح خرد تصویر (local level image information tensor) است که توسط مولفه ViT + Attention Pooling تولید میشود.
شبکه عصبی ما چگونه پیشبینیکننده احتمال کلمه فوق را پیادهسازی میکند؟
نمودار زیر ادامه نمودار قبلی است و نشان میدهد پیشبینیکننده احتمال کلمه که در بالا تعریف شد، چگونه در شبکه عصبی پیادهسازی میشود.
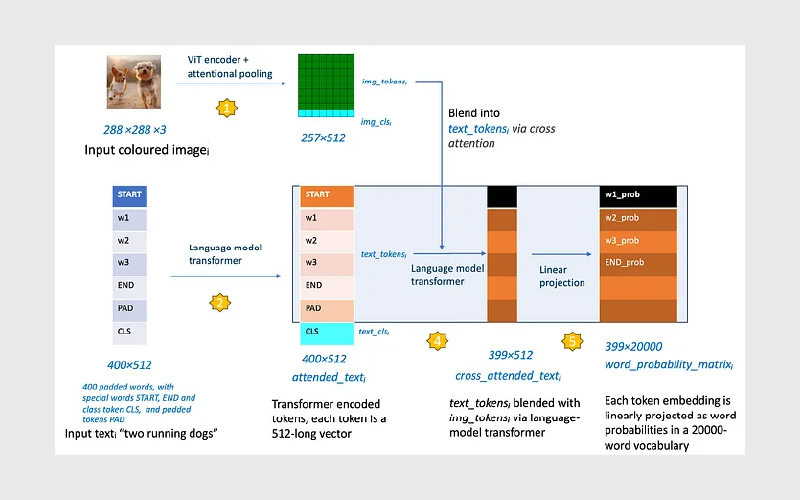
این شکل برای صرفهجویی در فضا، گام ۳ (محاسبه Contrastive Loss) را از نمودار قبلی حذف کرده است؛ اما توجه داشته باشید که گام ۳ همچنان در مدل وجود دارد و زیان کنتراستیو را تولید میکند.
گام ۴: همترازی محلی تصویر و متن با Cross-Attention
همان ترنسفورمر مدل زبانی، تنسور اطلاعات سطح خرد متن یعنی text_tokensᵢ با ابعاد ۳۹۹×۵۱۲ (بهجز سطر مربوط به کلمه CLS) را به تنسوری جدید به نام cross_attended_textᵢ با همان ابعاد تبدیل میکند.
در طول این تبدیل، تنسور اطلاعات سطح خرد تصویر یعنی img_tokensᵢ از طریق Cross-Attention در تنسور خروجی ادغام (blend) میشود. این همان سازوکاری است که همترازی بین اطلاعات سطح خرد متن و سطح خرد تصویر را برقرار میکند.
اگر به خاطر داشته باشید، در Cross-Attention، محاسبه اصلی نیز بر پایه حاصلضرب نقطهای (dot-product) است؛ بنابراین این همترازی بین تفسیر محلی تصویر و متن قابل اتکاتر و اقناعکنندهتر میشود.
توجه کنید که گام ۴ دومین فراخوانیِ ترنسفورمر زبانی است.
تنسور ورودی به این فراخوانی دوم، ۳۹۹ سطر اولِ text_tokensᵢ است؛ زیرا به کلمه CLS در فرایند تولید کپشن نیازی نیست. یک ترنسفورمر زبانی میتواند ورودیهایی با طولهای متفاوت بپذیرد؛ درونیسازیِ مدل، این ورودیهای با طول متغیر را به طول ثابت pad میکند.
برای برجستهکردن این نکته که شکل تنسور ورودی–خروجیِ فراخوانی دومِ کدگذار زبانی، ۳۹۹×۵۱۲ است، در شکل از یک کادر (box) برای محصور کردن این فراخوانی دوم و پروژکشن خطی پاییندستیاش استفاده شده است.
همچنین توجه کنید که در فراخوانی دومِ مدل زبانی، یک ورودی دیگر نیز وجود دارد: img_tokensᵢ.
این موضوع منطقی است؛ زیرا ترنسفورمر زبانی طوری آموزش داده شده که یک تنسور اختیاری برای Cross-Attention را بپذیرد.
