
رشد سریع مدلهای هوش مصنوعی و یادگیری ماشین نیاز به یک فضای مشترک برای انتشار، ارزیابی و همکاری را بیش از هر زمان دیگری آشکار کرده است. جایی که توسعهدهندگان، پژوهشگران و شرکتها بتوانند مدلها و دیتاستهای خود را در محیطی استاندارد و شفاف با یکدیگر به اشتراک بگذارند. Hugging Face Hub دقیقا برای پاسخ به همین نیاز طراحی شده؛ پلتفرمی که امروز به یکی از ستونهای اصلی اکوسیستم متنباز هوش مصنوعی تبدیل شده و نقش مهمی در دسترسپذیر کردن مدلها و افزایش سرعت نوآوری ایفا میکند.
در این مقاله از بلاگ آسا قدمبهقدم بررسی میکنیم که Hugging Face Hub چیست، چگونه کار میکند و چه قابلیتهایی برای توسعهدهندگان فراهم میکند. از مدلها و دیتاستها گرفته تا Spaces، نسخهبندی، همکاری جامعه، امکانات فنی و حتی چالشها و آینده این پلتفرم.
Hugging Face Hub چیست؟
Hugging Face Hub یک پلتفرم متنباز برای میزبانی، اشتراکگذاری و همکاری روی مدلهای هوش مصنوعی، دیتاستها و اپلیکیشنهای تعاملی است. این پلتفرم در واقع یک مرکز یکپارچه برای تمام اجزایی است که توسعهدهندگان و پژوهشگران برای ساخت، آموزش، تست و انتشار مدلهای AI نیاز دارند. همانطور که گیتهاب توانست فرایند توسعه نرمافزار را متحول کند، Hugging Face Hub نیز همین نقش را در دنیای مدلهای یادگیری ماشین ایفا میکند.
در این پلتفرم هزاران مدل از حوزههای مختلف—از پردازش زبان طبیعی و بینایی ماشین تا مدلهای چندوجهی و تولیدکننده—بهصورت رایگان قابلدسترسی هستند. کاربران میتوانند از مدلهای آماده استفاده کنند، نسخههای سفارشی منتشر کنند یا حتی مدلهای خود را برای استفاده جهانی در Hub آپلود کنند. وجود ابزارهایی مثل Cardهای مستندات مدل (Model Cards)، سیستم نسخهبندی، فضاهای قابلاجرا (Spaces) و ارزیابیهای خودکار باعث میشود Hub نهتنها یک مخزن، بلکه یک اکوسیستم کامل برای توسعه و بهاشتراکگذاری مدل باشد.
حضور فعال جامعه متخصصان، حجم زیاد محتواهای متنباز و همکاری شرکتهای بزرگ باعث شده Hugging Face Hub به استانداردی غیررسمی برای تبادل مدلهای یادگیری ماشین تبدیل شود و بسیاری از پروژهها—even در مقیاس سازمانی—به آن اتکا کنند.
Model Hub در Hugging Face چیست و چگونه کار میکند؟
Model Hub قلب تپندهی اکوسیستم Hugging Face است؛ جایی که هزاران مدل متنباز ذخیره، نسخهبندی، مستندسازی و برای استفاده عموم منتشر میشوند. این بخش در واقع همان نقشی را ایفا میکند که گیتهاب برای کد ایفا میکند—اما اینبار برای مدلهای یادگیری ماشین.
