
مدلهای زبانی بزرگ (LLMها) بدون دسترسی به دادههای اختصاصی و بهروز، توانایی محدودی در پاسخگویی دقیق و متناسب با نیازهای واقعی دارند. در این میان، LlamaIndex بهعنوان یکی از ابزارهای کلیدی اکوسیستم هوش مصنوعی، نقش مهمی در آمادهسازی، سازماندهی و بازیابی دادهها برای استفاده در کنار LLMها ایفا میکند. این ابزار به توسعهدهندگان کمک میکند تا منابع داده مختلف را به شکلی ساختاریافته و قابل فهم برای مدلهای زبانی تبدیل کنند.
LlamaIndex تنها یک ابزار ایندکسسازی ساده نیست؛ بلکه چارچوبی است برای مدیریت جریان داده از منابع خام تا مرحله پاسخگویی هوشمند. در این مقاله بررسی میکنیم که LlamaIndex چیست، چه مشکلی را حل میکند، چگونه در معماریهایی مانند Retrieval-Augmented Generation (RAG) بهکار میرود و چرا در بسیاری از پروژههای مبتنی بر LLM به یک انتخاب استاندارد تبدیل شده است. همچنین با مفاهیم اصلی، اجزای کلیدی و کاربردهای عملی آن آشنا خواهیم شد.
LlamaIndex چیست؟
LlamaIndex یک فریمورک دادهای برای ساخت اپلیکیشنهای مبتنی بر مدلهای زبانی بزرگ است. مدلهایی مانند GPT-4 از پیش روی حجم عظیمی از دادههای عمومی آموزش دیدهاند و بهصورت پیشفرض تواناییهای قابل توجهی در پردازش زبان طبیعی دارند. با این حال، بدون دسترسی به دادههای اختصاصی شما، کاربرد آنها محدود باقی میماند.
LlamaIndex این امکان را فراهم میکند که دادهها را از منابع مختلفی مانند APIها، پایگاههای داده، فایلهای PDF و سایر منابع وارد سیستم کنید. این دادهها سپس به نمایشهایی میانی تبدیل و ایندکس میشوند که برای استفاده توسط LLMها بهینه شدهاند. پس از آن، LlamaIndex امکان جستوجو و تعامل مکالمهای با دادهها را از طریق موتورهای پرسوجو، رابطهای چت و عاملهای داده مبتنی بر LLM فراهم میکند. به این ترتیب، مدلهای زبانی میتوانند بدون نیاز به آموزش مجدد، به دادههای خصوصی در مقیاس بزرگ دسترسی پیدا کرده و آنها را تفسیر کنند.
چه یک کاربر مبتدی باشید که به دنبال راهی ساده برای پرسوجوی دادهها به زبان طبیعی است، و چه کاربری پیشرفته که به سفارشیسازی عمیق نیاز دارد، LlamaIndex ابزارهای لازم را در اختیار شما قرار میدهد. APIهای سطح بالا امکان شروع کار تنها با چند خط کد را فراهم میکنند و در عین حال، APIهای سطح پایینتر کنترل کامل بر فرایندهایی مانند ورود داده، ایندکسسازی، بازیابی و سایر مراحل را در اختیار توسعهدهنده قرار میدهند.
LlamaIndex چگونه کار میکند؟
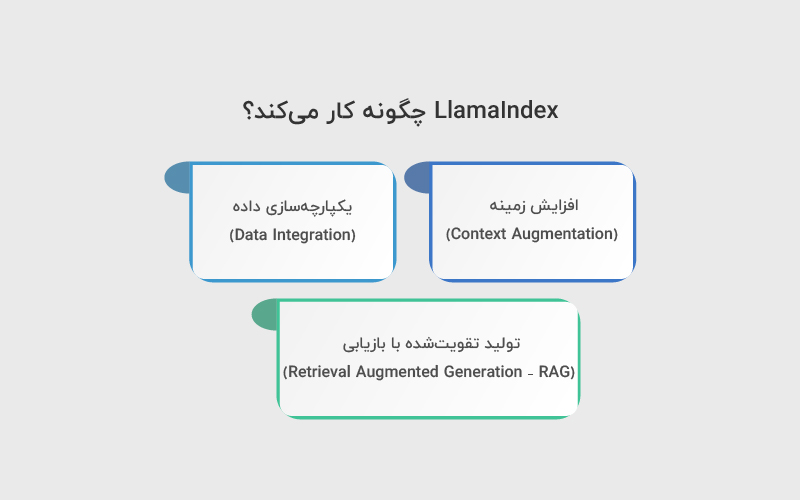
LlamaIndex به کاربران این امکان را میدهد که دادههای اختصاصی یا سفارشی خود را از طریق یکپارچهسازی داده (Data Integration) و افزایش زمینه (Context Augmentation) جمعآوری، سازماندهی و قابل استفاده برای مدلهای زبانی بزرگ کنند.
