هوش مصنوعی چندوجهی به مجموعهای از تکنیکها و مدلهای هوش مصنوعی گفته میشود که قادرند دادههای متنوعی مانند متن، تصویر، صدا و ویدیو را به صورت همزمان پردازش و تحلیل کنند. برخلاف مدلهای سنتی که تنها به یک نوع داده محدود هستند، مدلهای چندوجهی میتوانند ارتباطات میان دادههای مختلف را درک کرده و تصمیمگیریهای دقیقتری ارائه دهند. این قابلیت باعث شده که Multimodal AI در حوزههای متعددی از جمله پزشکی، خودروهای خودران، رسانه و تجارت الکترونیک کاربردی شود.
در این مقاله از بلاگ آسا، قصد داریم شما را با مفهوم هوش مصنوعی چندوجهی، انواع مدلها، کاربردها، وظایف اصلی، معماریها و روشهای پیشرفته، نمونههای واقعی، نحوه پیادهسازی و چالشهای پیش رو آشنا کنیم.
مفهوم هوش مصنوعی چندوجهی (Multimodal AI)

هوش مصنوعی چندوجهی یا Multimodal AI به مدلهایی گفته میشود که قادرند اطلاعات را از چندین نوع داده همزمان پردازش و تحلیل کنند. در حالی که مدلهای سنتی معمولا به یک نوع داده محدود میشوند، مثل متن یا تصویر، مدلهای چندوجهی میتوانند دادههای متنی، تصویری، صوتی و ویدئویی را همزمان دریافت کرده و روابط پیچیده میان آنها را درک کنند.
ورودیهای متنوع این مدلها میتواند شامل یک متن خبری همراه با تصویر، صدای ضبطشده یک جلسه یا حتی ویدیوهای آموزشی باشد. برای مثال، یک مدل Multimodal AI در حوزه پزشکی میتواند همزمان تصاویر MRI بیمار و یادداشتهای پزشک را تحلیل کند تا تشخیص دقیقتری ارائه دهد. در خودروهای خودران، این مدلها میتوانند دادههای دوربین، رادار و سنسورهای صوتی را ترکیب کرده و تصمیمگیریهای ایمنتری انجام دهند.
مزیت اصلی مدلهای چندوجهی نسبت به مدلهای تکوجهی، توانایی درک بهتر زمینه و روابط میان دادههاست. این مدلها میتوانند اطلاعات ناقص یا مبهم از یک منبع را با دادههای دیگر تکمیل کنند و خروجیهای دقیقتر و مرتبطتری ارائه دهند، که موجب بهبود عملکرد در کاربردهای پیچیده و دنیای واقعی میشود.
انواع مدلهای هوش مصنوعی چندوجهی (Multimodal AI)
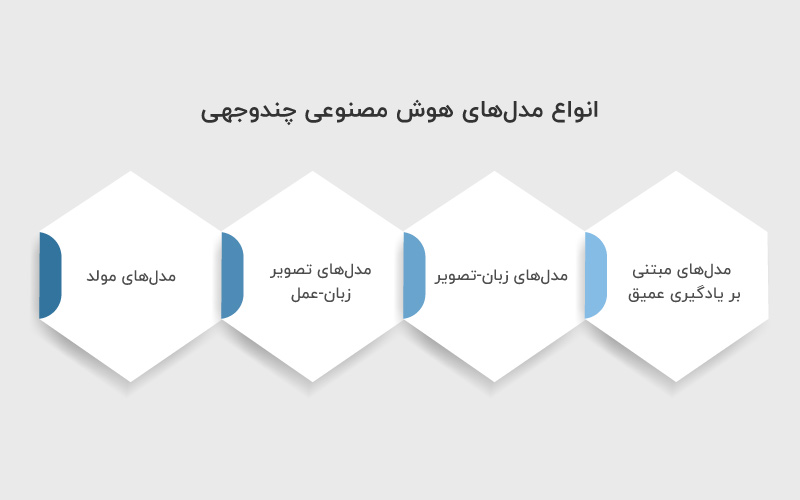
مدلهای هوش مصنوعی چندوجهی را میتوان به چند دسته اصلی تقسیم کرد که هر کدام ویژگیها و کاربردهای خاص خود را دارند:
۱. مدلهای مبتنی بر یادگیری عمیق (Deep Learning)
این مدلها از شبکههای عصبی پیچیده برای استخراج ویژگیها و الگوهای پنهان در دادههای مختلف استفاده میکنند. شبکههای عصبی کانولوشنی (CNN) معمولا برای پردازش تصاویر و ویدیو و شبکههای عصبی بازگشتی (RNN) یا Transformerها برای پردازش متن و دادههای توالیدار به کار میروند. این مدلها پایه و اساس بسیاری از سیستمهای چندوجهی هستند و توانایی ترکیب ورودیهای مختلف را دارند.
