
با رشد استفاده از مدلهای زبانی بزرگ (LLMها) و سیستمهای جستجوی معنایی، نیاز به دیتابیسهایی که بتوانند با دادههای برداری کار کنند بهطور جدی مطرح شده است. Weaviate یکی از شناختهشدهترین پایگاههای داده برداری متنباز است که دقیقا برای همین سناریوها طراحی شده و تلاش میکند فاصله بین دادههای غیرساختیافته و کاربردهای هوش مصنوعی را کمتر کند.
در این مقاله، ابتدا توضیح میدهیم Weaviate چیست و چگونه کار میکند، سپس مزیتهای اصلی آن نسبت به سایر دیتابیسهای برداری را بررسی میکنیم و در ادامه، مراحل نصب، تعریف داده و انجام جستجوی معنایی را مرور خواهیم کرد. در نهایت هم به نقش Weaviate در سناریوهای مبتنی بر LLM و RAG میپردازیم.
Weaviate چیست؟
Weaviate یک Vector Database متنباز است که برای ذخیره، جستجو و مدیریت دادههای برداری (embeddings) طراحی شده است. برخلاف دیتابیسهای سنتی که دادهها را بهصورت ردیف و ستون ذخیره میکنند و جستجو را بر اساس تطبیق دقیق انجام میدهند، Weaviate دادهها را به شکل بردارهای چندبعدی نگه میدارد و امکان جستجوی معنایی (Semantic Search) را فراهم میکند.

در Weaviate، هر داده (مثلا یک متن، مقاله، محصول یا سند) به یک embedding تبدیل میشود؛ این امبدینگ نماینده معنای داده در فضای برداری است. همین موضوع باعث میشود Weaviate بتواند دادههایی را پیدا کند که از نظر مفهومی شبیه هستند، حتی اگر از کلمات یکسانی استفاده نکرده باشند.
نکته مهم این است که Weaviate فقط یک «محل ذخیرهی embedding» نیست؛ بلکه یک سیستم کامل برای:
- مدیریت داده
- تولید embedding
- ایندکسگذاری
- و جستجوی ترکیبی (متنی + معنایی)
محسوب میشود.
معماری Weaviate چگونه است؟

معماری Weaviate بهصورت ماژولار طراحی شده و از چند بخش اصلی تشکیل میشود:
۱. Schema
Schema در Weaviate مشخص میکند:
- چه نوع دادههایی داریم (Classها)
- هر داده چه ویژگیهایی دارد (Properties)
- کدام ویژگیها باید vectorize شوند
این طراحی باعث میشود Weaviate برخلاف بسیاری از دیتابیسهای برداری، ساختارمند باشد و صرفا یک لیست از بردارها نباشد.
۲. Vector Index
Weaviate برای جستجوی سریع از الگوریتمهای Approximate Nearest Neighbor (ANN) استفاده میکند. این یعنی:
- جستجو بسیار سریع است
- حتی روی میلیونها یا میلیاردها بردار
- با کمی چشمپوشی از دقت مطلق، ولی کاملا کاربردی
۳. Vectorizer Modules
یکی از مهمترین تفاوتهای Weaviate این است که میتواند خودش embedding تولید کند.
ماژولهایی مثل:
به Weaviate اجازه میدهند متن خام را بگیرد و مستقیما به بردار تبدیل کند. این ویژگی، پیچیدگی pipeline را بهشدت کاهش میدهد.
راهاندازی و استفاده از Weaviate: راهنمای جامع با Python
شما میتوانید Weaviate را به دو شکل اجرا کنید:
یا روی زیرساخت خودتان (با استفاده از Docker، Kubernetes یا Embedded Weaviate) و یا بهصورت یک سرویس مدیریتشده از طریق Weaviate Cloud Services (WCS).
در این آموزش، از WCS استفاده میکنیم؛ چون سادهترین و پیشنهادشدهترین روش برای شروع کار با Weaviate است.
۱. راهاندازی Weaviate
در سایت Weaviate ثبتنام کنید.
روی دکمه Create cluster کلیک کنید.
