
سریهای زمانی که نوعی از دادههای ساختاریافته بر اساس زمان هستند و در حوزههایی مانند بازارهای مالی، فروش، آبوهوا و حتی سلامت نقش مهمی ایفا میکنند. حال سوال اینجاست که چگونه میتوان از این دادهها بهدرستی استفاده کرد؟ زبان برنامهنویسی پایتون، با ابزارهای قدرتمند و کتابخانههای تخصصی خود، یکی از محبوبترین انتخابها برای تحلیل و پیشبینی سریهای زمانی بهشمار میرود. در این مقاله از بلاگ آسا، به بررسی استفاده از پایتون برای تحلیل و پیش بینی دادههای سری زمانی میپردازیم، پس تا آخر مطلب با ما همراه باشید.
دادههای سری زمانی چیست و چه ویژگیهایی دارد؟
دادههای سری زمانی (Time Series Data) به مجموعهای از دادهها گفته میشود که در فواصل زمانی مشخص ثبت یا جمعآوری شدهاند. معمولا این دادهها بر اساس زمان مرتب میشوند و همین ترتیب زمانی، ویژگی اصلی و مهم آنها به شمار میآید. قیمت روزانه سهام، آمار ماهانه فروش یک فروشگاه یا دادههای آبوهوایی سالانه، نمونههایی از دادههای سری زمانی هستند.
چیزی که دادههای سری زمانی را از سایر انواع داده متمایز میکند، ویژگیهای خاصی است که باید در تحلیل آنها مورد بررسی قرار داد. از جمله مهمترین ویژگیهای دادههای سری زمانی، میتوان به موارد زیر اشاره کرد:
- روند (Trend): نشاندهنده تغییرات بلندمدت در دادههاست. برای مثال، اگر فروش یک شرکت طی چند سال بهطور پیوسته افزایش داشته باشد، این یک روند صعودی محسوب میشود.
- فصلی بودن (Seasonality): الگوهایی هستند که در بازههای زمانی مشخص تکرار میشوند. برای مثال، معمولا فروش بستنی در تابستان افزایش پیدا میکند که این یعنی داده دارای فصلپذیری است.
- الگوهای چرخهای (Cyclic Patterns): این الگوها شبیه به فصلپذیری هستند، اما زمان مشخص و ثابتی ندارند. نوسانات ناشی از چرخههای اقتصادی که ممکن است هر چند سال یکبار رخ دهند، مثالی مشخص برای الگوهای چرخهای به شمار میآید.
- مولفههای تصادفی (Irregular Components): تغییرات غیرقابل پیشبینی یا تصادفی که در دادهها دیده میشود و ممکن است ناشی از رویدادهای ناگهانی باشد. از جمله مولفههای تصادفی میتوان به بحرانهای اقتصادی یا بلایای طبیعی اشاره کرد.
چرا از پایتون برای تحلیل دادههای سری زمانی استفاده کنیم؟
پایتون در سالهای اخیر به یکی از محبوبترین زبانها برای تحلیل دادههای سری زمانی تبدیل شده است و این محبوبیت بیدلیل نیست. ترکیب سادگی در یادگیری، پشتیبانی قوی از کتابخانههای تخصصی و جامعه فعال برنامهنویسان، پایتون را به ابزاری قدرتمند و انعطافپذیر برای تحلیل دادههای زمانی تبدیل کرده است. در ادامه مهمترین دلایل استفاده از پایتون برای تحلیل دادههای سری زمانی را توضیح میدهیم:
- سهولت استفاده از پایتون: این زبان با ساختاری واضح و نگارشی نزدیک به زبان انسان، حتی برای افراد مبتدی نیز قابل فهم است. همین ویژگی باعث میشود که تمرکز برنامهنویس یا تحلیلگر، بهجای پیچیدگیهای فنی، روی خود تحلیل دادهها قرار بگیرد.
- متن باز بودن زبان پایتون: متن باز بودن زبان پایتون به این معناست که استفاده از آن رایگان است و هزاران توسعهدهنده در سراسر جهان بهصورت مداوم در حال بهبود و توسعه ابزارها و کتابخانههای مرتبط با آن هستند. این جامعه فعال باعث شده پایتون به گنجینهای از منابع و آموزشها برای تحلیل سریهای زمانی تبدیل شود.
