
بردارهای متنی (Text Embeddings) یکی از ابزارهای کلیدی در حوزهی پردازش زبان طبیعی (NLP) هستند.در این روش، متن به شکل عددی نمایش داده میشود؛ به این صورت که هر واژه یا عبارت در قالب یک بردار متراکم از اعداد حقیقی بیان میشود. شرکت OpenAI که بهدلیل دستاوردهای چشمگیرش در حوزه هوش مصنوعی شناخته میشود، در حال حاضر استفاده از مدل Ada V2 را برای ساخت Text Embeddings توصیه میکند. این مدل که بر پایه سری مدلهای GPT توسعه یافته، به گونهای آموزش دیده است که معنای متنی و ارتباطات موجود در زبان را با دقت بیشتری ثبت کند.
در این مقاله به شما کمک میکنیم حساب کاربری خود را راهاندازی کنید و با مزایای استفاده از API آشنا شوید. همچنین قصد داریم در کنار هم از خوشهبندی (Clustering) استفاده کنیم؛ روشی در یادگیری ماشین که برای گروهبندی نمونههای مشابه به کار میرود.
Text Embeddingها در چه زمینههایی استفاده میشوند؟
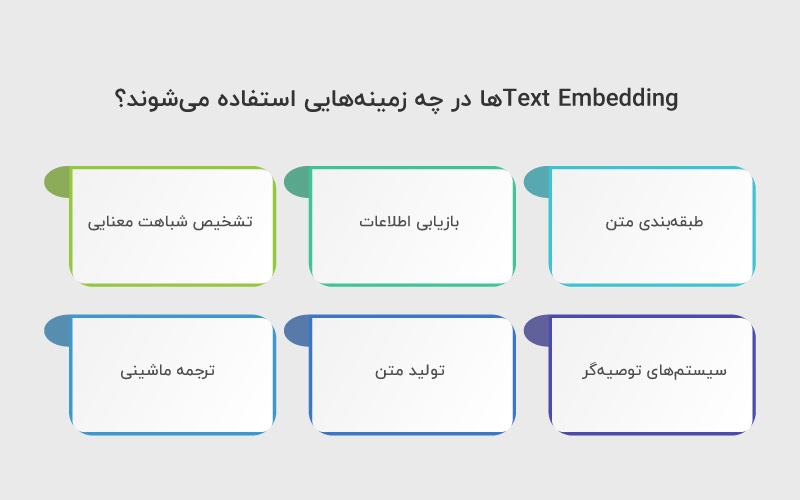
Text Embeddings را میتوان در کاربردهای متنوعی به کار گرفت، از جمله:
- طبقهبندی متن: کمک به ساخت مدلهای دقیق برای وظایفی مانند تحلیل احساسات یا شناسایی موضوع متن
- بازیابی اطلاعات: امکان جستجوی اطلاعات مرتبط با یک پرسش خاص، مشابه آنچه در موتورهای جستجو تجربه میکنیم
- تشخیص شباهت معنایی: اندازهگیری و شناسایی میزان شباهت معنایی بین بخشهای مختلف متن
- سیستمهای توصیهگر: بهبود کیفیت پیشنهادها از طریق درک بهتر ترجیحات کاربران بر اساس تعامل آنها با دادههای متنی
- تولید متن: کمک به تولید متنهای روانتر و مرتبطتر از نظر معنایی با زمینهی مورد نظر
- ترجمه ماشینی: ثبت و انتقال معانی در زبانهای مختلف که به ارتقای کیفیت فرایند ترجمه کمک میکند
آموزش مقدماتی Text Embeddings با Python و OpenAI
Text Embeddings یکی از تکنیکهای پایهای در هوش مصنوعی و پردازش زبان طبیعی است که به مدلها اجازه میدهد متون را به بردارهای عددی با ابعاد ثابت تبدیل کنند. این بردارها ویژگیهای معنایی متن را حفظ میکنند، به طوری که جملات یا کلمات با معناهای مشابه، Embeddingهای نزدیکی خواهند داشت.