افزایش زمینه (Context Augmentation)
افزایش زمینه به فرایندی گفته میشود که در آن دادههای خارجی یا خصوصی به پنجره زمینه (Context Window) مدل زبانی اضافه میشوند؛ بهعبارت دیگر، مدل با دادههایی فراتر از اطلاعات ازپیشآموزشدیدهشده تغذیه میشود.
بیشتر مدلهای زبانی متنباز رایج، روی حجم عظیمی از دادههای عمومی آموزش دیدهاند. این مدلها در حل بسیاری از مسائل دنیای واقعی بسیار توانمند هستند، اما آموزش یا بازآموزی آنها برای یک کاربرد خاص، زمانبر و پرهزینه است. علاوه بر این، دانش درونی یک مدل تنها تا زمانی معتبر است که آخرین مرحله آموزش آن انجام شده باشد؛ بنابراین برای بازتاب دادن اطلاعات بهروز یا دادههای اختصاصی، استفاده از افزایش زمینه ضروری است.
در سالهای اخیر، مدلهای پایه (Foundation Models) به دلیل انعطافپذیری بالا محبوب شدهاند. این مدلها میتوانند در حوزهها و کاربردهای متنوع مورد استفاده قرار گیرند. با این حال، چه مدل از ابتدا روی دادههای بزرگ آموزش داده شده باشد و چه یک مدل پایه ازپیشآموزشدیده باشد، در اغلب موارد برای پاسخگویی دقیق به نیازهای یک دامنه خاص، به دادههای خارجی و اختصاصی نیاز دارد.
در این نقطه، وجود یک فریمورک دادهای اهمیت پیدا میکند؛ سیستمی که مدل زبانی را به دادههای خصوصی متصل میکند و آن را متناسب با هدف اپلیکیشن تنظیم مینماید. این بخش از پشته نرمافزاری دقیقا همان جایی است که ابزارهایی مانند LlamaIndex وارد عمل میشوند.
یکپارچهسازی داده (Data Integration)
دادهها معمولا از منابع و فرمتهای مختلفی مانند پایگاههای داده، APIها، فایلها و اسناد متنی به دست میآیند و اغلب ساختارمند نیستند یا در سیلوهای جداگانه ذخیره شدهاند. وظیفه فریمورک داده این است که این اطلاعات را دریافت، تبدیل و به شکلی سازماندهی کند که برای استفاده مدلهای زبانی مناسب باشد.
در LlamaIndex، این فرایند از طریق مسیری به نام Ingestion Pipeline انجام میشود. پس از ورود داده و تبدیل آن به فرمت قابل استفاده برای LLM، مرحله بعدی تبدیل اطلاعات به یک ساختار دادهای مناسب برای ایندکسسازی است.
رایجترین روش، تبدیل دادههای غیرساختیافته به بردارهای عددی (Vector Embeddings) است. در حوزه پردازش زبان طبیعی، به این فرایند «ساخت امبدینگ» گفته میشود و در ادبیات داده، از آن با عنوان «ایندکسسازی» یاد میشود. ایندکسسازی ضروری است؛ زیرا به مدل اجازه میدهد دادهها را بر اساس شباهت برداری جستوجو و بازیابی کند. نوع ایندکسسازی نیز به استراتژی جستوجوی انتخابشده بستگی دارد.
