
آیا میدانستید که دادهها مانند طلا در دنیای امروز ارزشمند هستند؟ هر کاربر در فضای دیجیتال، ردپای منحصربهفردی از خود به جا میگذارد. تحلیل این ردپاها میتواند به شرکتها کمک کند تا رفتار کاربران را بفهمند و حتی رفتارهای آیندهشان را پیشبینی کنند. دادهها همچنین در بهبود فرایندها و تصمیمگیریهای داخلی شرکتها نقش کلیدی دارند. اما تحلیل این دادهها نیازمند مهارتی به نام داده کاوی (Data Mining) است.
از تحلیل رفتار مشتریان گرفته تا بهبود فرایندهای سازمانی، دادهکاوی ابزاری کلیدی در دنیای دیجیتال است. اما دادهکاوی دقیقا چیست؟ چه مراحلی دارد و چگونه میتواند دنیای امروز ما را متحول کند؟ در این مقاله قصد داریم به زبانی ساده به این سوالات پاسخ دهیم و اهمیت این مهارت را برای کسبوکارها بررسی کنیم.
داده کاوی یا دیتا ماینینگ چیست؟
دیتا ماینینگ فرایندی است که شرکتها از آن برای تبدیل دادههای خام به اطلاعات مفید استفاده میکنند. طی این فرایند کسبوکارها با استفاده از نرمافزارها، الگوهای موجود در دستههای بزرگ دادهها را پیدا میکنند و از این طریق، درباره مشتریان خود اطلاعات بیشتری به دست میآورند. آنها با داشتن این اطلاعات میتوانند استراتژیهای بازاریابی موثرتری را توسعه دهند، فروششان را افزایش و هزینههایشان را کاهش دهند.

به عبارت دیگر Data Mining، بخش کلیدی تجزیه و تحلیل داده و یکی از رشتههای اصلی در علم داده است که از تکنیکهای تجزیه و تحلیل پیشرفته برای یافتن اطلاعات مفید در مجموعه دادهها استفاده میکند. ناگفته نماند که میزان تاثیرگذاری داده کاوی به جمعآوری موثر دادهها، ذخیرهسازی و پردازش کامپیوتری آنها بستگی دارد.
تفاوت بین داده (Data) و اطلاعات (Information)
قبل از اینکه به سراغ موضوع اصلی برویم، نیاز است که اول درباره داده و اطلاعات حرف بزنیم و ببینیم چه تفاوتی با هم دارند. بهطور خلاصه، دادهها (Data) مجموعهای از حقایق خام هستند که بهخودیخود معنی خاصی ندارند. اینها میتوانند شامل اعداد، کلمات، اندازهگیریها، مشاهدات یا حتی تصاویر باشند. نکته مهم این است که دادهها بهتنهایی اغلب ناقص، بدون زمینه و بدون تفسیر هستند.
بهعنوان مثال، اعداد ۱۰، ۲۰، ۳۰ بدون هیچ زمینهای یک مجموعه داده هستند.
در مقابل اطلاعات (Information)، حاصل پردازش، سازماندهی یا تحلیل دادهها است که باعث میشود دادهها معنادار و مفید شوند، اغلب بهصورت پاسخ به یک سوال خاص یا بهمنظور رفع نیازی خاص ارائه میشوند و زمانی به وجود میآیند که دادهها در زمینهای قرار گیرند و با تفسیر همراه شوند.
بهعنوان مثال، اگر بگوییم که اعداد ۱۰، ۲۰، ۳۰ دمای هوا در سه روز متوالی است، این دادهها به اطلاعات تبدیل میشوند چرا که زمینه و معنا پیدا کردهاند.
بنابراین، دادهها مواد خامی هستند که از طریق تحلیل و پردازش به اطلاعات مفید تبدیل میشوند. این تبدیل از طریق افزودن زمینه، ساختار و معنا به دادهها انجام میشود.
تفاوت بین داده کاوی و علم داده در چیست؟
علم داده، از عباراتی است که در زمان صحبت از حوزه داده، در کنار دیتا ماینینگ قرار میگیرد. اما این دو حوزه تفاوتهایی دارند که در ادامه به آنها اشاره میکنیم. بهطور خلاصه تفاوت بین دادهکاوی (Data Mining) و علم داده (Data Science) در ماهیت و دامنه کاربردهای آنها قرار دارد. هرچند که این دو حوزه اغلب به هم مرتبط هستند و از ابزارها و روشهای مشابهی استفاده میکنند، اما اهداف و تمرکز آنها متفاوت است.