- کتابخانههای تخصصی: غنی بودن کتابخانه پیتون و ارائه ابزارهایی مانند pandas برای پردازش و مدیریت دادهها، NumPy برای محاسبات عددی، statsmodels برای مدلسازی آماری و scikit-learn برای یادگیری ماشین، به تحلیلگر این امکان را میدهند که در سریهای زمانی به سراغ مسائل پیچیده برود.
- امکان استفاده مجدد از کدهای موجود: بسیاری از فرایندهای تکراری مانند خواندن و پاکسازی دادهها، ترسیم نمودارها یا ساخت مدلهای اولیه، قبلا توسط جامعه توسعهدهنده نوشته شده است، بنابراین کاربران میتوانند بهصورت آماده از آنها استفاده کنند. این موضوع زمان تحلیل را کاهش میدهد و حتی احتمال خطا را نیز پایین میآورد.
چگونه دادههای سری زمانی را در پایتون تحلیل کنیم؟
تحلیل دادههای سری زمانی در پایتون را با یک فرایند چند مرحلهای انجام میدهند. این فرایند از آمادهسازی و نمایش اولیه دادهها آغاز میشود و تا مدلسازی و پیشبینی ادامه پیدا میکند. در این بخش از مقاله، مراحل مختلف تحلیل را با هم طی میکنیم تا ببینیم چگونه میتوان با کمک پایتون، از دادههای زمانی به اطلاعات قابل استفاده و بینشهای ارزشمند رسید. برای این آموزش، از یک مجموعهداده ساده و کاربردی استفاده میکنیم که شامل تعداد مسافران خطوط هوایی در طول زمان میشود.
۱. خواندن و نمایش اولیه دادهها
نخستین قدم در هر پروژه تحلیل داده، وارد کردن دادهها به محیط کاری است. در این مثال، ما از کتابخانه قدرتمند pandas استفاده میکنیم که ابزاری استاندارد در دنیای تحلیل داده با پایتون است. با استفاده از تابع ()read_csv، دادهها را از فایل CSV وارد میکنیم:
|
1 2 3 |
import pandas as pd df = pd.read_csv(“AirPassengers.csv”) print(df.head()) |
| #Passengers | Month | |
| 112 | 1949-01 | 0 |
| 118 | 1949-02 | 1 |
| 132 | 1949-03 | 2 |
| 129 | 1949-04 | 3 |
| 121 | 1949-05 | 4 |
با اجرای این کد، پنج ردیف اول داده به ما نمایش داده میشود. همانطور که میبینیم، ستون اول باعنوان «Month» شامل تاریخهایی به فرمت سال-ماه است و ستون دوم «#Passengers» تعداد مسافران هر ماه را نشان میدهد. حالا اگر از تابع tail() استفاده کنیم، متوجه میشویم که این دادهها از ژانویه ۱۹۴۹ آغاز و تا دسامبر ۱۹۶۰ ادامه دارند:
|
1 |
print(df.tail()) |
| #Passengers | Month | |
| 606 | 1960-08 | 139 |
| 508 | 1960-09 | 140 |
| 461 | 1960-10 | 141 |
| 390 | 1960-11 | 142 |
| 432 | 1960-12 | 143 |
برای آنکه بتوانیم راحتتر با اطلاعات زمانی کار کنیم، ابتدا ستون Month را به نوع داده datetime تبدیل میکنیم. این کار به ما اجازه میدهد تا بهصورت برنامهنویسی، اطلاعاتی مثل سال یا ماه را از هر ردیف استخراج کنیم:
|
1 2 |
df[‘Month’] = pd.to_datetime(df[‘Month’], format=‘%Y-%m’) print(df.head()) |
در این مرحله توجه داشته باشید که چون اطلاعات بهصورت ماهیانه هستند، پایتون بهصورت خودکار روز اول هر ماه (مثلا 1949-01-01) را بهعنوان مقدار پیشفرض در نظر میگیرد.
