
صدا یکی از پیچیدهترین انواع داده در سیستمهای هوشمند محسوب میشود؛ دادهای که هم ساختار زمانی دارد و هم ویژگیهای فرکانسی و دینامیکی. برخلاف متن یا تصویر، پردازش صوت نیازمند تحلیل همزمان سیگنال، الگوهای آماری و در بسیاری موارد، درک معنایی است. با ظهور مدلهای یادگیری عمیق و معماریهای مبتنی بر Transformer، رویکردهای سنتی پردازش سیگنال دیجیتال به سمت مدلهای دادهمحور و خودآموز تغییر کردهاند. امروزه سیستمهای هوش مصنوعی قادرند گفتار را به متن تبدیل کنند، گوینده را تشخیص دهند، احساسات را تحلیل کنند و حتی ناهنجاریهای صوتی را در محیطهای صنعتی شناسایی کنند.
در این مقاله، ابتدا به مفاهیم پایه پردازش صوت و تفاوت آن با پردازش متن و تصویر میپردازیم، سپس نقش یادگیری عمیق و مدلهای Transformer در تحول Audio AI را بررسی میکنیم. در ادامه، کاربردهای عملی این فناوری در حوزههایی مانند تشخیص گفتار، تحلیل احساسات و پایش هوشمند را تحلیل کرده و در نهایت به چالشها و ملاحظات فنی در طراحی سیستمهای مبتنی بر پردازش صوت با هوش مصنوعی خواهیم پرداخت.
پردازش صوت چیست؟ (مبانی سیگنال صوتی)

پردازش صوت (Audio Processing) شاخهای از پردازش سیگنال است که با تحلیل، تغییر و استخراج اطلاعات از سیگنالهای صوتی سروکار دارد. پیش از ورود هوش مصنوعی به این حوزه، مهندسان از تکنیکهای کلاسیک DSP (Digital Signal Processing) برای تحلیل موج صوتی استفاده میکردند.
در این بخش ابتدا با مفاهیم پایه آشنا میشویم.
موج صوتی چیست؟
صدا در اصل یک موج مکانیکی است که از طریق هوا منتقل میشود. وقتی آن را دیجیتال میکنیم، موج پیوسته به مجموعهای از اعداد تبدیل میشود.
یک فایل صوتی دیجیتال در واقع آرایهای از نمونهها (samples) است:
[0.02, 0.04, -0.01, -0.05, …]
هر عدد نشاندهنده دامنه موج در یک لحظه خاص است.
نمونهبرداری (Sampling)
برای دیجیتالسازی صدا، از فرایند نمونهبرداری استفاده میشود.
مثلا:
44.1 kHz → یعنی در هر ثانیه 44100 نمونه ثبت میشود
16 kHz → رایج در سیستمهای تشخیص گفتار
هر چه نرخ نمونهبرداری بالاتر باشد، کیفیت بهتر است اما حجم داده نیز بیشتر میشود.
مثال کد – بارگذاری فایل صوتی در Python
|
1 2 3 4 5 6 |
import librosa audio, sr = librosa.load(“audio.wav”, sr=16000) print(“Sample Rate:”, sr) print(“Number of Samples:”, len(audio)) |
این کد:
- فایل صوتی را میخواند
- آن را به نرخ 16kHz تبدیل میکند
- داده خام موج را برمیگرداند
Spectrogram چیست؟
سیگنال صوتی در حوزه زمان قابل مشاهده است، اما برای تحلیل دقیقتر، آن را به حوزه فرکانس میبریم.
Spectrogram نمایش زمان-فرکانس صداست.
