مدلهای زبانی بزرگ (LLMs) به یکی از ستونهای اصلی هوش مصنوعی امروزی تبدیل شدهاند و در زمینههایی مانند موتورهای جستجو، دستیارهای گفتگویی، تولید متن و تحلیل داده بهطور گسترده به کار گرفته میشوند. اما همه این مدلها به یک شکل در دسترس نیستند. برخی بهصورت متن باز (Open Source) ارائه میشوند و امکان مشاهده و تغییر کد و وزنها را فراهم میکنند؛ در حالیکه برخی دیگر تحت عنوان مدلهای متن بسته (Closed Source) تنها از طریق API یا سرویسهای ابری قابل استفاده هستند و کد منبع یا وزنهایشان محرمانه باقی میماند.
در این مقاله میخواهیم به شکل جامع به مدلهای متن بسته بپردازیم: اینکه دقیقا چه هستند، چه مزایا و معایبی دارند، چه نمونههای مهمی از آنها وجود دارد و چرا بسیاری از شرکتها و سازمانها همچنان به جای استفاده از مدلهای متن باز، سراغ این گزینه میروند.
معیارهای فنی مدلهای بسته
مدلهای بسته معمولا بر اساس معماریهای پیچیده و در مقیاس بسیار بزرگ طراحی میشوند. این معماریها تعداد پارامترهای زیادی دارند که تعیینکننده توانایی مدل در درک زبان و تولید پاسخهای دقیق است. یکی دیگر از شاخصهای کلیدی، اندازه پنجره کانتکست (Context Window) است که مشخص میکند مدل تا چه حد میتواند محتوای پیشین را در پردازش و تولید متن در نظر بگیرد.
از سوی دیگر، دادههای آموزشی نقشی حیاتی دارند. در مدلهای بسته، شرکتهای توسعهدهنده معمولا جزئیات کامل دادهها را افشا نمیکنند اما کیفیت و تنوع این دادهها تاثیر مستقیمی بر دقت و قابلیت تعمیمپذیری مدل میگذارد.
همچنین، فرایند آموزش مدل نیازمند منابع محاسباتی عظیم مانند GPUها یا TPUهای پیشرفته است. به همین دلیل، توسعه چنین مدلهایی تنها برای سازمانها یا شرکتهایی امکانپذیر است که بودجه و زیرساخت فنی لازم را در اختیار دارند.
انواع مدلهای منبع بسته (Closed-Source Models)
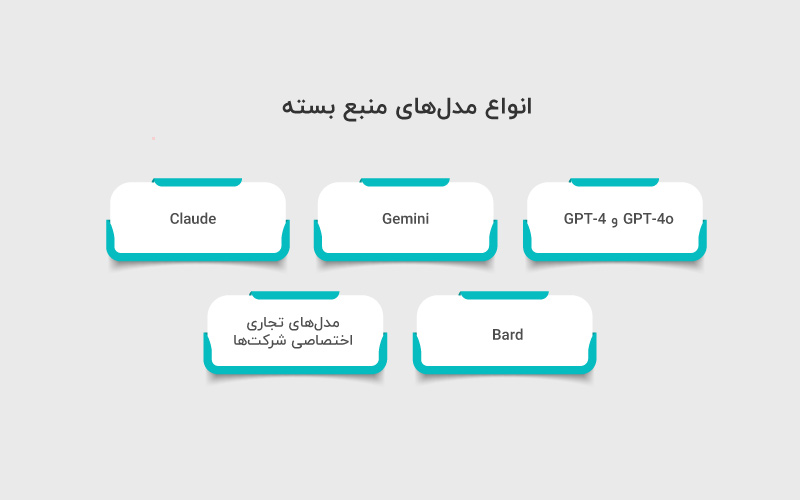
بسیاری از ابزارهای تجاری هوش مصنوعی از مدلهای زبان بزرگ متن بسته (Closed-Source LLMs) بهره میبرند و معمولا برای انجام مجموعهای مشخص از وظایف در صنایع خاص به کار گرفته میشوند. این مدلها معمولا شناختهشدهتر از مدلهای متن باز هستند.

