
حجم استفاده افراد از هوش مصنوعی روز به روز بیشتر میشود و هر روزه صنایع بیشتری از آموزش و درمان گرفته تا تولید و بازاریابی، از این فناوری برای بهبود خدمات خود استفاده میکنند. با این حال، توسعه مدلهای هوش مصنوعی بدون استفاده از شبکههای یادگیری عمیق ممکن نیست. کتابخانهها و فریمورکهای زیادی برای توسعه مدلهای یادگیری عمیق وجود دارد که در بین آنها پای تورچ (PyTorch) از جایگاه ویژهای برخوردار است. در این مقاله از بلاگ آسا در مورد این کتابخانه محبوب پایتون، ویژگیها، نحوه کار و رقبای آن صحبت میکنیم.
پای تورچ (PyTorch) چیست؟
PyTorch یک کتابخانه یادگیری ماشین است که برای ساخت و آموزش مدلهای یادگیری عمیق استفاده میشود. این کتابخانه در سال ۲۰۱۶ توسط فیسبوک عرضه شد تا فرایند توسعه مدلهای یادگیری عمیق را ساده و منعطف کند، دقیقا همان کاری که کتابخانه keras برای آن طراحی شده است!

مشابه کراس، PyTorch هم یک API سطح بالا برای یک کتابخانه سطح پایینتر است. با این تفاوت که کراس بیشتر به tensorflow متکی است اما پایتورچ از کتابخانه تورچ (Torch) برای محاسبات سطح پایین استفاده میکند. در حال حاضر با توجه به ویژگیهای کلیدی پایتورچ، آن را به عنوان یک رقیب جدی برای تنسورفلو و کراس میشناسند. در ادامه ویژگیهای کلیدی پایتورچ را مرور خواهیم کرد.
ویژگیهای کلیدی پایتورچ
پایتورچ یک کتابخانه قدرتمند، انعطافپذیر و در عین حال ساده است که بسیاری از توسعهدهندگان یادگیری عمیق آن را به عنوان انتخاب اول خود معرفی میکنند. در ادامه مهمترین مزایا و ویژگیهای این کتابخانه را بررسی میکنیم.
گرافهای محاسباتی پویا
یکی از ویژگیهای مهم PyTorch این است که به شما این امکان را میدهد تا نمودارهای محاسباتی را در لحظه ایجاد کنید و تغییر دهید. در نتیجه شما میتوانید ساختار و رفتار مدل خود را در طول زمان اجرا، بسته به دادهها و وظایف مورد نظر، تغییر دهید. این ویژگی به شما کنترل و خلاقیت بیشتری بر آزمایشهایتان میدهد و همچنین فرایند رفع خطا و بهینهسازی کد را آسانتر میکند. نمودارهای پویا همچنین به شما امکان میدهند از ورودیها و خروجیهای با طول متغیر استفاده کنید که برای پردازش زبان طبیعی (NLP) و یادگیری تقویتی (Reinforcement Learning) مفید هستند.
رابط پایتونیک
از آنجایی که پای تورچ یک کتابخانه پایتون است، رابط کاربری گرافیکی و کاربرپسندی دارد. بنابراین میتوانید از ساختارهای داده پایتون مانند لیستها، دیکشنریها و تاپلها برای دستکاری تانسورها (Tensor) و ساخت مدلها استفاده کنید. پایتونمحور بودن این کتابخانه باعث میشود تا قدرت دیگر کتابخانههای پایتون مانند NumPy، SciPy و Matplotlib در اختیار شما باشد و بتوانید از آنها برای انجام تجزیه و تحلیل و تجسم دادهها استفاده کنید. پایتورچ حتی امکان استفاده از کتابخانههایی مانند TensorFlow، Keras و Scikit-learn را به عنوان بکاند فراهم میکند، بنابراین نیازی نیست که حتما بین پای تورچ و کراس جابهجا شوید.
