
ChromaDB یک پایگاه داده برداری سبک و اوپنسورس است که برای ذخیرهسازی، جستجوی معنایی و بازیابی embeddingها در پروژههای مبتنی بر LLM طراحی شده است. وقتی در یک پروژه با دادههایی مثل متن، مستندات یا پاسخهای کاربر سروکار دارید و میخواهید بهجای تطابق سادهی کلمات، بر اساس شباهت مفهومی جستجو انجام دهید، استفاده از Chroma بهعنوان یک vector store میتواند مسیر پیادهسازی را بسیار سادهتر و قابلکنترلتر کند.
در این مقاله بررسی میکنیم ChromaDB دقیقا چه کاری انجام میدهد، چه تفاوتی با سایر پایگاههای داده برداری دارد و چرا در اکوسیستم ابزارهایی مثل LangChain بهطور گسترده استفاده میشود. سپس بهصورت گامبهگام سراغ نصب و راهاندازی ChromaDB با Python میرویم و با مثالهای عملی یاد میگیریم چطور embeddingها را ذخیره کنیم، جستجوی معنایی انجام دهیم و از Chroma در سناریوهایی مثل RAG و سیستمهای پرسشوپاسخ استفاده کنیم.
ChromaDB چیست و چه مسئلهای را حل میکند؟

در پروژههایی که با مدلهای زبانی بزرگ (LLM) کار میکنند، مسئله فقط تولید متن نیست؛ بازیابی اطلاعات مرتبط نقش تعیینکنندهای در کیفیت خروجی دارد. وقتی حجم دادهها زیاد میشود—مثلا مستندات، لاگها، FAQها یا مکالمات قبلی—جستجوی سادهی متنی دیگر جوابگو نیست. اینجا پای پایگاههای داده برداری به میان میآید و ChromaDB دقیقا برای حل همین مسئله طراحی شده است.
Chroma یک پایگاه داده برداری است که embeddingهای تولیدشده توسط مدلهای زبانی را ذخیره میکند و امکان جستجوی معنایی (Similarity Search) روی آنها را فراهم میسازد. بهجای اینکه دنبال تطابق دقیق کلمات باشید، Chroma شباهت مفهومی بین دادهها را محاسبه میکند؛ یعنی حتی اگر کاربر از واژههای متفاوتی استفاده کند، سیستم همچنان میتواند پاسخ مرتبط را پیدا کند.
نقش Chroma در معماری
در یک معماری رایج مبتنی بر RAG، ChromaDB معمولا این نقش را دارد:
۱. دریافت متن خام (مثلا فایل، دیتابیس، یا ورودی کاربر)
۲. تبدیل متن به امبدینگ با استفاده از یک مدل embedding
۳. ذخیره embeddingها در ChromaDB
۴. بازیابی نزدیکترین بردارها هنگام پرسش کاربر
۵. ارسال نتایج بازیابیشده به LLM برای تولید پاسخ
به بیان ساده، Chroma حافظهی معنایی سیستم شماست؛ حافظهای که بهجای کلمات، با بردارها فکر میکند.
چرا ChromaDB برای توسعهدهندگان محبوب است؟
چند ویژگی باعث شده ChromaDB در میان ابزارهای مشابه (مثل FAISS، Pinecone یا Milvus) جایگاه خاصی پیدا کند:
- راهاندازی سریع بدون نیاز به زیرساخت پیچیده
- امکان استفادهی محلی (in-memory یا روی دیسک)
- یکپارچگی مستقیم با LangChain
- API ساده برای ذخیره و بازیابی embeddingها
- مناسب برای MVP، تست و حتی برخی سناریوهای production سبک
به همین دلیل، Chroma اغلب انتخاب اول تیمهایی است که میخواهند سریع وارد فاز پیادهسازی شوند، بدون اینکه درگیر پیچیدگیهای دیتابیسهای توزیعشده شوند.
معماری و مزایای ChromaDB
ChromaDB با این هدف طراحی شده که کار با وکتور دیتابیس را برای توسعهدهندهها ساده، سریع و قابل کنترل کند. برخلاف بسیاری از گزینههای مشابه که بیشتر برای مقیاسهای بزرگ سازمانی ساخته شدهاند، Chroma تمرکز ویژهای روی توسعه سریع (Rapid Prototyping) و تجربه توسعهدهنده دارد.
