
سوگیری در هوش مصنوعی فقط یک بحث فنی یا دانشگاهی نیست؛ این پدیده امروز بهطور مستقیم روی زندگی ما تاثیر میگذارد، از استخدام و وام بانکی گرفته تا تشخیص چهره، پیشنهاد محتوا و حتی تصمیمهای قضایی. بسیاری تصور میکنند الگوریتمها بیطرف و عاری از قضاوت انسانی هستند اما واقعیت این است که سوگیری در هوش مصنوعی میتواند به شکل پنهان اما بسیار اثرگذار، تبعیض و ناعدالتی را بازتولید کند.
در این مقاله از بلاگ آسا بهصورت ساده و کاربردی بررسی میکنیم که سوگیری در هوش مصنوعی دقیقا چیست، از کجا وارد مدلها میشود، چه انواعی دارد و چه آسیبهایی در دنیای واقعی ایجاد کرده است. همچنین روشهای عملی برای کاهش بایاس در سیستمهای هوش مصنوعی، مفهوم عدالت الگوریتمی و نقش توسعهدهندگان و شرکتها را بررسی میکنیم تا بتوانیم هوشمندانهتر از AI استفاده کنیم.
سوگیری در هوش مصنوعی چیست؟

سوگیری در هوش مصنوعی (AI Bias) به وضعیتی گفته میشود که یک سیستم هوش مصنوعی بهجای تصمیمگیری منصفانه و بیطرف، به نفع یا ضرر یک فرد یا یک گروه خاص عمل میکند. این اتفاق معمولا زمانی رخ میدهد که دادههایی که برای آموزش مدل استفاده شدهاند، خودشان دارای نابرابری، تبعیض یا عدم توازن باشند. در چنین شرایطی، الگوریتم نهتنها بیطرف نیست، بلکه همان سوگیریهای انسانی و اجتماعی را با سرعت و مقیاسی بسیار بزرگتر بازتولید میکند.
برخلاف تصور رایج، هوش مصنوعی ذاتا عادل یا ناعادل نیست؛ این دادهها، فرضیات طراحان و نوع طراحی الگوریتم هستند که جهتگیری آن را مشخص میکنند. اگر دادههای ورودی نماینده همه افراد جامعه نباشند، یا اگر یک گروه خاص در دادهها بیشازحد پررنگ شده باشد، خروجی مدل نیز به همان سمت متمایل میشود. به همین دلیل است که میبینیم برخی سیستمهای تشخیص چهره در شناسایی افراد با رنگ پوست تیره دقت کمتری دارند یا بعضی الگوریتمهای استخدام، بهطور ناخودآگاه رزومه مردان را در اولویت قرار میدهند.
نکته مهم اینجاست که سوگیری در هوش مصنوعی همیشه آشکار و قابل مشاهده نیست. گاهی خروجیها ظاهرا منطقی به نظر میرسند اما اگر دقیقتر بررسی کنیم، متوجه میشویم یک الگوی تبعیضآمیز در تصمیمها وجود دارد. همین پنهان بودن سوگیری، آن را به یکی از خطرناکترین چالشهای هوش مصنوعی تبدیل کرده است؛ چون ممکن است بدون اینکه متوجه شویم، به تصمیمهای ناعادلانه اعتماد کنیم.
در واقع، هر جا که تصمیمگیری خودکار بر اساس داده انجام میشود، از سیستمهای پیشنهاد محتوا در شبکههای اجتماعی گرفته تا اعتبارسنجی مالی، استخدام، تشخیص پزشکی و نظارت تصویری، احتمال بروز سوگیری در هوش مصنوعی وجود دارد. به همین دلیل، شناخت دقیق این مفهوم، اولین و مهمترین قدم برای مقابله با تبعیض الگوریتمی و حرکت به سمت هوش مصنوعی عادلانهتر است.
سوگیری در هوش مصنوعی چگونه شکل میگیرد؟
سوگیری در هوش مصنوعی معمولا یک اتفاق تصادفی نیست، بلکه حاصل زنجیرهای از تصمیمها در مسیر طراحی، آموزش و پیادهسازی مدل است. این سوگیری میتواند از همان لحظهای که دادهها جمعآوری میشوند آغاز شود و تا مرحله تفسیر خروجی توسط انسان ادامه پیدا کند. بهطور کلی، سه نقطه اصلی وجود دارد که بایاس در آنها شکل میگیرد: دادهها، الگوریتم و انسان.
