
با محبوبشدن AI Agentها، ابزارها و فریمورکهای متعددی برای ساخت آنها معرفی شدهاند که بسیاری از جزئیات پیادهسازی را پنهان میکنند. این ابزارها اگرچه سرعت توسعه را بالا میبرند، اما درک دقیقی از اینکه یک Agent واقعا چگونه فکر میکند، تصمیم میگیرد و عمل انجام میدهد، به توسعهدهنده نمیدهند.
در این مقاله تمرکز بر پیادهسازی دستی AI Agentهاست؛ یعنی طراحی منطق Agent بدون اتکا به فریمورکهای آماده. اجزای اصلی یک AI Agent، چرخه تصمیمگیری آن و چالشهایی که در این مسیر با آن روبهرو میشویم را بررسی میکنیم تا بتوانید درک عمیقتری از رفتار Agentها داشته باشید و در صورت نیاز، آنها را متناسب با پروژه خود طراحی کنید.
عامل هوشمند (AI Agent) چیست؟

نرمافزارهای معمولی به کاربران کمک میکنند کارها و فرایندهایشان را سریعتر و خودکار انجام دهند. اما عاملهای هوشمند یک قدم جلوتر میروند؛ آنها میتوانند همان کارها را بدون دخالت مستقیم کاربر انجام دهند.
عامل هوشمند در سادهترین تعریف، سیستمی است که میتواند بهصورت مستقل وظایف مشخصی را از طرف کاربر انجام دهد.
هر هدفی که کاربر دارد، از پاسخدادن به یک درخواست پشتیبانی گرفته تا رزرو رستوران، اعمال تغییر در کد یا تهیه یک گزارش معمولا از چند مرحله تشکیل شده است. به این زنجیره از مراحل، «جریان کاری» یا Workflow گفته میشود.
نکته مهم این است که هر برنامهای که از مدلهای زبانی بزرگ استفاده میکند، لزوما عامل هوشمند نیست. برای مثال، چتباتهای ساده، مدلهایی که فقط یک پاسخ در یک مرحله تولید میکنند، یا سیستمهای تحلیل احساسات، اگر کنترلی روی اجرای مراحل کار نداشته باشند، در دسته عاملها قرار نمیگیرند.
آنچه یک سیستم را به «عامل هوشمند» تبدیل میکند، مجموعهای از ویژگیهای کلیدی است که باعث میشود بتواند بهطور قابلاعتماد از طرف کاربر عمل کند:
- اول اینکه عامل از یک مدل زبانی بزرگ برای تصمیمگیری و مدیریت اجرای مراحل کار استفاده میکند. این عامل میتواند تشخیص دهد چه زمانی کار به پایان رسیده، در صورت نیاز مسیر خود را اصلاح کند و اگر با خطا مواجه شد، اجرای فرایند را متوقف کرده و کنترل را به کاربر بازگرداند.
- دوم اینکه عامل به ابزارهای مختلفی برای تعامل با سیستمهای بیرونی دسترسی دارد؛ هم برای بهدست آوردن اطلاعات لازم و هم برای انجام اقدامهای عملی. عامل با توجه به وضعیت فعلی کار، ابزار مناسب را انتخاب میکند و همه این کارها را در چارچوب محدودیتها و قوانین مشخصشده انجام میدهد.
چه زمانی به ساخت یک AI Agent نیاز داریم؟
ساختن یک عامل هوشمند یعنی سپردن «تصمیمگیری و اجرای کار» به سیستم.
این کار همیشه بهترین انتخاب نیست و قرار نیست جای همهی اتوماسیونهای معمولی را بگیرد.
اگر کاری را میتوان با چند شرط ساده، if/else یا یک فلو مشخص انجام داد، معمولا نیازی به agent ندارید. عاملهای هوشمند زمانی ارزشمند میشوند که این روشها دیگر جواب نمیدهند.
برای مثال، بررسی تقلب در پرداخت را در نظر بگیرید:
- یک سیستم سنتی میگوید:
«اگر مبلغ زیاد بود و کشور مشکوک بود، تراکنش را بلاک کن.»