به جای اینکه فقط بگوییم «صدا بلند است»، میفهمیم:
- در چه لحظهای
- کدام فرکانسها فعال بودهاند
مثال کد – رسم Spectrogram
|
1 2 3 4 5 6 7 8 9 10 11 |
import matplotlib.pyplot as plt import librosa.display S = librosa.stft(audio) S_db = librosa.amplitude_to_db(abs(S)) plt.figure(figsize=(10, 4)) librosa.display.specshow(S_db, sr=sr, x_axis=‘time’, y_axis=‘hz’) plt.colorbar() plt.title(“Spectrogram”) plt.show() |
فیلترها (Filters)
در DSP کلاسیک از فیلترها برای حذف نویز یا تمرکز روی یک بازه فرکانسی خاص استفاده میشود:
- Low-pass ← حذف فرکانسهای بالا
- High-pass ← حذف فرکانسهای پایین
- Band-pass ← نگه داشتن یک بازه خاص
مثال ساده فیلتر پایینگذر
|
1 2 3 4 |
import scipy.signal as signal b, a = signal.butter(4, 3000/(sr/2), btype=‘low’) filtered_audio = signal.lfilter(b, a, audio) |
استخراج ویژگیها (Feature Extraction)
در روشهای سنتی، به جای دادن کل موج به مدل، ویژگیهای مهندسیشده استخراج میشدند:
- MFCC
- Zero Crossing Rate
- Spectral Centroid
مثال استخراج MFCC
|
1 2 |
mfcc = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=13) print(mfcc.shape) |
این همان رویکردی است که در سیستمهای کلاسیک تشخیص گفتار استفاده میشد.
ورود هوش مصنوعی به پردازش صوت

نقطه تحول اصلی زمانی رخ داد که به جای طراحی دستی ویژگیها، اجازه دادیم مدلها خودشان الگوها را یاد بگیرند.
مقایسه روشهای سنتی با یادگیری عمیق
در روش سنتی:
۱. پیشپردازش
۲. استخراج ویژگی (مثلا MFCC)
۳. طبقهبندی با SVM یا HMM
در یادگیری عمیق:
مدل خودش ویژگیها را یاد میگیرد.
Raw Audio → Neural Network → Output
مقایسه ویژگیهای دستی با یادگیری خودکار
در رویکرد سنتی:
مهندس باید تصمیم بگیرد چه ویژگیای مهم است
در Deep Learning:
مدل از داده یاد میگیرد کدام الگو مهم است
ورود CNN به پردازش صوت
وقتی Spectrogram را به تصویر تبدیل کردیم، CNN وارد ماجرا شد. مدل CNN میتواند الگوهای فرکانسی را مانند الگوهای تصویری تحلیل کند.
مثال مدل ساده CNN برای طبقهبندی صوت
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import torch import torch.nn as nn class AudioCNN(nn.Module): def __init__(self): super().__init__() self.conv = nn.Conv2d(1, 16, kernel_size=3) self.pool = nn.MaxPool2d(2) self.fc = nn.Linear(16*10*10, 10) def forward(self, x): x = self.pool(torch.relu(self.conv(x))) x = x.view(x.size(0), –1) return self.fc(x) |
ظهور Transformer در Audio AI
با ظهور معماری Transformer، پردازش صوت از مدلهای مبتنی بر CNN و RNN به سمت مدلهای Attention-based حرکت کرد.مدلهای جدید مانند:
- Whisper
- Wav2Vec
- Audio Spectrogram Transformer
دیگر به استخراج دستی ویژگی نیاز ندارند.
Transformer میتواند:
- وابستگیهای طولانی در زمان را درک کند
- متن را همزمان مدلسازی کند
- چندزبانه باشد
چرا Transformer برای صوت مناسب است؟
سیگنال صوتی یک دنباله زمانی (sequence) است. در گفتار:
- کلمهای که در ثانیه ۱ گفته شده
- ممکن است به کلمهای در ثانیه ۵ وابسته باشد
مدلهای قدیمی مانند RNN در مدیریت وابستگیهای طولانی مشکل داشتند (مشکل vanishing gradient).
اما Transformer:
✔ پردازش موازی انجام میدهد
✔ وابستگیهای بلندمدت را با Self-Attention یاد میگیرد
✔ برای دادههای طولانی مقیاسپذیر است
Self-Attention روی دنبالههای صوتی
در NLP، Transformer روی توکنهای متن کار میکند.
در صوت، ابتدا باید موج صوتی به embedding تبدیل شود.
روند کلی:
Raw Audio → Feature Extraction → Embedding → Self-Attention → Output
Self-Attention بررسی میکند:
هر بخش از سیگنال چقدر به سایر بخشها اهمیت دارد؟
مثلا:
- شروع جمله ممکن است روی تشخیص پایان جمله اثر بگذارد.
- یک آوای خاص ممکن است وابسته به بافت قبلی باشد.
