در دنیای بینایی ماشین، کیفیت دادهها بهاندازه معماری مدل اهمیت دارد. حتی دقیقترین شبکههای عصبی هم اگر با دادههای نامنظم، نویزی یا کمتنوع آموزش ببینند، نمیتوانند عملکرد مطلوبی داشته باشند. تصاویری با اندازههای متفاوت، روشناییهای ناهماهنگ یا سوژههایی که در موقعیتهای گوناگون قرار گرفتهاند، باعث میشوند مدل در مرحلهی یادگیری دچار خطا شود یا در شرایط واقعی دقتش کاهش یابد. درست همینجاست که پیشپردازش و تقویت دادهها بهعنوان دو گام حیاتی در فرایند آموزش مدلهای بینایی ماشین مطرح میشوند.
در این مقاله از بلاگ آسا به بررسی مراحل کلیدی آمادهسازی دادههای تصویری میپردازیم؛ از پیشپردازش برای پاکسازی، نرمالسازی و استانداردسازی دادهها تا تقویت داده با روشهایی مانند چرخش، برش و تغییر روشنایی تصاویر. همچنین نمونهکدهایی برای پیادهسازی این فرایندها در پایتون ارائه میشود تا ببینیم چگونه میتوان با ابزارهایی مانند Keras و Roboflow عملکرد مدلهای بینایی ماشین را بهبود داد.
افزایش داده به چه معناست؟
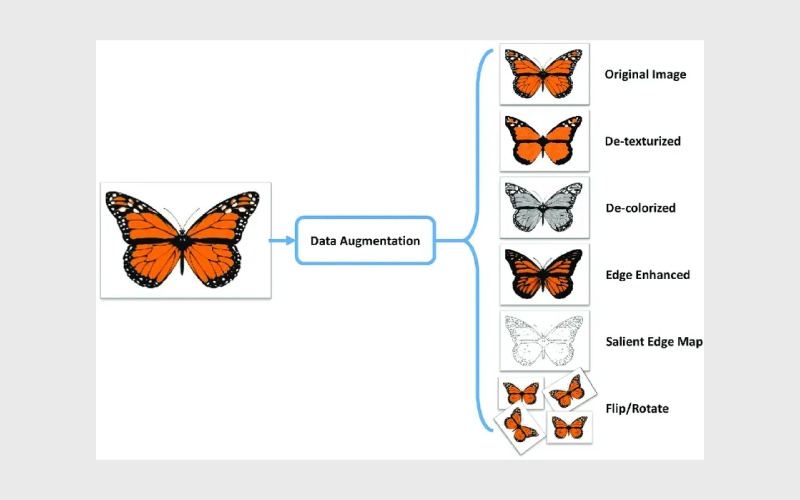
افزایش داده (Data Augmentation) فرایندی است که در آن مجموعه دادههای موجود با ایجاد نسخههای جدید و متنوع گسترش پیدا میکند. در دادههای تصویری، این کار معمولا از طریق تغییراتی مانند چرخش، وارونگی، برش، تغییر روشنایی یا افزودن نویز انجام میشود. هدف اصلی افزایش داده، بهبود تعمیمپذیری مدل و مقاومکردن آن در برابر تغییرات دنیای واقعی است، به طوری که مدل بتواند تصاویر ناشناخته را بهدرستی تحلیل کند.
در مقابل، داده مصنوعی (Synthetic Data) بهطور کامل توسط الگوریتمهای تولیدی مانند شبکههای GAN ایجاد میشود و مستقل از دادههای واقعی است. بنابراین، افزایش داده بر پایه نمونههای واقعی موجود انجام میشود، در حالی که داده مصنوعی از صفر ساخته میشود.