- اما یک agent شبیه یک تحلیلگر انسانی فکر میکند:
زمینه را بررسی میکند، رفتارهای قبلی را در نظر میگیرد و حتی بدون نقض صریح قوانین، به یک نتیجه میرسد.
بهطور خلاصه، agentها برای موقعیتهای مبهم و غیرقابلپیشبینی ساخته شدهاند.
معمولا ساخت agent زمانی منطقی است که با یکی از این شرایط روبهرو باشید:
۱. تصمیمگیری ساده نیست
اگر تصمیمگیری فقط بر اساس چند قانون مشخص انجام نمیشود و نیاز به قضاوت دارد (مثلا تایید یا رد درخواست بازپرداخت مشتری)، agent میتواند مفید باشد.
۲. قوانین زیاد و پیچیده شدهاند
اگر سیستم شما پر از قانونهای ریز و درهم است و هر تغییری باعث خطا میشود، agent میتواند جایگزین بهتری برای این حجم از rule باشد.
۳. دادهها متنی و بدون ساختار هستند
اگر ورودی شما متن، سند، ایمیل یا گفتوگو با کاربر است (مثل بررسی پرونده بیمه یا درخواست پشتیبانی)، agent انتخاب منطقیتری است.
مبانی طراحی Agentهای هوشمند (Agent Design Foundations)
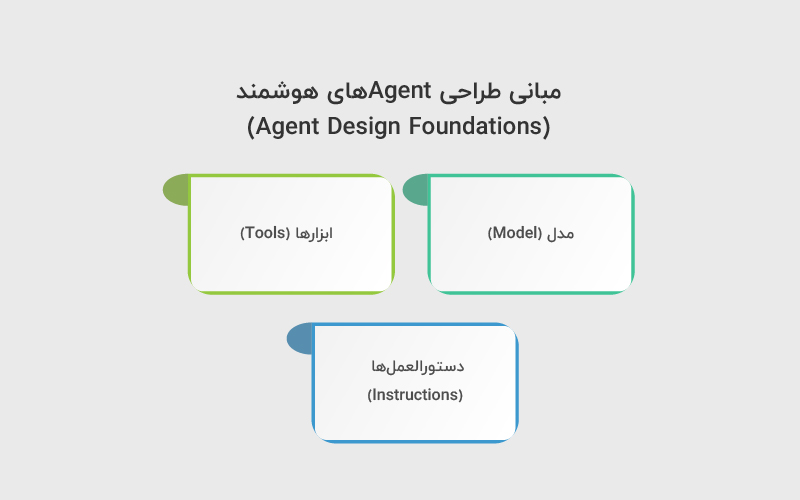
در سادهترین تعریف، یک AI Agent از سه جزء اصلی تشکیل میشود. این سه جزء هسته هر پیادهسازی دستی agent را میسازند:
۱. مدل (Model)
مدل زبانی یا LLM مغز agent است. این بخش مسئول درک ورودی کاربر، تحلیل موقعیت و تصمیمگیری دربارهی گام بعدی است.
۲. ابزارها (Tools)
ابزارها همان توابع یا APIهایی هستند که agent میتواند برای انجام کارهای واقعی از آنها استفاده کند؛ مثل انجام محاسبه، جستوجو در دادهها یا فراخوانی یک سرویس خارجی.
۳. دستورالعملها (Instructions)
قوانینی که مشخص میکنند agent چگونه رفتار کند، چه زمانی از ابزار استفاده کند و چه محدودیتهایی دارد. این بخش معمولا در قالب system prompt پیادهسازی میشود.
قبل از کدنویسی Agent چه تصمیمهایی باید بگیریم؟
پیادهسازی دستی agent فقط نوشتن کد نیست؛ قبل از آن باید چند تصمیم معماری مهم گرفته شود:
- agent به چه ابزارهایی دسترسی دارد؟
- چه کسی تصمیم میگیرد کدام ابزار اجرا شود؟ مدل زبانی یا کد برنامه؟
- agent چگونه وضعیت گفتگو یا حافظه را نگه میدارد؟
- از function calling آمادهی OpenAI استفاده میکنیم یا خودمان آن را شبیهسازی میکنیم؟
در این مقاله، رویکرد شبیهسازی دستی function calling را انتخاب میکنیم؛ یعنی از مدل میخواهیم ابزار مناسب را پیشنهاد دهد و اجرای ابزار را خودمان در کد کنترل میکنیم.