در گام بعد، برای سادهتر شدن تحلیلهای بعدی، ستون Month را بهعنوان ایندکس (شاخص ردیفها) در نظر میگیریم. این کار باعث میشود بسیاری از توابع و کتابخانههای تحلیل سری زمانی بهتر با دادهها کار کنند:
|
1 2 3 |
df.index = df[‘Month’] del df[‘Month’] print(df.head()) |
| #Passengers | |
| Month | |
| 112 | 1949-01-01 |
| 118 | 1949-02-01 |
| 132 | 1949-03-01 |
| 129 | 1949-04-01 |
| 121 | 1949-05-01 |
حالا که دادهها آماده شدهاند، نوبت به مرحله تصویرسازی میرسد. با استفاده از دو کتابخانه محبوب Matplotlib و Seaborn، میتوانیم یک نمودار خطی از روند تغییرات تعداد مسافران در طول زمان ترسیم کنیم. ابتدا کتابخانههای Matplotlib و Seaborn را ایمپورت میکنیم:
|
1 2 |
import matplotlib.pyplot as plt import seaborn as sns |
سپس با استفاده از Seaborn یک نمودار خطی رسم میکنیم:
|
1 |
sns.lineplot(data=df) |
با کمک Matplotlib محور y را نامگذاری میکنیم:
|
1 |
plt.ylabel(“Number of Passengers”) |

۲.بررسی ایستایی (Stationarity)
ایستایی یکی از مفاهیم کلیدی در تحلیل سریهای زمانی است. به زبان ساده، یک سری زمانی ایستا، به شکلی رفتار میکند که نحوه تغییرات آن در طول زمان ثابت باقی میماند. یعنی در سری ایستا، خبری از روندها (Trend) یا الگوهای فصلی (Seasonality) نیست.
بررسی ایستایی اهمیت زیادی دارد، زیرا بسیاری از روشهای پیشبینی سریهای زمانی (مانند مدلهای ARMA، ARIMA و SARIMA) فرض را بر این میگیرند که دادهها ایستا هستند. اگر این فرض برقرار نباشد، خروجی مدلها قابل اعتماد نیست.
برای بررسی ایستایی، ما از آزمون دیکی-فولر (Dickey-Fuller) استفاده میکنیم. این آزمون مقادیری مثل مقدار آماره آزمون و مقدار p-value را به ما میدهد تا بتوانیم فرضیه صفر را (که میگوید سری زمانی ایستا نیست) تایید یا رد کنیم. اگر فرضیه صفر رد شود، یعنی سری ایستا است.
این مقادیر به ما کمک میکنند تشخیص دهیم که آیا مقدار فعلی دادهها به مقدار گذشته آنها وابسته است؟ اگر سری ایستا نباشد، تغییرات مقادیر فعلی باعث تغییر قابل توجهی در مقادیر قبلی نمیشود. اکنون میخواهیم ایستایی را روی دادههای مسافران خطوط هوایی بررسی کنیم. در ابتدا، میانگین و انحراف معیار متحرک هفتماهه را محاسبه میکنیم:
|
1 2 |
rolling_mean = df.rolling(7).mean() rolling_std = df.rolling(7).std() |
در مرحله بعد، نمودار سری زمانی را همراه با میانگین متحرک و انحراف معیار متحرک ترسیم میکنیم. ابتدا نمودار سری اصلی:
|
1 |
plt.plot(df, color=“blue”,label=“Original Passenger Data”) |
سپس نمودار میانگین متحرک:
|
1 |
plt.plot(rolling_mean, color=“red”, label=“Rolling Mean Passenger Number”) |
در ادامه، نمودار انحراف معیار متحرک:
|
1 |
plt.plot(rolling_std, color=“black”, label = “Rolling Standard Deviation in Passenger Number”) |
حالا عنوان نمودار را اضافه میکنیم:
|
1 |
plt.title(“Passenger Time Series, Rolling Mean, Standard Deviation”) |
و در نهایت، نمایش راهنمای نمودار (legend):
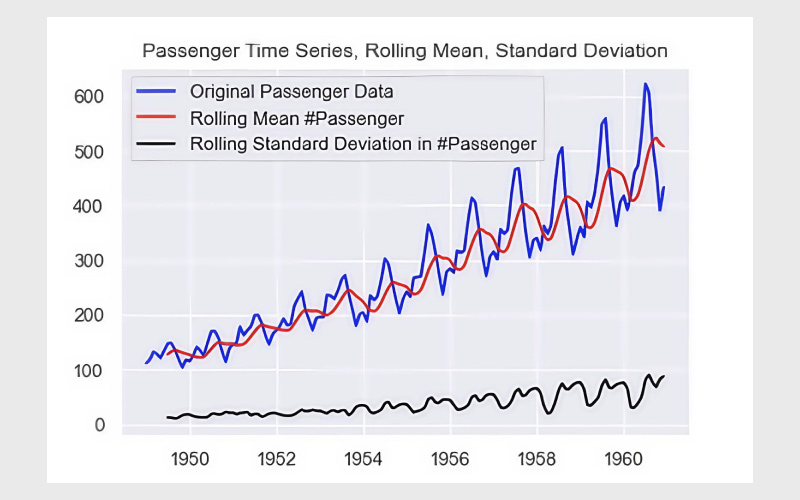
اکنون نوبت به اجرای آزمون دیکی-فولر رسیده است. ابتدا ماژول مورد نیاز را از statsmodels وارد میکنیم:
|
1 |
from statsmodels.tsa.stattools import adfuller |
