
جهان اطراف ما ترکیبی از سیگنالها و ورودیهای حسی مختلف است؛ ما با دیدن، شنیدن و لمس کردن میفهمیم. همین ترکیب چندحسی باعث میشود درک انسان از جهان بسیار غنیتر از چیزی باشد که مدلهای هوش مصنوعی سنتی (تکوجهی یا Unimodal) قادر به بازتولیدش هستند. مدلهای هوش مصنوعی چندوجهی با الهام از نحوه درک انسان، تلاش میکنند دادهها را از منابع مختلف مثل متن، تصویر، صدا یا دادههای حسگرها با هم ترکیب کنند. نتیجه این ترکیب، درکی جامعتر و دقیقتر از دادههاست که امکان انجام طیف گستردهای از وظایف و کاربردهای هوشمند را فراهم میکند.
در این بخش، نگاهی کوتاه داریم به انواع وظایف چندوجهی که بر پایه متن و تصویر انجام میشوند و مدلهایی که برای آنها طراحی شدهاند. پیش از ورود به جزئیات، بد نیست یادآوری کنیم منظور از «چندوجهی» چیست؟
مدلهای هوش مصنوعی چندوجهی
مدلهای هوش مصنوعی چندوجهی (Multimodal AI Models) سیستمهایی هستند که میتوانند دادهها را از چند نوع منبع مختلف — مانند متن، تصویر، صدا یا ویدئو — بهصورت همزمان دریافت و تحلیل کنند. این مدلها با ترکیب دادههای متنوع، درک عمیقتر و دقیقتری از موقعیتها و مفاهیم به دست میآورند؛ برای مثال، مدلی که هم تصویر و هم توضیح متنی آن را بررسی میکند، میتواند نتایج بسیار دقیقتری تولید کند.
نمونههایی از وظایف چندوجهی
قبل از بررسی مدلهای خاص، مهم است درک کنیم که چه نوع وظایفی میان تصویر و متن وجود دارد. این وظایف متنوعاند و شامل موارد زیر میشوند (اما محدود به آنها نیستند):
- پرسش و پاسخ و استدلال تصویری:
مدل با تحلیل تصویر به پرسشهایی مانند «چه کسی پشت فرمان است؟» پاسخ میدهد و در سطح پیشرفتهتر میتواند روابط و منطق صحنه را نیز درک کند.
- پرسش و پاسخ مبتنی بر سند:
مدل با ترکیب بینایی ماشین و پردازش زبان طبیعی، متن و ساختار یک سند (مثل فرم یا فاکتور) را تحلیل میکند و مستقیما از روی تصویر پاسخ میدهد.
- توصیف تصویر:
مدل پس از درک محتوای بصری، جملاتی طبیعی تولید میکند که داستان تصویر را بیان میکنند؛ مثلا «غروب آفتاب بر فراز دریا» یا «کودکی روی تاب در حال خندیدن».
- بازیابی تصویر و متن:
مدل میتواند از روی متن، تصویر مرتبط را پیدا کند یا برعکس، متنی که بهترین توصیف تصویر است را بازیابی کند.
- تطبیق زبانی و تصویری:
مدل یاد میگیرد بخشهای مختلف جمله را به نواحی خاصی از تصویر وصل کند؛ مثلا وقتی میپرسیم «سیب قرمز کجاست؟»، ناحیه مربوط به آن را در تصویر مشخص میکند.
- تولید تصویر از متن:
مدل با دریافت توضیح متنی، تصویری منحصربهفرد و خلاقانه میسازد؛ از مناظر واقعی گرفته تا طرحهای انتزاعی و تخیلی.
پرسش و پاسخ تصویری و استدلال تصویری

پرسش و پاسخ تصویری (VQA)
ورودی: یک جفت تصویر و پرسش (تصویر بههمراه سوالی درباره آن).
خروجی:
- در حالت چندگزینهای: برچسبی که نشاندهنده پاسخ درست از بین گزینههای از پیش تعیینشده است.
- در حالت پاسخ آزاد: پاسخی متنی و طبیعی که بر اساس تصویر و سوال تولید میشود.
وظیفه: پاسخدادن به پرسشهای مربوط به تصویر. (بیشتر مدلهای VQA این کار را بهصورت یک مسئله دستهبندی با پاسخهای مشخص انجام میدهند.)
استدلال تصویری
ورودی: بسته به نوع وظیفهی استدلال تصویری متفاوت است:
- در وظایف مشابه پرسش و پاسخ تصویری (VQA): یک جفت تصویر و سوال.
- در وظایف تطبیق: تصویر و جملهی متنی برای بررسی درستی یا نادرستی آن.
- در وظایف استنتاج معنایی: تصویر و متن (گاهی شامل چند جمله) برای ارزیابی ارتباط معنایی.
- در وظایف زیرسوال: تصویر بههمراه یک سوال اصلی و چند سوال فرعی مرتبط با جزئیات ادراکی.
خروجی: بسته به نوع وظیفه متفاوت است
- در VQA: پاسخ به سوال دربارهی تصویر.
- در Matching: مقدار درست/نادرست (True/False) برای سنجش صحت جمله نسبت به تصویر.