تبدیل موج صوتی به Embedding
مدلهای مدرن معمولا یکی از این دو روش را استفاده میکنند:
۱. تبدیل به Spectrogram
۲. استفاده مستقیم از موج خام (Raw waveform)
در مدلهایی مثل Wav2Vec یا Whisper:
- موج خام وارد encoder میشود
- به بردارهای embedding تبدیل میشود
- سپس وارد لایههای Transformer میشود
مثال عملی: استفاده از مدل Transformer برای Speech Recognition
در اینجا از HuggingFace برای استفاده از یک مدل مبتنی بر Transformer استفاده میکنیم (مانند Wav2Vec2).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor import torch import librosa # بارگذاری مدل و پردازشگر processor = Wav2Vec2Processor.from_pretrained(“facebook/wav2vec2-base-960h”) model = Wav2Vec2ForCTC.from_pretrained(“facebook/wav2vec2-base-960h”) # بارگذاری فایل صوتی audio, sr = librosa.load(“audio.wav”, sr=16000) # آمادهسازی ورودی inputs = processor(audio, sampling_rate=16000, return_tensors=“pt”, padding=True) # پیشبینی with torch.no_grad(): logits = model(inputs.input_values).logits predicted_ids = torch.argmax(logits, dim=–1) transcription = processor.decode(predicted_ids[0]) print(“Transcription:”, transcription) |
این دقیقاً نمونهای از استفاده Transformer در پردازش گفتار است.
مدلهای Speech-to-Text مبتنی بر Transformer
امروزه مدلهای معروف این حوزه:
- Whisper
- Wav2Vec 2.0
- Audio Spectrogram Transformer (AST)
همگی مبتنی بر Attention هستند و به صورت end-to-end آموزش دیدهاند.
معماری یک سیستم پردازش صوت مبتنی بر AI
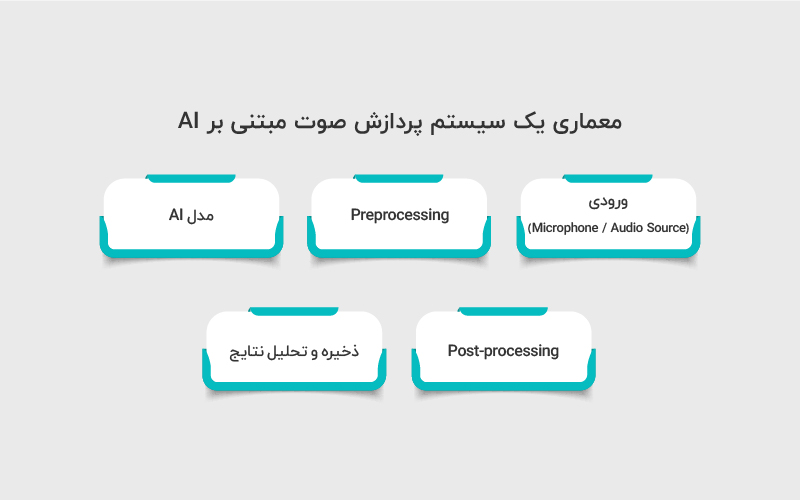
حالا از سطح مدل بیاییم به سطح سیستم واقعی. یک سیستم پردازش صوت مبتنی بر AI معمولا این مراحل را دارد:
Microphone → Preprocessing → AI Model → Post-processing → Storage/Analytics
۱. ورودی (Microphone / Audio Source)
ورودی میتواند:
- میکروفن زنده
- فایل صوتی
- استریم آنلاین
- تماس تلفنی
مثال دریافت صوت از میکروفن:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import sounddevice as sd import numpy as np duration = 5 # seconds sample_rate = 16000 print(“Recording…”) audio = sd.rec(int(duration * sample_rate), samplerate=sample_rate, channels=1) sd.wait() audio = np.squeeze(audio) print(“Recording finished”) |
۲. Preprocessing
مرحله آمادهسازی داده:
- حذف نویز
- نرمالسازی
- Resampling
- Voice Activity Detection
مثال نرمالسازی ساده:
|
1 |
audio = audio / np.max(np.abs(audio)) |
۳. مدل AI
در این مرحله مدل میتواند یکی از اینها باشد:
- Speech-to-Text
- Emotion Recognition
- Speaker Identification
- Sound Event Detection
مثلا استفاده از Whisper:
|
1 2 3 4 5 6 |
import whisper model = whisper.load_model(“base”) result = model.transcribe(“audio.wav”) print(result[“text”]) |
۴. Post-processing
بعد از خروجی مدل، معمولا:
- اصلاح متن
- حذف تکرار
- punctuation
- ترجمه
- تحلیل احساس
مثال ساده:
|
1 |
text = result[“text”].strip().capitalize() |
۵. ذخیره و تحلیل نتایج
در کاربردهای واقعی:
- ذخیره در دیتابیس
- ارسال به API دیگر
- تحلیل آماری
- ساخت داشبورد
مثال ذخیره در فایل:
|
1 2 |
with open(“transcription.txt”, “w”) as f: f.write(text) |
نگاه حرفهای به معماری
در سطح صنعتی، سیستم ممکن است شامل:
- Message Queue (Kafka)
- GPU inference server
- API Gateway
- Monitoring system
- Model versioning
یعنی Audio AI فقط یک مدل نیست؛ یک pipeline کامل مهندسی است.
