
انتخاب مناسبترین پایگاه داده (Database)، یکی از تصمیمات مهم در طراحی و توسعه نرمافزارها و سامانههای اطلاعاتی است. در واقع هر دیتابیس، ویژگیها، مزایا و محدودیتهای خاص خود را دارد و انتخاب نادرست آن از میان رایجترین دیتابیسها میتواند تاثیر زیادی بر عملکرد و مقیاسپذیری پروژه داشته باشد.
اگر در حال انتخاب یک پایگاه داده برای پروژه خود هستید یا میخواهید شناخت خود را از این حوزه افزایش دهید، این راهنما میتواند شروع خوبی برای شما باشد. در ادامه این مطلب از بلاگ آسا، همراه ما باشید تا رایجترین دیتابیسها را به همراه مزایا و معایب هرکدام با هم بررسی کنیم.
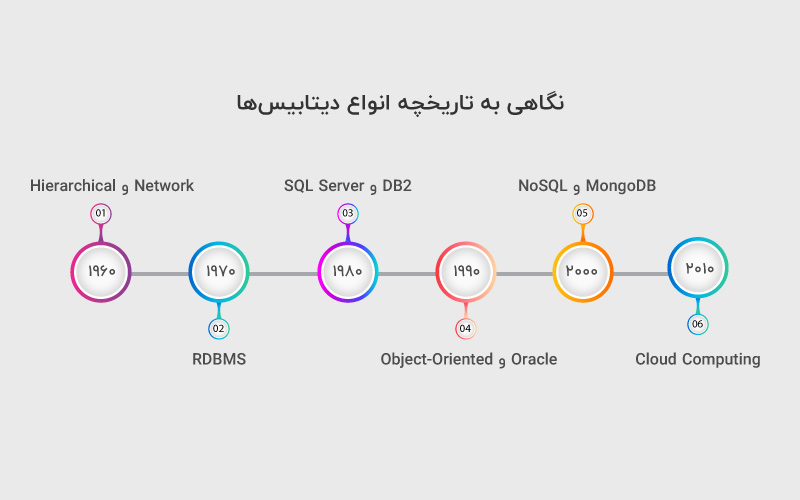
نگاهی به تاریخچه انواع دیتابیسها
در گذشته، اطلاعات تنها روی کاغذ ثبت میشد و بایگانیهای بزرگ، دفاتر ثبت و اسناد کاغذی، ابزار اصلی ذخیره اطلاعات بودند. این روشهای کند و زمانبر مشکلاتی مانند گمشدن اطلاعات، خرابی فیزیکی و عدم امنیت کافی به وجود میآوردند. هدف از ایجاد پایگاه دادهها، نیاز شدید به ذخیرهسازی بهتر، سریعتر و ایمنتر اطلاعات بود.
پیدایش پایگاه داده، پاسخی به این چالشها بود. سیستمهای اولیه، دادهها را در قالب رکوردها و فیلدها ساختاربندی کردند و بهتدریج مدلهای مختلفی برای نگهداری این دادهها شکل گرفت. در ادامه، روند تکامل دیتابیس از ابتدا تا امروز را مرور میکنیم:
- دهه ۱۹۶۰: اولین مدلهای پایگاه داده با ساختار سلسلهمراتبی (Hierarchical) و شبکهای (Network) معرفی شدند. شرکت IBM سیستم IMS را توسعه داد و سامانه SABRE برای مدیریت رزرو پروازهای American Airlines ساخته شد.
- ۱۹۶۹: IBM اولین سیستم Mainframe خود به نام System/360 را عرضه کرد.
- ۱۹۷۰ تا ۱۹۷۲: ایده پایگاه داده رابطهای (RDBMS) توسط E.F. Codd معرفی شد. او مفهومی را ارائه داد که ساختار منطقی پایگاه داده را از ذخیرهسازی فیزیکی جدا میکرد.
- دهه ۱۹۷۰: دو نمونه اولیه مهم از جمله INGRES (با زبان کوئری QUEL، که بعدها منجر به شکلگیری سیستمهایی مانند SQL Server، Sybase و Britton-Lee شد) و System R (از IBM که زبان SEQUEL را توسعه داد و پایهگذار SQL شد) توسعه یافتند.
