مدلهای ازپیشآموزشدادهشده (Pre-trained Models) امروز یکی از ستونهای اصلی توسعه کاربردهای هوش مصنوعی بهشمار میآیند؛ از پردازش زبان طبیعی و بینایی ماشین تا سامانههای چندمودال و ابزارهای تولید محتوا. این مدلها با یادگیری روی مجموعهدادههای وسیع، امکان «شروع سریع» پروژهها، صرفهجویی چشمگیر در زمان و هزینه محاسباتی و بهکارگیری پیشرفتهای پژوهشی را برای تیمها فراهم میکنند.
در این مقاله از بلاگ آسا علاوهبر مرور مزایا و محدودیتها، به کاستیهایی که در مسائل امنیتی و مهندسی تولید میپردازیم و راهنمای مهندسیمحوری برای استفاده امن و بهینه ارائه میکنیم.
تعریف و طبقهبندی مدلهای ازپیشآموزشدادهشده
مدلهای ازپیشآموزشدادهشده (PTM) به سامانههای یادگیری ماشین گفته میشود که ابتدا با دادههای عظیم و عمومی آموزش میبینند (Pre-training) و سپس برای یک وظیفه خاص با دادههای محدودتر تنظیم میشوند (Fine-tuning). این رویکرد مبتنی بر انتقال یادگیری (Transfer Learning) است و اغلب با روشهای یادگیری خودنظارتی (Self-supervised Learning) ترکیب میشود تا مدل بتواند الگوهای پیچیده را بدون نیاز گسترده به برچسبگذاری داده استخراج کند.
از نظر کاربردی، این مدلها را میتوان در سه دسته اصلی طبقهبندی کرد:
۱. زبان/متن: مانند GPT یا BERT که در پردازش زبان طبیعی بهکار میروند.
۲. بینایی کامپیوتری: مانند ResNet یا Vision Transformers برای تحلیل تصویر و ویدئو.
۳. چندمودال: مانند CLIP یا Flamingo که دادههای متنی و تصویری را همزمان درک و پردازش میکنند.
اگرچه مدلهای از پیش آموزشدادهشده قابلیتهای گستردهای در تحلیل دادههای متنی، تصویری و چندمودال ارائه میکنند، استفاده موثر و پایدار از آنها در محیطهای واقعی نیازمند نگاه مهندسی هوش مصنوعی است. مهندسی AI شامل آمادهسازی دادهها، فاینتیون مدل بر اساس نیازهای خاص، استقرار پایدار، پایش عملکرد و رعایت سیاستهای حاکمیت داده و امنیت است تا مدلها بتوانند با کیفیت، مقیاسپذیری و اعتماد لازم در سیستمهای عملیاتی بهکار گرفته شوند.
معرفی مدلهای OpenAI و نکات مهندسی مرتبط با PTM
خانواده مدلهای OpenAI، شامل سری GPT، نمونهای از مدلهای عمومی و چندمودال است که قابلیتهای زیر را دارند:
- تولید متن با کیفیت بالا در حوزههای عمومی و تخصصی
- تحلیل داده و استخراج اطلاعات از متن
- پاسخگویی چندرسانهای و پردازش ورودیهای ترکیبی
با این حال، استفاده عملی از این مدلها نیازمند رعایت نکات مهندسی و مدیریتی است:
- اعتبارسنجی دقیق: بررسی عملکرد مدل در دادههای واقعی قبل از استقرار
- بررسی هزینه و تاخیر (latency): انتخاب مدل متناسب با منابع پردازشی و نیاز پروژه
- انتخاب استراتژی استفاده: فاینتیون مدل یا استفاده از API بهمنظور کنترل هزینه و حفظ حریم خصوصی
- رعایت سیاستهای استفاده و حاکمیت داده: اطمینان از انطباق با قوانین و استانداردهای سازمانی

BERT: یک نمونه موفق از PTMها در پردازش زبان طبیعی
BERT، مخفف Bidirectional Encoder Representations from Transformers، یکی از شناختهشدهترین مدلهای از پیش آموزشدادهشده در حوزه پردازش زبان طبیعی است. این مدل با استفاده از معماری ترنسفورمر و یادگیری دوطرفه، قادر است زمینه کلمات را در متن بهطور دقیق درک کند و فهم عمیقتری از زبان طبیعی ارائه دهد.
