
در دنیای امروز که حجم عظیمی از دادههای متنی، تصویری و صوتی تولید میشود، دیگر روشهای سنتی ذخیرهسازی پاسخگو نیستند. پایگاههای داده کلاسیک بیشتر برای دادههای ساختاریافته طراحی شدهاند و نمیتوانند شباهت یا معنای پنهان میان دادههای پیچیده را درک کنند. همینجاست که هدف و کارکرد پایگاه داده برداری اهمیت پیدا میکند؛ این نوع دیتابیس، دادهها را به بردارهای عددی تبدیل میکند تا امکان تحلیل معنایی و جستجوی هوشمند فراهم شود.
با تکیه بر این قابلیت، پایگاه داده برداری میتواند زیرساختی قدرتمند برای توسعه اپلیکیشنهای هوش مصنوعی، موتورهای جستجوی پیشرفته و سامانههای توصیهگر ایجاد کند. در ادامه این مقاله بهطور دقیق بررسی میکنیم که پایگاه داده برداری چه اهدافی را دنبال میکند و چه نقشی در آینده پردازش دادههای غیرساختاریافته خواهد داشت.
هدف پایگاه داده برداری
یکی از دلایل اصلی شکلگیری پایگاههای داده برداری، محدودیتهای دیتابیسهای سنتی در ذخیره و بازیابی دادههای پیچیده است. سیستمهای کلاسیک برای دادههای جدولی و ساختاریافته طراحی شدهاند و وقتی صحبت از بردارهای با ابعاد بالا (مانند امبدینگ متون، تصاویر یا صداها) میشود، کارایی لازم را ندارند.
از سوی دیگر، بسیاری از کاربردهای امروزی نیازمند جستجوی معنایی (Semantic Search) و یافتن شباهت (Similarity Search) میان دادهها هستند. برای مثال، در یک موتور جستجو کاربر میخواهد عبارتی را تایپ کند و نتایجی دریافت کند که از نظر معنا نزدیک باشند، نه صرفا مشابه از نظر کلمات.
برای رسیدن به این هدف، پایگاههای داده برداری از الگوریتمهای خاصی مانند ANN (Approximate Nearest Neighbor) استفاده میکنند. این الگوریتمها امکان مقایسه سریع بردارها و یافتن نزدیکترین دادهها را فراهم میکنند، بدون آنکه نیاز به محاسبات سنگین و پرهزینه در مقیاس بزرگ باشد.
به این ترتیب، هدف اصلی پایگاه داده برداری نهتنها ذخیرهسازی بردارها، بلکه فراهم کردن بستری بهینه برای جستجو و بازیابی هوشمند دادههای غیرساختاریافته است.
پایگاه داده برداری چه کاربردی دارد؟
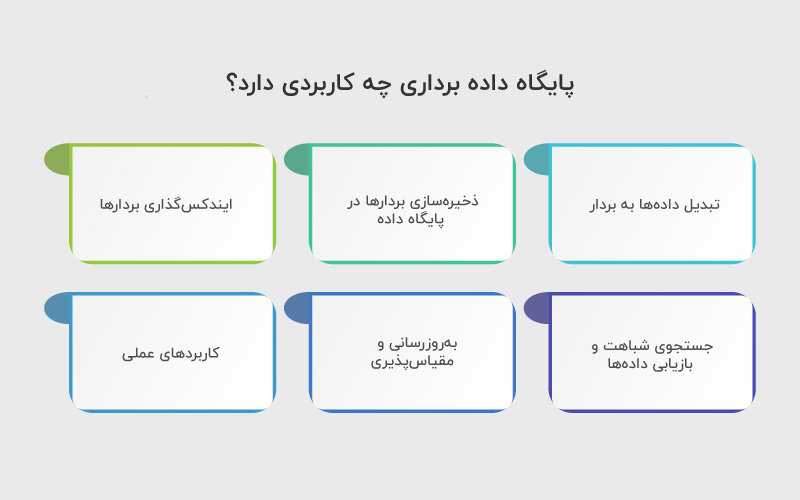
پایگاه داده برداری چندین مرحله مشخص برای مدیریت و بازیابی دادهها دارد. در ادامه هر مرحله را توضیح میدهیم:
۱. تبدیل دادهها به بردار (Vectorization / Embedding)
- دادههای غیرساختاریافته مانند متن، تصویر یا صدا به شکل بردارهای عددی (امبدینگ) تبدیل میشوند.
