
تابهحال فکر کردهاید که کامپیوتر چگونه زبان انسانی ما را درک میکند؟ وقتی عبارتی را در گوگل یا سایر موتورهای جستجو وارد میکنیم، چگونه نتایج مرتبط از میان حجم انبوهی از اطلاعات برایمان نمایان میشوند؟ پردازش زبان طبیعی (NLP)، شاخهای از هوش مصنوعی است که به تعامل میان انسان و ماشین از طریق زبان طبیعی میپردازد. این فناوری مهم تلاش میکند تا رایانهها بتوانند زبان انسان را درک، تفسیر و حتی تولید کنند. شاید برایتان جالب باشد که از جستجوی صوتی در گوشیهای هوشمند گرفته تا چتباتهای مختلف، همگی از ثمرات و نتایج استفاده از پردازش زبان طبیعی هستند.
اهمیت بالای NLP و تاثیر بسیار زیادی که در فناوری هوش مصنوعی گذاشته است، باعث میشود افراد زیادی بهدنبال آشنایی با مفاهیم و موضوعات مختلف آن باشند. در واقع داشتن تسلط کامل روی این حوزه مهم، مسیر پیشرفت و موفقیت را برای علاقهمندان AI هموارتر میکند. در این مقاله از بلاگ آسا، بهطور کامل شما را با پردازش زبان طبیعی آشنا میکنیم و از زوایای مختلف به بررسی موضوعات مهم آن میپردازیم.
پردازش زبان طبیعی (NLP) چیست؟

NLP مخفف Natural Language Processing به معنای پردازش زبان طبیعی است. NLP شاخهای از هوش مصنوعی محسوب میشود که هدف اصلی آن، تعامل میان انسان و ماشین از طریق زبان انسانی است. به عبارت سادهتر، NLP تلاش میکند توانایی درک، تفسیر و تولید زبان انسان (چه بهصورت گفتار و چه بهصورت نوشتار) را به ماشینها بدهد. مثلا، پلتفرمهای ترجمه زبان مانند Google Translate از NLP استفاده میکنند. این مترجمها با استفاده از الگوریتمهای پیچیده NLP، ساختار و معنای متن ورودی را تجزیه و تحلیل میکنند و پس از ترجمه آن به زبان مقصد، یک خروجی قابل فهم ارائه میدهند. بهطور کلی، هدف پردازش زبان طبیعی این است که کامپیوترها، گفتار و نوشتار انسان را با دقتی مشابه انسان درک کنند.
نحوه کار پردازش زبان طبیعی
البته باید بدانید که این فرایند ساده نیست. در واقع، پشت این تعامل پیچیده، ترکیبی از زبانشناسی رایانشی، یادگیری ماشین، مدلسازی آماری و یادگیری عمیق قرار دارد. NLP با تلفیق این تکنیکها، به سیستمها کمک میکند تا بتوانند مفاهیم را از زبان استخراج و حتی پاسخ مناسب تولید کنند. فرقی نمیکند که این ورودی گفتاری باشد یا نوشتاری! همانطور که انسانها حسگرهای مختلفی دارند (مانند گوش برای شنیدن و چشم برای دیدن) کامپیوترها هم حسگرهایی برای خواندن و میکروفونهایی برای جمعآوری صدا دارند. برای مثال، وقتی با یک دستیار صوتی مانند Siri یا Alexa صحبت میکنید، در واقع در حال استفاده از قابلیتهای پردازش زبان طبیعی هستید.
مقایسه NLP، NLU و NLG در پردازش زبان طبیعی

پردازش زبان طبیعی، یکی از شاخههای اصلی هوش مصنوعی، به مطالعه و توسعهی سیستمهایی میپردازد که قادر به تعامل با زبان انسانی باشند. این حوزه شامل زیرشاخههای مختلفی است که هر کدام بخشی از چرخهی پردازش زبان را پوشش میدهند. دو مفهوم کلیدی که در این زمینه اهمیت دارند، فهم زبان طبیعی و تولید زبان طبیعی هستند.
- NLP: بهعنوان یک چارچوب گسترده، شامل تمام فرایندهایی است که یک ماشین را قادر میسازد زبان انسانی را پردازش کند. این فرایندها میتوانند شامل تجزیهی جملات، استخراج اطلاعات، ترجمهی ماشینی و حتی تحلیل احساسات باشند. ابزارهای NLP عمدتا درکی کلی از دادههای متنی ارائه میدهند و بر جنبههای محاسباتی تمرکز دارند، نظیر تحلیل دستوری و کلمهبرداری.
- NLU: فهم زبان طبیعی زیرمجموعهای از NLP است که هدف اصلی آن، تفسیر معنایی و استنتاجهای عمیق از متون است. سیستمهای NLU تلاش میکنند تا نهتنها متن را پردازش کنند، بلکه معنای پنهان در پشت عبارات را درک کنند. بهعنوان مثال، درک جملاتی با ابهام معنایی یا پیچیدگیهای زبانی، مثل کنایه یا اصطلاحات خاص فرهنگی، در حوزهی NLU قرار میگیرد.
- NLG: برخلاف NLU که بر درک تمرکز دارد، تولید زبان طبیعی به تولید محتوا توسط ماشین میپردازد. هدف NLG این است که متنی مشابه انسان تولید شود که برای خواننده قابل فهم و طبیعی باشد. برای مثال، تولید گزارشهای مالی یا محتوای خبری بهصورت خودکار، یکی از کاربردهای NLG است. این فرایند شامل انتخاب کلمات، تنظیم ساختار جملات و رعایت قوانین دستوری است.
NLP بهعنوان چارچوب اصلی، بنیانی برای توسعه سیستمهای NLU و NLG فراهم میکند. در حالی که NLU بر تحلیل عمیق زبان تمرکز دارد، NLG به تولید خروجی مناسب معطوف است. این دو حوزه بهصورت مکمل عمل میکنند و در بسیاری از سیستمهای مدرن، بهویژه چتباتها یا سیستمهای تولید محتوای خودکار، بهطور همزمان کاربرد دارند.