افزایش داده بهویژه زمانی که مجموعه داده محدود باشد اهمیت بیشتری پیدا میکند. این روش از بیشبرازش (overfitting) جلوگیری کرده و باعث میشود مدل دقت و کارایی بالاتری در دادههای جدید داشته باشد. با این حال، استفاده نادرست یا اعمال بیش از حد تغییرات میتواند منجر به تولید دادههای غیرواقعی یا مغرضانه شود و نتیجه آموزش را تحتتاثیر قرار دهد. همچنین اعتبارسنجی دادههای افزوده نیازمند دقت و تنظیم پارامترهاست تا بین تنوع و واقعگرایی تعادل برقرار شود.
تعریف پیشپردازش دادههای تصویری
پیشپردازش تصاویر یکی از مراحل پایهای آمادهسازی داده برای مدلهای بینایی ماشین است و هدف آن پاکسازی و استانداردسازی دادههاست تا مدل بتواند بهتر یاد بگیرد و تعمیمپذیری بالاتری داشته باشد. این مرحله شامل چندین تکنیک کلیدی است:
۱. تغییر اندازه (Resize)
تصاویر با ابعاد مختلف میتوانند باعث مشکل در ورودی شبکههای عصبی شوند. تغییر اندازه تصاویر به یک ابعاد استاندارد، هماهنگی دادهها را تضمین میکند و پردازش مدل را سریعتر و بهینهتر میسازد.
۲. نرمالسازی (Normalization / Rescaling)
نرمالسازی باعث میشود مقادیر پیکسلها در بازه مشخصی (مثلا ۰ تا ۱ یا -۱ تا ۱) قرار بگیرند. این کار سرعت همگرایی مدل را افزایش داده و از مشکلات عددی هنگام آموزش جلوگیری میکند.
۳. اصلاح جهت، برش و همترازی (Alignment / Cropping / Orientation)
گاهی تصاویر در زوایای متفاوت یا با سوژه نامتوازن هستند. اصلاح جهت، برش مناسب و همترازی سوژهها کمک میکند تا مدل روی اطلاعات اصلی تمرکز کند و کمتر تحتتاثیر نویز محیطی قرار گیرد.
۴. حذف نویز و افزایش وضوح (Denoising / Sharpening)
نویز تصویری میتواند کیفیت آموزش را کاهش دهد. فیلترها و تکنیکهای افزایش وضوح، جزئیات مهم تصویر را حفظ و نویز غیرضروری را حذف میکنند.
۵. تبدیل رنگ و کانالها (Color / Channel Transformations)
تبدیل تصاویر به مقیاس خاکستری یا تغییر کانالهای رنگی RGB میتواند باعث کاهش پیچیدگی داده و تمرکز مدل روی ویژگیهای مهم شود. این روشها در برخی کاربردها مانند بینایی پزشکی یا تشخیص اشیا موثر هستند.
تکنیکهای افزایش داده تصویری
افزایش داده تصویری (Image Data Augmentation) هسته فنی آمادهسازی داده برای مدلهای بینایی ماشین است. با استفاده از تکنیکهای مختلف، میتوان مجموعه داده را متنوعتر و مدل را در برابر تغییرات دنیای واقعی مقاومتر کرد. در ادامه مهمترین روشها و نکات کاربردی آنها آمده است:
تبدیلات هندسی (Geometric Transformations)
- چرخش (Rotation): تغییر زاویه تصویر برای افزایش تنوع دیدگاهها.
- برش (Crop): برش بخشهای مختلف تصویر برای تمرکز روی سوژههای متفاوت.
- وارونسازی (Flip): چرخاندن تصویر به صورت افقی یا عمودی.
- زوم و تغییر مقیاس (Zoom / Scaling): بزرگ یا کوچک کردن تصویر بدون تغییر نسبت طول و عرض.
نکته: این روشها ساده هستند و مدل را در مقابل تغییر زاویه یا اندازه مقاوم میکنند اما باید مطمئن شد که سوژه اصلی تصویر حفظ شود.
تبدیلات رنگی و کانالها (Color / Channel Transformations)
- تغییر روشنایی و کنتراست (Brightness / Contrast): شبیهسازی شرایط نوری متفاوت.
- تغییر اشباع و کانال RGB (Saturation / RGB Shift): تنوع رنگی تصاویر برای تعمیم بهتر مدل.
