
ساخت Multimodal AI با LangChain رویکردی نوین برای ایجاد سیستمهای هوش مصنوعی است که میتوانند همزمان با چند نوع داده مانند متن، تصویر و سایر ورودیهای غیرمتنی کار کنند. برخلاف سیستمهای سنتی که تنها به ورودی متنی محدود بودند، مدلهای چندوجهی این امکان را فراهم میکنند که هوش مصنوعی درک غنیتری از دنیای واقعی داشته باشد. LangChain بهعنوان یک لایه orchestration، نقش کلیدی در اتصال مدلهای زبانی، دادههای چندرسانهای و منطق برنامه ایفا میکند و مسیر توسعه چنین سیستمهایی را ساختاریافتهتر و قابل مدیریتتر میسازد.
در این مقاله، بهصورت گامبهگام به طراحی و پیادهسازی multimodal AI با LangChain میپردازیم. ابتدا مفهوم multimodality و اهمیت آن را توضیح میدهیم، سپس بررسی میکنیم LangChain چگونه از ورودیهای چندرسانهای پشتیبانی میکند. در ادامه با یک مثال ساده متن و تصویر شروع میکنیم و بعد به سراغ معماریهای پیشرفتهتر مثل Multi-Modal RAG میرویم تا ببینیم چطور میتوان از LangChain برای ساخت اپلیکیشنهای چندرسانهای واقعی و قابل استفاده در مقیاس محصول بهره برد.
Multimodal یعنی چه و چرا مهم است؟

در دنیای واقعی، اطلاعات فقط به شکل متن وجود ندارند. انسانها همزمان با دیدن، شنیدن و خواندن تصمیم میگیرند، اما بسیاری از سیستمهای هوش مصنوعی سنتی فقط قادر به پردازش متن بودند. اصطلاح Multimodal به سیستمهایی اشاره دارد که میتوانند چند نوع داده (modalities) مانند متن، تصویر، صدا یا ویدیو را بهصورت همزمان دریافت، تحلیل و ترکیب کنند.
برای مثال، یک سیستم فقط متنی ممکن است بتواند به سوال «این تصویر درباره چیست؟» پاسخ ندهد، اما یک سیستم multimodal میتواند خود تصویر را ببیند، محتوای آن را تحلیل کند و سپس پاسخ متنی دقیق ارائه دهد. این تغییر، هوش مصنوعی را از یک ابزار صرفا متنی به یک سیستم نزدیکتر به درک انسانی تبدیل میکند.
تفاوت سیستمهای متنی با سیستمهای Multimodal
برای درک بهتر اهمیت multimodality، مقایسه زیر کمککننده است:
سیستم فقط متنی
- ورودی: متن
- خروجی: متن
- محدود به توصیفهایی است که کاربر از قبل نوشته
سیستم Multimodal
- ورودی: متن + تصویر (و در موارد پیشرفتهتر صدا و ویدیو)
- خروجی: متن، تحلیل یا تصمیم
- قادر به تحلیل مستقیم دادههای غیرمتنی
به همین دلیل، بسیاری از مسائل واقعی را نمیتوان فقط با متن حل کرد. اسناد اسکنشده، تصاویر محصولات، نمودارها، اسلایدها و حتی اسکرینشاتها همگی نیاز به پردازش چندرسانهای دارند.
چرا Multimodal AI برای اپلیکیشنهای واقعی حیاتی است؟
اهمیت multimodal AI زمانی مشخص میشود که وارد سناریوهای واقعی محصول میشویم. برخی نمونههای رایج عبارتاند از:
- پرسش و پاسخ روی تصاویر: مثل پرسیدن درباره محتوای یک نمودار، فاکتور یا تصویر محصول
- تحلیل اسناد ترکیبی: اسنادی که هم متن دارند و هم تصویر (PDFها، اسلایدها، کاتالوگها)
- جستجوی پیشرفته: جستجو در مجموعهای از متنها و تصاویر بهصورت همزمان
- سیستمهای پشتیبانی هوشمند: تحلیل اسکرینشات خطا به همراه توضیح متنی کاربر
در تمام این سناریوها، اگر سیستم فقط متن را بفهمد، بخش مهمی از اطلاعات را از دست میدهد.