۱. مخازن مدل (Model Repositories)
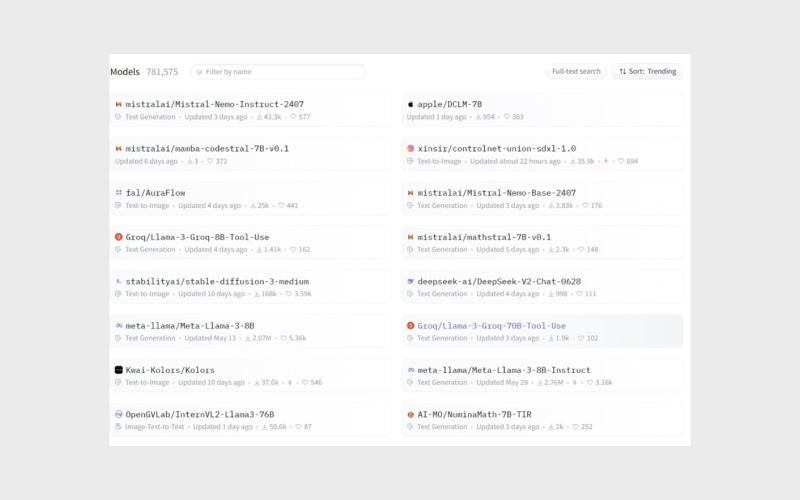
هر مدل در Hugging Face یک مخزن اختصاصی دارد؛ درست مثل یک ریپازیتوری Git. این مخزن شامل همه فایلهای لازم برای اجرای مدل است:
- وزنها و فایلهای چکپوینت
- کانفیگ مدل
- توکنایزر
- اسکریپتهای کمکی
- فایل README و Model Card
Model Card چیست؟
Model Card یک صفحه مستندات استاندارد است که اطلاعات کلیدی یک مدل را بهصورت شفاف ارائه میدهد، از جمله:
- توضیح کلی مدل و معماری آن
- دادههای آموزش و محدودیتها
- معیارهای ارزیابی و نتایج بنچمارک
- موارد استفاده پیشنهادی و هشدارهای اخلاقی
- مجوز (License) و نحوه استناد
وجود این کارتها کمک میکند کاربران بدون نیاز به تستهای طولانی بفهمند آیا مدل مناسب پروژهشان هست یا نه.
نسخهبندی (Versioning)
همانند Git، هر تغییر در مخزن مدل نسخهگذاری میشود.
مزیت اصلی:
میتوانید هر نسخه از مدل را بازیابی کنید و مدل خود را با خیال راحت آپدیت کنید، بدون اینکه نسخههای قدیمی از بین بروند.
۲. جستجو و کاوش مدلها در Hub
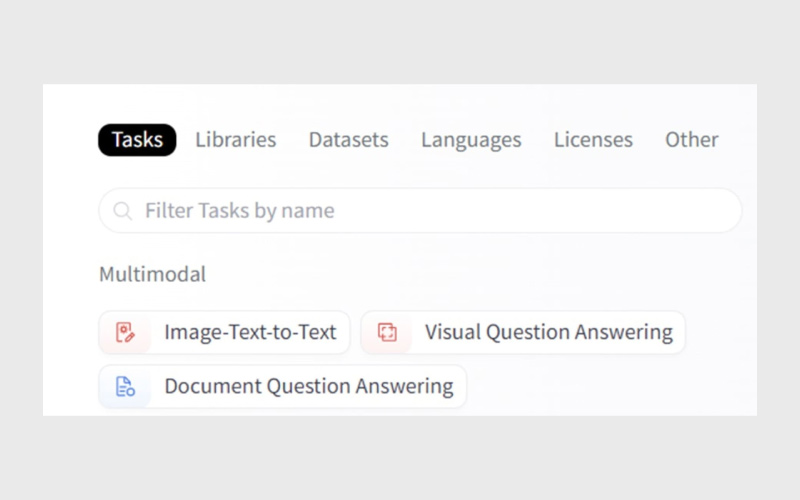
Hugging Face یک جستجوی قدرتمند و فیلترهای دقیق ارائه میدهد تا بین هزاران مدل، بهترین گزینه را پیدا کنید. برخی از فیلترهای کلیدی عبارتاند از:
- Task / کاربرد: Translation، Text Classification، Image Segmentation
- Framework: PyTorch، TensorFlow، JAX، ONNX)
- Language (انگلیسی، فارسی، چندزبانه و …)
- License (MIT، Apache 2.0، CC، تجاری یا متنباز)
- Model Size (مثلا کمتر از ۱GB)
- Training Data (برای مدلهایی که کارت مستندات کامل دارند)
جستجوی پیشرفته
علاوه بر فیلترها، قابلیتهای زیر هم وجود دارد:
- مرتبسازی براساس محبوبیت، تاریخ انتشار، میزان استفاده و تعداد لایک
- مشاهده نتایج بنچمارک هر مدل
- بررسی نمونه ورودی/خروجی (Inference Widget) بدون نیاز به نصب
این ابزارها باعث میشود Hub بهترین نقطه شروع برای انتخاب مدل مناسب پروژه باشد.
۳. استفاده و ادغام مدلها با huggingface_hub
برای کار با مدلها، فقط نگاه کردن کافی نیست—باید بتوانید آنها را دانلود، مدیریت و حتی منتشر کنید.