یکی از نقاط قوت BERT این است که میتواند بدون نیاز به آموزش از صفر، برای انواع کاربردهای NLP مانند دستهبندی متن، پرسش و پاسخ، تشخیص موجودیتها و تحلیل احساسات فاینتیون شود. با این حال، استفاده از BERT نیازمند منابع پردازشی نسبتا زیاد است و برای دستیابی به بهترین عملکرد در حوزههای تخصصی، فاینتیون روی دادههای بومی ضروری است.
علاوه بر این، بررسی سوگیریها، رعایت حاکمیت داده و شفافسازی تصمیمات مدل همچنان اهمیت دارد تا استفاده عملی از BERT ایمن و قابل اعتماد باشد.
مزایای مدلهای ازپیشآموزشدادهشده
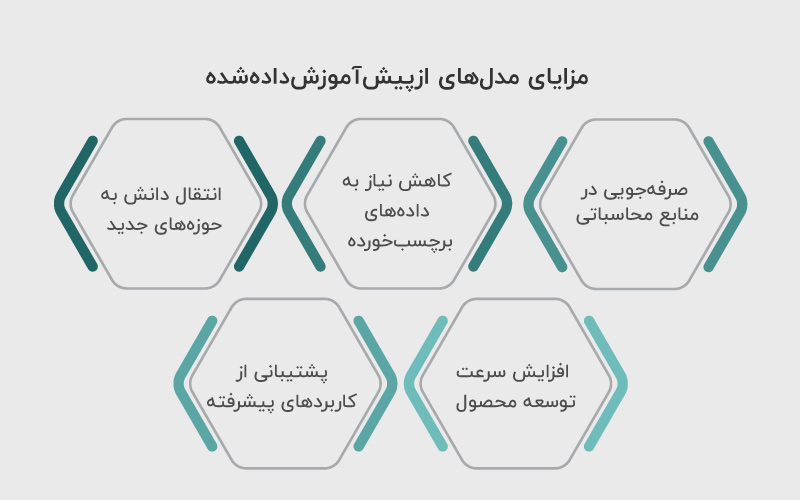
مدلهای ازپیشآموزشدادهشده نقطهی عطفی در توسعه هوش مصنوعی هستند؛ زیرا با کاهش هزینهها و زمان آموزش، مسیر رسیدن به کاربردهای عملی را هموار کردهاند. مهمترین مزایا عبارتاند از:
- صرفهجویی در منابع محاسباتی: بهجای آموزش از صفر روی دادههای عظیم، میتوان از دانش ازپیشآموختهی مدلها بهره برد و تنها بخش کوچکی از آن را برای کاربرد خاص بازآموزی کرد.
- کاهش نیاز به دادههای برچسبخورده: بسیاری از سازمانها به دادههای کافی و باکیفیت دسترسی ندارند. مدلهای ازپیشآموزشدادهشده این نیاز را کاهش میدهند.
- انتقال دانش به حوزههای جدید: مدلها قابلیت انتقال دانش میان وظایف مختلف را دارند؛ برای مثال، مدلی آموزشدیده روی متون عمومی میتواند در حوزه پزشکی یا حقوق نیز با اندکی تنظیم عملکرد خوبی نشان دهد.
- افزایش سرعت توسعه محصول: تیمها میتوانند سریعتر نمونهسازی کرده و محصولات کاربردی را به بازار برسانند.
- پشتیبانی از کاربردهای پیشرفته: بسیاری از کاربردهای پیچیده مانند چتباتهای هوشمند، سیستمهای ترجمه خودکار، تولید تصویر یا تحلیل ویدئو عملا بدون مدلهای ازپیشآموزشدادهشده غیرممکن یا بسیار پرهزینه بودند.