نقش LangChain در دنیای Multimodal
اینجا دقیقا جایی است که LangChain اهمیت پیدا میکند. وقتی با دادههای چندرسانهای سروکار داریم، فقط «مدل» کافی نیست؛ ما به سیستمی نیاز داریم که بتواند:
- ورودیهای مختلف را مدیریت کند
- آنها را به مدل مناسب ارسال کند
- پاسخها را ترکیب و کنترل کند
LangChain این نقش را بهعنوان یک لایه هماهنگکننده (orchestration layer) بازی میکند. بهجای اینکه منطق پردازش متن، تصویر و retrieval را بهصورت پراکنده در کد پیادهسازی کنیم، LangChain کمک میکند این اجزا در یک جریان مشخص و قابل نگهداری کنار هم قرار بگیرند.
LangChain چگونه ورودیهای چندرسانهای را پشتیبانی میکند؟
برای ساخت یک سیستم multimodal AI، صرفا داشتن یک مدل چندرسانهای کافی نیست. چالش اصلی در عمل این است که چگونه متن، تصویر و سایر ورودیها را بهشکل درست مدیریت کنیم، به مدل مناسب بدهیم و خروجی قابل استفاده بگیریم. این دقیقا همان جایی است که LangChain نقش خود را نشان میدهد.
LangChain یک فریمورک orchestration است که کمک میکند تعامل بین مدلها، دادهها و منطق برنامه بهصورت ساختاریافته انجام شود. بهجای نوشتن کدهای پراکنده برای ارسال متن و تصویر به مدلهای مختلف، LangChain این فرایند را استاندارد و قابل کنترل میکند.
مفهوم Multimodal Models در LangChain
در LangChain، پشتیبانی از ورودیهای چندرسانهای از طریق مفهوم Multimodal Models انجام میشود. این مدلها میتوانند بیش از یک نوع ورودی را همزمان دریافت کنند؛ برای مثال:
- متن + تصویر
- توضیح متنی درباره یک تصویر
- پرسش متنی درباره محتوای یک تصویر
LangChain خودش مدل چندرسانهای نمیسازد، بلکه بهعنوان یک لایه میانی، ورودیها را در قالب مناسب آماده کرده و به مدلهایی که چندوجهی هستند ارسال میکند.
به بیان ساده:
- LangChain = مدیر جریان داده
- Multimodal Model = مغز تحلیل متن و تصویر
چرا LangChain برای Multimodal از API خام بهتر است؟
در مثالهای ساده، شاید استفاده مستقیم از API مدلهای multimodal کافی باشد. اما بهمحض اینکه:
- چند نوع ورودی داشته باشید
- بخواهید retrieval اضافه کنید
- یا پاسخ را با دادههای دیگر ترکیب کنید
کد بهسرعت پیچیده میشود. LangChain این پیچیدگی را مدیریت و مهار میکند، نه اینکه آن را حذف کند و همین موضوع برای پروژههای واقعی حیاتی است.
جریان ساده پردازش Multimodal در LangChain
در سادهترین حالت، جریان کار به این شکل است:
۱. کاربر ورودی متنی و تصویری ارسال میکند
۲. LangChain ورودیها را در قالب مناسب آماده میکند
۳. مدل multimodal (مثلا یک LLM با پشتیبانی تصویر) ورودی را تحلیل میکند
۴. پاسخ متنی تولید میشود
۵. LangChain پاسخ را به لایه بعدی (نمایش، ذخیره، یا پردازش بیشتر) میفرستد
این تفکیک مراحل باعث میشود کد:
- خواناتر باشد
- تستپذیرتر باشد
- و در پروژههای بزرگتر قابل نگهداری بماند
مثال Multimodal با LangChain (متن + تصویر)
تا اینجا درباره مفهوم multimodal و نقش LangChain صحبت کردیم. حالا وقتش رسیده با یک مثال ساده اما واقعی ببینیم چطور میتوان متن و تصویر را همزمان به یک مدل ارسال کرد و پاسخ گرفت. هدف این مثال این نیست که یک سیستم پیچیده بسازیم، بلکه میخواهیم جریان پایهی یک اپلیکیشن multimodal را درک کنیم.