کتابخانهی رسمی huggingface_hub دقیقا برای همین ساخته شده است.
امکانات کلیدی این کتابخانه:
دانلود مدلها، دیتاستها و فایلها
|
1 2 3 |
from huggingface_hub import hf_hub_download hf_hub_download(repo_id=“bert-base-uncased”, filename=“config.json”) |
- آپلود مدل و انتشار نسخه جدید: (برای ساخت ریپازیتوری مدل از طریق API یا CLI)
- مدیریت نسخهها (Commits و Tags): مشابه Git، اما با امکانات تخصصیتر برای مدلهای ML.
- احراز هویت ساده (Token Login) برای دسترسی به مدلهای خصوصی
چرا مهم است؟
چون با این کتابخانه میتوان:
- مدل را بدون کلون کردن کل مخزن دانلود کرد
- از نسخهبندی دقیق استفاده کرد
- مدلها را بهراحتی در CI/CD یا محیطهای ابری ادغام کرد
- مدلهای سفارشی را منتشر و به جامعه ارائه کرد
قابلیتها و اجزای کلیدی Hugging Face Hub

Hugging Face Hub فقط یک مخزن مدل نیست؛ بلکه یک اکوسیستم کامل است که ابزارها، زیرساختها و قابلیتهایی را فراهم میکند تا توسعهدهندگان در تمام مراحل—از ایده تا انتشار—بتوانند کار خود را مدیریت کنند. در این بخش، مهمترین اجزا و امکانات Hub را بررسی میکنیم.
۱. دیتاستها (Datasets)
Hub میزبان هزاران دیتاست متنباز در حوزههای مختلف است؛ از NLP و بینایی ماشین گرفته تا گفتار، مولتیمودال و دادههای تخصصی دامنهای. هر دیتاست یک مخزن اختصاصی دارد و همراه با مستندات کامل منتشر میشود.
ویژگیهای کلیدی دیتاستها:
بارگذاری سریع و استاندارد با کتابخانهی datasets
بدون نیاز به دانلود دستی:
|
1 2 |
from datasets import load_dataset dataset = load_dataset(“imdb”) |
- نسخهبندی و مستندسازی کامل: شامل توضیحات، منبع داده، لایسنس، ساختار نمونهها و محدودیتها.
- پشتیبانی از انواع فرمتها: CSV، JSON، تصاویر، صوت، Parquet و …
- قابلیت Stream کردن: برای کار با دیتاستهای بسیار بزرگ بدون دانلود کامل.
دیتاستها Hub را به یک منبع قابلاعتماد برای پژوهشگران و شرکتها تبدیل کردهاند.
۲. Spaces
Spaces یکی از جذابترین امکانات Hugging Face Hub است؛ جایی که میتوانید اپلیکیشنهای تعاملی هوش مصنوعی بسازید و منتشر کنید.
Spaces از چند فریمورک پشتیبانی میکند:
- Gradio
- Streamlit
- Docker (برای پروژههای پیشرفتهتر)
قابلیتهای کلیدی Spaces:
- اجرای خودکار اپلیکیشن با تغییرات جدید
- میزبانی رایگان برای پروژههای متنباز
- یکپارچگی با مدلها و دیتاستهای Hub
- لود سریع، UI استاندارد و پشتیبانی از GPU در پلنهای اشتراکی
Spaces عملا باعث شده هر توسعهدهندهای بتواند نسخه Deploy شدهی مدلش را بدون زیرساخت پیچیده ارائه دهد.
۳. Evaluations
بخش Evaluations در Hub یک سیستم استاندارد برای ارزیابی مدلهاست.
چرا مهم است؟
زیرا به کاربران کمک میکند:
- مدلها را براساس بنچمارکهای رسمی مقایسه کنند
- عملکرد مدلها را روی وظایف مختلف ببینند
- نتایج معتبر و قابلاستناد به دست بیاورند
این سیستم بهطور مداوم در حال توسعه است و نقش مهمی در شفافیت مدلها ایفا میکند.