بیشتر بخوانید: معرفی 30 مورد از بهترین کتابخانه های پایتون
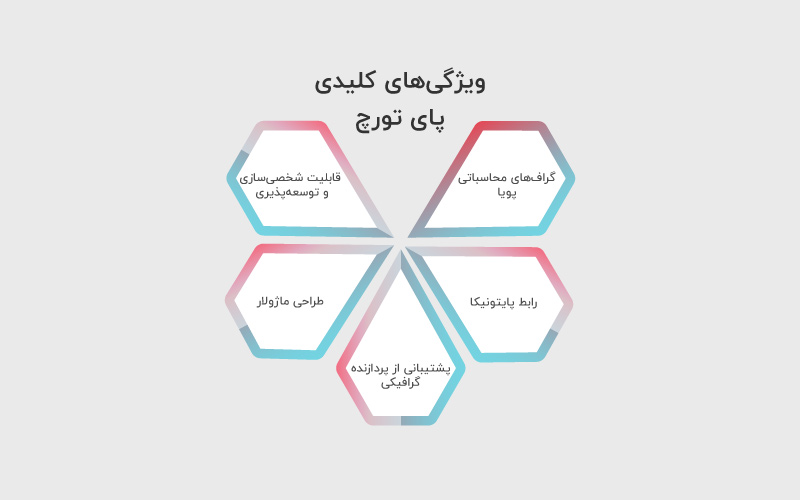
پشتیبانی از پردازنده گرافیکی
پایتورچ از GPU پشتیبانی میکند و امکان اجرای مدلها روی پردازنده گرافیکی را فراهم میکند. برای مقایسه بهتر است بدانید که سرعت یک پردازنده گرافیکی بالارده حتی تا ۱۰۰ برابر یک CPU هم میرسد و این یعنی میتوانید مدلها را سریعتر و کارآمدتر اجرا کنید. توابع داخلی این کتابخانه همچنین امکان جابهجایی تانسورها و مدلها بین GPUها و استفاده از چندین GPU برای پردازش موازی را فراهم میکنند. علاوه بر همه اینها، قدرت بالای پردازندههای گرافیکی باعث شده تا پای تورچ بتواند قابلیت تمایز خودکار را ارائه دهد که محاسبه گرادیان و انتشار پس زمینه را ساده میکند.
طراحی ماژولار
پایتورچ مشابه با کراس، دارای طراحی ماژولار است. این ویژگی باعث میشود تا بتوانید از اجزای مختلف فریمورک به صورت مستقل یا با هم استفاده کنید. به عنوان مثال، میتوانید از کتابخانه تانسور PyTorch به نام Torch برای انجام عملیات سطح پایین روی آرایههای چندبعدی استفاده کنید. همچنین میتوانید از کتابخانه شبکه عصبی PyTorch به نام Torch.nn برای ایجاد و آموزش مدلهای سطح بالا با لایهها و فعالسازها استفاده کنید. دیگر ماژولهای PyTorch مانند Torch.optim، Torch.utils و Torchvision نیز امکان بهینهسازی، ذخیره، بارگذاری و پیش پردازش دادهها و مدلها را فراهم میکنند.
قابلیت شخصیسازی و توسعهپذیری
PyTorch قابل تنظیم و توسعهپذیر است، یعنی شما میتوانید آن را بر اساس نیازها و ترجیحات خاص خود تنظیم کنید. شما به عنوان توسعهدهنده میتوانید لایهها، بهینهسازها و مجموعه دادههای سفارشی خود را ایجاد کنید یا از لایههای موجود در اکوسیستم PyTorch استفاده کنید. کتابخانهها و ابزارهای پایتورچ مانند PyTorch Lightning، PyTorch Ignite و PyTorch Geometric میتواند برای طیف وسیعی از وظایف و کاربردها استفاده شود و همین موضوع باعث شده تا این کتابخانه هم توسط توسعهدهندگان تازهکار و هم متخصصان یادگیری عمیق مورد استقبال قرار گیرد.
پای تورچ چگونه کار میکند؟
پایتورچ عملکرد خود را بر اساس مدیریت دادهها و محاسبات ریاضی روی تانسورها انجام میدهد. در ادامه به صورت خلاصه نحوه کار این کتابخانه را بررسی میکنیم.