در این سناریو، فرض میکنیم:
- یک تصویر داریم (مثلا تصویر یک محصول یا نمودار)
- یک سوال متنی درباره همان تصویر میپرسیم
- مدل با در نظر گرفتن هر دو ورودی پاسخ میدهد
پیشنیازها
برای اجرای این مثال به موارد زیر نیاز داریم:
- Python 3.9 یا بالاتر
- نصب LangChain
- دسترسی به یک مدل multimodal (مثل مدلهایی که ورودی تصویر را پشتیبانی میکنند)
- یک تصویر نمونه (URL یا فایل محلی)
نصب LangChain:
|
1 |
pip install langchain |
در این مثال تمرکز روی نحوه استفاده LangChain از ورودی چندرسانهای است، نه تنظیمات خاص یک ارائهدهنده مدل.
ایدهی کلی مثال
جریان داده در این مثال به شکل زیر است:
- کاربر یک تصویر + یک سوال متنی وارد میکند
- LangChain این دو ورودی را در یک پیام واحد ترکیب میکند
- مدل multimodal تصویر را تحلیل میکند
- پاسخ متنی تولید میشود
این دقیقا همان الگوی پایهای است که بعدا میتوان آن را گسترش داد و وارد معماریهای پیچیدهتر کرد.
آمادهسازی پیام Multimodal در LangChain
LangChain از ساختار پیامها (Messages) استفاده میکند. برای ورودی چندرسانهای، پیام میتواند شامل چند بخش مختلف باشد؛ مثلاً متن و تصویر در کنار هم.
نمونهای ساده از ساخت یک پیام multimodal:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from langchain_core.messages import HumanMessage message = HumanMessage( content=[ {“type”: “text”, “text”: “در این تصویر چه چیزی دیده میشود؟”}, { “type”: “image_url”, “image_url”: { “url”: “https://example.com/sample-image.jpg” } } ] ) |
در اینجا:
- بخش اول پیام، متن سوال است
- بخش دوم، تصویر موردنظر (بهصورت URL)
- LangChain این دو را بهعنوان یک ورودی واحد به مدل ارسال میکند
ارسال پیام به مدل با LangChain
حالا پیام ساختهشده را به یک مدل multimodal میدهیم. در LangChain، این کار معمولا از طریق یک کلاس مدل انجام میشود.
نمونه ساده:
|
1 2 3 4 5 6 7 8 9 10 |
from langchain.chat_models import ChatOpenAI model = ChatOpenAI( model=“gpt-4o-mini”, temperature=0 ) response = model.invoke([message]) print(response.content) |
در این مرحله:
- مدل متن و تصویر را همزمان دریافت میکند
- تصویر تحلیل میشود
- پاسخ متنی تولید میشود
چرا این مثال مهم است؟
این مثال ساده چند نکته کلیدی را نشان میدهد:
- ورودی multimodal در LangChain یک چیز پیچیده یا جادویی نیست
- متن و تصویر در یک ساختار استاندارد کنار هم قرار میگیرند
- همان الگوی پیامها که برای متن استفاده میشود، برای تصویر هم قابل گسترش است
در واقع، LangChain کمک میکند بدون درگیر شدن با جزئیات فرمتهای خام API، تمرکزمان روی منطق برنامه باشد.
LangChain در نقش مغز برنامههای چندرسانهای
وقتی یک مثال ساده multimodal (متن + تصویر) را پیادهسازی میکنیم، شاید در نگاه اول به نظر برسد که LangChain فقط یک لایهی نازک روی API مدل است. اما در عمل، ارزش اصلی LangChain زمانی مشخص میشود که سیستم شروع به بزرگ شدن، چندمرحلهای شدن و ترکیب با دادههای مختلف میکند.
در برنامههای چندرسانهای واقعی، ما معمولا فقط یک درخواست و یک پاسخ نداریم. بلکه با سناریوهایی مثل این روبهرو هستیم:
- ورودی کاربر شامل متن + تصویر + context قبلی است
- پاسخ مدل باید با دادههای داخلی سیستم ترکیب شود
- گاهی لازم است قبل یا بعد از پاسخ مدل، ابزار یا retrieval اجرا شود
LangChain دقیقا در این نقطه بهعنوان مغز (Coordinator) سیستم عمل میکند.