در معماری Chroma، تمرکز اصلی روی سه لایه است:
۱. لایهی Embedding
Chromaخودش امبدینگ تولید نمیکند و بهجای آن با مدلهای مختلف (OpenAI، HuggingFace، یا مدلهای لوکال) کار میکند. این جداسازی باعث انعطافپذیری بالا در انتخاب مدل میشود.
۲. لایهی ذخیرهسازی و ایندکس برداری
بردارها بههمراه document و metadata در collectionها ذخیره میشوند و Chroma عملیات similarity search را با کارایی بالا انجام میدهد.
۳. لایهی API و Integration
APIساده Chroma بهگونهای طراحی شده که بهراحتی با ابزارهایی مثل LangChain و LlamaIndex ترکیب شود؛ بدون نیاز به تنظیمات پیچیده دیتابیسی.
مزایای کلیدی ChromaDB

ChromaDB با تمرکز روی سادگی، انعطافپذیری و تجربهی توسعهدهنده طراحی شده است. بهجای ارائهی یک سیستم پیچیده و سنگین، تلاش میکند نیازهای رایج در پروژههای مبتنی بر LLM و semantic search را با حداقل سربار فنی پوشش دهد. مزایای آن عبارتند از:
اوپنسورس و مناسب استفاده تجاری
ChromaDB تحت لایسنس Apache 2.0 منتشر شده است. این یعنی میتوان بدون محدودیت، حتی در پروژههای تجاری، از آن استفاده کرد؛ مزیتی مهم برای تیمهایی که نمیخواهند به سرویسهای SaaS وابسته باشند.
سبک و قابل اجرا روی لپتاپ
یکی از تفاوتهای مهم Chroma با بسیاری از vector databaseها این است که بهراحتی روی سیستم شخصی اجرا میشود. این ویژگی آن را به گزینهای ایدئال برای تست، یادگیری و ساخت MVP تبدیل میکند.
یکپارچگی قوی با اکوسیستم LLM
Chroma بهصورت پیشفرض با ابزارهای رایج اکوسیستم LLM سازگار است:
- Python و JavaScript
- LangChain
- LlamaIndex
این یکپارچگی باعث میشود راهاندازی pipelineهایی مثل RAG بسیار سریعتر و تمیزتر انجام شود.
ChromaDB چگونه کار میکند؟
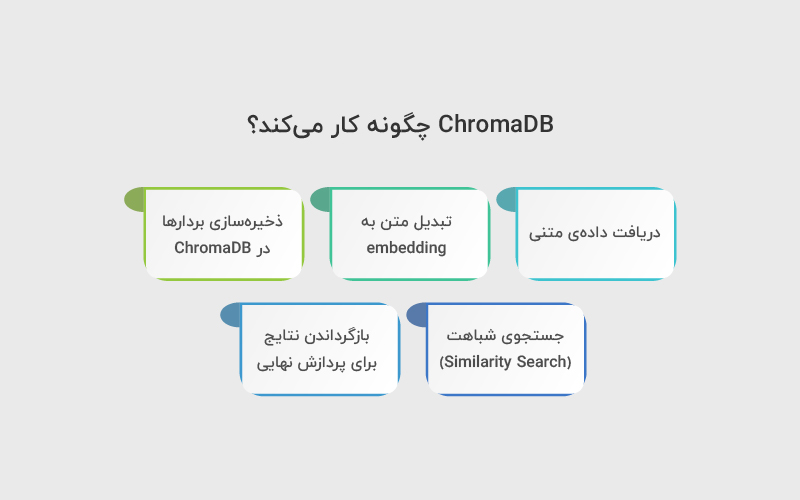
برای استفادهی درست از ChromaDB، مهم است بدانیم در پشت صحنه چه اتفاقی میافتد. Chroma یک سیستم ذخیرهسازی و بازیابی برداری است که روی embeddingها کار میکند؛ یعنی نمایش عددی متن که شباهت معنایی را قابل محاسبه میکند.
فرایند کلی کار ChromaDB را میتوان در چند مرحله خلاصه کرد:
۱. دریافت دادهی متنی
این داده میتواند هر چیزی باشد: فایلهای متنی، مستندات، دیتابیس، یا حتی پیامهای چت.
