
تصور کنید با ماشین خودران به محل کار میروید. وقتی به تابلوی ایست نزدیک میشوید، خودرو به جای توقف سرعت خود را افزایش میدهد و از علامت توقف عبور میکند؛ زیرا علامت توقف را بهعنوان علامت محدودیت سرعت تشخیص میدهد. حتی با وجود اینکه سیستم یادگیری ماشینی (ML) برای تشخیص علائم توقف آموزش دیده است، اما چطور این اتفاق میافتد؟
احتمالا شخصی برچسبهایی را به علامت توقف اضافه کرده تا ماشین را فریب دهد و تصور کند که علامت محدودیت سرعت 60 کیلومتر در ساعت است. این عمل سادهی قرار دادن برچسبها روی علامت توقف، نمونهای از حمله خصمانه به سیستمهای یادگیری ماشین و هوش مصنوعی (Adversarial Machine Learning) است. این تنها یک مثال کوچک بود و برای درک بهتر این موضوع، در این مقاله از بلاگ آسا به قصد داریم به بررسی مقابله با یادگیری ماشین متخاصم بپردازیم.
یادگیری ماشین خصمانه چیست؟
یادگیری ماشین خصمانه یا هوش مصنوعی متخاصم (Adversary AI)، زیرشاخهای از تحقیقات در زمینه هوش مصنوعی و یادگیری ماشین است که حملات خصمانه علیه ماشینها و مدلهای هوش مصنوعی را بررسی میکند. حملات خصمانه هوش مصنوعی به حملات سایبری گفته میشود که هدف آن گمراه کردن یا از کار انداختن یک مدل یادگیری ماشین از راههای مختلف است.
حملات به سیستمهای یادگیری ماشینی میتواند در مراحل مختلف توسعه مدل رخ دهد؛ از دستکاری دادههای آموزشی یا مسموم کردن مدلهای ML با معرفی اطلاعات اشتباه یا سوگیریها گرفته تا ارائه ورودیهای فریبنده برای تولید خروجیهای نادرست!
هوش مصنوعی متخاصم اخیرا نشان داده که میتواند پتانسیل قابل توجهی در ایجاد آسیبها و نگرانیها داشته باشد. بهعنوان مثال، مهاجمان میتوانند از هوش مصنوعی متخاصم برای دستکاری وسایل نقلیه خودران، سیستمهای تشخیص پزشکی، سیستمهای تشخیص چهره و سایر برنامههای کاربردی مبتنی بر هوش مصنوعی استفاده کنند که منجر به نتایج فاجعهآمیزی میشود.
مثال یادگیری ماشین خصمانه

یکی از معروفترین مثالهای هوش مصنوعی متخاصم، حملهای است که روی مدلهای تشخیص تصویر صورت میگیرد.
حمله متخاصم Google Inception
حمله متخاصم به شبکه عصبی Google Inception یکی از همین نمونههاست که در آن تصویری از یک پاندا که توسط مدلهای تشخیص تصویر به درستی بهعنوان «پاندا» شناسایی شده، انتخاب میشود. سپس یک نویز بسیار کوچک و دقیق (Adversarial Noise) به تصویر اضافه میشود. این نویز برای چشم انسان تقریبا نامرئی است و ما همچنان تصویر را به شکل «پاندا» میبینیم. اما مدل هوش مصنوعی، تصویر دستکاریشده را بررسی میکند و آن را به اشتباه بهعنوان یک حیوان کاملا متفاوت، یعنی یک میمون تشخیص میدهد. در این مثال، تغییرات اعمالشده بهقدری جزئی هستند که برای انسان قابل شناسایی نیستند، اما میتوانند مدل هوش مصنوعی را فریب دهند.