LangChain بهعنوان لایه Orchestration
میتوان LangChain را بهعنوان یک لایه orchestration در نظر گرفت که:
- تصمیم میگیرد چه ورودیای به کدام مدل برود
- مشخص میکند چه زمانی retrieval انجام شود
- خروجی مدل را به مرحله بعدی هدایت میکند
- اجازه میدهد کل جریان بهصورت مرحلهای و شفاف تعریف شود
در سیستمهای multimodal، این نقش حتی پررنگتر است، چون:
- ورودیها متنوعترند
- خطاها پیچیدهترند
- و نیاز به انعطافپذیری بیشتر است
چرا Multimodal بدون orchestration سریعا پیچیده میشود؟
فرض کنید بخواهید بدون LangChain یک سیستم زیر را بسازید:
- کاربر یک تصویر ارسال میکند
- یک سوال متنی میپرسد
- سیستم باید:
- تصویر را تحلیل کند
- اطلاعات مرتبط را از دیتابیس یا vector store پیدا کند
- پاسخ نهایی را با context کامل بسازد
اگر همه این مراحل را دستی و بدون ساختار انجام دهید:
- کد بهسرعت شلوغ و غیرقابل نگهداری میشود
- اضافه کردن قابلیت جدید (مثلا حافظه یا ابزار جدید) سخت میشود
- تست و دیباگ دشوار میشود
LangChain با تعریف الگوهای مشخص (Chains، Runnables، Pipelines) کمک میکند این پیچیدگی کنترلشده و قابل توسعه باقی بماند.
معماری و پیادهسازی یک Multi-Modal RAG ساده با LangChain
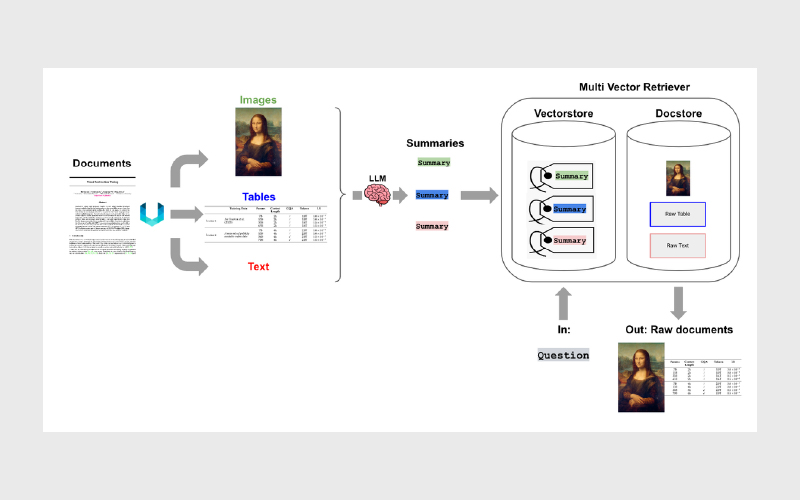
برای اینکه Multimodal RAG از حد تئوری خارج شود، بهتر است معماری و پیادهسازی را همزمان ببینیم. هدف این بخش ساخت یک pipeline کامل و واقعی است، اما به سادهترین شکل ممکن؛ بدون اینکه وارد جزئیات اضافی شویم.
- ابتدا تصاویر و متنها را از فایلها استخراج میکنیم.
- از یک Vision LLM میخواهیم برای آنها خلاصه/توضیح کوتاه تولید کند.
- خلاصهها را در Chroma امبد (Embed) میکنیم و فایلهای اصلی را در یک دیتابیس درونحافظهای (in-memory) ذخیره میکنیم.
- یک Multi-Vector Retriever میسازیم. این بازیاب با استفاده از امتیاز شباهت، خلاصهها را از وکتوراستور پیدا میکند و سپس سند/محتوای اصلی متناظر با آن خلاصهها را از دیتاستور برمیگرداند.
- در نهایت، اسناد بازیابیشده را به یک MM-LLM (مدل چندرسانهای) میدهیم تا پاسخ را تولید کند.