نکته: این روشها به مدل کمک میکنند تا تحت شرایط نوری یا رنگی مختلف، عملکرد پایدار داشته باشد، اما تغییر بیش از حد ممکن است تصویر غیرطبیعی شود.
فیلترها و هستهها (Kernel Filters)
- Blur: کاهش نویز و شبیهسازی تصاویر کمکیفیت.
- Sharpen: برجستهسازی لبهها و جزئیات.
نکته: مناسب برای دادههای واقعی با نویز یا تاری، اما باید در حد متعادل استفاده شود تا تصویر اصلی حفظ شود.
حذف تصادفی (Random Erasing / Cutout)
- حذف تصادفی بخشی از تصویر برای افزایش مقاومت مدل در مواجهه با بخشهای گمشده یا مخدوش.
نکته: باعث تعمیم بهتر مدل میشود اما حذف بیش از حد ممکن است اطلاعات مهم تصویر را از بین ببرد.
ترکیب تصاویر (Mixing / Blending / MixUp / CutMix)
ترکیب دو یا چند تصویر برای تولید نمونههای جدید.
- MixUp: ترکیب خطی تصاویر و برچسبها.
- CutMix: برش و جایگذاری بخشهایی از یک تصویر در تصویر دیگر.
نکته: باعث افزایش چشمگیر تنوع داده و جلوگیری از overfitting میشود اما پیچیدگی مدل و آموزش را کمی افزایش میدهد.
روشهای پیشرفتهتر
- GAN برای تولید تصاویر جدید: استفاده از شبکههای مولد برای خلق نمونههای واقعی اما جدید.
- انتقال سبک عصبی (Neural Style Transfer): اعمال سبک بصری خاص روی تصاویر برای تنوع بصری بیشتر.
نکته: این روشها قدرت بالایی در تولید داده دارند اما نیازمند منابع محاسباتی بیشتر و تنظیم دقیق هستند.
کاربردهای افزایش داده در صنایع مختلف چیست؟
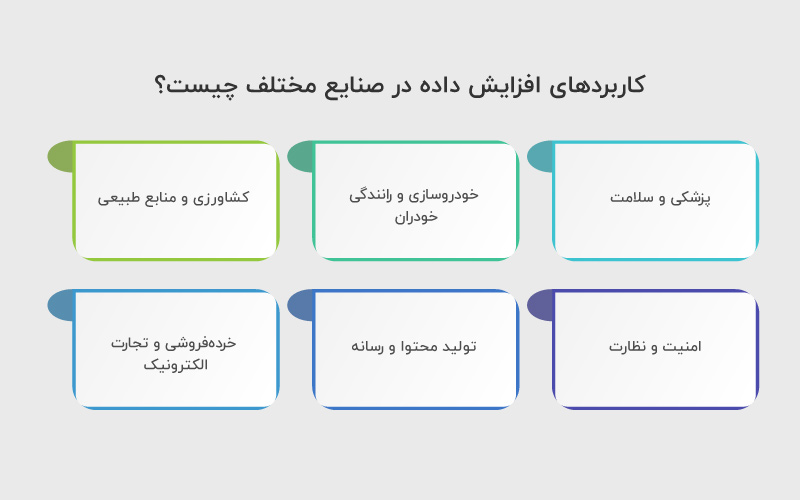
افزایش داده تصویری به مدلهای بینایی ماشین کمک میکند تا با تغییرات دنیای واقعی و محدودیت دادهها بهتر کنار بیایند. این روش کاربردهای عملی گستردهای در صنایع مختلف دارد که در جدول زیر با مثالهای مشخص آورده شده است:
| صنعت | کاربرد عملی |
| پزشکی و سلامت | تشخیص بیماریها و ناهنجاریها از تصاویر پزشکی (MRI، CT، X-ray) و شناسایی سرطان پوست و ریه |
| خودروسازی و رانندگی خودران | تشخیص علائم، خطوط جاده، عابران و خودروها و شبیهسازی شرایط نوری و جوی مختلف |
| کشاورزی و منابع طبیعی | تشخیص آفات و بیماری گیاهان، شناسایی محصولات و بهینهسازی برداشت خودکار با تصاویر هوایی یا زمینی |
| امنیت و نظارت | تشخیص چهره و افراد و نظارت تصویری در شرایط نوری و زاویههای متفاوت |
| تولید محتوا و رسانه | واقعیت افزوده و مجازی، بازیها و شناسایی اشیا در تصاویر و ویدیو |
| خردهفروشی و تجارت الکترونیک | جستجوی تصویرمحور، مدیریت کاتالوگ محصولات و شناسایی محصولات در شرایط مختلف |
پیادهسازی عملی با استفاده از فریمورکها و کتابخانهها
در این بخش، نحوه پیادهسازی تکنیکهای افزایش داده تصویری با استفاده از فریمورکهای محبوب مانند Keras/TensorFlow و کتابخانههای تخصصی مانند Albumentations را بررسی خواهیم کرد. هدف این است که شما بتوانید بهراحتی این تکنیکها را در پروژههای خود به کار بگیرید.