مراحل پردازش زبان طبیعی
دو مرحله اصلی برای پردازش زبان طبیعی وجود دارد:
مرحله اول: پیشپردازش دادهها
پیشپردازش دادهها مانند آماده کردن مواد اولیه قبل از پختن یک وعده غذایی است. در این مرحله، دادههای ورودی جداسازی و سازماندهی میشوند تا کامپیوتر بتواند آن را بفهمد و با آن کار کند. در ادامه، آنچه در طول پیشپردازش دادهها در NLP اتفاق میافتد را مرحله به مرحله شرح میدهیم:
- پاکسازی متن: عناصر غیرضروری مانند علائم نگارشی، کاراکترهای خاص و فاصلههای اضافی از متن حذف میشوند. این کار پردازش را برای کامپیوتر آسانتر میکند.
- توکنسازی: در این مرحله، متن به واحدهای کوچکتری (معمولا کلمات یا عبارتها) تقسیم میشود. این مرحله تجزیه و تحلیل و دستکاری متن را آسانتر میکند.
- تبدیل حروف بزرگ: در زبان انگلیسی، تمام متن به حروف کوچک تبدیل میشوند تا کلماتی مانند «hello» و «HELLO» به یک شکل درک شوند و سردرگمی از بین برود.
- حذف حروف اضافه: کلماتی مانند «با»، «از» و غیره از متن حذف میشوند؛ زیرا معنای مهمی ندارند و در تجزیه و تحلیل متن مشکل ایجاد میکنند.
- تبدیل کلمات مشابه: در این مرحله، کلماتی که معنی مشابهی دارند، یکسانسازی میشوند. مثلا، «پاسخ» و «جواب» یا «ویژه» و «مخصوص» معنیهای یکسانی دارند.
مرحله دوم: توسعه الگوریتم
پس از آمادهسازی مواد غذایی، باید دستور پخت را اجرا کنیم و مرحله توسعه الگوریتم دقیقا همان است. این مرحله شامل طراحی و ساخت روشها و تکنیکهایی است که کامپیوترها را قادر میسازد تا زبان انسان را بهطور موثر درک و پردازش کنند. مراحل زیر نشان میدهند که در طول فرایند توسعه الگوریتم چه اتفاقی میافتد:
- انتخاب الگوریتم: در این مرحله، الگوریتمها و تکنیکهای مناسب براساس وظیفه خاصی که کامپیوتر میخواهد انجام دهد، انتخاب میشوند. بهعنوان مثال، اگر در حال ساختن یک سیستم تحلیل احساسات هستیم، از الگوریتمهایی استفاده میکنیم که درک و دستهبندی احساسات بیانشده در متن را بهخوبی انجام دهند.
- آمادهسازی دادههای آموزشی: در این مرحله باید دادههای برچسبگذاریشده برای آموزش الگوریتمها جمعآوری شوند. مثلا، اگر در حال ساخت یک جداساز ایمیل هرزنامه باشیم، به مجموعه دادهای نیاز داریم که حاوی برچسب ایمیلهای هرزنامه (اسپم) و غیرهرزنامه باشد.
- مدلسازی: حالا با استفاده از الگوریتمهای انتخابشده و دادههای آموزشی، مدلی ساخته میشود که الگوها و روابط درون دادههای متنی را یاد بگیرد. در این مرحله، به کامپیوتر گفته میشود که چگونه متن را پردازش کند تا به نتیجه دلخواه برسد.
- آموزش: در این مرحله، دادههای آموزشی وارد مدل میشوند و با این کار، کامپیوتر الگوریتم را بهخوبی یاد میگیرد. در نتیجه، پارامترها و تنظیمات داخلی برای به حداقل رساندن خطاها و بهبود عملکرد، تنظیم میشوند.
- ارزیابی: حالا باید ببینیم که آیا الگوریتم با دادههای جدیدی که تا حالا ندیده هم کار میکند یا نه! در واقع این مرحله، چگونگی پاسخ الگوریتم به دادههای متنی جدید را نشان میدهد. مثل این است که غذا را بچشیم تا ببینیم خوشمزه است و انتظارات ما را برآورده میکند یا نه!
- بهینهسازی: اگر عملکرد مدل رضایتبخش نباشد، باید پارامترهای آن را به دقت تنظیم کنیم یا الگوریتمهای مختلفی را برای بهبود دقت و اثربخشی آن امتحان کنیم. یعنی همان اضافه کردن چاشنی برای رسیدن به طعم دلخواه!
- استقرار: در نهایت، هنگامی که از عملکرد مدل راضی شدیم، آن را در خروجی قرار میدهیم تا بتوان از آن برای پردازش دادههای متنی دنیای واقعی استفاده کرد.
آشنایی با الگوریتمهای NLP

مجموعهای از الگوریتمها و تکنیکها وجود دارند که به کامپیوترها این امکان را میدهد که زبان انسانی را درک، تفسیر و پاسخهایی مشابه آن، تولید کنند. برخی از الگوریتمهای مهم در این حوزه عبارتند از:
-
مدلهای مبتنی بر قوانین (Rule-Based Models): این الگوریتمها از مجموعهای از قوانین دستنویس زبانشناسی استفاده میکنند تا متون را تجزیه و تحلیل کنند.
-
مدلهای آماری: این مدلها با استفاده از تکنیکهای آماری، الگوها و روابط موجود در دادههای زبانی را شناسایی میکنند.
-
مدلهای یادگیری ماشین: الگوریتمهایی که با استفاده از دادههای آموزشی، توانایی یادگیری و بهبود عملکرد در وظایف زبانی را دارند.
-
مدلهای یادگیری عمیق: شبکههای عصبی عمیق که قادر به درک مفاهیم پیچیده زبانی هستند، در بسیاری از کاربردهای NLP استفاده میشوند.