در فراخوانی اول، این تنسور Cross-Attention روی null تنظیم میشود؛ بنابراین تمام عملیاتهای Cross-Attention در ترنسفورمر نادیده گرفته میشوند.
در فراخوانی دوم، این تنسور روی img_tokensᵢ قرار میگیرد و به این ترتیب تمام عملیاتهای Cross-Attention فعال میشوند.
این نمودار همچنین نحوه استفاده آموزشی از encoder مدل زبانی را از طریق فراخوانی اول و دوم نشان میدهد.
گام ۵: تولید ماتریس احتمال کلمات با فرافکنی خطی
تنسور cross_attended_textᵢ با ابعاد ۳۹۹×۵۱۲ بهصورت خطی (Linear Projection) به یک word_probability_matrixᵢ با ابعاد ۳۹۹×۲۰۰۰۰ نگاشت میشود. عدد ۲۰۰۰۰ یک مقدار دلخواه و نشاندهنده اندازه واژگان (vocabulary size) است. در این لایه فرافکنی خطی، پارامترهای قابلآموزش وجود دارد.
مقادیر هر سطر در word_probability_matrixᵢ مثل w₁_prob، w₂_prob به گونهای نُرمالسازی میشوند که در بازه [۰، ۱] قرار گیرند و مجموعشان برابر ۱ باشد تا بتوان هر سطر را بهعنوان بردار احتمالات پیشبینیشده برای هر ۲۰۰۰۰ کلمه واژگان تفسیر کرد.
یک مشاهده مهم این است که در ماتریس word_probability_matrixᵢ،
سطر اول بهعنوان احتمالهای کلمات برای w₁ تفسیر میشود، با توجه به کلمه آغازین START،
که خود اولین سطر در تنسور cross_attended_textᵢ است.
سطر دوم بیانگر احتمالهای w₂ با توجه به کلمات START و w₁ است.
و سطر سوم احتمالهای w₃ را با توجه به START، w₁ و w₂ نشان میدهد.
این همترازی یکبهیک بین تنسور ورودی و خروجی، در واقع مکانیزم پیشبینی کلمه بعدی (Next-Word Prediction) را بر اساس تمام کلمات قبلی پیادهسازی میکند.
اما منظور از عبارت «بهعنوان احتمالهای کلمات برای w₁ تفسیر میشود» چیست؟
این عبارت در زمینه یک تابع زیان جدید به نام Caption Loss معنا پیدا میکند؛ تابعی که میزان دقت مدل در پیشبینی کلمات را اندازهگیری میکند.
تابع Caption Loss از آنتروپی متقاطع (Cross-Entropy) میان بردار احتمال پیشبینیشده هر کلمه و کلمه واقعی (Ground Truth) استفاده میکند تا دقت پیشبینی را بسنجد. هدف ما در آموزش این است که این دقت را بیشینه کنیم، یا بهصورت معادل، منفی آن را کمینه کنیم.
به عنوان مثال، در مورد w₁_prob که یک بردار ۲۰۰۰۰بعدی است (هر ورودیاش مقداری بین ۰ و ۱ دارد و مجموع آنها ۱ است)، تابع آنتروپی متقاطع الزام میکند که ورودی متناظر با کلمه درست (مثلا “two”) مقدار بالایی داشته باشد؛ چون با توجه به اطلاعات سطح خرد تصویر (img_tokensᵢ) و کلمه شروع “START”، مدل باید یاد بگیرد که کلمه بعدی “two” را با احتمال بالا پیشبینی کند.
زیان آنتروپی متقاطع برای یک کلمه پیشبینیشده
نمودار زیر نشان میدهد که چگونه بردار احتمال کلمه پیشبینیشده w₁_prob، با روش کدگذاری وانهات (one-hot encoding) کلمه واقعی “two” مقایسه میشود تا مدل یاد بگیرد مقدار مربوط به کلمه “two” در w₁_prob بزرگتر از سایر مقادیر باشد. بهعبارت دیگر، این یعنی مدل باید در این موقعیت، کلمه “two” را پیشبینی کند.
در نمایش one-hot encoding برای کلمهی “two”، خانه مربوط به کلمه “two” مقدار ۱ دارد و تمام خانههای دیگر مقدار ۰ دارند.
در مقابل، در بردار احتمال پیشبینیشده w₁_prob، مقادیر عددی تصادفی (که در شکل نشان داده شدهاند) بیانگر خروجیهایی هستند که توسط ترنسفورمر مدل زبانی تولید شدهاند.