استفاده از Keras/TensorFlow برای افزایش داده
Keras و TensorFlow ابزارهای قدرتمندی برای اعمال تکنیکهای افزایش داده بهصورت زنده در طول آموزش مدل فراهم میکنند. در اینجا یک نمونه کد برای اعمال تغییرات هندسی مانند چرخش، وارونسازی و تغییر مقیاس آورده شده است:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from tensorflow.keras.preprocessing.image import ImageDataGenerator datagen = ImageDataGenerator( rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode=‘nearest’ ) # فرض کنید X_train دادههای آموزشی شما هستند # datagen.fit(X_train) |
در این کد، ImageDataGenerator با تنظیمات مختلفی مانند چرخش، تغییر مقیاس و وارونسازی پیکسلها، دادههای آموزشی را برای آموزش مدل آماده میکند.
استفاده از Albumentations برای افزایش داده
کتابخانه Albumentations یکی از ابزارهای محبوب و سریع برای اعمال تکنیکهای افزایش داده است. در اینجا یک نمونه کد برای اعمال تغییرات هندسی مانند چرخش، تغییر مقیاس و برش آورده شده است:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import albumentations as A from albumentations.pytorch import ToTensorV2 transform = A.Compose([ A.RandomRotate90(), A.HorizontalFlip(), A.VerticalFlip(), A.RandomBrightnessContrast(), A.Normalize(), ToTensorV2() ]) # فرض کنید image داده تصویری شما باشد # augmented = transform(image=image) # image = augmented[‘image’] |
در این کد، A.Compose ترکیبی از چندین تکنیک افزایش داده را تعریف میکند که بهصورت تصادفی روی تصویر اعمال میشوند.
استفاده از OpenCV برای افزایش داده
کتابخانه OpenCV ابزارهای قدرتمندی برای پردازش تصویر فراهم میکند که میتوان از آنها برای اعمال تکنیکهای افزایش داده استفاده کرد. در اینجا یک نمونه کد برای اعمال تغییرات هندسی مانند چرخش و تغییر مقیاس آورده شده است:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import cv2 import numpy as np image = cv2.imread(‘image.jpg’) # چرخش تصویر rows, cols, _ = image.shape M = cv2.getRotationMatrix2D((cols / 2, rows / 2), 45, 1) rotated = cv2.warpAffine(image, M, (cols, rows)) # تغییر مقیاس تصویر scaled = cv2.resize(image, None, fx=1.2, fy=1.2) # نمایش تصاویر cv2.imshow(‘Rotated Image’, rotated) cv2.imshow(‘Scaled Image’, scaled) cv2.waitKey(0) cv2.destroyAllWindows() |
در این کد، ابتدا تصویر خوانده میشود و سپس با استفاده از توابع OpenCV تغییرات مورد نظر اعمال میشود.