شبکه عصبی ResNet برای تحلیل تصاویر پزشکی و شناسایی تومورها، زمانی که با یادداشتهای بالینی بیمار ترکیب میشود، میتواند تشخیص دقیقتری ارائه دهد.
۲. مدلهای زبان-تصویر (Vision-Language Models)
این مدلها قادر به ترکیب دادههای متنی و تصویری هستند. آنها میتوانند تصاویر را توصیف کنند، به سوالات متنی درباره تصاویر پاسخ دهند یا اطلاعات متنی را با عناصر تصویری مرتبط کنند. مثالهای معروف شامل CLIP و ALIGN هستند که در تحلیل محتوای تصویری و تولید توضیحات متنی کاربرد دارند.
۳. مدلهای تصویر-زبان-عمل (Vision-Language-Action Models)
این دسته علاوهبر پردازش متن و تصویر، توانایی تحلیل و پیشبینی اقدامات یا تعاملات در محیط را نیز دارند. کاربرد اصلی آنها در رباتیک، خودروهای خودران و سیستمهای تعاملی است که نیاز دارند بر اساس اطلاعات چندوجهی تصمیم بگیرند و عمل کنند.
رباتهای خانگی مانند SayCan که توسط OpenAI توسعه داده شدهاند، با ترکیب دادههای تصویری و دستورات متنی، قادرند وظایف پیچیدهای مانند برداشتن اشیا و جابهجایی آنها را انجام دهند.
۴. مدلهای مولد (Generative Models)
این مدلها قادر به تولید محتوای جدید بر اساس دادههای ورودی هستند. بهعنوان مثال، مدلهای مولد میتوانند تصویر یا ویدیو بسازند، متنی تولید کنند یا حتی موسیقی خلق کنند، به طوری که خروجی با ورودیهای چندوجهی هماهنگ باشد. مثالهای شناختهشده شامل DALL·E، Imagen و GPT-4V هستند.
معماری Multimodal AI چگونه است؟
برای پردازش دادههای چندوجهی و استخراج اطلاعات معنادار از منابع مختلف، مدلهای Multimodal AI از معماریها و روشهای پیشرفتهای استفاده میکنند که هر کدام نقش خاصی در بهبود عملکرد دارند.
روشهای Fusion یکی از پایههای اصلی ترکیب دادهها هستند. در Early Fusion، ویژگیهای استخراجشده از منابع مختلف پیش از ورود به شبکه عصبی با هم ترکیب میشوند تا مدل بتواند روابط میان دادهها را از ابتدا درک کند. Late Fusion برعکس، ابتدا هر منبع داده بهصورت جداگانه پردازش شده و سپس نتایج آنها در مرحله آخر ادغام میشود. Hybrid Fusion ترکیبی از هر دو روش است و سعی میکند مزایای هر روش را حفظ کند.
