
در دنیای امروز که دادهها با سرعت فوقالعادهای در حال گسترش و تنوع هستند، نیاز به سیستمهای ذخیرهسازی دادهها با توانایی بالا برای مدیریت حجم بسیار بزرگی از اطلاعات پیچیده و ساختارهای متنوع بیش از پیش احساس میشود. در این زمینه پایگاهدادههای NoSQL به ویژه دیتابیسهای سندگرا یا مستندگرا (Document-Oriented Databases) بهعنوان یک راهحل خوب و مدرن برای حل مشکلات ذخیرهسازی دادهها ساخته شدهاند. در این مقاله از بلاگ آسا با دیتابیسهای مستندگرا بیشتر آشنا میشویم.
دیتابیس سندگرا (Document-Oriented) چیست؟
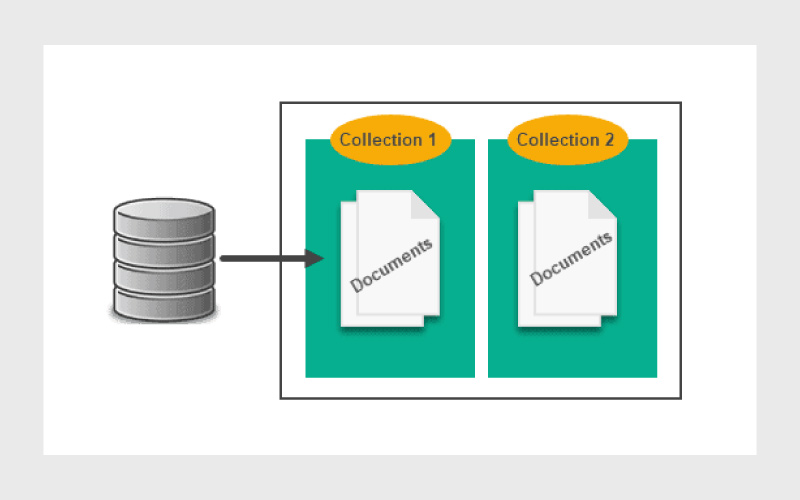
دیتابیسهای Document-Oriented نوعی از دیتابیسهای NoSQL هستند که برای ذخیرهسازی دادهها در سند (Document) طراحی شدهاند. این پایگاه دادهها برخلاف پایگاههای داده رابطهای (RDBMS) که دادهها را در جدولها و ردیفها ذخیره میکنند، از مجموعهای از اسناد به نام کالکشن (collection) برای ذخیرهسازی اطلاعات استفاده میکنند. این مستندات میتوانند بهصورت فایلهای BSON، JSON یا XML باشند که امکان ذخیرهسازی دادههای پیچیده و انعطافپذیر را فراهم میکند. این ویژگیها باعث شده تا این نوع دیتابیسها به گزینهای مناسب برای سیستمهای مقیاسپذیر (Scalable) تبدیل شوند.
یکی از معروفترین پایگاه دادههای سندگرا، MongoDB است. برای مثال، در MongoDB شما ممکن است یک کالکشن به نام users داشته باشید که هر سند در آن نشاندهنده اطلاعات یک کاربر است:
|
1 2 3 4 5 6 7 8 9 10 |
{ “_id”: ObjectId(“603d1f7f9b1e8b3f9b8a8c32”), “name”: “Mehran Ahmadi”, “email”: “mehran.a@example.com”, “age”: 30, “address”: { “street”: “123 Main St”, “city”: “Tehran” } } |
همچنین در همان کالکشن، سند دیگری ممکن است ویژگیهای متفاوتی داشته باشد:
|
1 2 3 4 5 6 |
{ “_id”: ObjectId(“603d1f7f9b1e8b3f9b8a8c33”), “name”: “Amir Abbasi”, “email”: “amir.a@example.com”, “age”: 25 } |
در این مثال، هر کاربر میتواند اطلاعات متفاوتی (مثل وجود یا عدم وجود فیلد address) داشته باشد، که همین ویژگی یکی از ویژگیهای برجسته دیتابیسهای مستندگرا است.