بهترین الگوریتمهای NLP
در ادامه، به برخی از بهترین الگوریتمها و مدلهای مورد استفاده در پردازش زبان طبیعی اشاره میکنیم:
-
Naïve Bayes: یک الگوریتم ساده و کارآمد برای دستهبندی متون و تحلیل احساسات است.
-
LSTM (Long Short-Term Memory): نوعی شبکه عصبی بازگشتی است که برای پردازش و پیشبینی دادههای ترتیبی مانند متن استفاده میشود.
-
TF-IDF (Term Frequency-Inverse Document Frequency): روشی برای ارزیابی اهمیت یک کلمه در یک سند نسبت به کل مجموعه اسناد است و برای دستهبندی موضوعی کاربرد دارد.
تکنیکها و روشهای پردازش زبان طبیعی

پردازش زبان طبیعی برای درک و تفسیر زبان انسان، مجموعهای از تکنیکهای نحوی و معنایی را به کار میگیرد. این تکنیکها به الگوریتمها کمک میکنند تا ساختار گرامری جملات را تحلیل و معانی پنهان در آنها را استخراج کنند. بهطورکلی میتوان روشهای بهکاررفته در NLP را به دو دسته اصلی تحلیل نحوی (Syntax Analysis) و تحلیل معنایی (Semantic Analysis) تقسیم کرد:
تحلیل نحوی (Syntax Analysis)
تحلیل نحوی به ساختار گرامری جملات میپردازد و کمک میکند تا کامپیوتر بتواند جملهای را مطابق با قواعد زبان تفکیک و تفسیر کند. از مهمترین تکنیکهای نحوی میتوان به موارد زیر اشاره کرد:
- تجزیه (Parsing): تجزیه گرامری یک جمله به اجزای سخن مانند اسم و فعل (این کار برای فهم دقیقتر ساختار جمله ضروری است.)
- تقسیم کلمات (Word Segmentation): جدا کردن رشتهای از متن به واحدهای معنایی (در زبانهایی با ساختار پیوسته مانند چینی یا هنگام اسکن متون دستنویس اهمیت بالایی دارد.)
- شکستن جملهها (Sentence Breaking): شناسایی مرزهای جمله در متنهایی با حجم بالا (هدف این تکنیک پردازش واحدهای مستقل از معنا است.)
- تقسیمبندی واژگانی (Morphological Segmentation): تفکیک واژه به اجزای کوچکتری به نام «واجمعنا» (morpheme)؛ مانند تجزیه واژه untestably به اجزای «un»، «test»، «able» و «ly».
- ریشهیابی (Stemming): یافتن ریشه اصلی کلمات صرفشده برای کاهش پیچیدگی در تحلیل دادهها. (برای مثال: “barked” به “bark” تقلیل پیدا میکند.)
تحلیل معنایی (Semantic Analysis)
تحلیل معنایی به فهم دقیقتر معانی پنهان در کلمات و جملات میپردازد و برای کاربردهایی مانند ترجمه ماشینی یا تشخیص احساسات بسیار حیاتی است. از تکنیکهای معنایی پرکاربرد میتوان به موارد زیر اشاره کرد:
- تعیین معنای دقیق واژهها (Word Sense Disambiguation): انتخاب معنای صحیح واژههای چندمعنا براساس بافت جمله (برای مثال فرق بین «شیر» بهمعنای نوشیدنی یا حیوان)
- شناسایی موجودیتهای نامدار (Named Entity Recognition – NER): شناسایی اسامی اشخاص، مکانها، سازمانها و… در متن و تمایز بین آنها حتی در صورت تشابه ظاهری
- تولید زبان طبیعی (Natural Language Generation – NLG): تولید خودکار متنهای معنادار بر پایه دادهها (مانند نوشتن خلاصه گزارشهای مالی یا اخبار توسط الگوریتم)
NLP از چه تکنولوژیهایی استفاده میکند؟
پردازش زبان طبیعی از رویکردها و تکنولوژیهای مختلفی برای پردازش و درک زبان انسان استفاده میکند. اگر میخواهید درباره این موضوع بیشتر بدانید، در اینجا برخی از تکنولوژیهای رایج در NLP را توضیح میدهیم:
- تکنولوژی یادگیری ماشین: فناوری یادگیری ماشین در پردازش زبان طبیعی به معنی آموزش کامپیوترها برای درک زبان انسان است. در این تکنولوژی از دادههای آموزشی و نمونههای فراوان استفاده میشود تا کامپیوتر الگوها را یاد بگیرد و آنها را روی متنهای جدید اعمال کند.
- مدل شبکه عصبی: در این مدل، از یک شبکه عصبی مصنوعی استفاده میشود که شبیه مدلی ساده شده از مغز انسان است. از این شبکه، برای درک و تولید زبانی شبیه زبان انسان استفاده میشود. این فناوری به کامپیوترها کمک میکند تا زبان انسان را با دقت بیشتری درک کنند و برنامههایی مانند تصحیح و تکمیل خودکار جملات، باتهای گفتگو و سیستمهای تشخیص گفتار بسازند.
- رویکردهای آماری: هدف رویکردهای آماری در NLP به دست آوردن ویژگیهای آماری زبان است. تکنیکهایی مانند مدلهای n-gram، مدلهای پنهان مارکوف (HMM) و مدلهای گرافیکی احتمالی برای کارهایی مانند مدلسازی زبان، برچسبگذاری و تشخیص گفتار استفاده میشوند. این رویکردها برای تحلیل زبان، بر استنباط و تخمین آماری تکیه میکنند.
- رویکردهای واژگانی: رویکردهای واژگانی بر تجزیه و تحلیل کلمات و معانی آنها تمرکز دارند. منابع واژگانی مانند لغتنامهها و اصطلاحنامهها برای استخراج اطلاعات معنایی استفاده میشوند. در این رویکرد، از روشهای مختلفی برای سازماندهی لغات مترادف یا هممعنا استفاده میشود.
- رویکردهای معنایی: در رویکردهای معنایی، هدف درک کل متن است، نه فقط درک تک به تک کلمات! این رویکردها بر معناشناسی جملات و اسناد تمرکز میکنند. تکنیکهایی مانند تشابه معنایی برای به دست آوردن معنا و روابط بین کلمات و حتی عبارات استفاده میشوند.
