
نرمالسازی پایگاه داده فرایندی است که با سازماندهی جداول و روابط بین آنها، از تکرار بیرویه دادهها جلوگیری کرده و یکپارچگی و کارایی پایگاه داده را افزایش میدهد. این ساختار منظم به طراحان پایگاه داده و معماران داده کمک میکند تا مدل دادهای متناسب با نیازهای خاص یک کسبوکار ایجاد کنند. همچنین نرمالسازی نقش تعیینکنندهای در بهینهسازی عملکرد پایگاههای داده دارد.
در این مطلب از بلاگ آسا نرمالسازی پایگاه داده را از زوایای مختلف مورد بررسی قرار میدهیم تا درک کاملی از مفاهیم پایه، یژگیها، مزایا و معایب آن داشته باشید.
نرمالسازی پایگاه داده چیست؟

نرمالسازی پایگاه داده (Database Normalization) فرایندی ساختاری برای ساماندهی دادهها است که در قالب جدولهایی مرتبط و منسجم انجام میشود. هدف اصلی انجام این کار، کاهش افزونگی اطلاعات و جلوگیری از وابستگیهای ناسازگار میان دادهها است.
این کار با ایجاد جدولهای جداگانه برای هر نوع داده و تعریف روابط منطقی میان آنها انجام شده و باعث میشود که پایگاه داده هم از نظر ساختار داخلی بهینه باشد و هم عملکرد آن در استفادههای واقعی، بدون ابهام باقی بماند.
مفهوم نرمالسازی دیتابیس از نظریه پایگاه داده رابطهای نشئت گرفت و برای نخستین بار توسط «ادگار اف. کاد» (E.F. Codd) در دهه ۱۹۷۰ معرفی شد. او با ارائه مفهومی بهنام «فرم نرمال» (Normal Form) سنگبنای علمی آن را بنا کرد. در آن زمان، بهینهسازی فضای ذخیرهسازی یک ضرورت جدی بود و Normalization توانست با کاهش دادههای تکراری، به این نیاز پاسخ دهد. همچنین این فرایند پایهایترین اصل در طراحی پایگاه داده رابطهای بهشمار میرود که اگر بهدرستی پیادهسازی شود، موجب عملکرد دقیق، پایدار و قابل اعتماد سامانههای دادهمحور میشود.
پیشنیازهای لازم برای درک نرمالسازی داده چیست؟
برای درک صحیح نرمالسازی پایگاه داده، ابتدا باید با برخی از مفاهیم پایهای در طراحی پایگاه داده آشنا شوید. در واقع باید ابتدا بدانید که چه ویژگیهایی (Attribute) به یکدیگر وابسته هستند و چگونه این وابستگیها را تشخیص دهیم. در این مسیر، دو مفهوم کلیدی زیر نقش اساسی ایفا میکنند:
کلیدها (Keys)
کلیدها در پایگاه داده نقش شناسههای منحصربهفرد را دارند. برای مثال، در یک جدول اطلاعات دانشآموزان، «شناسه دانشآموز» (Student ID) یک کلید است، زیرا به کمک آن میتوانید هر دانشآموز را بهطور منحصربهفرد شناسایی کنید.
بدون کلید، تمایز میان رکوردهای مشابه یا تکراری (مثلا دانشآموزانی با نام یکسان) دشوار میشود. در واقع کلیدها به جلوگیری از تکرار دادهها کمک میکنند و حتی دسترسی سریع و دقیق به هر رکورد را ممکن میسازد.

وابستگی تابعی (Functional Dependency)
وابستگی تابعی نشان میدهد که چگونه یک ویژگی از داده میتواند ویژگیهای دیگر را تعیین کند. بهعنوان مثال، اگر با داشتن شناسه دانشآموز بتوانید نام، سن و کلاس او را مشخص کنید، یعنی این ویژگیها تابعی از شناسه دانشآموز هستند.
شناخت این نوع وابستگیها به شما کمک میکند تا روابط منطقی میان دادهها را درک کنید و طراحی جداول را بهگونهای انجام دهید که این روابط بهدرستی حفظ شوند. زمانی که این وابستگیها بهدرستی شناسایی شوند، میتوانید جدولها را به بخشهایی کوچکتر تقسیم کنید که هر کدام شامل دادههای مرتبط با یکدیگر باشند.