- ۱۹۷۶: مدل مفهومی ERD (نمودار موجودیت-رابطه) توسط P. Chen معرفی شد.
- دهه ۱۹۸۰: زبان SQL به استاندارد اصلی تبدیل شد و سیستمهایی مانند DB2 توسط IBM به بازار عرضه شدند. همزمان، سیستمهایی مانند RBASE 5000 و PARADOX هم معرفی شدند.
- اوایل دهه ۹۰: با شکلگیری ابزارهای توسعه مانند Oracle Developer، Visual Basic و PowerBuilder، صنعت پایگاه داده متحول شد. همچنین ODBC و برنامههایی مثل Excel و Access رواج یافتند.
- اواسط دهه ۹۰: گسترش اینترنت باعث رشد چشمگیر صنعت پایگاه داده شد. سیستمهای Client/Server رواج پیدا کردند.
- اواخر دهه ۹۰: ورود ابزارهایی مانند ASP، Java Servlets و MySQL، مفهوم پایگاه داده آنلاین را عمومی کرد. راهحلهای متنباز محبوب شدند و OLTP و OLAP رشد کردند.
- دهه ۲۰۰۰: توسعه نرمافزارهای تعاملی، ابزارهای فروش و یکپارچهسازی بازار پایگاه داده ادامه یافت.
- وضعیت فعلی: شرکتهای مایکروسافت، اوراکل و IBM، پیشتازان بازار پایگاه داده هستند.
معرفی رایجترین دیتابیسها
دیتابیسها نقشی اساسی در ذخیرهسازی و مدیریت دادهها دارند و بخش جداییناپذیر از زیرساخت هر نرمافزاری هستند. انتخاب دیتابیس مناسب به عوامل مختلفی مانند نوع پروژه، حجم دادهها و نیازهای مقیاسپذیری بستگی دارد. در این بخش، با رایجترین دیتابیسهای جهان که بهطور گسترده در توسعه نرمافزار استفاده میشوند، آشنا میشویم. هرکدام از این دیتابیسها ویژگیها و کاربردهای خاص خود را دارند که در ادامه به طور مختصر بررسی خواهیم کرد.
Hierarchical Databases
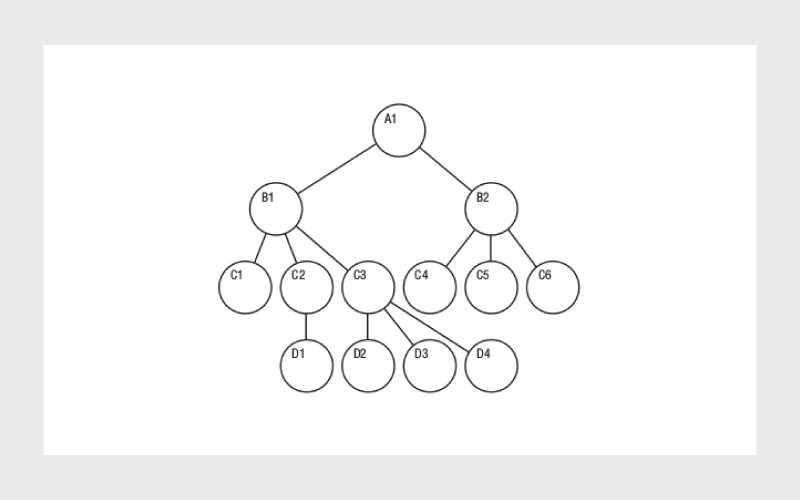
پایگاه داده سلسلهمراتبی (Hierarchical) یکی از اولین مدلهای ذخیرهسازی داده است که در دهه ۱۹۶۰ توسعه یافت. همانطور که از نام این دیتابیسها مشخص است، ساختار آنها شباهت زیادی به درخت خانوادگی دارد، یعنی هر رکورد والد میتواند دارای چندین رکورد فرزند باشد، اما هر رکورد فرزند فقط به یک والد متصل است.