محدودیتها و ریسکهای مدلهای ازپیشآموزشدادهشده
با وجود موفقیت چشمگیر مدلهای از پیش آموزشدادهشده در طیف گستردهای از کاربردها، این رویکرد بدون چالش و ریسک نیست. یکی از مهمترین عوامل، اندازه و پیچیدگی بالای این مدلها است؛ به طوری که تصمیماتشان گاهی غیرقابل پیشبینی و تبیین نیست. نخستین مسئله، سوگیری و تبعیض (Bias) است؛ زیرا این مدلها بر اساس دادههای عظیم اینترنتی آموزش میبینند و بهطور ناخواسته بازتابدهندهی همان تعصبات و کلیشهها میشوند. این موضوع میتواند در حوزههایی مانند استخدام، قضاوت یا خدمات مالی پیامدهای جدی اخلاقی داشته باشد.
از سوی دیگر، نشت اطلاعات و حریم خصوصی یکی از نگرانیهای مهم است. گاهی مدلها بهطور مستقیم اطلاعات حساس یا شخصی موجود در دادههای آموزشی را بازتولید میکنند که تهدیدی برای امنیت دادهها محسوب میشود. چالش بعدی مربوط به انتقالپذیری به حوزههای خاص (Domain-shift) است؛ هرچند این مدلها در دادههای عمومی عملکرد خوبی دارند، اما در کاربردهای تخصصی مانند پزشکی یا حقوق، بدون تنظیم دقیق و دادههای بومی، ممکن است کارایی مطلوب نداشته باشند.
علاوهبر این، هزینه استقرار و مصرف منابع یکی از موانع کلیدی است. آموزش و بهویژه استفاده از مدلهای بزرگ به توان پردازشی، حافظه و انرژی قابل توجهی نیاز دارد که برای بسیاری از سازمانها مقرونبهصرفه نیست. این مسائل نشان میدهد که Explainable AI و ابزارهای تبیینپذیری مانند Local explanations، SHAP و LIME، همراه با کنترلهای مستندسازی و گزارشدهی، برای فهم و اعتمادپذیری رفتار این مدلها ضروری هستند.
در نهایت، این مدلها در برابر مثالهای خصمانه (Adversarial Attacks) آسیبپذیرند؛ تغییرات جزئی اما هدفمند در ورودی میتواند خروجیهای اشتباه یا خطرناک ایجاد کند. برای کاهش ریسکها و افزایش اعتماد کاربران، سیاستهای حاکمیت داده و شفافسازی فرایند آموزش اهمیت ویژهای دارند و تضمین میکنند که مدلها در محیط واقعی امن، قابل اعتماد و مطابق استانداردهای قانونی عمل کنند.
چطور امن و موثر از PTM استفاده کنیم؟

پیش از بهکارگیری مدلهای ازپیشآموزشدادهشده در پروژههای واقعی، لازم است مجموعهای از اصول فنی و امنیتی رعایت شوند. این اصول به تیمها کمک میکنند تا از صحت منبع مدل مطمئن شوند، هزینه و زمان آموزش را کاهش دهند، خطرات امنیتی را به حداقل برسانند و در نهایت مدل را به شکلی پایدار و مقیاسپذیر در محصول نهایی مستقر کنند. مهمترین نکات در این مسیر عبارتاند از:
۱. اعتبارسنجی منبع مدل (Provenance): بررسی کنید که مدل از منبع معتبر منتشر شده و وزنها دستکاری نشده باشند.
۲. گامهای مقدماتی پیش از فاینتیون: اجرای baseline ساده، فریز کردن لایهها برای شروع و تست در مقیاس کوچک (pilot) پیش از صرف هزینهی زیاد.
۳. روشهای سبکسازی و کاهش هزینه: استفاده از Pruning (حذف وزنهای غیرضروری)، Quantization (کاهش دقت محاسباتی)، Knowledge Distillation (انتقال دانش به مدل کوچکتر) و تکنیکهای ماژولار مثل LoRA یا Adapters.
۴. تضمین حریم خصوصی: پاکسازی و ناشناسسازی دادهها (data sanitization) و بهرهگیری از Differential Privacy در فرایند فاینتیون.
۵. تستهای امنیتی: اجرای حملات آزمایشی (adversarial testing) و بازرسی وزنها (weight inspection) برای شناسایی بکدور یا رفتار غیرمنتظره.