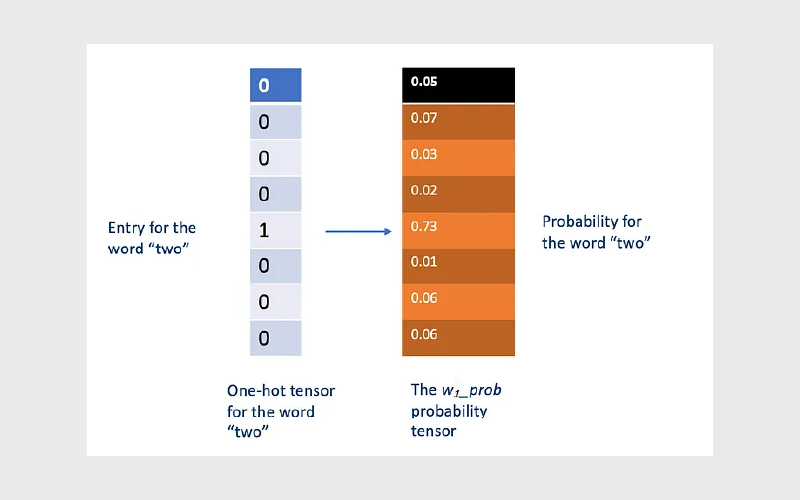
آنتروپی متقاطع (Cross-Entropy) برای کلمهی w₁ در جملهی textᵢ بهصورت زیر تعریف میشود:
که در آن j روی تمام ورودیهای بردار one-hot واقعی و بردار احتمال کلمه تکرار میشود.
\( L_{w_1}^{(i)} = – \sum_{j=1}^{20000}
w_{1\_\text{one\_hot},\,j} \; \log\left(w_{1\_\text{prob},\,j}\right)\)
توجه داشته باشید که زیان بالا برای یک کلمه در جفت (imageᵢ, textᵢ) است، به همین دلیل دارای نمای بالای “i” است.
با تعریف زیان کپشن برای یک کلمه، آنتروپی متقاطع برای کل جمله در textᵢ برابر است با مجموع آنتروپی متقاطع تمام ۳۹۹ کلمه آن:
\( L^{(i)} = \sum_{t=1}^{399} L_{w_t}^{(i)}\)
و زیان کپشن برای کل mini-batch با N جفت (imageₖ, textₖ)، که در آن k عددی بین ۱ و N است، بهصورت زیر است:
\( L_{\mathrm{cap}} = \sum_{k=1}^{N} L^{(k)}\)
تمام کلمات بهصورت همزمان پیشبینی میشوند
حال به گام ۵ در نمودار قبلی برگردیم. اکنون میتوان دید که تمام کلمات توضیح (caption) بهطور همزمان تولید میشوند:
- سطر اول در word_probability_matrixᵢ نمایشدهنده P(w₁|START, img_tokensᵢ) است.
- سطر دوم نمایشدهنده P(w₂|START, w₁, img_tokensᵢ) است.
- سطر سوم نمایشدهنده P(w₃|START, w₁, w₂, img_tokensᵢ) است.
و به همین ترتیب ادامه دارد.
به استفاده از واژه “produced” دقت کنید.
در اینجا در مورد زیان آموزش مدل (training loss) صحبت میکنیم، نه فرایند استنتاج مدل (inference). در زمان آموزش، احتمال تمام کلمات خروجی بهصورت همزمان و یکباره محاسبه میشود اما در زمان استنتاج (که بعدا توضیح داده خواهد شد)، کلمات خروجی بهصورت گامبهگام و بازگشتی (recursive) پیشبینی میشوند.
زیان کامل (Full Loss)
تابع زیان کلی مدل ما ترکیب خطی از دو بخش است:
- زیان کنتراستیو (Contrastive Loss)
- زیان کپشن (Caption Loss)
\( \mathcal{L}_{\mathrm{CoCa}}
= \lambda_{\mathrm{Con}} \cdot \mathcal{L}_{\mathrm{Con}}
+ \lambda_{\mathrm{Cap}} \cdot \mathcal{L}_{\mathrm{Cap}}\)
دو ضریب λ پارامترهای اَبَرتنظیم (hyper-parameters) هستند که برای تنظیم وزن میان این دو مولفه زیان به کار میروند.