۲. تبدیل متن به embedding
متن ورودی با استفاده از یک مدل embedding به بردارهای عددی با ابعاد بالا تبدیل میشود.
۳. ذخیرهسازی بردارها در ChromaDB
هر embedding بههمراه متادیتا (مثل منبع، تاریخ، یا شناسه) در یک collection ذخیره میشود.
۴. جستجوی شباهت (Similarity Search)
هنگام پرسش کاربر، سوال نیز به embedding تبدیل شده و Chroma نزدیکترین بردارها را بر اساس معیارهایی مثل cosine similarity بازیابی میکند.
۵. بازگرداندن نتایج برای پردازش نهایی
نتایج بازیابیشده معمولا به یک LLM داده میشوند تا پاسخ نهایی تولید شود (الگوی RAG).
نکته مهم این است که ChromaDB خودش مدل زبانی یا embedding تولید نمیکند؛ بلکه روی ذخیرهسازی، ایندکسگذاری و بازیابی سریع بردارها تمرکز دارد.
مقایسه حالتهای اجرای Chroma
ChromaDB را میتوان به چند شکل مختلف اجرا کرد که هرکدام برای یک سناریوی خاص مناسباند. انتخاب حالت اجرا، مستقیما به مرحله پروژه و نیازهای فنی شما بستگی دارد.
اجرای In-Memory
در این حالت، تمام دادهها فقط در حافظهی RAM نگهداری میشوند و با پایان اجرای برنامه از بین میروند.
مناسب برای:
- تست و یادگیری
- نمونههای اولیه (Prototype)
- اسکریپتهای موقتی
مزیت اصلی آن سادگی و سرعت بالا اما عدم ذخیرهسازی دائمی دادهها جزو محدودیت آن است.
اجرای Persistent (ذخیره روی دیسک)
در این حالت، Chroma دادهها را روی دیسک ذخیره میکند و بعد از ریاستارت هم در دسترس میمانند.
مناسب برای:
- پروژههای واقعی کوچک تا متوسط
- سیستمهای RAG لوکال
- ابزارهای داخلی تیمها
مزیت اصلی آن پایداری دادهها بدون پیچیدگی دیتابیسهای بزرگ است.
اجرای Server-based با Docker
Chroma میتواند بهصورت یک سرویس مستقل اجرا شود (مثلا داخل Docker) و از طریق API در دسترس باشد.
مناسب برای:
- تیمهای چندنفره
- پروژههایی با چند سرویس
- استفاده همزمان چند اپلیکیشن از یک دیتابیس برداری
مزیت اصلی آن جداسازی دیتابیس از منطق اپلیکیشن و مقیاسپذیری بهتر است.
Chroma Cloud (سرویس مدیریتشده)
Chroma Cloud نسخه مدیریتشدهای از Chroma است که نیاز به نگهداری زیرساخت را حذف میکند.
مناسب برای:
- پروژههای Production
- تیمهایی که نمیخواهند درگیر DevOps شوند
- سناریوهای مقیاسپذیر
مزیت اصلی آن تمرکز کامل روی منطق محصول بهجای زیرساخت است.
نصب و راهاندازی Chroma
برای شروع کار با ChromaDB، ابتدا باید محیط توسعه را آماده کنیم و وابستگیهای لازم را نصب کنیم. Chroma بهگونهای طراحی شده که هم بتوان آن را بهصورت کاملا محلی و بدون نیاز به تنظیمات پیچیده اجرا کرد و هم در مقیاس بزرگتر از طریق سرور یا Chroma Cloud به کار گرفت. در این بخش، مراحل نصب و راهاندازی ChromaDB را قدمبهقدم بررسی میکنیم و سناریوهای رایج استفاده از آن در کنار LangChain و Python را مرور خواهیم کرد.
Chroma علاوهبر امکان استفادهی مستقیم از API خود، بهراحتی با ابزارهایی مانند LangChain یکپارچه میشود. در این مقاله، بهجای تمرکز روی API، از رویکرد مبتنی بر LangChain برای راهاندازی و استفاده عملی استفاده میکنیم.