سپس دادهها را به تابع adfuller میدهیم. در اینجا از پارامتر autolag=”AIC” استفاده میکنیم تا بهترین مقدار lag بهصورت خودکار انتخاب شود:
|
1 |
adft = adfuller(df,autolag=“AIC”) |
در نهایت، نتایج آزمون را در یک دیتافریم ذخیره و نمایش میدهیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# فرض کنید adft خروجی تابع adfuller است adf_stat, p_value, used_lag, n_obs, critical_values, icbest = adft output_df = pd.DataFrame({ “Metric”: [ “Test Statistic”, “p-value”, “No. of lags used”, “Number of observations used”, “Critical value (1%)”, “Critical value (5%)”, “Critical value (10%)” ], “Value”: [ adf_stat, p_value, used_lag, n_obs, critical_values[‘1%’], critical_values[‘5%’], critical_values[‘10%’] ] }) print(output_df) |
| Metric | Values | |
| Test Statistics | 0.815369 | 0 |
| p-value | 0.991880 | 1 |
| No. of lags used | 13.000000 | 2 |
| Number of observations used | 130.000000 | 3 |
| critical value (1%) | 3.481682- | 4 |
| critical value (5%) | 2.884042- | 5 |
| critical value (10%) | 2.578770- | 6 |
با بررسی خروجی این آزمون مشاهده میکنید که مقدار p-value بیشتر از ۵٪ است و همچنین آمار آزمون بیشتر از مقدار بحرانی است. در واقع فرضیه صفر رد نشده و سری زمانی ما ایستا نیست. این موضوع از روی نمودار نیز قابل مشاهده است، زیرا روند افزایشی مشخصی در تعداد مسافران دیده میشود.
۳. بررسی خودهمبستگی (Autocorrelation)
خودهمبستگی یکی دیگر از مفاهیم کلیدی در تحلیل سریهای زمانی است. در واقع خودهمبستگی به این معناست که دادههای فعلی تا چه اندازه با دادههای قبلی خود همبستگی دارند. به بیان دیگر، اگر امروز مقدار یک متغیر و خودهمبستگی بالا باشد، میتوان انتظار داشت که فردا هم مقدار بالایی دارد.
در بسیاری از صنایع، این ویژگی اهمیت زیادی دارد. برای مثال، اگر دادههای تعداد مسافر خطوط هوایی خودهمبستگی زیادی داشته باشند، میتوان گفت که تعداد زیاد مسافر در یک ماه، احتمال تعداد زیاد در ماه بعد را هم بالا میبرد.
پانداس یک متد داخلی برای محاسبه خودهمبستگی دارد که میتوان از آن برای بررسی تاخیرهای مختلف استفاده کرد. ابتدا خودهمبستگی با تاخیر یکماهه را بررسی میکنیم:
|
1 |
autocorrelation_lag1 = df[‘#Passengers’].autocorr(lag=1) |
| 0.9601946480498523 | One Month Lag: |
|
1 |
print(“One Month Lag: “, autocorrelation_lag1) |
حالا همین محاسبه را برای تأخیرهای سه، شش و نهماهه انجام میدهیم:
|
1 2 3 4 5 6 |
autocorrelation_lag3 = df[‘#Passengers’].autocorr(lag=3) print(“Three Month Lag: “, autocorrelation_lag3) autocorrelation_lag6 = df[‘#Passengers’].autocorr(lag=6) print(“Six Month Lag: “, autocorrelation_lag6) autocorrelation_lag9 = df[‘#Passengers’].autocorr(lag=9) print(“Nine Month Lag: “, autocorrelation_lag9 |
| 0.837394765081794 | Three Month Lag: |
| 0.7839187959206183 | Six Month Lag: |
| 0.8278519011167601 | Nine Month lag: |
خروجی این محاسبات نشان میدهد که حتی با گذشت نه ماه هم دادهها همچنان خودهمبستگی بالایی دارند. این موضوع روندهای کوتاهمدت و بلندمدت در دادههای مسافران را نشان میدهد.