این تقسیمبندی که از اصول نرمالسازی پیروی میکند، باید بهگونهای انجام شود که هیچ اطلاعاتی از بین نرود و حتی ساختار کلی پایگاه داده همچنان منسجم باقی بماند.
چرا به نرمالسازی پایگاه داده نیاز داریم؟
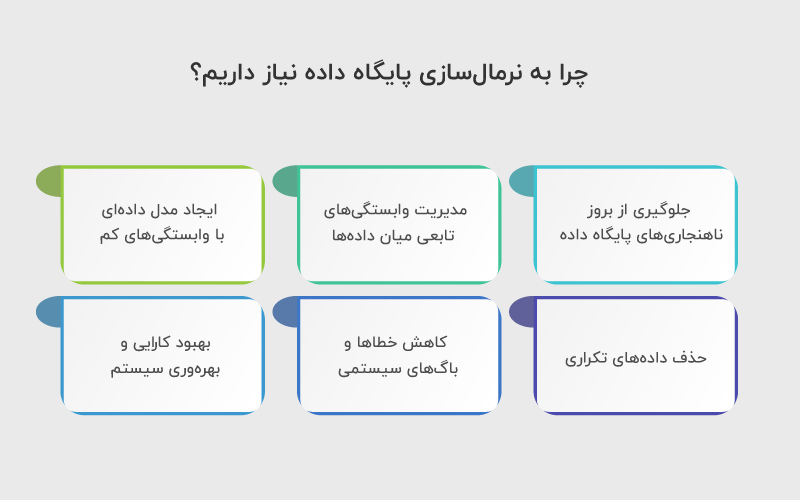
حال سوالی که ایجاد میشود این است که چرا باید نرمالسازی را انجام داد؟ در پاسخ به این سوال باید گفت که Database Normalization یکی از ضروریترین کارها برای حفظ یکپارچگی و عملکرد بهینه سامانههای اطلاعاتی بهشمار میآید. همچنین دلایل مهم دیگری برای اجرای فرایند نرمال سازی وجود دارند که در ادامه آنها را بررسی میکنیم:
۱. جلوگیری از بروز ناهنجاریهای پایگاه داده
هنگامی که بخواهید فرایندهایی مانند درج، ویرایش یا حذف اطلاعات را انجام دهید، احتمال دارد که خطاهایی موسوم به «ناهنجاری» رخ دهند و دادهها به شکل نادرست یا ناقص ثبت شوند. Normalization با ایجاد ساختاری استاندارد و منطقی، این مشکلات را به حداقل میرساند و از بروز اختلالات در عملیات روزانه جلوگیری میکند.
۲. مدیریت وابستگیهای تابعی میان دادهها
وابستگی تابعی به این معنا است که شما بتوانید یک ویژگی بر اساس ویژگی دیگر تعیین کنید. بهعنوان مثال، اگر با داشتن کد مشتری بتوانید شماره تماس او را بهطور یکتا مشخص کنید، وابستگی تابعی را انجام دادهاید. نرمال کردن به ما کمک میکند این وابستگیها را بهدرستی تعریف و مدیریت کنیم تا ساختار دادهها معنادار و منسجم باشد.
۳. ایجاد مدل دادهای با وابستگیهای کم (loose coupling)
پایگاه دادههایی که اجزای آنها بهشدت به یکدیگر وابستهاند (Tightly Coupled)، در برابر خطا آسیبپذیری بالایی دارند. در چنین ساختاری، از کار افتادن یک بخش، میتواند کل سیستم را مختل کند. استانداردسازی ساختار پایگاه داده با کاهش این وابستگیها، به ایجاد یک معماری ماژولار، انعطافپذیر و قابل مدیریت کمک میکند.
۴. حذف دادههای تکراری (redundancy)
تکرار دادهها فضای ذخیرهسازی را هدر میدهد و حتی میتواند فرایند بهروزرسانی و نگهداری را هم دشوار کند. نرمالسازی میتواند با حذف افزونگی، مدل دادهای را ساده و منسجم کند و به شما این امکان را بدهد که مدیریت یکپارچه اطلاعات را بهراحتی انجام دهید.
۵. کاهش خطاها و باگهای سیستمی
در بیشتر اوقات ساختارهای غیرنرمالسازیشده منبع خطاها و باگهای نرمافزاری هستند. این اشکالات احتمالا عملکرد کلی سامانه را مختل میکنند و حتی باعث توقف آن میشوند. در اینجا نرمالسازی با کاهش پیچیدگی و ابهام در دادهها، احتمال بروز چنین خطاهایی را بهشدت کاهش میدهد.