مرحله اول: تعریف ابزارها (Tools)
ابتدا ابزارهایی را که agent اجازه دارد از آنها استفاده کند، بهصورت توابع پایتون تعریف میکنیم.
ابزار محاسبهگر
|
1 2 3 4 5 6 7 8 9 10 |
import re def calculate_expression(expression): safe_expr = re.sub(r‘[^0-9+\-*/(). ]’, ”, expression) if safe_expr.strip() == “”: return None try: return eval(safe_expr) except: return None |
در اینجا:
- ورودی پاکسازی میشود تا فقط عبارات ریاضی باقی بماند
- agent اجازه اجرای کد دلخواه کاربر را ندارد
- خروجی یا نتیجهی محاسبه است یا None
ابزار جستجوی دانش (شبیهسازیشده)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
knowledge_base = { “python”: “Python یک زبان برنامهنویسی محبوب با خوانایی بالا است.”, “openai”: “OpenAI شرکتی است که ChatGPT را توسعه داده است.”, “ai”: “AI مخفف Artificial Intelligence یا هوش مصنوعی است.” } def search_knowledge(query): q = query.lower() for keyword, value in knowledge_base.items(): if keyword in q: return value return None |
این فقط یک شبیهسازی ساده است. در دنیای واقعی، این بخش میتواند دیتابیس، سرچ داخلی یا API باشد.
مرحله دوم: وادار کردن LLM به انتخاب ابزار (Tool Routing)
در این مرحله، بهجای استفاده از function calling آماده، از مدل میخواهیم تصمیم بگیرد:
- کدام ابزار؟
- با چه ورودیای؟
Prompt مخصوص انتخاب ابزار
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import openai import os openai.api_key = os.getenv(“OPENAI_API_KEY”) def query_openai_tool_selector(user_input): messages = [ { “role”: “system”, “content”: ( “You are an AI assistant. Based on the user’s message, “ “decide which tool to use: ‘calculator’, ‘knowledge_search’, or ‘none’. “ “Respond ONLY with a JSON object like:\n” “{ \”tool\”: \”calculator\”, \”input\”: \”5 * (4 + 3)\” }” ) }, {“role”: “user”, “content”: user_input} ] response = openai.ChatCompletion.create( model=“gpt-3.5-turbo”, messages=messages ) try: tool_call = eval(response.choices[0].message[“content”]) return tool_call.get(“tool”), tool_call.get(“input”) except: return “none”, user_input |
در اینجا:
- مدل فقط تصمیمگیرنده است
- هیچ ابزاری اجرا نمیکند
- خروجی آن یک ساختار قابلپردازش برای کد ماست
مرحله سوم: اجرای ابزار و تولید پاسخ نهایی
حالا تصمیم مدل را میگیریم و در لایهی اپلیکیشن اجرا میکنیم.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
def query_openai(user_input): tool, tool_input = query_openai_tool_selector(user_input) if tool == “calculator”: result = calculate_expression(tool_input) return f“نتیجه محاسبه: {result}” if result else “محاسبه امکانپذیر نیست.” elif tool == “knowledge_search”: result = search_knowledge(tool_input) return result if result else “اطلاعاتی پیدا نشد.” else: response = openai.ChatCompletion.create( model=“gpt-3.5-turbo”, messages=[ {“role”: “system”, “content”: “You are a helpful assistant.”}, {“role”: “user”, “content”: user_input} ] ) return response.choices[0].message[“content”] |
مرحله چهارم: حلقهی اصلی Agent (Agent Loop)
در نهایت، agent را در یک حلقهی تعاملی اجرا میکنیم:
|
1 2 3 4 5 6 7 8 9 10 |
print(“Agent آماده است. برای خروج، ‘quit’ را وارد کنید.”) while True: user_input = input(“You: “) if user_input.lower() == “quit”: print(“Agent: خداحافظ!”) break response = query_openai(user_input) print(“Agent:”, response) |
جریان کامل اجرای Agent
مثال زیر نشان میدهد agent چگونه فکر میکند و عمل میکند:
ورودی کاربر
|
1 |
What‘s 7 * (2 + 3)? |
تصمیم مدل
|
1 |
{ “tool”: “calculator”, “input”: “7 * (2 + 3)” } |
اجرای ابزار در پایتون
|
1 |
35 |
پاسخ نهایی agent
|
1 |
نتیجه محاسبه: 35 |
چه زمانی پیادهسازی دستی بهتر از استفاده از فریمورک است؟
با وجود تمام چالشها، پیادهسازی دستی همیشه انتخاب بدی نیست. در برخی سناریوها، حتی گزینهی منطقیتری نسبت به فریمورکهای آماده محسوب میشود.