تولید کپشن تصویر: استنتاج مدل
اکنون میتوان دید که این مدل، که با زیان کامل (Full Loss) آموزش داده شده است، چگونه میتواند برای یک تصویر کپشن تولید کند:
۱. از مولفه ViT + Attention Pooling برای تولید تنسورهای اطلاعات سطح خرد تصویر (local level image information tensors) از تصویر ورودی استفاده میشود.
۲. پیشوند کپشن (caption prefix) ساخته میشود که در ابتدا فقط شامل کلمه START است.
۳. ترنسفورمر مدل زبانی (language-model transformer) دو بار اجرا میشود؛ بار اول برای تولید attended_text و بار دوم برای تولید cross_attended_text. سپس با یک فرافکنی خطی (linear projection)، احتمالات کلمات تولید میشوند تا مدل بتواند کلمهی بعدی را بر اساس پیشوند فعلی کپشن پیشبینی کند. این کلمات پیشبینیشده را predicted_w₁، predicted_w₂ مینامیم. توجه داشته باشید که این دو کلمه از دو اجرای جداگانه از گام ۳ بهدست میآیند.
۴. کلمهی پیشبینیشده به پیشوند کپشن اضافه میشود.
۵. گامهای ۳ و ۴ بهصورت بازگشتی (recursive) تکرار میشوند تا زمانی که مدل کلمهی END را پیشبینی کند.
پدینگ
توجه داشته باشید که ترنسفورمر مدل زبانی (language-model transformer) تنها ورودیهایی با طول ثابت ۴۰۰ کلمه را میپذیرد. بنابراین، در ابتدای فرایند تولید کپشن، ورودیهای مدل شامل تعداد زیادی کلمه پد (PAD) خواهند بود.
برای مثال:
- جمله ورودی اول به شکل “START PAD … PAD” است،
- جمله دوم به شکل “START predicted_w₁ PAD … PAD”،
- جمله سوم به شکل “START predicted_w₁ predicted_w₂ PAD … PAD” و به همین ترتیب ادامه پیدا میکند.
بهعبارت دیگر، در هر مرحله جمله بهگونهای پد میشود که همیشه شامل ۳۹۹ کلمه باشد قبل از آنکه به ترنسفورمر مدل زبانی ارسال شود.
خروجی ترنسفورمر مدل زبانی (پس از دو بار اجرا) یک ماتریس احتمال کلمه با ابعاد ۳۹۹×۲۰۰۰۰ است.
در هر بار اجرا، فقط یک سطر از این ماتریس برای پیدا کردن بیشترین احتمال کلمهی بعدی و سپس تعیین کلمه واقعی بعدی استفاده میشود. سایر سطرهای این ماتریس ۳۹۹×۲۰۰۰۰ در آن مرحله مورد استفاده قرار نمیگیرند.
روشهایی برای بهینهسازی این فرایند وجود دارد اما در این مقاله تنها بر درک مفهوم کلی تمرکز داریم و به جزئیات بهینهسازی نمیپردازیم.
چرا برای پشتیبانی از توضیحنویسی تصویر از یک کدگذار مدل زبانی استفاده میکنیم؟
مدل CoCa از یک کدگذار مدل زبانی (language-model encoder) استفاده میکند و برای پشتیبانی از تولید کپشن تصویر، این کدگذار را دو بار فراخوانی میکند.
سوال اینجاست: چرا باید وارد چنین پیچیدگیای شد؟
به بیان دیگر، آیا نمیتوان مدلی طراحی کرد که تصویر را بهعنوان ورودی بگیرد و مستقیما یک جمله را بهعنوان خروجی تولید کند؟
از نظر تئوری، چنین مدلی ممکن است؛ اما از آنجا که کپشن تصاویر طولهای متفاوتی دارند، یک شبکه معمولی با خروجیِ با طول ثابت مجبور میشود تمام کلمات کپشن را بهصورت یکجا پیشبینی کند و برای کپشنهای کوتاهتر از پدینگ (padding) استفاده کند.
این کار بسیار دشوار است؛ زیرا دادههای آموزشی شامل جفتهای (image, caption) به اندازه کافی فراوان نیستند. در مقابل، کدگذار مدل زبانی از یک مکانیزم پیشبینی بازگشتی (recursive prediction) استفاده میکند؛ یعنی پیشبینی کلمه بعدی به تمام کلمات پیشبینیشده قبلی وابسته است.