این ساختار باعث میشود مسیر دسترسی به دادهها واضح و قابل پیشبینی باشد، اما در عین حال محدودیتهایی را در نمایش روابط پیچیده تحمیل میکند. ازجمله مهمترین نمونههای استفادهشده میتوان به Windows Registry، IBM IMS، فایلهای مسیریابی، XML و XAML اشاره کرد.
| مزایا | معایب |
| بازیابی سریع و کارآمد اطلاعات | عدم پشتیبانی از روابط پیچیده مانند many-to-many |
| ساختار قابل پیشبینی برای ذخیره و جستجو | تغییر ساختار یا افزودن روابط جدید، بسیار دشوار است |
| افزودن یا حذف دادهها بهسادگی انجام میشود | مقیاسپذیری محدودی دارد و برای نیازهای امروزی انعطافپذیری کمی دارد |
Object-Oriented Databases
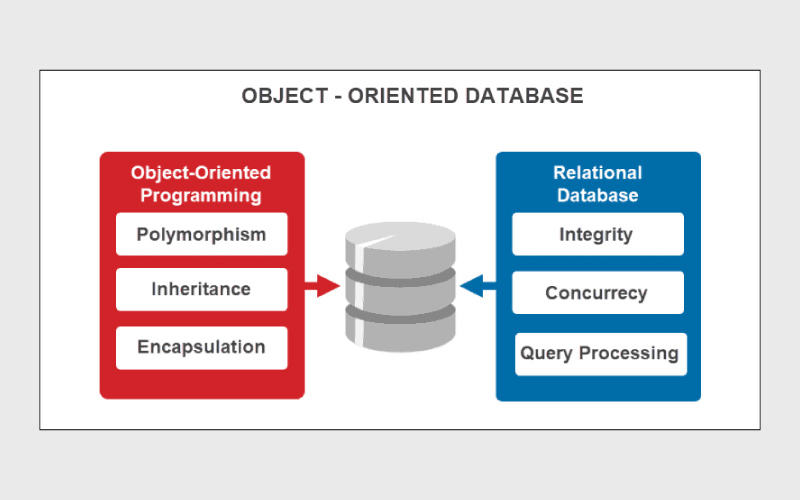
پایگاه داده شیگرا (Object-Oriented Database) براساس اصول برنامهنویسی شیگرا طراحی شده است. در این مدل، دادهها در قالب اشیائی که شامل ویژگیها (attributes) و متدها (methods) هستند، ذخیره میشوند.
این نوع پایگاه داده برای برنامههای شیگرای پیچیده بسیار مناسب است و امکان مدلسازی روابط و ساختارهای پیشرفته را بهصورت طبیعی فراهم میکند. همچنین ObjectDB، Db4o، Oracle، IBM DB2 و Dbase از جمله مهمترین و رایجترین دیتابیسهای Object-Oriented Databases به شمار میآیند.
| مزایا | معایب |
| نمایش طبیعی روابط پیچیده بین دادهها | عملکرد نهچندان بهینه در مجموعهدادههای ساده |
| مدیریت کارآمد ساختارهای داده تودرتو و پیچیده | پیچیدگی در پیادهسازی و نگهداری |
| افزایش سرعت توسعه در برنامههای شیگرا | نرخ پذیرش کمتر نسبت به پایگاههای داده رابطهای رایج |

Network Databases
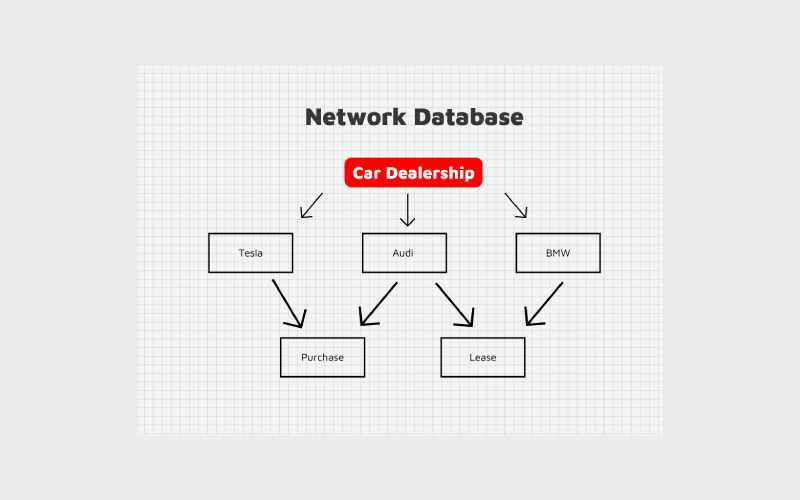
پایگاه داده شبکهای (Network Database) ساختاری مشابه مدل سلسلهمراتبی دارد، اما با این تفاوت که یک رکورد فرزند میتواند به چندین رکورد والد متصل باشد. این ارتباط دوطرفه، امکان ایجاد روابط many-to-many که در مدلهای قدیمیتر ممکن نبود را فراهم میکند.