۶. بهبود کارایی و بهرهوری سیستم
بهبود کارایی و بهرهوری سیستم، یکی دیگر از دلایل استفاده از Database Normalization است. در واقع به کمک نرمالسازی، عملیات پردازش دادهها سادهتر و سریعتر انجام میشود. این امر زمان پاسخگویی را کاهش میدهد و حتی مصرف منابع سختافزاری و نرمافزاری را بهینه میکند. در نتیجه، هزینههای زیرساختی کاهش پیدا میکنند و کارایی کلی سامانه بالا میرود.
مراحل نرمالسازی پایگاه داده به همراه مثال
فرایند نرمالسازی پایگاه داده از چند مرحله متوالی تشکیل شده است که هر مرحله با نام «فرم نرمال» (Normal Form) شناخته میشود. در ادامه، این مراحل را بهصورت گامبهگام همراه با مثال بررسی میکنیم.
صفرمین فرم نرمال (0NF)
در این مرحله، دادهها، ساختاری خام و غیرمنظم دارند. معمولا در این حالت، با شرایط خاصی مانند افزونگی بالا، تکرار اطلاعات و نبود منطق مشخص در نحوه ذخیرهسازی دادهها روبهرو هستیم. اصطلاح 0NF به صورت رسمی یک فرم نرمال محسوب نمیشود، بلکه مفهومی غیررسمی برای اشاره به دادههای بدون ساختار است.
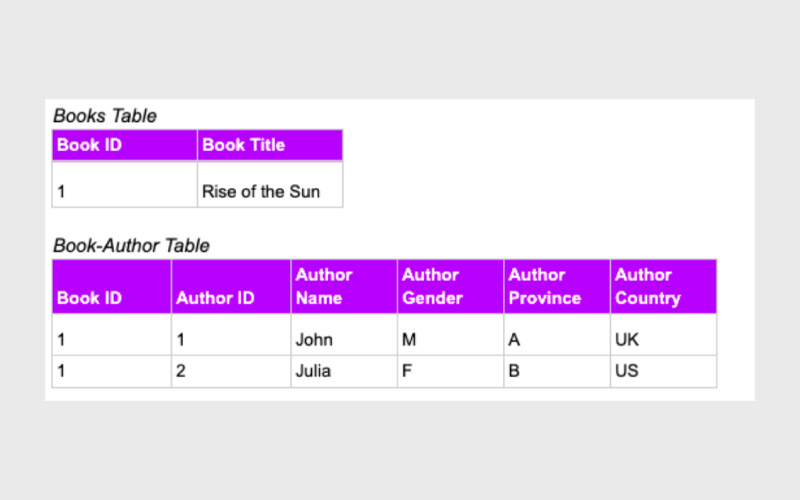
در مثال زیر، اطلاعات مربوط به کتابها بهصورت تکراری و غیراستاندارد ذخیره شدهاند. هر کتاب دارای چند ستون برای نویسنده است (مانند Author 1 و Author 2) که نشانهای از تکرار غیرضروری دادهها است. همچنین برخی ستونها شامل چند مقدار در یک سلول هستند که این هم برخلاف اصول طراحی پایگاه داده است.

اولین فرم نرمال (1NF)
در این مرحله باید برای تبدیل دادهها از 0NF به 1NF، سه اقدام اصلی زیر را انجام دهیم:
- حذف ستونهای تکراری که دادههای مشابه را نگهداری میکنند.
- اطمینان از این که هر ویژگی (Attribute) فقط یک مقدار در هر سلول دارد.
- تعیین یک کلید اصلی برای شناسایی یکتای هر رکورد.
در مثال ما، دادهها با تفکیک به دو جدول مجزا نرمالسازی شدهاند. جدول اول، شامل اطلاعات کتابها میشود که دارای شناسه منحصربهفرد (Book ID) است. جدول دوم، اطلاعات نویسندگان هر کتاب را نگهداری میکند. در این جدول، همه نویسندگان بهجای داشتن ستونهای متعدد، در یک ستون بهصورت ردیفهای جداگانه ذخیره میشوند. هر نویسنده هم شناسه اختصاصی (Author ID) خاص خود را دارد.