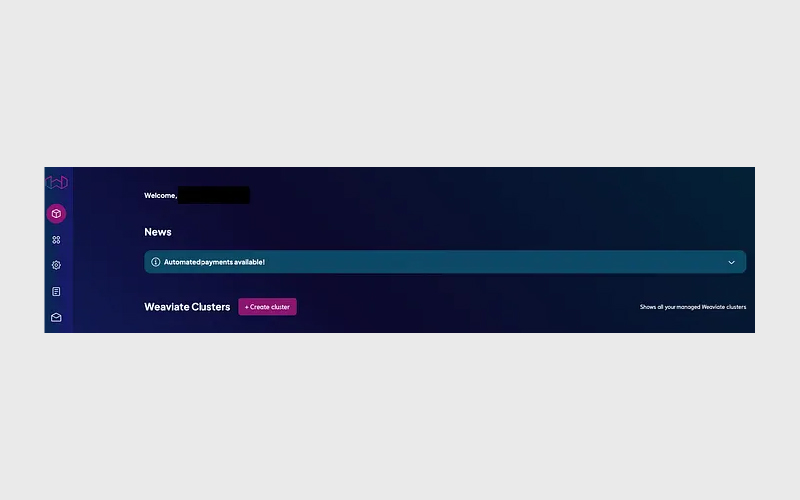
در تب Free sandbox:
- نام خوشه (cluster name) وارد کنید.
- احراز هویت (Authentication) را روی YES بگذارید.
- دکمه Create را بزنید.
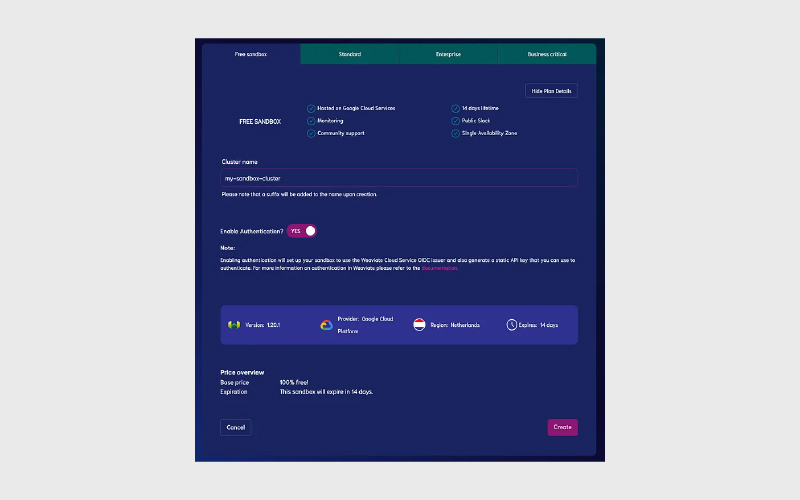
پس از ایجاد، دو اطلاعات مهم را یادداشت کنید:
Cluster URL (مثلا https://your-sandbox-name.weaviate.network)
Weaviate API Key
Docker Compose (محلی): فایل docker-compose.yml را از سایت Weaviate دانلود کنید و دستور docker compose up -d را اجرا کنید.
Embedded Weaviate مستقیما داخل برنامه Python اجرا میشود (مناسب توسعه محلی).
AWS Marketplace یا سایر ارائهدهندگان ابری.
۲. نصب کلاینت Python
|
1 |
pip install –U weaviate–client |
سپس کتابخانه را ایمپورت کنید:
|
1 |
import weaviate |
۳. اتصال به خوشه Weaviate
برای اتصال به کلاستر، به دو اطلاعات نیاز دارید:
- آدرس URL کلاستر
- کلید API مربوط به Weaviate (در بخش Authentication)
سپس میتوانید کلاینت Weaviate را به شکل زیر مقداردهی کنید:
|
1 2 3 4 5 6 7 8 9 |
auth_config = weaviate.AuthApiKey(api_key=“YOUR-WEAVIATE-API-KEY”) client = weaviate.Client( url=“https://<your-sandbox-name>.weaviate.network”, auth_client_secret=auth_config, additional_headers={ “X-OpenAI-Api-Key”: “YOUR-OPENAI-API-KEY”, } ) |
در اینجا از کلید OpenAI در بخش additional_headers استفاده شده تا بعدا بتوانیم از مدلهای embedding استفاده کنیم.
اگر از ارائهدهنده دیگری استفاده میکنید، میتوانید بهجای آن یکی از کلیدهای زیر را قرار دهید:
- X-Cohere-Api-Key
- X-HuggingFace-Api-Key
- X-Palm-Api-Key
برای اطمینان از صحت راهاندازی، دستور زیر را اجرا کنید:
|
1 |
client.is_ready() |
اگر خروجی True بود، همهچیز آماده است.
۴. ایجاد دیتابیس برداری
در مرحله بعد باید یک پایگاه داده برداری بسازید.