این مدل برای سیستمهایی با ساختار داده پیچیده و روابط درهمتنیده بسیار مناسب است. از جمله نمونههای شناختهشده آن، میتوان به IDS (Integrated Data Store) و EDMS توسط Xerox اشاره کرد.
| مزایا | معایب |
| پشتیبانی از ساختارهای پیچیده و روابط چندبهچند | به ساختار از پیشتعریفشده وابستگی بسیار زیادی دارد |
| نسبت به مدل سلسلهمراتبی انعطافپذیرتر است | تغییر در ساختار یا افزودن رابطه جدید، زمانبر و دشوار است |
| مناسب برای چارچوبهای داده تودرتو | پیچیدگی در طراحی و نگهداری سیستم |
MySQL

MySQL یک سیستم مدیریت پایگاه داده رابطهای (RDBMS) متنباز است که در سال ۱۹۹۴ توسط شرکت سوئدی MySQL AB توسعه یافت. این سیستم بعدها توسط Sun Microsystems و سپس توسط Oracle خریداری شد. در ابتدا، MySQL بهصورت اختصاصی عرضه شد، اما بعدا تحت مجوز GNU GPL متنباز شد. این دیتابیس یکی از محبوبترین گزینهها برای توسعه وب است و در بسیاری از پروژههای کوچک و متوسط به کار میرود.
| مزایا | معایب |
| رایگان و متنباز، مناسب برای شرکتها و تیمهایی با بودجه محدود | برای پردازشهای لحظهای (Real-Time) یا برنامههایی با دسترسپذیری بالا طراحی نشده است |
| پشتیبانی گسترده توسط شرکتهای ارائهدهنده هاستینگ | مقیاسپذیری پایین؛ برای دادههای حجیم مناسب نیست |
| رابط کاربری ساده و قابل فهم، مناسب برای مبتدیها | فاقد پشتیبانی داخلی از جستجوی متنی پیشرفته یا دادههای مکانی |
| جامعه کاربری بزرگ و فعال با منابع آموزشی زیاد | برخی از امکانات پیشرفته که در سایر دیتابیسها وجود دارد را ارائه نمیدهد |
PostgreSQL

PostgreSQL یا بهاختصار Postgres، یک سیستم مدیریت پایگاه داده شی-رابطهای (Object-Relational) و متنباز است که در سال ۱۹۸۶ توسط تیمی از پژوهشگران دانشگاه کالیفرنیا توسعه یافت. این سیستم بهدلیل قابلیت اطمینان، عملکرد بالا و انعطافپذیری، محبوبیت زیادی در میان توسعهدهندگان حرفهای دارد. اگر برنامه شما به ویژگیهای پیشرفته، تراکنشهای پیچیده و تحمل بار بالا نیاز دارد، Postgres گزینهای مناسب به شمار میآید.