وابستگیها (Dependencies)
PDFها و بسیاری از فرمتهای داده معمولا جدول و تصویر داخل خود دارند. استخراج آنها به سادگی استخراج متن نیست. برای این کار به ابزارهایی نیاز داریم که مخصوص این کار طراحی شدهاند؛ مثل Unstructured.
Unstructured یک ابزار متنباز برای پیشپردازش فایلهایی مثل HTML، PDF و Word است و میتواند با استفاده از OCR، تصاویر جاسازیشده را از فایلها استخراج کند. برای اجرای Unstructured روی سیستم، باید Poppler و Tesseract نصب باشند.
نصب Tesseract و Poppler
|
1 2 |
!sudo apt install tesseract–ocr !sudo apt–get install poppler–utils |
حالا میتوانیم Unstructured را همراه با کتابخانههای موردنیاز نصب کنیم:
|
1 2 |
!pip install “unstructured[all-docs]” langchain langchain_community \ chromadb langchain–experimental |
استخراج تصاویر و جدولها (Extract Images and Tables)
برای استخراج تصاویر و جدولها از تابع partition_pdf استفاده میکنیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from unstructured.partition.pdf import partition_pdf image_path = “./” pdf_elements = partition_pdf( “mistral.pdf”, chunking_strategy=“by_title”, extract_images_in_pdf=True, max_characters=3000, new_after_n_chars=2800, combine_text_under_n_chars=2000, image_output_dir_path=image_path ) |
این کد PDF را بخشبندی (partition) میکند، تصاویر را در مسیر مشخصشده استخراج میکند، و متنها را نیز بر اساس استراتژی و محدودیتهای کاراکتری تعیینشده تکهتکه (chunk) میکند.
حالا متنها و جدولها را از هم جدا میکنیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Categorize elements by type def categorize_elements(raw_pdf_elements): “”“ Categorize extracted elements from a PDF into tables and texts. raw_pdf_elements: List of unstructured.documents.elements ““” tables = [] texts = [] for element in raw_pdf_elements: if “unstructured.documents.elements.Table” in str(type(element)): tables.append(str(element)) elif “unstructured.documents.elements.CompositeElement” in str(type(element)): texts.append(str(element)) return texts, tables texts, tables = categorize_elements(pdf_elements) |
خلاصهسازی متن و جدولها (Text and Table Summaries)
برای تولید خلاصههای کوتاه از چانکهای متن و جدولها، از Gemini Pro استفاده میکنیم. در LangChain یک زنجیرهی خلاصهسازی وجود دارد و ما با Expression Language یک زنجیرهی ساده میسازیم.
برای استفاده از مدلهای Gemini در LangChain باید:
- یک حساب GCP داشته باشید
- VertexAI را فعال کنید
- و Credentialها را تنظیم کنید
کد خلاصهسازی:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
from langchain.chat_models import ChatVertexAI from langchain.llms import VertexAI from langchain.prompts import PromptTemplate from langchain.schema.output_parser import StrOutputParser from langchain_core.messages import AIMessage from langchain_core.runnables import RunnableLambda # Generate summaries of text elements def generate_text_summaries(texts, tables, summarize_texts=False): “”“ Summarize text elements texts: List of str tables: List of str summarize_texts: Bool to summarize texts ““” # Prompt prompt_text = “”“You are an assistant tasked with summarizing tables and text for retrieval. \ These summaries will be embedded and used to retrieve the raw text or table elements. \ Give a concise summary of the table or text that is well-optimized for retrieval. Table \ or text: {element} ““” prompt = PromptTemplate.from_template(prompt_text) empty_response = RunnableLambda( lambda x: AIMessage(content=“Error processing document”) ) # Text summary chain model = VertexAI( temperature=0, model_name=“gemini-pro”, max_output_tokens=1024 ).with_fallbacks([empty_response]) summarize_chain = {“element”: lambda x: x} | prompt | model | StrOutputParser() # Initialize empty summaries text_summaries = [] table_summaries = [] # Apply to text if texts are provided and summarization is requested if texts and summarize_texts: text_summaries = summarize_chain.batch(texts, {“max_concurrency”: 1}) elif texts: text_summaries = texts # Apply to tables if tables are provided if tables: table_summaries = summarize_chain.batch(tables, {“max_concurrency”: 1}) return text_summaries, table_summaries # Get text, table summaries text_summaries2, table_summaries = generate_text_summaries( texts[9:], tables, summarize_texts=True ) |
در این زنجیره، چهار جزء اصلی داریم:
- یک دیکشنری برای عبور دادن دادهها
- ساخت prompt template
- مدل LLM
- پارسر رشتهای (StrOutputParser)
همچنین AIMessage بهکمک RunnableLambda در صورت خطا، یک پیام جایگزین برمیگرداند.