داده کاوی (Data Mining)، به فرایند استخراج الگوها و دانش از مجموعههای بزرگ داده میپردازد و هدف آن کشف روابط، الگوها و دانش نهفته در دادهها است. این حوزه بیشتر بر تکنیکهای خاص تحلیلی مانند خوشهبندی، تجزیه و تحلیل انجمنی و رگرسیون تمرکز دارد و بخشی از فرایند علم داده است؛ اما تنها بخشی از کل داستان و نه همه آن.
در مقابل علم داده (Data Science)، یک حوزه گستردهتر است که شامل جمعآوری، پاکسازی، تحلیل و تفسیر دادهها میشود و علاوهبر داده کاوی، به پیشپردازش داده، آمار، یادگیری ماشین، و تحلیل پیشبینیکننده هم میپردازد. هدف علم داده ایجاد بینش و تصمیمگیریهای دادهمحور است که میتواند برای حل مسائل کسبوکاری، علمی و اجتماعی به کار گرفته شود.
بنابراین، در حالی که داده کاوی بر استخراج دانش و الگوها از دادهها تمرکز دارد، علم داده یک حوزه جامعتر است که شامل استخراج داده و دیگر جنبههای تحلیل داده هم میشود.
تفاوت داده کاوی و تحلیل داده چیست؟
تفاوت دادهکاوی و تحلیل داده به هدف و نوع استفاده از دادهها برمیگردد. دادهکاوی فرایندی اکتشافی است که به کشف الگوها، روابط و اطلاعات پنهان در دادههای بزرگ و پیچیده میپردازد. هدف اصلی آن پیدا کردن دانش جدید و پیشبینی رویدادها یا رفتارها با استفاده از الگوریتمهای پیشرفته مانند یادگیری ماشین و خوشهبندی است. برای مثال، یک کسبوکار میتواند با دادهکاوی پیشبینی کند که کدام مشتریان احتمالاً اشتراک خود را لغو میکنند.
از سوی دیگر، تحلیل داده (Data Analysis) بیشتر بر درک، بررسی و تفسیر دادههای موجود تمرکز دارد. این فرایند اغلب برای پاسخ به سوالات مشخص و پشتیبانی از تصمیمگیری انجام میشود. تحلیل داده از تکنیکهای آماری و بصریسازی برای استخراج اطلاعات معنادار و ایجاد گزارشهایی که بینشهای کاربردی ارائه میدهند، استفاده میکند. برای مثال، محاسبه میانگین فروش ماهانه برای بهبود استراتژی بازاریابی نمونهای از تحلیل داده است.
بهطور خلاصه، دادهکاوی بیشتر در جستجوی کشف الگوهای ناشناخته است، در حالی که تحلیل داده بر درک و توضیح دادههای موجود تمرکز دارد.
پیشنهاد مطالعه: لیست بهترین ابزارهای تحلیل داده و نرم افزار
آشنایی با مراحل داده کاوی
دیتا ماینینگ معمولا توسط دانشمندان داده و سایر متخصصان هوش تجاری (BI) و تحلیلگران داده انجام میشود. البته تحلیلگران کسبوکار، مدیران اجرایی و افرادی که در زمینه دیتاساینس یا علم داده کار میکنند هم میتوانند وظایف مربوط به Data Mining را انجام دهند. یادگیری ماشین و تحلیل آماری، عناصر اصلی داده کاوی هستند که به همراه تسکهای مدیریت داده برای آمادهسازی دادهها و بعد تحلیل آنها استفاده میشوند.

الگوریتمهای یادگیری ماشین و ابزارهای هوش تجاری و هوش مصنوعی (AI)، بیشتر فرایندهای دادهکاوی را خودکار کردهاند. با کمک این دو، استخراج مجموعه دادههای عظیم مانند پایگاههای اطلاعاتی مشتریان، سوابق تراکنشها و فایلهای گزارش از سرورهای وب، اپلیکیشنهای موبایل و حسگرها آسانتر از گذشته انجام میشوند.
۱. جمعآوری دادهها
در این مرحله دادههای مربوط به یک برنامه تحلیلی شناسایی و جمعآوری میشوند. دادهها ممکن است از سیستمها و منابع داده مختلف، انبارهای داده یا دریاچههای داده جمعآوری شوند. دریاچه داده (Data Lake) مخزن دادهای رایج در در محیطهای کلان داده است که ترکیبی از دادههای ساختاریافته و بدون ساختار را شامل میشود. همچنین در این مرحله ممکن است از منابع داده خارجی هم استفاده شود.
دادهها از هر کجا که بیایند، اغلب یک دانشمند داده آنها را برای باقی مراحل در فرایند، به دریاچه داده منتقل میکند.
۲. آمادهسازی دادهها
این مرحله شامل مجموعهای از گامها بهمنظور آمادهسازی دادهها برای استخراج است. این کار با کاوش، پروفایلسازی و پیشپردازش دادهها آغاز میشود و بعد با تمیز کردن یا پاکسازی دادهها برای رفع خطاها و سایر مشکلات کیفیت داده، ادامه پیدا میکند.