یکپارچهسازی داده، زمینهسازی را ممکن میکند؛ به این معنا که دادههای خصوصی عملا به پایگاه دانشی مدل زبانی اضافه میشوند. با افزایش طول پنجره زمینه در مدلهای جدید (برای مثال تا ۱۲۸ هزار توکن)، مدل قادر است حجم بیشتری از متن، مکالمههای طولانی یا حتی کدهای بزرگ را در حافظه کاری خود نگه دارد. این قابلیت باعث میشود پاسخها هم در کوتاهمدت و هم در مکالمات طولانی، منسجمتر و دقیقتر باشند.
با این حال، حتی با وجود پنجره زمینه بزرگ، فاینتیون کردن مدل با دادههای اختصاصی میتواند هزینه بالایی در آموزش و اجرا داشته باشد. به همین دلیل، استفاده از روشهایی که بازیابی داده را بهینه میکنند، اهمیت زیادی پیدا میکند. یکی از موثرترین این روشها، RAG است.
تولید تقویتشده با بازیابی (Retrieval Augmented Generation – RAG)
RAG یکی از شناختهشدهترین و پرکاربردترین روشهای افزایش زمینه است. این رویکرد به مدلهای زبانی اجازه میدهد به یک پایگاه دانش تخصصی متصل شوند و پاسخهایی دقیقتر و مرتبطتر تولید کنند.
فرایند RAG معمولا در سه مرحله انجام میشود:
- Chunking: دادههای متنی طولانی به بخشهای کوچکتر تقسیم میشوند.
- Embedding: هر بخش به یک بردار عددی (امبدینگ) تبدیل میشود.
- Retrieval: مرتبطترین بردارها بر اساس پرسوجوی کاربر بازیابی میشوند.
LlamaIndex این فرایند را با ارائه APIهای جامع برای هر مرحله ساده میکند. هسته این مکانیزم، مفهومی به نام Query Engine است که به کاربران اجازه میدهد با زبان طبیعی روی دادههای خود سوال بپرسند. ترکیب دادههای خارجی با پرامپتهای مدل زبانی، امکان ساخت اپلیکیشنهای مبتنی بر LLM را فراهم میکند که کاملا متناسب با یک دامنه یا کاربرد خاص طراحی شدهاند. این فرایند بهطور کلی از دو مرحله اصلی تشکیل شده است: مرحله ایندکسسازی و مرحله پرسوجو.
مرحله ایندکسسازی (Indexing stage)
در مرحله ایندکسسازی، LlamaIndex دادههای خصوصی را بهصورت بهینه در یک ایندکس برداری (Vector Index) ذخیره میکند. این مرحله به ایجاد یک پایگاه دانش قابل جستجو و متناسب با دامنه تخصصی شما کمک میکند. دادههای ورودی میتوانند شامل اسناد متنی، رکوردهای پایگاه داده، گرافهای دانشی و انواع دیگر داده باشند.
در عمل، ایندکسسازی دادهها را به بردارهای عددی یا همان امبدینگها (Embeddings) تبدیل میکند که معنای مفهومی محتوا را در خود نگه میدارند. این کار امکان انجام جستجوهای سریع مبتنی بر شباهت معنایی را در میان حجم زیادی از داده فراهم میکند.
مرحله پرسوجو (Querying stage)
در مرحله پرسوجو، RAG Pipeline بهدنبال مرتبطترین اطلاعات بر اساس پرسش کاربر میگردد. سپس این اطلاعات به همراه پرسش، در اختیار مدل زبانی قرار میگیرد تا پاسخ دقیقتری تولید شود.
این فرایند به مدل زبانی اجازه میدهد به اطلاعات بهروز و فعلی دسترسی داشته باشد؛ اطلاعاتی که ممکن است در زمان آموزش اولیه مدل وجود نداشتهاند.
چالش اصلی در این مرحله، بازیابی، سازماندهی و استدلال روی دادههایی است که ممکن است از چندین پایگاه دانش مختلف به دست آمده باشند.
راهاندازی LlamaIndex
قبل از ورود به آموزش و پروژهی LlamaIndex، ابتدا باید پکیج پایتون آن را نصب کرده و API مربوطه را تنظیم کنیم.