راهاندازی (Setup)
برای استفاده از Chroma vector store در LangChain، ابتدا باید پکیج یکپارچهسازی langchain-chroma را نصب کنید:
|
1 |
pip install –qU “langchain-chroma>=0.1.2” |
احراز هویت (Credentials)
برای استفاده از Chroma نیازی به هیچگونه credential نیست و صرفا نصب پکیج بالا کافی است.
اگر از Chroma Cloud استفاده میکنید، باید متغیرهای محیطی زیر را تنظیم کنید:
- CHROMA_TENANT
- CHROMA_DATABASE
- CHROMA_API_KEY
با نصب پکیج chromadb، به CLI Chroma نیز دسترسی خواهید داشت که میتواند این تنظیمات را برای شما انجام دهد. ابتدا از طریق CLI لاگین کنید و سپس با دستور زیر به دیتابیس متصل شوید:
|
1 |
chroma db connect [db_name] —env–file |
اگر میخواهید تریسینگ خودکار و دقیق از فراخوانیهای مدل داشته باشید، میتوانید کلید API مربوط به LangSmith را نیز تنظیم کنید:
|
1 2 |
os.environ[“LANGSMITH_API_KEY”] = getpass.getpass(“Enter your LangSmith API key: “) os.environ[“LANGSMITH_TRACING”] = “true” |
مقداردهی اولیه (Initialization)
در مثال زیر، یک مقداردهی اولیه ساده بههمراه ذخیرهسازی محلی دادهها انجام شده است:
|
1 2 3 |
from langchain_openai import OpenAIEmbeddings embeddings = OpenAIEmbeddings(model=“text-embedding-3-large”) |
اجرای محلی (In-Memory)
اگر فقط قصد تست یا توسعه دارید و نیازی به ذخیرهسازی دائمی دادهها ندارید، میتوانید Chroma را بهصورت در حافظه (In-Memory) اجرا کنید:
|
1 2 3 4 5 6 |
from langchain_chroma import Chroma vector_store = Chroma( collection_name=“example_collection”, embedding_function=embeddings, ) |
این روش برای آزمایش سریع هنگام توسعهی اپلیکیشنهای LangChain بسیار مناسب است.
اجرای محلی با ذخیرهسازی داده (Persistent)
برای نگهداشتن دادهها بین اجرایهای مختلف برنامه، از پارامتر persist_directory استفاده کنید:
|
1 2 3 4 5 6 7 |
from langchain_chroma import Chroma vector_store = Chroma( collection_name=“example_collection”, embedding_function=embeddings, persist_directory=“./chroma_langchain_db”, ) |
اتصال به سرور Chroma
اگر یک سرور Chroma بهصورت محلی یا روی سرور اجرا کردهاید، میتوانید با تعیین host به آن متصل شوید.
مثلاً اگر سرور را با دستور chroma run اجرا کردهاید:
|
1 2 3 4 5 6 7 |
from langchain_chroma import Chroma vector_store = Chroma( collection_name=“example_collection”, embedding_function=embeddings, host=“localhost”, ) |
در سایر سناریوها میتوانید پارامترهایی مثل port، ssl و headers را نیز تنظیم کنید.
Chroma Cloud
کاربران Chroma Cloud میتوانند LangChain را بهصورت مستقیم به Chroma Cloud متصل کنند:
|
1 2 3 4 5 6 7 8 9 |
from langchain_chroma import Chroma vector_store = Chroma( collection_name=“example_collection”, embedding_function=embeddings, chroma_cloud_api_key=os.getenv(“CHROMA_API_KEY”), tenant=os.getenv(“CHROMA_TENANT”), database=os.getenv(“CHROMA_DATABASE”), ) |
مقداردهی از طریق Client
اگر میخواهید به دیتابیس Chroma دسترسی مستقیمتری داشته باشید، میتوانید ابتدا یک client بسازید.