دومین فرم نرمال (2NF)
برای رسیدن به 2NF، باید ابتدا دادهها در 1NF باشند تا بتوانید بررسی کنید که آیا تمام ویژگیها بهطور کامل به کلید اصلی وابسته هستند؟ درصورتیکه این وابستگی بهصورت جزئی وجود داشته باشد، یعنی برخی ویژگیها فقط به بخشی از کلید وابستهاند و شما نیاز به بازطراحی ساختار دادهها دارید.
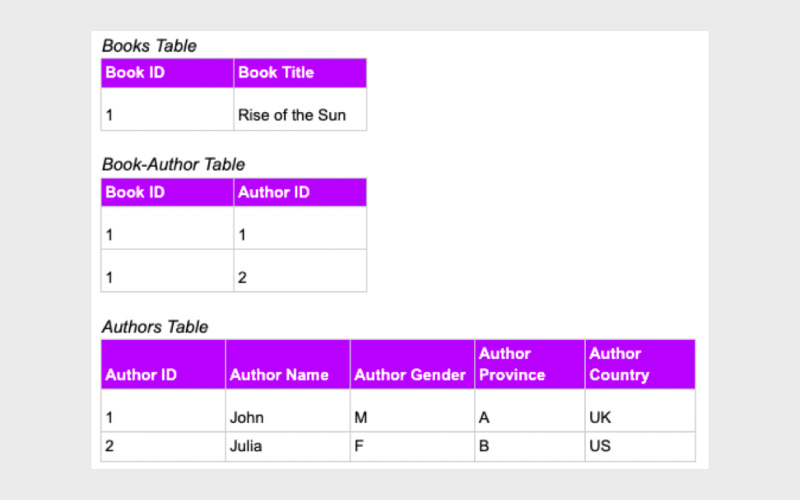
در مثال دادههای کتاب، وابستگی تابعی بهدرستی برقرار نیست. برای مثال، ازآنجاییکه یک کتاب ممکن است چند نویسنده داشته باشد، با دانستن شناسه کتاب (Book ID) نمیتوانید بهطور منحصربهفرد اطلاعات نویسنده را استخراج کنید. برای حل این مشکل، لازم است وابستگیها را بهینهسازی کنیم.
در واقع شما باید ساختار دادهها را دوباره طراحی کنید و جدول مستقلی را به نویسندگان اختصاص دهید. در این حالت، هر نویسنده با استفاده از Author ID در جدول Authors قابلشناسایی است و هر کتاب با استفاده از Book ID در جدول Books شناسایی میشود.
رابطه میان کتاب و نویسنده هم از طریق جدول Book-Author با یک شناسه جدید (Book-Author ID) مدیریت میشود.
فرم نرمال بویس-کُد (BCNF)
در این مرحله باید به فرم نرمال بویس-کد (Boyce-Codd Normal Form) برسید. در واقع برای این کار باید مراحل زیر را انجام دهید:
- دادهها باید ابتدا در فرم سوم نرمال باشند.
- تمام وابستگیهای تابعی فقط به کلید اصلی وابسته باشند. در واقع حتی اگر ویژگی خاصی وجود داشته باشد که میتوانست بهعنوان کلید استفاده شود، نباید وابستگی تابعی به آن وجود داشته باشد.
نکته بسیار مهمی که باید در اینجا به آن توجه کنید، تفاوت اصلی بین 3NF و BCNF است. در فرم سوم نرمال، بر حذف وابستگیهای تابعی روی ویژگیهای غیرکلیدی تمرکز میکنید اما در اینجا (فرم بویس-کد)، حذف وابستگیهای تابعی روی ویژگیهایی که میتوانند به عنوان کلید باشند را مدنظر قرار میدهید.
در این مرحله، دادههای شما به میزان قابل توجهی نرمال شدهاند و اگر از این حد فراتر بروید، وارد قلمرو نرمالسازی افراطی میشوید. به عبارتی دیگر، دادهها آنقدر تفکیک و پراکنده میشوند که این امر میتواند باعث مشکلات عملکردی در پایگاه داده شود.
فرم چهارم و پنجم نرمال (4NF و 5NF)
فرم چهارم و پنجم نرمال از دیگر فرمهای نرمالسازی پایگاه داده هستند که معمولا در عمل کاربرد زیادی ندارند و بیشتر در مباحث نظری و آکادمیک مطرح میشوند. هدف از این مراحل پیشرفته، حذف وابستگیهای پیچیدهتر مانند وابستگیهای چند مقداری (Multi-Valued Dependencies) و وابستگیهای پیوندی (Join Dependencies) است که در طراحیهای خاص و تخصصی به وجود میآیند.