ویژگیهای کلیدی دیتابیسهای مستندگرا چیست؟
پایگاه دادههای Document-Oriented ویژگیها و قابلیتهایی دارند که باعث میشود نسبت به دیگر پایگاه دادهها برتری داشته باشند. در ادامه به بررسی این ویژگیها میپردازیم.
۱- مدل مستند (Document model)
همانطور که قبلتر به آن اشاره کردیم، دادهها در پایگاهدادههای مستندگرا بهصورت «سند» ذخیره میشوند. این مسئله به این معناست که برخلاف پایگاهدادههای سنتی که از ساختارهای ثابت مثل جداول یا گرافها برای ذخیرهسازی دادهها استفاده میکنند، در پایگاه دادههای مستندگرا هر داده بهصورت یک سند ذخیره میشود. این اسناد که فرمتهای مختلفی دارند (مثل JSON، BSON و غیره) ساختاری مشابه اشیاء در زبانهای برنامهنویسی دارند.
به عبارت دیگر، دادهها بهشکل مستقیم در قالب اشیاء برنامهنویسی ذخیره میشوند که این موضوع به توسعهدهندگان کمک میکند تا بهراحتی و با سرعت بیشتر برنامههای خودشان را بسازند؛ چون دادهها بهصورت مستقیم با کد برنامهنویسی ارتباط برقرار میکنند.
۲- اسکیماهای انعطافپذیر (Flexible schema)
یکی ویژگیهای مهم پایگاههای داده سندگرا این است که آنها، اسکیماهای انعطافپذیری دارند. این به این معنی است که شما هیچ نیازی به داشتن ساختار مشابه در تمام اسناد یک کالکشن ندارید. بهعنوان مثال، ممکن است در یک کالکشن اطلاعات کاربران، بعضی از اسناد شامل فیلدهایی مثل آدرس یا تاریخ تولد باشند، درحالیکه اسناد دیگر میتوانند این فیلدها را نداشته باشند. این ویژگی انعطافپذیری، بهخصوص در پروژههایی که با دادههای پیچیده یا در حال تغییر سروکار دارید، بسیار مفید است.
البته بعضی از پایگاهدادههای مستندگرا از ابزارهای اعتبارسنجی اسکیمای داده پشتیبانی میکنند که به شما این امکان را میدهد که اسکیمای دادهها را بهطور اختیاری قفل کنید و از تغییرات ناخواسته جلوگیری کنید.
۳- توزیعشده و مقاوم در برابر خرابیها (Distributed and resilient)
پایگاه دادههای مستندگرا معمولا بهصورت توزیعشده طراحی میشوند. این به این معناست که دادهها بهطور گسترده در چندین سرور یا گره (Node) پخش میشوند که این کار امکان مقیاسپذیری افقی را برایتان فراهم میکند. مقیاسپذیری افقی یعنی میتوانید بهسادگی سرورهای جدیدی را به سیستم اضافه کنید تا ظرفیت پردازش دادهها افزایش پیدا کند. این قضیه معمولا هزینه کمتری نسبت به مقیاسپذیری عمودی (افزایش ظرفیت یک سرور واحد) دارد.
همچنین، پایگاههای داده مستندگرا با استفاده از تکنیکهای تکثیر داده (replication)، از دادهها نسخههای اضافی میسازند تا در صورت خرابی سرور یا قطعی سیستم، دادهها از بین نروند و عملکرد سیستم حفظ شود.
۴- امکان جستجو و عملیات با API یا زبان کوئری
پایگاههای داده سندگرا معمولا یک API یا زبان کوئری اختصاصی دارند که به توسعهدهندگان کمک میکند تا عملیاتهای اصلی پایگاه داده مثل ایجاد، خواندن، بهروزرسانی و حذف (CRUD) را انجام دهند. همچنین، توسعهدهندگان میتوانند دادهها را براساس شناسههای یکتا (ID) یا مقادیر موجود در فیلدهای مختلف جستجو کنند. این ویژگی جستجو، توانایی پیدا کردن اسناد خاص را با سرعت بالا فراهم میکند و میتوان از آن برای فیلتر کردن دادهها و بازیابی اطلاعات مورد نیاز استفاده کرد.