حملات خودروهای خودران
مثال معروف دیگر حملات متخاصم به خودروهای خودران است که در این نوع حملات، با دستکاری کوچک علائم راهنمایی رانندگی (مانند تغییرات جزئی در شکل یا رنگ علامت) میتوان سیستم تشخیص خودرو را فریب داد. مثلا علامتی که بهصورت معمول باید به عنوان «توقف» (Stop) شناسایی شود، ممکن است پس از حمله به اشتباه بهعنوان «محدودیت سرعت» (Speed Limit) شناخته شود. چنین حملاتی میتوانند خطراتی جدی برای امنیت خودروهای خودران ایجاد کنند.
این نمونهها نشان میدهند که حتی تغییرات بسیار کوچک و غیرمحسوس هم میتوانند پیامدهای بزرگی در دنیای واقعی به همراه داشته باشند.
حملات هوش مصنوعی متخاصم چگونه کار میکنند؟
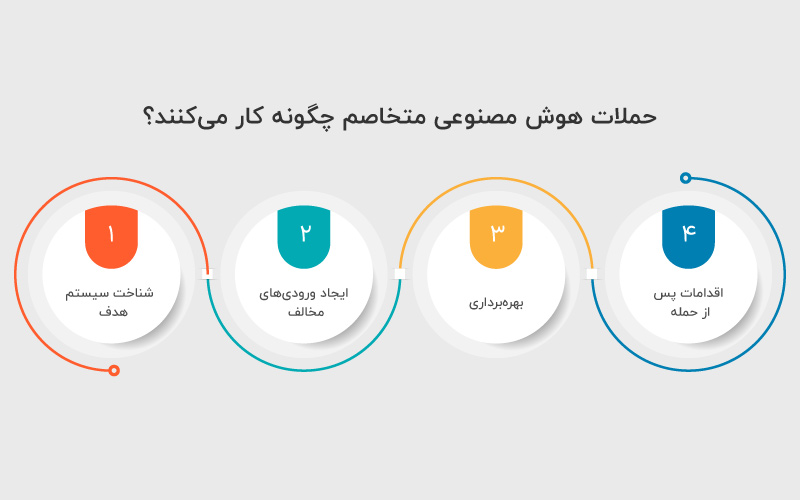
حملات خصمانه از آسیبپذیریها و محدودیتهای ذاتی مدلهای یادگیری ماشین، به ویژه شبکههای عصبی عمیق (DNN)، سو استفاده میکنند. این حملات دادههای ورودی یا خود مدل را دستکاری میکنند تا سیستم هوش مصنوعی نتایج نادرست یا نامطلوب تولید کند. حملات AI و ML متخاصم معمولا از یک الگوی چهار مرحلهای پیروی میکنند که شامل درک، دستکاری و بهرهبرداری از سیستم هدف است.
مرحله ۱: شناخت سیستم هدف
مجرمان سایبری که میخواهند یک حمله هوش مصنوعی خصمانه را انجام دهند باید بدانند که سیستم هوش مصنوعی هدف چگونه کار میکند. آنها این کار را با تجزیه و تحلیل الگوریتمهای سیستم، روشهای پردازش دادهها و الگوهای تصمیمگیری انجام میدهند. برای رسیدن به این هدف، آنها از تکنیکهایی مانند مهندسی معکوس برای شکستن مدل AI استفاده میکنند و بهدنبال نقاط ضعف یا شکاف در آن میگردند.
مرحله ۲: ایجاد ورودیهای مخالف
هنگامی که مهاجمان درک کنند که یک سیستم AI چگونه کار میکند، میتوانند نمونههای متخاصم ایجاد کنند. نمونههای متخاصم ورودیهایی با طراحی و ویژگیهای خاص هستند که سیستم را دچار خطا میکنند. برای مثال، مهاجمان میتوانند با تغییر جزئی یک تصویر، سیستم تشخیص تصویر را فریب دهند یا با دستکاری دادههای ورودی به یک مدل پردازش زبان طبیعی (NLP)، آن را وادار به طبقهبندی نادرست کنند.