- رویکردهای ترکیبی: در رویکردهای ترکیبی، چندین تکنیک و مدل برای انجام وظایف مختلف NLP ترکیب میشوند. به عنوان مثال، یک رویکرد ترکیبی ممکن است از یک تکنولوژی مبتنی بر قانون برای تجزیه و تحلیل اولیه و سپس از تکنیکهای یادگیری ماشین برای تجزیه و تحلیل بیشتر استفاده کند. این رویکردها از نقاط قوت روشهای مختلف برای بهبود عملکرد و رفع محدودیتهای رویکردهای فردی استفاده میکنند.
زبانهای برنامهنویسی رایج NLP
پردازش زبان طبیعی را میتوان با استفاده از زبانهای برنامهنویسی مختلف پیادهسازی کرد. برخی از زبانهای برنامهنویسی رایج NLP عبارتند از:
- پایتون: این زبان بهدلیل داشتن کتابخانهها و فریمورکهای گسترده، در NLP پرکاربرد است. این ابزارها مانند NLTK، spaCy و TensorFlow قابلیتهای قدرتمندی برای پردازش متن، یادگیری ماشین و یادگیری عمیق ارائه میدهند.
- جاوا: فریمورکهای مختلف جاوا مانند Stanford CoreNLP و Apache OpenNLP در پردازش زبان طبیعی محبوب هستند. جاوا بهدلیل مقیاسپذیری و عملکرد خوب خود در برنامههای NLP با مقیاس بزرگ مناسب است.
- R :R یک زبان برنامهنویسی آماری است که برای متنکاوی، تجزیه و تحلیل احساسات، مدلسازی موضوع و سایر وظایف NLP کاربردی است. بستههای tm و quanteda اغلب در زبان R برای NLP استفاده میشوند.
- C++: این زبان بهدلیل کارایی و سرعت خود برای توسعه برنامههای NLP با منابع فشرده مناسب است. کتابخانههایی مانند Boost و کتابخانههای گروه Stanford NLP عملکردهای قوی برای پردازش زبان طبیعی ارائه میدهند.
- جاوا اسکریپت: برای توسعه برنامههای NLP مبتنی بر وب، مانند چتباتها از جاوااسکریپت استفاده میشود. کتابخانههای محبوب مانند Natural، Compromise و NLP.js قابلیتهای خوبی را در NLP ارائه میکنند.
ابزارهای رایگان پرکاربرد در NLP
در دنیای توسعه و تحقیق، ابزارهای متنباز متعددی برای پردازش زبان طبیعی وجود دارد. در ادامه سه نمونه معروف را معرفی میکنیم:
- NLTK: یک کتابخانه پایتون بسیار جامع همراه با مجموعه دادهها و آموزشهای کاربردی برای آموزش NLP.
- Gensim: ابزار تخصصی برای مدلسازی موضوعی و نمایهسازی متون (مخصوصا برای کار با دادههای حجیم و بدون برچسب)
- NLP Architect (توسعهیافته توسط اینتل): کتابخانهای حرفهای برای پیادهسازی مدلهای یادگیری عمیق و تکنیکهای پیشرفته NLP
مهمترین وظایف پردازش زبان طبیعی
یک سیستم هوشمند برای اینکه بتواند زبان انسان را بفهمد، باید علاوهبر تشخیص کلمات و ترجمه جملات، وظایف دیگری را انجام دهد. در واقع پردازش زبان طبیعی شامل مجموعهای از وظایف تخصصی است که به ماشین کمک میکند تا معنای دقیق جملات را از دل واژهها، ساختارها و بافت زبانی استخراج کند. در ادامه با مهمترین این وظایف آشنا میشوید:
۱. تشخیص ارجاع (Coreference Resolution)
یکی از چالشهای مهم در زبان انسانی، تشخیص ارجاعهاست؛ یعنی ماشین بفهمد کلمات مختلف در متن به یک چیز یا شخص واحد اشاره دارند. برای مثال، در جمله «مریم به کتابخانه رفت. او کتابی امانت گرفت»، سیستم باید بفهمد که «او» همان «مریم» است. این وظیفه حتی میتواند مفاهیم استعاری یا کنایی را هم شناسایی کند. برای مثال، وقتی واژه «خرس» به معنای یک فرد بزرگ و پشمالو (نه یک حیوان وحشی) به کار رفته باشد، ماشین میتواند این استعاره و یا کنایه را تشخیص دهد.
۲. شناسایی موجودیتهای نامدار (Named Entity Recognition – NER)
در این وظیفه، سیستم باید بتواند نامها، مکانها، سازمانها و دیگر موجودیتهای مشخص را در متن تشخیص دهد. برای مثال، واژه «تهران» را بهعنوان نام یک شهر یا «علی» را بهعنوان نام یک شخص شناسایی کند. این فرایند برای دستهبندی اطلاعات متنی (مخصوصا در موتورهای جستجو، خبرخوانها و تحلیل دادههای متنی) اهمیت بسیار زیادی دارد.
۳. برچسبگذاری اجزای سخن (Part-of-Speech Tagging)
پردازش زبان طبیعی باید وظیفه برچسبگذاری اجزای سخن را هم بهخوبی انجام دهد، یعنی هر واژه در جمله براساس نقش گرامری خود (مثل فعل، اسم، صفت و…) شناخته شود. در واقع این کار کمک میکند تا ساختار جمله برای ماشین قابل درک شود. برای مثال، در جمله «او میتواند پرندهای بسازد»، واژه «بسازد» بهوضوح یک فعل است، اما اگر بگوییم «این سازه ساخت دست اوست»، این بار واژه «ساخت» نقش اسم دارد. تشخیص این تفاوتها برای یک انسان ساده است، اما ماشین باید بافت جمله و ساختار آن را تحلیل کند.
