
در سالهای اخیر، پردازش تصویر به یکی از بنیادیترین شاخههای هوش مصنوعی و یادگیری ماشین تبدیل شده است. از خودروهای خودران گرفته تا سامانههای تشخیص بیماری در تصاویر پزشکی و سیستمهای امنیتی مبتنی بر دوربین، همه و همه به درک دقیق محتواهای بصری وابستهاند. توانایی ماشین در «دیدن» و «فهمیدن» تصاویر، حاصل فرایندهای پیچیدهای است که دادههای خام پیکسلی را به معنا و مفهوم قابل درک تبدیل میکنند. در این میان، شناسایی، تشخیص و بخشبندی اشیا سه وظیفهی کلیدی و بهظاهر مشابه هستند که هرکدام هدف و سطح دقت خاص خود را دارند.
درک تفاوت میان این سه مفهوم برای توسعهدهندگان، پژوهشگران و فعالان حوزه بینایی ماشین حیاتی است؛ چراکه انتخاب نادرست هر یک میتواند باعث افزایش هزینه، کاهش دقت مدل یا پیچیدگی غیرضروری پروژه شود. در این مقاله، ابتدا هرکدام از این سه فرایند را از نظر عملکرد، کاربرد و نقش یادگیری ماشین و یادگیری عمیق بررسی میکنیم و سپس به مقایسهی آنها و روندهای نوین در حوزهی بینایی ماشین خواهیم پرداخت.
شناسایی اشیا (Object Recognition)
شناسایی اشیا یکی از بنیادیترین مراحل در بینایی ماشین است که هدف آن، تشخیص نوع شی در تصویر بدون نیاز به مشخص کردن مکان آن است. در واقع، مدل تنها به این پرسش پاسخ میدهد که «چه چیزی در تصویر وجود دارد؟» نه «کجا قرار دارد؟». برای مثال، اگر تصویری از یک گربه به مدل داده شود، خروجی صرفا شامل برچسب «گربه» خواهد بود، بدون اشاره به محل حضور آن در تصویر. این روش بهویژه در کاربردهایی مانند دستهبندی تصاویر، فیلتر محتوای خودکار، جستجوی تصویری و سیستمهای تشخیص کیفیت بصری کاربرد دارد.
در گذشته، الگوریتمهای یادگیری ماشین کلاسیک مانند SVM (ماشین بردار پشتیبان)، k-NN و Random Forest برای این کار بهکار میرفتند. این الگوریتمها ابتدا ویژگیهای دستی (Handcrafted Features) مانند SIFT یا HOG را از تصویر استخراج کرده و سپس آنها را برای طبقهبندی به مدل یادگیری ماشین میدادند. اما با گسترش یادگیری عمیق، این رویکرد سنتی جای خود را به شبکههای عصبی کانولوشنی (CNN) داد که میتوانند ویژگیها را بهصورت خودکار و چندلایه از دادههای تصویری بیاموزند. مدلهایی مانند AlexNet، VGGNet، ResNet و EfficientNet توانستند دقت شناسایی را بهطرز چشمگیری افزایش دهند و نقطهعطفی در تاریخ بینایی ماشین رقم بزنند.
یکی از مزیتهای اصلی شناسایی اشیاء، سادگی نسبی و سرعت بالای آن در مقایسه با سایر روشهاست. با این حال، محدودیت بزرگ آن در ناتوانی برای تشخیص مکان دقیق اشیا نهفته است. این ضعف، زمانی خود را نشان میدهد که در یک تصویر چندین شی وجود داشته باشد یا زمینه (background) پیچیده باشد. به همین دلیل، در پروژههایی که نیاز به تشخیص چند شی یا موقعیت آنها وجود دارد، از مرحلهی پیشرفتهتری به نام تشخیص اشیا استفاده میشود.
تشخیص اشیا (Object Detection)
تشخیص اشیا گام بعدی و پیشرفتهتر از شناسایی است. در این مرحله، مدل نهتنها نوع شی را شناسایی میکند، بلکه موقعیت دقیق آن را نیز در تصویر مشخص میسازد. این موقعیت معمولا با استفاده از جعبههای محدودکننده (Bounding Boxes) نمایش داده میشود که پیرامون هر شی ترسیم میشوند. به بیان سادهتر، اگر شناسایی اشیا به پرسش «چه چیزی در تصویر است؟» پاسخ دهد، تشخیص اشیا به سوال «چه چیزی در تصویر است و کجا قرار دارد؟» پاسخ میدهد.