این کدگذار میتواند ابتدا با دادههای متنی خالص که بهوفور در دسترساند، پیشآموزش (pre-train) داده شود و سپس با دادههای (image, caption)، مانند کاری که CoCa انجام میدهد، فاینتیون (fine-tune) شود. چنین الگوی آموزشیای، در عمل شانس موفقیت بسیار بیشتری دارد.
آموزش مدل (Model Training)
برای بهدست آوردن یک مدل تولید کپشن تصویر، لازم است مدل را دوباره با یک دیتاست شامل جفتهای (image, caption) آموزش دهیم.

چگونه از پاسخگویی به پرسشهای تصویری پشتیبانی کنیم؟
پس از آنکه نحوه کار تولید کپشن تصویر را درک کردیم، فهم سازوکار پاسخگویی به پرسشهای تصویری سادهتر میشود:
- در تولید کپشن تصویر، ورودی شامل تصویر و پیشوند متنی “START” است.
- در پاسخگویی به پرسش تصویری، ورودی شامل تصویر و سوال بهعنوان پیشوند متنی است.
البته یک ظرافت در مورد سطرهای ماتریس احتمال کلمات پیشبینیشده وجود دارد، زیرا کلمات مربوط به سوال باید نادیده گرفته شوند؛ اما احتمالا با صرف کمی زمان، میتوانید منطق آن را بهخوبی درک کنید.
توجه داشته باشید که برای بهدست آوردن یک مدل پاسخگویی به پرسشهای تصویری، باید کل مدل دوباره آموزش داده شود، آن هم با یک مجموعهداده جدید شامل سهتاییهای (image, question, answer).
مدلهای پایه (Foundation Models)
اکنون میبینیم که مدل ما پس از آموزش، میتواند بهصورت آماده (out of the box) وظایف مختلفی را انجام دهد، یا برای انجام وظایف جدید دوباره آموزش داده شود.
به همین دلیل به آن مدل پایه گفته میشود؛ زیرا یک مدل پایه یا نیمهآماده را فراهم میکند که میتواند بهعنوان نقطه شروع برای وظایف پاییندستی (downstream tasks) مختلف مورد استفاده قرار گیرد.
کدگذار ViT و Attention Pooling
اکنون که بخش عمدهای از مدل توضیح داده شد، به سراغ آخرین قطعه میرویم: اینکه مدل چگونه با استفاده از کدگذار ViT و Attention Pooling، تنسورهای اطلاعات تصویری در سطح کلان و سطح خرد را تولید میکند.
کدگذار ViT
کدگذار ViT یک تصویر با اندازه ثابت را به مجموعهای از پچها (patches) تقسیم میکند و هر پچ را بهصورت جداگانه رمزگذاری (encode) میکند. نمودار زیر نشان میدهد که کدگذار ViT چگونه پچهای تصویر را بهصورت رمزگذاریشده تولید میکند.
توجه داشته باشید که در اینجا اندیس i (که قبلا در نمادهایی مثل img_tokensᵢ استفاده میشد) نادیده گرفته شده است. دلیلش این است که در بخشهای قبلی لازم بود درباره تنسورها در قالب mini-batch صحبت کنیم؛ چون توابع زیان در سطح mini-batch تعریف میشوند. اما در اینجا دیگر نیازی به صحبت درباره mini-batchها نیست.

کدگذار ViT فریز میشود
توجه داشته باشید که پارامترهای کدگذار ViT در طول فرایند رمزگذاری پچهای تصویر فریز (frozen) هستند؛ بنابراین هیچ پارامتر قابلآموزشی در کدگذار ViT وجود ندارد.
این سوال مطرح میشود که چرا ترنسفورمر مدل زبانی که قبلا معرفی شد فریز نشده و دارای پارامترهای قابلآموزش است، اما کدگذار ViT در اینجا فریز شده است؟ به نظر میرسد نویسنده مقاله استفاده از یک ترنسفورمر زبانی فریزشده را نیز امتحان کرده اما نتیجه به اندازه نسخه قابلآموزش خوب نبوده است.
میتوان این انتخابِ فریز یا غیرفریز بودن را عمیقتر بررسی کرد.