- هر بردار شامل مجموعهای از اعداد است که ویژگیها و معنای داده را بازنمایی میکند.
- این تبدیل باعث میشود ماشینها بتوانند معنای دادهها را درک و پردازش کنند.
۲. ذخیرهسازی بردارها در پایگاه داده
- بردارهای تولیدشده در ساختارهای پایگاه داده برداری ذخیره میشوند.
- برخلاف دیتابیسهای سنتی، پایگاه داده برداری توانایی مدیریت بردارهای با ابعاد بالا (High-Dimensional) را دارد.
۳. ایندکسگذاری بردارها (Indexing)
برای جستجوی سریع و مقایسه بردارها، پایگاه داده آنها را ایندکسگذاری میکند.
الگوریتمهای رایج شامل:
- ANN (Approximate Nearest Neighbor): جستجوی تقریبی برای یافتن نزدیکترین بردارها
- HNSW (Hierarchical Navigable Small World Graphs): ساخت گرافهای سلسلهمراتبی برای جستجوی سریع
- IVF-PQ (Inverted File with Product Quantization): کاهش فضای مورد نیاز و افزایش سرعت بازیابی
۴. جستجوی شباهت و بازیابی دادهها
- وقتی کاربر یا مدل نیاز به اطلاعات دارد، پایگاه داده برداری با محاسبه فاصله بین بردارها (مثل فاصله کسینوسی یا فاصله اقلیدسی) نزدیکترین دادهها را پیدا میکند.
- این عملیات میتواند جستجوی معنایی (Semantic Search) یا یافتن مشابهترین دادهها باشد.
۵. بهروزرسانی و مقیاسپذیری
- پایگاه داده برداری بهراحتی میتواند بردارهای جدید را اضافه یا بردارهای قدیمی را بهروزرسانی کند.
- طراحی آن به گونهای است که مقیاسپذیری در حجمهای بزرگ داده حفظ شود و عملیات جستجو همچنان سریع باقی بماند.
۶. کاربردهای عملی
- موتورهای جستجوی پیشرفته که نتایج معنایی ارائه میدهند.
- سیستمهای توصیهگر محصولات یا محتوا.
- تحلیل و طبقهبندی دادههای متنی یا تصویری بهصورت هوشمند.
روشهای جستجو در پایگاه داده برداری
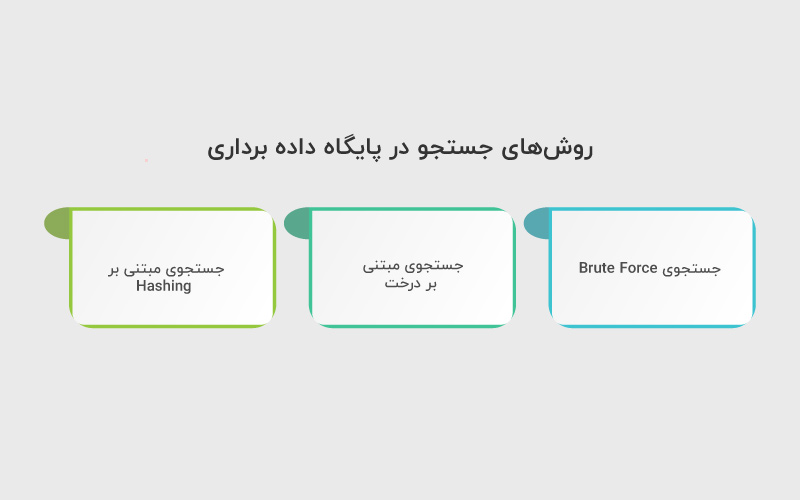
برای بازیابی دادهها در پایگاه داده برداری، چند روش اصلی وجود دارد که هر کدام مزایا و محدودیتهای خاص خود را دارند:
۱. جستجوی Brute Force (تمام-نگر)
در این روش، فاصله یا شباهت بین بردار پرسوجو و تمام بردارهای ذخیرهشده محاسبه میشود.
- مزیت: ساده و دقیق؛ نتیجه کاملا درست است.
- محدودیت: در حجم بالای داده بسیار کند و پرهزینه است.
۲. جستجوی مبتنی بر درخت (Tree-Based)
بردارها در ساختارهای درختی مانند KD-Tree یا Ball-Tree ذخیره میشوند.
- مزیت: سرعت بالاتر نسبت به Brute Force برای دادههای با بعد پایین تا متوسط.