۱. نصب LlamaIndex
میتوان LlamaIndex را بهسادگی با استفاده از pip نصب کرد:
|
1 |
pip install llama–index |
۲. تنظیم API (Powered By OpenAI)
بهصورت پیشفرض، LlamaIndex از مدل GPT-3 text-davinci-003 شرکت OpenAI استفاده میکند. برای استفاده از این مدل، لازم است متغیر OPENAI_API_KEY را تنظیم کنید.
میتوانید با ساخت یک حساب کاربری رایگان در OpenAI، کلید API خود را دریافت کنید.
|
1 2 3 |
import os os.environ[“OPENAI_API_KEY”] = “INSERT OPENAI KEY” |
همچنین مطمئن شوید که پکیج openai نیز نصب شده باشد:
|
1 |
pip install openai |
۳. افزودن دادههای شخصی به LLM با استفاده از LlamaIndex
در این بخش یاد میگیریم چگونه با کمک LlamaIndex یک Resume Reader بسازیم.
برای این کار میتوانید رزومهی خود را از صفحه پروفایل لینکدین دانلود کنید (از بخش More و گزینه Save to PDF).
توجه: در این مثال، کدهای پایتون با استفاده از محیط DataLab اجرا شدهاند. شما میتوانید بدون نصب هیچ چیز روی سیستم خود، یک نسخه از نوتبوک مربوطه بسازید و کدها را اجرا کنید.
قبل از اجرای کدها، باید پکیجهای llama-index، openai و pypdf را نصب کنیم.
پکیج pypdf برای خواندن و تبدیل فایلهای PDF استفاده میشود.
|
1 |
%pip install llama–index openai pypdf |
۴. بارگذاری دادهها و ساخت ایندکس
در این مثال، یک پوشه به نام Private-Data داریم که شامل یک فایل PDF است.
برای خواندن فایل از SimpleDirectoryReader استفاده میکنیم و سپس دادهها را با کمک TreeIndex به یک ایندکس تبدیل میکنیم.
|
1 2 3 4 |
from llama_index import TreeIndex, SimpleDirectoryReader resume = SimpleDirectoryReader(“Private-Data”).load_data() new_index = TreeIndex.from_documents(resume) |
۵. اجرای پرسوجو (Query)
پس از ایندکس شدن دادهها، میتوان با استفاده از متد as_query_engine() سوالهای مختلفی درباره محتوای سند پرسید.
این متد به شما اجازه میدهد اطلاعات مشخصی را از داخل سند استخراج کرده و با کمک مدل GPT-3 پاسخ دریافت کنید.
|
1 2 3 |
query_engine = new_index.as_query_engine() response = query_engine.query(“When did Abid graduated?”) print(response) |
خروجی:
|
1 |
Abid graduated in February 2014. |
میتوان سوالات دقیقتری نیز مطرح کرد، مثلا درباره گواهینامهها:
|
1 2 |
response = query_engine.query(“What is the name of certification that Abid received?”) print(response) |
خروجی:
|
1 |
Data Scientist Professional |
این مثال نشان میدهد که LlamaIndex درک کاملی از محتوای رزومه پیدا کرده است؛ قابلیتی که میتواند برای شرکتها در شناسایی افراد مناسب بسیار مفید باشد.
۶. ذخیره و بارگذاری Context
ساخت ایندکس فرایندی زمانبر است. برای جلوگیری از ساخت مجدد ایندکس، میتوان context را ذخیره کرد.
بهصورت پیشفرض، دستور زیر ایندکس را در مسیر ./storage ذخیره میکند.
|
1 |
new_index.storage_context.persist() |
بارگذاری ایندکس ذخیرهشده
پس از ذخیره، میتوان context را دوباره بارگذاری کرده و ایندکس را سریعا بازسازی کرد:
|
1 2 3 4 |
from llama_index import StorageContext, load_index_from_storage storage_context = StorageContext.from_defaults(persist_dir=“./storage”) index = load_index_from_storage(storage_context) |
برای اطمینان از عملکرد صحیح، دوباره یک پرسوجو اجرا میکنیم:
|
1 2 3 |
query_engine = index.as_query_engine() response = query_engine.query(“What is Abid’s job title?”) print(response) |
خروجی:
|
1 |
Abid‘s job title is Technical Writer. |
۷. ساخت Chatbot با LlamaIndex
بهجای پرسشوپاسخ ساده، میتوان از LlamaIndex برای ساخت یک چتبات شخصی نیز استفاده کرد.
