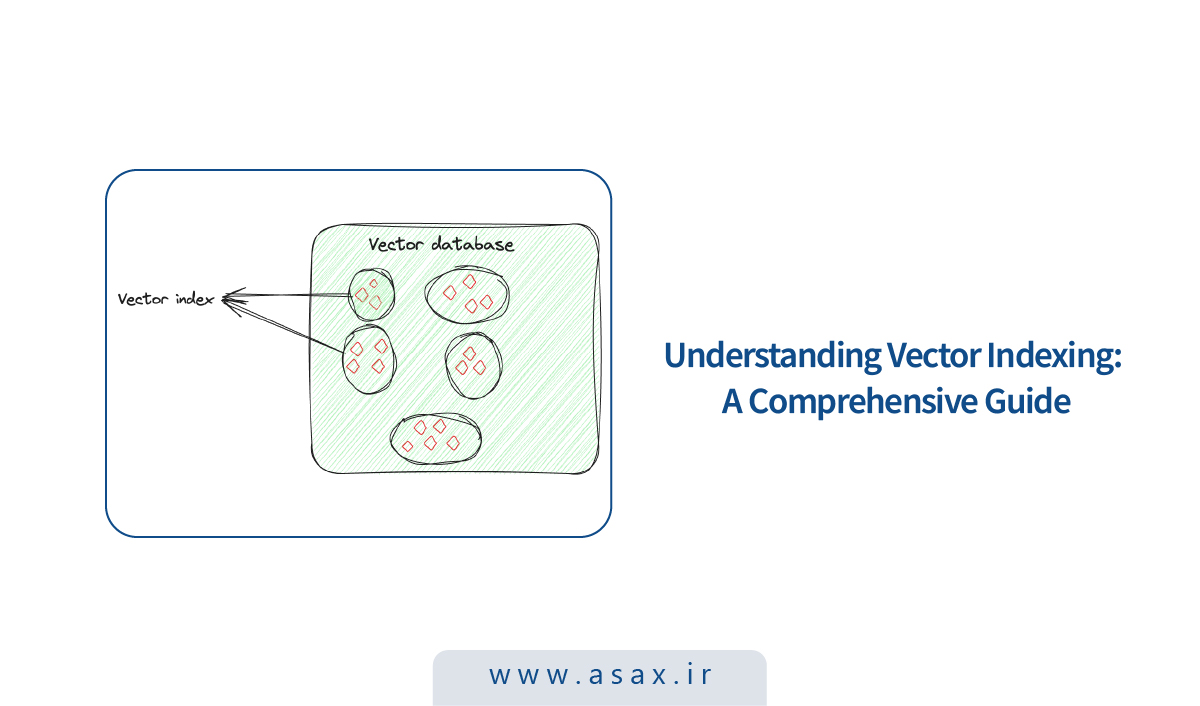
ایندکسگذاری مدتهاست یکی از ابزارهای مهم در مدیریت پایگاه داده به شمار میآید و کمک میکند اطلاعات با سرعت بالا بازیابی شوند. مشابه کاری که فهرست یک کتابخانه انجام میدهد و شما را سریع به کتاب موردنظر میرساند، ایندکس در دیتابیس هم مسیر دسترسی به داده را کوتاه و مستقیم میکند. در RAG، ایندکسگذاری برداری همین ایده را یک قدم جلوتر میبرد و امکان میدهد از میان یک پایگاه دانشی، اطلاعات مرتبط با هر درخواست را سریع و دقیق پیدا کنیم.
در این بخش از مجموعه مقالات RAG پیشرفته، وارد مبانی Vector Indexing میشویم و بررسی میکنیم این مفهوم با چه تکنیکهایی پیادهسازی میشود. وقتی قدرت ایندکسگذاری برداری را درست بشناسید، میتوانید از ظرفیت کامل اپلیکیشنهای مبتنی بر RAG استفاده کنید و خروجیهایی تولید کنید که هم دقیقترند و هم از نظر زمینه و کانتکست غنیتر. بیایید شروع کنیم و ببینیم Vector Indexing چطور میتواند استراتژیهای Retrieval Augmented Generation را ارتقا دهد.