۴. تشخیص معنای واژهها در بافت (Word Sense Disambiguation)
بسیاری از واژهها در زبان فارسی یا انگلیسی، چند معنای مختلف دارند. این نوع از وظیفه NLP، تلاش میکند که از طریق تحلیل معنایی، معنای دقیق واژه را در بافت جمله تشخیص دهد. برای مثال، واژه «شیر» میتواند بهمعنای «حیوان درنده»، «نوشیدنی شیر» و یا «وسیله انتقال آب» باشد. حال در جمله «شیر را درون لیوان ریخت»، ماشین باید بهکمک ساختار جمله و معنای کلی آن، تشخیص دهد که منظور ما نوشیدنی است.
کاربردهای NLP در دنیای واقعی
NLP بسیاری از فرایندهای تجاری را سادهتر کرده است، بهخصوص فرایندهایی که شامل حجم زیادی از دادههای متنی بدون ساختار مانند ایمیلها، نظرسنجیها، مکالمات شبکههای اجتماعی و موارد مشابه هستند. از جمله صنایعی که پردازش زبان طبیعی در آن نقش دارد، عبارتند از:
- صنایع پزشکی: ازآنجاییکه سوابق پزشکی بیماران به سمت الکترونیکی شدن میروند، صنعت پزشکی با حجم زیادی از دادههای بدون ساختار مواجه میشود. NLP میتواند برای تجزیه و تحلیل و به دست آوردن بینشهای جدید در مورد سوابق پزشکی استفاده شود.
- حقوقی: وکیلها برای بررسی یک پرونده باید ساعتهای زیادی را صرف بررسی اسناد و جستجوی مطالب مرتبط با یک پرونده خاص کنند. فناوری NLP میتواند فرایند کشف قانونی را خودکار کند و با بررسی حجم زیادی از اسناد، زمان و خطای انسانی را کاهش دهد.
- امور مالی: در زمینه مالی، معاملهگران از فناوری NLP برای استخراج خودکار اطلاعات از اسناد و اخبار شرکتها برای به دست آوردن اطلاعات مرتبط با پرتفوی و تصمیمات تجاری خود استفاده میکنند.
- خدمات مشتری: بسیاری از شرکتهای بزرگ از دستیاران مجازی یا رباتهای گفتگو برای پاسخگویی به سوالات مشتری و سوالات متداول استفاده میکنند.
- بیمه: شرکتهای بیمه بزرگ از NLP برای بررسی اسناد و گزارشهای مربوط به خسارتها استفاده میکنند تا فرایند تجارت را سادهتر کنند.
حتما شما هم بهطور روزانه با بسیاری از برنامههای NLP مانند تصحیح خودکار متن و ترجمه سروکار دارید. با این حال، کاربردهای پردازش زبان طبیعی به این موارد ختم نمیشود و بسیار گستردهتر از چیزی است که تصور میکنید. در ادامه، به برخی از مهمترین کاربردهای پردازش زبان طبیعی اشاره میکنیم.

۱. موتورهای جستجو (Information Retrieval)
پردازش زبان طبیعی بهطور قابل توجهی به موتورهای جستجو کمک میکند تا پرسوجوهای زبان انسانی را بهطور موثرتری درک و تفسیر کنند. از طریق تکنیکهایی مانند تجزیه و تحلیل معنایی و تجزیه و تحلیل احساسات، NLP به موتورهای جستجو اجازه میدهد تا هدف و تفاوتهای پرسوجوهای کاربر را درک کنند و نتایج جستجوی دقیقتر و مرتبطتری را به او نشان دهند. با استفاده از الگوریتمهای یادگیری ماشین، موتورهای جستجو میتوانند الگوهای زبان و خواستههای کاربر را بهتر درک کنند و در نهایت، نتایج کارآمدتری را برای کاربران در حوزهها و زبانهای مختلف فراهم کنند.
۲. تشخیص گفتار خودکار (Automatic Speech Recognition)
اپلیکیشنهای تشخیص گفتار خودکار یا ASR از NLP برای تبدیل زبان گفتاری به متن استفاده میکنند. این قابلیت در برنامههایی مانند سیری یا الکسا کاربردی است. در سیستم تشخیص گفتار خودکار، الگوریتمهای NLP ورودی صوتی را تجزیه و تحلیل و با تشخیص الگوهای گفتار، آنها را به متن قابل فهم تبدیل میکنند. در نتیجه، انسان میتواند از طریق گفتوگوی صوتی با کامپیوتر ارتباط برقرار کند. علاوهبر این، NLP با درک زمینه و اصلاح خطاها بر اساس الگوهای زبانی، به بهبود دقت سیستمهای تشخیص گفتار کمک میکند.
- تعامل از طریق گفتگو و بدون نیاز به دخالت دست
- قابلیت دسترسی برای افراد معلول یا ناتوان
- کاهش زمان برای وارد کردن دادههای ورودی
یکی از کاربردهای پیشرفته پردازش زبان طبیعی، شناسایی محتوای سمی و توهینآمیز در متنهای دیجیتال (Toxicity Classification) است. این سیستمها میتوانند انواع توهینها، تهدیدها، الفاظ رکیک یا نفرتپراکنی را در متنها تشخیص دهند. معمولا پلتفرمهایی مانند شبکههای اجتماعی یا بخش نظرات سایتها از این ابزار برای بهبود کیفیت گفتگوها و جلوگیری از انتشار محتوای آسیبزا استفاده میکنند.
۳. شبکههای اجتماعی
حتما شما هم هنگام گشتوگذار در شبکههای اجتماعی متوجه شدید که پستهای دلخواهتان بیشتر از هرچیزی نمایش داده میشوند. این به لطف همکاری پردازش زبان طبیعی با دیگر تکنولوژیهای هوش مصنوعی اتفاق میافتد. در کنار تکنولوژیهای هوش مصنوعی دیگر مانند پردازش تصویر، NLP محتوا و ماهیت پستها را درک میکند تا بتواند محتوای مناسب را به افرادی که بهدنبال آن محتوا هستند، نمایش دهد. NLP با تسهیل کارهایی مانند تجزیه و تحلیل پیامها در شبکههای اجتماعی، به بهبود تعامل با کاربر در این رسانهها کمک میکند. در نتیجه، کسبوکارها میتوانند با سنجش افکار عمومی و شناسایی ترندها، بهسرعت مشکلات کاربران را برطرف کنند.
