
تقریبا همه ما با پایتون آشنایی داریم؛ یک زبان برنامهنویسی قدرتمند که به لطف کتابخانهها و فریمورکهای متنوع، طرفداران زیادی در یادگیری ماشینی، هوش مصنوعی و بهخصوص علم داده دارد. یکی از این کتابخانههای محبوب، پانداس (pandas) است که متخصصین داده را شیفته خود کرده است. اگر شما هم در این حوزه فعالیت دارید و میخواهید یک جعبه ابزار بزرگ برای کار با دادهها داشته باشید، بهتر است با پانداس آشنا شوید. با ما در ادامه این مقاله از مجله آسا همراه باشید تا این کتابخانه جذاب پایتون را معرفی کنیم.
پانداس (pandas) چیست؟
پانداس (pandas) یک کتابخانه مدرن، قدرتمند و غنی است که امکان مدیریت و تجزیه و تحلیل دادهها در پایتون را فراهم میکند. این کتابخانه، بهطور گسترده در زمینههای مختلف علم استفاده میشود و امکاناتی مانند ادغام، مرتبسازی، تمیز کردن، گروهبندی و تجسم دادهها را ارائه میدهد. پانداس به دانشمندان و متخصصان داده کمک میکند تا راحتتر دادهها را بخوانند، با آنها کار کنند و دانش و بینش بهدستآمده از دادهها را برای تصمیمگیری و پیادهسازی فرایندها به کار ببرند.

برای مثال، نتفلیکس از پانداس برای تجزیهوتحلیل دادههای بیننده استفاده میکند تا بتواند نمایشها و فیلمهای متناسب با اولویتهای هر کاربر را به او پیشنهاد دهد. در حقیقت، یکی از مهمترین دلایل موفقیت نتفلیکس، همین پیشنهادهای شخصیسازی شده است که بدون ابزارهایی مانند پانداس ممکن نبود! اما این کتابخانه پایتون دقیقا چگونه کار میکند؟
پانداس چگونه کار میکند؟

نحوه کار پانداس حول مفهوم آبجکتهای DataFrame و Series میچرخد. دیتافریمها جداول دوبعدی هستند که میتوانند دادهها را در ردیفها و ستونها ذخیره کنند، درحالیکه سریها آرایههای یکبعدی هستند که فقط دادههای یک نوع را ذخیره میکنند. بنابراین، میتوان گفت که نحوه ذخیره دادهها در این کتابخانه، شبیه به اکسل یا R است که از مفهوم یک دیتافریم هم استفاده میکنند. در واقع، هدف خالق پانداس این بود که آن را بهعنوان جایگزینی برای R و مقابله با ساختارهای پیچیده آن توسعه دهد.
باوجوداین، وجه تمایز پانداس در استفاده از ماژول Numpy است که از عملیات عددی کارآمد (Efficient numerical operations) در مقیاس بزرگ پشتیبانی میکند. کاربران میتوانند از منابع داده مختلف مانند فایلهای CSV، فایلهای اکسل، پایگاههای داده SQL یا حتی دیکشنریها و لیستهای پایتون برای ساخت دیتافریمها و سریها استفاده کنند.
مثالی از نحوه کار پانداس
بهعنوان مثال، فرض کنید شما یک فایل CSV دارید که در آن اطلاعات مشتریان فروشگاه ذخیره شده است. با چند خط کد ساده در پانداس، میتوانید این فایل را بخوانید و اطلاعات آن را به یک DataFrame تبدیل کنید. سپس پانداس به شما اجازه میدهد تا روی این دادهها کارهای مختلفی انجام دهید: میتوانید آنها را مرتب کنید، فیلتر کنید، گروهبندی کنید یا حتی ستونهای جدید اضافه کنید. مثلا، اگر بخواهید فقط مشتریانی که بالای ۳۰ سال سن دارند را مشاهده کنید، کافی است یک شرط ساده تعریف کنید و پانداس بقیه را انجام میدهد. جالبتر اینکه، اگر دادهها ناقص باشند، پانداس ابزارهای قدرتمندی برای پیدا کردن و حتی پر کردن دادههای ازدسترفته در اختیار شما قرار میدهد. این تنها یک مثال ساده از نحوه کار پانداس است، در ادامه به کاربردهای این کتابخانه در حوزههای مختلف میپردازیم.
بیشتر بخوانید: معرفی بهترین کتابخانه های پایتون
ویژگیهای کلیدی پانداس کدامند؟

قبل از پرداختن به کاربردهای پانداس، بیایید نگاهی به ویژگیهای مهم این کتابخانه داشته باشیم.