برای این کار کافی است ایندکس را با متد as_chat_engine() مقداردهی کنیم.
|
1 2 3 |
query_engine = index.as_chat_engine() response = query_engine.chat(“What is the job title of Abid in 2021?”) print(response) |
خروجی:
|
1 |
Abid‘s job title in 2021 is Data Science Consultant. |
بدون ارائهی context جدید، میتوان سؤالات ادامهدار پرسید:
|
1 2 |
response = query_engine.chat(“What else did he do during that time?”) print(response) |
خروجی:
|
1 |
In 2021, Abid worked as a Data Science Consultant for Guidepoint, a Writer for Towards Data Science and Towards AI, a Technical Writer for Machine Learning Mastery, an Ambassador for Deepnote, and a Technical Writer for Start It Up. |
این مثال بهخوبی نشان میدهد که موتور چت LlamaIndex چگونه میتواند مکالمهای منسجم و دقیق را بر اساس دادههای شخصی مدیریت کند.
کاربردهای LlamaIndex در اپلیکیشنهای مبتنی بر LLM

LlamaIndex بهعنوان یک فریمورک دادهای برای مدلهای زبانی بزرگ، امکان ساخت انواع اپلیکیشنهای مبتنی بر هوش مصنوعی را فراهم میکند. این ابزار با اتصال LLMها به دادههای اختصاصی، پایهی توسعهی سیستمهایی را میسازد که بتوانند بر اساس دانش داخلی سازمان یا دادههای شخصیشده پاسخ تولید کنند.
مهمترین موارد استفاده LlamaIndex عبارتاند از:
پرسشوپاسخ مبتنی بر RAG
یکی از اصلیترین کاربردهای LlamaIndex، پیادهسازی سیستمهای RAG است که به مدل زبانی اجازه میدهد به دادههای خارجی و اختصاصی دسترسی داشته باشد.
- جستجو و بازیابی اطلاعات از اسناد بدون ساختار مانند PDF، فایل متنی و صفحات وب
- پشتیبانی از دادههای ساختاریافته از طریق Text-to-SQL و Text-to-Pandas
- ارائه پاسخهای دقیقتر و بهروز بدون نیاز به fine-tuning مدل
- مناسب برای پایگاههای دانش، مستندات فنی و سیستمهای پشتیبانی
چتباتها و Chat Engine
LlamaIndex امکان ساخت چتباتهای stateful را از طریق Chat Engine فراهم میکند؛ چتباتهایی که میتوانند زمینه گفتگو را در چندین تعامل حفظ کنند.
- پشتیبانی از گفتگوهای چندمرحلهای (برخلاف Q&A ساده)
- امکان پیادهسازی چتباتهای شخصیسازیشده شبیه ChatGPT
- استفاده از الگوهای پیشرفته مانند ReAct Agent برای استدلال و تصمیمگیری
- مناسب برای دستیارهای داخلی سازمان و ابزارهای تعاملی
Query Engine برای جستجوی معنایی
Query Engine یک جریان end-to-end برای پرسوجوی طبیعی روی دادههاست که بخش مهمی از معماری LlamaIndex را تشکیل میدهد.
- دریافت سوال به زبان طبیعی
- بازیابی مرتبطترین بخشهای داده
- ارسال context مناسب به LLM برای تولید پاسخ
- قابل استفاده در داشبوردهای تحلیلی و ابزارهای جستجوی هوشمند
مدیریت و زنجیرهسازی پرامپتها (Prompting & Workflows)
LlamaIndex از گردشکارهای رویدادمحور پشتیبانی میکند که امکان اتصال چندین فراخوانی LLM را بهصورت ساختاریافته فراهم میکند.