استفاده از Attention Mechanisms و Transformers در پردازش دادههای چندوجهی امکان میدهد که مدل بتواند بهطور هوشمند بر بخشهای مهم هر نوع داده تمرکز کند و اطلاعات مرتبط را از میان حجم زیادی از ورودیها استخراج کند. این تکنیکها به ویژه در مدلهای بینایی-زبان و مولد کاربرد دارند و باعث بهبود دقت و فهم زمینهای میشوند.
کاربردهای هوش مصنوعی Multimodal
هوش مصنوعی چندوجهی در حال حاضر در بسیاری از صنایع و حوزهها کاربرد دارد و توانسته عملکرد سیستمها را به شکل چشمگیری بهبود بخشد.
- یکی از مهمترین حوزهها، مراقبتهای بهداشتی است. در این زمینه، مدلهای Multimodal AI قادرند تصاویر پزشکی مانند MRI، CT و سونوگرافی را با دادههای بالینی و یادداشتهای پزشکان ترکیب کنند تا تشخیص دقیقتر و سریعتری ارائه دهند. این قابلیت به پزشکان کمک میکند تا تصمیمگیریهای درمانی بهتری داشته باشند و خطاهای تشخیصی کاهش یابد.
مثال: در حوزه پزشکی، پروژه IBM Watson for Health از مدلهای Multimodal AI برای تحلیل تصاویر پزشکی، یادداشتهای بالینی و دادههای ژنتیکی استفاده میکند. این سیستم توانسته تشخیص بیماریها و پیشنهاد درمانها را با دقت بالاتری نسبت به روشهای سنتی ارائه دهد.
- در رسانههای اجتماعی، این مدلها میتوانند محتواهای متنی، تصویری و ویدیویی کاربران را تحلیل کنند تا احساسات، علایق و رفتارهای آنها شناسایی شود. این کاربرد برای برندها و بازاریابها اهمیت بالایی دارد؛ زیرا میتوانند تجربه کاربری شخصیسازیشده و استراتژیهای بازاریابی دقیقتری طراحی کنند.
مثال: مدل CLIP از OpenAI قادر است تصاویر و متنهای همراه آنها را تحلیل کرده و محتواهای مشابه یا مرتبط را شناسایی کند.
- در حوزه خودروهای خودران، مدلهای چندوجهی با ترکیب دادههای دوربینها، رادارها، حسگرهای صوتی و نقشهها، توانایی تصمیمگیری در لحظه و شناسایی موانع را دارند. این امر باعث افزایش ایمنی و عملکرد بهینه خودرو میشود.
مثال: خودروهای خودران Tesla Autopilot با پردازش همزمان دادههای دوربینها، رادار و نقشهها تصمیمگیری لحظهای میکنند و ایمنی رانندگی را افزایش میدهند.
- سیستمهای آموزشی نیز از این فناوری بهره میبرند تا تجربه یادگیری تعاملیتری ایجاد کنند. با پردازش همزمان متن، تصویر و ویدیو، مدلها میتوانند بازخوردهای دقیقتر و محتواهای متناسب با سطح دانش دانشآموزان ارائه دهند.
- در تجارت الکترونیک، مدلهای Multimodal AI با تحلیل رفتار مشتری از طریق دادههای متنی، تصویری و تعاملی، تجربه خرید شخصیسازیشده و پیشبینی نیازهای کاربران را ممکن میسازند. این کاربردها نه تنها باعث افزایش رضایت مشتری میشوند بلکه به کسبوکارها کمک میکنند تصمیمات هوشمندانهتری در بازاریابی و فروش اتخاذ کنند.
وظایف اصلی مدلهای هوش مصنوعی چندوجهی (Multimodal AI)
مدلهای هوش مصنوعی چندوجهی دارای وظایف متنوعی هستند که آنها را از مدلهای تکوجهی متمایز میکند. ادغام دادهها از منابع مختلف یکی از مهمترین وظایف این مدلهاست؛ به این معنا که اطلاعات متنی، تصویری، صوتی و ویدیویی به گونهای ترکیب میشوند که مدل بتواند یک نمای جامع از موضوع مورد نظر بسازد. این ادغام امکان درک عمیقتر و دقیقتر از دادهها را فراهم میکند.