۵. ایجاد Schema (کلاس)
قبل از وارد کردن داده، باید ساختار داده را تعریف کنید. یک کلاس شامل:
- class: نام مجموعهی دادهها در فضای برداری
- properties: ویژگیهای هر آبجکت (معادل ستونها در DataFrame)
- vectorizer: مدلی که embedding تولید میکند
- moduleConfig: تنظیمات جزئی مربوط به ماژولها
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
class_obj = { “class”: “JeopardyQuestion”, “properties”: [ {“name”: “category”, “dataType”: [“text”]}, {“name”: “question”, “dataType”: [“text”]}, {“name”: “answer”, “dataType”: [“text”]}, ], “vectorizer”: “text2vec-openai”, “moduleConfig”: { “text2vec-openai”: { “vectorizeClassName”: False, “model”: “ada”, “modelVersion”: “002”, “type”: “text” }, }, } |
در این Schema:
- یک کلاس به نام JeopardyQuestion ساخته میشود
- سه ویژگی متنی دارد
- از مدل Ada v2 برای تولید embedding استفاده میشود
- نام کلاس در embedding لحاظ نمیشود
پس از تعریف Schema، آن را ایجاد میکنیم:
|
1 |
client.schema.create_class(class_obj) |
و برای بررسی:
|
1 |
client.schema.get(“JeopardyQuestion”) |
۶. وارد کردن داده (Import Data)
در این مرحله دیتابیس هنوز خالی است و باید دادهها را وارد کنیم. این فرایند «upserting» نام دارد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from weaviate.util import generate_uuid5 with client.batch(batch_size=200, num_workers=2) as batch: for _, row in df.iterrows(): question_object = { “category”: row.category, “question”: row.question, “answer”: row.answer, } batch.add_data_object( question_object, class_name=“JeopardyQuestion”, uuid=generate_uuid5(question_object) ) |
اگرچه Weaviate خودش UUID تولید میکند، اما اینجا برای جلوگیری از ورود دادهی تکراری، UUID را بهصورت دستی تولید کردهایم.
برای بررسی تعداد دادههای واردشده:
|
1 |
client.query.aggregate(“JeopardyQuestion”).with_meta_count().do() |
۷. کوئری و جستجو
رایجترین عملیات در دیتابیسهای برداری، بازیابی دادههاست.
برای این کار از متد get() استفاده میکنیم.
|
1 2 3 4 |
client.query.get( <Class>, [<properties>] ).<arguments>.do() |
مثال:
|
1 2 3 4 |
res = client.query.get( “JeopardyQuestion”, [“question”, “answer”, “category”] ).with_additional([“id”, “vector”]).with_limit(2).do() |
در اینجا:
- دادهها بر اساس شباهت معنایی برگردانده میشوند
- به همین دلیل استفاده از limit اهمیت زیادی دارد
۸. جستجوی برداری (Vector Search)
یکی از جذابترین قابلیتها، جستجوی مفهومی است.
مثلا پیدا کردن سوالاتی که به مفهوم «حیوانات» نزدیک هستند:
|
1 2 3 4 |
res = client.query.get( “JeopardyQuestion”, [“question”, “answer”, “category”] ).with_near_text({“concepts”: “animals”}).with_limit(2).do() |
در این حالت:
- متن «animals» به embedding تبدیل میشود
- نزدیکترین بردارها در دیتابیس پیدا میشوند
- نتایج میتوانند از دستهبندیهای کاملاً متفاوت باشند
۹. پرسشوپاسخ (Question Answering)
برای فعالسازی QA باید ماژول مربوطه را اضافه کنید:
|
1 2 3 |
“qna-openai”: { “model”: “text-davinci-002” } |
سپس با with_ask() سوال را مطرح کنید:
|
1 2 3 4 |
ask = { “question”: “Which animal was mentioned in the title of the Aesop fable?”, “properties”: [“answer”] } |
Weaviate سوال را روی دادهها اجرا کرده و پاسخ را استخراج میکند.
۱۰. جستجوی مولد (Generative Search)
با اضافهکردن مدلهای زبانی، میتوان خروجیها را تولید یا بازنویسی کرد.
به این قابلیت، Generative Search گفته میشود.
|
1 2 3 |
generative–openai“: { “model“: “gpt–3.5–turbo“ } |
و استفاده:
|
1 2 3 |
with_generate( single_prompt=“Generate a question to which the answer is {answer}” ) |
در این حالت:
- ابتدا جستجوی برداری انجام میشود
- سپس خروجی با کمک LLM بازتولید میشود
مثلا یک سوال جدید بر اساس پاسخ «octopus» ساخته میشود.