۴. چتباتها در فروشگاههای اینترنتی (Conversation Generation)
بسیاری از فروشگاههای اینترنتی، از چتباتهای مبتنی بر NLP برای کمک فوری به مشتریان استفاده میکنند. این چتباتها میتوانند زبان طبیعی مشتریان را درک کنند و با اطلاعات مرتبط، مانند جزئیات محصول، شرایط ارسال یا بازگشت محصول، به سوال مشتری پاسخ دهند. چتباتهای نسل جدید علاوهبر پاسخ به سوالات تکراری، میتوانند با انسانها مکالمات طبیعی و چندلایه داشته باشند. همچنین برخلاف چتباتهای سنتی که فقط پایگاه دادهای از سوال و جواب دارند، این چتباتها میتوانند مانند LaMDA گوگل گفتوگویی شبیه به انسان را شبیهسازی کنند.
مزایای آن عبارت است از:
- تسریع پاسخگویی به مشتری
- پاسخ به حجم بیشتری از سوالات مشتریان
- بهبود تجربهی کلی مشتری
۵. تحلیل احساسات برای بررسی محصول (Sentiment & Emotion Analysis)
تجزیه و تحلیل احساسات یکی از تکنیکهای NLP است که بینشی عمیق از نظرات و بازخورد مشتریان ارائه میدهد. با درک احساسات بیانشده در نظرات محصول، فروشگاههای اینترنتی میتوانند نتایج ارزشمندی درباره ترجیحات مشتری، سطح رضایت و نکات بهبود به دست آورند. از جمله مزایای آن میتوان به موارد زیر اشاره کرد:
- توسعه محصول
- بهبود استراتژیهای بازاریابی
- رضایت مشتری
- افزایش وفاداری مشتری
۶. تولید محتوا (Content Creation)
برخی از مدلهای NLP، مانند ChatGPT، میتوانند متنی شبیه نوشتههای انسان را براساس درخواستهای ورودی تولید کنند. تولید متن در زمینههای مختلفی مانند تولید محتوا برای وبسایتها، تولید توضیحات محصول، نوشتن پیامهای شخصی یا حتی سرودن شعر و داستان کاربرد دارد. از دیگر کاربردهای پردازش زبان طبیعی در زمینه تولید محتوا میتوان موارد زیر را نام برد:
- ترجمه ماشینی (Machine Translation): ترجمه خودکار زبانهای مختلف، دیگر از برجستهترین کاربردهای NLP است. در واقع ابزارهایی مانند Google Translate با کمک مدلهای پیشرفته یادگیری عمیق، میتوانند متنهای مختلف را از زبانی به زبان دیگر ترجمه و حتی تفاوتهای ظریف معنایی را تشخیص دهند. این ابزارها به ارتباط بینفرهنگی کمک میکنند و نقش مهمی در ابزارهای پیامرسان و شبکههای اجتماعی دارند.
- اصلاح خطاهای گرامری (Grammatical Error Correction): مدلهای اصلاح گرامری میتوانند جملات نادرست را به نسخههای درست و مطابق با قواعد دستور زبان تبدیل کنند. این ابزارها در ویرایشگرهای متنی مانند Microsoft Word و سرویسهایی مانند Grammarly برای بهبود نگارش کاربران استفاده میشوند و حتی در ارزیابی انشاهای دانشآموزی هم کاربرد دارند.
- پیشنهاد خودکار کلمات (Autocomplete): سیستمهای تکمیل خودکار با پیشبینی کلمات یا عبارات بعدی در متن، تجربه تایپ و جستجو را برای شما سریعتر و روانتر میکنند. این قابلیت در نرمافزارهایی مانند Google Search و پیامرسانهایی مانند واتساپ کاربرد زیادی دارد و بر پایه مدلهایی مانند GPT-2 توسعه یافته است.
۷. خلاصه کردن متن (Summarizing)
خلاصهسازی متن به معنی کوتاه کردن اسناد، مقالات یا سایر منابع متنی به صورتی است که اطلاعات مهم آن حفظ شوند. این کاربرد پردازش زبان طبیعی زمانی مفید است که افراد میخواهند به سرعت نکات اصلی اسناد طولانی مانند مقالات خبری، مقالات تحقیقاتی یا اسناد قانونی را درک کنند. خلاصه کردن متن ممکن است شامل استخراج نکات مهم و کلیدی از متن یا تولید جملات جدیدی باشد که معنای اصلی متن را منتقل میکنند.
مزایا:
- تسریع درک متنهای طولانی
- تبدیل متنهای پیچیده به متن ساده و قابل درک
- حذف جزئیات غیرضروری از متنها
- زبانهای برنامهنویسی و ابزارهای NLP
۸. تشخیص و فیلتر پیامهای اسپم (Spam Detection)
فیلتر کردن ایمیلها و پیامهای ناخواسته، یکی از کاربردهای بسیار عالی NLP در دنیای دیجیتال است. سیستمهای شناسایی اسپم با بررسی محتوای ایمیل، عنوان پیام و اطلاعات فرستنده، احتمال اسپم بودن آن را تشخیص میدهند و در صورت لزوم، آن را به پوشه اسپم منتقل میکنند. این فناوری تجربه شما را در استفاده از سرویسهای ایمیل بهطور چشمگیری بهبود میدهد.
۹. شناسایی موجودیتهای نامدار (Named Entity Recognition)
در بسیاری از متنها، تشخیص نام افراد، مکانها، سازمانها یا اعداد مهم (مثل تاریخها و قیمتها) اهمیت بالایی دارد. الگوریتمهای NER این موجودیتها را از متن استخراج و دستهبندی میکنند. این ابزار بهویژه در خلاصهسازی اخبار، تحلیل اطلاعات و مقابله با اطلاعات نادرست کاربرد زیادی دارد.