در این مرحله همچنین برای سازگاری مجموعه دادهها، برخی از این دادهها به فرمت مورد نظر تبدیل میشوند؛ مگر اینکه دانشمند دادهای بهدنبال تجزیه و تحلیل دادههای خام فیلترنشده برای یک کاربرد خاص باشد.
۳. استخراج یا کاوش دادهها
وقتی دادهها آماده شدند، یک دانشمند داده تکنیک دادهکاوی مناسب را انتخاب و بعد برای شروع استخراج اطلاعات، یک یا چند الگوریتم را پیادهسازی میکند.
در برنامههای یادگیری ماشین، الگوریتمها معمولاً باید بر روی مجموعه دادههای نمونه آموزش داده شوند تا قبل از اجرای آنها روی مجموعه کامل دادهها، به دنبال اطلاعات مورد نظر دانشمند داده باشند.
۴. تجزیه و تحلیل و تفسیر دادهها
از نتایج داده کاوی برای ایجاد مدلهای تحلیلی استفاده میشود که به تصمیمگیری و سایر اقدامات کسبوکاری کمک میکنند. در این مرحله دانشمند داده یا یکی دیگر از اعضای تیم علم داده باید یافتهها را با مدیران تجاری و کاربران در میان بگذارد. این کار اغلب از طریق تصویرسازی دادهها و استفاده از تکنیکهای داستانسرایی داده انجام میشود.
انواع تکنیکهای دیتا ماینینگ
در این روش تکنیکهای مختلفی وجود دارند که میتوانیم از آنها در کاربردهای مختلف علم داده استفاده کنیم. استخراج قوانین انجمنی یا وابستگی، کلاسبندی، کلاسترینگ، رگرسیون و شبکههای عصبی از شناختهشدهترینهای این تکنیکها هستند که در زیر معرفی کوتاهی از هر کدام را آوردهایم.

📈 استخراج قوانین وابستگی (Association rule mining)
در داده کاوی قوانین وابستگی عبارتهای if-then هستند که روابط بین داده را مشخص میکنند. از معیارهای «پشتیبان و اطمینان» برای ارزیابی این روابط استفاده میشوند؛ معیار پشتیبان مشخص میکند که عناصر مرتبط چندبار در مجموعه داده دیده شدهاند و معیار اطمینان مشخص میکند که یک گزاره if-then، چند بار اتفاق افتاده است.
📈 کلاسبندی یا طبقهبندی (Classification)
در این رویکرد، دادهها به کلاسهای ازپیشتعیینشدهای اختصاص داده میشوند. این کلاسها، مشخصههای آیتمها را توصیف میکنند یا نشان میدهند که دادههای مختلف چه اشتراکاتی با هم دارند. با این تکنیک داده کاوی دادههای اساسی (underlying data) براساس ویژگیهای مشترکی که دارند، بهطور منظمتری دستهبندی و خلاصه میشوند.
📈 خوشهبندی یا کلاسترینگ (Clustering)
این تکنیک شبیه کلاسبندی است. بااینحال، تکنیک خوشهبندی، شباهتهای بین اشیاء را شناسایی میکند و بعد آیتمها براساس چیزهایی که آنها را از هم متمایز میکند، گروهبندی میشوند. درحالیکه کلاسبندی گروههایی مانند «شامپو»، «نرمکننده»، «صابون» و «خمیر دندان» را به وجود میآورد، خروجی کلاسترینگ گروههایی مانند «مراقبت از مو» و «سلامت دندان» است.
📈 رگرسیون (Regression)
این تکنیک برای پیشبینی مقادیر عددی به کار میرود. با رگرسیون براساس مجموعهای از متغیرها، ارتباط بین دادهها کشف میشود. رگرسیون خطی ساده، رگرسیون خطی چندگانه و رگرسیون چند جملهای نمونههایی از رگرسیونهایی هستند که در Data Mining استفاده میشوند. گفتنی است، درخت تصمیم و برخی روشهای طبقهبندی دیگر هم میتوانند در رگرسیون استفاده شوند.
📈 شبکههای عصبی (Neural networks)
شبکه عصبی مجموعهای از الگوریتمهایی هستند که فعالیت مغز انسان را شبیهسازی میکند. شبکههای عصبی بهویژه در کاربردهای پیچیده تشخیص الگو مانند یادگیری عمیق یا دیپ لرنینگ مفیدند.
ابزارها و زبانهای برنامهنویسی مناسب داده کاوی
در حال حاضر عرضهکنندهها یا فروشندگان زیادی هستند که ابزارهای دیتا ماینینگ ارائه میدهند؛ این ابزارها، معمولا بهعنوان بخشی از پلتفرمهای نرمافزاری هستند که انواع دیگری از علم داده و ابزارهای تجزیهوتحلیل پیشرفته را هم شامل میشوند.

