
در سالهای اخیر، مدلهای زبانی بزرگ (LLMs) به بخش جداییناپذیر بسیاری از محصولات، ابزارها و سرویسهای هوش مصنوعی تبدیل شدهاند. با این حال، اجرای این مدلها در محیطهای واقعی همیشه با چالشهای جدی همراه بوده است: مصرف بالای حافظه، نیاز به توان پردازشی سنگین، هزینههای سختافزاری و محدودیت در پاسخگویی همزمان به کاربران زیاد. کتابخانه vLLM پاسخی است برای این چالشها.
vLLM با معرفی الگوریتم PagedAttention و مجموعهای از تکنیکهای بهینهسازی، امکان اجرای سریعتر، مقیاسپذیرتر و مقرونبهصرفهتر مدلهای زبانی را فراهم میکند. در این مقاله، عملکرد vLLM، مزایای آن و دلیل تبدیلشدنش به یک استاندارد نوظهور در دنیای LLMها را بررسی میکنیم.
vLLM چیست؟
vLLM مخفف virtual Large Language Model است؛ یک کتابخانه متنباز که توسط جامعه vLLM توسعه و نگهداری میشود. این کتابخانه به مدلهای زبانی بزرگ (LLMها) کمک میکند محاسبات را کارآمدتر و در مقیاس بزرگتر انجام دهند.
بهطور دقیقتر، vLLM یک Inference Server است که خروجیدادن مدلهای مولد (Generative AI) را سرعت میدهد. این کار با بهینهسازی استفاده از حافظه GPU انجام میشود تا توان مدل برای پردازش و تولید متن افزایش پیدا کند.
vLLM چگونه کار میکند؟
برای درک ارزش vLLM، ابتدا لازم است بفهمیم یک Inference Server دقیقا چه کاری انجام میدهد و یک مدل زبانی بزرگ در حالت پایه چگونه عمل میکند. وقتی این بخشها را بشناسیم، راحتتر میتوانیم بفهمیم vLLM چگونه وارد جریان اجرا میشود و عملکرد مدلهای زبانی موجود را بهبود میدهد.
Inference Server چیست؟

Inference Server نوعی نرمافزار است که به مدل هوش مصنوعی کمک میکند بر اساس دانشی که در مرحله آموزش کسب کرده، به نتایج جدید برسد. این سرور، ورودی را دریافت میکند، آن را از داخل مدل یادگیری ماشین عبور میدهد و در نهایت خروجی تولیدشده را برمیگرداند.
واژه infer یعنی «نتیجهگیری بر پایه شواهد». مثلا ممکن است چراغ خانه دوستتان روشن باشد اما خود او را نبینید. شما نتیجه میگیرید که او در خانه است، هرچند مدرک قطعی ندارید.
یک مدل زبانی هم مثل انسان شواهد قطعی ندارد؛ فقط یک نرمافزار است. بنابراین از دادههایی که در زمان آموزش دیده، به عنوان «شواهد» استفاده میکند. با انجام مجموعهای از محاسبات روی این دادهها، به یک نتیجه میرسد؛ درست شبیه زمانی که شما نتیجه میگیرید اگر چراغ خاموش باشد، دوستتان احتمالا خانه نیست.

مدلهای زبانی با محاسبات ریاضی به نتیجه میرسند
یک LLM در مرحله آموزش، با انجام محاسبات ریاضی یاد میگیرد. هنگام تولید پاسخ (Inference) هم دوباره همین کار را انجام میدهد؛ یعنی مجموعهای از محاسبات احتمالاتی را اجرا میکند.
برای اینکه یک LLM بتواند درخواست شما را بفهمد، باید بداند واژهها چگونه به هم مرتبط میشوند و چه ارتباطهای معنایی میان آنها وجود دارد. اما برخلاف انسان که از معناشناسی و استدلال زبانی استفاده میکند، LLMها این «استدلال» را با ریاضیات انجام میدهند.
وقتی یک LLM روزانه به میلیونها کاربر پاسخ میدهد، حجم عظیمی از محاسبات انجام میدهد. پردازش همزمان این محاسبات بهصورت زنده و بلادرنگ چالشبرانگیز است؛ زیرا در معماریهای سنتی، توان پردازشی لازم برای اجرای LLMها میتواند خیلی سریع حافظه زیادی مصرف کند.