- در Entailment: پیشبینی اینکه آیا محتوای تصویر از نظر معنا با متن مطابقت دارد یا نه.
- در Sub-question: پاسخ به سوالهای فرعی مرتبط با جزئیات درک تصویر.
وظیفه: اجرای انواع مختلف استدلال و تحلیل بر روی تصاویر (همانطور که در مثال بالا نشان داده شده است).
بهطور کلی، وظایف «پرسش و پاسخ تصویری» و «استدلال تصویری» هر دو در دسته VQA قرار میگیرند.
مدلهای معروف برای VQA
۱- BLIP
یکی از مدلهای پرکاربرد در این حوزه BLIP-VQA است که توسط تیم هوش مصنوعی Salesforce توسعه داده شده است. BLIP از روشی به نام Bootstrapping Language-Image Pre-training استفاده میکند که دادههای متنی و تصویری موجود در وب را با تولید کپشن ترکیب میکند تا عملکردی در سطح مدلهای پیشرفته بینایی–زبان ارائه دهد.
این مدل در پلتفرم Hugging Face هم در دسترس است و میتوان آن را برای انجام وظایف VQA استفاده کرد.
|
1 2 3 4 5 6 7 8 9 10 11 |
from PIL import Image from transformers import pipeline vqa_pipeline = pipeline( “visual-question-answering”, model=“Salesforce/blip-vqa-capfilt-large” ) image = Image.open(“elephant.jpeg”) question = “Is there an elephant?” vqa_pipeline(image, question, top_k=1) |
۲- DePlot
DePlot یک مدل استدلال زبانی–تصویری است که برای تبدیل نمودارها و چارتها به توضیحات متنی آموزش داده شده است. این مدل بهصورت one-shot (یعنی با تنها یک مثال آموزشی) قادر است اطلاعات تصویری را به متن قابلدرک برای مدلهای زبانی تبدیل کند.
به لطف این ویژگی، DePlot میتواند در کنار مدلهای زبانی بزرگ (LLMها) استفاده شود تا به پرسشهای پیچیده درباره دادهها پاسخ دهد؛ حتی زمانی که سوالها جدید و بهصورت طبیعی توسط انسان نوشته شده باشند. این مدل با استانداردسازی فرایند «تبدیل نمودار به جدول» و بهرهگیری از معماری Pix2Struct، عملکردی بهتر از مدلهای پیشرفته پیشین در حوزه پرسش و پاسخ درباره نمودارها (Chart QA) بهدست آورده است.
در پلتفرم Hugging Face هم میتوان از DePlot بهسادگی برای انجام وظایف مرتبط با تحلیل نمودارها و دادههای بصری استفاده کرد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from transformers import Pix2StructProcessor, Pix2StructForConditionalGeneration import requests from PIL import Image processor = Pix2StructProcessor.from_pretrained(“google/deplot”) model = Pix2StructForConditionalGeneration.from_pretrained(“google/deplot”) url = “https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/5090.png” image = Image.open(requests.get(url, stream=True).raw) inputs = processor( images=image, text=“Generate underlying data table of the figure below:”, return_tensors=“pt”, ) predictions = model.generate(**inputs, max_new_tokens=512) print(processor.decode(predictions[0], skip_special_tokens=True)) |
۳- VLIT
VLIT یک مدل مبتنی بر ترنسفورمر است که برای پردازش همزمان تصویر و زبان طراحی شده است. این مدل برخلاف بسیاری از مدلهای بینایی، از هیچ لایه کانولوشنی (Convolution) یا نظارت ناحیهای (Region Supervision) استفاده نمیکند و بهطور مستقیم روی دادههای تصویر و متن با هم آموزش میبیند.
نسخه اصلی ViLT معماری بزرگی دارد (در اندازهی B32) و با یادگیری مشترک تصویر و متن، در طیف وسیعی از وظایف بینایی–زبانی عملکرد قابلقبولی نشان میدهد.
مدل VLIT نیز نسخهای از ViLT است که بهصورت خاص روی دیتاست VQAv2 آموزش داده شده تا بتواند به پرسشهای متنی دربارهی تصاویر پاسخ دهد.
بهدلیل سادگی معماری و عدم نیاز به شبکههای کانولوشنی سنگین، این مدل در وظایفی مثل پرسش و پاسخ تصویری (VQA) عملکردی رقابتی و در عین حال سریع دارد.
در پلتفرم Hugging Face هم میتوان از VLIT برای اجرای وظایف ترکیبی متن و تصویر استفاده کرد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from transformers import ViltProcessor, ViltForQuestionAnswering import requests from PIL import Image # prepare image + question url = “http://images.cocodataset.org/val2017/000000039769.jpg” image = Image.open(requests.get(url, stream=True).raw) text = “How many cats are there?” processor = ViltProcessor.from_pretrained(“dandelin/vilt-b32-finetuned-vqa”) model = ViltForQuestionAnswering.from_pretrained(“dandelin/vilt-b32-finetuned-vqa”) # prepare inputs encoding = processor(image, text, return_tensors=“pt”) # forward pass outputs = model(**encoding) logits = outputs.logits idx = logits.argmax(–1).item() print(“Predicted answer:”, model.config.id2label[idx]) |
پرسش و پاسخ تصویری مبتنی بر سند (DocVQA)
در این نوع وظیفه، ورودی شامل یک تصویر از سند (مثلا فایل اسکنشده یا نسخه دیجیتالی آن) و یک پرسش متنی درباره محتوای آن است و خروجی، پاسخی متنی است که بهطور دقیق به سوال مطرحشده پاسخ میدهد.