۶. MLOps و استقرار: نسخهبندی همزمان مدل و داده، مانیتورینگ data/model drift، تعریف روتین برای بازآموزی و استراتژی ریکاوری در صورت خرابی.
کاستیهای فنی و مهندسی در مدلهای ازپیشآموزشدادهشده
اگرچه بیشتر پژوهشهای علمی تمرکز خود را بر جنبههای نظری و کارایی این مدلها گذاشتهاند، در عمل هنگام توسعه و استفاده از آنها مجموعهای از کاستیهای فنی و مهندسی وجود دارد که کمتر مورد توجه قرار گرفتهاند. یکی از مهمترین مسائل، امنیت و وجود Backdoor یا Weight Poisoning است؛ در این حالت، وزنهای مدل میتوانند در مراحل آموزش یا انتشار توسط عوامل مخرب دستکاری شوند و در شرایط خاص خروجیهای غیرقابلاعتماد تولید کنند. بنابراین اعتبارسنجی منبع و ممیزی دقیق وزنها ضروری است.
از سوی دیگر، فرایند فاینتیون (Fine-tuning) با چالشهای قابلتوجهی همراه است. تنظیم دقیق ابرپارامترها، کنترل تغییرات ناخواسته در رفتار مدل و پیچیدگیهای پرامپتینگ میتوانند زمان و هزینه توسعه را افزایش دهند. همچنین، در سطح مهندسی نرمافزار، باگهای فنی مانند مصرف بیشازحد حافظه، Crash شدن هنگام بارگذاری یا اجرای مدلهای بزرگ مشکلات رایجی هستند که تیمهای توسعه باید برای آنها راهکارهای پایدار بیابند.
نهایتا، موضوع بهینهسازی منابع اهمیت ویژهای دارد. مدلهای بزرگ بهشدت پرهزینه هستند و استفاده عملیاتی از آنها بدون روشهایی چون Pruning (حذف بخشهای غیرضروری مدل)، Quantization (کاهش دقت محاسباتی) و Knowledge Distillation (انتقال دانش به مدل کوچکتر) بهسختی امکانپذیر است. این رویکردها نهتنها هزینه زیرساختی را کاهش میدهند، بلکه امکان استقرار مدلها در محیطهای واقعی مانند موبایل و لبه شبکه (Edge) را نیز فراهم میکنند.
جمعبندی
مدلهای از پیش آموزشدادهشده (PTM) ابزارهای قدرتمندی برای حل مسائل متنوع در حوزههای عمومی و تخصصی هستند، اما همراه با توانمندی بالا، محدودیتها و ریسکهایی مانند سوگیری، چالشهای حریم خصوصی، هزینه استقرار و آسیبپذیری در برابر حملات خصمانه دارند. برای استفاده موثر و ایمن از این مدلها، رعایت نکات مهندسی مانند اعتبارسنجی، انتخاب مدل مناسب بر اساس نیاز و منابع، بهینهسازی مصرف و پیروی از سیاستهای حاکمیت داده ضروری است.
علاوهبر این، بهرهگیری از تکنیکهای Explainable AI و ابزارهای تبیینپذیری به افزایش شفافیت، اعتماد و پذیرش مدلها در محیطهای واقعی کمک میکند و مسیر عملی و امن استفاده از PTMها را هموار میسازد.
منابع
سوالات متداول
PTMها پیشتر با دادههای گسترده و عمومی آموزش دیدهاند و قابلیت تعمیم و استفاده سریع در حوزههای مختلف را دارند، در حالی که مدلهای معمولی از صفر آموزش داده میشوند و به دادههای اختصاصی وابستهاند.
تکنیکهای تبیینپذیری مانند SHAP و LIME کمک میکنند تصمیمات مدل قابل درک و شفاف باشد، اعتماد کاربران افزایش یابد و استفاده از مدلها در محیطهای حساس ایمنتر شود.
مدلهای بزرگ به توان پردازشی، حافظه و انرژی قابل توجه نیاز دارند. استفاده از API یا فاینتیون مدلهای سبکتر میتواند هزینهها و مصرف منابع را بهینه کند.


دیدگاهتان را بنویسید