چقدر کار با مستندات نسبت به جدولها آسانتر است؟
توسعهدهندگان معمولا کار با داده در قالب سندها را آسانتر و شهودیتر از کار با داده در قالب جدولها میدانند. مستندات با ساختارهای دادهای در زبانهای برنامهنویسی محبوب مطابقت دارند. این موضوع به این معناست که توسعهدهندگان نیازی ندارند دادههای مرتبط را بهصورت دستی در چندین جدول ذخیره کنند یا هنگام بازیابی دادهها، آنها را مجدد به هم متصل کنند. همچنین نیازی به استفاده از ORM (ابزارهایی که بهطور خودکار دادهها را تبدیل و مدیریت میکنند) برای دستکاری دادهها نیست. در عوض، آنها میتوانند بهراحتی و مستقیم با دادهها در برنامه خود کار کنند.
برای روشنتر شدن موضوع، بیایید نگاهی به یک مستند دیگر بیندازیم که اطلاعات مربوط به کاربری به نام «علی» را نشان میدهد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
{ “_id”: 1, “first_name”: “Ali”, “email”: “Ali@example.com”, “cell”: “123-456-7899”, “likes”: [ “math”, “game”, “Coding” ], “businesses”: [ { “name”: “Example 1234”, “status”: “Bankrupt”, “date_founded”: { “$date”: “2009-01-18T04:00:00Z” } }, { “name”: “Asa Co”, “date_founded”: { “$date”: “2010-03-21T04:00:00Z” } } ] } |
در پایگاهدادههای رابطهای، اطلاعات مشابهی که در یک سند مستندگرا ذخیره شده است، باید در چندین جدول مختلف ذخیره شوند، چون پایگاه دادههای رابطهای از دادههای ساختاریافته و با اسکیمای ازپیشتعریفشده استفاده میکنند. در این حالت، چون اطلاعات مختلفی از جمله اطلاعات کاربر، علایق و کسبوکارها وجود دارد، باید چندین جدول ایجاد کنیم تا نرمالسازی را انجام دهیم و از تکرار دادهها جلوگیری کنیم. در اینجا نحوه ذخیرهسازی اطلاعات «علی» در یک پایگاه داده رابطهای را بررسی میکنیم:
۱- جدول Users
این جدول اطلاعات پایهای کاربر مثل نام، ایمیل و شماره تلفن همراه را ذخیره میکند.
| Users | |||
| ID | name | cell | |
| 1 | Ali | Ali@example.com | 123-456-7899 |
۲- جدول Likes و User_Likes
برای ذخیره علایق کاربر، نیاز به یک جدول جداگانه داریم؛ چون یک کاربر میتواند چندین علاقه داشته باشد. در پایگاه دادههای رابطهای معمولا برای مدیریت چنین موقعیتهایی از رابطه چند به چند یا به اصطلاح Many to Many استفاده میشود. این کار با ایجاد یک جدول دوم برای ذخیره علایق و یک جدول دیگر برای ارتباط دادن کاربران به علایقشان انجام میشود.
| Likes | |
| ID | like |
| 1 | math |
| 2 | game |
| 3 | coding |
این جدول رابطه بین جدول Users و جدول Likes را برقرار میکند و هر کاربر را به علایق خود متصل میکند.
| User_Likes | |
| user_id | like_id |
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
۳- جدول Businesses و User_Businesses
ازآنجاییکه علی ممکن است چندین کسبوکار داشته باشد، به یک جدول جداگانه برای آنها و یک جدول دیگر برای ایجاد رابطه بین کسبوکارها و افراد نیاز داریم. جدول اول شامل نام کسبوکار، وضعیت و تاریخ تاسیس آن است.
| Businesses | |||
| ID | name | status | date_founded |
| 1 | Example 1234 | Bankrupt | 04:00:00 2009-01-18 |
| 2 | Asa Co | Active | 04:00:00 2010-03-21 |
این جدول رابطه بین جدول Users و جدول Businesses را برقرار میکند و نشان میدهد که کدام کسبوکارها متعلق به کدام کاربر هستند.
| User_Businesses | |
| user_id | business_id |
| 1 | 1 |
| 1 | 2 |
بهطور کلی، در مقایسه با رویکرد پایگاه دادههای مستندگرا که تمام اطلاعات کاربر را در یک سند ذخیره میکند، در این رویکرد رابطهای، نیاز به ایجاد چندین جدول برای ذخیره دادههای مرتبط داریم و از کلیدهای خارجی برای برقراری روابط بین این جداول استفاده میکنیم. مزیت این روش، نرمالسازی دادهها است، اما پیچیدگی آن بیشتر است؛ زیرا برای بازیابی دادهها باید از عملگرهای Join استفاده کنیم تا دادههای مربوطه را به هم وصل کنیم.