ورودیها:
- تصویر سند: شامل متن، چیدمان (layout) و عناصر بصری مانند جدول، امضا یا مهر.
- سوال: یک پرسش متنی طبیعی درباره محتوای سند (برای مثال: «تاریخ صدور این فاکتور چیست؟»).
وظیفه مدل:
- تحلیل و درک محتوا: مدل باید اطلاعات متنی و بصری موجود در سند را پردازش کند تا معنای کلی آن را بفهمد.
- استدلال و نتیجهگیری: باید بتواند بین اجزای تصویری، متن و سوال ارتباط برقرار کند و از آنها نتیجه بگیرد.
- تولید پاسخ متنی: در نهایت، پاسخی واضح، خلاصه و دقیق در قالب متن طبیعی تولید کند که دقیقا به سوال کاربر پاسخ دهد.
خروجی:
- پاسخی متنی که به سوال مربوط به سند پاسخ میدهد و بر اساس اطلاعات واقعی موجود در تصویر است.
- در ادامه با چند نمونه از مدلهای محبوب DocVQA که در پلتفرم Hugging Face در دسترس هستند آشنا میشویم.
مدلهای محبوب DocVQA
۱- LayoutLM
LayoutLM یک شبکه عصبی از پیش آموزشدیده است که برای درک محتوای اسناد طراحی شده و بهصورت همزمان هم متن و هم چیدمان (layout) سند را تحلیل میکند.
برخلاف مدلهای پردازش زبان طبیعی سنتی که فقط به متن خام توجه دارند، LayoutLM ویژگیهایی مانند اندازه فونت، موقعیت مکانی کلمات در صفحه و فاصله میان آنها را هم در نظر میگیرد. این اطلاعات به مدل کمک میکند تا روابط میان کلمات و معنای آنها را در بافت بصری سند درک کند.
بهدلیل همین توانایی، LayoutLM در وظایفی مانند تشخیص و درک فرمها، تحلیل رسیدها و طبقهبندی اسناد عملکرد بسیار خوبی دارد و یکی از ابزارهای قدرتمند برای استخراج داده از اسناد اسکنشده بهشمار میآید.
این مدل در پلتفرم Hugging Face هم قابل استفاده است و میتوان از آن برای کاربردهای متنوع پردازش اسناد استفاده کرد.
|
1 2 3 4 5 6 7 8 9 10 11 |
from transformers import pipeline from PIL import Image pipe = pipeline(“document-question-answering”, model=“impira/layoutlm-document-qa”) question = “What is the purchase amount?” image = Image.open(“your-document.png”) pipe(image=image, question=question) ## [{‘answer’: ‘20,000$’}] |
۲- Donut
Donut که مخفف Document Understanding Transformer است، یک مدل پیشرفته برای درک محتوای اسناد تصویری محسوب میشود که برخلاف روشهای سنتی، به مرحله OCR (تشخیص کاراکتر نوری) نیازی ندارد.
در واقع Donut مستقیما خودِ تصویر سند را تحلیل میکند تا ساختار و محتوای آن را بفهمد. این مدل از ترکیب یک رمزگذار تصویری (Swin Transformer) و یک رمزگشای متنی (BART) تشکیل شده و میتواند اطلاعات را استخراج کرده و توضیحات متنی تولید کند.
توانایی اصلی Donut در ماهیت «پایانبهپایان» آن است؛ یعنی تمام فرایند از تحلیل تصویر تا تولید متن را بدون نیاز به OCR انجام میدهد. به همین دلیل هم خطاهای ناشی از تشخیص نادرست متن در روشهای سنتی را حذف میکند و در عین حال با سرعت بالا و دقت چشمگیر عمل میکند.
Donut در وظایفی مانند طبقهبندی اسناد، درک فرمها و پرسش و پاسخ تصویری عملکرد بسیار قویای دارد و در پلتفرم Hugging Face هم در دسترس است.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from transformers import pipeline from PIL import Image pipe = pipeline( “document-question-answering”, model=“naver-clova-ix/donut-base-finetuned-docvqa” ) question = “What is the purchase amount?” image = Image.open(“your-document.png”) pipe(image=image, question=question) ## [{‘answer’: ‘20,000$’}] |
۳- Nougat
Nougat یک مدل ترنسفورمر بینایی است که برای «خواندن» مستقیم مقالات علمی و فایلهای PDF طراحی شده و بدون نیاز به OCR میتواند محتوای آنها را به زبان نشانهگذاری ساختاریافته (markup) تبدیل کند.
این مدل روی میلیونها مقالهی آکادمیک آموزش دیده و قادر است حتی عناصر پیچیدهای مانند فرمولهای ریاضی، جدولها و نمودارها را بهدرستی درک و بازتولید کند.