| مزایا | معایب |
| متنباز و رایگان با جامعهای فعال | یادگیری آن نسبت به MySQL پیچیدهتر است |
| عملکرد بالا در شرایط بار سنگین؛ مناسب برای مقیاسپذیری و دسترسپذیری بالا | ممکن است نسبت به دیتابیسهای NoSQL از نظر سرعت و مقیاسپذیری ضعیفتر عمل کند |
| پشتیبانی از امکانات پیشرفته مانند تریگرها، پروسیجرها و تراکنشهای چند رکوردی | پشتیبانی فناوری محدودتر نسبت به سایر دیتابیسها مانند MySQL |
NoSQL Databases
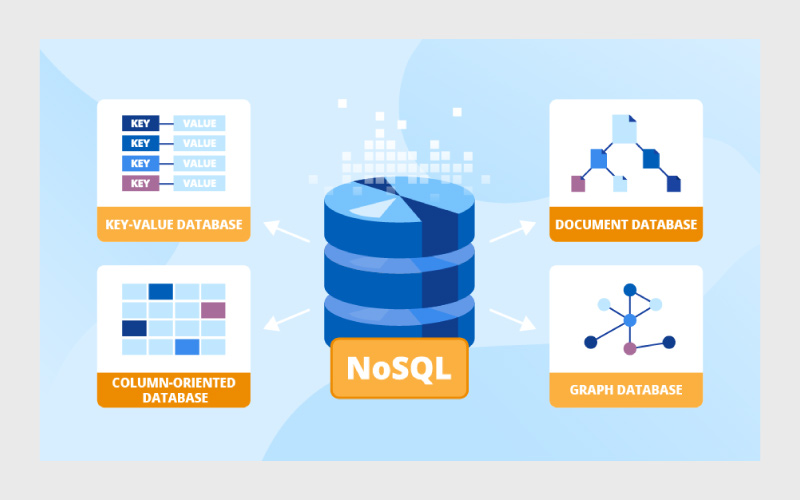
پایگاه داده NoSQL (مخفف Not Only SQL) از انواع سیستم مدیریت پایگاه داده است که برای پاسخ به نیازهای مقیاسپذیری بالا، عملکرد سریع و انعطافپذیری در مدلسازی داده طراحی شدهاند. دیتابیسهای Redis و Elasticsearch از جمله مهمترین و رایجترین دیتابیسهای NoSQL که میتوانید از مزایای بسیار عالی آنها استفاده کنید.
NoSQL برخلاف پایگاههای داده رابطهای که ساختاری ثابت و مبتنی بر جداول دارند، به شما اجازه میدهد تا دادههای بدون ساختار یا نیمهساختاریافته را در قالبهایی مانند سند (Document)، کلید-مقدار (Key-Value)، ستونمحور (Column-oriented) یا گراف (Graph) ذخیره کنید.
این نوع از دیتابیسها، برای توسعهدهندگانی که نیاز به سرعت در پیادهسازی، توانایی تغییر سریع ساختار دادهها و کار با حجمهای بزرگ از داده دارند، گزینهای بسیار مناسب به شمار میآیند. همچنین ازآنجاییکه این پایگاهها اغلب در محیطهای توزیعشده اجرا میشوند، معمولا از مفهومی بهنام «همگرایی نهایی» (Eventual Consistency) بهجای پایداری آنی (Strong Consistency) استفاده میشود.
این موضوع اگرچه مزایای عملکردی دارد، اما برای برنامههایی که نیازمند تضمین قوی تراکنش هستند، میتواند چالشبرانگیز باشد.
| مزایا | معایب |
| انعطافپذیری در ساختار داده بدون نیاز به تعریف اسکیما | عدم پشتیبانی استاندارد از زبان پرسوجوی SQL |
| مقیاسپذیری افقی در محیطهای توزیعشده | ضعف در تضمین تراکنشها و همزمانی قوی (ACID) |
| عملکرد بالا برای خواندن/نوشتن در دادههای حجیم | پیچیدگی در طراحی مدل داده برای برخی نیازها |
| مناسب برای دادههای متنوع و غیرساختاریافته | یادگیری ابزارهای خاص هر مدل (Document، Graph، …) مورد نیاز است |
Microsoft SQL Server

SQL Server محصولی از مایکروسافت است که از سال ۱۹۸۹ تاکنون، یکی از اصلیترین گزینههای پایگاه داده در سطح سازمانی به شمار میآید. این سیستم که در لیست رایجترین دیتابیسها قرار میگیرد، یک پایگاه داده رابطهای (Relational) است و از زبان T-SQL برای مدیریت و پردازش دادهها استفاده میکند.
در واقع T-SQL نسخهای توسعهیافته از SQL است که امکانات بیشتری از جمله توابع، متغیرهای محلی و… را در اختیار شما قرار میدهد.