پاکسازی دادهها
کتابخانه Pandas امکانات مختلفی برای تمیز کردن و بهبود دادهها ارائه میدهد که شامل پر کردن مقادیر ازدسترفته، حذف ستونها یا ردیفهای خاص، حذف مقادیر NULL و تغییر نام ستونهای مورد نظر است.
فیلتر و انتخاب دادهها
پانداس طیف وسیعی از فیلترهای دقیق را ارئه میدهد. بنابراین، مهم نیست که داده ها چقدر پیچیده هستند، شما در سریعترین زمان میتوانید اطلاعات موردنظرتان را استخراج کنید.
تجمیع دادهها
پانداس امکان عملیات تجمیع دادهها مانند ترکیب و ادغام دادهها را برای خلاصهسازی و بازسازی آنها ارائه میدهد. بنابراین شما میتوانید بهراحتی دادهها را از چند منبع ترکیب کنید و یک مجموعه داده واحد ایجاد کنید.
خواندن و نوشتن دادهها
پانداس قابلیت خواندن و نوشتن دادهها از منابع مختلف مانند فایلهای CSV، Excel، JSON، SQL و حتی وب APIها را دارد. بنابراین بهراحتی میتوانید دادهها را از منابع مختلف استخراج و مدیریت کنید.
تجسم دادهها
هرچند پانداس بهطور مستقیم قابلیت رسم نمودارها را ندارد، اما با امکان یکپارچگی با کتابخانههایی مثل Matplotlib و Seaborn، به شما اجازه میدهد بهراحتی دادهها را بصری و نمودارهای متنوعی رسم کنید.
پشتیبانی از سریهای زمانی
پانداس ابزارهای قوی برای کار با سریهای زمانی دارد. این شامل تغییر فرکانس دادهها، محاسبه اختلافات و شیفت دادن دادههای سری زمانی است که در تحلیل روندها و پیشبینیها کاربرد دارد. بهعنوان مثال، شما میتوانید بهراحتی با دادههایی که دارای برچسب زمانی هستند (مانند قیمت سهام، دادههای آبوهوایی یا دادههای مالی) کار کنید.
بهطور کلی باید گفت که ویژگیهای اصلی کتابخانه Pandas بر سادهسازی فرایند تجزیهوتحلیل دادهها تمرکز دارند که آن را به ابزاری ضروری برای متخصصان و محققان داده تبدیل میکند.
مزایای پانداس چیست؟
با وجود رقبای زیاد برای Pandas، ممکن است از خود بپرسید که چرا باید آن را انتخاب کنم. بههرحال، انجام بسیاری از وظایف مشابه با Microsoft Excel یا Google Sheets امکانپذیر است. بااینحال باید توجه داشت که اکسل و گوگل شیت، محیطهای بستهتری دارند و تنها از طریق نرمافزار یا از طریق یک برنامه وب در دسترس هستند. در سمت مقابل، کتابخانه پانداس به ما اجازه میدهد تا طیف وسیعی از عملکردها و APIهای مختلف پایتون را پیادهسازی کنیم.
از طرفی، پانداس بر پایه کتابخانه NumPy ساخته شده که عملیات عددی سریع و بهینه را در مقیاس بسیار بزرگ تضمین میکند. علاوهبر این، پانداس بهراحتی با کتابخانههای معروف پایتون مانند NumPy، SciPy، و Matplotlib یکپارچه میشود تا برای مسائل پیچیده تحلیل دادهها، کارآمد باشد. یکی دیگر از مزایای مهم پانداس توانایی آن در پردازش دادهها از منابع متنوع مانند فایلهای CSV، Excel و پایگاههای داده SQL است که آن را به ابزاری قدرتمند در بسیاری از حوزههای مختلف تبدیل کرده است.
کاربردهای پانداس در صنایع و حوزههای مختلف
طبق گزارشها، حدود ۲۲۰ شرکت بزرگ در حوزههای مختلف، از جمله غولهایی مانند فیسبوک، بوئینگ و فیلیپس، از Pandas برای مقاصد علم داده خود استفاده میکنند. در ادامه به مهمترین کاربردهای این کتابخانه در صنایع و حوزههای گوناگون میپردازیم.

علم داده
شاید بتوان گفت که مهمترین کاربرد پانداس در علم داده و تجزیهوتحلیل داده است، به عبارتی پانداس و علم داده تقریبا مترادف هستند. این کتابخانه به متخصصان داده کمک میکند تا مجموعههای داده را بخوانند، تجزیهوتحلیل کنند و الگوهای مخفی را کشف کنند. همه اینها با ابزارهای ارائهشده توسط پانداس مانند فیلتر کردن دادهها، گروهبندی، محاسبات آماری و بصریسازی دادهها، سادهتر خواهد بود.