برای همتراز کردن دو مجموعه بردار، یکی حاصل از کدگذار ViT و دیگری حاصل از ترنسفورمر مدل زبانی، کافی است یکی از بخشهای مدل که یکی از این مجموعهبردارها را تولید میکند ثابت نگه داشته شود و به بهینهساز اجازه داده شود پارامترهای بخش دیگر را که مجموعهبردار دوم را تولید میکند، تنظیم کند. لزومی ندارد هر دو مولفه مدل بهطور همزمان تغییر کنند.
با فریز کردن بخشی از مدل، کار بهینهساز سادهتر میشود، زیرا تعداد پارامترهای قابلآموزش کاهش مییابد و فرایند بهینهسازی پایدارتر و قابلکنترلتر خواهد بود.
Attention Pooling پارامترهای قابلآموزش را با پچهای رمزگذاریشدهی تصویر ترکیب میکند
گام بعدی، یعنی Attention Pooling، خروجی encoded_img_patches را با تعدادی پارامتر قابلآموزش مدل ترکیب میکند. این رویکرد یکی از روشهای بسیار رایج در طراحی معماری شبکههای عصبی برای استفاده مجدد از encoderهای آماده (off-the-shelf) است:
encoder را بهصورت فریزشده استفاده میکنیم و سپس با اضافهکردن لایههای قابلآموزش در مدل خودمان، خروجی encoder فریزشده را با سایر بخشهای شبکه ادغام میکنیم. نمودار زیر نشان میدهد که Attention Pooling چگونه این فرایند ترکیب را انجام میدهد.
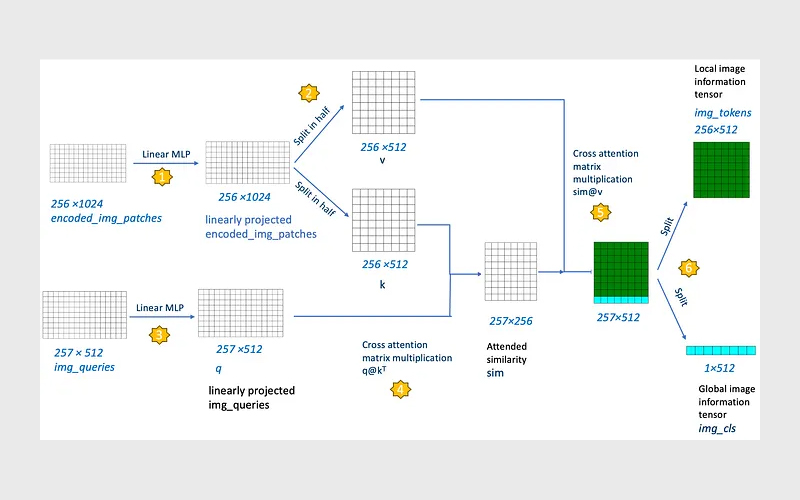
گام ۱. خروجی encoded_img_patches با ابعاد ۲۵۶×۱۰۲۴ که توسط ViT تولید شده است، بهصورت خطی به تنسوری دیگر با همان ابعاد نگاشت میشود. در این لایهی فرافکنی خطی، پارامترهای قابلآموزش وجود دارد. این فرافکنی خطی روشی است برای تزریق پارامترهای قابلآموزش به یک ماژول ثابت، یعنی ترنسفورمر ViT.
گام ۲. تنسور encoded_img_patches که بهصورت خطی فرافکنی شده است، در بعد ویژگیها (بعد ۱۰۲۴) به دو تنسور کوچکتر با ابعاد یکسان ۲۵۶×۵۱۲ تقسیم میشود. یکی از این دو تنسور v نام دارد و دیگری k. احتمالا با نامگذاری k و v آشنا هستید، زیرا اینها ماتریسهای کلیدی (key) و مقدار (value) در مکانیزم attention هستند.
چرا encoded_img_patches به دو بخش مساوی تقسیم میشود؟
برای ساخت تنسورهای v و k، بهطوری که هر دو شامل اطلاعات پچهای تصویر باشند. در ادامه، در گام ۵، یک عملیات cross-attention میان آنها انجام میشود که باعث میشود اطلاعات از تمام پچها به تمام پچها منتقل و ترکیب شود.