یکی دیگر از وظایف اصلی، تولید خروجیهای چندوجهی است. مدلهای Multimodal AI میتوانند بر اساس ورودیهای ترکیبی، خروجیهایی در قالب متن، تصویر، صدا یا ویدیو ایجاد کنند. برای مثال، میتوانند تصویر یک صحنه را تحلیل کرده و توضیح متنی درباره آن ارائه دهند یا بر اساس متن، تصویر تولید کنند.
این مدلها همچنین قادر به درک زمینه و معنای عمیقتر دادهها هستند، به طوری که اطلاعات ناقص یا مبهم از یک منبع با دادههای دیگر تکمیل میشود. علاوهبر این، توانایی پاسخ به سوالات پیچیده با اطلاعات چندمنبعی و شبیهسازی تعاملات انسانی با ورودیهای چندگانه از ویژگیهای دیگر آنهاست. این تواناییها باعث میشوند مدلهای چندوجهی در تصمیمگیری، تعامل با کاربران و کاربردهای عملی دنیای واقعی عملکرد بسیار موثری داشته باشند.
مراحل پیادهسازی مدلهای هوش مصنوعی چندوجهی (Multimodal AI)
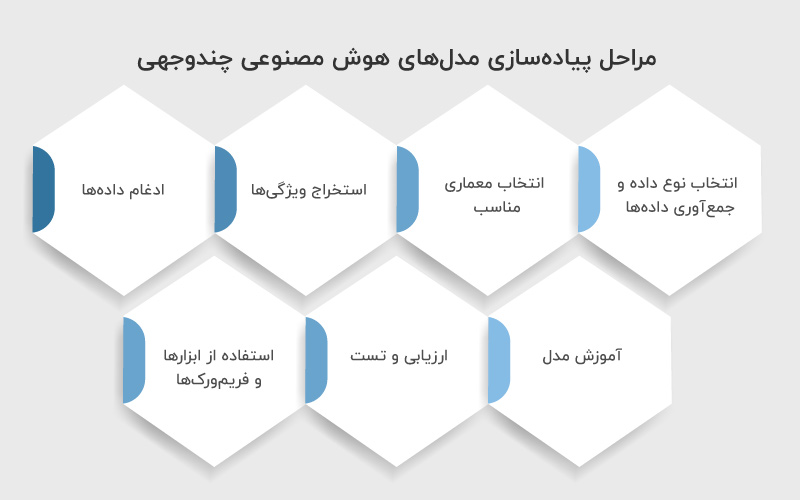
در مهندسی هوش مصنوعی پیادهسازی یک مدل Multimodal AI را میتوان به مراحل مشخص و گامبهگام تقسیم کرد:
۱. انتخاب نوع داده و جمعآوری دادهها
- شناسایی منابع داده: متن، تصویر، صدا و ویدیو
- جمعآوری دادههای با کیفیت و متنوع برای هر نوع داده
- پیشپردازش دادهها برای حذف نویز و استانداردسازی
۲. انتخاب معماری مناسب
- استفاده از شبکه عصبی کانولوشنی (CNN) برای تصاویر و ویدیوها
- استفاده از RNN یا Transformer برای متن و دادههای صوتی
- در نظر گرفتن ترکیب معماریها برای دادههای چندوجهی
۳. استخراج ویژگیها (Feature Extraction)
- پردازش هر نوع داده بهصورت جداگانه برای استخراج ویژگیهای مهم
- استفاده از مدلهای پیشآموزشدیده (Pre-trained) برای بهبود عملکرد و کاهش زمان آموزش
۴. ادغام دادهها (Fusion)
- انتخاب روش مناسب ادغام: Early Fusion، Late Fusion یا Hybrid Fusion
- ترکیب ویژگیهای استخراجشده از منابع مختلف به منظور ایجاد نمای جامع از دادهها
۵. آموزش مدل (Training)
- ارائه دادههای ترکیبی به مدل برای یادگیری روابط میان دادهها
- تنظیم پارامترهای مدل و بهینهسازی با استفاده از الگوریتمهای یادگیری
۶. ارزیابی و تست (Evaluation)
- استفاده از معیارهایی مانند دقت (Accuracy)، فراخوانی (Recall)، F1-Score و معیارهای خاص حوزه کاربرد
- بررسی عملکرد مدل در دادههای واقعی و شبیهسازیشده
۶. استفاده از ابزارها و فریمورکها