سوگیری در دادهها رایجترین و خطرناکترین منش بایاس است. اگر دادههای آموزشی نماینده همه گروههای جامعه نباشند، مدل نیز تصویری ناقص و ناعادلانه از واقعیت یاد میگیرد.
سوگیری در طراحی الگوریتم به نحوه وزندهی ویژگیها، انتخاب متغیرها و حتی نوع مسئلهبندی برمیگردد. گاهی یک الگوریتم به شکلی طراحی میشود که ناخواسته به نفع یک گروه خاص تصمیمگیری کند، بدون آنکه سازنده در لحظه متوجه این موضوع باشد.
سوگیری انسانی نیز نقش بسیار مهمی دارد. فرضیات ذهنی توسعهدهندگان، اولویتهای تجاری سازمانها و حتی نحوه تفسیر خروجی مدل توسط کاربران میتواند باعث تشدید بایاس شود. به زبان ساده، چون انسان در تمام مراحل حضور دارد، رد پای سوگیریهای انسانی هم بهنوعی وارد سیستمهای هوش مصنوعی میشود.
انواع سوگیری در هوش مصنوعی
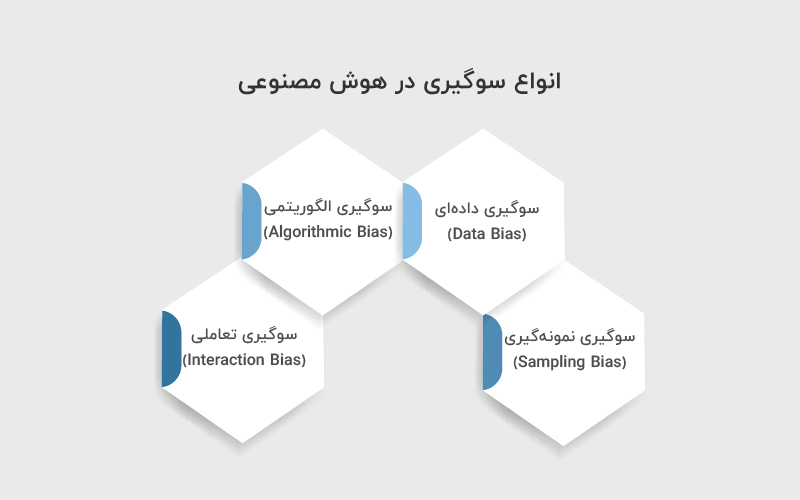
سوگیری در هوش مصنوعی فقط یک شکل ندارد و بسته به محلی که ایجاد میشود، میتواند انواع مختلفی داشته باشد. شناخت این دستهبندیها کمک میکند راحتتر منش خطا را پیدا کنیم و برای اصلاح آن اقدام کنیم.
۱. سوگیری دادهای (Data Bias): زمانی رخ میدهد که دادهها ناقص، نامتوازن یا تحریفشده باشند. برای مثال، اگر دادههای مربوط به استخدام بیشتر مربوط به یک گروه جنسیتی باشد، مدل نیز همان الگو را بازتولید میکند.
۲. سوگیری الگوریتمی (Algorithmic Bias): زمانی شکل میگیرد که منطق تصمیمگیری مدل به شکلی تنظیم شده باشد که یک گروه را در اولویت یا حاشیه قرار دهد.
۳. سوگیری نمونهگیری (Sampling Bias): زمانی اتفاق میافتد که فقط بخشی از جامعه در دادهها بازنمایی شود و سایر گروهها نادیده گرفته شوند.
۴. سوگیری تعاملی (Interaction Bias): این نوع سوگیری از رفتار کاربران در طول زمان ایجاد میشود. برای مثال، در سیستمهای پیشنهاد محتوا، رفتار کاربران میتواند الگوریتم را به سمت تقویت کلیشهها سوق دهد.