قابلیتهای آمادهسازی داده، الگوریتمهای داخلی و پیشفرض، پشتیبانی از مدلسازی پیشبینیکننده، یک محیط توسعه مبتنی بر رابط کاربری گرافیکی و ابزارهایی برای استقرار مدلها و امتیازدهی به نحوه عملکرد آنها از ویژگیهای کلیدی هستند که نرمافزارهای داده کاوی ارائه میدهند.
مهمترین عرضهکنندههایی که ابزارهای دیتا ماینینگ ارائه میدهند، عبارتند از:
- IBM
- Microsoft
- SAP
- AWS
- SAS Institute
- RapidMiner
- Knime
- Tibco Software
- Alteryx
- Databricks
- Dataiku
- DataRobot
- H2O.ai
- Oracle
همچنین انواع فناوریهای منبع باز (Open Source) رایگانی هم وجود دارند که میتوانند برای استخراج دادهها استفاده شوند؛ از جمله DataMelt، Elki، Orange، Rattle، scikit-learn و Weka. بعضی از عرضهکنندههای نرمافزار هم گزینههای منبع باز ارائه میدهند. حال که با ارائهدهندگان ابزارهای داده کاوی آشنا شدیم، بد نیست در مورد زبانهای برنامهنویسی مورد استفاده برای دیتا ماینینگ هم صحبت کنیم.
دانشمندان داده از زبان های برنامه نویسی مختلفی برای ذخیره، سازماندهی و تجسم و تصویرسازی دادهها استفاده میکنند. پایتون، جاوا، آر (R)، اسکیوال (SQL)، آپاچی اسپارک، هدوپ، نواسکیوال (NoSQL) از رایجترین زبانهای برنامهنویسی هستند که بهعنوان ابزارهای دیتا ماینینگ هم شناخته میشوند.
داده کاوی چه مزیتهایی دارد؟

دادهکاوی مزایای متعددی دارد که به کسبوکارها و سازمانها کمک میکند تصمیمات دقیقتر، سریعتر و موثرتری بگیرند. در زیر به برخی از مهمترین مزایای دادهکاوی اشاره میکنیم:
۱. بهبود تصمیمگیری: با شناسایی الگوها و روندهای پنهان در دادهها، مدیران میتوانند تصمیماتی مبتنی بر اطلاعات واقعی بگیرند و از تصمیمگیریهای مبتنی بر حدس و گمان جلوگیری کنند.
۲. افزایش بهرهوری و کارایی: شناسایی نقاط ضعف و گلوگاههای فرایندها به کسبوکارها کمک میکند تا کارایی خود را بهبود بخشند و منابع خود را بهینهتر مدیریت کنند.
۳. پیشبینی رفتار مشتریان: دادهکاوی به کسبوکارها این امکان را میدهد که رفتار مشتریان را پیشبینی کنند، محصولات و خدمات خود را براساس نیازها و ترجیحات آنها سفارشی کنند و در نتیجه فروش و رضایت مشتری را افزایش دهند.
۴. شناسایی تقلب و کاهش ریسکها: از دادهکاوی میتوان برای شناسایی رفتارهای غیرعادی و تقلب در صنایع مختلف مانند بانکداری، بیمه و تجارت الکترونیک استفاده کرد. این تکنیک به کاهش ریسک و افزایش امنیت کمک میکند.
۵. ایجاد مزیت رقابتی: کسبوکارهایی که از دادهکاوی بهره میگیرند، میتوانند بازار را بهتر درک و روندها را زودتر شناسایی کنند و استراتژیهایی پیشرو ارائه دهند که آنها را از رقبا متمایز میکند.
۶. کاهش هزینهها: تحلیل دادهها میتواند به شناسایی منابع هدررفت هزینه و کاهش آنها کمک کند، بهویژه در صنایعی که کارایی عملیاتی اهمیت بالایی دارد.
۷. توسعه محصولات جدید: با تحلیل نیازها و خواستههای مشتریان، شرکتها میتوانند محصولات و خدماتی طراحی کنند که دقیقا با انتظارات بازار هدف مطابقت داشته باشند.
۸. بهبود تجربه کاربری: با تحلیل دادههای رفتاری کاربران، میتوان تجربه کاربری را در اپلیکیشنها، وبسایتها و خدمات بهبود داد و میزان تعامل و رضایت کاربران را افزایش داد.
۹. پیشگیری از مشکلات احتمالی: دادهکاوی به شناسایی مشکلات قبل از وقوع کمک میکند، مثلا پیشبینی نقص در ماشینآلات یا کاهش فروش در یک دوره خاص.