با این مراحل، یک پایگاه داده برداری کاملا عملی در Weaviate خواهید داشت که میتوانید دادههای متنی را به صورت برداری ذخیره کنید، جستجوی معنایی انجام دهید و با ترکیب مدلهای زبانی بزرگ (LLM) قابلیتهای پیشرفتهای مانند پاسخ به سوالات یا تولید محتوا اضافه کنید. برای پروژههای بزرگتر، حتما از batch import و تنظیمات بهینه vectorizer استفاده کنید. مستندات رسمی Weaviate منبع عالی برای جزئیات بیشتر است.
مزایای کلیدی Weaviate نسبت به Pinecone و Chroma

Weaviate با تمرکز بر انعطافپذیری، جستجوی هیبریدی (ترکیب جستجوی برداری با فیلترهای ساختیافته و keyword-based مانند BM25)، پشتیبانی از دادههای چندرسانهای (multi-modal) و ادغام مستقیم با مدلهای ML/LLM، خود را از رقبا متمایز میکند.
در مقابل، Pinecone بیشتر بر عملکرد بالا در مقیاس بزرگ، مدیریت کامل (serverless) و latency پایین تمرکز دارد (مناسب تولید enterprise)، و Chroma ساده و سبک است و برای پروتوتایپینگ سریع و توسعه محلی ایدئال، اما در مقیاس بزرگ ضعیفتر عمل میکند.
| ویژگی | Weaviate | Pinecone | Chroma |
| نوع و deployment | منبعباز، self-hosted یا managed cloud، hybrid options | کاملا managed/serverless (بدون self-host) | منبعباز، عمدتا محلی/in-memory، ساده برای Python |
| جستجو | Hybrid search (vector + keyword + filters)، GraphQL API | Vector search خالص، filtering قوی، latency پایین | Vector search ساده، مناسب پروتوتایپ |
| انعطافپذیری و ویژگیها | Built-in modules برای embedding/generative/QA، multi-modal، knowledge graph | عملکرد بالا در billion-scale، auto-scaling | آسانترین integration با LangChain، سریع برای شروع |
| مقیاسپذیری | خوب در self-hosted، تا صدها میلیون vector | عالی برای billion+ vectors، بدون مدیریت زیرساخت | محدود به small/medium، نه برای تولید بزرگ |
| هزینه | رایگان self-hosted، managed ارزانتر | گران در مقیاس بزرگ | رایگان/کمهزینه |
| بهترین استفاده | اپهای پیچیده RAG، hybrid search، on-premise | تولید enterprise با نیاز به reliability بالا | پروتوتایپ، یادگیری، اپهای کوچک |
ادغام Weaviate با مدلهای زبانی بزرگ
RAG روشی قدرتمند است که با ترکیب جستجوی برداری از پایگاه دادهای مانند Weaviate با مدلهای زبانی بزرگ (LLMها مانند OpenAI، Cohere، Google یا مدلهای محلی مانند Llama/Ollama)، دقت، بهروز بودن و قابلیت اعتماد پاسخها را افزایش میدهد.
Weaviate به طور native از RAG پشتیبانی میکند و ماژولهای آمادهای مانند text2vec-* (برای تولید embedding)، generative-openai/cohere/google (برای تولید متن شرطی) و ابزارهای پیشرفتهتری مانند Query Agent و Personalization Agent ارائه میدهد. این ادغام اجازه میدهد retrieval و generation در یک کوئری واحد انجام شود، که فرایند را ساده و کارآمد میکند.