کاربردهای عملی پردازش صوت با هوش مصنوعی

پردازش صوت با هوش مصنوعی دیگر فقط یک موضوع تحقیقاتی نیست؛ امروز در قلب بسیاری از محصولات دیجیتال قرار دارد. از سیستمهای تماس هوشمند گرفته تا ابزارهای پایش صنعتی، Audio AI به یک زیرساخت کلیدی تبدیل شده است.
در ادامه مهمترین کاربردهای عملی را بررسی میکنیم.
۱. Speech-to-Text (تبدیل گفتار به متن)
یکی از گستردهترین کاربردها، تبدیل گفتار به متن است.
کاربردهای عملی:
- زیرنویس خودکار ویدئو
- مستندسازی جلسات
- تحلیل تماسهای پشتیبانی
- سیستمهای دیکته هوشمند
در سیستمهای مدرن، مدلهای Transformer مانند Whisper یا Wav2Vec2 بهصورت end-to-end کار میکنند.
نمونه پیادهسازی ساده:
|
1 2 3 4 5 6 |
import whisper model = whisper.load_model(“base”) result = model.transcribe(“meeting.wav”) print(result[“text”]) |
در سطح صنعتی، خروجی متن معمولا وارد سیستمهای NLP میشود تا:
- تحلیل احساس مشتری
- استخراج کلمات کلیدی
- شناسایی intent
۲. Voice Assistant (دستیارهای صوتی)
دستیارهای صوتی ترکیبی از چند ماژول هستند:
Speech Recognition → NLP → Action Engine → Text-to-Speech
مثال کاربردی:
- سیستمهای خانه هوشمند
- کیوسکهای خدماتی
- اپلیکیشنهای موبایل
چالش اصلی در این حوزه latency پایین و پردازش real-time است.
۳. Emotion Detection (تشخیص احساس از صدا)
برخلاف Speech-to-Text که تمرکز بر«چه چیزی گفته شد» دارد،
Emotion Detection تمرکز بر «چگونه گفته شد» دارد.
ویژگیهای مهم:
- Pitch
- Energy
- Speaking rate
- Prosody
کاربردها:
- تحلیل تماسهای پشتیبانی
- پایش سلامت روان
- سیستمهای آموزشی هوشمند
در این حوزه معمولا از ترکیب CNN + Transformer یا مدلهای Spectrogram-based استفاده میشود.
۴. Audio Classification (طبقهبندی صوت)
در این کاربرد، هدف تشخیص نوع صداست، نه محتوای آن.
مثالها:
- تشخیص صدای آژیر
- تشخیص صدای شیشه شکستن
- تشخیص حیوانات
- دستهبندی ژانر موسیقی
نمونه ساده با استخراج ویژگی:
|
1 2 3 4 5 6 7 |
import librosa import numpy as np audio, sr = librosa.load(“sound.wav”) mfcc = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=13) print(“MFCC shape:”, mfcc.shape) |
در مدلهای پیشرفتهتر، Spectrogram مستقیماً به Transformer داده میشود (مانند Audio Spectrogram Transformer).
۵. Smart Monitoring (پایش هوشمند صنعتی)
یکی از کاربردهای مهم در صنعت:
- تشخیص خرابی ماشینآلات از روی صدا
- پایش خطوط تولید
- تحلیل آکوستیکی تجهیزات
اینجا مدل باید بتواند:
- anomaly detection انجام دهد
- در محیطهای نویزی پایدار باشد
- real-time عمل کند
در کاربردهای صنعتی، pipeline معمولا شامل edge device + cloud inference است.
چالشها و محدودیتها در پردازش صوت با AI

با وجود پیشرفتهای چشمگیر، پردازش صوت هنوز با چالشهای جدی روبهروست.