انتخاب مدل متن بسته مناسب به نوع کاربرد بستگی دارد. برای نمونه، مدلهای عمومی طوری طراحی شدهاند که بتوانند طیف گستردهای از وظایف را انجام دهند، مانند مکالمه، خلاصهسازی، تولید محتوا و استدلال منطقی. انواع این مدلها عبارتند از:
GPT-4 و GPT-4o (محصول OpenAI)
این دو مدل از پیشرفتهترین و پرکاربردترین نمونههای بسته هستند. GPT-4 تواناییهای گستردهای در تولید متن، ترجمه، خلاصهسازی و تحلیل داده دارد، در حالی که GPT-4o نسخهای بهینهشده و چندوجهی است که میتواند علاوهبر متن، ورودیهای صوتی و تصویری را نیز پردازش کند. این ترکیب باعث شده کاربرد آنها در حوزههایی مثل تولید محتوا، دستیارهای هوشمند، آموزش و حتی تحلیل دادههای پیچیده روزبهروز گستردهتر شود.

Gemini (محصول گوگل)
گوگل با معرفی Gemini تلاش کرده مدلی چندوجهی ارائه دهد که قابلیت ترکیب دادههای متنی، تصویری و حتی صوتی را دارد. این مدل بیشتر در سرویسهای گوگل ادغام شده و به کاربران کمک میکند تا تجربه جستجو و تعامل هوشمندتری داشته باشند. تمرکز اصلی Gemini روی کارایی بالا، سرعت پردازش و ادغام عمیق با ابزارهای گوگل است.
Claude (محصول Anthropic)
Claude بهطور ویژه با محوریت ایمنی و شفافیت طراحی شده است. این مدل سعی میکند از تولید محتوای مضر جلوگیری کند و پاسخهایی دقیق اما در عین حال قابل اعتماد ارائه دهد. Claude برای استفاده در سازمانهایی که حساسیت بالایی نسبت به ریسکها و پیامدهای اخلاقی هوش مصنوعی دارند، انتخاب محبوبی است.

مدلهای تجاری اختصاصی شرکتها
علاوهبر نامهای شناختهشده، بسیاری از شرکتها و استارتاپها مدلهای بسته مخصوص خود را توسعه دادهاند. این مدلها معمولا برای استفاده داخلی یا ارائه خدمات اختصاصی به مشتریان ساخته میشوند. بهدلیل بسته بودن کد و دسترسی محدود، اطلاعات کمتری از معماری یا پارامترهای آنها در دسترس عموم است اما در حوزههایی مانند مالی، پزشکی و تحلیل دادههای سازمانی بسیار استفاده میشوند.
مدلهای متن بسته چگونه کار میکنند؟
مثل دیگر مدلهای زبان بزرگ، مدلهای متن بسته برای تولید متنی روان و شبیه به انسان آموزش داده میشوند و با یادگیری الگوها از مجموعه دادههای عظیم به این توانایی میرسند. این مدلها به روش منحصربهفردی توسعه و مدیریت میشوند: روشهای آموزش، منابع داده، وزنهای مدل و معماری آنها بهصورت عمومی منتشر نمیشوند.
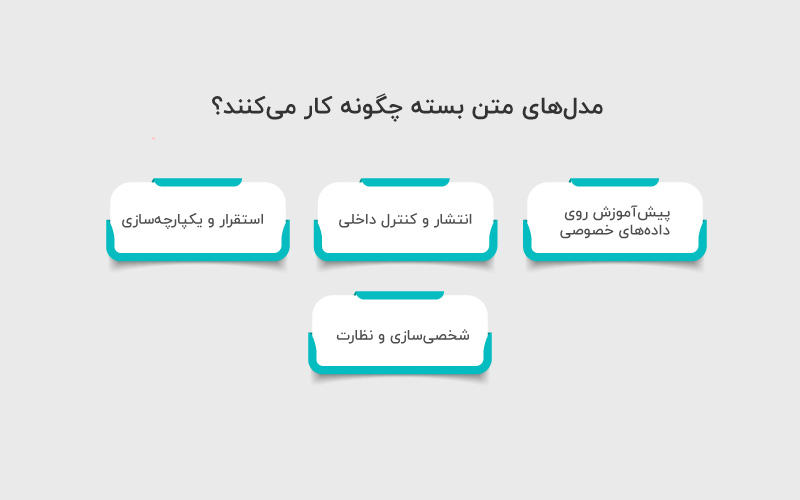
فرایند توسعه از پیشآموزش تا انتشار، یکپارچهسازی و نظارت شامل مراحل زیر است:
۱. پیشآموزش روی دادههای خصوصی
شرکتها مدلهای متن بسته خود را با استفاده از دادههای گسترده و باکیفیت آموزش میدهند که ممکن است شامل محتوای مجاز، دادههای عمومی و منابع اختصاصی باشد؛ با این حال، ترکیب دقیق دادهها معمولا فاش نمیشود.