با استفاده از Python و کتابخانههایی مانند OpenAI API، میتوان به سادگی Embeddingهای متنی را تولید کرد و در کاربردهای متنوعی مانند جستجوی معنایی، خوشهبندی متون، تحلیل احساسات و تشخیص شباهت معنایی به کار گرفت. این آموزش به شما کمک میکند تا مراحل اولیه تولید Embedding، کار با دادهها و درک مفاهیم پایهای شباهت متنی را یاد بگیرید و پایهای برای پروژههای پیچیدهتر بسازید.
۱. راهاندازی اولیه و نصب کتابخانهها
برای کار با Text Embeddings به چندین بسته پایتونی نیاز داریم که در ادامه معرفی میکنیم:
- os: یک کتابخانهی داخلی پایتون برای تعامل با سیستمعامل
- openai: کلاینت پایتون برای برقراری ارتباط با OpenAI API
- scipy.spatial.distance: شامل توابعی برای محاسبه فاصله بین نقاط داده مختلف
- sklearn.cluster.KMeans: ابزاری برای پیادهسازی الگوریتم خوشهبندی k-Means
- umap.UMAP: یک تکنیک برای کاهش ابعاد در دادههای با ابعاد بالا
پیش از استفاده از این کتابخانهها، مطمئن شوید که بستههای openai، scipy, plotly, sklearn و umap را با دستور زیر نصب کردهاید.
|
1 |
pip install –U openai, scipy, plotly–express, scikit–learn, umap–learn |
پس از اجرای موفق دستور قبلی، میتوانید همهی کتابخانهها را به شکل زیر در کد خود import کنید:
|
1 2 3 4 5 6 |
import os import openai from scipy.spatial import distance import plotly.express as px from sklearn.cluster import KMeans from umap import UMAP |
اکنون میتوانیم کلید OpenAI API را به صورت زیر تنظیم کنیم:
|
1 |
openai.api_key = “<YOUR_API_KEY_HERE>” |
توجه داشته باشید که لازم است کلید API اختصاصی خودتان را تنظیم کنید. کلیدی که در کد منبع وجود دارد قابل استفاده نیست و صرفا برای استفاده فردی در نظر گرفته شده بود.
۲. الگوی کدنویسی برای فراخوانی GPT از طریق API
تابع کمکی زیر را میتوان برای تبدیل یک خط متن به Embedding با استفاده از OpenAI API به کار برد. در این کد، از نسخهی Ada v2 برای تولید Embeddingها استفاده شده است.
|
1 2 3 4 5 6 7 8 9 |
def get_embedding(text_to_embed): # Embed a line of text response = openai.Embedding.create( model= “text-embedding-ada-002”, input=[text_to_embed] ) # Extract the AI output embedding as a list of floats embedding = response[“data”][0][“embedding”] return embedding |
۳. معرفی مجموعه داده
در این بخش از دادههای مربوط به نقد و بررسی سازهای موسیقی در آمازون استفاده میکنیم که به صورت رایگان در Kaggle در دسترس است. همچنین میتوانید این دادهها را از مخزن GitHub من با دستور زیر دانلود کنید:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import pandas as pd data_URL = “https://raw.githubusercontent.com/keitazoumana/Experimentation-Data/main/Musical_instruments_reviews.csv” review_df = pd.read_csv(data_URL) review_df.head() review_df = review_df[[‘reviewText’]] print(“Data shape: {}”.format(review_df.shape)) display(review_df.head()) Data shape: (10261, 1) |
از میان تمام ستونهای موجود در دادهها، تنها ستونی که برای ما اهمیت دارد ستون reviewText است.