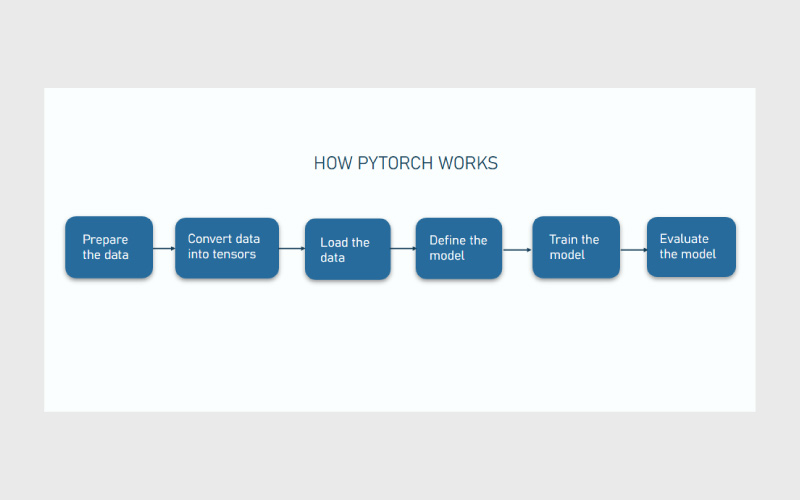
۱. آمادهسازی دادهها
پایه و اساس هر شبکه عصبی موفق، کیفیت و مناسب بودن دادههای ورودی است. PyTorch ابزارها و توابع مختلفی را برای پیشپردازش دادهها ارائه میدهد تا مطمئن شوید که دادهها در فرمت مناسبی برای آموزش مدل قرار دارند. این فرایند معمولا شامل مراحل زیر است:
- نرمالسازی (Normalization): مقیاسبندی دادهها به یک بازه استاندارد (مثلا بین ۰ تا ۱).
- افزایش دادهها (Data Augmentation): اعمال تغییراتی مانند چرخش، برش یا وارونه کردن تصاویر برای افزایش تنوع دادههای آموزشی.
- تقسیم دادهها: تقسیم دادهها به مجموعههای آموزشی، اعتبارسنجی و تست برای ارزیابی عملکرد مدل و جلوگیری از بیشبرازش (Overfitting).
۲. تبدیل دادهها به تانسورها
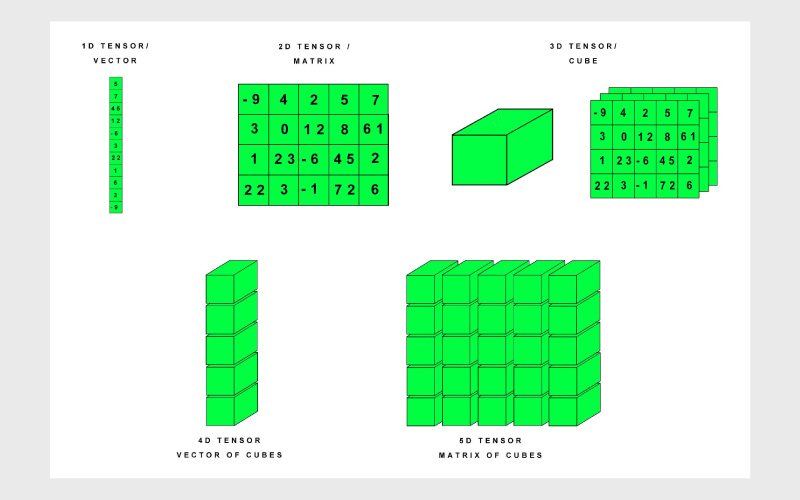
قبل از اینکه دادهها به شبکه عصبی ورودی داده شوند باید فرمت آنها به شکلی تغییر کند تا PyTorch بتواند آنها را پردازش کند؛ این یعنی باید به تانسور تبدیل شوند. تانسورها آرایههای چندبعدی هستند که به عنوان ساختارهای دادهای پایهای در PyTorch عمل میکنند. این تبدیل معمولا با استفاده از تابع «torch.tensor» انجام میشود. یکی از تفاوتهای مهم پای تورچ با دیگر ابزارهای یادگیری در همین مرحله و زمانی است که پایتورچ از گرافهای محاسباتی پویا (Dynamic Computational Graphs) استفاده میکند تا گراف محاسباتی در زمان اجرا و به صورت پویا ساخته شود. این ویژگی باعث میشود دیباگ کردن و تغییرات آنی در ساختار شبکه راحتتر انجام شود.