مزایای پردازش زبان طبیعی برای کسبوکارها
پردازش زبان طبیعی مزایای بیشماری را بهصورت مستقیم و غیرمستقیم برای اهداف مختلف ارائه میدهد. برخی از این مزایا برای کسبوکارها عبارتند از:
- افزایش نرخ تبدیل: NLP به کسب و کارها کمک میکند تا با تجزیه و تحلیل نظرات مشتریان، استراتژیهای بازاریابی و پیامهای خود را بهبود ببخشند و در نهایت ارتباط بهتری با مخاطبان خود برقرار کنند. این باعث افزایش نرخ تبدیل و فروش خواهد شد.
- نظارت بر شبکههای اجتماعی: NLP با تجزیه و تحلیل مکالمات شبکههای اجتماعی، به کسب و کارها در شناسایی ترندها و درک احساسات مردم نسبت به برند کمک میکند. با این اطلاعات ارزشمند، میتوان شهرت و وفاداری برند را افزایش داد.
- انجام جستجوهای پیچیده: NLP با انجام جستجوهای پیچیده در دادههای بزرگ، اطلاعات و بینشهای مرتبط را به سرعت و با دقت استخراج میکند. در نتیجه، تصمیمگیری و تنظیم استراتژی بهبود پیدا میکند.
- افزایش رضایت مشتری: ارائه خدمات فوری به مشتری، تجزیه و تحلیل احساسات، شناسایی نیازها و ترجیحات مشتری، همگی از نتایج NLP هستند که باعث افزایش رضایت مشتری خواهند شد.
- صرفهجویی در هزینه و زمان: NLP با خودکارسازی کارهای تکراری مانند پشتیبانی مشتری و تولید محتوای متنی، به کسب و کارها کمک میکند تا در زمان و هزینه صرفهجویی کنند.
- مدیریت ریسک: NLP با تجزیه و تحلیل دادهها، تهدیدات امنیت سایبری و نقض قوانین را شناسایی میکند که باعث کاهش خطرات امنیتی خواهد شد.
- ارائه تحلیل عینی و بدون سوگیری: انسانها ممکن است در تحلیلهای متنی دچار خستگی یا سوگیری شوند، اما ابزارهای مبتنی بر NLP توانایی ارائه تحلیلهایی عینی، پایدار و قابل اعتماد را دارند. این ویژگی به کسبوکارها کمک میکند تا تصمیمگیریهای بهتری بر پایه دادههای واقعی و بدون دخالت احساسات انسانی انجام دهند.
- بهبود شخصیسازی محتوا: با استفاده از NLP، کسبوکارها میتوانند محتوایی متناسب با علایق و سابقه تعامل هر کاربر ارائه دهند. این سطح از شخصیسازی باعث افزایش تعامل کاربر و رضایتمندی او از خدمات میشود.
چالشهای NLP
در کنار همهی مزایا و کاربردهایی که پردازش زبان طبیعی ارائه میدهد، چالشهایی هم وجود دارند که برای رفع آنها تلاشهای زیادی توسط متخصصان صورت گرفته است. این چالشها عبارتند از:
- تفاوت زبان: تفاوت زبان، به خصوص اگر به دنبال جذب مخاطبان بینالمللی باشید، یک چالش بزرگ خواهد بود. در نتیجه، باید زمانی را صرف آموزش مجدد سیستم NLP خود برای هر زبان کنید.
- دادههای آموزشی: حتی بهترین هوش مصنوعی باید زمان قابل توجهی را صرف خواندن و استفاده از یک زبان کند. اگر دادههای اشتباه یا مشکوک را به سیستم بدهید، چیزهای اشتباهی را یاد میگیرد و در نهایت درست کار نمیکند.
- زمان توسعه: برای اینکه یک هوش مصنوعی به اندازه کافی آموزش ببیند، باید میلیونها داده را بررسی کند که این فرآیند زمانبر خواهد بود.
- ابهامات عبارتی: گاهی حتی برای یک انسان سخت است که ابهامات عبارتی را درک کند. بنابراین، هوش مصنوعی هم ممکن است معنای واضحی در تحلیل کلمات پیدا نکند و از کاربر شفافیت بیشتری بخواهد.
- غلط املایی: برای یک کامپیوتر، تشخیص غلط املایی دشوارتر از انسان است. برای حل این مشکل، باید از یک ابزار NLP با قابلیت تشخیص غلط املاییهای رایج استفاده کنید.
- سوگیریهای ذاتی: گاهی ابزارهای NLP سوگیریهای برنامهنویسان خود یا سوگیریهایی در مجموعه دادههای آموزشی وجود دارد را به ارث میبرند، در نتیجه نتایج ناعادلانهای به دست میآید.
- تجزیه و تحلیل احساسات: معنای یک جمله میتواند بر اساس احساسات مرتبط با آن تغییر کند و تشخیص دقیق احساسات از متن مستلزم درک نشانههای زبانی ظریف، طعنه و کنایهها است.
مدلهای مختلف پردازش زبان طبیعی
در طول دهههای اخیر، مدلهای متعددی برای پردازش زبان طبیعی توسعه یافتهاند که هر کدام نقش مهمی در پیشرفت هوش مصنوعی ایفا کردهاند. در ادامه، برخی از مهمترین مدلهای NLP را بررسی میکنیم:
۱. مدل Eliza
مدل Eliza نخستین تلاش جدی برای ساخت چتبات، بود که با هدف عبور از آزمون تورینگ طراحی شد. این سیستم بدون اینکه بتواند درک عمیقی از معنای زبان داشته باشد، از تطبیق الگو و مجموعهای از قواعد استفاده میکرد. همچنین مدل Eliza تحلیلگر واقعی زبان نبود و بیشتر نقش تقلیدکننده را داشت.