بردارهای امبدینگ (Vector Embeddings) چیست؟
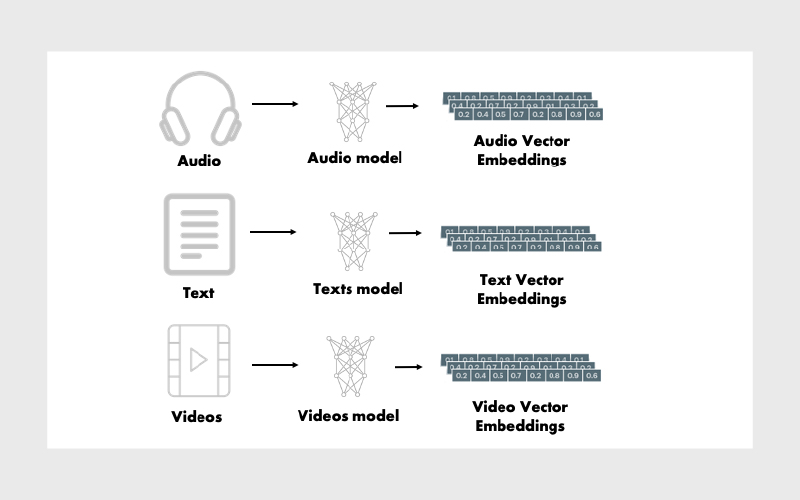
Vector Embedding یا همان بردارهای امبدینگ در سادهترین تعریف، یک نمایش عددی از دادههاست که از ورودیهایی مثل تصویر، متن یا صدا تولید میشود. یعنی برای هر آیتم، یک بردار ریاضی ساخته میشود که معنا (semantics) یا ویژگیهای آن آیتم را در خودش خلاصه میکند. این بردارها برای سیستمهای محاسباتی قابلفهمتر هستند و به مدلهای یادگیری ماشین کمک میکنند شباهتها و رابطهی بین آیتمهای مختلف را بهتر تشخیص دهند.
پایگاههای دادهای که بهصورت تخصصی برای ذخیرهسازی این بردارهای تعبیهسازیشده استفاده میشوند، Vector Database نام دارند. این دیتابیسها از ویژگیهای ریاضی embeddingها استفاده میکنند تا آیتمهای مشابه را نزدیک هم نگه دارند. برای این کار، از تکنیکهای مختلفی استفاده میشود تا بردارهای مشابه کنار هم و بردارهای غیرمشابه، دور از هم ذخیره شوند. به این روشها، تکنیکهای ایندکسگذاری برداری (Vector Indexing Techniques) گفته میشود.
ایندکس برداری (Vector Index) چیست؟
ایندکسگذاری برداری فقط «ذخیرهکردن داده» نیست؛ هدف اصلی آن سازماندهی هوشمندانه امبدینگها برای بهینهکردن فرایند بازیابی است. در این روش، با استفاده از الگوریتمهای پیشرفته، بردارهای با بُعد بالا (High-dimensional) به شکلی مرتب میشوند که قابل جستوجو و کارآمد باشند. این چینش اتفاقی نیست؛ بهگونهای انجام میشود که بردارهای مشابه کنار هم قرار بگیرند. نتیجه این است که میتوان جستوجوی شباهت (Similarity Search) و شناسایی الگوها را با سرعت و دقت بالا انجام داد؛ مخصوصا وقتی با دیتاستهای بزرگ و پیچیده سروکار داریم.
فرض کنید برای هر تصویر یک بردار دارید که ویژگیهای آن تصویر را نمایندگی میکند. Vector Index این بردارها را طوری سازماندهی میکند که پیدا کردن تصاویر مشابه سادهتر شود. میتوانید این موضوع را مثل این در نظر بگیرید که عکسهای هر نفر را جداگانه دستهبندی کردهاید؛ در این حالت اگر دنبال عکس یک نفر در یک رویداد مشخص باشید، لازم نیست بین همه عکسها بگردید؛ فقط سراغ مجموعه همان فرد میروید و سریعتر به تصویر موردنظر میرسید.