۱. نویز محیطی (Environmental Noise)
در محیطهای واقعی:
- صدای پسزمینه
- اکو
- تداخل چند گوینده
- میتواند دقت مدل را کاهش دهد.
راهکارها:
- Noise reduction preprocessing
- Data augmentation
- آموزش مدل روی دادههای noisy
۲. لهجهها و تنوع زبانی
مدلها معمولا روی دیتاستهای خاص آموزش دیدهاند.
چالشها:
- لهجههای محلی
- ترکیب زبانها (Code-switching)
- گفتار غیررسمی
راهکار:
- Fine-tuning
- استفاده از مدلهای multilingual
- افزایش تنوع دیتاست آموزشی
۳. Latency در سیستمهای Real-Time
در کاربردهایی مثل:
- دستیار صوتی
- تماس زنده
- پایش امنیتی
تاخیر حتی چند صد میلیثانیه مهم است.
چالشهای latency:
- اندازه مدل
- قدرت GPU
- سرعت انتقال داده
راهکار:
استفاده از مدلهای کوچکتر
- quantization
- edge deployment
۴. مصرف منابع (Compute & Memory)
مدلهای Transformer بزرگ هستند.
مشکلات:
- نیاز به GPU
- مصرف RAM بالا
- هزینه inference
در سیستمهای صنعتی باید بین دقت مدل و هزینه پردازش تعادل برقرار شود.
۵. دقت مدلها در سناریوهای پیچیده
در محیطهای چندگوینده (Multi-speaker):
- overlap speech
- قطع و وصل شدن صدا
- فاصله متفاوت از میکروفن
- مدل ممکن است اشتباه کند.
در پژوهشهای پیشرفته (مانند تحقیقات صنعتی MERL) تمرکز بر بهبود robustness و generalization است.
آینده پردازش صوت با هوش مصنوعی
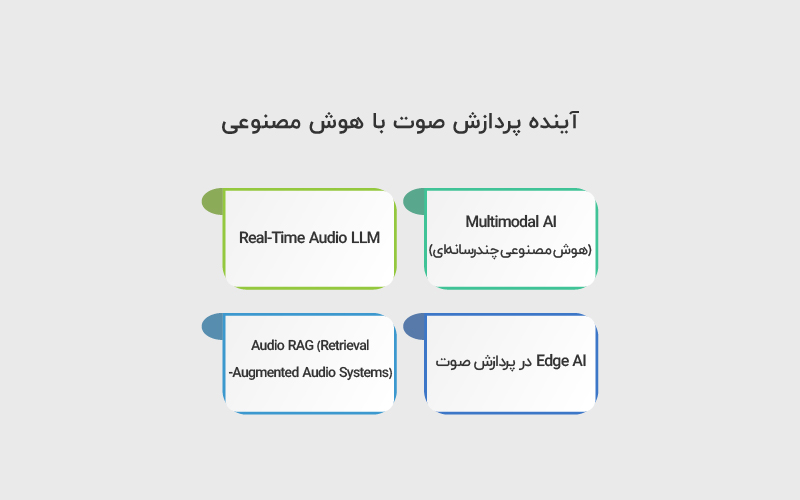
پردازش صوت با هوش مصنوعی هنوز به نقطه نهایی خود نرسیده است. آنچه امروز بهعنوان Speech-to-Text، تشخیص احساس یا طبقهبندی صوت میشناسیم، تنها بخشی از مسیر تحول Audio AI است. آینده این حوزه در همگرایی چند فناوری کلیدی شکل میگیرد.
در ادامه مهمترین روندهای پیشرو را بررسی میکنیم.
۱. Multimodal AI (هوش مصنوعی چندرسانهای)
مدلهای آینده فقط صوت را پردازش نمیکنند؛ آنها همزمان متن، تصویر و ویدئو را نیز درک میکنند.
مثالهای کاربردی آینده:
- تحلیل همزمان تماس تصویری (صدا + تصویر چهره)
- سیستمهای آموزشی که لحن و زبان بدن را تحلیل میکنند
- پایش صنعتی با ترکیب صوت و دادههای سنسور
در این رویکرد، صوت دیگر یک ورودی مستقل نیست؛ بلکه بخشی از یک سیستم چندوجهی (Multimodal System) است که تصمیمگیری عمیقتری انجام میدهد.