۱. پروژههای کوچک یا بسیار خاص
اگر پروژه:
- دامنهی محدود دارد
- فقط به چند ابزار مشخص نیاز دارد
- یا workflow آن ساده و قابل کنترل است
پیادهسازی دستی میتواند سریعتر و سبکتر از استفاده از یک فریمورک کامل باشد. در این حالت، overhead فریمورک بیشتر از ارزشی است که ایجاد میکند.
۲. نیاز به کنترل دقیق رفتار Agent
در برخی پروژهها، رفتار agent باید کاملا قابل پیشبینی و قابل توضیح باشد؛ برای مثال:
- سیستمهای حساس
- کاربردهای سازمانی
- یا سناریوهایی که نیاز به audit دارند
در این موارد، پیادهسازی دستی اجازه میدهد:
- هر تصمیم agent قابل ردیابی باشد
- منطق انتخاب ابزار شفاف بماند
- و هیچ رفتار پنهانی از سمت فریمورک وجود نداشته باشد
۳. سناریوهای تحقیقاتی و آزمایشی
برای اهداف آموزشی، تحقیقاتی یا R&D، پیادهسازی دستی ارزش زیادی دارد.
چون توسعهدهنده:
- دقیقا میبیند agent چگونه فکر میکند
- محدودیتهای واقعی LLM را لمس میکند
- و میتواند ایدههای جدید را بدون قید فریمورک آزمایش کند
به همین دلیل، بسیاری از تیمها ابتدا agent را بهصورت دستی پیادهسازی میکنند و بعد، در صورت نیاز، به سمت فریمورکها میروند.
چالشهای پیادهسازی دستی AI Agent
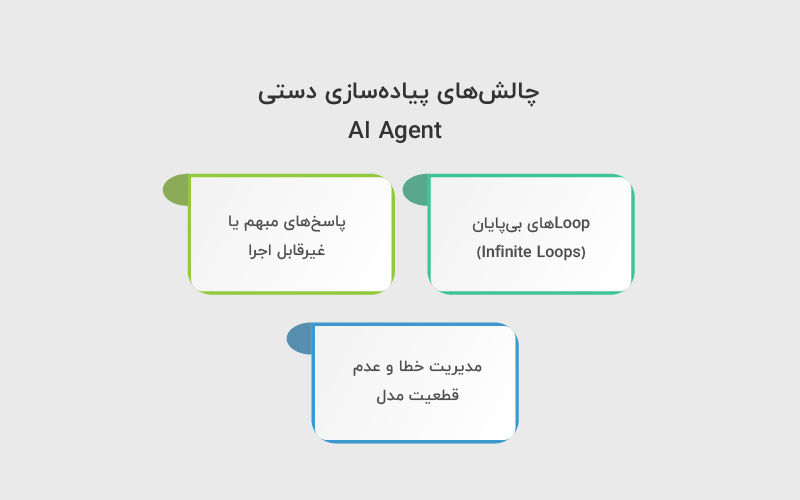
پیادهسازی دستی agentها، اگرچه درک عمیقتری از نحوهی کار آنها میدهد، اما بدون چالش نیست. برخلاف فریمورکهای آماده که بسیاری از این مسائل را پنهان یا مدیریت میکنند، در پیادهسازی دستی همهچیز مستقیما بر عهدهی توسعهدهنده است.