۴. ابزارهای جامعه (Community Tools)
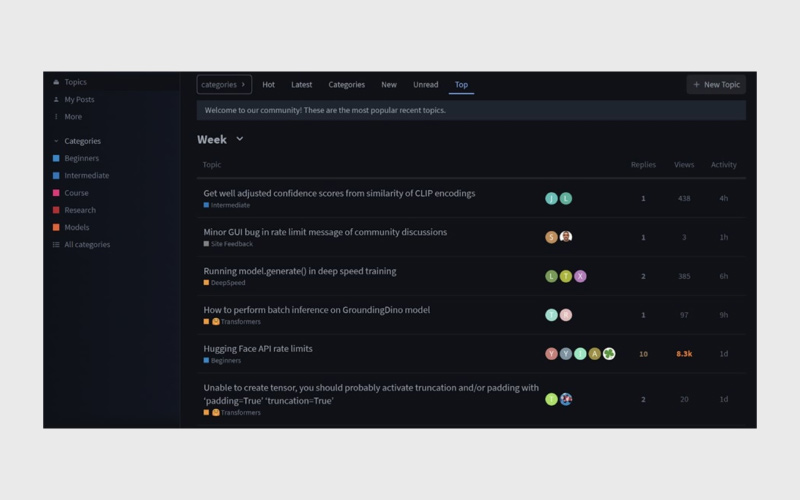
Hugging Face یک جامعه بسیار فعال دارد و ابزارهای کاملی برای همکاری ارائه میدهد:
- Discussions برای گفتوگو درباره هر مدل یا دیتاست
- Pull Requests برای بهبود مستندات یا فایلهای مدل
- Collections برای دستهبندی مدلها توسط کاربران
- Spaces Community برای تست، مشاهده و تعامل با پروژههای دیگران
این ویژگیها باعث شده Hub فقط یک پلتفرم میزبانی نباشد، بلکه یک جامعه باز و پویا باشد که از طریق همکاری جمعی رشد میکند.
چه نوع مدلهایی در Hugging Face Hub منتشر میشوند؟

Hugging Face Hub مجموعهای عظیم و متنوع از مدلهای هوش مصنوعی را در خود جای داده است؛ مدلهایی که از سادهترین معماریها تا پیچیدهترین LLMها را شامل میشوند. تنوع این مدلها باعث شده Hub به یک «کتابخانه کامل AI» تبدیل شود و کاربران بتوانند بدون نیاز به آموزش از صفر، مستقیما از مدلهای آماده استفاده کنند یا آنها را مطابق نیازشان فاینتیون کنند.
در ادامه مهمترین دستهبندیهای مدلها را معرفی میکنیم:
۱. مدلهای پردازش زبان طبیعی (NLP Models)
این دسته محبوبترین بخش Hub است و شامل مدلهایی برای وظایف مختلف زبان طبیعی میشود:
- Text Classification (تحلیل احساسات، دستهبندی موضوعی، تشخیص اسپم و …)
- Named Entity Recognition (NER)
- Machine Translation (ترجمه ماشینی چندزبانه)
- Summarization
- Question Answering
- Language Modeling (مدلهای پیشبینی کلمه و ادامه متن)
- Text Generation
- Conversational AI و Chatbots
مدلهایی مثل BERT، GPT-2، T5، RoBERTa، DistilBERT، LLaMA، Mistral و مدلهای فارسی مثل ParsBERT همگی در این دسته قرار میگیرند.
۲. مدلهای بینایی کامپیوتری (Computer Vision Models)
Hub میزبان مدلهای تخصصی بینایی برای انواع وظایف تصویری است:
- Image Classification
- Object Detection
- Image Segmentation
- Image Generation / Diffusion Models (مثل Stable Diffusion)
- Super Resolution
- Face Recognition
- Image Captioning
بسیاری از مدلها با PyTorch، TensorFlow یا JAX قابل اجرا هستند و برخی از آنها رابط Gradio برای تست سریع دارند.

۳. مدلهای گفتار و صوت (Audio & Speech Models)
برنامهنویسان و پژوهشگران میتوانند مدلهای صوتی زیادی را در Hub پیدا کنند:
- Automatic Speech Recognition (ASR) مثل Whisper
- Text-to-Speech (TTS)
- Speaker Identification
- Audio Classification
- Music Generation
Presence مدلهای Whisper در نسخههای مختلف یکی از کاربردیترین بخشهای Hub برای پردازش صوت است.
۴. مدلهای چندوجهی (Multimodal Models)
یکی از جذابترین بخشهای جدید Hub مدلهایی هستند که ورودیها و خروجیهای ترکیبی دارند:
- متن + تصویر
- صوت + متن
- ویدئو + متن
- متن + تصویر + صوت (کاملا چندوجهی)
مدلهایی مثل CLIP، Florence، BLIP، Flamingo، LLaVA نمونههای رایج این دسته هستند.