اهمیت دیتاماینینگ برای کسب و کارها
به زبان ساده، آنالیز داده کسبوکار را بهبود میبخشد. میتواند در هزینهها صرفهجویی کند، مزیت رقابتی ایجاد کند، تجربه مشتری را بهبود بخشد و مشتریان جدید و جریانهای درآمدی را شناسایی کند.
براساس یک نظرسنجی که در سال ۲۰۱۸ توسط شرکت مایکرواستراتژی (MicroStrategy) انجام شده است، ۶۳ درصد از پاسخدهندگان گفتند که تجزیه و تحلیل دادهها، کارایی و بهرهوری شرکت آنها را بهبود بخشیده است، ۵۷ درصد معتقدند که داده کاوی به آنها کمک میکند سریعتر تصمیم بگیرند و ۵۱ درصد به بهبود عملکرد مالیشان اشاره کردند. در تصویر زیر گزارش کاملتری از این نظرسنجی را مشاهده میکنید.

سرعت، یکی از مزایای اصلی Data Mining است. دههها پیش، برای تجزیهوتحلیل مجموعه دادههای بزرگ، هفتهها یا ماهها زمان نیاز بود. بانکها و شرکتهای کارت اعتباری مجبور بودند میلیونها رکورد را برای کشف تقلب یا خطا بررسی کنند. اکنون با پیشرفت در زمینههای شبکههای عصبی، یادگیری ماشین و هوش مصنوعی، شرکتها میتوانند این مجموعه دادههای عظیم را در چند ساعت یا حتی چند دقیقه تجزیه و تحلیل کنند.
ارتباط کسبوکارهای آنلاین و دادهکاوی چیست؟
در دنیای مصرفکنندهای که غرق در دادههاست، شرکتها به روشهای کارآمدی برای بررسی دادهها نیاز دارند تا بتوانند نکات مرتبط و قابل اجرای آن را پیدا کنند. آنها میتوانند تمام دادههای موجود را سفارشی (Customize) کنند تا متوجه شوند چه کسی محصولاتشان را میخرد، کجا آنها را میخرد و چگونه میتوانند بیشتر بفروشند. پس ارتباط بین داده کاوی و کسبوکارها را میتوان عوامل زیر دانست:
- شناخت مشتری:این حوزه به کسبوکارهای آنلاین کمک میکند تا الگوهای رفتاری، ترجیحات و نیازهای مشتریان خود را بهتر درک کنند. این شناخت از طریق تجزیه و تحلیل دادههای جمعآوریشده از وبسایتها، شبکههای اجتماعی، تراکنشهای خرید و غیره به دست میآید.
- توصیههای شخصیسازیشده: با استفاده از تکنیکهای دیتا ماینینگ، کسبوکارهای آنلاین میتوانند توصیههای محصول یا خدمات را براساس تاریخچه خرید، جستجوها و رفتار کاربران شخصیسازی کنند.
- پیشبینی روندها: دادهکاوی به کسبوکارها امکان میدهد تا روندهای فعلی و آینده بازار را پیشبینی کنند. این امر میتواند در تصمیمگیریهای استراتژیک مانند مدیریت موجودی، برنامهریزی تبلیغات و توسعه محصول کمک کننده باشد.
- بهینهسازی قیمتگذاری: دیتاماینینگ میتواند در شناسایی الگوهای قیمتی موثر بر فروش کمک کند، که این امر به کسبوکارها اجازه میدهد تا قیمتهای خود را بهطور دینامیک تنظیم کنند.
- کشف تقلب: در بخشهای مانند بانکداری آنلاین و خردهفروشی، استخراج داده میتواند به شناسایی تراکنشهای مشکوک و جلوگیری از تقلب کمک کند.
- بهبود تجربه کاربری (UX): اسخراج داده به تجزیه و تحلیل رفتار کاربران در وبسایتها کمک کرده و این اطلاعات را برای بهبود طراحی وبسایت و تجربه کلی کاربران استفاده میکند.
دیتا ماینینگ در چه صنایعی کاربرد دارد؟
دادهکاوی در صنایع مختلف بهدلیل توانایی آن در استخراج دانش پنهان و ایجاد ارزش از دادهها، کاربردهای گستردهای دارد. در ادامه به مهمترین صنایع و کاربردهای آن اشاره میکنیم:
۱. بانکداری و امور مالی: در این صنعت، دادهکاوی برای شناسایی تقلب در تراکنشهای مالی بسیار اهمیت دارد. به کمک این فناوری، بانکها میتوانند رفتارهای غیرعادی را تشخیص داده و از فعالیتهای مشکوک جلوگیری کنند. همچنین، ارزیابی ریسک اعتباری مشتریان با استفاده از الگوریتمهای دادهکاوی انجام میشود تا احتمال بازپرداخت وام توسط مشتریان تخمین زده شود. علاوهبر این، بانکها میتوانند با تحلیل دادهها، محصولات مالی مناسب را به مشتریان پیشنهاد دهند و پیشبینیهایی درباره تغییرات بازارهای مالی ارائه دهند.