خلاصهسازی تصاویر (Image Summaries)
همانطور که گفتیم، برای تصاویر باید از یک مدل vision استفاده کنیم تا تصویر را به توضیح متنی تبدیل کند. میتوانید از GPT-4، Llava، Gemini و… استفاده کنید. در اینجا از Gemini Pro Vision استفاده شده است.
برای پردازش تصاویر:
- تصویر را به base64 تبدیل میکنیم
- همراه با یک prompt ثابت به Gemini Pro Vision میدهیم
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
import base64 import os from langchain_core.messages import HumanMessage def encode_image(image_path): “”“Getting the base64 string”“” with open(image_path, “rb”) as image_file: return base64.b64encode(image_file.read()).decode(“utf-8”) def image_summarize(img_base64, prompt): “”“Make image summary”“” model = ChatVertexAI(model_name=“gemini-pro-vision”, max_output_tokens=1024) msg = model( [ HumanMessage( content=[ {“type”: “text”, “text”: prompt}, { “type”: “image_url”, “image_url”: {“url”: f“data:image/jpeg;base64,{img_base64}”}, }, ] ) ] ) return msg.content def generate_img_summaries(path): “”“ Generate summaries and base64 encoded strings for images path: Path to list of .jpg files extracted by Unstructured ““” # Store base64 encoded images img_base64_list = [] # Store image summaries image_summaries = [] # Prompt prompt = “”“You are an assistant tasked with summarizing images for retrieval. \ These summaries will be embedded and used to retrieve the raw image. \ Give a concise summary of the image that is well optimized for retrieval.”“” # Apply to images for img_file in sorted(os.listdir(path)): if img_file.endswith(“.jpg”): img_path = os.path.join(path, img_file) base64_image = encode_image(img_path) img_base64_list.append(base64_image) image_summaries.append(image_summarize(base64_image, prompt)) return img_base64_list, image_summaries fpath = “./” # Image summaries img_base64_list, image_summaries = generate_img_summaries(fpath) |
بازیاب چندبرداری (Multi-Vector Retriever)
ایده این است که:
- خلاصههای متن/جدول/تصویر را در یک vector store ذخیره کنیم
- محتوای اصلی را در یک document store درونحافظهای نگه داریم
- سپس هنگام جستجو، اول خلاصههای نزدیک را پیدا کنیم و بعد اصل سند متناظر را برگردانیم
LangChain برای این کار MultiVectorRetriever را ارائه میدهد:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
import uuid from langchain.embeddings import VertexAIEmbeddings from langchain.retrievers.multi_vector import MultiVectorRetriever from langchain.schema.document import Document from langchain.storage import InMemoryStore from langchain.vectorstores import Chroma def create_multi_vector_retriever( vectorstore, text_summaries, texts, table_summaries, tables, image_summaries, images ): “”“ Create retriever that indexes summaries, but returns raw images or texts ““” # Initialize the storage layer store = InMemoryStore() id_key = “doc_id” # Create the multi-vector retriever retriever = MultiVectorRetriever( vectorstore=vectorstore, docstore=store, id_key=id_key, ) # Helper function to add documents to the vectorstore and docstore def add_documents(retriever, doc_summaries, doc_contents): doc_ids = [str(uuid.uuid4()) for _ in doc_contents] summary_docs = [ Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(doc_summaries) ] retriever.vectorstore.add_documents(summary_docs) retriever.docstore.mset(list(zip(doc_ids, doc_contents))) # Add texts, tables, and images if text_summaries: add_documents(retriever, text_summaries, texts) if table_summaries: add_documents(retriever, table_summaries, tables) if image_summaries: add_documents(retriever, image_summaries, images) return retriever # The vectorstore to use to index the summaries vectorstore = Chroma( collection_name=“mm_rag_mistral”, embedding_function=VertexAIEmbeddings(model_name=“textembedding-gecko@latest”), ) # Create retriever retriever_multi_vector_img = create_multi_vector_retriever( vectorstore, text_summaries, texts, table_summaries, tables, image_summaries, img_base64_list, ) |
در این کد:
- یک Chroma vector store برای خلاصهها داریم
- یک InMemoryStore برای محتوای اصلی