۵. مدلهای تولیدی (Generative Models)
برای تولید محتوا در حوزههای مختلف:
- متنمولد (LLMها)
- مدلهای تصویر مولد (Diffusion)
- Audio Generation
- Code Generation
Hub یکی از اصلیترین منابع مدلهای تولیدی در جهان است.
۶. مدلهای علمی و دامنهمحور
این مدلها برای صنایع خاص توسعه یافتهاند:
- پزشکی و سلامت (Medical NLP)
- قوانین و حقوق
- خدمات مالی
- علوم پایه
- مدلهای پژوهشی تخصصی
چطور میتوان از مدلهای Hugging Face Hub استفاده کرد؟
یکی از مهمترین دلایلی که Hugging Face Hub را به استاندارد اصلی دنیای هوش مصنوعی تبدیل کرده، سهولت استفاده از مدلهاست. حتی اگر تجربهی کمی در یادگیری ماشین داشته باشید، میتوانید مدلهای آماده را فقط با چند خط کد اجرا کنید. در این بخش، روشهای اصلی استفاده از مدلها را مرور میکنیم.
۱. اجرای مدلها در محیط آنلاین (Inference Widget)
تقریبا تمام مدلهای Hub یک ابزار تست آنلاین دارند که اجازه میدهد بدون نصب هیچ کتابخانهای، مدل را امتحان کنید.
چه کارهایی میتوان با آن انجام داد؟
- وارد کردن یک متن، تصویر یا فایل صوتی
- دریافت خروجی مدل از همان صفحه
- بررسی سریع عملکرد مدل قبل از دانلود یا فاینتیون
- این کار برای ارزیابی اولیه مدلها بسیار کاربردی است.
۲. استفاده از مدلها با کتابخانه Transformers
پرکاربردترین روش برای اجرای مدلهای NLP و Multimodal در پروژههای واقعی است.
نمونه استفاده:
|
1 2 3 |
from transformers import pipeline classifier = pipeline(“sentiment-analysis”, model=“distilbert-base-uncased-finetuned-sst-2-english”) classifier(“I love Hugging Face Hub!”) |
مزایا:
- استفاده بسیار ساده
- پشتیبانی از صدها معماری مدرن
- یکپارچگی کامل با مخازن مدلها
- مناسب برای پروتوتایپسازی تا استقرار (deployment)
۳. دانلود مدلها با huggingface_hub
این کتابخانه رسمی برای کار با فایلها، نسخهها و ریپازیتوریهاست.
مثال ساده:
|
1 2 3 4 5 6 |
from huggingface_hub import hf_hub_download hf_hub_download( repo_id=“bert-base-uncased”, filename=“pytorch_model.bin” ) |
قابلیتها:
- دانلود فایلهای خاص (بدون کلون کامل)
- مدیریت نسخهها
- احراز هویت برای مدلهای خصوصی
- انتشار مدلهای جدید و بهروزرسانی آنها
۴. استفاده از API برای استقرار سریع مدلها
اگر برنامهنویس بکاند، فرانتاند، یا مهندس ML هستید و میخواهید مدل را بدون زیرساخت پیچیده در اپلیکیشن خود قرار دهید، API بهترین روش است.
مثال فراخوانی API:
|
1 2 3 4 5 6 7 |
import requests API_URL = “https://api-inference.huggingface.co/models/google/flan-t5-base” headers = {“Authorization”: “Bearer YOUR_TOKEN”} response = requests.post(API_URL, headers=headers, json={“inputs”: “Translate to French: machine learning”}) print(response.json()) |
مزایا:
- مدیریت خودکار inference توسط Hugging Face
- نیاز نداشتن به GPU یا سرور
- مناسب برای MVP و پروژههای سبک و متوسط
۵. استفاده از Spaces برای ساخت اپلیکیشنهای تعاملی
اگر میخواهید:
- یک Chatbot بسازید
- یک ابزار تحلیل متن ارائه دهید
- یک نمایشگر تصویر یا مدل صوتی منتشر کنید
Spaces بهترین گزینه است.