۲. بازاریابی و فروش: در بازاریابی، دادهکاوی برای تحلیل رفتار خرید مشتریان استفاده میشود. این تحلیلها به کسبوکارها کمک میکند تا پیشنهادات شخصیسازیشدهای برای هر مشتری ارائه دهند. دادهکاوی میتواند مشتریانی که احتمال ترک برند دارند را شناسایی کرده و استراتژیهای مناسبی برای حفظ آنها پیشنهاد کند. همچنین، دادهکاوی در بهینهسازی کمپینهای بازاریابی و افزایش بازدهی تبلیغات نقش بسزایی دارد.
۳. سلامت و پزشکی: در حوزه سلامت، دادهکاوی به پیشبینی بیماریها و شناسایی عوامل خطر کمک میکند. با تحلیل دادههای بیماران، میتوان بهترین روشهای درمانی را انتخاب کرد و هزینههای درمانی را کاهش داد. در زمینه ژنتیک، دادهکاوی برای کشف ارتباطات ژنتیکی و شناسایی درمانهای جدید کاربرد دارد. همچنین، مدیریت بهتر بیمارستانها و پیشگیری از تقلب در بیمههای سلامت با استفاده از دادهکاوی امکانپذیر است.
۴. فناوری و اینترنت: در صنعت فناوری، دادهکاوی برای بهبود الگوریتمهای پیشنهاددهنده در سرویسهایی مانند نتفلیکس و آمازون استفاده میشود. این تکنیکها رفتار کاربران را تحلیل کرده و محتوا یا محصولات متناسب با علاقه آنها را پیشنهاد میدهند. همچنین، تحلیل رفتار کاربران در شبکههای اجتماعی و شناسایی تهدیدات امنیتی از دیگر کاربردهای دادهکاوی در این حوزه است.
۵. خردهفروشی: دادهکاوی در خردهفروشی برای مدیریت موجودی کالا و پیشبینی تقاضای مشتریان مورد استفاده قرار میگیرد. این تحلیلها به بهینهسازی چیدمان فروشگاهها و افزایش فروش کمک میکنند. همچنین، با تحلیل رفتار خرید آنلاین مشتریان، فروشگاهها میتوانند تخفیفهای هدفمند و جذابی ارائه دهند تا فروش بیشتری داشته باشند.
۶. صنایع تولیدی: در تولید، دادهکاوی به پیشبینی مشکلات ماشینآلات و کاهش خرابیها کمک میکند. این تکنیکها فرایندهای تولید را بهینه کرده و بهرهوری را افزایش میدهند. همچنین، دادهکاوی در مدیریت زنجیره تأمین و کاهش هزینههای موجودی نقشی کلیدی دارد.
۷. حملونقل و لجستیک: در این صنعت، دادهکاوی برای پیشبینی الگوهای ترافیکی و بهینهسازی مسیرها کاربرد دارد. شرکتهای حملونقل میتوانند با تحلیل دادهها، مدیریت ناوگان خود را بهبود بخشند و هزینههای خود را کاهش دهند. همچنین، دادهکاوی به ارائه خدمات بهتر به مسافران در حملونقل عمومی کمک میکند.
۸. آموزش: در حوزه آموزش، دادهکاوی برای تحلیل عملکرد دانشآموزان و شناسایی نقاط ضعف آنها استفاده میشود. با این تحلیلها میتوان محتوای آموزشی شخصیسازیشدهای ارائه داد و موفقیت تحصیلی دانشآموزان را افزایش داد. همچنین، دادهکاوی میتواند عواملی که بر کیفیت آموزش تاثیر میگذارند را شناسایی کند.
۹. بیمه: در صنعت بیمه، دادهکاوی به ارزیابی ریسکهای بیمهای کمک میکند. شرکتهای بیمه میتوانند با تحلیل دادهها، سیاستهایی متناسب با نیازهای مشتریان طراحی کنند. همچنین، دادهکاوی نقش مهمی در کشف تقلب در درخواستهای بیمه و کاهش زیانهای مالی ایفا میکند.
۱۰. انرژی و محیطزیست: در این صنعت، دادهکاوی برای پیشبینی مصرف انرژی و بهینهسازی شبکههای توزیع استفاده میشود. همچنین، تحلیل دادههای هواشناسی به پیشبینی شرایط جوی و مدیریت منابع طبیعی کمک میکند. در زمینه محیطزیست، دادهکاوی به شناسایی الگوهای آلودگی و ارائه راهکارهای کاهش آن کمک میکند.