نتیجه این است که محتوای علمی موجود در PDFها با دقت بالا و بدون از دست رفتن معنا و ساختار، به فرم قابلاستفادهتری تبدیل میشود.
Nougat از همان معماری Donut استفاده میکند؛ یعنی رمزگذار تصویری مبتنی بر Transformer بههمراه رمزگشای متنی خودبازگشتی (Autoregressive) تا اسناد علمی را از قالب تصویری به Markdown تبدیل کند و دسترسی به آنها را سادهتر سازد.
این مدل در پلتفرم Hugging Face نیز در دسترس است و ابزار قدرتمندی برای پردازش و استخراج محتوای علمی از PDFها بهشمار میآید.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
from huggingface_hub import hf_hub_download import re from PIL import Image from transformers import NougatProcessor, VisionEncoderDecoderModel from datasets import load_dataset import torch processor = NougatProcessor.from_pretrained(“facebook/nougat-base”) model = VisionEncoderDecoderModel.from_pretrained(“facebook/nougat-base”) device = “cuda” if torch.cuda.is_available() else “cpu” model.to(device) # prepare PDF image for the model filepath = hf_hub_download( repo_id=“hf-internal-testing/fixtures_docvqa”, filename=“nougat_paper.png”, repo_type=“dataset”, ) image = Image.open(filepath) pixel_values = processor(image, return_tensors=“pt”).pixel_values # generate transcription (here we only generate 30 tokens) outputs = model.generate( pixel_values.to(device), min_length=1, max_new_tokens=30, bad_words_ids=[[processor.tokenizer.unk_token_id]], ) sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0] sequence = processor.post_process_generation(sequence, fix_markdown=False) # note: we’re using repr here such for the sake of printing the \n characters, feel free to just print the sequence print(repr(sequence)) |
توصیف تصویر (Image Captioning)

در این وظیفه، هدف مدل این است که برای یک تصویر، توضیحی طبیعی و معنادار در قالب متن تولید کند؛ توضیحی که محتوای تصویر را با دقت توصیف کند، از اشیا و کنشها گرفته تا روابط میان آنها و فضای کلی صحنه.
ورودیها:
- تصویر: در قالبهای مختلف مانند JPEG یا PNG.
- استخراجگر ویژگی (اختیاری): یک شبکهی عصبی از پیش آموزشدیده (مثلا CNN) که ویژگیهای مهم تصویر را استخراج میکند.
خروجی:
- یک یا چند جمله متنی که محتوای تصویر را بهصورت دقیق و روان توصیف میکنند. هدف این است که جملهها هم از نظر معنایی غنی باشند و هم از نظر زبانی طبیعی و منسجم.
فرایند کلی:
- درک محتوای بصری تصویر (شناسایی اشیا، کنشها و روابط).
- رمزگذاری این اطلاعات در قالب یک نمایش عددی قابلفهم برای مدل.
- رمزگشایی این نمایش به جملهای طبیعی و دستوری درست.
مدلهای محبوب برای توصیف تصویر
ViT-GPT2
یکی از مدلهای شناختهشده در این حوزه ViT-GPT2 است.
این مدل بر پایه PyTorch ساخته شده و از ترکیب ویژن ترنسفورمر (ViT) برای استخراج ویژگیهای تصویری و GPT-2 برای تولید متن استفاده میکند.
ViT-GPT2 روی دیتاست COCO آموزش دیده و با ترکیب قدرت درک بصری ViT و توانایی زبانی GPT-2، توضیحاتی دقیق و روان درباره تصاویر تولید میکند.
بهدلیل متنباز بودن، این مدل یکی از گزینههای کارآمد برای وظایف مرتبط با درک تصویر و تولید کپشن بهشمار میآید.
|
1 2 3 4 5 6 7 |
from transformers import pipeline image_to_text = pipeline(“image-to-text”, model=“nlpconnect/vit-gpt2-image-captioning”) image_to_text(“https://ankur3107.github.io/assets/images/image-captioning-example.png”) # [{‘generated_text’: ‘a soccer game with a player jumping to catch the ball ‘}] |
BLIP – مدل تولید توضیح تصویر
مدل BLIP Image Captioning یکی از پیشرفتهترین مدلها در زمینه تولید توضیح تصویر است. این مدل بر پایه چارچوب BLIP ساخته شده؛ چارچوبی که برای درک و تولید یکپارچه متن و تصویر طراحی شده و روی ترکیبی از دادههای وب تمیز و نویزی آموزش دیده است.
BLIP با استفاده از یک فرایند bootstrapping (یعنی پالایش تدریجی دادهها)، کپشنهای نامعتبر یا نویزی را فیلتر میکند تا کیفیت یادگیری و دقت خروجی افزایش یابد. نتیجه این رویکرد، عملکرد بهتر در وظایفی مانند تولید توضیح تصویر، بازیابی تصویر و متن و پرسش و پاسخ تصویری است.
نسخه بزرگ این مدل با استفاده از معماری ViT-L ساخته شده و قادر است توضیحهایی دقیق، روان و جزئینگر از تصاویر تولید کند؛ بهطوریکه توصیف نهایی هم از نظر معنایی درست و هم از نظر زبانی طبیعی باشد.