۲. مدل Tay
Tay یک چتبات توییتری بود که شرکت مایکروسافت میخواست مانند یک نوجوان صحبت کند و از تعامل با کاربران یاد بگیرد. با اینکه اهمیت زیادی به این مدل داده شد، اما بهدلیل نبود فیلترهای اخلاقی و عدم پاکسازی دادههای آموزشی، بهسرعت زبان زننده و نژادپرستانه کاربران را یاد گرفت و مایکروسافت مجبور شد آن را خیلی زود غیرفعال کند. این مورد نمونهای بارز از ضرورت حذف سوگیری (de-biasing) از دادههای آموزشی در NLP است.
۳. مدل BERT و خانواده
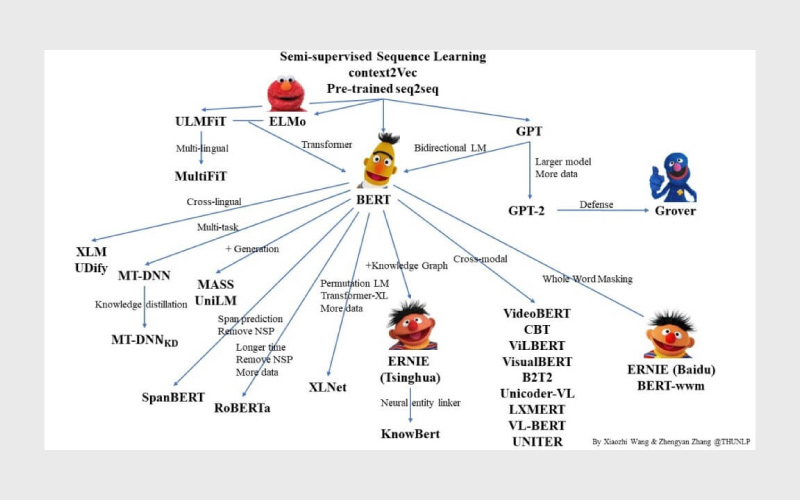
مدلهای مبتنی بر معماری ترنسفورمر مانند BERT، ELMo، RoBERTa، BigBird و ERNIE، از جمله پیشرفتهترین ابزارهای حوزه درک معنای کلمات در بافت جمله هستند. این مدلها میتوانند نمایشهای برداری زمینهمحور (contextual embeddings) تولید کنند که در بسیاری از وظایف NLP مانند پرسش، پاسخ و تحلیل احساسات بسیار موثر هستند.
۴. مدل GPT-3 یا (Generative Pre-trained Transformer 3)
GPT-3 یکی از بزرگترین و قدرتمندترین مدلهای زبانی است که با ۱۷۵ میلیارد پارامتر، میتواند متنی همسطح با انسان تولید کند. این مدل از معماری ترنسفورمر استفاده میکند و توسط OpenAI توسعه یافته است. GPT-3 برخلاف نسخه قبلی یعنی GPT-2 که متنباز بود، از طریق API قابل دسترسی است. همچنین نسخههای متنباز مشابه آن هم توسط گروههایی مانند EleutherAI و Meta عرضه شدهاند.
۵. مدل LaMDA یا (Language Model for Dialogue Applications)

LaMDA مدل گفتگومحور گوگل بهحساب میآید که برخلاف سایر مدلها، بر پایه مکالمات انسانی آموزش دیده است. این مدل با هدف تولید پاسخهایی منطقی، خاص و طبیعی در مکالمات طراحی شد. همچنین جنجالیترین بخش توسعه LaMDA مربوط به یکی از توسعهدهندگان گوگل است که ادعا کرد این مدل دارای «هوشیاری» است. البته این ادعا از سوی بسیاری رد شد.
۶. مدل Mixture of Experts یا MoE
در مدلهای سنتی، تمام دادهها با یک مجموعه پارامتر ثابت پردازش میشوند، اما MoE به کمک مجموعهای از کارشناسان و بسته به ورودی، فقط بخشی از شبکه را فعال میکند. این کار باعث کاهش هزینه محاسباتی و افزایش بهرهوری مدل میشود. Switch Transformer نمونهای از این رویکرد است که عملکرد بالایی را با مصرف منابع کمتر فراهم میکند.
سخن پایانی
پردازش زبان طبیعی (NLP) یکی از مهمترین و کاربردیترین شاخههای هوش مصنوعی بهحساب میآید که هدف آن ایجاد ارتباطی موثر و طبیعی میان زبان انسان و ماشین است. این فناوری فراتر از تحلیل ساده متن عمل میکند و به رمزگشایی زبان، تشخیص احساسات، رفع ابهامات معنایی و استخراج اطلاعات ارزشمند از حجم وسیعی از دادههای متنی میپردازد.
با پیشرفت مدلهای یادگیری ماشین و معماریهای پیشرفته مانند ترانسفورمرها، پردازش زبان طبیعی به یکی از ارکان اصلی در توسعه چتباتها، دستیارهای صوتی، ابزارهای ترجمه و تحلیل داده تبدیل شده است. در آیندهای نزدیک انتظار میرود که NLP نقش پررنگتری در بهبود تعاملات انسان و کامپیوتر ایفا کند.
منابع
aws.amazon.com | www.oracle.com | www.ibm.com | www.coursera.org | www.deeplearning.ai | www.techtarget.com | www.denodo.com | www.sonarplatform.com | www.shaip.com
سوالات متداول
NLP روی تحلیل زبان انسانی تمرکز دارد، اما یادگیری ماشین تکنیکی کلی برای آموزش ماشینها از دادهها است. در واقع، NLP اغلب از یادگیری ماشین برای تحلیل زبان استفاده میکند.
از جمله مدلهای معروف میتوان به Eliza، BERT، GPT-3، LaMDA، RoBERTa و Switch Transformer اشاره کرد.
NLP به کسبوکارها در تحلیل نظرات مشتریان، خودکارسازی خدمات پشتیبانی، شخصیسازی محتوا، ترجمه متون، شناسایی احساسات و تحلیل دادههای متنی کمک میکند.


دیدگاهتان را بنویسید