نکات مهم در اعمال تکنیکهای افزایش داده
- انتخاب تکنیک مناسب: انتخاب تکنیکهای مناسب بستگی به نوع داده و مدل مورد استفاده دارد. برای مثال، در تشخیص ارقام دستنویس، اعمال وارونسازی عمودی ممکن است باعث اشتباه در شناسایی شود.
- اعتبارسنجی دادههای افزوده: دادههای افزوده باید به دقت اعتبارسنجی شوند تا از ایجاد دادههای غیرواقعی یا مغرضانه جلوگیری شود.
- تنظیم پارامترها: پارامترهای هر تکنیک باید به دقت تنظیم شوند تا تعادل بین تنوع داده و واقعگرایی حفظ شود.
افزایش داده تصویری با Keras و TensorFlow
در این آموزش، یاد میگیریم چگونه با استفاده از Keras و TensorFlow دادههای تصویری را افزایش دهیم. همچنین خواهید دید چگونه میتوان از دادههای افزایشیافته برای آموزش یک مدل ساده دستهبندی دودویی استفاده کرد. کدهای ارائهشده نسخهای تغییریافته از مثال رسمی TensorFlow هستند.
توصیه میشود همراه با این آموزش، خودتان هم کدنویسی و تمرین انجام دهید.
مرحله اول: شروع کار
برای افزایش دادهها از TensorFlow و Keras و برای نمایش تصاویر از matplotlib استفاده میکنیم:
|
1 2 3 4 5 |
import matplotlib.pyplot as plt import numpy as np import tensorflow as tf from tensorflow.keras import layers from tensorflow.keras.models import Sequential |
مرحله دوم: بارگذاری دادهها
مجموعه دادههای TensorFlow شامل انواع متن، صوت، ویدیو، گراف، سریهای زمانی و تصاویر است. در این مثال از مجموعه داده «cats_vs_dogs» استفاده میکنیم که حجم آن ۷۸۶.۶۸ مگابایت است. این دادهها را برای افزایش دادههای تصویری و آموزش یک مدل دستهبندی دودویی استفاده خواهیم کرد.
۸۰٪ دادهها برای آموزش، ۱۰٪ برای اعتبارسنجی و ۱۰٪ برای تست استفاده میشوند:
|
1 2 3 4 5 6 7 8 |
import tensorflow_datasets as tfds (train_ds, val_ds, test_ds), metadata = tfds.load( ‘cats_vs_dogs’, split=[‘train[:80%]’, ‘train[80%:90%]’, ‘train[90%:]’], with_info=True, as_supervised=True, ) |
مرحله سوم: تحلیل دادهها
این مجموعه داده شامل دو کلاس است: «گربه» و «سگ»:
|
1 2 |
num_classes = metadata.features[‘label’].num_classes print(num_classes) # خروجی: 2 |
برای نمایش نمونه، چهار تصویر تصادفی همراه با برچسبهایشان از مجموعه آموزش انتخاب و نمایش داده میشوند:
|
1 2 3 4 5 6 7 8 9 |
get_label_name = metadata.features[‘label’].int2str train_iter = iter(train_ds) fig = plt.figure(figsize=(7, 8)) for x in range(4): image, label = next(train_iter) fig.add_subplot(1, 4, x + 1) plt.imshow(image) plt.axis(‘off’) plt.title(get_label_name(label)) |

مرحله چهارم: افزایش داده با Keras Sequential
میتوان از keras.Sequential() نهتنها برای ساخت مدل، بلکه برای افزودن لایههای افزایش داده استفاده کرد.