مرحله ۳: بهرهبرداری
سپس، مهاجمان ورودیهای متخاصم را علیه AI هدف اعمال میکنند. هدف این است که سیستم، رفتاری غیرقابل پیشبینی یا نادرست داشته باشد. این میتواند از پیشبینیها یا طبقهبندهای نادرست تا دور زدن پروتکلهای امنیتی متغیر باشد. حملات خصمانه از ضعفها و حساسیتهای مدلهای یادگیری ماشین سوءاستفاده میکند تا آنها را به پیشبینیها یا تصمیمگیریهای نادرست وادار کنند. تغییرات در دادههای ورودی میتواند بهطور قابل توجهی بر خروجی مدل تاثیر بگذارد.
مرحله ۴: اقدامات پس از حمله
یادگیری ماشین Adversarial میتوانند پیامدهای مختلفی داشته باشند، از طبقهبندی اشتباه تصاویر یا متن گرفته تا خطرهای جدی و تهدیدکننده زندگی مانند اشتباه در مراقبتهای بهداشتی یا وسایل نقلیه خودران! دفاع در برابر این حملات مستلزم معماریهای مدل قوی، آزمایشهای گسترده در برابر نمونههای متخاصم و تحقیقات مداوم در مورد تکنیکهای آموزش متخاصم برای انعطافپذیری بیشتر سیستمهای هوش مصنوعی است. در ادامه، روشهای مقابله با هوش مصنوعی متخاصم را بیشتر بررسی میکنیم.
انواع حملات خصمانه

حملات خصمانه را میتوان به دو دسته کلیتر حملات جعبه سفید (White Box) و جعبه سیاه (Black Box) تقسیم کرد. مهاجمان جعبه سفید دانش کاملی از معماری مدل هوش مصنوعی دارند، در حالی که مهاجمان جعبه سیاه اطلاعات محدودی دارند. سطح دانش بهطور قابل توجهی بر موفقیت حمله تاثیر میگذارد. حملات متخاصم را میتوان از لحاظ نحوه حمله و عملکرد آن بر مدلها به دستههای زیر تقسیم کرد.
۱. حملات فرار (Evasion Attacks)
حملات فرار زمانی رخ میدهند که دادههای ورودی برای فرار مدلهای هوش مصنوعی دستکاری میشوند. بهعنوان مثال، اضافه کردن تغییرات نامحسوس به یک تصویر میتواند باعث شود که سیستم هوش مصنوعی آن را به اشتباه شناسایی کند. این حملات میتوانند بهطور جدی بر تشخیص تصویر و سیستمهای امنیتی تاثیر بگذارند، بهخصوص زمانی که پیشبینیهای دقیق ضروری است. حملات فرار معمولا به دو نوع زیر دستهبندی میشوند:
- حملات غیرهدفمند: در حملات فرار غیرهدفمند، هدف این است که مدل هوش مصنوعی، فارغ از هر نتیجهای؛ خروجی نادرستی تولید کند. بهعنوان مثال، یک مهاجم ممکن است تصویر علامت توقف را دستکاری کند تا سیستم هوش مصنوعی آن را بهعنوان علامت توقف تشخیص ندهد و منجر به موقعیتهای خطرناک جادهای شود.
- حملات هدفمند: در حملات فرار هدفمند، مهاجم قصد دارد مدل هوش مصنوعی را مجبور به تولید یک خروجی خاص، ازپیشتعریفشده و نادرست کند. بهعنوان مثال، آنها ممکن است بخواهند که این مدل، یک تومور خوشخیم را بهعنوان یک مورد بدخیم طبقهبندی کند، که منجر به هشدارهای نادرست میشود.
تشخیص و مقابله با حملات فرار میتوانند بسیار دشوار باشند؛ زیرا مهاجمان از ویژگیها یا الگوهای خاصی که یک مدل هوش مصنوعی در طول آموزش انتخاب کرده، برای نفوذ به آن استفاده میکنند. این حملات معمولا از تکنیکهای بهینهسازی برای گمراه کردن مدلها استفاده میکنند و به همین دلیل ممکن است توسط ناظران انسانی قابل شناسایی نباشند.