نمونههای واقعی از سوگیری در هوش مصنوعی
وقتی هوش مصنوعی به دلیل سوگیری دچار خطا میشود، مثلا فرصتهایی از گروهی از افراد گرفته میشود، افراد به اشتباه در تصاویر شناسایی میشوند یا ناعادلانه تنبیه میشوند، سازمانی که از آن سیستم استفاده کرده، آسیب جدی به اعتبار و برند خود وارد میکند. در عین حال، افراد آن گروهها و حتی کل جامعه ممکن است دچار آسیب شوند، بدون اینکه الزاما متوجه منشا آن باشند. در ادامه، چند نمونه شاخص از تبعیض و سوگیری در هوش مصنوعی و آسیبهایی که ایجاد کردهاند آمده است.
در حوزه سلامت، اگر دادههای مربوط به زنان یا اقلیتها بهدرستی در مجموعه دادهها نمایندگی نشوند، الگوریتمهای پیشبینی دچار انحراف میشوند. برای مثال، مشخص شده که سیستمهای تشخیص پزشکی مبتنی بر کامپیوتر (CAD) در تشخیص بیماران آفریقاییتبار دقت کمتری نسبت به بیماران سفیدپوست دارند.
در حوزه استخدام، ابزارهای خودکار بررسی رزومه میتوانند فرایند جذب نیرو را سریعتر کنند، اما نوع اطلاعاتی که دریافت میکنند و نحوه غربالگری، ممکن است منجر به نتایج ناعادلانه بین گروهها شود. برای مثال، اگر در آگهی شغلی از واژهای مثل «نابغه» یا «نینجا» استفاده شود، ممکن است مردان بیشتری جذب شوند تا زنان، در حالی که این موضوع هیچ ارتباطی با شایستگی شغلی ندارد.
بلومبرگ در یک آزمایش بیش از ۵۰۰۰ تصویر با هوش مصنوعی تولید کرد و به این نتیجه رسید که «دنیای Stable Diffusion توسط مردان سفیدپوست مدیر اداره میشود. زنان بهندرت پزشک، وکیل یا قاضی هستند. مردان با پوست تیره مجرم نمایش داده میشوند و زنان با پوست تیره اغلب در حال کارهای ساده مثل فستفود دیده میشوند.»
Midjourney نیز در آزمایشی مشابه نشان داد که وقتی از AI خواسته میشود افراد در مشاغل تخصصی را تصویرسازی کند، افراد مسن همیشه مرد هستند و این موضوع کلیشه جنسیتی نقش زنان در محیط کار را تقویت میکند.
در حوزه عدالت کیفری، ابزارهای پیشبینی جرم که در برخی کشورها استفاده میشوند، قرار است مناطقی را که احتمال وقوع جرم در آنها بالاست شناسایی کنند. اما چون این ابزارها بر اساس دادههای قدیمی بازداشتها آموزش دیدهاند، عملا الگوهای قدیمی تبعیض نژادی را تقویت کرده و باعث هدفگیری بیش از حد اقلیتها میشوند.
این مثالها نشان میدهد که اگر سوگیری کنترل نشود، میتواند به شکل مستقیم روی زندگی، شغل، آزادی و فرصتهای انسانها اثر بگذارد.
چرا سوگیری در هوش مصنوعی خطرناک است؟
خطر سوگیری در هوش مصنوعی فقط در تبعیض خلاصه نمیشود، بلکه پیامدهای عمیقتری نیز دارد. وقتی یک سیستم هوشمند تصمیم اشتباه میگیرد، این تصمیم میتواند به شکل گسترده و خودکار هزاران یا میلیونها نفر را تحتتاثیر قرار دهد. این یعنی یک اشتباه کوچک، تبدیل به یک بحران بزرگ در مقیاس اجتماعی میشود.
از طرف دیگر، سوگیری باعث از بین رفتن اعتماد عمومی به فناوری میشود. اگر کاربران احساس کنند که هوش مصنوعی علیه آنها تصمیم میگیرد، پذیرش این فناوری بهطور جدی کاهش پیدا میکند. علاوه بر این، در بسیاری از کشورها، پیامدهای حقوقی و جریمههای سنگینی برای استفاده از الگوریتمهای تبعیضآمیز در نظر گرفته شده است.