برای ورود به حرفه داده کاوی چکار کنیم؟
بسیاری از کسانی که مشتاقند در زمینه داده کاوی کار کنند، این سوال را در ذهن خود دارند که «چگونه یک شغل مرتبط با داده کاوی پیدا کنیم؟» بهترین پاسخ به این سوال این است که تجربه کار بر روی پروژههای داده کاوی را به دست آورید. اما چطور؟
راههای مختلفی برای کسب این تجربه وجود دارد. یکی از راههای خوب انجام دوره کارآموزی است. بسیاری از شرکتهای کوچک و بزرگ چنین دورههایی را ارائه میدهند. این دورههای کارآموزی مدتزمانی محدود و ازپیشتعریفشدهای دارند و در آنها شما فقط روی یک پروژه یا دامنه خاص کار میکنید. این دورهها به شما کمک میکنند تا تجربه واقعی کار داده کاوی در یک صنعت خاص را به دست آورید.
در کنار این، شما میتوانید بهصورت فریلنس کار کنید و پروژههای داده کاوی را خودتان انجام دهید. این کار به شما کمک میکند با انجام پروژههای مختلف نسبت به سایر علاقهمندان به داده کاوی برتری داشته باشید و کمکم به یک متخصص تبدیل شوید.
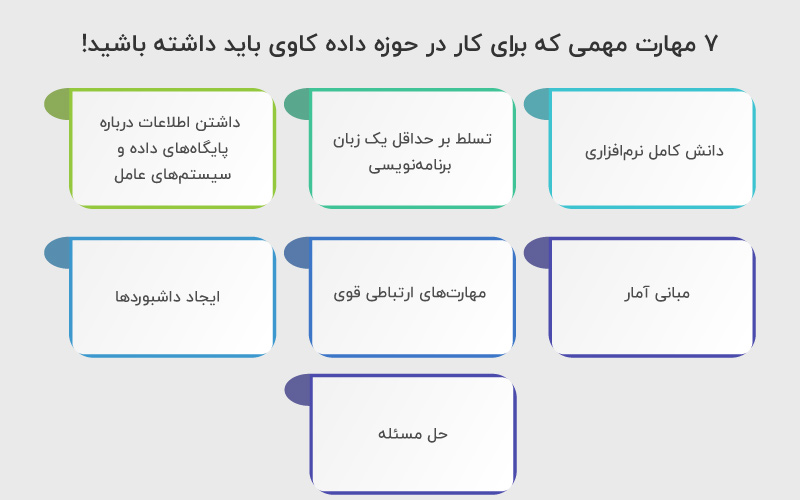
۷ مهارت مهمی که برای کار در حوزه داده کاوی باید داشته باشید!
برای کار در حوزه داده کاوی هم مانند تمام حوزههای دیگر باید مجموعهای مهارتهای مختص این حوزه را داشته باشید. در این بخش میخواهیم درباره چند مهارت مهم که میتوانند شما را به یک حرفهای در حوزه داده کاوی تبدیل کنند، صحبت کنیم.
۱. دانش کامل نرمافزاری
دادهکاوی یک حوزه تخصصی است که نیاز به تسلط بر نرمافزارها و ابزارهای مختلف دارد. نرمافزارهایی مانند SAS، Hadoop، Spark و Hive برای کار با دادههای حجیم (Big Data) ضروری هستند، اما برای شروع، یادگیری ابزارهایی مثل Python، R، و SQL اولویت دارند. ابزارهای BI مانند Tableau و Power BI نیز برای بصریسازی دادهها و ارائه گزارشها بسیار مفید هستند.
۲. تسلط بر حداقل یک زبان برنامهنویسی
در دنیای دادهکاوی، زبانهای Python و R بیشترین استفاده را دارند. Python بهدلیل کتابخانههای قوی مانند Pandas، NumPy، Scikit-learn و TensorFlow بسیار پرکاربرد است. SQL نیز برای مدیریت و استخراج دادهها از پایگاه دادهها ضروری است. سایر زبانها مانند Java یا Scala بیشتر در پروژههای مرتبط با دادههای حجیم (Big Data) موردنیاز هستند، اما زبانهایی مثل PHP ارتباط مستقیمی با دادهکاوی ندارند.
۳. داشتن اطلاعات درباره پایگاههای داده و سیستمهای عامل
تسلط بر پایگاه دادهها (مانند MySQL، PostgreSQL، MongoDB یا Redis) و مهارت در نوشتن کوئریهای SQL برای استخراج دادهها از پایگاههای داده ضروری است. آشنایی با سیستمعاملهایی مثل Linux نیز برای تنظیم سرورها یا اجرای ابزارهای دادهمحور مفید است، اما این مهارت بیشتر در نقشهای زیرساختی یا DevOps اهمیت دارد و برای تحلیلگران داده نقش کمتری ایفا میکند.