یادگیری ماشین
اگر با مفاهیم یادگیری ماشین آشنا باشید، احتمالا میدانید که مدلهای یادگیری ماشین به دادههای تمیز و ساختاریافته نیاز دارند. کتابخانه پانداس، فراهم کردن چنین دادههایی را سادهتر میکند. توسعهدهندگان میتوانند از این کتابخانه برای پیشپردازش دادهها (مانند پاکسازی دادهها، حذف مقادیر نادرست یا پر کردن دادههای ازدسترفته) و آمادهسازی آنها برای الگوریتمهای یادگیری ماشین بهره ببرند.
اقتصاد
اقتصاد بدون دادهها و تجزیهوتحلیل آنها بیمعنی است. پانداس به اقتصاددانان کمک میکند تا با تجزیهوتحلیل دادهها بتوانند الگوها و روندهای اقتصادی را درک کنند. بهعنوان مثال، اقتصاددانان میتوانند با استفاده از قابلیت سریهای زمانی در پانداس، روندهای پیشرو را تحلیل و پیشبینی کنند.
سیستمهای پیشنهاد محتوا
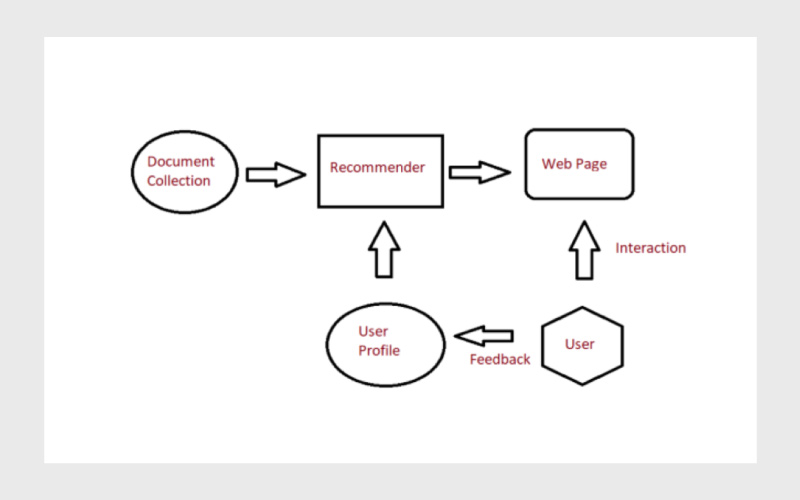
همانطور که گفتیم، نامهای بزرگی مثل نتفلیکس و اسپاتیفای از پانداس برای ارائه پیشنهادات شخصیسازیشده استفاده میکنند. در حقیقت، بدون پانداس و قابلیتهای این کتابخانه در زمینه یادگیری عمیق، ارائه چنین پیشنهادات دقیقی غیرممکن است. پانداس به توسعهدهندگان چنین سازمانهایی کمک میکند تا با زحمت کمتری بتوانند تحلیل دادههای وب و شبکههای اجتماعی، مثل بررسی تعامل کاربران، الگوهای رفتاری و دادههای ترافیکی را انجام دهند.
پیشبینی سهام
همه ما میدانیم که بازار سهام بهشدت بیثبات است. بااینحال، این به این معنا نیست که نمیتوان آن را پیشبینی کرد. با کمک پانداس و چند کتابخانه دیگر مانند NumPy و matplotlib، میتوانیم بهراحتی مدلهایی بسازیم که رفتار بازار و روندهای پیشرو را آشکار کنند. علاوهبر این بسیاری از اندیکاتورهای مدرن از پانداس برای تجزیه و تحلیل دادههای گذشته و حال استفاده میکنند.
مراقبتهای بهداشتی
صنعت مراقبتهای بهداشتی برای بررسی نتایج درمانها، مدیریت منابع بیمارستانی و حتی پیشبینی شیوع بیماریها به حجم وسیعی از دادهها متکی است. بهعنوان مثال، یک بیمارستان ممکن است از پانداس برای تجزیهوتحلیل روند درمان یک بیمار یا نظارت بر گسترش بیماریهای عفونی استفاده کند.
علاوهبر موارد گفته شده، کتابخانه Pandas در حوزههای دیگری مانند پردازش زبان طبیعی، عصب شناسی، آمار، ریاضیات محض، تبلیغات و مهندسی داده استفاده میشود که قدرت بالای این کتابخانه را نشان میدهد.