تکنیکهای رایج ایندکسگذاری برداری
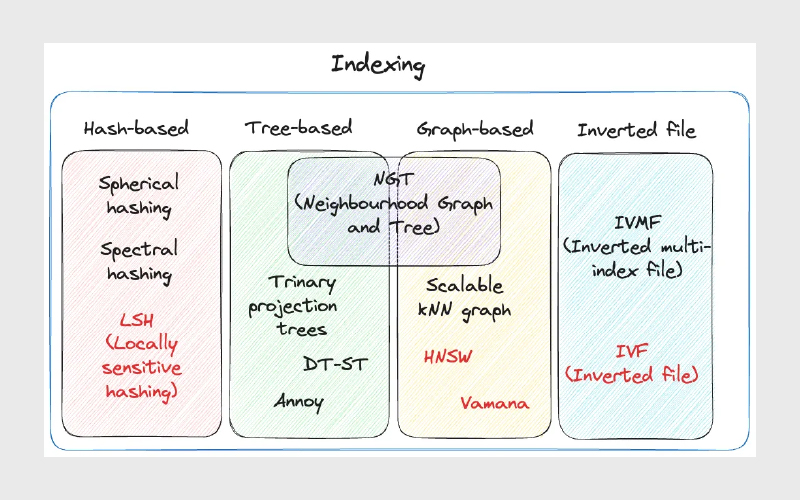
بسته به نیازهای سیستم و محدودیتهایی مثل حجم داده، دقت، سرعت و هزینه محاسباتی، از تکنیکهای متفاوتی برای ایندکسگذاری استفاده میشود. در ادامه، چند مورد از روشهای رایج را مرور میکنیم.
۱- Inverted File (IVF)
IVF یکی از سادهترین و رایجترین تکنیکهای ایندکسگذاری است. در این روش، کل داده به چند خوشه (Cluster) تقسیم میشود؛ معمولا با الگوریتمهایی مثل K-means. سپس هر بردارِ موجود در دیتابیس به یکی از این خوشهها نسبت داده میشود.
این ساختار باعث میشود اجرای کوئریهای جستوجو خیلی سریعتر شود. وقتی یک کوئری جدید وارد سیستم میشود، لازم نیست کل دیتاست پیمایش شود. سیستم ابتدا نزدیکترین یا مشابهترین خوشهها را پیدا میکند و بعد فقط داخل همان خوشهها به دنبال آیتم یا سند مرتبط میگردد.
به این ترتیب، به جای اینکه جستوجوی brute-force روی کل پایگاه داده انجام شود، این کار فقط روی خوشههای مرتبط انجام میشود؛ نتیجه هم افزایش محسوس سرعت جستوجو و کاهش قابلتوجه زمان پاسخگویی (Query Time) است.
IVF بسته به نیازهای اپلیکیشن (مثل حجم داده، محدودیت حافظه، و حساسیت به دقت) چند واریانت رایج دارد. در ادامه هر کدام را دقیقتر بررسی میکنیم.
۱- IVFFLAT
IVFFLAT نسخه سادهتری از IVF است. این روش هم دیتاست را به چند خوشه تقسیم میکند اما داخل هر خوشه از یک ساختار Flat (به معنی بدون لایهبندی یا ساختار سلسلهمراتبی) برای نگهداری بردارها استفاده میشود.
در هر خوشه، بردارها معمولا به شکل یک لیست یا آرایه ساده ذخیره میشوند. وقتی بردار کوئری به یک خوشه نسبت داده شد، نزدیکترین همسایه با یک جستوجوی brute-force داخل همان خوشه پیدا میشود؛ یعنی فاصله کوئری با تکتک بردارهای آن خوشه محاسبه میشود تا نزدیکترین مورد مشخص شود.
از IVFFLAT معمولا وقتی استفاده میشود که دیتاست خیلی بزرگ نیست و هدف، رسیدن به دقت بالا در جستوجو است؛ در عین حال، با محدود کردن جستوجو به خوشههای مرتبط، سرعت هم نسبت به brute-force روی کل دیتابیس بهتر میشود.
۲- IVFPQ
IVFPQ نسخه پیشرفتهتری از IVF است و مخفف Inverted File with Product Quantization است. این روش هم داده را خوشهبندی میکند اما داخل هر خوشه، هر بردار به چند بخش کوچکتر تقسیم میشود و هر بخش با تکنیک Product Quantization به یک نمایش فشرده (encoded/compressed) با تعداد بیت محدود تبدیل میشود.
در زمان جستوجو، بعد از اینکه خوشههای مرتبط پیدا شدند، الگوریتم به جای مقایسه بردارهای خام، نمایش quantized کوئری را با نمایش quantized بردارهای داخل خوشه مقایسه میکند. چون این نمایشها کوچکتر و کمحجمترند، مقایسه سریعتر انجام میشود.