۴. تجزیه سری زمانی (Decomposition)
تجزیه روند (Decomposition) یکی از روشهای بسیار موثر برای درک بهتر سریهای زمانی محسوب میشود. برای شروع، ابتدا تابع seasonal_decompose را از کتابخانه statsmodels ایمپورت میکنیم:
|
1 |
from statsmodels.tsa.seasonal import seasonal_decompose |
سپس دادهها را به این تابع میدهیم و نتیجه را ترسیم میکنیم:
|
1 2 3 |
decompose = seasonal_decompose(df[‘#Passengers’],model=‘additive’, period=7) decompose.plot() plt.show() |
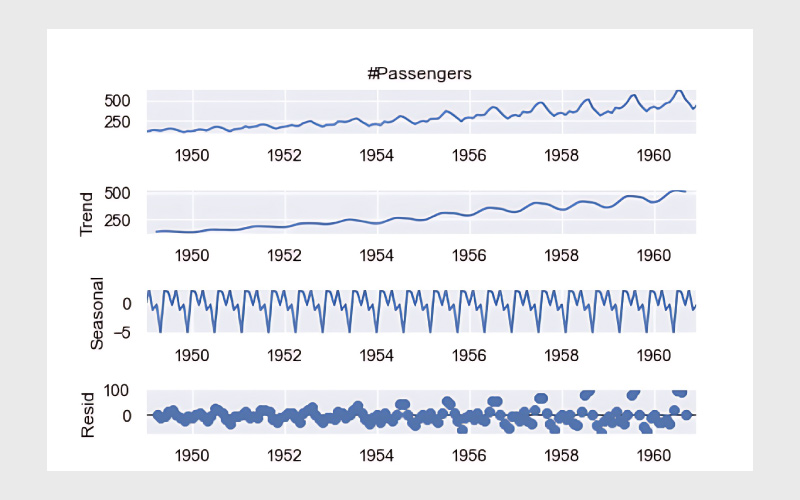
از این نمودار بهوضوح میتوانیم روند افزایشی تعداد مسافران و همچنین الگوهای فصلی (کاهش و افزایش مقادیر در هر سال) را مشاهده کنیم.
۵. پیشبینی سری زمانی (Forecasting)
پیشبینی در سریهای زمانی، یکی از اهداف اصلی تحلیل دادههای زمانی است. در این مرحله، میخواهیم با استفاده از روش ARIMA آینده تعداد مسافران را پیشبینی کنیم. روش ARIMA بر پایه ترکیبی خطی از مقادیر گذشته دادهها کار میکند.
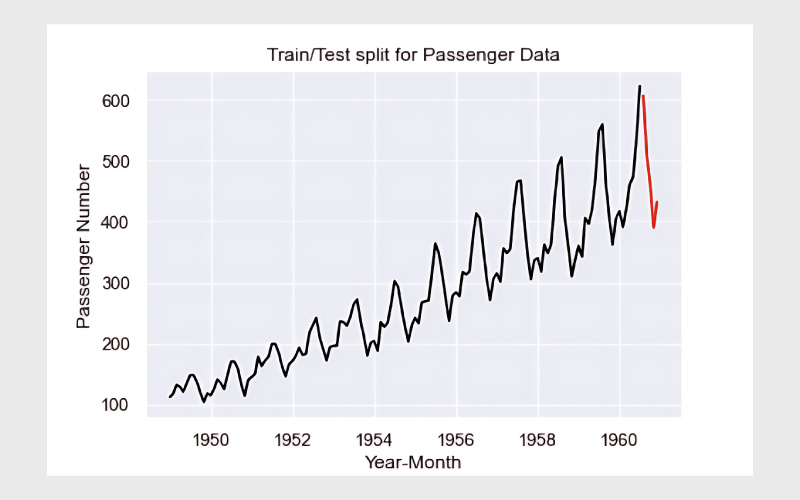
برای سادهتر کردن فرایند انتخاب پارامترها، از پکیج auto_arima استفاده میکنیم. این پکیج بهطور خودکار بهترین پارامترهای مدل را با توجه به دادهها انتخاب میکند و دیگر نیازی به تنظیمات دستی و زمانبر نیست. در ابتدا دادهها را به دو بخش آموزشی (Train) و آزمایشی (Test) تقسیم و آن را رسم میکنیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
df[‘Date’] = df.index train = df[df[‘Date’] < pd.to_datetime(“1960-08”, format=‘%Y-%m’)] train[‘train’] = train[‘#Passengers’] del train[‘Date’] del train[‘#Passengers’] test = df[df[‘Date’] >= pd.to_datetime(“1960-08”, format=‘%Y-%m’)] del test[‘Date’] test[‘test’] = test[‘#Passengers’] del test[‘#Passengers’] plt.plot(train, color = “black”) plt.plot(test, color = “red”) plt.title(“Train/Test split for Passenger Data”) plt.ylabel(“Passenger Number”) plt.xlabel(‘Year-Month’) sns.set() plt.show() |