- تغییر اندازه و نرمالسازی
تصاویر ابتدا به ابعاد ۱۸۰×۱۸۰ تغییر اندازه داده شده و سپس مقیاسبندی میشوند:
|
1 2 3 4 5 6 7 8 9 10 |
IMG_SIZE = 180 resize_and_rescale = tf.keras.Sequential([ layers.Resizing(IMG_SIZE, IMG_SIZE), layers.Rescaling(1./255) ]) result = resize_and_rescale(image) plt.axis(‘off’) plt.imshow(result) |
- چرخش و وارونسازی تصادفی
|
1 2 3 4 5 6 7 8 9 10 11 |
data_augmentation = tf.keras.Sequential([ layers.RandomFlip(“horizontal_and_vertical”), layers.RandomRotation(0.4), ]) plt.figure(figsize=(8, 7)) for i in range(6): augmented_image = data_augmentation(image) ax = plt.subplot(2, 3, i + 1) plt.imshow(augmented_image.numpy()/255) plt.axis(“off”) |
نکته: اگر با هشدار مربوط به نمایش تصویر مواجه شدید، تصویر را به numpy تبدیل و بر ۲۵۵ تقسیم کنید تا خروجی واضح باشد.

مرحله پنجم: افزودن مستقیم لایههای افزایش داده به مدل
|
1 2 3 4 5 6 7 8 9 10 |
model = tf.keras.Sequential([ resize_and_rescale, data_augmentation, layers.Conv2D(16, 3, padding=‘same’, activation=‘relu’), layers.MaxPooling2D(), layers.Flatten(), layers.Dense(128, activation=‘relu’), layers.Dense(64, activation=‘relu’), layers.Dense(1,activation=‘sigmoid’) ]) |
توجه: لایههای افزایش داده فقط هنگام آموزش فعال هستند و در مراحل ارزیابی یا پیشبینی غیرفعال میشوند.
مرحله ششم: اعمال افزایش داده با Dataset.map
میتوان تمام مجموعه آموزش را با استفاده از .map و تابع افزایش داده تغییر داد:
|
1 |
aug_ds = train_ds.map(lambda x, y: (data_augmentation(x, training=True), y)) |
مرحله هفتم: پیشپردازش دادهها
یک تابع پیشپردازش برای آموزش، اعتبارسنجی و تست ایجاد میکنیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
batch_size = 32 AUTOTUNE = tf.data.AUTOTUNE def prepare(ds, shuffle=False, augment=False): ds = ds.map(lambda x, y: (resize_and_rescale(x), y), num_parallel_calls=AUTOTUNE) if shuffle: ds = ds.shuffle(1000) ds = ds.batch(batch_size) if augment: ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y), num_parallel_calls=AUTOTUNE) return ds.prefetch(buffer_size=AUTOTUNE) train_ds = prepare(train_ds, shuffle=True, augment=True) val_ds = prepare(val_ds) test_ds = prepare(test_ds) |
مرحله هشتم: ساخت مدل و آموزش
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
model = tf.keras.Sequential([ layers.Conv2D(32, (3, 3), input_shape=(180,180,3), padding=‘same’, activation=‘relu’), layers.MaxPooling2D(pool_size=(2, 2)), layers.Flatten(), layers.Dense(32, activation=‘relu’), layers.Dense(1,activation=‘softmax’) ]) model.compile(optimizer=‘adam’, loss=‘binary_crossentropy’, metrics=[‘accuracy’]) history = model.fit(train_ds, validation_data=val_ds, epochs=1) loss, acc = model.evaluate(test_ds) |
در یک اجرای نمونه، دقت اعتبارسنجی حدود ۵۱٪ است. با آموزش چند اپوک و تنظیم هایپرپارامترها، میتوان نتایج بهتری گرفت.
مرحله نهم: افزایش داده با tf.image
TensorFlow توابع پیشرفتهای برای کنترل دقیق افزایش داده ارائه میدهد:
- چرخش ۹۰ درجه:
|
1 |
tf.image.rot90(image) |

- وارونسازی افقی:
|
1 |
tf.image.flip_left_right(image) |

- تبدیل به خاکستری:
|
1 |
tf.image.rgb_to_grayscale(image) |

- تنظیم روشنایی و اشباع:
|
1 |
tf.image.adjust_brightness, tf.image.adjust_saturation |

- برش مرکزی:
|
1 |
tf.image.central_crop(image, central_fraction=0.5) |
- افزایش روشنایی تصادفی:
|
1 |
tf.image.stateless_random_brightness(image, max_delta=0.95, seed=(i,0)) |

میتوان این توابع را با .map روی کل مجموعه آموزش اعمال کرد تا pipeline کاملا آماده آموزش باشد.