- محدودیت: برای بردارهای با ابعاد خیلی بالا کارایی کاهش مییابد (Curse of Dimensionality).
۳. جستجوی مبتنی بر Hashing (مثل LSH – Locality Sensitive Hashing)
بردارها به کمک توابع هش به سطلهای مختلف اختصاص داده میشوند.
- مزیت: سرعت بسیار بالا در جستجوی بردارهای نزدیک به هم، مناسب برای بردارهای با بعد بالا.
- محدودیت: نتیجه تقریبی است؛ ممکن است نزدیکترین بردار دقیق پیدا نشود.
در عمل، پایگاههای داده برداری اغلب ترکیبی از این روشها را برای بهینهسازی سرعت و دقت استفاده میکنند تا بتوانند جستجوی سریع و مقیاسپذیر روی دادههای بزرگ انجام دهند.
مقایسه پایگاه داده برداری و دیتابیسهای سنتی
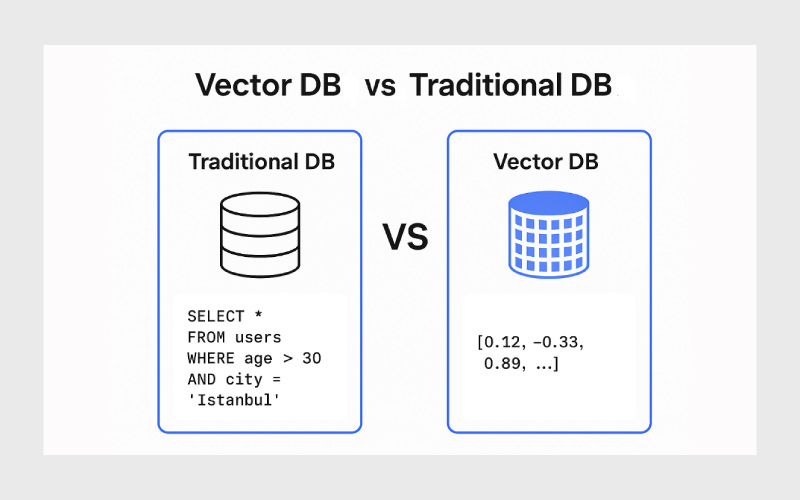
پایگاههای داده برداری و دیتابیسهای سنتی هر دو برای ذخیره و بازیابی دادهها طراحی شدهاند، اما در ماهیت دادهها و روش عملکرد تفاوتهای اساسی دارند. دیتابیسهای سنتی مانند SQL و NoSQL بیشتر روی دادههای ساختاریافته تمرکز دارند و جستجو بر اساس ستونها یا کلیدها انجام میشود، در حالی که پایگاه داده برداری دادههای غیرساختاریافته را به بردارهای عددی تبدیل کرده و بازیابی آنها را بر اساس شباهت معنایی امکانپذیر میکند.
در ادامه جدول مقایسهای این دو نوع پایگاه داده را میبینیم:
| ویژگی | پایگاه داده برداری | دیتابیس سنتی (SQL/NoSQL) |
| نوع داده | دادههای غیرساختاریافته و امبدینگهای برداری | دادههای ساختاریافته و جدولی |
| هدف | بازیابی معنایی و یافتن مشابهترین دادهها | ذخیره و بازیابی مستقیم بر اساس کلید یا ستونها |
| روش جستجو | بر اساس فاصله بردارها (Cosine, Euclidean) و الگوریتمهای ANN | بر اساس ایندکسهای ستونها یا کلید اصلی |
| سرعت (Latency) | بهینهشده برای جستجوی نزدیکترین همسایه، حتی در دادههای بزرگ | سریع برای دادههای ساختاریافته، کند برای دادههای پیچیده یا با ابعاد بالا |
| مقیاسپذیری (Scalability) | طراحیشده برای مقیاس بزرگ دادههای غیرساختاریافته | مقیاسپذیر اما محدود به دادههای ساختاریافته |
| کاربرد | جستجوی معنایی، توصیهگر، پردازش هوشمند دادههای غیرساختاریافته | سیستمهای تراکنشی، پایگاه دادههای مدیریتی |
نمونههای کاربردی پایگاه داده برداری برای توسعهدهندگان
پایگاههای داده برداری ابزارهای قدرتمندی هستند که به توسعهدهندگان اجازه میدهند اپلیکیشنهای هوشمند بسازند و تجربه کاربری بهتری ارائه کنند. برخی از کاربردهای متداول شامل موارد زیر هستند:
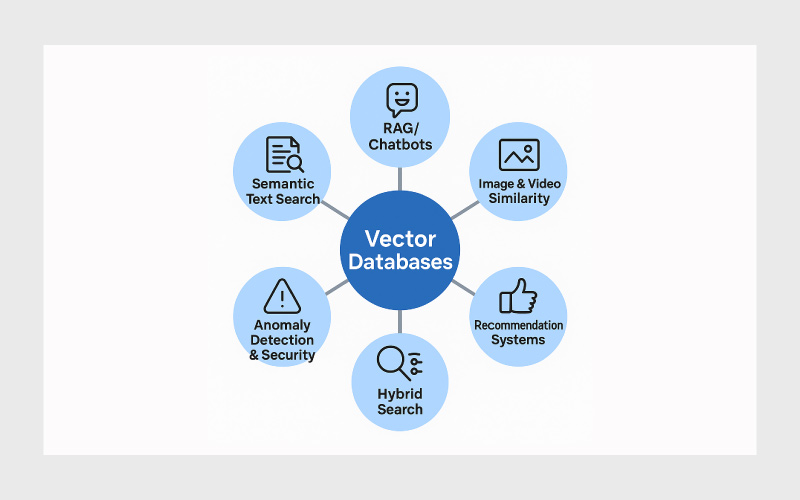
- جستجوی معنایی در متن: این قابلیت به ویژه در سیستمهای چتبات و معماری RAG (Retrieval-Augmented Generation) اهمیت دارد و به کاربران اجازه میدهد نتایجی دریافت کنند که از نظر معنا به پرسش آنها نزدیک هستند، نه صرفا از نظر کلمات مشابه.
- سیستمهای توصیهگر (Recommendation Systems): بردارها امکان تحلیل شباهت میان کاربران یا محتواها را فراهم میکنند و تجربه شخصیسازیشدهای ارائه میدهند.
- جستجوی تصویر و ویدئو: با تبدیل ویژگیهای تصاویر و ویدئوها به بردار، میتوان محتواهای مشابه را سریع شناسایی و بازیابی کرد.
- امنیت و تشخیص ناهنجاری: پایگاه داده برداری میتواند الگوهای غیرمعمول را در تراکنشها یا فعالیتهای کاربران شناسایی کند و در زمینه تشخیص تقلب (Fraud Detection) کاربرد داشته باشد.

جمعبندی
پایگاههای داده برداری با توانایی مدیریت دادههای غیرساختاریافته و بازیابی معنایی، به ابزار کلیدی توسعهدهندگان برای ساخت اپلیکیشنهای هوشمند تبدیل شدهاند. این پایگاهها امکان پردازش همزمان متن، تصویر و صدا را فراهم میکنند و با الگوریتمهای ایندکسگذاری و جستجوی بردار، سرعت و دقت بالایی در بازیابی دادهها ارائه میدهند.
در آینده، ادغام پایگاههای داده برداری با مدلهای زبانی بزرگ (LLM) و معماریهای RAG روند غالب خواهد بود، که باعث بهبود پاسخدهی هوشمند و توسعه سیستمهای پیشرفته هوش مصنوعی میشود. استفاده از این فناوریها به توسعهدهندگان امکان میدهد تجربه کاربری بهتر، پردازش سریعتر دادههای پیچیده و قابلیتهای هوشمند بیشتری را در اپلیکیشنهای خود ارائه کنند.
منابع
سوالات متداول
پایگاه داده برداری، دادههای غیرساختاریافته مانند متن، تصویر و صدا را به بردارهای عددی (امبدینگ) تبدیل میکند و بازیابی آنها را بر اساس شباهت معنایی انجام میدهد، در حالی که دیتابیس سنتی بر دادههای ساختاریافته و جستجو بر اساس کلید یا ستونها تمرکز دارد.
هدف اصلی، امکان جستجوی معنایی، یافتن دادههای مشابه و بهبود پردازش هوشمند دادههای پیچیده است، به ویژه در اپلیکیشنهای مبتنی بر هوش مصنوعی و سیستمهای توصیهگر.
سه روش اصلی وجود دارد:
Brute Force: دقیق اما کند
Tree-Based: سریعتر برای بعدهای پایین تا متوسط
Hashing (مثل LSH): سریع و مناسب برای بعدهای بالا، نتیجه تقریبی



دیدگاهتان را بنویسید