در این نمودار، خط سیاه نمایانگر دادههای آموزشی و خط قرمز نمایانگر دادههای آزمایشی است. اکنون مدل ARIMA را آموزش میدهیم و پیشبینی را انجام میدهیم. ابتدا تابع auto_arima را ایمپورت میکنیم، مدل را آموزش میدهیم و در نهایت پیشبینیها را تولید میکنیم:
|
1 |
from pmdarima.arima import auto_arima |
|
1 2 3 4 |
model = auto_arima(train, trace=True, error_action=‘ignore’, suppress_warnings=True) model.fit(train) forecast = model.predict(n_periods=len(test)) forecast = pd.DataFrame(forecast,index = test.index,columns=[‘Prediction’]) |
در تصویر زیر نمونه خلاصهشده از خروجی را مشاهده میکنید:
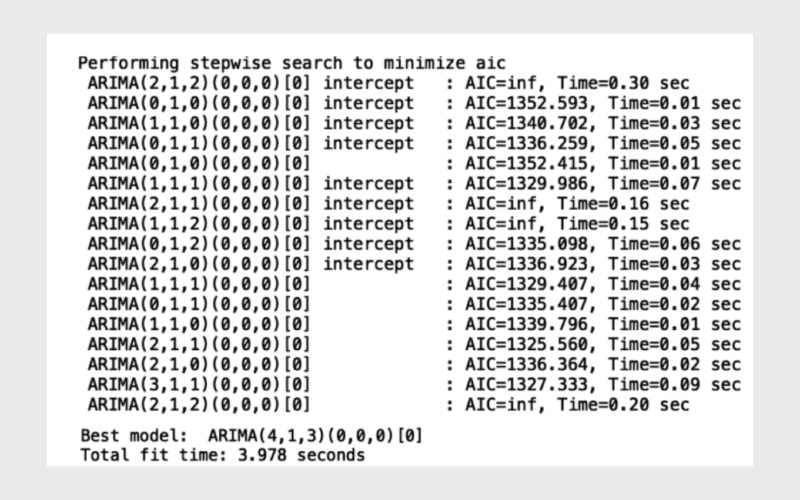
حالا بیایید نتایج مدل را نمایش دهیم:
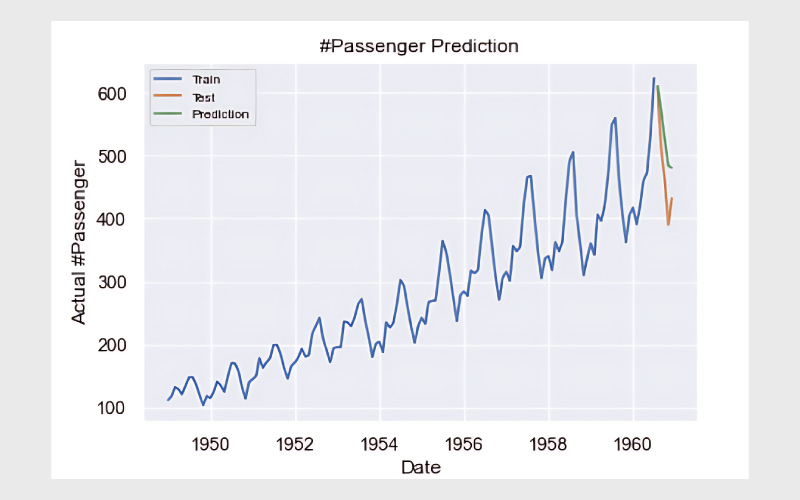
پیشبینیهای ما با رنگ سبز و مقادیر واقعی با رنگ نارنجی نمایش داده شدهاند. در نهایت، برای بررسی دقت مدل، مقدار خطای RMSE (ریشه میانگین مربعات خطا) را محاسبه میکنیم:
|
1 2 3 4 |
from math import sqrt from sklearn.metrics import mean_squared_error rms = sqrt(mean_squared_error(test,forecast)) print(“RMSE: “, rms) |
| 61.36535942376535 | RMSE: |
اهمیت تحلیل سریهای زمانی در پایتون
تحلیل سریهای زمانی یکی از مهمترین وظایفی است که تقریباً هر متخصص داده در طول مسیر حرفهای خود با آن روبرو میشود. تسلط بر ابزارها و روشهای مرتبط با این نوع تحلیل، به دانشمندان و متخصصان این حوزه کمک میکند که در مرحله اول بتوانند الگوهای پنهان را کشف و سپس با شناسایی روندها، تصمیمات آگاهانهتری اتخاذ کنند.
در کنار اینها، درک الگوهای فصلی از طریق مفاهیمی مانند ایستایی (stationarity)، خودهمبستگی (autocorrelation) و تجزیه روند (trend decomposition) میتواند به برنامهریزی موثر برای تبلیغات در طول سال منجر شود که این امر به نوبه خود سودآوری شرکتها را افزایش میدهد.