دادهها براساس کاربردهایی که مدل برای آنها طراحی شده، انتخاب میشوند؛ برای مثال خدمات مشتری، پشتیبانی فنی یا تولید محتوای کسبوکاری.
آموزش مدل نیازمند قدرت محاسباتی قابل توجهی است و شرکتها معمولا از زیرساختهای اختصاصی یا همکاری با ارائهدهندگان ابری استفاده میکنند. در این مرحله، مدل دانش عمومی و ساختار زبان را یاد میگیرد و توانایی استدلال آن نیز شکل میگیرد.

۲. انتشار و کنترل داخلی
پس از آموزش، مدل میتواند در محیطهای کنترلشده مانند رابط وب یا نرمافزار سازمانی منتشر شود. کاربران میتوانند با مدل تعامل داشته باشند، اما قادر به مشاهده جزئیات ساختار و نحوه آموزش آن نخواهند بود.
معماری مدل (چگونگی ساختار شبکه عصبی) و وزنهای آموزش که شامل دانستههای مدل هستند، خصوصی نگه داشته میشوند. همچنین کدی که برای تولید پاسخ استفاده میشود، بهصورت عمومی در دسترس نیست.
۳. استقرار و یکپارچهسازی
پس از انتشار داخلی، شرکتها میتوانند از طریق APIهای امن یا پلتفرمهای نرمافزاری مدیریتشده توسط ارائهدهنده، به مدل دسترسی پیدا کنند. مدل همچنان توسط ارائهدهنده اصلی میزبانی میشود و کسبوکارها میتوانند آن را با سیستمهای خود از طریق API یا کانکتورهای آماده یکپارچه کنند.
با یکپارچهسازی، شرکتها میتوانند مدل را در وبسایت، چتباتها، ابزارهای اداری یا سیستمهای داخلی خود استفاده کنند بدون نیاز به مدیریت زیرساخت اصلی. ارائهدهنده مسئول مدیریت عملکرد سیستم، مقیاسبندی ظرفیت و رعایت استانداردهای امنیت و حفاظت دادهها است.
۴. شخصیسازی و نظارت
پس از استقرار و یکپارچهسازی، ارائهدهندگان استفاده از مدل را نظارت میکنند و ممکن است پاسخها را از طریق فاین تیونینگ داخلی بهبود دهند. همچنین میتوانند بهروزرسانیهای سیستم را بر اساس الگوهای استفاده اعمال کنند.
کاربران نهایی در فرایند فاین تیونینگ دخیل نیستند. اگرچه برخی پلتفرمها اجازه تغییرات جزئی مانند تنظیم حافظه یا قالبهای پرامپت را میدهند، مدل پایه هیچ تغییری نمیکند.
مزایا و معایب مدلهای منبع بسته
مدلهای بسته معمولا در کاربردهای خاص عملکرد بسیار بالایی دارند و برای کارهای تعیینشده بهینه شدهاند. علاوهبر این، پشتیبانی رسمی شرکت سازنده موجب اطمینان از بهروزرسانی، رفع اشکال و کمک فنی میشود. امنیت دادهها و کنترل کیفیت نیز از دیگر مزیتهاست؛ زیرا دادهها و فرایند آموزش تحت نظارت مستقیم ارائهدهنده است. همچنین پایش و رصد عملکرد مدل سادهتر است و شرکت میتواند به سرعت واکنش نشان دهد.
استفاده از مدلهای بسته معمولا هزینه بالایی دارد و بهدلیل عدم شفافیت در معماری و دادههای آموزش، کاربران نمیتوانند جزئیات عملکرد مدل را بررسی کنند. وابستگی به شرکت عرضهکننده باعث محدود شدن انعطافپذیری و ریسک وابستگی میشود و امکان سفارشیسازی مدل محدود است.
کاربرد مدلهای متن بسته
مدلهای متن بسته در بسیاری از ابزارها و خدمات روزمره کاربرد دارند. اگرچه شفافیت کمتری دارند اما بهدلیل پایداری و سهولت در ادغام، به ویژه در محیطهای تجاری، ارزشمند هستند.
این مدلها برای سازمانهایی که کارکنان آنها نسبت به استفاده از هوش مصنوعی تردید دارند، مفیدند. تحقیقات مککنزی نشان میدهد که ۴۱٪ کارکنان درباره امنیت سایبری و کیفیت خروجیهای هوش مصنوعی نگرانی دارند، که نشان میدهد در هنگام پیادهسازی هوش مصنوعی نیاز به حمایت بیشتری دارند. بنابراین دقت و مزایای امنیتی مدلهای متن بسته برای چنین شرایطی ایدئال است.