- بهرهگیری از PyTorch Multimodal، TensorFlow Multimodal، Hugging Face و OpenAI API برای توسعه، آموزش و آزمایش مدلها
- استفاده از این ابزارها برای سادهتر کردن پیادهسازی و افزایش سرعت توسعه
چالشها و ملاحظات اخلاقی در هوش مصنوعی چندوجهی
هوش مصنوعی چندوجهی با وجود مزایای چشمگیر، با چالشها و ملاحظات اخلاقی مهمی نیز مواجه است. یکی از مسائل کلیدی، نیاز به دادههای با کیفیت و متنوع است. جمعآوری و استفاده از دادههای متعدد، به ویژه دادههای شخصی یا حساس، میتواند نگرانیهای مربوط به حریم خصوصی را افزایش دهد و نیازمند رعایت قوانین و استانداردهای حفاظت از دادههاست.
پیچیدگی در طراحی و آموزش مدلها نیز چالش دیگری است؛ مدلهای چندوجهی نیازمند منابع محاسباتی بالا هستند و مصرف انرژی بالای آنها میتواند به ملاحظات پایداری و محیط زیست مرتبط شود.
مسائل اخلاقی مانند تعصب (Bias) و شفافیت مدلها اهمیت زیادی دارند. مدلهای Multimodal AI ممکن است تعصبات موجود در دادههای ورودی را تقویت کنند یا تصمیمات غیرشفاف بگیرند که در کاربردهای حساس مثل پزشکی یا خودروسازی میتواند پیامدهای جدی داشته باشد.
پردازش مسئولانه دادهها، ارزیابی منظم عملکرد مدل و طراحی شفاف سیستمها، از جمله راهکارهایی هستند که میتوانند این چالشها را کاهش دهند و امنیت و اخلاق هوش مصنوعی را تضمین کنند.
نتیجهگیری
هوش مصنوعی چندوجهی (Multimodal AI) با توانایی پردازش همزمان دادههای متنی، تصویری، صوتی و ویدئویی، ابزار قدرتمندی برای بهبود دقت و کارایی در حوزههای مختلف از جمله پزشکی، خودروهای خودران، رسانه و آموزش فراهم کرده است. این مدلها نهتنها امکان تحلیل دقیقتر و تولید خروجیهای متنوع را فراهم میکنند، بلکه تجربه تعاملی بهتری برای کاربران ایجاد میکنند.
منابع
mckinsey.com | ibm.com | splunk.com | datacamp.com
سوالات متداول
Multimodal AI مدلهایی هستند که قادرند همزمان دادههای متنی، تصویری، صوتی و ویدیویی را پردازش و تحلیل کنند، در حالی که مدلهای تکوجهی تنها یک نوع داده را پردازش میکنند.
از جمله مهمترین ابزارها: PyTorch Multimodal، TensorFlow Multimodal، Hugging Face Multimodal Transformers و OpenAI API.
بله، مدلهای مولد چندوجهی مانند DALL·E، Imagen و GPT-4V میتوانند بر اساس دادههای ورودی ترکیبی، تصویر، متن یا ویدیو تولید کنند.


دیدگاهتان را بنویسید