این روش نسبت به IVFFLAT دو مزیت اصلی دارد:
- بردارها به شکل فشرده ذخیره میشوند و فضای ذخیرهسازی کمتری نسبت به بردار خام نیاز دارند.
- فرایند جستوجو سریعتر است، چون مقایسه روی بردارهای encode شده انجام میشود، نه روی بردارهای خام.
۳-IVFSQ
IVFSQ (Inverted File with Scalar Quantization) مثل سایر واریانتهای IVF داده را به خوشهها تقسیم میکند اما تفاوت اصلی آن در نوع quantization است. در IVFSQ، هر بردار داخل خوشه با Scalar Quantization فشرده میشود؛ یعنی هر بُعد (dimension) بردار بهصورت جداگانه پردازش و کوانتیزه میشود.
به بیان سادهتر، برای هر بُعد از بردار یک مقدار یا بازه از پیش تعریفشده در نظر گرفته میشود. سپس هر مولفه بردار با این مقدارها یا بازهها تطبیق داده میشود تا جایگاهش مشخص شود. این رویکرد که هر بُعد را جداگانه encode میکند، پیادهسازی را سرراستتر میکند و معمولا برای دادههای کمبعدتر کاربردیتر است، چون هم فرایند encoding سادهتر میشود و هم فضای ذخیرهسازی کاهش پیدا میکند.
الگوریتم HNSW (Hierarchical Navigable Small World) یکی از روشهای پیشرفته برای ذخیرهسازی و بازیابی کارآمد داده است. این الگوریتم یک ساختار شبیه گراف دارد و ایده اصلیاش را از ترکیب دو مفهوم میگیرد: Skip List و Navigable Small World (NSW).
برای اینکه HNSW را بهتر بفهمیم، ابتدا باید با مفاهیم پایهای مرتبط با آن آشنا شویم.
Skip List
Skip List یک ساختار داده پیشرفته است که مزیتهای دو ساختار کلاسیک را ترکیب میکند:
- قابلیت درج سریع مثل Linked List
- قابلیت دسترسی و جستوجوی سریع مثل Array
این ساختار با یک معماری چندلایه به این هدف میرسد. دادهها در چند لایه سازماندهی میشوند، بهطوریکه هر لایه فقط زیرمجموعهای از نقاط داده را نگه میدارد.
- در پایینترین لایه، همه نقاط داده حضور دارند.
- هرچه به لایههای بالاتر میرویم، بعضی نقاط «پرش» داده میشوند و تعداد نقاط کمتر میشود.
- در نهایت، بالاترین لایه کمترین تعداد نقطه را دارد.
برای جستوجوی یک مقدار در Skip List، از بالاترین لایه شروع میکنیم و از چپ به راست جلو میرویم. هرجا که مقدار موردنظر از مقدار نقطه فعلی بزرگتر باشد، به حرکت ادامه میدهیم. وقتی به نقطهای برسیم که دیگر نمیتوانیم در همان لایه جلو برویم، به لایهی پایینتر میرویم و جستوجو را از همان حوالی ادامه میدهیم تا در نهایت به مقدار دقیق برسیم.
NSW شبیه یک گراف مجاورت (Proximity Graph) عمل میکند؛ یعنی نودها بر اساس میزان شباهت به هم وصل میشوند. برای پیدا کردن نزدیکترین همسایه (Nearest Neighbor) هم از یک روش حریصانه استفاده میشود.
فرایند معمولا اینطور است:
- از یک نقطه شروع (Entry Point) که از قبل تعیین شده آغاز میکنیم.
- این نقطه به چند نود نزدیک متصل است.
- بررسی میکنیم کدام نود به بردار کوئری ما نزدیکتر است و به همان نود حرکت میکنیم.
- این حرکت تکرار میشود تا به جایی برسیم که هیچ نودی نزدیکتر از نود فعلی نسبت به کوئری وجود نداشته باشد؛ این نقطه شرط توقف الگوریتم است.
HNSW چگونه ساخته میشود؟
در HNSW ایده لایهبندی را از Skip List میگیریم؛ یعنی ساختاری چندلایه ایجاد میشود. اما برای اتصال نقاط داده، بهجای لینکهای ساده، بین نودها یک اتصال گرافمحور شکل میگیرد. نودهای هر لایه فقط به نودهای همان لایه وصل نیستند، بلکه به نودهای لایههای پایینتر هم ارتباط دارند.