این مدل نیز در پلتفرم Hugging Face در دسترس است و یکی از گزینههای اصلی برای پروژههای مرتبط با درک و توصیف تصویر محسوب میشود.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import requests from PIL import Image from transformers import BlipProcessor, BlipForConditionalGeneration processor = BlipProcessor.from_pretrained(“Salesforce/blip-image-captioning-large”) model = BlipForConditionalGeneration.from_pretrained( “Salesforce/blip-image-captioning-large” ) img_url = “https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg” raw_image = Image.open(requests.get(img_url, stream=True).raw).convert(“RGB”) # conditional image captioning text = “a photography of” inputs = processor(raw_image, text, return_tensors=“pt”) out = model.generate(**inputs) print(processor.decode(out[0], skip_special_tokens=True)) # unconditional image captioning inputs = processor(raw_image, return_tensors=“pt”) out = model.generate(**inputs) print(processor.decode(out[0], skip_special_tokens=True)) |
GIT-Base
مدل GIT-Base نسخه پایه مدل GIT (Generative Image-to-Text) است که توسط مایکروسافت توسعه یافته است. این مدل نوعی ترنسفورمر از نوع decoder است که برای تولید توضیحات متنی از تصاویر آموزش دیده است.
GIT هم داده تصویری و هم داده متنی را بهصورت توکن دریافت میکند و بر اساس ترکیب هر دو، توکن بعدی متن را پیشبینی میکند. به همین دلیل، علاوه بر تولید کپشن برای تصاویر، برای وظایفی مانند تولید توضیح ویدیو هم قابل استفاده است.
مایکروسافت نسخههای آموزشدیده مختلفی از این مدل را نیز منتشر کرده؛ از جمله:
- git-base-coco که روی دیتاست COCO برای توصیف تصاویر تنظیم دقیق (Fine-tune) شده،
- git-base-textcaps که برای وظایف مبتنی بر توضیحات متنی گستردهتر آموزش دیده است.
نسخه پایه GIT-Base گزینهای مناسب برای توسعهدهندگانی است که میخواهند مدل را متناسب با دادهها یا نیازهای خاص خودشان سفارشیسازی کنند.
این مدل نیز در پلتفرم Hugging Face در دسترس است و میتوان از آن برای وظایف مرتبط با درک و تولید متن از تصاویر و ویدیوها بهره برد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from transformers import AutoProcessor, AutoModelForCausalLM import requests from PIL import Image processor = AutoProcessor.from_pretrained(“microsoft/git-base-coco”) model = AutoModelForCausalLM.from_pretrained(“microsoft/git-base-coco”) url = “http://images.cocodataset.org/val2017/000000039769.jpg” image = Image.open(requests.get(url, stream=True).raw) pixel_values = processor(images=image, return_tensors=“pt”).pixel_values generated_ids = model.generate(pixel_values=pixel_values, max_length=50) generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0] print(generated_caption) |
بازیابی تصویر و متن (Image–Text Retrieval)

در این وظیفه، هدف ایجاد ارتباط میان تصویر و متن است؛ به این معنا که بتوان از طریق متن به تصاویر مرتبط رسید، یا برعکس، از طریق تصویر به توضیحات متنی مرتبط دست یافت.
ورودیها:
- تصاویر: در قالبهای مختلف مانند JPEG یا PNG.
- متن: توصیف، کپشن یا عبارتهای طبیعی که با تصاویر مرتبط هستند.
خروجیها:
- در جستوجوی متنی (Text-to-Image): زمانی که کاربر متنی را وارد میکند، مدل فهرستی از تصاویر مرتبط را بر اساس میزان شباهت برمیگرداند.
- در جستوجوی تصویری (Image-to-Text): اگر ورودی تصویر باشد، مدل متنها یا کپشنهایی را برمیگرداند که بهترین توصیف از محتوای تصویر را ارائه میدهند.
انواع وظایف:
- Image-to-Text Retrieval: دریافت تصویر و یافتن توصیفات متنی مناسب برای آن.
- Text-to-Image Retrieval: دریافت متن و یافتن تصاویری که با محتوای توصیفشده در آن بیشترین تطابق را دارند.
مدلهای محبوب برای بازیابی تصویر و متن
مدل CLIP (Contrastive Language–Image Pretraining)
یکی از شناختهشدهترین مدلها در حوزه بازیابی تصویر و متن، مدل CLIP است که توسط OpenAI توسعه یافته است.
CLIP با استفاده از روش «یادگیری متقابل» (Contrastive Learning) آموزش دیده و میتواند متن و تصویر را در یک فضای معنایی مشترک (shared embedding space) نگاشت کند.
در این فضا، فاصله بین بردار تصویر و بردار متن نشاندهنده میزان شباهت معنایی آنهاست.
در مرحله آموزش، CLIP روی حجم عظیمی از دادههای متنی و تصویری تمرین میبیند و یاد میگیرد که مفاهیم را بدون نیاز به تنظیم دقیق (Fine-tuning) خاص، بهدرستی درک و مقایسه کند.