در نخستین نسل از مدلهای تشخیص اشیا، الگوریتمها بر پایهی استخراج ویژگیهای دستی و طبقهبندیهای ساده بنا شده بودند، اما دقت و کارایی پایین آنها باعث شد با ظهور یادگیری عمیق، معماریهای مدرنتر شکل بگیرند. یکی از اولین تحولات بزرگ در این حوزه، معرفی R-CNN (Regions with CNN features) توسط «روس گيرشک» در سال ۲۰۱۴ بود. این مدل با ترکیب شبکههای عصبی کانولوشنی با نواحی پیشنهادی (Region Proposals) توانست دقت بالایی در تشخیص ارائه دهد. پس از آن نسخههای بهینهتری همچون Fast R-CNN و Faster R-CNN معرفی شدند که سرعت و کارایی را به میزان قابل توجهی افزایش دادند.
در ادامه، معماریهایی مانند YOLO (You Only Look Once) و SSD (Single Shot MultiBox Detector) بهعنوان نسل سریعتر و بلادرنگ (Real-time) تشخیص اشیا مطرح شدند. این مدلها با پردازش کل تصویر در یک مرحله (بهجای چندین ناحیه مجزا) توانستند تعادلی میان دقت و سرعت برقرار کنند. به همین دلیل، امروزه در کاربردهایی مانند نظارت شهری، خودروهای خودران، شمارش افراد در فضاهای عمومی و تحلیل ویدیوهای امنیتی، مدلهای YOLO و SSD بسیار رایج هستند.
یادگیری عمیق در این حوزه نقش محوری دارد؛ زیرا شبکههای عصبی عمیق قابلیت استخراج ویژگیهای چندسطحی و تمایز دقیق میان اشیا را فراهم میکنند. با این حال، چالشهایی همچنان باقی است—از جمله نیاز به دادههای برچسبخوردهی حجیم، زمان آموزش طولانی، و کاهش دقت در مواجهه با اشیا کوچک یا همپوشان. به همین دلیل، در پروژههایی که نیاز به تفکیک دقیقتر و مرزهای واضح بین اشیا وجود دارد، گام بعدی یعنی بخشبندی تصویر بهکار گرفته میشود.

بخشبندی تصویر (Image Segmentation)

بخشبندی تصویر پیشرفتهترین مرحله در درک محتوای بصری است؛ مرحلهای که ماشین نهتنها تشخیص میدهد چه اشیایی در تصویر وجود دارند و کجا قرار گرفتهاند، بلکه هر پیکسل از تصویر را بهصورت دقیق به یک کلاس یا شی خاص نسبت میدهد. در واقع، اگر تشخیص اشیا تصویری کلی از موقعیت اشیا ارائه دهد، بخشبندی تصویر آن را به نقشهای پیکسلی و دقیق از هر جزء تبدیل میکند.
بخشبندی معمولا در دو سطح انجام میشود:
۱. بخشبندی معنایی (Semantic Segmentation): در این روش، هر پیکسل از تصویر به یک کلاس معنایی اختصاص داده میشود، مثلا همهی پیکسلهای مربوط به «آسمان» یا «جاده» به یک گروه تعلق دارند.
۲. بخشبندی نمونهای (Instance Segmentation): در این نوع، مدل علاوهبر تشخیص کلاس، نمونههای مختلف از همان کلاس را نیز تفکیک میکند؛ مثلا در یک تصویر گروهی، هر فرد بهصورت مجزا شناسایی میشود.
در گذشته، روشهای کلاسیک مانند Watershed، K-means Clustering و Graph Cuts برای بخشبندی تصویر استفاده میشدند، اما دقت پایین و ناتوانی آنها در درک معنای عمیق تصویر باعث شد یادگیری عمیق به سرعت جایگزین آنها شود. مدلهای مبتنی بر شبکههای عصبی کانولوشنی، بهویژه U-Net و Fully Convolutional Networks (FCN)، انقلابی در بخشبندی تصاویر به وجود آوردند. U-Net در ابتدا برای تصاویر پزشکی طراحی شده بود و بهدلیل ساختار متقارن «encoder–decoder» خود، توانست دقت پیکسلی بسیار بالایی را با دادههای محدود فراهم کند.
مدلهای پیشرفتهتری مانند Mask R-CNN، بخشبندی نمونهای را به مرحلهی جدیدی رساندند. این مدل با افزودن یک شاخهی خروجی برای پیشبینی ماسک هر شی، توانست همزمان عملیات تشخیص و بخشبندی را انجام دهد. امروزه، رویکردهای جدیدتر مبتنی بر یادگیری عمیق و ترنسفورمرها (Transformers) مانند SegFormer و Segment Anything (SAM) از Meta، توانایی مدلها را در تعمیم به دادههای جدید و صحنههای پیچیده بهطور چشمگیری افزایش دادهاند.
کاربردهای بخشبندی تصویر بسیار گستردهاند؛ از تحلیل تصاویر پزشکی (برای شناسایی سلولها، تومورها یا اندامها) گرفته تا نقشهبرداری شهری، کشاورزی دقیق، خودروهای خودران و واقعیت افزوده. با این حال، اجرای موفق این مدلها مستلزم منابع محاسباتی سنگین، دادههای برچسبخوردهی دقیق و تنظیمات ظریف برای جلوگیری از بیشبرازش (Overfitting) است.