۲. حملات مسمومیت (Poisoning Attacks)
حملات مسمومیت، شکل پیچیدهتر و ظریفتر از هوش مصنوعی متخاصم را نشان میدهد. در این حملات، عوامل مخرب مستقیما مدل یادگیری ماشین را هدف قرار نمیدهند، بلکه دادههای آموزشی مورد استفاده برای ایجاد مدل را دستکاری میکنند. ایده پشت حملات مسمومیت، تزریق دادههای آلوده به مجموعه دادههای آموزشی است، به طوری که درک مدل از الگوهای زیربنایی در دادهها را مخدوش کند.
۳. حملات انتقالی (Transfer Attacks)
حملات انتقال یک چالش منحصربهفرد در حوزه یادگیری ماشین Adversarial است. برخلاف سایر حملات که بهطور خاص یک سیستم هوش مصنوعی را هدف قرار میدهند، حملات انتقال شامل ایجاد مدلهای متخاصم برای یک سیستم و انطباق آنها برای حمله به سایر مدلهای هوش مصنوعی است. هنگامی که یک سیستم در معرض خطر قرار می گیرد، حملات خصمانه میتوانند چندین سیستم هوش مصنوعی با عملکردهای مشابه را تحت کنترل خود درآورند. این امر سازگاری و تطبیقپذیری این تکنیکها را نشان میدهد.
اما چطور میتوانیم از مدلهای یادگیری ماشین و هوش مصنوعی در برابر این حملات دفاع کنیم؟
نحوه دفاع در برابر هوش مصنوعی Adversary

ماهیت پیچیده تهدیدات هوش مصنوعی و یادگیری ماشین Adversarial مستلزم یک رویکرد امنیت سایبری چند وجهی، چندلایه و فعال است که راهحلهای تکنولوژیکی را با استراتژیهای سازمانی و آموزشی ترکیب میکند. هدف، ایجاد یک چارچوب محکم و انعطافپذیر است که قادر به شناسایی و جلوگیری از حملات باشد و به تیمها این امکان را بدهد که در صورت وقوع حمله، سریع و موثر پاسخ دهند.
پیشگیری و تشخیص
اولین و شاید مهمترین اقدام علیه حملات هوش مصنوعی متخاصم، پیشگیری و شناسایی است. پیشگیری شامل اجرای اقدامات امنیتی پیشرفته هوش مصنوعی است که میتواند ورودیهای متخاصم را قبل از اینکه بر سیستم تاثیر بگذارد، شناسایی و خنثی کند. تکنیکهای مهم عبارتند از مدلهای یادگیری ماشین انعطافپذیر، که حساسیت کمتری نسبت به دستکاری دشمنان دارند و سیستمهای تشخیص ناهنجاری که میتوانند الگوها یا ورودیهای غیرعادی را شناسایی کنند.
آموزش خصمانه
آموزش خصمانه (Adversarial training) اصلیترین روش مقابله با این حملات است که بر دادههای مورد استفاده در آموزش مدلها تمرکز میکند. این نوع آموزش شامل تقویت مجموعه دادههای آموزشی با مثالهای متخاصم است تا مدلها در برابر حملات مشابه آماده باشند. به کمک آموزش خصمانه، مدلها میتوانند ورودیهای مخرب را بشناسند و بهعنوان تهدیدکننده برچسبگذاری کنند. ایده اصلی این است که مدلها در مرحله آموزش، تحت حملات خصمانه قرار بگیرند و با شناسایی آنها بتوانند عملکرد صحیحی در دنیای واقعی داشته باشند.
تقطیر دفاعی
تقطیر دفاعی (Defensive Distillation) یکی دیگر از تکنیکهای اصلی مقابله با حملات متخاصم در یادگیری ماشین است که با هدف مقاومسازی مدلها در برابر این حملات توسعه داده شده است. در این روش، ابتدا یک مدل اصلی (Teacher Model) آموزش داده میشود و سپس از خروجیهای نرم (Soft Labels) این مدل برای آموزش یک مدل جدید و فشردهتر (Student Model) استفاده میشود. ایده اصلی این است که خروجیهای نرم، اطلاعات بیشتری نسبت به برچسبهای سخت (Hard Labels) فراهم میکنند و این باعث میشود مدل دوم به نویزهای کوچک و تغییرات جزئی که در حملات متخاصم اعمال میشوند، کمتر حساس باشد. به این ترتیب، مدل نهایی میتواند در مواجهه با حملات متخاصم مقاومتر عمل کند.