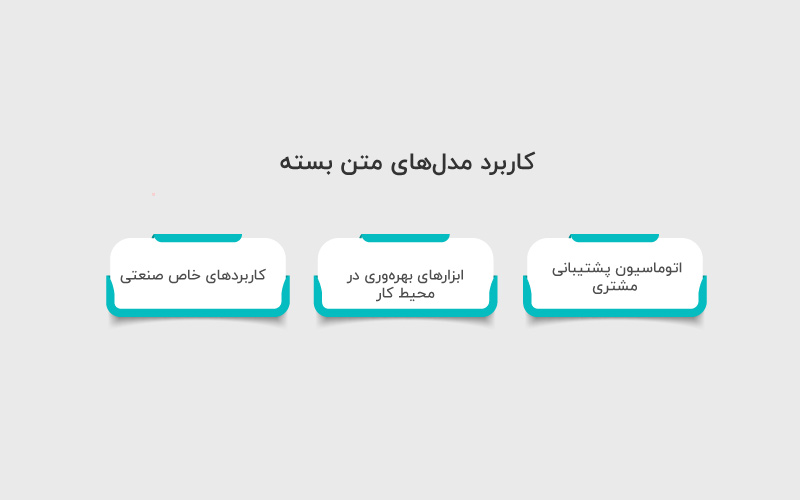
نمونههایی از کاربرد عملی مدلهای متن بسته عبارتند از:
- اتوماسیون پشتیبانی مشتری: بسیاری از کسبوکارها از مدلهای متن بسته برای مدیریت تعاملات خدمات مشتری استفاده میکنند. برای مثال، مدل Claude از Anthropic برای پاسخ به پرسشها و ارائه راهنمایی کاربرد دارد. تیمهای پشتیبانی اغلب از مدل برای رسیدگی به پرسشهای معمول استفاده میکنند تا کارکنان بتوانند روی موقعیتهای پیچیدهتر تمرکز کنند.
- ابزارهای بهرهوری در محیط کار: مدلهای متن بسته در ابزارهایی که به افراد در انجام وظایف نوشتاری و دادهای کمک میکنند نیز به کار میروند. برای نمونه، GPT-4 در Microsoft Copilot به کار گرفته شده است تا پیشنهاد تغییرات نگارشی بدهد و کاربران را در توضیح و تحلیل دادههای صفحات گسترده پشتیبانی کند. این مدل مستقیما در نرمافزار کار میکند و نیاز به جابهجایی بین ابزارها را کاهش میدهد.
- کاربردهای خاص صنعتی: سازمانهای بزرگ در حوزههای سلامت، مالی و حقوقی از LLMها از طریق پلتفرمهایی مانند IBM Watsonx.ai استفاده میکنند. این مدلها برای مدیریت اطلاعات حساس، تولید گزارش، کمک به بررسی اسناد طولانی و غیره تطبیق داده شدهاند. شرکتها این ابزارها را بهدلیل توانایی آنها در رعایت مقررات و نیازهای انطباقی انتخاب میکنند.

انتخاب بین مدلهای متنباز و مدلهای متن بسته

برای تصمیمگیری میان مدلهای متنباز و مدلهای متن بسته، چند معیار کلیدی وجود دارد. اگر سازمان شما بزرگ است، با پروژههای حساس سروکار دارد یا دادههای محرمانهای دارد، انتخاب یک مدل متن بسته منطقیتر است؛ زیرا این مدلها پایداری و امنیت بالاتری ارائه میدهند. از طرف دیگر، برای پژوهش، استارتاپها یا پروژههایی با بودجه محدود، مدلهای متنباز گزینه مناسبتری هستند؛ این مدلها انعطافپذیری و امکان سفارشیسازی بیشتری فراهم میکنند.
- معیار اصلی در انتخاب میان این دو نوع مدل شامل هزینهها، مقیاسپذیری، و میزان نیاز به سفارشیسازی است. با ارزیابی این عوامل، میتوان مناسبترین مدل را با توجه به نیازهای سازمان و پروژه انتخاب کرد.