اکنون میتوانیم برای هر سطر از کل دیتاست، با استفاده از تابعی که پیشتر تعریف کردیم و به کمک عبارت lambda، Embeddingها را تولید کنیم:
|
1 2 3 4 5 |
review_df = review_df.sample(100) review_df[“embedding”] = review_df[“reviewText”].astype(str).apply(get_embedding) # Make the index start from 0 review_df.reset_index(drop=True) review_df.head(10) |
۴. درک شباهت متنی
برای نشان دادن مفهوم شباهت معنایی، دو نمونه نقد را در نظر بگیریم که احساس مشابهی را منتقل میکنند:
“This product is fantastic!”
“It really exceeded my expectations!”
با استفاده از تابع pdist() از ماژول scipy.spatial.distance میتوانیم فاصله اقلیدسی (Euclidean distance) بین Embeddingهای این دو جمله را محاسبه کنیم.
فاصلهی اقلیدسی برابر است با ریشه دوم مجموع تفاضلهای مربعی بین دو بردار. نمونه تصویری این مفهوم در ادامه نمایش داده شده است:
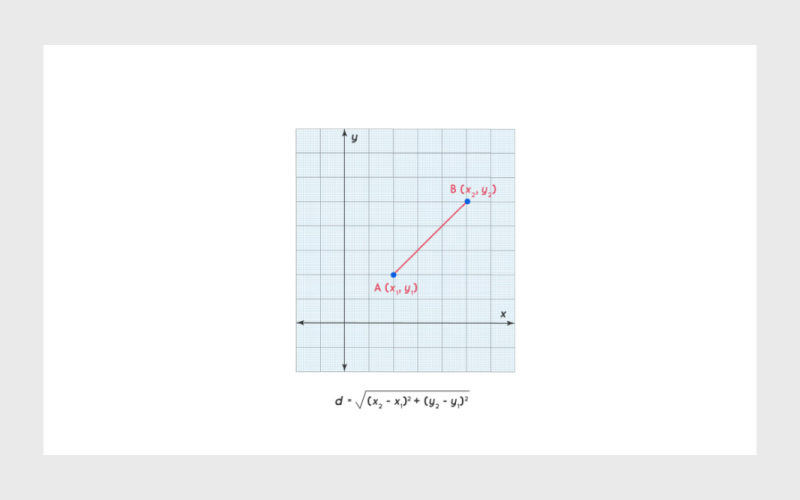
اگر این دو نقد واقعا مشابه باشند، فاصلهی بین Embeddingهای آنها باید نسبتا کوچک باشد.
حال دو نقد متفاوت را در نظر بگیریم:
“This product is fantastic!”
“I’m not satisfied with the item.”
فاصله بین Embeddingهای این دو جمله بهمراتب بیشتر از فاصله بین جملات مشابه خواهد بود.
نمونه کاربردی: استفاده از Text Embedding در خوشهبندی دادهها
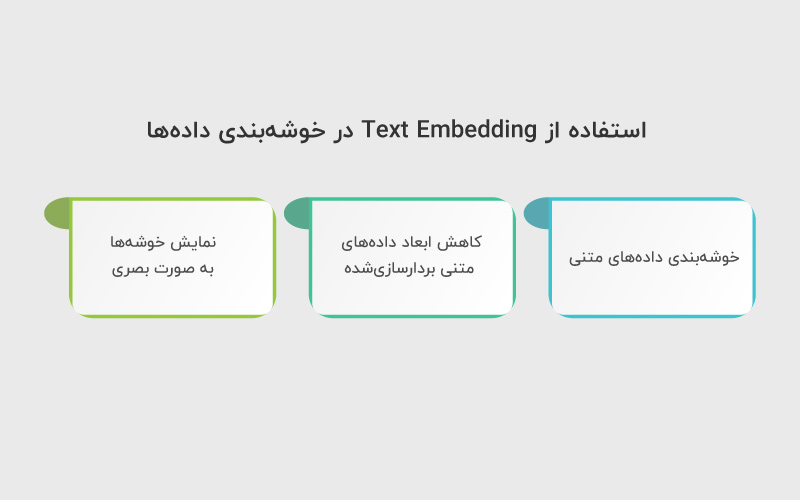
Text Embeddingهایی که ایجاد کردهایم را میتوان برای تحلیل خوشهای به کار برد؛ بهطوری که سازهای موسیقی با شباهت بیشتر در یک گروه قرار بگیرند.