۱. Loopهای بیپایان (Infinite Loops)
یکی از رایجترین مشکلات در agentهای دستی، گیر افتادن در حلقههای تصمیمگیری بیپایان است.
از آنجا که agent معمولا بر اساس خروجی مدل تصمیم میگیرد که «مرحلهی بعدی چیست»، اگر شرایط توقف (Termination Conditions) بهدرستی تعریف نشوند، agent ممکن است:
- بارها و بارها یک ابزار را صدا بزند
- مدام سعی کند پاسخ را «بهبود» دهد
- یا بین چند تصمیم تکراری نوسان کند
برای مثال، اگر agent پس از هر پاسخ دوباره تصمیم بگیرد که «آیا نیاز به ابزار هست یا نه» و هیچ سیگنال روشنی برای پایان کار نداشته باشد، عملا وارد یک loop میشود.
به همین دلیل، در پیادهسازی دستی لازم است:
- تعداد گامها (steps) محدود شود
- شرایط پایان workflow بهصورت صریح تعریف شود
- یا کنترل نهایی در برخی نقاط به کاربر بازگردد
۲. پاسخهای مبهم یا غیرقابل اجرا
مدلهای زبانی ذاتا قطعی نیستند. در پیادهسازی دستی، این موضوع خودش را بیشتر نشان میدهد، چون ما مستقیما به خروجی مدل تکیه میکنیم.
برخی از مشکلات رایج عبارتاند از:
- انتخاب ابزار اشتباه برای یک درخواست
- تولید ورودی نامعتبر برای ابزار
- خروجیهایی که ساختار مورد انتظار را ندارند (مثلا JSON ناقص یا خراب)
در مثالهای ساده، ممکن است مدل بهجای برگرداندن:
|
1 |
{ “tool”: “calculator”, “input”: “5 + 3” } |
در پیادهسازی دستی، باید فرض را بر این گذاشت که:
- مدل ممکن است اشتباه کند
- خروجی همیشه قابل اعتماد نیست
- نیاز به validation و fallback وجود دارد
به همین دلیل، کد agent معمولا شامل لایههایی برای:
- بررسی صحت خروجی مدل
- مدیریت پاسخهای ناقص
- و بازگشت به حالت امن (safe mode) است
۳. مدیریت خطا و عدم قطعیت مدل
برخلاف کدهای سنتی که رفتار مشخص و قابل پیشبینی دارند، agentهای مبتنی بر LLM با عدم قطعیت (Uncertainty) کار میکنند. این یعنی:
- دو درخواست مشابه ممکن است خروجی متفاوتی داشته باشند
- مدل ممکن است در شرایط خاص تصمیمهای غیرمنتظره بگیرد
- یا حتی درک نادرستی از هدف کاربر داشته باشد
در پیادهسازی دستی، این موضوع باعث میشود مدیریت خطا پیچیدهتر شود. خطا فقط به معنای exception در کد نیست، بلکه شامل مواردی مثل:
- تصمیم اشتباه agent
- انتخاب ابزار نامناسب
- یا پاسخ نادرست ولی ظاهراً منطقی
برای کاهش این ریسکها، معمولا از ترکیبی از این روشها استفاده میشود:
- تعریف guardrail در prompt
- محدودکردن دامنهی تصمیمگیری agent
- و ثبت لاگ برای بررسی رفتار agent در طول زمان
جمعبندی
پیادهسازی دستی AI Agentها یک مسیر ساده یا بیدردسر نیست، اما دید عمیقی نسبت به نحوهی کار این سیستمها ایجاد میکند. در نهایت، انتخاب بین پیادهسازی دستی و استفاده از فریمورکها یک trade-off است:
- فریمورکها ← سرعت توسعه بالاتر، پیچیدگی کمتر
- پیادهسازی دستی ← کنترل بیشتر، انعطافپذیری بالاتر
نگاه واقعبینانه این است که AI Agentها «جادویی» نیستند؛ آنها سیستمهایی هستند متشکل از مدل، ابزار و منطق کنترلی. هرچه این اجزا را بهتر بشناسیم، تصمیمهای بهتری در طراحی و پیادهسازی آنها خواهیم گرفت.
منابع




دیدگاهتان را بنویسید