۳. ایجاد دیتاستها و دیتا لودرها
پس از تبدیل دادهها به تانسورها، مرحله بعدی ایجاد دیتاستها (Datasets) و دیتا لودرها (Data Loaders) است. دیتاستها، دادههای نمونه و برچسبهای مرتبط با آنها را ذخیره میکنند. دیتالودرها نیز برای پیمایش دیتاست در طول آموزش استفاده میشوند. با استفاده از دیتا لودر میتوانید اندازه دستهها (Batch Size) را تعریف کنید، مشخص کنید که آیا دادهها باید برای بهبود تعمیمپذیری مدل به صورت تصادفی مرتب شوند یا خیر و دیگر عملیات مشابه را روی آنها انجام دهید.
۴. تعریف شبکه عصبی
در قلب هر شبکه عصبی، معماری آن قرار دارد که ساختار و جریان اطلاعات را با استفاده از لایههای شبکه تعریف میکند. در PyTorch، شبکههای عصبی به عنوان کلاسهای پایتون تعریف میشوند که از کلاس «torch.nn.Module» ارثبری میکنند. در این کلاس:
از متد «init» برای تعریف لایههای شبکه استفاده میشود و متد «forward» هم نحوه عبور دادههای ورودی از طریق این لایهها برای تولید خروجی مورد نظر مشخص میکند. این متد باید شامل لایهها و توابع فعالسازی باشد که شبکه عصبی را تشکیل میدهند.
۵. تابع زیان و بهینهساز
در حین آموزش شبکه، به روشی نیاز داریم تا عملکرد شبکه را ارزیابی و وزنها و بایاسهای آن را تنظیم کنیم. اینجا است که تابع زیان (Loss Function) و بهینهساز (Optimizer) وارد میشوند. تابع زیان، نشان میدهد که چقدر پیشبینیهای شبکه با برچسبهای واقعی دادههای آموزشی تطابق دارد.
توابع زیان رایج در PyTorch شامل «torch.nn.CrossEntropyLoss» برای وظایف طبقهبندی و «torch.nn.MSELoss» برای وظایف رگرسیون است. تابع مهم دیگر که به آن اشاره کردیم، تابع بهینهساز است که با تنظیم و بهروزرسانی پارامترهای داخلی شبکه (وزنها و بایاسها) به کاهش مقدار زیان کمک میکند. بهینهسازهای محبوب PyTorch شامل الگوریتمهایی مانند SGD (گرادیان نزولی تصادفی)، Adam و RMSprop هستند.
۶. آموزش مدل
در فرایند آموزش، دادهها به صورت دستهای به شبکه عصبی داده میشوند و سپس شبکه با استفاده از تابع زیان و یک الگوریتم بهینهسازی، پیشبینیها را انجام میدهد و پارامترهای داخلی خود را بر اساس عملکرد مناسب تنظیم میکند. PyTorch نتایج زیان را پس از هر ۱۰۰۰ دسته گزارش میدهد.
۷. ارزیابی مدل
پس از آموزش مدل، باید عملکرد آن را روی یک داده جدید دیگر ارزیابی کنیم. این به ما کمک میکند تا بفهمیم مدل بر دادههای جدید و نادیده چگونه عمل میکند. با عبور دادن دادههای تست از مدل آموزشدیده و مقایسه پیشبینیهای آن با جوابهای درست، میتوان معیارهایی مانند دقت، صحت و بازخوانی را محاسبه کرد تا عملکرد شبکه عصبی را اندازهگیری کنیم.
این تنها یک مثال ساده از نحوه کار پای تورچ بود، همانطور که قبلا گفتیم این کتابخانه بسیار انعطافپذیر است و به همین دلیل توسعهدهندگان میتوانند رویکردهای کاملا متفاوتی را در پیش بگیرند. در ادامه با کاربردهای این کتابخانه قدرتمند آشنا میشویم.