نصب و شروع استفاده از کتابخانه پانداس

پانداس یک کتابخانه با سینتکس پایتونیک (مبتنی بر پایتون) است و به همین دلیل یادگیری آن برای کسانی که با این زبان آشنایی دارند نسبتا راحت خواهد بود. Pandas یک کتابخانه بالغ محسوب میشود که با یک جامعه قوی و منابع یادگیری فراوان پشتیبانی میشود. در این قسمت نگاهی کوتاه به نحوه نصب و استفاده از این کتابخانه خواهیم داشت.
نصب و ایمپورت Pandas در پایتون
برای نصب پانداس کافیست از دستور pip به صورت زیر استفاده کنیم.
|
1 |
pip install pandas |
در مرحله بعد برای استفاده از این کتابخانه باید آن را ایمپورت کنیم:
|
1 |
import pandas as pd |
ایجاد یک DataFrame
همانطور که گفته شد، ساختار داده استاندارد در این کتابخانه، دیتافریمها و سریها هستند. در قطعه کد زیر میتواند نحوه ایجاد یک دیتافریم را مشاهده کنید:
|
1 2 3 4 |
data = {‘Name’: [‘Alice’, ‘Bob’, ‘Charlie’], ‘Age’: [25, 30, 35]} df = pd.DataFrame(data) print(df) |
خروجی بهصورت زیر خواهد بود:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
عملیات پایه در Pandas
پانداس، عملیات و امکانات بسیار زیادی ارائه میدهد اما بیایید چند مورد از عملیات ابتدایی را بررسی کنیم.
انتخاب داده
قطعه کد زیر، نحوه انتخاب یک ستون خاص از دیتافریم شما را نشان میدهد:
|
1 2 3 |
# Select the ‘Name’ column names = df[‘Name’] print(names) |
فیلتر دادهها
با استفاده از کد زیر میتوانید دادههای خود را با استفاده از شرایط مدنظرتان فیلتر کنید:
|
1 2 3 |
# Select individuals older than 28 filtered_data = df[df[‘Age’] > 28] print(filtered_data) |
گروهبندی دادهها
عملیات گروهبندی دادهها در پانداس، تنها با چند خط کد و بهصورت زیر امکانپذیر است:
|
1 2 3 |
# Group by age and calculate the average grouped_data = df.groupby(‘Age’).mean() print(grouped_data) |
کدهای بالا تنها نمونهای کوچک از قابلیتهای پانداس است که برای آشنایی شما با این کتابخانه قدرتمند ارائه شده است.
آیا پانداس بهترین کتابخانه علم داده است؟
با خواندن این مقاله، احتمالا این سوال برای شما پیش آمده که آیا پانداس بهترین ابزار در علم داده است یا رقبای قدرتمندتری هم برای آن وجود دارند؟ پانداس قطعا یکی از بهترین کتابخانهها برای علم داده در پایتون است، اما نمیتوان گفت که دقیقا بهترین گزینه است. بهعنوان مثال، کتابخانه Polars بهدلیل سرعت بالای خود، توجه متخصصین علم داده را به خود جلب کرده است. این کتابخانه میتواند عملیات معمولی را حدود ۵ تا ۱۰ برابر سریعتر از پانداس انجام دهد. علاوهبر این، حافظه مورد نیاز برای عملیات پیچیده بهطور قابل توجهی کمتر از این کتابخانه است. برای مقایسه بد نیست که بدانید پانداس به ۵ تا ۱۰ برابر رم بیشتر از اندازه مجموعه داده برای انجام عملیات نیاز دارد، درحالیکه این عدد برای کتابخانه Polars حدود ۲ تا ۴ برابر است.
علاوهبر Polars، رقبای دیگری هم وجود دارند، بنابراین قبل از انتخاب هر یک از این ابزارها باید اهداف و نیازهای خود را بسنجید.
نتیجهگیری
به پایان این مطلب و معرفی کتابخانه Pandas رسیدیم. در نهایت، اگر بهدنبال ابزاری هستید که بتواند دادههای شما را از یک فایل خام به بینشهای ارزشمند تبدیل کند، پانداس یکی از بهترین انتخابهای ممکن است. این کتابخانه، ترکیبی از سادگی و قدرت را به شما ارائه میدهد تا از آن برای مدیریت و تحلیل دادهها استفاده کنید. پس اگر تابهحال پانداس را امتحان نکردهاید، همین حالا شروع کنید؛ شاید راهحلی که به دنبالش بودید، دقیقا در دل این کتابخانه پنهان شده باشد!
منابع:
www.geeksforgeeks.org | www.w3schools.com | www.activestate.com


دیدگاهتان را بنویسید