در واقع هنگام بررسی اغلب سیستمهای تجاری، میتوان به این نتیجه رسید که Normalization تا BCNF کافی است و مراحل 4NF و 5NF بیشتر در مواردی استفاده میشوند که ساختار داده بسیار پیچیده، حساس به ناسازگاری و یا نیازمند دقت بسیار بالا در بهینهسازی ذخیرهسازی باشد.
مزایای نرمالسازی پایگاه داده چیست؟
در واقع نرمال کردن دیتابیس بهعنوان فرایندی حیاتی در طراحی سیستمهای اطلاعاتی، مزایای زیادی را برای نگهداری، توسعه و استفاده از دادهها فراهم میکند که در ادامه مهمترین آنها را معرفی میکنیم:
۱. حذف افزونگی و صرفهجویی در فضای ذخیرهسازی: با نرمالسازی، اطلاعات تکراری از بین میرود و هر قطعه از داده فقط در یک محل ذخیره میشود. این موضوع باعث صرفهجویی در فضای ذخیرهسازی و جلوگیری از ایجاد نسخههای مختلف از یک داده میشود.
۲. تضمین صحت و یکپارچگی دادهها: زمانی که اطلاعات تکراری وجود ندارد، احتمال بروز تناقض در اطلاعات کاهش پیدا میکند. Normalization از طریق تعریف وابستگیهای منطقی بین جداول، به یکپارچگی دادهها کمک میکند.
۳. جلوگیری از ناهنجاریهای بهروزرسانی (Update Anomalies): اگر یک دیتابیس بهینه نشده باشد، احتمالا لازم باشد که بهروزرسانی یک داده در چند جدول انجام شود. در واقع انجام نرمالسازی به کمک تقسیم دقیق دادهها به جدولهای مرتبط، علاوه بر حل مشکل، روند بهروزرسانی را ساده میکند.
۴. سادهسازی نگهداری و توسعه پایگاه داده: این فرایند ساختار دادهها را به اجزای سادهتر و مرتبط تقسیم میکند. این کار باعث میشود نگهداری، افزودن یا حذف اطلاعات با کمترین تغییر در ساختار پایگاه داده انجام شود.
۵. بهبود طراحی منطقی پایگاه داده: پایگاه دادههای نرمال شده دارای ساختاری منظم، ماژولار و قابل درک هستند. این نوع طراحی باعث افزایش انعطافپذیری در مقابل تغییرات و توسعههای آینده میشود.
۶. افزایش دقت در بازیابی دادهها (Query Accuracy): با سازماندهی دقیق دادهها، کوئریهای SQL میتوانند به شکل بهینهتری اجرا شوند. علاوه بر این، اتصال جداول مرتبط با استفاده از کلیدهای مشخص، باعث بازیابی دقیقتر و سریعتر اطلاعات میشود.
۷. انعطافپذیری و مقیاسپذیری بالا: پایگاه دادهای که ساختار نرمال دارد، بهراحتی قابل گسترش است. در واقع این پایگاه داده انعطافپذیری و مقیاسپذیری بالایی دارد و شما میتوانید علاوهبر تعریف جدولهای جدید، فیلدهایی را بدون آسیب به ساختار فعلی اضافه کنید.
۸. استانداردسازی ذخیرهسازی دادهها: نرمالسازی بهصورت خودکار باعث ایجاد ساختاری استاندارد و منسجم برای ذخیرهسازی دادهها میشود. این موضوع باعث میشود تمام دادهها با یک الگو و نظم مشخص وارد پایگاه داده شوند.
۹. تسهیل در یکپارچهسازی سیستمها و اپلیکیشنها: پایگاه دادههایی که نرمالشده هستند، میتوانند به دلیل ساختار دقیق و بدون تکرار، بهراحتی توسط چند سیستم یا اپلیکیشن بهصورت مشترک استفاده شوند و دادههای هماهنگ و یکدستی را فراهم کنند.