در نهایت، پیشبینی (forecasting) بهعنوان قدرتمندترین بخش این تحلیلها، به ما این توانایی را میدهد تا اتفاقات آینده را با دقت بالاتری پیشبینی کنیم. در واقع این همان چیزی است که بسیاری از تصمیمگیریهای کلان را متحول میکند.
چنین تحلیلهایی، سرمایهای ارزشمند برای هر تیم علم داده است که میخواهد از دل دادههای زمانی، ارزش واقعی استخراج کند و تصمیمات تجاری را به سطح بالاتری ببرد.
کلام آخر
تحلیل سریهای زمانی یکی از کلیدیترین ابزارها در جعبهابزار هر متخصص داده است که به درک عمیقتر از گذشته و پیشبینی دقیقتر آینده کمک میکند. پایتون با پشتیبانی از کتابخانههای قدرتمند و جامعهای فعال، این فرایند را آسانتر و کارآمدتر کرده است.
با رشد روزافزون دادههای زمانی در حوزههایی مانند مالی، سلامت، بازاریابی و لجستیک، توانایی تحلیل درست این نوع دادهها میتواند به تصمیمات هوشمندانهتر و مزیت رقابتی منجر شود. در واقع چه برای کشف روندهای پنهان و الگوهای فصلی و چه برای پیشبینی آینده، استفاده از پایتون بهعنوان ابزار اصلی، مسیری سریع، دقیق و قابلاعتماد را برای تحلیلگران و شرکتها فراهم میکند.
منابع
builtin.com | medium.com | tigerdata.com
سوالات متداول
یکی از روشهای رایج استفاده از آزمون ADF (Augmented Dickey-Fuller) است که در کتابخانه statsmodels قابل اجراست. اگر مقدار p-value کمتر از ۰.۰۵ باشد، سری ایستا تلقی میشود.
مهمترین مراحل عبارتاند از:
– بررسی و پاکسازی دادهها
– بررسی ایستایی
– نرمالسازی یا استانداردسازی دادهها (برای مدلهای یادگیری ماشین)
– تقسیمبندی دادهها به آموزش و تست
پایتون ابزارهای بسیار قدرتمندی برای تحلیل سریهای زمانی دارد. پرکاربردترین آنها عبارتاند از:
pandas برای مدیریت و پردازش دادههای زماندار
statsmodels برای مدلهای آماری مانند ARIMA و آزمونهای ایستایی
scikit-learn برای یادگیری ماشین
prophet (توسعهیافته توسط متا) برای پیشبینی خودکار
matplotlib و seaborn برای مصورسازی


دیدگاهتان را بنویسید