- و MultiVectorRetriever این دو را به هم متصل میکند
ساخت پایپلاین RAG با LangChain Expression Language
در مرحله نهایی، پایپلاین را با Expression Language میسازیم. این بخش شامل چند تابع کمکی است تا:
- متن و تصویر را از هم جدا کند
- اگر داده base64 تصویر باشد، آن را تشخیص دهد و resize کند
- یک prompt مناسب بسازد
- و سپس مدل vision پاسخ نهایی را تولید کند
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
import io import re from IPython.display import HTML, display from langchain.schema.runnable import RunnableLambda, RunnablePassthrough from PIL import Image def looks_like_base64(sb): “”“Check if the string looks like base64”“” return re.match(“^[A-Za-z0-9+/]+[=]{0,2}$”, sb) is not None def is_image_data(b64data): “”“ Check if the base64 data is an image by looking at the start of the data ““” image_signatures = { b“\xFF\xD8\xFF”: “jpg”, b“\x89\x50\x4E\x47\x0D\x0A\x1A\x0A”: “png”, b“\x47\x49\x46\x38”: “gif”, b“\x52\x49\x46\x46”: “webp”, } try: header = base64.b64decode(b64data)[:8] for sig, format in image_signatures.items(): if header.startswith(sig): return True return False except Exception: return False def resize_base64_image(base64_string, size=(128, 128)): “”“ Resize an image encoded as a Base64 string ““” img_data = base64.b64decode(base64_string) img = Image.open(io.BytesIO(img_data)) resized_img = img.resize(size, Image.LANCZOS) buffered = io.BytesIO() resized_img.save(buffered, format=img.format) return base64.b64encode(buffered.getvalue()).decode(“utf-8”) def split_image_text_types(docs): “”“ Split base64-encoded images and texts ““” b64_images = [] texts = [] for doc in docs: if isinstance(doc, Document): doc = doc.page_content if looks_like_base64(doc) and is_image_data(doc): doc = resize_base64_image(doc, size=(1300, 600)) b64_images.append(doc) else: texts.append(doc) if len(b64_images) > 0: return {“images”: b64_images[:1], “texts”: []} return {“images”: b64_images, “texts”: texts} def img_prompt_func(data_dict): “”“ Join the context into a single string ““” formatted_texts = “\n”.join(data_dict[“context”][“texts”]) messages = [] text_message = { “type”: “text”, “text”: ( “You are an AI scientist tasking with providing factual answers.\n” “You will be given a mixed of text, tables, and image(s) usually of charts or graphs.\n” “Use this information to provide answers related to the user question. \n” f“User-provided question: {data_dict[‘question’]}\n\n” “Text and / or tables:\n” f“{formatted_texts}” ), } messages.append(text_message) if data_dict[“context”][“images”]: for image in data_dict[“context”][“images”]: image_message = { “type”: “image_url”, “image_url”: {“url”: f“data:image/jpeg;base64,{image}”}, } messages.append(image_message) return [HumanMessage(content=messages)] def multi_modal_rag_chain(retriever): “”“ Multi-modal RAG chain ““” model = ChatVertexAI( temperature=0, model_name=“gemini-pro-vision”, max_output_tokens=1024 ) chain = ( { “context”: retriever | RunnableLambda(split_image_text_types), “question”: RunnablePassthrough(), } | RunnableLambda(img_prompt_func) | model | StrOutputParser() ) return chain chain_multimodal_rag = multi_modal_rag_chain(retriever_multi_vector_img) |
این زنجیره چند بخش دارد:
- یک دیکشنری شامل context و question
- یک زنجیره برای context که شامل retriever و تابع جداسازی متن/تصویر است
- تابعی که یک دستورالعمل برای grounded بودن پاسخ اضافه میکند
- مدل vision برای تولید پاسخ
- و در پایان parser برای خروجی متن
اجرای Retriever و RAG Chain
میتوانید ابتدا retriever را تست کنید تا مطمئن شوید اسناد درست بازیابی میشوند:
|
1 2 3 4 |
query = “”“compare and contrast between mistral and llama2 across benchmarks and explain the reasoning in detail”“” docs = retriever_multi_vector_img.get_relevant_documents(query, limit=1) docs[0] |
حالا خود زنجیره RAG را اجرا کنید:
|
1 |
chain_multimodal_rag.invoke(query) |
برای گرفتن پاسخ بهتر، معمولاً کافی است prompt را کمی تنظیم کنید؛ در بسیاری از موارد با تغییر کوچک در prompt، کیفیت جوابها به شکل محسوسی بهتر میشود.