نظارت مستمر
نظارت مستمر سیستمهای هوش مصنوعی برای بررسی رفتارها یا خروجیهای غیرمنتظره میتواند به تشخیص زودهنگام حملات دشمن کمک کند. تیمهای سایبری میتوانند از رمزگذاری و دسترسی ایمن به مدلها و مجموعه دادههای هوش مصنوعی برای جلوگیری از دستکاری یا استخراج غیرمجاز استفاده کنند.
آموزش افراد
آموزش شامل برنامههای آموزشی خاص و هدفمند برای تیمهای امنیت سایبری، توسعهدهندگان هوش مصنوعی و همه کارکنان سازمان است. آموزش تخصصی باید بر درک ماهیت حملات خصمانه، شناسایی آسیبپذیریهای احتمالی در سیستمهای هوش مصنوعی و یادگیری آخرین تکنیکها برای ساخت مدلهای قوی ML متمرکز شود. تیمهای سایبری با حصول اطمینان از اینکه تمام سطوح سازمان به خوبی آگاه و هوشیار هستند، میتوانند دفاع جامعتری در برابر هوش مصنوعی و ML خصمانه ایجاد کنند و نفوذ این حملات پیچیده به زیرساختهای دیجیتال سازمان را سختتر کنند.
خود ارزیابی آسیبپذیری
ارزیابی آسیبپذیری (Vulnerability Assessment) احتمالی یک مدل برای درک و تقویت سیستم دفاعی سازمان در برابر حملات AI بسیار مهم است. فرایند ارزیابی شامل آزمایش منظم سیستمهای هوش مصنوعی برای شناسایی آسیبپذیریهایی است که حملات متخاصم میتوانند از آنها سوءاستفاده کنند.
تیمهای سایبری میتوانند از ابزارها و روشهایی مانند تست نفوذ و ارزیابیهای مبتنی بر سناریو برای شبیهسازی حملات خصمانه و ارزیابی انعطافپذیری سیستمهای هوش مصنوعی استفاده کنند. این ارزیابیها باید یکپارچگی دادهها، استحکام مدل و پاسخ سیستم به ورودیهای متخاصم را پوشش دهد. بینش بهدستآمده از این ارزیابیها باید اصلاح و تقویت مداوم استراتژیهای امنیتی هوش مصنوعی را هدایت کند.
سخن پایانی
همانطور که دیدید، یادگیری ماشین Adversarial یک چالش مهم و روبهرشد در حوزه یادگیری ماشین و هوش مصنوعی است. هر چقدر که هوش مصنوعی به تکامل خود ادامه میدهد، تاکتیکهای مورد استفاده کسانی که بهدنبال بهرهبرداری از آن برای مقاصد شوم هستند نیز افزایش مییابد. به همین دلیل، توسعهدهندگان مدلها باید ماهیت این حملات، پیامدهای واقعی آنها و نحوه دفاع در برابر آنها را درک کنند.
منابع
www.openai.com | www.techtarget.com | www.coursera.org
سوالات متداول
ابزارهایی مانند Foolbox، CleverHans، و Adversarial Robustness Toolbox (ART) برای طراحی و اجرای این حملات استفاده میشوند.
– استفاده از تکنیک Adversarial Training
– افزودن نویز تصادفی به دادههای آموزشی
– بهینهسازی معماری مدل برای کاهش حساسیت به تغییرات جزئی
حملات فعال: شامل تغییر مستقیم در دادهها برای فریب مدل است.
حملات غیرفعال: شامل بهرهبرداری از مدل بدون تغییر مستقیم در دادههاست.

دیدگاهتان را بنویسید