این جدول مقایسهای از مدلهای متن باز (Open-source LLMs) و مدلهای متن بسته (Closed-source LLMs) ارائه میدهد:
| ویژگی | مدلهای متن باز | مدلهای متن بسته |
| دسترسی به کد و معماری | کاملا عمومی؛ میتوان کد، معماری و وزنها را مشاهده و ویرایش کرد | خصوصی؛ کد، وزنها و معماری در دسترس عموم نیست |
| شخصیسازی و فاینتیون | امکان تغییر و فاینتیون کامل توسط کاربران | محدود یا غیرممکن برای کاربران؛ شخصیسازی معمولا توسط ارائهدهنده انجام میشود |
| هزینه و زیرساخت | اغلب رایگان یا کمهزینه، نیازمند مدیریت زیرساخت توسط کاربر | معمولا نیازمند پرداخت اشتراک یا هزینه استفاده، زیرساخت توسط ارائهدهنده مدیریت میشود |
| شفافیت و امنیت داده | شفافیت بالا ولی مسئولیت امنیت داده با کاربر است | شفافیت کمتر ولی امنیت داده و مطابقت با استانداردها توسط ارائهدهنده تضمین میشود |
| سرعت و راحتی استفاده | ممکن است نیاز به پیکربندی و مدیریت منابع داشته باشد | آماده استفاده و سریع مناسب برای محیطهای تجاری و سازمانی |
| محدودیتهای کاربردی | انعطافپذیری بالا در کاربردها اما ممکن است نیاز به دانش فنی داشته باشد | کاربردهای محدودتر و هدفمند ولی بهینهشده برای صنایع خاص |
| بهروزرسانی و پشتیبانی | توسط جامعه متن باز انجام میشود؛ ممکن است منظم نباشد | بهروزرسانی و پشتیبانی حرفهای توسط شرکت ارائهدهنده انجام میشود |
ملاحظات حقوقی، اخلاقی و امنیتی در استفاده از منابع متن بسته
در استفاده از مدلهای هوش مصنوعی، توجه به جنبههای قانونی و اخلاقی اهمیت زیادی دارد. حفظ حریم خصوصی دادهها و جلوگیری از افشای اطلاعات حساس یکی از نکات کلیدی است. همچنین رعایت حقوق مالکیت معنوی، قوانین استفاده و مجوزها، بهویژه هنگام استفاده از دادهها و مدلهای خارجی، ضروری است. مدیریت ریسک تعصب (Bias)، خطا یا تولید محتوای نادرست (Hallucination) نیز اهمیت دارد تا خروجیهای مدل قابل اعتماد باشند. علاوهبر این، فراهم کردن امکان بازبینی و کنترل محتوا به سازمانها کمک میکند تا استفاده از هوش مصنوعی شفاف و ایمن باشد.
آینده مدلهای بسته در حوزه هوش مصنوعی
مدلهای بسته با وجود محدودیت دسترسی به ساختار و دادههایشان، نقش مهمی در صنایع مختلف ایفا میکنند. آنها بهدلیل پایداری، امنیت و سهولت یکپارچهسازی در محیطهای تجاری ارزشمند هستند و اغلب برای کاربردهایی انتخاب میشوند که نیاز به دقت و حفاظت اطلاعات بالا دارند.
- گرایش به مدلهای هیبریدی که ترکیبی از متنباز و بسته هستند و سعی میکنند مزایای هر دو را ارائه دهند.
- افزایش فشار قانونی و مقرراتی برای شفافیت بیشتر در نحوه آموزش، دادهها و عملکرد مدلها.
- پیشرفتهای فنی با هدف بهبود بهرهوری، کاهش هزینههای عملیاتی و ارائه تجربه کاربری بهتر.
جمعبندی
مدلهای متن بسته (Closed-source LLMs) با ارائه قابلیتهای قدرتمند و کنترلشده، راهحلهای ایمن و پایدار برای صنایع مختلف فراهم میکنند. این مدلها به شرکتها امکان میدهند بدون نیاز به مدیریت زیرساختهای پیچیده، از هوش مصنوعی در پشتیبانی مشتری، ابزارهای بهرهوری و کاربردهای تخصصی صنعتی استفاده کنند. با اینکه شفافیت این مدلها کمتر است، امنیت داده، دقت بالا و سهولت یکپارچهسازی، آنها را به گزینهای جذاب برای محیطهای تجاری و سازمانی تبدیل کرده است.
منابع
ai21.com | analyticsindiamag.com | datasciencedojo.com | dsstream.com | arcee.ai
سوالات متداول
بهدلیل امنیت، پایداری و راحتی استفاده؛ زیرساخت و پشتیبانی توسط ارائهدهنده مدیریت میشود و با استانداردهای سازمانی سازگار است.
معمولا خیر، فقط تغییرات محدود مثل تنظیم الگوهای پاسخ امکانپذیر است.
خدمات مشتری، ابزارهای بهرهوری و صنایع حساس مانند بهداشت، مالی و حقوقی.

دیدگاهتان را بنویسید