در لایههای بالایی تعداد نودها خیلی کم است و هرچه به لایههای پایینتر میرویم، تراکم نودها بیشتر میشود. در نهایت، آخرین لایه شامل تمام نقاط دادهی دیتابیس است. این همان نمای کلی معماری HNSW است.
کوئری جستوجو در HNSW چگونه اجرا میشود؟
الگوریتم از یک نود از پیش تعیینشده در بالاترین لایه شروع میکند. سپس فاصله بردار کوئری را با نودهای متصل در لایهی فعلی و همچنین نودهایی که در لایهی پایینتر در دسترساند محاسبه میکند.
اگر در لایه پایینتر نودی پیدا شود که فاصلهاش از کوئری کمتر از نزدیکترین نودهای لایه فعلی باشد، الگوریتم به لایه پایینتر منتقل میشود. این فرایند ادامه پیدا میکند تا یکی از این دو حالت رخ دهد:
- به آخرین لایه برسد
- یا به نودی برسد که نسبت به همهی نودهای متصل، کمترین فاصله را با کوئری دارد (شرط توقف)
لایه نهایی شامل همه نقاط داده است و یک نمایش کامل و جزئی از دیتاست ارائه میدهد. این لایه اهمیت زیادی دارد چون باعث میشود جستوجو تمام گزینههای ممکن برای نزدیکترین همسایهها را در نظر بگیرد.
مشابه تفاوتی که بین IVFFLAT و IVFSQ وجود دارد (یکی ذخیرهی بردار خام، دیگری ذخیرهی داده کوانتیزهشده)، در HNSW هم دو واریانت رایج داریم:
- HNSWFLAT: بردارهای خام همانطور که هستند ذخیره میشوند.
- HNSWSQ: بردارها به شکل Quantized ذخیره میشوند.
بهجز این تفاوت مهم در شیوه ذخیرهسازی، بقیه فرایند ایندکسسازی و جستوجو در هر دو روش تقریبا یکسان است.
۱- الگوریتم Multi-Scale Tree Graph (MSTG)
ایندکسگذاری استاندارد Inverted File (IVF) یک دیتاست برداری را به تعداد زیادی خوشه تقسیم میکند، در حالی که HNSW یک گراف سلسلهمراتبی روی دادههای برداری میسازد. با این حال، این روشها یک محدودیت جدی دارند: در دیتاستهای بسیار بزرگ، اندازه ایندکس به شکل قابلتوجهی رشد میکند و معمولا لازم است همه دادههای برداری در حافظه (RAM) نگهداری شوند.
راهکارهایی مثل DiskANN میتوانند ذخیرهسازی بردارها را به SSD منتقل کنند اما در عوض ساخت ایندکس کندتر میشود و عملکرد آن در جستوجوی فیلترشده (Filtered Search) چندان خوب نیست.
MSTG (Multi-Scale Tree Graph) الگوریتمی است که توسط MyScale توسعه داده شده و تلاش میکند این محدودیتها را با ترکیب چند ایده کنار بزند: خوشهبندی درختیِ سلسلهمراتبی بههمراه پیمایش گراف و استفاده همزمان از حافظه و SSDهای NVMe پرسرعت.
MSTG در مقایسه با IVF/HNSW مصرف منابع را به شکل محسوسی کاهش میدهد و در عین حال، عملکرد بسیار خوبی حفظ میکند. این روش هم سریع ایندکس میسازد، هم سریع جستوجو میکند و در نسبتهای مختلف جستوجوی فیلترشده هم سریع و دقیق باقی میماند؛ در کنار اینها، از نظر منابع و هزینه هم بهینهتر عمل میکند.
۲- HNSWSQ چیست؟
HNSWSQ یکی از واریانتهای HNSW است که بهجای ذخیرهسازی بردارهای خام، آنها را به شکل Quantized نگه میدارد. تفاوت اصلی این روش با HNSWFLAT دقیقا همین نقطه است: در HNSWFLAT بردارها همانطور که هستند ذخیره میشون اما در HNSWSQ بردارها قبل از ذخیرهسازی از طریق Scalar Quantization (SQ) فشرده میشوند؛ یعنی هر بُعد از بردار بهصورت جداگانه کوانتیزه میشود تا حجم داده کمتر شود.