بهطور خلاصه، بخشبندی تصویر دقیقترین اما پیچیدهترین گام در درک محتوای تصویری است؛ روشی که نهتنها به تشخیص اشیا کمک میکند، بلکه به ماشین امکان میدهد «دنیای بصری» را در سطح پیکسلها درک کند.
مقایسه سه روش
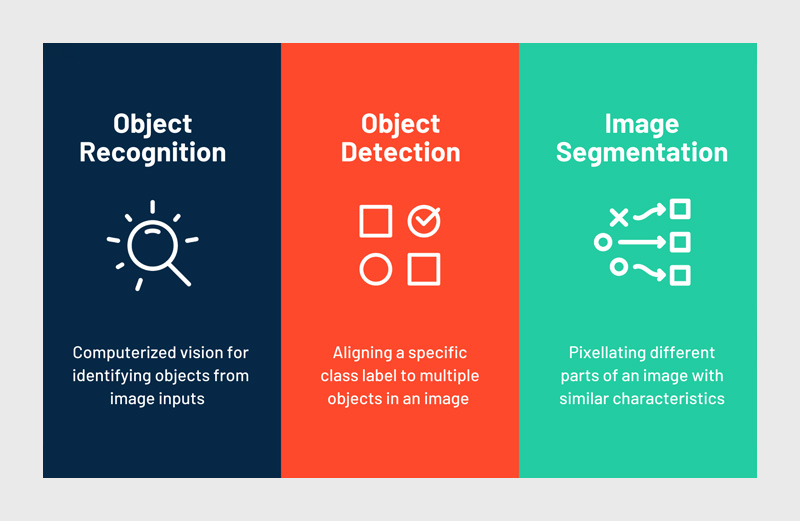
برای درک بهتر تفاوتهای شناسایی، تشخیص و بخشبندی اشیا، جدول زیر مقایسهای خلاصه و کاربردی ارائه میدهد:
| ویژگیها | شناسایی اشیا | تشخیص اشیا | بخشبندی تصویر |
| هدف اصلی | شناسایی نوع شی | شناسایی و مکانیابی | تفکیک دقیق نواحی تصویر به سطح پیکسل |
| خروجی | برچسب کلاس | برچسب + موقعیت (Bounding Box) | نقشه پیکسلی یا ناحیهبندی دقیق |
| دقت مکانی | پایین | متوسط | بالا |
| پیچیدگی محاسباتی | کم | متوسط | زیاد |
| نقش یادگیری ماشین/عمیق | ML سنتی و CNN برای استخراج ویژگیها | CNN و معماریهای پیچیده مانند R-CNN، YOLO | CNN و شبکههای Encoder–Decoder، Mask R-CNN، Transformers |
| کاربردها | دستهبندی تصاویر، جستجوی تصویر، فیلتر محتوا | نظارت ویدئویی، خودروهای خودران، شمارش افراد | پزشکی، کشاورزی دقیق، واقعیت افزوده، خودروهای خودران |
۱. شناسایی اشیا: سادهترین و سریعترین روش است که تنها به برچسب کلاس اهمیت میدهد و برای کاربردهایی که موقعیت دقیق شی اهمیت ندارد، مناسب است. نقش یادگیری عمیق در آن، استخراج ویژگیهای پیچیده از تصاویر و افزایش دقت طبقهبندی است.
۲. تشخیص اشیا: مرحلهای پیشرفتهتر که علاوه بر شناسایی نوع شی، موقعیت آن را نیز مشخص میکند. مدلهای مبتنی بر یادگیری عمیق، با توانایی استخراج ویژگیهای چندسطحی و تشخیص همزمان چند شی، باعث شدهاند که این مرحله کاربردی و قابل اعتماد باشد.
۳. بخشبندی تصویر: دقیقترین و پیچیدهترین روش است که هر پیکسل تصویر را به کلاس مربوطه اختصاص میدهد. یادگیری عمیق و شبکههای پیشرفته نقش حیاتی در دقت و توانایی مدل در تعمیم به تصاویر جدید دارند. این روش برای کاربردهایی که دقت پیکسلی بالا ضروری است، مانند پزشکی و خودروهای خودران، انتخاب مناسبی است.
انتخاب روش مناسب
انتخاب میان شناسایی، تشخیص و بخشبندی تصویر بستگی مستقیم به هدف پروژه و نیاز به دقت دارد:
- زمانی که فقط نوع شی اهمیت دارد: شناسایی اشیا کافی است و اجرای سریع و کمهزینهای ارائه میدهد. برای مثال، دستهبندی تصاویر موجود در یک گالری یا فیلتر محتوای خودکار.