چه زمانی LangChain برای Multimodal انتخاب درستی است؟
LangChain ابزار قدرتمندی است، اما استفاده از آن همیشه بهترین انتخاب نیست. در پروژههای multimodal، مهم است بدانیم کِی LangChain ارزش اضافه میکند و کِی فقط پیچیدگی میآورد. اگر این تصمیم درست گرفته نشود، سیستم بیشازحد مهندسیشده (over-engineered) میشود.
استفاده از LangChain برای multimodal AI انتخاب درستی است اگر:
- ورودیها فقط متن نیستند و با تصویر یا دادههای غیرمتنی سروکار دارید
- نیاز دارید چند مرحله پردازش (تحلیل تصویر، retrieval، پاسخدهی) را هماهنگ کنید
- قصد دارید سیستم را به RAG یا pipelineهای پیچیدهتر گسترش دهید
- نگهداری و توسعهپذیری کد برایتان مهم است
در مقابل، استفاده از LangChain ضروری نیست اگر:
- فقط یک درخواست ساده متن + تصویر دارید
- retrieval یا حافظه در کار نیست
- سیستم قرار نیست رشد کند یا قابلیت جدید بگیرد
- استفاده مستقیم از API مدلها نیازتان را برطرف میکند
بهطور خلاصه، LangChain زمانی بیشترین ارزش را ایجاد میکند که multimodality بههمراه جریانهای چندمرحلهای و دادهمحور وارد بازی شود.
جمعبندی
برنامههای چندرسانهای نشان میدهند که آینده هوش مصنوعی فقط در پردازش متن خلاصه نمیشود. دادههای واقعی معمولا ترکیبی از متن، تصویر و زمینه هستند و سیستمهایی که نتوانند این ترکیب را درک کنند، بهسرعت به محدودیت میخورند. Multimodal AI تلاشی است برای نزدیکتر کردن مدلها به این واقعیت و LangChain نقش مهمی در عملیکردن این رویکرد ایفا میکند.
LangChain با قرار گرفتن در نقش یک لایه orchestration، امکان مدیریت ورودیهای متنوع، اتصال مدلها و کنترل جریان پردازش را فراهم میکند؛ بدون اینکه توسعهدهنده مجبور شود منطق سیستم را بهصورت پراکنده و شکننده پیادهسازی کند. زمانی که multimodality با retrieval و دادههای خارجی ترکیب میشود، داشتن چنین لایهای دیگر یک انتخاب لوکس نیست، بلکه به یک نیاز عملی تبدیل میشود.
منابع
سوالات متداول
LangChain یک فریمورک برای مدیریت، اتصال و ارکستریشن مدلهای زبانی است که ساخت pipelineهای چندمرحلهای و چندوجهی (Multimodal) را ساده میکند.
بسته به نیاز پروژه میتوان از:
– مدلهای متنی (LLM)
– مدلهای Vision
– مدلهای Speech-to-Text
– مدلهای Text-to-Image
بله، اما:
– برای پروژههای ساده ممکن است بیشازحد پیچیده باشد
– بیشترین ارزش LangChain در پروژههای چندمرحلهای و مقیاسپذیر دیده میشود
– پروژههای بسیار ساده
– نیاز به latency بسیار پایین
– سناریوهایی که pipeline ثابت و بدون تصمیمگیری دارند




دیدگاهتان را بنویسید