به همین دلیل، CLIP در طیف وسیعی از کاربردها از جمله:
- جستوجوی مبتنی بر محتوا (Content-based Image Retrieval)،
- پاسخ به پرسشهای متنی دربارهی تصاویر،
- و حتی فیلتر کردن دادههای تصویری بر اساس توضیحات زبانی،
کاربرد دارد.
در پلتفرم Hugging Face نیز مدل CLIP بهراحتی برای وظایف مرتبط با بازیابی تصویر و متن قابل استفاده است.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from PIL import Image import requests from transformers import CLIPProcessor, CLIPModel model = CLIPModel.from_pretrained(“openai/clip-vit-base-patch32”) processor = CLIPProcessor.from_pretrained(“openai/clip-vit-base-patch32”) url = “http://images.cocodataset.org/val2017/000000039769.jpg” image = Image.open(requests.get(url, stream=True).raw) inputs = processor( text=[“a photo of a cat”, “a photo of a dog”], images=image, return_tensors=“pt”, padding=True, ) outputs = model(**inputs) logits_per_image = outputs.logits_per_image # this is the image-text similarity score probs = logits_per_image.softmax( dim=1 ) # we can take the softmax to get the label probabilities |
تطبیق زبانی و تصویری (Visual Grounding)

در این وظیفه، مدل باید بتواند ارتباط میان زبان و تصویر را بهدرستی تشخیص دهد — یعنی بفهمد هر بخش از جمله یا عبارت متنی به کدام قسمت از تصویر اشاره دارد.
ورودیها:
- تصویر: نمایی بصری از یک صحنه یا شیء.
- عبارت یا پرسش متنی: جملهای طبیعی که به شیء یا ناحیهای خاص در تصویر اشاره دارد (برای مثال: «گربه سفید روی مبل کجاست؟»).
خروجی:
- جعبهی محدودکننده (Bounding Box) یا ماسک ناحیه (Segmentation Mask): بخشی از تصویر که با توصیف متنی مطابقت دارد. معمولا این خروجی با مختصات ناحیه یا هایلایت شدن بخش مربوطه نمایش داده میشود.
وظیفه:
- مدل باید شی یا ناحیهای از تصویر را که با عبارت متنی مرتبط است پیدا کند. این کار نیازمند درک همزمان محتوای بصری و معنای زبانی است تا بتواند بین توصیف و عناصر موجود در تصویر ارتباط دقیق برقرار کند.
مدلهای محبوب تطبیق زبانی و تصویری
مدل OWL-ViT
OWL-ViT (Vision Transformer for Open-World Localization) یکی از مدلهای قدرتمند تشخیص و تطبیق شیء است که بر پایه معماری Vision Transformer ساخته شده و روی مجموعهدادههای بزرگ تصویر–متن آموزش دیده است.
ویژگی برجسته OWL-ViT توانایی آن در تشخیص واژگان باز (Open-Vocabulary Detection) است؛ یعنی میتواند اشیایی را شناسایی کند که هرگز در دادههای آموزشیاش وجود نداشتهاند، فقط بر اساس توضیح متنی.
این مدل با ترکیب یادگیری متقابل (Contrastive Pre-training) و تنظیم دقیق (Fine-tuning)، در وظایفی مانند تشخیص بدون نمونه قبلی (Zero-Shot) و با تنها یک نمونه (One-Shot) عملکرد بسیار خوبی دارد.
در نتیجه، OWL-ViT ابزاری چندمنظوره و انعطافپذیر برای جستوجو و شناسایی اشیا در تصاویر است و در پلتفرم Hugging Face هم قابل استفاده است.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import requests from PIL import Image import torch from transformers import OwlViTProcessor, OwlViTForObjectDetection processor = OwlViTProcessor.from_pretrained(“google/owlvit-base-patch32”) model = OwlViTForObjectDetection.from_pretrained(“google/owlvit-base-patch32”) url = “http://images.cocodataset.org/val2017/000000039769.jpg” image = Image.open(requests.get(url, stream=True).raw) texts = [[“a photo of a cat”, “a photo of a dog”]] inputs = processor(text=texts, images=image, return_tensors=“pt”) outputs = model(**inputs) # Target image sizes (height, width) to rescale box predictions [batch_size, 2] target_sizes = torch.Tensor([image.size[::–1]]) # Convert outputs (bounding boxes and class logits) to COCO API results = processor.post_process_object_detection( outputs=outputs, threshold=0.1, target_sizes=target_sizes ) i = 0 # Retrieve predictions for the first image for the corresponding text queries text = texts[i] boxes, scores, labels = results[i][“boxes”], results[i][“scores”], results[i][“labels”] # Print detected objects and rescaled box coordinates for box, score, label in zip(boxes, scores, labels): box = [round(i, 2) for i in box.tolist()] print( f“Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}” ) |
Grounding DINO
مدل Grounding DINO ترکیبی از یک آشکارساز شیء مبتنی بر ترنسفورمر (DINO) و رویکردی به نام پیشآموزش مبتنی بر تطبیق زبانی (Grounded Pre-training) است. نتیجه این ترکیب، یکی از پیشرفتهترین مدلهای تشخیص شیء بدون داده نمونه (Zero-Shot Object Detection) محسوب میشود.