کاربردهای PyTorch چیست؟
انعطافپذیری بالای پایتورچ باعث شده تا محبوبیت زیادی در حوزههای مختلف یادگیری عمیق به دست آورد و به یک ابزار جذاب برای سرعت بخشیدن به توسعه و آموزش مدلها تبدیل شود. برخی از زمینههایی که PyTorch در آنها بیشترین استفاده را دارد عبارتند از:
تحقیق و آزمایش
نمودارهای محاسباتی پویا و معماری انعطافپذیر، PyTorch را به انتخابی مناسب برای محققان و دانشجویان تبدیل میکند که به نمونهسازی سریع و آزمایش مدلها و ایدههای جدید یادگیری عمیق نیاز دارند.
پردازش زبان طبیعی (NLP)
پای تورچ به طور گسترده در وظایف NLP مانند تجزیه و تحلیل احساسات، ترجمه ماشینی، تشخیص گفتار، شناسایی موجودیتها و تولید متن استفاده میشود.
بیشتر بخوانید: NLP چیست؟
بینایی کامپیوتر
یادگیری عمیق بخشی مهمی در بینایی کامپیوتر است، به همین دلیل کتابخانههایی مانند کراس و پایتورچ پای ثابت این حوزه هستند. طبقهبندی تصاویر، تشخیص اشیا، تجزیه و تحلیل تصاویر پزشکی و سایر وظایف بینایی کامپیوتری به کمک این کتابخانهها سادهتر میشوند.
مدلهای مولد
پایتورچ از مدلهای مولد (Generative Models) مانند رمزگذارهای خودکار متغیر (VAE) و شبکههای متخاصم مولد (GANs) پشتیبانی میکند که برای کارهایی مانند تولید تصویر و تقویت دادهها استفاده میشوند.

سیستمهای خودمختار
پایتورچ همچنین ساخت مدلهایی برای وسایل نقلیه خودمختار و رباتیک را ممکن میسازد. ترکیب پای تورچ و مفاهیم بینایی کامپیوتر، به ماشینها این امکان را میدهد تا محیط اطراف خود را بر اساس ورودیهای حسگر درک کنند.
یادگیری انتقالی
یادگیری انتقالی تکنیکی در یادگیری ماشین است که در آن دانش و مهارتهای کسبشده از یک مدل یا وظیفه به زمینه یا وظیفهی جدید منتقل میشود. به این صورت، یادگیری و حل مسئله در شرایط جدید سریعتر و موثرتر انجام شود. انعطافپذیری و ماژولار بودن پایتورچ در یادگیری انتقالی یک مزیت مهم است.
موارد گفته شده تنها چند نمونه از کاربردهای وسیع PyTorch است. این کتابخانه قدرتمند، تقریبا در تمام حوزههای یادگیری عمیق قابل استفاده است.
مقایسه پای تورچ با دیگر کتابخانههای یادگیری ماشین
پایتورچ یکی از محبوبترین کتابخانهها در حوزه یادگیری ماشین و هوش مصنوعی است، اما کتابخانههای دیگری مانند TensorFlow و Keras هم وجود دارند. بیایید یک مقایسه کوتاه بین آنها و پای تورچ داشته باشیم.
PyTorch در برابر TensorFlow
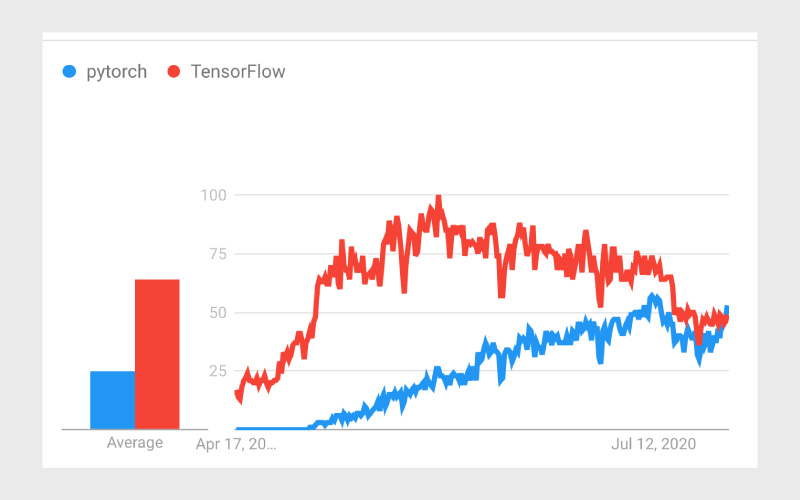
در حال حاضر هم پایتورچ و هم تنسورفلو از گرافهای محاسباتی پویا بهره میبرند. این گرافها به توسعهدهندگان امکان میدهند تا در زمان اجرا، تغییرات را در مدل ایجاد کنند و به انعطافپذیری بیشتری دست یابند. با این وجود، برتری تنسورفلو در ارائه ابزار داخلی قدرتمند به نام TensorFlow Serving است که برای استقرار مدلها در محیط تولید استفاده میشود. در مقابل، یادگیری پایتورچ سادهتر است، زیرا از رویکرد «پایتونیک» و نزدیک به مفاهیم اصلی پایتون استفاده میکند که یادگیری توسعه شبکههای عمیق را سادهتر میکند.