ویژگیها:
- میزبانی رایگان برای پروژههای متنباز
- پشتیبانی از Gradio و Streamlit
- یکپارچگی آسان با مدلها و دیتاستها
- مناسب دمو، PoC یا انتشار پروژه برای جامعه
مزایا و محدودیتهای Hugging Face Hub
Hugging Face Hub با ارائه یک اکوسیستم کامل برای توسعه، به اشتراکگذاری و ارزیابی مدلها، فرصتهای زیادی برای توسعهدهندگان، پژوهشگران و شرکتها فراهم کرده است. در عین حال، محدودیتهایی هم وجود دارد که کاربران باید از آنها آگاه باشند. در این بخش، مزایا و محدودیتها را بررسی میکنیم.
مزایای Hugging Face Hub
- دسترسی آسان به هزاران مدل و دیتاست: بدون نیاز به آموزش از صفر میتوانید مدلهای آماده را دانلود و استفاده کنید.
- نسخهبندی و مستندسازی استاندارد: Model Card و سیستم commit دقیق، شفافیت و قابلیت بازگشت به نسخههای قبلی را فراهم میکنند.
- فضای همکاری فعال: جامعه کاربران و ابزارهای بحث، Pull Request و Collections باعث شده کاربران بتوانند با هم همکاری کنند و پروژهها را بهبود دهند.
- ابزارهای سریع برای تست و انتشار مدل: Inference Widget، API و Spaces فرایند پروتوتایپسازی و انتشار را بسیار ساده میکنند.
- یادگیری و اشتراکگذاری آسان: منابع آموزشی، مستندات کامل و اپلیکیشنهای آماده برای جامعه کاربری، آموزش و تحقیق را تسهیل میکنند.
محدودیتهای Hugging Face Hub
- تنوع کیفیت مدلها: از آنجایی که هر کسی میتواند مدل آپلود کند، کیفیت مدلها ممکن است متفاوت باشد.
- نگهداری و بهروزرسانی مدلها: برخی مدلها ممکن است آپدیت نشوند یا مستنداتشان ناقص باشد.
- سوگیری و مسائل اخلاقی: مدلهای پیشآموزش ممکن است شامل bias یا نتایج غیرقابل اعتماد باشند.
- پیچیدگی برای تازهکاران: نسخهبندی، APIها و ابزارهای پیشرفته ممکن است برای کاربران تازهکار کمی دشوار باشد.
- محدودیت منابع برای Spaces رایگان: برای پروژههای سنگین و پردازش حجیم، نیاز به پلنهای اشتراکی یا منابع محاسباتی اضافی است.
نتیجهگیری
Hugging Face Hub بیش از یک مخزن مدل است؛ این پلتفرم یک اکوسیستم کامل برای توسعه، اشتراکگذاری و همکاری روی مدلهای هوش مصنوعی است. با دسترسی به هزاران مدل و دیتاست، ابزارهای تست و استقرار سریع، نسخهبندی دقیق و جامعه فعال، Hub راه را برای پژوهشگران، توسعهدهندگان و شرکتها هموار کرده است. هرچند محدودیتهایی مثل تنوع کیفیت مدلها و مسائل اخلاقی وجود دارد، اما این پلتفرم همچنان به یکی از ستونهای اصلی نوآوری و توسعه در حوزه هوش مصنوعی تبدیل شده است.
استفاده از Hugging Face Hub به شما امکان میدهد بهسرعت ایدهها را به مدل عملی تبدیل کنید، با جامعه تخصصی همکاری داشته باشید و پروژههای خود را با ابزارهای حرفهای منتشر کنید. این ویژگیها باعث شده Hub به «گیتهاب مدلهای AI» تبدیل شود و جایگاه ویژهای در اکوسیستم متنباز هوش مصنوعی داشته باشد.
منابع
huggingface.co | machinelearningmastery.com
سوالات متداول
بخش عمدهای از مدلها و دیتاستها رایگان است، اما برای استفاده از منابع محاسباتی پیشرفته، پلنهای اشتراکی ارائه شده است.
بله، با ثبت حساب کاربری و استفاده از ابزارهای huggingface_hub میتوانید مدل و دیتاست خود را بهصورت عمومی یا خصوصی منتشر کنید.
مدلها شامل NLP، بینایی کامپیوتری، صوت، مولتیمودال، تولید محتوا و مدلهای دامنهمحور تخصصی هستند.
مدلها و دیتاستهای خصوصی با توکن احراز هویت محافظت میشوند و دسترسی کنترلشده است. دادهها بدون اجازه شما برای آموزش مدلهای جدید استفاده نمیشوند.




دیدگاهتان را بنویسید