معایب نرمالسازی دیتابیس
با اینکه Normalization یکی از اصول مهم در طراحی پایگاه داده است، اما در کنار مزایای زیاد، معایبی خاصی هم دارد که نباید نادیده گرفته شوند. در ادامه این معایب را معرفی میکنیم:
- افزایش پیچیدگی طراحی پایگاه داده: معمولا نرمالسازی باعث ایجاد تعداد زیادی جدول مرتبط با یکدیگر میشود. این مسئله احتمالا طراحی دیتابیس را برای برنامهنویسان یا تحلیلگرانی که با ساختار پایگاه داده آشنایی کمتری دارند، پیچیدهتر و دشوارتر کند.
- عملکرد پایینتر در برخی کوئریها: معمولا برای دریافت یک مجموعه داده کامل، باید چندین عملیات Join را در بین جدولهای مختلف انجام دهید. این موضوع میتواند در برخی از سناریوها (مخصوصا در پایگاه دادههایی با حجم بالا) باعث کاهش سرعت اجرای کوئریها و افزایش بار پردازشی شود.
- نیاز به دانش تخصصی برای طراحی صحیح: برای پیادهسازی درست نرمالسازی دیتابیس، باید درک عمیقی از ساختار دادهها، روابط بین آنها و اصول طراحی پایگاه داده داشته باشید. درصورتیکه این تواناییها را نداشته باشید، این فرآیند ناقص یا نادرست انجام میشود.
- افزایش پیچیدگی در نوشتن کوئریها: در پایگاه دادههایی که نرمالسازی آنها انجام شده است، معمولا برای استخراج دادهها باید چند جدول را به هم مرتبط کنید. این کار نوشتن کوئریهای SQL را دشوارتر میکند (مخصوصا زمانی که کوئریهای پیچیده یا ترکیبی نوشته میشوند) و به مهارت بالاتری نیاز دارد.
- احتمال بیشازحد نرمالسازی (Over-Normalization): در برخی موارد، انجام بیش از حد این فرایند باعث ایجاد جدولهای بسیار زیاد میشود. این اتفاق میتواند در عمل استفاده از پایگاه داده را دشوار کند و عملکرد را بهطور محسوسی پایین بیاورد.
- از بین رفتن سیاق یا بافت دادهها (Context Loss): زمانی که اطلاعات به بخشهای مختلف شکسته و در جدولهای جداگانه ذخیره میشوند، احتمالا درک معنای کلی دادهها دشوارتر شود. معمولا برای بازسازی این سیاق یا بافت داده، به کوئریهای ترکیبی و پیچیده نیاز دارید.
- افزایش مصرف فضای ذخیرهسازی در برخی موارد خاص: با اینکه هدف اصلی نرمالسازی پایگاه داده کاهش افزونگی است اما احتمالا در برخی از مواقع (بهخصوص اگر سیستم از ایندکسگذاری سنگین استفاده کند) به دلیل اضافه شدن جدولهای جدید، کلیدهای خارجی و ایندکسها، مصرف حافظه افزایش پیدا کنید.
کلام آخر
افرادی که در حوزه سیستمهای اطلاعاتی کار میکنند، باید بهخوبی بدانند که نرمالسازی پایگاه داده چیست و چه مزایایی دارد؟ در واقع استانداردسازی ساختار پایگاه داده از جمله مهمترین اصول در طراحی ساختاریافته سیستمهای اطلاعاتی محسوب میشود.
این فرایند با هدف حذف افزونگی، بهبود انسجام دادهها و افزایش انعطافپذیری در نگهداری اطلاعات انجام میگیرد و در صورت پیادهسازی اصولی، میتواند نقشی تعیینکننده در کیفیت عملکرد دیتابیسها ایفا کند.
منابع
builtin.com | geeksforgeeks.org | linkedin.com
سوالات متداول
نرمالسازی برای کاهش افزونگی دادهها و بهبود انسجام استفاده میشود، در حالی که دنرمالسازی عمداً دادههای تکراری ایجاد میکند تا سرعت پرسوجوها افزایش پیدا کند.
نرمالسازی از نظر یکپارچگی و دقت دادهها مفید است، اما گاهی باعث ایجاد جداول زیاد و کوئریهای پیچیده میشود که میتواند سرعت اجرای پرسوجو را کاهش دهد.
بله، نرمالسازی عمدتا در پایگاه دادههای رابطهای (Relational Databases) کاربرد دارد؛ در پایگاه دادههای NoSQL معمولا به جای آن از طراحیهای مبتنی بر کارایی و الگوهای دادهای دیگر استفاده میشود.



دیدگاهتان را بنویسید