- زمانی که علاوه بر نوع شی، موقعیت آن نیز اهمیت دارد: تشخیص اشیا گزینه مناسب است. این روش برای کاربردهایی مانند نظارت شهری، شمارش افراد یا شناسایی خودروها در تصاویر و ویدیوها بهخوبی جوابگو است.
- زمانی که دقت پیکسلی و تفکیک دقیق ضروری است: بخشبندی تصویر بهترین انتخاب است. کاربردهای پزشکی، کشاورزی دقیق، واقعیت افزوده و خودروهای خودران از این روش بهره میبرند.
در پروژههای پیشرفته، ترکیب این روشها نیز رایج است. برای نمونه، Mask R-CNN همزمان عملیات تشخیص و بخشبندی را انجام میدهد، که باعث کاهش پیچیدگی توسعه و افزایش کارایی در پروژههای صنعتی میشود.
نکات مهم در انتخاب روش:
۱. حجم و کیفیت دادههای برچسبخورده
۲. منابع محاسباتی در دسترس
۳. نیاز به دقت مکانی یا پیکسلی
۴. محدودیت زمانی پردازش و سرعت اجرا
روندهای نوین و آینده پردازش تصویر
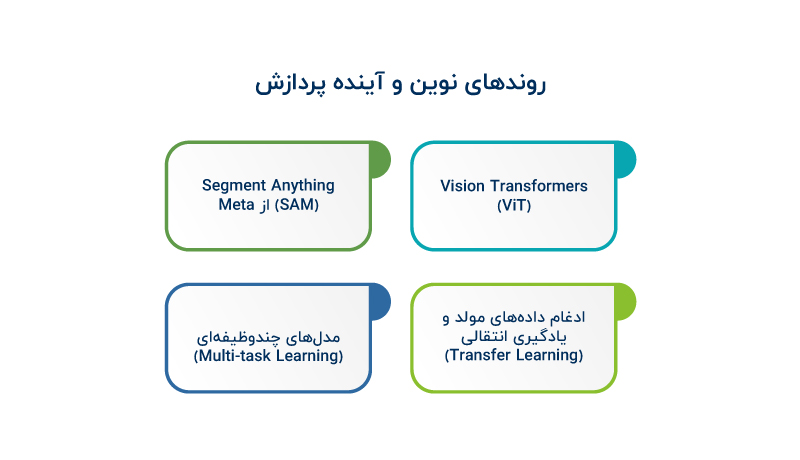
روندهای نوظهور در بینایی ماشین با تمرکز بر یادگیری عمیق و مدلهای چندوظیفهای، آینده این حوزه را شکل میدهند:
- Vision Transformers (ViT):
استفاده از ترنسفورمرها در پردازش تصویر امکان یادگیری وابستگیهای طولانیمدت در تصاویر را فراهم کرده و دقت مدلها را در شناسایی و بخشبندی افزایش داده است.
- Segment Anything (SAM) از Meta:
این مدلها قابلیت بخشبندی اشیا در تصاویر و ویدیوها را بدون نیاز به دادههای برچسبخوردهی فراوان ارائه میدهند و امکان تعمیم به صحنههای جدید را بهبود میبخشند.
- ادغام دادههای مولد و یادگیری انتقالی (Transfer Learning):
استفاده از مدلهای پیشآموزشدیده و دادههای مصنوعی، امکان تقویت دقت و کاهش نیاز به دادههای واقعی حجیم را فراهم کرده است.
- مدلهای چندوظیفهای (Multi-task Learning):
ترکیب شناسایی، تشخیص و بخشبندی در یک مدل واحد، کارایی و سرعت توسعه را بهبود میبخشد و هزینه محاسباتی را کاهش میدهد.
جمعبندی
شناسایی، تشخیص و بخشبندی اشیا مراحل کلیدی پردازش تصویر هستند که به ترتیب برای تعیین نوع شیء، موقعیت آن و تحلیل دقیق پیکسلی کاربرد دارند. یادگیری ماشین و یادگیری عمیق، بهویژه مدلهای CNN و پیشرفتهای مانند R-CNN، YOLO و U-Net، دقت مدلها را افزایش میدهند و روندهای نوین مانند Vision Transformers و SAM امکان توسعه مدلهای سریعتر و قابل تعمیم را فراهم کردهاند.
منابع
سوالات متداول
شناسایی: تعیین نوع شی
تشخیص: تعیین نوع و موقعیت شی
بخشبندی: تحلیل پیکسلی و تفکیک نمونهها
مدلهایی مانند YOLO و SSD برای کاربردهای بلادرنگ و صنعتی مناسب هستند.
علاوه بر شناسایی کلاسها، نمونههای مختلف از همان کلاس را تفکیک میکند، مانند شناسایی هر فرد در یک گروه.




دیدگاهتان را بنویسید