مرحله دهم: استفاده از ImageDataGenerator در Keras
برای دادههای محلی یا CSV، ImageDataGenerator سادهترین روش است:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from tensorflow.keras.preprocessing.image import ImageDataGenerator (x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data() datagen = ImageDataGenerator(rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, horizontal_flip=True, validation_split=0.2) datagen.fit(x_train) for X_batch, y_batch in datagen.flow(x_train,y_train, batch_size=6): for i in range(0, 6): plt.subplot(2,3,i+1) plt.imshow(X_batch[i]/255) plt.axis(‘off’) break |
ابزارها و کتابخانههای محبوب در افزایش داده
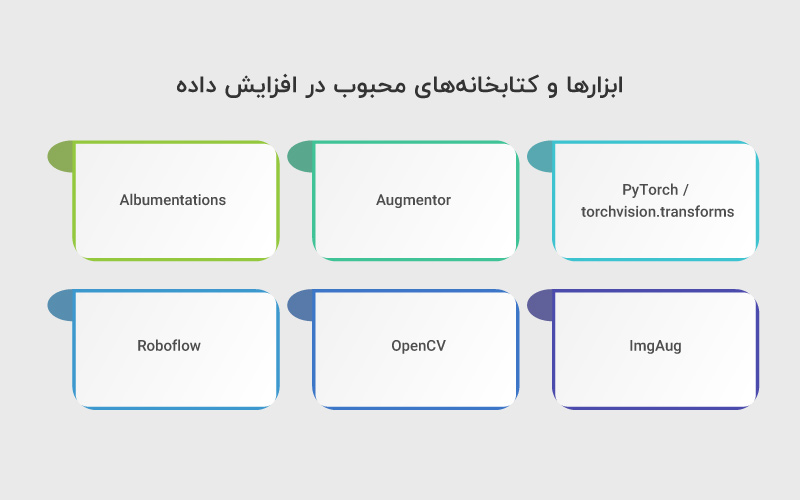
افزایش داده تصویری میتواند با ابزارها و کتابخانههای متنوعی انجام شود که هر کدام ویژگیها و مزایای خاص خود را دارند. آشنایی با این ابزارها به شما کمک میکند مناسبترین گزینه را برای پروژهتان انتخاب کنید.
- PyTorch / torchvision.transforms: یک کتابخانه قدرتمند برای اعمال تغییرات هندسی، رنگی و نویز به تصاویر در حین آموزش مدلها. این ابزار برای توسعه مدلهای سفارشی بسیار انعطافپذیر است.
- Augmentor: یک کتابخانه ساده پایتون برای افزایش داده تصاویر با رابطی کاربرپسند. قابلیت تعریف pipeline از تکنیکهای مختلف را دارد و برای پروژههای کوچک و متوسط مناسب است.
- Albumentations: یکی از سریعترین و کاملترین کتابخانهها برای augment تصاویر، با پشتیبانی از تبدیلهای هندسی، رنگی و نویزی و همچنین سازگار با PyTorch و TensorFlow.
- ImgAug: کتابخانهای پیشرفته که امکان ترکیب تعداد زیادی تبدیل را فراهم میکند. مناسب پروژههایی است که به augment پیچیده و تصادفی نیاز دارند.
- OpenCV: ابزار پایه و عمومی برای پردازش تصویر که میتوان با آن تغییرات هندسی، برش، چرخش و تنظیم رنگ را اعمال کرد. مناسب برای augment ساده یا قبل از feed کردن داده به مدل.
- Roboflow: یک پلتفرم تحت وب برای pipeline کامل دادههای تصویر و augment بدون نیاز به کدنویسی. مناسب تیمهایی که میخواهند سریع شروع کنند و دادههای آماده داشته باشند.