گام ۳. یک تنسور به نام img_queries با ابعاد ۲۵۷×۵۱۲ معرفی میشود. این تنسور از کلاس Embedding در PyTorch ساخته میشود و شامل پارامترهای قابلآموزش است. این نیز یکی دیگر از روشهای تزریق پارامترهای قابلآموزش به یک ماژول ثابت محسوب میشود.
تنسور img_queries سپس بهصورت خطی به تنسور q با همان ابعاد نگاشت میشود. در این فرافکنی خطی نیز پارامترهای قابلآموزش وجود دارد. توجه داشته باشید که img_queries دارای ۲۵۷ سطر است؛ یعنی یک بردار بیشتر از تعداد پچهای تصویر رمزگذاریشده که ۲۵۶ عدد هستند.
این بردار اضافه برای نمایش اطلاعات سطح کلان (Global) تصویر استفاده میشود.
گام ۴. این مرحله همان ضرب ماتریسی معروف cross-attention یعنی q@kᵀ است. نتیجه این ضرب، تنسور sim با ابعاد ۲۵۷×۲۵۶ خواهد بود. ماتریس sim یک ماتریس حاصلضرب نقطهای (dot-product matrix) است؛ هر درایه آن، میزان شباهت حاصلضرب نقطهای بین یک سطر از تنسور img_queries و یک سطر از تنسور k را نشان میدهد که هر سطر از k نمایندهی یک پچ از تصویر ورودی است.
گام ۵. یک ضرب ماتریسی دیگر از نوع cross-attention یعنی sim@v انجام میشود که نتیجه آن تنسوری با ابعاد ۲۵۷×۵۱۲ است. گامهای ۴ و ۵ همان ضربهای کلاسیک q، k و v در مکانیزم attention هستند.
توجه داشته باشید که این ضرب، اطلاعات تمام پچها را در هر پچ ترکیب میکند. برای درک این موضوع، باید توجه کنیم که هر دو ورودی این ضرب، یعنی v و k، از پچهایی میآیند که توسط ترنسفورمر ViT تولید شدهاند. بنابراین این ضرب، در عمل یک ماتریس شباهت پچبهپچ ایجاد میکند که باعث میشود اطلاعات از تمام پچها به تمام پچها منتقل و ترکیب شود. در نتیجه، هر پچِ توجهیافته (attended patch) نهتنها شامل اطلاعات همان پچ است، بلکه اطلاعات سایر پچها را نیز در خود دارد. میتوان این عملیات را بهعنوان نوعی self-attention نیز در نظر گرفت.
گام ۶. تنسور حاصل از ضرب sim@v با ابعاد ۲۵۷×۵۱۲ به دو تنسور تقسیم میشود:
- تنسور اول، img_tokens با ابعاد ۲۵۶×۵۱۲ است. این تنسور بهعنوان نمایش اطلاعات سطح خرد تصویر بهصورت پچمحور تفسیر میشود؛ یعنی هر سطر ۱×۵۱۲ در img_tokens نمایندهی اطلاعات یکی از ۲۵۶ پچ تصویر است.
- تنسور دوم، img_cls با ابعاد ۱×۵۱۲ است. این تنسور بهعنوان نمایش اطلاعات سطح کلان (Global) تصویر تفسیر میشود که کل تصویر را خلاصه میکند.
این دو تنسور برای ایجاد همترازی بین تصویر و متن استفاده میشوند؛ همانطور که پیشتر در این مقاله توضیح داده شد.
جمعبندی
این مقاله طراحی یک مدل پایه دووجهی تصویر–متن را توضیح میدهد. بخش کلیدی این طراحی، ایجاد همترازی بین تصویر و متن است؛ در سطح کلان (Global) با استفاده از تابع زیان کنتراستیو (contrastive loss) و در سطح خرد (Local) با استفاده از تابع زیان آنتروپی متقاطع (cross-entropy loss).
همترازی تصویر–متن در سطح کلان از وظایفی مانند دستهبندی تصویر، جستوجوی تصویر بر اساس متن و یافتن تصاویر مشابه بهصورت عمیق پشتیبانی میکند. در مقابل، همترازی تصویر–متن در سطح خرد امکان انجام وظایفی مانند تولید کپشن برای تصویر و پاسخگویی به پرسشهای تصویری را فراهم میسازد.
منابع


دیدگاهتان را بنویسید