سناریوهای کاربردی اصلی RAG با Weaviate
- جستجوی معنایی پایه (Naive RAG): جستجو برای مفاهیم مرتبط (مثل «حیوانات») و بازیابی نتایج نزدیک بدون نیاز به keyword دقیق؛ ایدئال برای چتباتهای ساده
- Question Answering پیشرفته: ترکیب context بازیابیشده با LLM برای پاسخ دقیق به سوالات پیچیده، مانند تحلیل اسناد پزشکی یا حقوقی با کاهش hallucination
- Generative Search: تولید متن جدید بر اساس نتایج، مثلا ساخت خلاصه، سوال جدید یا پاسخ شخصیسازیشده (با single/grouped prompt)
- Agentic RAG: استفاده از AI agentها برای استدلال چندمرحلهای، مسیریابی بین منابع متعدد (داخلی + web search)، validation نتایج و ابزارهای خارجی – مناسب اپهای پیچیده مانند دستیارهای تحقیقاتی، مدیریت incident یا personalization پویا (مانند توصیه محصولات در e-commerce)
- Local/Privacy-Focused RAG: اجرای کاملا محلی با Ollama و embeddingهای open-source (مانند all-minilm یا nomic-embed) برای دادههای حساس، بدون ارسال به cloud
- Multimodal RAG: پشتیبانی از تصاویر، ویدیو و صدا برای جستجوی any-to-any و تولید پاسخهای چندرسانهای (مانند visual QA)
- Hybrid RAG با Chunking پیشرفته: ترکیب vector search با فیلترهای metadata، BM25 و استراتژیهای chunking هوشمند برای دقت بالاتر در دادههای بزرگ (مانند پادکستها یا گزارشهای مالی)
- Production-Ready RAG: با ابزارهایی مانند Verba (اپ open-source RAG) یا Weaviate Agents برای query طبیعیزبانی، تولید خودکار متادیتا و scaling enterprise
Weaviate با فریمورکهایی مانند LangChain، LlamaIndex و DSPy ادغام عالی دارد و قابلیتهایی مانند hybrid search، multi-tenancy و generative feedback loops را برای بهبود مداوم ارائه میدهد.
محدودیتهای استفاده از Weaviate در RAG
- مصرف منابع: import دادههای بزرگ ممکن است حافظه زیادی مصرف کند (ریسک OOM)؛ نیاز به تنظیم batch size و compression.
- latency در مقیاس عظیم: معمولا بالاتر از Pinecone (۱۰۰-۲۰۰ms vs زیر ۵۰ms در billion-scale)، هرچند hybrid search دقت را جبران میکند.
- پیچیدگی اولیه: schema-based بودن و GraphQL ممکن است برای تازهکارها سختتر از Chroma باشد؛ self-hosted نیاز به دانش DevOps دارد.
- هزینه در cloud: برای حجم خیلی بالا گران میشود (هرچند self-hosted رایگان است).
- محدودیتهای فنی: وابستگی به ماژولهای خاص برای generative (نیاز به API key خارجی)، و گاهی نتایج غیرقابل پیشبینی در فیلترینگ post-retrieval.
- نیاز به بهینهسازی: عملکرد RAG به شدت به chunking، embedding model و prompt engineering وابسته است؛ بدون تنظیم، ممکن است hallucination باقی بماند.
جمعبندی
Weaviate بهعنوان یک پایگاه داده برداری منبعباز و انعطافپذیر، گزینهای عالی برای توسعهدهندگان و تیمهایی است که به جستجوی هیبریدی، ادغام عمیق با LLMها در سناریوهای RAG و کنترل کامل (self-hosted) نیاز دارند؛ بهویژه در اپهای پیچیده که نیاز به ترکیب دانش ساختیافته و معنایی دارند. اگر پروژهتان از پروتوتایپ به تولید میرود، Weaviate میتواند پایهای محکم برای سیستمهای AI هوشمند و scalable باشد.
منابع
سوالات متداول
خیر، Weaviate یک پایگاه داده برداری تخصصی است و جایگزین کامل پایگاههای داده رابطهای سنتی نمیشود. در مدیریت بردارها و جستجوی معنایی عالی عمل میکند اما معمولا در کنار پایگاههای داده موجود برای دادههای ساختیافته (مانند حسابهای کاربری یا اطلاعات صورتحساب) استفاده میشود.
قطعا. Weaviate طراحی مدولار دارد و به راحتی با مدلهای یادگیری ماشین مختلف و سرویسهای سومشخص مانند OpenAI، Cohere و Hugging Face ادغام میشود. این انعطافپذیری به شما اجازه میدهد مدلهای embedding دلخواه یا APIهای مورد نظرتان را متصل کنید.
Weaviate با لایسنس BSD-3-Clause عرضه میشود و میتواند به صورت on-premises (محلی) یا در سرویس ابری عمومی اجرا شود. Pinecone تحت لایسنس proprietary توزیع میشود و در cloud (و همچنین از طریق لینک به cloud خصوصی AWS) اجرا میشود. Pinecone از انواع گستردهای از دادهها پشتیبانی میکند، در حالی که Weaviate به دلیل منبعباز بودن لایسنسش، قابلیت سفارشیسازی بیشتری دارد.
بله، Weaviate به کاربران اجازه میدهد مدلهای پردازش زبان طبیعی خودشان را اجرا و مقیاسپذیر کنند، علاوه بر استفاده از مدلهایی که به صورت پیشفرض همراه نرمافزار ارائه شدهاند.


دیدگاهتان را بنویسید