۴. مبانی آمار
آمار و ریاضیات پایههای اساسی دادهکاوی هستند. مفاهیمی مانند احتمال، توزیعها، تحلیل رگرسیون، همبستگی و جبر خطی برای تحلیل دادهها و مدلسازی بسیار اهمیت دارند. داشتن این دانش به متخصصان کمک میکند تا دادهها را بهتر درک کرده و نتایج معناداری استخراج کنند.
۵. مهارتهای ارتباطی قوی
مهارتهای ارتباطی قوی برای ترجمه دادهها به بینشهای قابلفهم برای مدیران و تیمهای غیرفنی ضروری است. این مهارت شامل توانایی ارائه گزارشها، توضیح مفاهیم پیچیده با زبانی ساده، و استفاده از ابزارهای بصریسازی داده (مانند Tableau یا Power BI) میشود.
۶. ایجاد داشبوردها
ایجاد داشبوردها یک مهارت مهم برای متخصصان BI یا نقشهایی است که بیشتر با Data Visualization سر و کار دارند. در دادهکاوی، این مهارت برای ارائه نتایج و تجزیهوتحلیلها به تیمهای غیرفنی مفید است، اما اولویت آن بعد از مهارتهایی مانند آمار، SQL و Python قرار دارد.
۷. حل مسئله
حل مسئله مهارتی عمومی است که در مواجهه با چالشهایی مانند کیفیت پایین دادهها، دادههای ناقص، محدودیت منابع و مشکلات فنی ابزارها در دادهکاوی اهمیت دارد. این مهارت در ترکیب با خلاقیت و تفکر انتقادی به متخصصان کمک میکند تا بهترین راهحلها را برای مشکلات پیچیده پیدا کنند.
وضعیت بازار کار داده کاوی در ایران
دادهها، امروز به بخش جداییناپذیر اکثر کسب و کارها، به خصوص کسب و کارهای دیجیتالی تبدیل شدهاند. از این رو نیاز به کسی که بتواند از این دادهها، اطلاعات مهم را استخراج کند، حسیاست که اکثر کسب و کارها تجربه میکنند.
نتایج جستجوی عبارتهای «داده کاوی» و «دیتا ماینینگ» در پلتفرمهای کاریابی داخلی هم، این واقعیت را تایید میکند. نکته مهم دیگر این که معمولا شرکتهای پیشرو و بزرگ هستند که به دنبال نیروهای متخصص داده هستند، پس میزان پرداختی به این نیروها هم قابل توجه است. البته درباره حقوق دریافتی متخصصان داده کاوی در ایران، اطلاعات دقیقی نداریم.
با این حال وبسایت glassdoor نشان میدهد که هر فرد با سابقه کاری زیر یک سال در صنایع مختلف، به طور متوسط ۸۲ هزار دلار و افراد با سابقه کاری ۱ تا ۳ سال تا ۹۰ هزار دلار دریافتی دارند.
جمعبندی
کسب و کارهای مدرن توانایی جمعآوری دادهها در مورد مشتریان، محصولات، خطوط تولید، کارمندان و ویترین فروشگاهها را دارند. این اطلاعات تصادفی ممکن است حرفی برای گفتن نداشته باشند اما استفاده از تکنیکها، برنامهها و ابزارهای داده کاوی کمک میکند تا اطلاعات را در کنار هم قرار دهید و ارزش ایجاد کنید. هدف نهایی فرآیند داده کاوی گردآوری دادهها، تجزیه و تحلیل نتایج و اجرای استراتژیهای عملیاتی بر اساس نتایج به دست آمده از داده کاوی (Data Mining) است.
منابع
www.techtarget.com | www.sap.com
سوالات متداول
فرایندی است که شرکتها از آن برای تبدیل دادههای خام به اطلاعات مفید استفاده میکنند. طی این فرایند، با استفاده از نرمافزارها، الگوهای موجود در دستههای بزرگ دادهها را پیدا میکنند
پیش نیازهای یادگیری داده کاوی شامل دانش آمار و احتمال، برنامهنویسی (معمولا در زبانهای Python یا R)، پایگاه داده و SQL، مهارتهای ریاضی، مفاهیم یادگیری ماشین، تجزیه و تحلیل دادهها، مهارتهای ارتباطی و تجاری، فهم دادههای بزرگ و آگاهی از اخلاق و حریم خصوصی دادهها است.
داده کاوی بر استخراج الگوها و دانش از مجموعههای بزرگ داده تمرکز دارد، در حالی که علم داده یک حوزه گستردهتر است که شامل جمعآوری، پاکسازی، تحلیل، و تفسیر دادهها است.