معماری vLLM با بهینهسازیهای مداوم، بهرهوری منابعی مثل حافظه و سرعت را بهشکل چشمگیری بهبود میدهد.
vLLM با استفاده از PagedAttention محاسبات را کارآمدتر پردازش میکند
در یک پژوهش مهم با عنوان Efficient Memory Management for Large Language Model Serving with PagedAttention نشان داده شد که سیستمهای مدیریت حافظه LLMهای فعلی، محاسبات را بهینه سازماندهی نمیکنند.
PagedAttention یک تکنیک مدیریت حافظه است که توسط vLLM معرفی شده و الهامگرفته از سیستمهای Virtual Memory و Paging در سیستمعاملهاست.
این تحقیقات نشان میدهد که KV Cache (حافظه کوتاهمدت LLM) در زمان پردازشِ حجم بالا دائما کوچک و بزرگ میشود و همین باعث بیثباتی در مصرف حافظه و منابع میشود. vLLM راهکاری ارائه میدهد که این فضای حافظه و توان پردازشی را به شکل پایدارتر مدیریت کند.
در عمل، vLLM مثل مجموعهای از دستورالعملها عمل میکند که KV Cache را تشویق میکند با استفاده از Continuous Batching مسیرهای میانبر بسازد و پاسخهای کاربران را دستهبندیشده پردازش کند.
vLLM چگونه میتواند به سازمان شما کمک کند؟
در دنیایی که سختافزار مورد نیاز برای اجرای برنامههای مبتنیبر LLM هزینه بالایی دارد، vLLM به سازمانها کمک میکند با منابع کمتر، کار بیشتری انجام دهند.
ساخت سرویسهای مقیاسپذیر، قابلاعتماد و مقرونبهصرفه بر پایه LLM نیازمند توان پردازشی بالا، مصرف انرژی قابلتوجه و مهارتهای تخصصی در عملیات است. همین چالشها باعث میشود بسیاری از سازمانها نتوانند به مزایای مدلهای شخصیسازیشده، قابل استقرار و امنتر دسترسی پیدا کنند.
vLLM و الگوریتم پایه آن یعنی PagedAttention تلاش میکنند این چالشها را با استفاده کارآمدتر از سختافزارهای مورد نیاز برای پردازشهای هوش مصنوعی برطرف کنند.
مزایای vLLM

عملکرد vLLM تنها به اجرای سریعتر مدلها محدود نمیشود؛ این معماری با ایجاد یک لایه بهینهسازی در سطح پردازش و مدیریت حافظه، تجربهای متفاوت از سرویسدهی LLM را ارائه میکند. به همین دلیل، بسیاری از تیمهای فنی از vLLM بهعنوان یک رویکرد پایدارتر و کارآمدتر نسبت به روشهای سنتی یاد میکنند. در ادامه، برخی از مهمترین مزایایی که این کتابخانه برای توسعهدهندگان و سازمانها ایجاد کرده را بررسی میکنیم.
۱. پاسخدهی سریعتر
در برخی آزمایشها، vLLM توانسته تا ۲۴ برابر حجم پردازش بیشتری در واحد زمان نسبت به Hugging Face Transformers انجام دهد. این یعنی دادههای بیشتری میتواند در یک بازه زمانی پردازش کند، در نتیجه سرعت پاسخگویی افزایش پیدا میکند.
۲. کاهش هزینه سختافزار
وقتی مصرف منابع بهینه باشد، نیاز به GPUهای متعدد کاهش پیدا میکند و این موضوع مستقیما هزینههای زیرساخت را کم میکند.
۳. مقیاسپذیری بهتر
vLLM با سازماندهی هوشمندانه حافظه مجازی، باعث میشود GPU بتواند درخواستهای همزمان بیشتری را مدیریت کند. بنابراین برای سرویسهای پرترافیک، کارایی پایدارتر و ظرفیت بالاتری فراهم میشود.
۴. حفظ حریم خصوصی داده
استفاده از vLLM در محیط Self-Hosted کنترل کاملتری بر دادههای کاربران فراهم میکند، در مقایسه با سرویسهای خارجی مانند ChatGPT یا APIهای شخص ثالث.