PyTorch در برابر Keras
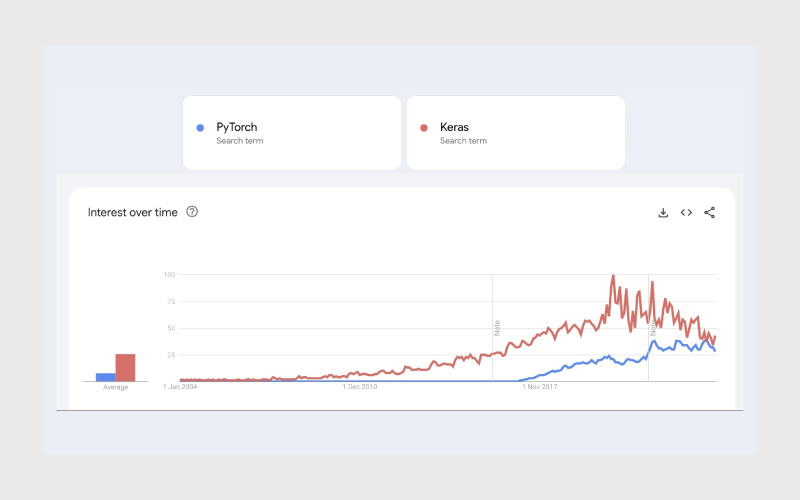
همانطور که در مقاله معرفی کراس گفته شد، این کتابخانه در حقیقت یک API سطح بالا برای ساخت شبکههای عصبی است که سادگی بیشتری دارد و و میتواند به سرعت پروتوتایپ ایجاد کند. در مقایسه با کراس، پایتورچ کمی پیچیدهتر است اما کنترل بیشتری روی معماری مدل و فرایند آموزش به توسعهدهندگان میدهد. از لحاظ محبوبیت، پای تورچ به دلیل گرافهای محاسباتی پویا، کنترل سطح پایین و یکپارچگی قوی با پایتون، در تحقیقات علمی و پروژههای صنعتی محبوبیت بیشتری دارد. در سمت دیگر، کراس به دلیل سادگی و رابط کاربری مناسب، برای کسانی که تازه وارد یادگیری عمیق شدهاند یا نیاز به ساخت سریع مدلها دارند، گزینه محبوبی است.
به طور کلی، PyTorch برای تحقیقات و توسعه مدلهای انعطافپذیر مناسبتر است، TensorFlow توسعه و استقرار مدلهای پیچیده برای استفادهی عملی را امکانپذیر میکند و Keras برای ساخت سریع پروتوتایپها و مدلهای سادهتر مناسبتر است.
سخن پایانی
پایتورچ به طور مداوم در حال تکامل است تا نیازهای موجود در یادگیری عمیق را برطرف کند. این کتابخانه با امکاناتی مانند نمودارهای محاسباتی پویا، تمایز خودکار و ماژولهای از پیش طراحی شده، توسعه مدلهای یادگیری ماشینی را بهبود داده است و پذیرش آن در صنایع مختلف را هر روز افزایش میدهد.
منابع:


دیدگاهتان را بنویسید