۲. Real-Time Audio LLM
مدلهای زبانی بزرگ (LLM) در حال ورود به حوزه پردازش صوت هستند.
نسل جدید سیستمها:
- ورودی صوتی را مستقیم دریافت میکنند
- به صورت لحظهای پاسخ تولید میکنند
- مکالمه را در حافظه نگه میدارند
این یعنی آینده Voice Assistantها:
- طبیعیتر
- سریعتر
- context-aware
- مکالمهمحور
چالش اصلی در این حوزه کاهش latency و بهینهسازی inference در زمان واقعی است.
۳. Edge AI در پردازش صوت
یکی از مهمترین روندهای صنعتی، انتقال پردازش به لبه شبکه (Edge) است. چون:
- کاهش تأخیر
- حفظ حریم خصوصی
- کاهش هزینه انتقال داده
- استقلال از اینترنت
در آینده:
- دستگاههای IoT
- گوشیهای هوشمند
- تجهیزات صنعتی
مدلهای فشردهشده (Quantized / Distilled) را مستقیماً روی دستگاه اجرا خواهند کرد.
۴. Audio RAG (Retrieval-Augmented Audio Systems)
یکی از مفاهیم نوظهور، ترکیب Retrieval با پردازش صوت است.
در این معماری:
۱. گفتار به متن تبدیل میشود
۲. متن وارد سیستم بازیابی دانش میشود
۳. اطلاعات مرتبط از پایگاه داده استخراج میشود
۴. پاسخ دقیق و مستند تولید میشود
کاربردهای آینده:
- سیستمهای پشتیبانی سازمانی
- تحلیل تماسهای حقوقی
- مستندسازی جلسات با ارجاع به دانش سازمان
در این رویکرد، صوت فقط تبدیل به متن نمیشود؛ بلکه به یک نقطه ورود به دانش سازمان تبدیل میشود.
جمعبندی
پردازش صوت با هوش مصنوعی از یک فناوری آزمایشگاهی به یک زیرساخت کلیدی در محصولات دیجیتال تبدیل شده است. امروز سیستمهای مبتنی بر Audio AI میتوانند گفتار را به متن تبدیل کنند، احساسات را تشخیص دهند، صداها را طبقهبندی کنند و حتی خرابی تجهیزات صنعتی را پیشبینی کنند.
با ظهور معماریهای Transformer و مدلهای بزرگ، کیفیت و دقت پردازش صوت به شکل چشمگیری افزایش یافته است. با این حال، چالشهایی مانند نویز محیطی، تنوع زبانی، مصرف منابع و نیاز به پردازش بلادرنگ همچنان نقش تعیینکننده دارند.
آینده این حوزه در همگرایی با مدلهای چندرسانهای، سیستمهای Real-Time مبتنی بر LLM، پردازش لبهای و معماریهای مبتنی بر بازیابی دانش شکل میگیرد. در چنین مسیری، صوت دیگر فقط یک سیگنال خام نیست، بلکه به یک لایه هوشمند در سیستمهای تصمیمیار، تحلیلی و تعاملی تبدیل خواهد شد.
پردازش صوت با هوش مصنوعی نهتنها یک قابلیت فنی، بلکه یک مزیت رقابتی برای محصولات نسل بعد محسوب میشود؛ محصولاتی که هوشمندتر میشنوند، دقیقتر تحلیل میکنند و طبیعیتر پاسخ میدهند.
منابع
markheath.net | merl.com | geeksforgeeks.org | reference.wolfram.com
سوالات متداول
WaveNet و U-Net برای شناسایی و حذف نویز از سیگنال صوتی
گرافهای عصبی برای تولید صدا تمیز و قابل استفاده
Transfer Learning به توسعهدهندگان امکان میدهد از مدلهای آموزشدادهشده قبلی (مانند Wav2Vec, HuBERT) برای سریعتر کردن پردازش صوت استفاده کنند. مزایا:
کاهش زمان آموزش
کاهش نیاز به دادههای بزرگ
کارایی بهتر در موارد کم داده
WER (Word Error Rate): برای سنجش دقت تشخیص گفتار
CER (Character Error Rate): برای ارزیابی دقت در شناسایی کاراکترها
SNR (Signal-to-Noise Ratio): برای ارزیابی کیفیت صدا
F1 Score: برای ارزیابی دقت و بازیابی در تشخیص گفتار



دیدگاهتان را بنویسید