- مدیریت منطقی پرامپتها در پروژههای پیچیده
- کنترل بهتر جریان داده و پاسخها
- مناسب برای اپلیکیشنهایی با چند مرحله استدلال یا تصمیمگیری
- کاهش پیچیدگی در توسعه سیستمهای LLMمحور
استخراج دادههای ساختیافته از متن
مدلهای زبانی میتوانند با کمک LlamaIndex اطلاعات مهم را از دادههای بدون ساختار استخراج کنند.
- استخراج موجودیتهایی مانند نام، تاریخ، آدرس و اعداد
- تبدیل متن آزاد به دادهی ساختیافته و استاندارد
- آمادهسازی داده برای ذخیره در دیتابیس یا تحلیلهای بعدی
- کاربردی در پردازش اسناد، قراردادها و گزارشها
عاملهای خودکار (Autonomous Agents)
LlamaIndex امکان ساخت عاملهای هوشمند را فراهم میکند که فراتر از پاسخگویی ساده عمل میکنند.
- اجرای وظایف چندمرحلهای و پیچیده
- ترکیب جستجو، استدلال و تولید پاسخ
- پیادهسازی Agentic RAG برای تحقیق و تحلیل
- مناسب برای دستیارهای تحقیقاتی و سیستمهای تصمیمیار
پیادهسازی RAG با LlamaIndex (مثال عملی)
در این بخش، با یک مثال عملی میبینیم که چگونه میتوان با استفاده از LlamaIndex یک سیستم RAG ساده اما کاربردی پیادهسازی کرد. هدف این است که یک فایل متنی را ایندکس کنیم و سپس با پرسوجوهای زبان طبیعی، پاسخهای مرتبط از محتوای آن دریافت کنیم.
سناریو
- یک فایل متنی
- ساخت یا بارگذاری index برداری
- اجرای یک یا چند query روی دادهها
- استفاده مجدد از index ذخیرهشده برای بهینهسازی عملکرد
اجرای یک Query ساده (Single Query)
در سادهترین حالت، میتوان یک اسکریپت نوشت که:
- بررسی کند آیا index از قبل وجود دارد یا نه
- در صورت وجود، آن را بارگذاری کند
- در غیر این صورت، داده را ایندکس و ذخیره کند
- یک پرسوجو به مدل ارسال کند
کد: single_query.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
from pathlib import Path from llama_index.core import ( SimpleDirectoryReader, StorageContext, VectorStoreIndex, load_index_from_storage, ) # Define the storage directory BASE_DIR = Path(__file__).resolve().parent PERSIST_DIR = BASE_DIR / “storage” DATA_FILE = BASE_DIR / “data” / “pep8.rst” def get_index(persist_dir=PERSIST_DIR, data_file=DATA_FILE): if persist_dir.exists(): storage_context = StorageContext.from_defaults( persist_dir=str(persist_dir), ) index = load_index_from_storage(storage_context) print(“Index loaded from storage…”) else: reader = SimpleDirectoryReader(input_files=[str(data_file)]) documents = reader.load_data() index = VectorStoreIndex.from_documents(documents) index.storage_context.persist(persist_dir=str(persist_dir)) print(“Index created and persisted to storage…”) return index def main(): index = get_index() query_engine = index.as_query_engine() response = query_engine.query(“What is this document about?”) print(response) if __name__ == “__main__”: main() |
توضیح عملکرد کد
- SimpleDirectoryReader فایل متنی را بارگذاری میکند
- VectorStoreIndex دادهها را به embedding تبدیل کرده و ایندکس میکند
- StorageContext امکان ذخیره و بارگذاری index را فراهم میکند
- query_engine نقش موتور RAG را دارد و query را با context مناسب به LLM ارسال میکند
خروجی نمونه
|
1 2 |
Index loaded from storage... This document provides coding conventions for Python code... |
این خروجی نشان میدهد که مدل، پس از بازیابی بخشهای مرتبط از سند، پاسخ را بر اساس آن تولید کرده است.
اجرای چند Query بهصورت همزمان (Async Queries)
در پروژههای واقعی، معمولا نیاز داریم چند پرسوجو را بهصورت همزمان اجرا کنیم.
LlamaIndex این امکان را با متد aquery() و کتابخانه asyncio فراهم میکند.