الگوریتمهای مختلفی برای خوشهبندی وجود دارد؛ مانند K-Means، DBSCAN، خوشهبندی سلسلهمراتبی (Hierarchical Clustering) و مدلهای ترکیبی گاوسی (Gaussian Mixture Models). در این مثال مشخص، ما از الگوریتم K-Means استفاده خواهیم کرد.
۱. خوشهبندی دادههای متنی
استفاده از الگوریتم K-Means نیازمند تعیین تعداد خوشهها از پیش است. در این مثال، تعداد خوشهها را برابر با ۳ در نظر میگیریم و مقدار پارامتر n_clusters را به شکل زیر تنظیم میکنیم:
|
1 2 |
kmeans = KMeans(n_clusters=3) kmeans.fit(review_df[“embedding”].tolist()) |
۲. کاهش ابعاد دادههای متنی بردارسازیشده
انسانها معمولا تنها قادر به تجسم دادهها تا سه بُعد هستند. به همین دلیل، در این بخش از UMAP استفاده میکنیم؛ ابزاری سریع و مقیاسپذیر برای کاهش ابعاد.
ابتدا یک نمونه از کلاس UMAP تعریف میکنیم و سپس تابع fit_transform را روی Embeddingها اعمال میکنیم. خروجی این مرحله یک نمایش دوبعدی از Embedding نقدهاست که میتوان آن را ترسیم کرد.
|
1 2 |
reducer = UMAP() embeddings_2d = reducer.fit_transform(review_df[“embedding”].tolist()) |
۳. نمایش خوشهها به صورت بصری
در نهایت یک نمودار پراکندگی (Scatter Plot) از Embeddingهای دوبعدی ترسیم میکنیم.
مختصات x و y بهترتیب از embeddings_2d[:, 0] و embeddings_2d[:, 1] گرفته میشوند.
خوشهها در این نمودار بهصورت بصری از یکدیگر متمایز خواهند بود.
|
1 2 |
fig = px.scatter(x=embeddings_2d[:, 0], y=embeddings_2d[:, 1], color=kmeans.labels_) fig.show() |
در مجموع، سه خوشه اصلی در نمودار مشاهده میشود که هر کدام با رنگ متفاوت مشخص شدهاند. رنگ هر نقد در شکل، بر اساس برچسب یا شماره خوشهای تعیین میشود که مدل K-Means به آن اختصاص داده است. همچنین موقعیت هر نقطه، نشاندهنده میزان شباهت آن نقد با سایر نقدهاست.
سخن پایانی
با توجه به رشد روزافزون دادههای متنی و اهمیت تحلیل آنها، تسلط بر تکنیکهایی مانند Text Embeddings برای توسعهدهندگان حوزهی یادگیری ماشین و پردازش زبان طبیعی یک مهارت کلیدی محسوب میشود. بهرهگیری از مدلهای پیشرفتهای همچون Ada V2 میتواند توسعه اپلیکیشنهای هوشمند را سریعتر و کارآمدتر کند و مسیر ساخت محصولات دادهمحور نوآورانه را هموارتر سازد.
سوالات متداول
Embedding ابزاری برای نمایش عددی متن است، در حالی که خوشهبندی یک تکنیک یادگیری ماشین برای گروهبندی دادهها بر اساس شباهت است. Embeddingها میتوانند ورودی الگوریتمهای خوشهبندی باشند.
بله. با استفاده از الگوریتمهایی مثل UMAP میتوان ابعاد بالا را به دو یا سه بُعد کاهش داد و سپس دادهها را با نمودارهایی مثل Scatter Plot نمایش داد.
ابتدا باید کلید API خود را تعریف کنید و سپس از متد openai.Embedding.create با مدل text-embedding-ada-002 استفاده کنید.


دیدگاهتان را بنویسید