عدالت در هوش مصنوعی یعنی چه؟
عدالت در هوش مصنوعی (AI Fairness) به این معناست که سیستمهای هوشمند بدون تبعیض، صرفنظر از جنسیت، نژاد، سن، موقعیت جغرافیایی یا وضعیت اقتصادی افراد تصمیمگیری کنند. هدف عدالت الگوریتمی این است که هیچ گروهی بهصورت سیستماتیک در موقعیت ضعیفتری قرار نگیرد.
عدالت در AI فقط یک ویژگی فنی نیست، بلکه ترکیبی از اخلاق، حقوق، فناوری و سیاستگذاری است. یعنی هم توسعهدهنده، هم سازمان و هم قانونگذار در تحقق آن نقش دارند.

نقش شفافیت در تحقق عدالت الگوریتمی
شفافیت یکی از ابزارهای کلیدی برای کاهش سوگیری است. وقتی الگوریتم و منطق تصمیمگیری آن شفاف باشد:
- کاربران و ناظران میتوانند بررسی کنند که آیا سیستم منصفانه عمل میکند یا خیر؛
- توسعهدهندگان میتوانند نقاط ضعف مدل و بایاسهای بالقوه را شناسایی و اصلاح کنند؛
- سازمانها میتوانند گزارشهای عملکرد عادلانه ارائه دهند و اعتماد عمومی را حفظ کنند.
شفافیت یعنی قابلیت دسترسی و فهم روند تصمیمگیری الگوریتم توسط افراد ذینفع.
عدالت یعنی خروجی یکسان برای همه یا رفتار متناسب با تفاوتها؟
عدالت الگوریتمی صرفا به معنای «یکسان بودن همه چیز برای همه» نیست. گاهی عدالت واقعی یعنی در نظر گرفتن تفاوتها و ارائه پاسخ متناسب با نیاز و شرایط هر فرد یا گروه.
مثال: در سیستمهای آموزشی، ممکن است یک الگوریتم برای دانشآموزان مدارس کمبرخوردار امکانات یا توجه بیشتری ارائه دهد تا فرصتی برابر با دانشآموزان مدارس برخوردار داشته باشند.
چگونه میتوان سوگیری در هوش مصنوعی را کاهش داد؟
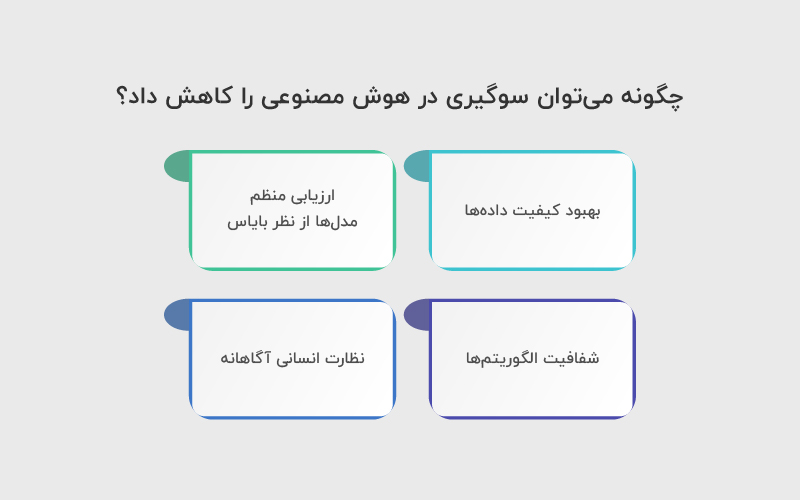
کاهش سوگیری در هوش مصنوعی نیازمند مجموعهای از اقدامات فنی و مدیریتی است.
اولین و مهمترین اقدام، بهبود کیفیت دادهها است. دادهها باید متنوع، متوازن و نماینده همه گروههای جامعه باشند.
دومین گام، ارزیابی منظم مدلها از نظر بایاس است. یعنی خروجی سیستم بهصورت دورهای بررسی شود تا الگوهای تبعیضآمیز شناسایی شوند.
سوم، شفافیت الگوریتمها اهمیت بسیار زیادی دارد. هر چه منطق تصمیمگیری مدل شفافتر باشد، تشخیص سوگیری و اصلاح آن سادهتر میشود.