۵. نوآوری متنباز
بازبودن کد منبع و مشارکت فعال جامعه توسعهدهندگان باعث میشود vLLM دائما بهبود پیدا کند. این شفافیت همچنین آزادی عمل بیشتری به توسعهدهندگان میدهد تا vLLM را مطابق نیازهای خود سفارشیسازی کنند.
قبل از ادامه، بیایید بهصورت خلاصه تعریف کنیم KV Cache چیست و Continuous Batching چه نقشی دارد.
KV Cache چیست؟
KV مخفف Key-Value است. Key-Value روشی است که یک LLM برای تعریف «معناداری» یک کلمه یا عبارت از آن استفاده میکند.
مثلاً در منوی یک رستوران:
- French fries میشود Key
- قیمت $3.99 میشود Value
پس وقتی صندوقدار سفارش سیبزمینی سرخکرده را ثبت میکند، مقدار مرتبط با آن Key همان ۳.۹۹ دلار است.
LLMها هم KVها را به شکل مشابهی پردازش میکنند: برای هر توکن، یک مقدار (Value) ذخیره میکنند و این اطلاعات را در KV Cache نگه میدارند.
Cache هم یعنی محل نگهداری حافظه کوتاهمدت. مثل کامپیوتر شخصیتان که وقتی کند میشود، معمولا کش مرورگر یا سیستم را خالی میکنید تا پردازش سریعتر شود.
Continuous Batching چیست؟
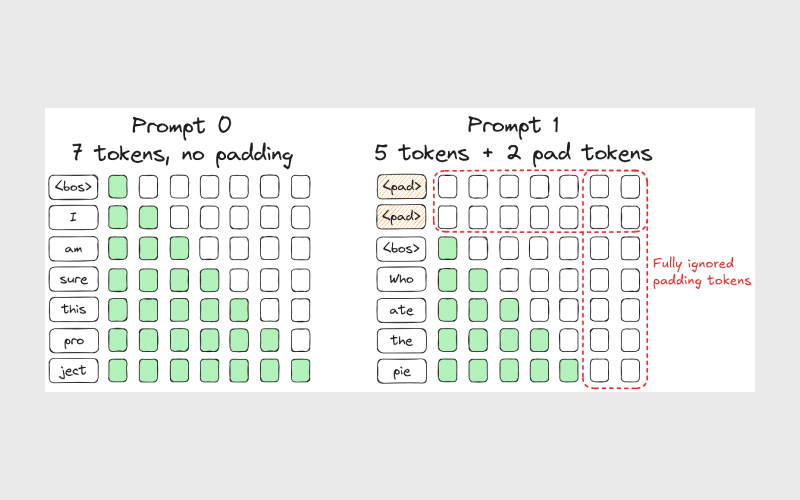
Continuous Batching تکنیکی است که برای پردازش همزمان چندین کوئری استفاده میشود تا راندمان و سرعت کلی سیستم افزایش پیدا کند. فرض کنید یک چتبات در هر دقیقه هزاران درخواست دریافت میکند. بسیاری از این درخواستها شبیه هم هستند، مثل:
- «پایتخت هند چیست؟»
- «پایتخت ایرلند چیست؟»
هر دو درخواست شامل عبارت مشترک «?what is the capital of» هستند؛ یعنی رشتهای از توکنها که مدل باید برای درک آنها محاسبات سنگینی انجام دهد. vLLM این امکان را فراهم میکند که چتبات این رشته مشترک از توکنها را در حافظه کوتاهمدت (KV Cache) نگه دارد و یک بار آن را پردازش کند، بهجای اینکه برای هر کوئری مجزا دوباره همان محاسبات را انجام دهد.
به بیان دیگر، vLLM باعث میشود KV Cache بتواند بخشی از حافظه محاسباتی را نگه دارد و برای درخواستهای مشابه از آن میانبُر بسازد. پردازش این کوئریهای مشابه در قالب یک Batch (بهجای پردازش تکبهتک) باعث افزایش Throughput و بهینهشدن مصرف حافظه میشود.
در نهایت، vLLM کمک میکند مصرف حافظه بهینهتر شود و ظرفیت پردازش توکن برای Batchهای بزرگتر و تسکهایی با کانتکست طولانی افزایش پیدا کند.