این مدل میتواند اشیایی را شناسایی کند که هرگز در دادههای آموزشیاش وجود نداشتهاند، چون علاوه بر تصویر، زبان انسان مثل نام دستهبندیها یا توصیف متنی اشیا را هم میفهمد.
معماری Grounding DINO از اجزای کلیدی زیر تشکیل شده است:
- شبکه متنی و تصویری (Text & Image Backbone) برای استخراج ویژگیهای هر دو نوع داده،
- بخش تقویت ویژگیها (Feature Enhancer) برای بهبود نمایشهای بصری،
- بخش انتخاب پرسش بر پایه زبان (Language-Guided Query Selection) که تعیین میکند مدل باید دنبال چه چیزی در تصویر بگردد،
- و رمزگشای چندوجهی (Cross-Modality Decoder) که ارتباط بین دادههای متنی و تصویری را برقرار میکند.
به کمک این معماری، Grounding DINO قادر است ارتباط میان تصویر و توصیفهای زبانی را بهخوبی درک کند و بر اساس آن، اشیاء را حتی در دستههای کاملا جدید شناسایی کند.
این مدل در آزمونهای استانداردی مانند COCO و LVIS عملکرد بسیار چشمگیری داشته و یکی از قویترین گزینهها برای وظایف تشخیص شیء و تطبیق زبان–تصویر به شمار میرود.
تولید تصویر از متن (Text-to-Image Generation)
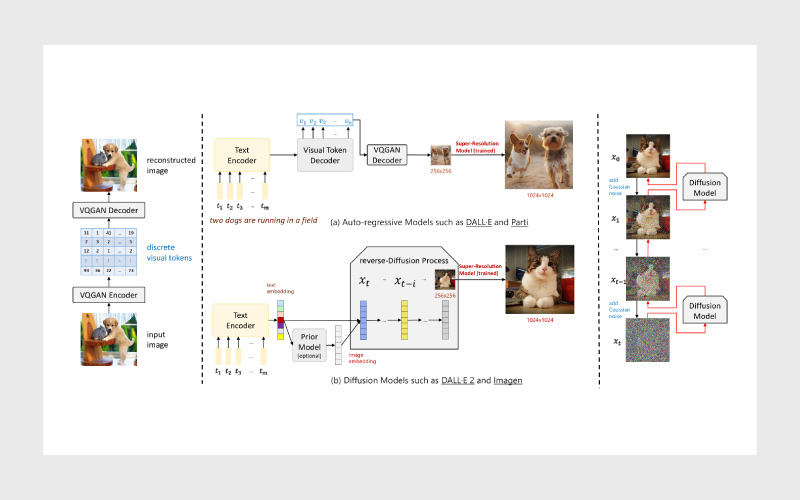
در این بخش به دو رویکرد اصلی برای تولید تصویر از متن میپردازیم: مدلهای خودبازگشتی (Auto-Regressive) و مدلهای انتشار (Diffusion Models). هر دو روش با هدف تبدیل توضیحات متنی به تصاویر واقعی یا خلاقانه طراحی شدهاند اما مسیر و سازوکار متفاوتی دارند.
مدلهای خودبازگشتی (Auto-Regressive Models)
در این روش، مدل فرایند تولید تصویر را مانند ترجمهی متن در نظر میگیرد یعنی جمله توصیفی (prompt) را به دنبالهای از «توکنهای تصویری» تبدیل میکند.
این توکنها که توسط مدلهایی مثل VQ-VAE ساخته میشوند، اجزای پایه تصویر را نشان میدهند؛ چیزی شبیه تکههای پازل.
مدل از معماری encoder-decoder استفاده میکند:
- Encoder اطلاعات معنایی را از متن استخراج میکند،
- Decoder با هدایت همین اطلاعات، توکنهای تصویری را یکییکی پیشبینی کرده و در نهایت تصویر را پیکسلبهپیکسل میسازد.
مزیت اصلی این روش، کنترل بالا و جزئیات دقیق تصویر است. اما در عین حال، پردازش آن برای توضیحات طولانی یا پیچیده دشوارتر است و معمولا سرعت تولید پایینتری نسبت به مدلهای انتشار دارد.
(فرایند این نوع تولید در شکل بخش (a) نشان داده شده است.)
مدلهای انتشار پایدار (Stable Diffusion Models)
مدلهای انتشار پایدار بر پایهی تکنیکی به نام Latent Diffusion عمل میکنند. در این رویکرد، مدل از نویز تصادفی شروع میکند و بهصورت تدریجی آن را حذف میکند تا تصویر نهایی شکل بگیرد؛ تمام این فرایند تحت هدایت یک توضیح متنی انجام میشود.
در این مدل، رمزگذار متنی CLIP و معماری سبکوزن UNet نقش کلیدی دارند:
- CLIP متن را تفسیر میکند و به مدل میگوید «چه چیزی باید کشیده شود»،
- UNet تصویر را گامبهگام از دل نویز بیرون میکشد.
تمرکز محاسبات در فضای نهفته (latent space) باعث میشود حافظه کمتری مصرف شود و تولید تصویر سریعتر انجام گیرد.