این کار باعث میشود مصرف حافظه کاهش پیدا کند و در بسیاری از سناریوها، بهخصوص وقتی دیتاست بزرگ است، جستوجو هم سریعتر و اقتصادیتر انجام شود. البته چون بردارها بهصورت تقریبی ذخیره شدهاند، ممکن است نسبت به حالت FLAT کمی افت دقت داشته باشیم. با این حال، ساختار گراف، منطق ایندکسسازی و مسیر جستوجو در HNSWSQ همان HNSW است و فقط شیوه ذخیرهسازی و محاسبه فاصله روی نمایش فشرده تغییر میکند.
جمعبندی
ایندکسگذاری برداری بخش کلیدی RAG است، چون تعیین میکند امبدینگها چطور سازماندهی شوند تا جستوجوی شباهت سریع و دقیق انجام شود. در این مقاله دیدیم که Vector Embedding نمایش عددی دادههاست و Vector Database با تکیه بر آن، بازیابی اطلاعات مرتبط را در مقیاس بالا ممکن میکند.
در ادامه با تکنیکهای رایج آشنا شدیم: IVF با خوشهبندی دامنه جستوجو را محدود میکند و واریانتهای آن (IVFFLAT، IVFPQ، IVFSQ) بین دقت، سرعت و مصرف منابع توازن ایجاد میکنند. HNSW هم با گراف سلسلهمراتبی بازیابی را سریعتر میکند و در HNSWSQ با کوانتیزهسازی، مصرف حافظه کاهش پیدا میکند. در نهایت، MSTG تلاش میکند در دیتاستهای بزرگ، با ترکیب ساختار درختی و گراف و استفاده از NVMe، هم عملکرد را حفظ کند و هم هزینه منابع را پایین بیاورد.
منابع
سوالات متداول
Vector Embedding یک نمایش عددی از داده (متن، تصویر، صدا و…) است که معنا و ویژگیهای اصلی آن را در قالب یک بردار ذخیره میکند. تفاوتش با داده خام این است که بهجای کار با متن یا پیکسلها، با یک بردار عددی کار میکنیم که برای سنجش شباهت و بازیابی، بسیار مناسبتر است.
Vector Index امبدینگها را طوری سازماندهی میکند که برای پیدا کردن نزدیکترین موارد لازم نباشد کل دیتاست پیمایش شود. در RAG، این یعنی مرحله بازیابی سریعتر و دقیقتر انجام میشود و مدل میتواند کانتکست مرتبطتری دریافت کند؛ در نتیجه خروجی نهایی بهتر میشود.
IVF وقتی خوب است که دیتاست بزرگ باشد و بخواهید با خوشهبندی، دامنهی جستوجو را محدود کنید.
– IVFFLAT داخل خوشهها بردار خام را نگه میدارد و معمولا دقت بالاتری میدهد.
– IVFPQ بردارها را با Product Quantization فشرده میکند تا حافظه کمتر مصرف شود و جستوجو سریعتر شود.
– IVFSQ با Scalar Quantization هر بُعد را جداگانه کوانتیزه میکند و برای کاهش حجم و سادهتر شدن ذخیرهسازی کاربردی است.
HNSW یک گراف سلسلهمراتبی میسازد تا جستوجو از لایههای بالاتر شروع شود و خیلی سریع به نواحی نزدیکتر برسد. در HNSWSQ همین ساختار حفظ میشود اما بردارها به شکل کوانتیزه ذخیره میشوند تا مصرف حافظه پایین بیاید و در دیتاستهای بزرگ، جستوجو اقتصادیتر شود (با احتمال افت دقت جزئی نسبت به حالت FLAT).
بهطور کلی:
– اگر دیتاست خیلی بزرگ نیست و دقت مهمتر است، IVFFLAT یا HNSWFLAT گزینههای خوبیاند.
– اگر محدودیت حافظه/هزینه دارید، سراغ واریانتهای Quantized مثل IVFPQ/IVFSQ/HNSWSQ بروید.
– اگر با دیتاستهای بسیار بزرگ و نیاز جدی به کارایی و هزینهی بهینه روبهرو هستید (بهخصوص در سناریوهای فیلترشده)، روشهایی مثل MSTG که برای مقیاس طراحی شدهاند میتوانند انتخاب مناسبتری باشند.

دیدگاهتان را بنویسید