مقایسه این ابزارها در جدول زیر بهخوبی نشان میدهد که کدام یک برای شما کاربردیتر هستند:
| ابزار / کتابخانه | مزایا | معایب |
| PyTorch / Albumentations | سریع، انعطافپذیر، مناسب مدلهای سفارشی | نیازمند کدنویسی |
| Augmentor / ImgAug | آسان برای پیادهسازی، قابلیت ایجاد pipeline ساده | سرعت متوسط، محدودیت در پروژههای بزرگ |
| OpenCV | کنترل کامل روی تصاویر، انعطافپذیر | نیازمند برنامهنویسی دستی، پیچیدگی بیشتر |
| Roboflow | راهاندازی سریع، بدون نیاز به کدنویسی، مناسب تیمها | محدودیتهای نسخه رایگان، وابسته به پلتفرم آنلاین |
اعمال افزایش داده تصویری ممکن است در نگاه اول ساده به نظر برسد، اما برای استفاده موثر نیازمند رعایت چند نکته کلیدی است. اول از همه، انتخاب ترکیب مناسب از تکنیکها اهمیت زیادی دارد، زیرا هر تبدیل برای هر پروژه مناسب نیست. برای مثال، وارونسازی عمودی برای ارقام دستنویس مناسب نیست، اما برای تصاویر حیواناتی مانند سگ و گربه کاملا قابل قبول است.
همچنین باید مراقب over-augmentation بود؛ تولید دادههای زیاد و غیرواقعی میتواند مدل را گیج کند و کیفیت آن را کاهش دهد، بنابراین حفظ تعادل بین تنوع و واقعگرایی ضروری است. تاثیر افزایش داده روی توزیع اصلی دادهها نیز نباید نادیده گرفته شود؛ زیرا تغییرات غیرواقعی ممکن است باعث شود مدل در دادههای واقعی عملکرد ضعیفی داشته باشد.
علاوهبر این، هنگام اعمال augment روی دادههای انسانی باید به مسائل اخلاقی و بایاس توجه شود تا تغییرات مصنوعی باعث برداشت نادرست از گروههای مختلف نشود. مستندسازی تمام تبدیلهای اعمال شده نیز اهمیت دارد تا فرایند قابل بازتولید باشد و در صورت نیاز بتوان نتایج را بررسی کرد. در نهایت، اجرای بهینه تکنیکهای افزایش داده اهمیت دارد تا مصرف حافظه و زمان آموزش کاهش یابد؛ استفاده از روشهایی مانند batching و پیشخوانی (prefetching) میتواند این بهینهسازی را ممکن سازد.
جمعبندی
افزایش داده تصویری ابزار کلیدی برای تقویت مدلهای بینایی ماشین است و باعث میشود آنها بتوانند با تنوع دادههای واقعی و شرایط محیطی مختلف بهتر سازگار شوند. با استفاده از تکنیکهایی مانند چرخش، وارونسازی، تغییر روشنایی و برش، مدلها دقت بالاتر و تعمیمپذیری بهتری پیدا میکنند و حتی با مجموعه دادههای محدود عملکرد قابل اعتماد ارائه میدهند. کاربردهای این روش در صنایع مختلف از پزشکی و خودروسازی گرفته تا کشاورزی و تجارت الکترونیک، نشاندهنده اهمیت آن در پروژههای واقعی و عملی است.
منابع
سوالات متداول
افزایش داده بهویژه زمانی مفید است که مجموعه داده محدود باشد یا مدل در معرض شرایط محیطی و تنوع واقعی تصاویر قرار گیرد. استفاده از آن میتواند دقت و تعمیمپذیری مدل را بهبود دهد.
اگرچه رایجترین کاربرد آن در تصاویر است، تکنیکهای مشابه برای دادههای ویدئویی و چند مدالیته نیز قابل استفاده هستند، اما پیادهسازی آن پیچیدهتر است.
نه، اعمال بیش از حد یا غیرواقعی افزایش داده میتواند مدل را گیج کند و باعث کاهش دقت شود. انتخاب ترکیب مناسب و مستندسازی تغییرات اهمیت دارد.

دیدگاهتان را بنویسید