چرا vLLM در حال تبدیلشدن به استانداردی برای بهبود عملکرد LLMهاست؟
الگوریتم اصلی که از vLLM معرفی شد PagedAttention است، اما توانمندیهای vLLM فقط به همین ویژگی محدود نمیشود. این کتابخانه مجموعهای از بهینهسازیهای مهم فراهم میکند که میتواند عملکرد مدلهای زبانی را به شکل قابلتوجهی ارتقا دهد، از جمله:
۱. PyTorch Compile / CUDA Graph: برای بهینهسازی مصرف حافظه GPU و کاهش سربار پردازشی.
۲. Quantization (کوانتایز): کاهش دقت وزنها برای کمکردن فضای حافظه و اجرای مدلها با منابع کمتر بدون افت محسوس در کیفیت خروجی.
۳. Tensor Parallelism: تقسیمکردن بار پردازش بین چند GPU تا کارها سریعتر و مقیاسپذیرتر انجام شوند.
۴. Speculative Decoding: روشی برای افزایش سرعت تولید متن؛ یک مدل کوچکتر توکنهای احتمالی را پیشبینی میکند و یک مدل بزرگتر این پیشبینی را تایید میکند. ترکیب این دو، تولید متن را بهطور قابلتوجهی سرعت میدهد.
۵. Flash Attention: بهینهسازی اجرای Transformerها از طریق کاهش عملیات غیرضروری و استفاده کارآمد از حافظه.
انعطافپذیری؛ یکی از دلایل محبوبیت vLLM
علاوه بر بهینهسازیهای بالا، vLLM بهدلیل انعطافپذیری بالای خود نیز محبوب شده است:
- با مدلهای کوچک و بزرگ بهخوبی کار میکند.
- با فریمورکها و مدلهای محبوب سازگاری دارد و بهراحتی در معماریهای مختلف ادغام میشود.
- متنباز بودن آن باعث شفافیت کامل کد، امکان سفارشیسازی، و رفع سریعتر باگها میشود.
نتیجهگیری
vLLM تنها یک ابزار کمکی برای LLMها نیست، بلکه یک زیرساخت جدید برای اجرای مدلهای هوش مصنوعی در مقیاس بالا است. چه در حال توسعه یک چتبات باشید، چه یک موتور تولید محتوا یا سیستم تحلیل زبان، vLLM میتواند سرعت، پایداری و هزینههای شما را بهطور چشمگیری بهبود دهد.
با ترکیبی از تکنیکهایی مثل PagedAttention، Continuous Batching، Quantization، Tensor Parallelism و Flash Attention، این کتابخانه توانسته است اجرای مدلهای زبانی را به سطحی برساند که برای بسیاری از سازمانها قبلا دستنیافتنی بود.
اوپنسورس بودن و انعطافپذیری بالا نیز vLLM را به گزینهای جذاب برای تیمهای فنی تبدیل کرده است. در نهایت، اگر به دنبال ساخت سرویسهای مبتنیبر LLM با عملکرد بهتر و هزینه کمتر هستید، vLLM یکی از بهترین انتخابهاست.
منابع
سوالات متداول
خیر. vLLM با مدلهای کوچک و بزرگ بهطور کامل سازگار است و میتواند برای کاربردهای سبک تا پروژههای سازمانی با ترافیک بالا استفاده شود.
vLLM روی بیشتر GPUهای سازگار با CUDA اجرا میشود. هرچه GPU حافظه بیشتری داشته باشد، بهرهوری vLLM نیز بیشتر خواهد بود اما استفاده از آن حتما نیازمند سختافزارهای گرانقیمت نیست.
بله. بهینهسازی حافظه و افزایش توان پردازشی باعث میشود تعداد GPUهای کمتری برای اجرای مدل لازم باشد، که به کاهش مستقیم هزینهها منجر میشود.
Transformers برای کارهای پژوهشی و توسعه مدلها عالی است اما vLLM برای اجرای مدلها در محیط Production طراحی شده و روی سرعت، بهرهوری حافظه و مقیاسپذیری تمرکز دارد.
بله. vLLM متنباز است و توسعهدهندگان میتوانند آن را مطابق نیازهای پروژه خود تغییر دهند یا با معماریهای موجود ادغام کنند.




دیدگاهتان را بنویسید