مزایا و معایب پایگاه دادههای مستندگرا
پایگاه دادههای Document Oriented مزایا و معایب خاص خودشان را دارند. در اینا بهطور خلاصه به بررسی آنها میپردازیم:
مزایا:
- مدل داده شهودی و راحت: دادهها بهصورت مستند ذخیره میشوند که مشابه ساختار داده در زبانهای برنامهنویسی است و به توسعهدهندگان کمک میکند تا سریعتر برنامهنویسی کنند.
- اسکیماهای انعطافپذیر: ساختار دادهها میتواند بهراحتی تغییر کند و به برنامههای در حال رشد انعطاف میدهد.
- API و زبان پرسوجوی غنی: ابزارهای قوی برای تعامل با دادهها، از جمله امکان جستجو، اضافه کردن، حذف و بهروزرسانی دادهها بهطور مستقیم در این پایگاههای داده وجود دارد.
- مقیاسپذیری و مقاومت بالا: این پایگاهها مقیاسپذیر هستند و میتوانند بهراحتی دادهها را توزیع کنند و در برابر خرابیها مقاوم باشند.
- مناسب برای استفاده عمومی: این دیتابیسها برای اکثر برنامهها که نیاز به مقیاسپذیری دارند، بسیار مناسب هستند.
معایب:
- عدم پشتیبانی از تراکنشهای ACID در چند مستند: بسیاری از پایگاه دادههای مستند از تراکنشهای پیچیده که شامل چندین سند میشوند، پشتیبانی نمیکنند که میتواند برای بعضی از برنامهها مشکلساز باشد.
- تکرار دادهها: دادهها ممکن است در چندین مستند تکرار شوند که این میتواند باعث افزایش مصرف فضای ذخیرهسازی و مشکلات همگامسازی شود.
- کمبود ویژگیهای پیشرفته پرسوجو: پایگاههای داده مستند معمولا از ویژگیهای پیچیده پایگاه دادههای رابطهای مانند جوینهای چندجدولی و زیرپرسوجوها پشتیبانی نمیکنند.
سخن آخر
در نتیجه، پایگاه داده مستند با مدل داده انعطافپذیر، مقیاسپذیری بالا و سازگاری آسان با زبانهای برنامهنویسی، گزینهای مناسب برای بسیاری از برنامههای مدرن هستند. این پایگاهها به شما اجازه میدهند تا بدون نیاز به نگرانی درباره ساختارهای پیچیده یا تراکنشهای پیچیده، بهسرعت و بهراحتی دادهها را ذخیره و مدیریت کنید.
بااینحال، برای برنامههایی که به تراکنشهای پیچیده یا جوینهای چندجدولی نیاز دارند، این مدل ممکن است محدودیتهایی داشته باشد. بنابراین، برای انتخاب پایگاه داده مستند باید به نیازهای خاص برنامه و پیچیدگی دادههای خود بیشتر توجه کنید.
منابع
سوالات متداول
از شناختهشدهترین دیتابیسهای Document-Oriented میتوان به MongoDB، CouchDB و Amazon DocumentDB اشاره کرد.
بله، ولی به شکل مستقیم مانند پایگاه دادههای رابطهای نیست. روابط معمولاً از طریق nested documents (اسناد تودرتو) یا manual references پیادهسازی میشوند و نیاز به مدیریت منطقی توسط توسعهدهنده دارند.
بله، بسیاری از دیتابیسهای مدرن مانند MongoDB در نسخههای جدید از تراکنشهای چند سندی نیز پشتیبانی میکنند، ولی پیادهسازی آنها ممکن است با دیتابیسهای رابطهای متفاوت باشد.



دیدگاهتان را بنویسید