نتیجه این ترکیب، سیستمی قدرتمند و خلاق است که میتواند ورودیهای متنی را به تصاویر واقعگرایانه، هنری و تخیلی تبدیل کند.
(فرایند این نوع تولید در شکل بخش (b) نشان داده شده است.)
در ادامه، نحوه استفاده از مدلهای تولید تصویر از متن در Hugging Face توضیح داده میشود.
اولین گام، نصب کتابخانه diffusers است:
|
1 |
pip install diffusers —upgrade |
علاوهبر این، مطمئن شوید که کتابخانههای transformers، safetensors، accelerate و همچنین invisible-watermark را نیز نصب کردهاید.
|
1 |
pip install invisible_watermark transformers accelerate safetensors |
برای استفاده از مدل پایه، میتوانید دستور زیر را اجرا کنید:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from diffusers import DiffusionPipeline import torch pipe = DiffusionPipeline.from_pretrained( “stabilityai/stable-diffusion-xl-base-1.0”, torch_dtype=torch.float16, use_safetensors=True, variant=“fp16”, ) pipe.to(“cuda”) prompt = “An astronaut riding a unicorn” images = pipe(prompt=prompt).images[0] |
اکنون با مهمترین وظایف و مدلهای مرتبط با ترکیب متن و تصویر آشنا شدید.
اما شاید این سوال برایتان پیش آمده باشد که چطور میتوان چنین مدلهایی را آموزش داد یا برای وظایف خاص، تنظیم (Fine-tune) کرد؟
در ادامه، نگاهی کوتاه خواهیم داشت به فرایند آموزش مدلهای بینایی–زبانی (Vision-Language Models).
نگاهی کوتاه به مدلهای ازپیشآموزشدیدهی بینایی–زبانی
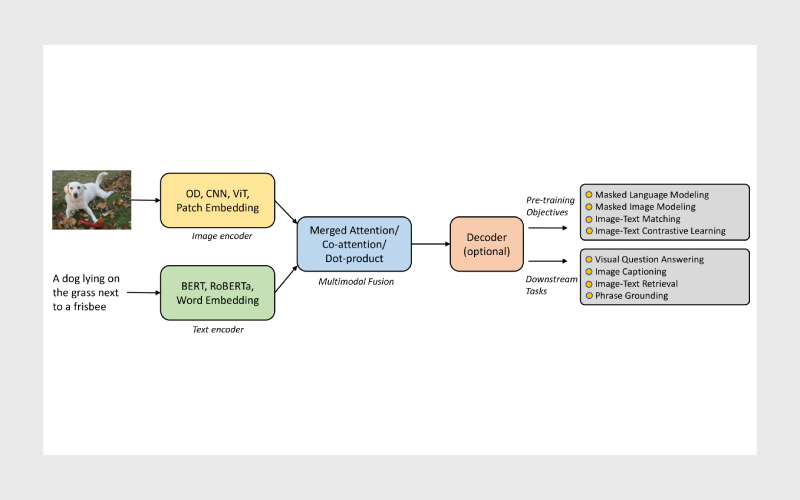
در یک جفت دادهی تصویر و متن، مدل بینایی–زبانی ابتدا ویژگیهای متنی را با استفاده از رمزگذار متنی (Text Encoder) و ویژگیهای تصویری را با رمزگذار تصویری (Vision Encoder) استخراج میکند.
سپس این دو نوع ویژگی وارد ماژول ادغام چندوجهی (Multimodal Fusion Module) میشوند تا نمایش مشترکی از هر دو مدالیته تولید شود.
در برخی مدلها، این نمایش چندوجهی پیش از تولید خروجی نهایی وارد رمزگشا (Decoder) نیز میشود تا متن یا پاسخ نهایی تولید شود.
در شکل بالا، ساختار کلی این چارچوب نمایش داده شده است.
در عمل، مرز روشنی میان اجزای مختلف یعنی رمزگذارهای تصویر و متن، ماژول ادغام و رمزگشا وجود ندارد و بسیاری از مدلها این بخشها را بهصورت درهمتنیده و یکپارچه پیادهسازی میکنند.
منابع
سوالات متداول
ترکیب متن و تصویر (و گاهی صوت/حسگرها) را برای درک بهتر محتوا ممکن میکند؛ نتیجهاش دقت بیشتر در پاسخگویی، جستوجو، توصیف و استدلال روی دادههای واقعی است.
VQA معمولا پاسخ به یک سوال مشخص دربارهی تصویر است؛ استدلال تصویری علاوه بر پاسخ، روابط، قیاسها و منطق صحنه را هم در نظر میگیرد.
بسته به نیاز: BLIP برای کیفیت پاسخهای عمومی قوی است؛ ViLT برای سرعت و سادگی معماری گزینهی خوبی است؛ DePlot برای نمودار و شکلها تخصصیتر عمل میکند.
CLIP بهدلیل فضای برداری مشترک متن–تصویر و آموزش گسترده، استاندارد عملی خوبی برای Text-to-Image و Image-to-Text Retrieval است.

دیدگاهتان را بنویسید