اجرای محلی (In-Memory)
|
1 2 3 |
import chromadb client = chromadb.Client() |
اجرای محلی با ذخیرهسازی داده
|
1 2 3 |
import chromadb client = chromadb.PersistentClient(path=“./chroma_langchain_db”) |
اتصال به سرور Chroma
|
1 2 3 |
import chromadb client = chromadb.HttpClient(host=“localhost”, port=8000, ssl=False) |
Chroma Cloud
پس از تنظیم متغیرهای محیطی:
|
1 2 3 |
import chromadb client = chromadb.CloudClient() |
دسترسی به دیتابیس Chroma
|
1 2 |
collection = client.get_or_create_collection(“collection_name”) collection.add(ids=[“1”, “2”, “3”], documents=[“a”, “b”, “c”]) |
ساخت Vector Store از Client
|
1 2 3 4 5 |
vector_store_from_client = Chroma( client=client, collection_name=“collection_name”, embedding_function=embeddings, ) |
مدیریت Vector Store
افزودن اسناد (Add)
|
1 2 3 4 5 |
from uuid import uuid4 from langchain_core.documents import Document (تعریف اسناد — بدون تغییر باقی میماند) vector_store.add_documents(documents=documents, ids=uuids) |
بهروزرسانی اسناد (Update)
|
1 2 3 4 5 |
vector_store.update_document(document_id=uuids[0], document=updated_document_1) vector_store.update_documents( ids=uuids[:2], documents=[updated_document_1, updated_document_2] ) |
حذف اسناد (Delete)
|
1 |
vector_store.delete(ids=uuids[–1]) |
جستجو در Vector Store
جستجوی شباهت (Similarity Search)
|
1 2 3 4 5 |
results = vector_store.similarity_search( “LangChain provides abstractions to make working with LLMs easy”, k=2, filter={“source”: “tweet”}, ) |
جستجوی شباهت همراه با امتیاز
|
1 2 3 |
results = vector_store.similarity_search_with_score( “Will it be hot tomorrow?”, k=1, filter={“source”: “news”} ) |
جستجو بر اساس بردار
|
1 2 3 |
results = vector_store.similarity_search_by_vector( embedding=embeddings.embed_query(“I love green eggs and ham!”), k=1 ) |
استفاده بهعنوان Retriever
|
1 2 3 4 |
retriever = vector_store.as_retriever( search_type=“mmr”, search_kwargs={“k”: 1, “fetch_k”: 5} ) retriever.invoke(“Stealing from the bank is a crime”, filter={“source”: “news”}) |
مثال عملی کامل با Chroma
در این بخش میخواهیم یک سناریوی واقعی را قدمبهقدم پیادهسازی کنیم:
چند متن را ذخیره میکنیم، برای آنها embedding میسازیم، در Chroma نگه میداریم و در نهایت با جستجوی شباهت (Similarity Search) مرتبطترین نتایج را برمیگردانیم. این دقیقا همان چیزی است که در سیستمهای RAG و جستجوی معنایی استفاده میشود.
۱. ذخیره متنها در Chroma
ابتدا چند متن نمونه تعریف میکنیم. در یک پروژه واقعی، این متنها میتوانند محتوای مستندات، مقالات، FAQ یا دادههای داخلی شرکت باشند.
|
1 2 3 4 5 6 |
texts = [ “Chroma یک پایگاه داده برداری متنباز برای ذخیره embedding هاست.”, “LangChain ابزاری برای ساخت اپلیکیشنهای مبتنی بر LLM است.”, “Vector Database امکان جستجوی معنایی را فراهم میکند.”, “Chroma بهسادگی با LangChain و Python یکپارچه میشود.” ] |
در این مرحله:
- هنوز embedding ساخته نشده
- فقط دادهی خام متنی داریم
- Chroma بعدا این متنها را به بردار تبدیل میکند
۲. تولید embedding با OpenAI (یا مدل دیگر)
حالا باید متنها را به بردارهای عددی تبدیل کنیم. این کار با Embedding Model انجام میشود.
مثال با OpenAI:
|
1 2 3 4 5 |
from langchain.embeddings import OpenAIEmbeddings embeddings = OpenAIEmbeddings( model=“text-embedding-3-small” ) |
توضیح:
- OpenAIEmbeddings مسئول ارتباط با API است
- هر متن ← یک بردار عددی با طول ثابت
- اگر نخواستید از OpenAI استفاده کنید، میتوانید از:
- HuggingFace
- SentenceTransformers
- یا مدلهای لوکال استفاده کنید
۳. ساخت Vector Store با Chroma
حالا متنها و embedding را به Chroma میدهیم تا ذخیره شوند.