در نهایت، نظارت انسانی آگاهانه نقش کلیدی دارد. تصمیم نهایی در بسیاری از موارد نباید فقط به یک مدل خودکار سپرده شود.
نقش قوانین و مقررات در کنترل سوگیری هوش مصنوعی
در بسیاری از کشورها، قوانین داده و هوش مصنوعی سختگیرانهتر میشوند. مقرراتی مانند GDPR در اروپا، توسعهدهندگان را ملزم میکند که از تبعیض الگوریتمی جلوگیری کنند و حق اعتراض به تصمیم خودکار را برای کاربران به رسمیت بشناسند.
این قوانین عملا سازمانها را مجبور میکنند که پیش از استفاده از AI، ریسکهای سوگیری و تبعیض را ارزیابی کنند و مستندات شفاف داشته باشند.
ما بهعنوان کاربر چه نقشی داریم؟
کاربران هم در برابر سوگیری در هوش مصنوعی کاملا بینقش نیستند. آگاهی از نحوه جمعآوری داده، دقت در مجوزهایی که به اپلیکیشنها میدهیم، و پرسشگری درباره تصمیمهای خودکار، همه بخشی از مسئولیت ماست.
هر جا تصمیمی بدون توضیح شفاف توسط یک سیستم گرفته شد، باید نسبت به آن حساس باشیم و حق پرسش و اعتراض را برای خودمان قائل شویم.
چرا «بیطرف بودن الگوریتم» از نظر حقوقی کافی نیست؟
بیطرف بودن تنها به معنای عدم جانبداری آشکار نیست. حتی الگوریتمی که بهظاهر منصف است میتواند نتایج ناعادلانه تولید کند. به همین دلیل قوانین و مقررات، سازمانها را ملزم میکنند که نه فقط بیطرف بودن، بلکه عدالت در خروجیها و اثرات واقعی سیستم را تضمین کنند.
ارزیابی ریسک تبعیض قبل از استفاده از AI
قبل از پیادهسازی هر سیستم هوش مصنوعی، لازم است ارزیابی ریسک تبعیض و سوگیری انجام شود. این شامل:
- بررسی دادههای ورودی برای نمایندگی کامل همه گروهها؛
- شبیهسازی تصمیمها در سناریوهای مختلف؛
- پیشبینی اثرات اجتماعی و اقتصادی الگوریتم.
هدف این است که قبل از آنکه سیستم وارد دنیای واقعی شود، نقاط ضعف و خطرات تبعیض شناسایی و اصلاح شوند.
جمعبندی: سوگیری در هوش مصنوعی، چالشی فنی یا مسئلهای انسانی؟
سوگیری در هوش مصنوعی نشان میدهد که فناوری، هرچقدر هم پیشرفته باشد، بازتابی از دادهها و تصمیمهای انسانی است. اگر دادهها ناعادلانه باشند، خروجیها هم ناعادلانه خواهند بود. مسیر رسیدن به هوش مصنوعی عادلانه از شفافیت، مسئولیتپذیری و آگاهی جمعی میگذرد؛ هم از سمت توسعهدهندگان، هم سازمانها و هم کاربران.
منابع
ibm.com | ico.org.uk | sap.com | chapman.edu | hbr.org
سوالات متداول
سوگیری میتواند منجر به تصمیمهای ناعادلانه در استخدام، اعتبارسنجی مالی، سلامت، آموزش و سیستمهای نظارتی شود. این تصمیمها نه تنها به گروههای خاص آسیب میرسانند، بلکه اعتماد عمومی به فناوری را نیز کاهش میدهند.
عدالت در هوش مصنوعی یعنی تصمیمهای سیستم بدون تبعیض و نابرابری باشد و هیچ گروهی بهصورت سیستماتیک در موقعیت ضعیفتری قرار نگیرد. عدالت الگوریتمی میتواند شامل تعدیل تصمیمها با توجه به تفاوتها باشد، نه صرفاً رفتار یکسان برای همه.
بله، قوانینی مانند GDPR در اروپا توسعهدهندگان و سازمانها را ملزم میکنند که ریسکهای تبعیض و سوگیری را بررسی کنند، شفافیت داشته باشند و حق اعتراض کاربران به تصمیمات خودکار را رعایت کنند.




دیدگاهتان را بنویسید