دیتابیس SQL Server مجموعهای از ابزارها و سرویسهای مکمل را هم به شما ارائه میدهد که همه آنها در کنار هم، امکان ساخت یک زیرساخت قدرتمند دادهای را فراهم میسازند. با وجود محدودیتهایی در نسخههای غیررایگان، این سیستم بهدلیل امنیت بالا، قابلیت بازیابی اطلاعات و سازگاری با اکوسیستم مایکروسافت، انتخاب اصلی بسیاری از سازمانها به حساب میآید.
| مزایا | معایب |
| مستندات قوی و پشتیبانی گسترده | نسخههای حرفهای هزینه بالایی دارند |
| راهاندازی آسان و رابط کاربری مناسب | نسخههای قبل از ۲۰۱۷ فقط روی ویندوز قابل اجرا بودند |
| امنیت بالا و امکانات بازیابی پیشرفته | برای بهرهبرداری کامل، به برخی از نرمافزارهای جانبی مایکروسافت نیاز دارید |
| مناسب برای سازمانها و پروژههای بزرگ |

Cloud Databases
پایگاه داده ابری (Cloud Database) نوعی از سیستمهای مدیریت داده است که روی زیرساختهای ابری اجرا میشود و از طریق اینترنت در دسترس قرار میگیرد. این مدل جدید، بار سنگین نگهداری از سختافزار، تنظیمات سرور و ارتقا سیستم را از دوش سازمانها برمیدارد و آن را بر عهده ارائهدهندگان خدمات ابری میگذارد.
در این نوع پایگاه داده، شما براساس میزان مصرف خود (Pay-as-you-go) هزینه میکنید و بسته به نیاز میتوانید منابع خود را بهراحتی افزایش یا کاهش دهید. مهمترین ویژگیهای این مدل شامل مقیاسپذیری آسان، دسترسی جهانی و عدم نیاز به مدیریت زیرساخت است.
| مزایا | معایب |
| مقیاسپذیری خودکار در پاسخ به نیازهای متغیر | وابستگی به ارائهدهنده خدمات ابری |
| بدون هزینه راهاندازی اولیه و مدل پرداخت بر اساس استفاده | نگرانیهای امنیتی و حریم خصوصی در محیطهای ابری |
| در دسترس بودن جهانی و دسترسی با تأخیر پایین | هزینههای بلندمدت ممکن است در صورت مدیریت نادرست افزایش پیدا کند |
| عدم نیاز به نگهداری فیزیکی و بهروزرسانی زیرساخت | محدودیتهایی در سفارشیسازی تنظیمات پایینسطح |
Vector Databases
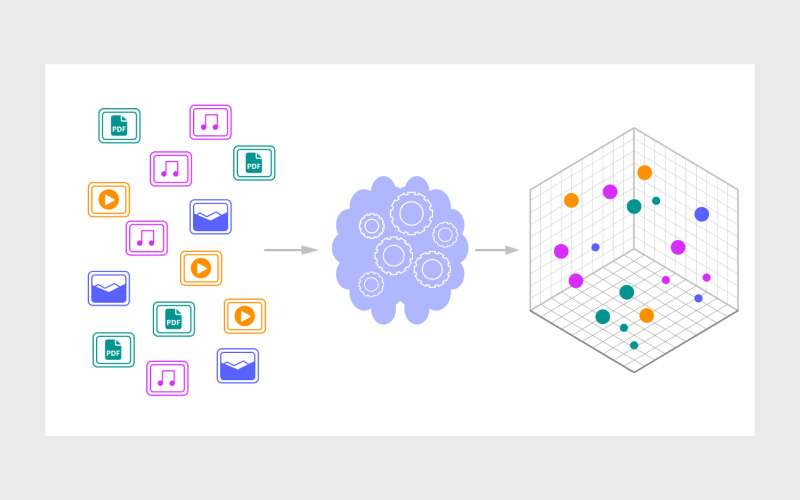
پایگاه داده برداری (Vector Database) نسل جدیدی از سیستمهای مدیریت داده است که برای پشتیبانی از کاربردهای هوش مصنوعی، یادگیری ماشین و پردازش زبان طبیعی طراحی شده است. این پایگاهها که در دسته رایجترین دیتابیسها قرار میگیرند، بهطور خاص برای ذخیره، جستجو و بازیابی بردارهای با ابعاد بالا (High-dimensional vectors) طراحی شدهاند.