|
1 2 3 4 5 6 7 |
from langchain.vectorstores import Chroma vectorstore = Chroma.from_texts( texts=texts, embedding=embeddings, persist_directory=“./chroma_db” ) |
این کد چه کار میکند؟
- from_texts:
- متنها را میگیرد
- embedding میسازد
- همه را در Chroma ذخیره میکند
- persist_directory:
- باعث میشود دادهها روی دیسک ذخیره شوند
- اگر برنامه بسته شود، اطلاعات از بین نمیرود
۴. جستجوی شباهت (Similarity Search)
حالا میتوانیم یک پرسوجوی معنایی بزنیم:
|
1 2 3 4 5 6 |
query = “پایگاه داده برداری چیست؟” results = vectorstore.similarity_search( query=query, k=2 ) |
توضیح:
- query یک متن طبیعی است (نه کلیدواژه)
- Chroma:
- embedding کوئری را میسازد
- نزدیکترین بردارها را پیدا میکند
- k=2 یعنی دو نتیجهی مرتبطتر برگردانده شود
۵. نمایش نتایج
|
1 2 |
for doc in results: print(doc.page_content) |
خروجی:
- متنی که از نظر معنایی بیشترین شباهت را دارد
- دقیقا همان چیزی که در سیستمهای پرسشوپاسخ استفاده میشود
نکات عملی و چالشها در استفاده از Chroma
بعد از پیادهسازی، چند نکتهی مهم وجود دارد که دانستن آنها جلوی دردسرهای بعدی را میگیرد.
مشکلات رایج نصب و Persist
- پاک شدن دادهها بعد از ریاستارت
- ناسازگاری نسخهی chromadb با langchain
- رفتار غیرمنتظره در persist_directory
راهکارها
- حتما مسیر persist_directory را مشخص کنید
نسخهها را قفل کنید:
|
1 |
pip install chromadb==0.4.x langchain==0.1.x |
- در پروژههای واقعی، از تست persist بعد از ریاستارت استفاده کنید
در انجمنهایی مثل Reddit بارها گزارش شده که wrapper های LangChain در نسخههای خاص با Chroma مشکل داشتهاند، بنابراین بررسی نسخهها مهم است.
مقایسه مختصر Chroma با سایر Vector DBها
| ابزار | مناسب برای | پیچیدگی |
| Chroma | پروژههای Python، MVP، RAG | کم |
| FAISS | پردازش سریع لوکال | متوسط |
| Pinecone | مقیاس ابری بالا | زیاد |
| Weaviate | گراف + متادیتا | زیاد |
Chroma بهترین انتخاب برای شروع و پروژههای آموزشی و نیمهتولیدی است.
جمعبندی
Chroma یک پایگاه داده برداری ساده، سبک و متنباز است که بهخصوص در اکوسیستم Python و LangChain تجربهی توسعهی روانی ارائه میدهد. اگر هدف شما ساخت سیستمهای مبتنی بر embedding، جستجوی معنایی یا RAG است، Chroma میتواند نقطهی شروع بسیار مناسبی باشد.
منابع
docs.langchain.com | medium.com | oracle.com | deepchecks.com
سوالات متداول
ChromaDB یک پایگاه داده برداری متنباز است که برای ذخیره و جستجوی embeddingها طراحی شده است. این ابزار امکان جستجوی معنایی، پیادهسازی سیستمهای RAG و ساخت چتباتهای مبتنی بر اسناد را بهسادگی فراهم میکند.
در پایگاه دادههای سنتی دادهها بهصورت ساختاریافته ذخیره میشوند، اما ChromaDB دادهها را به شکل بردارهای عددی نگه میدارد. این ساختار باعث میشود بتوان شباهت معنایی بین متون را محاسبه کرد، نه صرفاً تطابق کلمات.
خیر، ChromaDB میتواند بهصورت مستقل استفاده شود. LangChain تنها یک لایهی کمکی است که کار با embeddingها، مدلهای زبانی و زنجیرههای پردازشی را سادهتر میکند.
تمرکز اصلی ChromaDB روی Python است، اما APIهای آن بهگونهای طراحی شدهاند که امکان استفاده در محیطهای مختلف و اتصال به سرویسهای دیگر نیز وجود داشته باشد.
بله، ChromaDB متنباز و رایگان است. تنها هزینهی احتمالی مربوط به استفاده از سرویسهای جانبی مانند APIهای تولید embedding (مثلا OpenAI) خواهد بود.




دیدگاهتان را بنویسید