کد: async_query.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import asyncio from pathlib import Path from llama_index.core import ( SimpleDirectoryReader, StorageContext, VectorStoreIndex, load_index_from_storage, ) # Define the storage directory BASE_DIR = Path(__file__).resolve().parent PERSIST_DIR = BASE_DIR / “storage” DATA_FILE = BASE_DIR / “data” / “pep8.rst” def get_index(persist_dir=PERSIST_DIR, data_file=DATA_FILE): if persist_dir.exists(): storage_context = StorageContext.from_defaults( persist_dir=str(persist_dir), ) index = load_index_from_storage(storage_context) print(“Index loaded from storage…”) else: reader = SimpleDirectoryReader(input_files=[str(data_file)]) documents = reader.load_data() index = VectorStoreIndex.from_documents(documents) index.storage_context.persist(persist_dir=str(persist_dir)) print(“Index created and persisted to storage…”) return index async def main(): index = get_index() query_engine = index.as_query_engine() queries = [ “What is this document about?”, “Summarize the naming conventions in Python.”, ] # Run queries asynchronously tasks = [query_engine.aquery(query) for query in queries] responses = await asyncio.gather(*tasks) # Print responses for i, (query, response) in enumerate(zip(queries, responses), 1): print(f“\nQuery {i}: {query}”) print(f“Response: {response}\n”) print(“-“ * 80) if __name__ == “__main__”: asyncio.run(main()) |
نکات مهم این پیادهسازی
- aquery() نسخه asynchronous متد query است
- asyncio.gather() چند درخواست را همزمان اجرا میکند
- این روش برای سیستمهای مقیاسپذیر، APIها و چتباتها بسیار کاربردی است
جمعبندی
LlamaIndex یک ابزار قدرتمند برای توسعه برنامههای مبتنی بر مدلهای زبانی بزرگ است که به شما اجازه میدهد دادههای حوزهمحور خود را سازماندهی کرده و از آنها برای تولید پاسخهای دقیق و مرتبط استفاده کنید.
این ابزار با فراهم کردن امکاناتی مانند ساخت شاخصهای جستجو، بارگذاری آسان دادهها و ادغام با مدلهای مختلف LLM، فرایند ایجاد سیستمهای بازیابی و تولید محتوا (RAG) را ساده و موثر میکند. با بهرهگیری از LlamaIndex، توسعهدهندگان میتوانند برنامههای هوش مصنوعی مبتنی بر داده بسازند که هم قابل اعتماد و هم کاربردی باشند، و به راحتی پاسخهای مدل را بر اساس منابع واقعی و معتبر تقویت کنند.
منابع
ibm.com | realpython.com | datacamp.com
سوالات متداول
LlamaIndex یک چارچوب توسعهدهندهمحور است که سرعت تولید برنامههای مبتنی بر هوش مصنوعی تولیدی (GenAI) را افزایش میدهد. این ابزار شامل انتزاعهای سطح بالا و پایین مطمئن برای ساخت عاملها، سیستمهای بازیابی و تولید محتوا (RAG)، جریانهای کاری سفارشی و ادغامها است.
کتابخانه متنباز LlamaIndex تحت مجوز MIT کاملا رایگان است و میتوانید آن را روی سیستم محلی یا سرور خود اجرا کنید. تنها هزینهای که پرداخت میکنید، هزینه استفاده از مدلهای LLM مانند OpenAI API است.
بله. میتوانید LangChain را برای مدیریت جریانهای کاری و منطق کلی برنامه استفاده کنید و موتور پرسوجوی LlamaIndex را به عنوان یک ابزار در جریان LangChain خود ادغام کنید تا اطلاعات مرتبط از دادههای شاخصگذاری شده بازیابی شود.
بله. LlamaIndex کاملا همکاریمحور است و اجازه میدهد تیم شما برای هر کاربردی عاملهای سفارشی بسازد. با رابط کاربری شهودی، استفاده از آن آسان است و به راحتی با پشته تکنولوژی موجود، دادهها و هر مدل NLU یا LLM ادغام میشود.




دیدگاهتان را بنویسید