این پایگاههای داده میتوانند به کمک الگوریتمهای جستجوی همسایگی نزدیک (ANN)، با سرعت و دقت بالا، بردارهایی را پیدا کنند که بیشترین شباهت را به بردار ورودی دارند. از جمله مهمترین کاربردهای رایج این دیتابیس، میتوان به موارد زیر اشاره کرد:
- سیستمهای توصیهگر (Recommendation Systems)
- تشخیص تصویر و ویدئو
- جستجوی معنایی در متون
- پردازش زبان طبیعی (NLP)
- تشخیص تقلب مبتنی بر شباهت
| مزایا | معایب |
| جستجوی بسیار سریع و بهینه در فضای برداری با استفاده از الگوریتمهای ANN | هنوز تکنولوژی نسبتا جدیدی است و جامعه کاربری محدودی دارد |
| مناسب برای دادههای بدون ساختار مانند متن و تصویر | نیاز به استفاده از مدلهای بردارساز (Embedding Models) برای تولید داده اولیه |
| پشتیبانی از کاربردهای پیشرفته AI و ML | عدم جایگزینی مناسب برای پایگاههای رابطهای در کاربردهای سنتی |
| امکان فیلتر ترکیبی برداری و متادیتا |
Graph Databases

پایگاه داده گراف (Graph Database) ساختاری مبتنی بر نود (Node) و رابطه (Edge) دارد که آن را به گزینهای ایدئال برای مدلسازی و تحلیل روابط پیچیده میان موجودیتها تبدیل میکند. برخلاف پایگاههای رابطهای که روی داده تمرکز دارند، پایگاههای گراف تمرکز اصلی خود را بر روابط بین دادهها میگذارند. این مدل در جاهایی مانند شبکههای اجتماعی، تحلیل تقلب، سامانههای پیشنهاددهنده و نمودارهای دانشی کاربرد زیادی دارد.
| مزایا | معایب |
| مدل داده طبیعی برای نمایش روابط پیچیده | ممکن است یادگیری مفاهیم گراف برای توسعهدهندگان سنتی دشوار باشد |
| جستجوی بهینه و سریع روابط در ساختارهای شبکهای | برای تحلیلهای جدولی یا تراکنشی کلاسیک مناسب نیست |
| مقیاسپذیری افقی برای گرافهای بزرگ | پشتیبانی محدود نسبت به پایگاههای داده سنتی (در برخی فریمورکها) |
| عملکرد بالا برای تحلیل روابط عمیق (Deep Link Traversal) | ابزارهای گزارشگیری و BI کمتر توسعهیافته نسبت به RDBMS |
کلام آخر
آشنایی با رایجترین دیتابیسها، یکی از مهمترین گامها در مسیر طراحی و توسعه سیستمهای دادهمحور به شمار میآید. هر دسته از دیتابیسها، بسته به نوع داده، نیازهای عملکردی و اهداف پروژه، ویژگیها و مزایای خاص خود را دارند، به همین دلیل انتخاب درست پایگاه داده میتواند بر سرعت، دقت و مقیاسپذیری اپلیکیشن تاثیر بسزایی داشته باشد.
منابع
www.astera.com | www.blog.codersee.com | www.datacamp.com
سوالات متداول
SQL سادهتر است و استاندارد مشخصی دارد. NoSQL پیچیدگی بیشتری دارد چون انواع مختلفی (مانند سندمحور، گرافی) را شامل میشود، اما منابع یادگیری کافی برای هر دو موجود است.
بله، این روش «پایداری چندرگه» نام دارد و برای رفع نیازهای مختلف (مثلا MySQL برای دادههای ساختیافته و MongoDB برای دادههای غیرساختیافته) استفاده میشود.
SQLite برای ذخیرهسازی محلی، Realm برای سرعت و Firebase برای همگامسازی داده در اپلیکیشنهای موبایل پیشنهاد میشوند.
بله، گزینههایی مانند PostgreSQL و MariaDB مناسباند، اما برای ویژگیهای پیشرفته ممکن است نسخههای پولی نیاز باشد.


دیدگاهتان را بنویسید