
در سالهای اخیر، مدلهای زبانی بزرگ مانند ChatGPT توانستهاند نحوه تعامل انسان و ماشین را متحول کنند. با این حال، یکی از جنبههای فنی کمتر شناختهشده اما حیاتی در عملکرد این مدلها، حجم متن قابل پردازش است که هر مدل میتواند در یک جلسه پردازش کند. این محدودیت که با عنوان پنجره کانتکست شناخته میشود، تعیین میکند مدل تا چه اندازه از مکالمات، اسناد یا ورودیهای پیشین را میتواند به خاطر بسپارد و در پاسخگویی لحاظ کند.
در این مقاله بررسی میکنیم که پنجره کانتکست دقیقا چیست، چرا محدودیت تعداد توکنها اهمیت دارد، و مدلهای مختلف OpenAI (از GPT-3 تا GPT-4 و GPT-4 Turbo) چه تفاوتهایی در ظرفیت پردازش متن دارند. همچنین توضیح میدهیم چگونه این مدلها برای مدیریت ورودیهای طولانی، خلاصهسازی و فشردهسازی دادهها را بهکار میگیرند و چه راهکارهایی برای کار با متون حجیم وجود دارد تا دقت و کارایی مدل حفظ شود.
پنجره کانتکست چیست و چرا اهمیت دارد؟
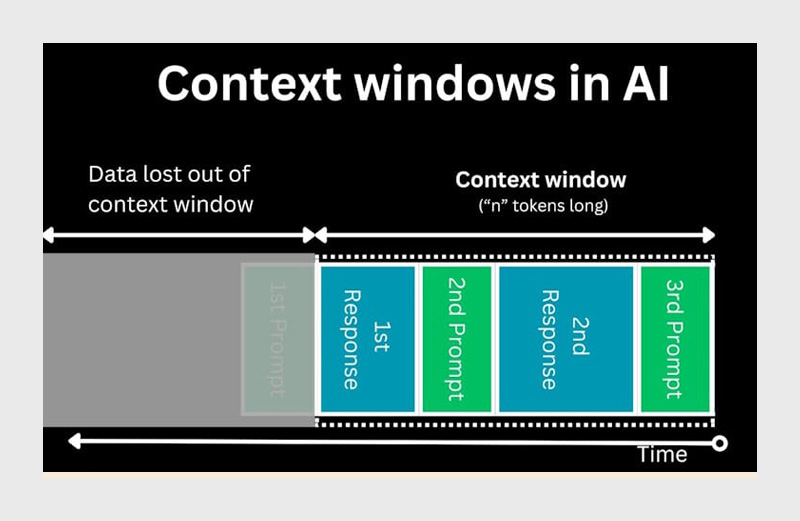
هر مدل زبانی بزرگ مانند ChatGPT، GPT-4 یا GPT-4 Turbo برای پردازش ورودیها از واحدی به نام توکن (Token) استفاده میکند. هر توکن معمولا معادل چند کاراکتر یا بخشی از یک کلمه است. در واقع، مدلها به جای خواندن کل متن بهصورت مستقیم، آن را به مجموعهای از توکنها تبدیل میکنند و سپس بر اساس الگوهای آماری میان آنها پیشبینی میکنند که پاسخ بعدی چه باید باشد.
اما این فرایند محدود است. مدلهای OpenAI تنها میتوانند تعداد مشخصی از توکنها را در هر تعامل پردازش کنند؛ به این محدوده اصطلاحا پنجره کانتکست (Context Window) گفته میشود. این یعنی مدل فقط قادر است بخشی از مکالمه یا متن را «به خاطر بسپارد» و در تحلیل خود در نظر بگیرد. هرچه ورودی طولانیتر شود، بخشهای قدیمیتر گفتگو از حافظه موقت مدل حذف یا خلاصه میشوند تا جا برای اطلاعات جدید باز شود.
بهعنوان مثال، اگر پنجره کانتکست یک مدل 128k توکن باشد، کل ورودی (متن کاربر بهعلاوه پاسخهای تولیدشده) نمیتواند از این مقدار بیشتر شود. در غیر این صورت مدل ناچار است محتوای قدیمیتر را فشرده کند یا کنار بگذارد. به همین دلیل، هرچند مدلها در ظاهر «به مکالمات قبلی آگاه» به نظر میرسند، در واقع حافظهای دائمی ندارند و صرفا با مدیریت هوشمند همین محدودهی کانتکست کار میکنند.
این محدودیت تاثیر مستقیم بر دقت پاسخها دارد. وقتی گفتگو بسیار طولانی یا چندمرحلهای شود، مدل ممکن است جزئیات اولیه را از دست بدهد یا برداشتهای نادرستی از زمینه گفتگو داشته باشد. برای همین است که OpenAI در نسخههای جدیدتر خود، مانند GPT-4 Turbo، تلاش کرده ظرفیت پردازش را تا چند صد هزار توکن افزایش دهد تا مدلها بتوانند متون بلند، کدهای حجیم یا چندین سند همزمان را بدون افت دقت تحلیل کنند.
مقایسه ظرفیت مدلهای مختلف از نظر پنجره زمینه
در این بخش، عددها و مدلهای مختلف را مرور میکنیم تا درک کنیم چقدر متن (یا گفتوگو) میتوانند مدلهای مختلف OpenAI پردازش کنند، و این ظرفیت چه معنایی برای کاربردهای واقعی دارد.
| نام مدل | ظرفیت پنجره کانتکست (تعداد توکن) | معادل تقریبی کلمات | توضیح کاربردی |
| GPT-3.5 Turbo | ۱۶۰۰۰ توکن | حدود ۱۲۰۰۰ کلمه | مناسب برای گفتوگوهای چندمرحلهای یا تحلیل اسناد کوتاه (مثلاً گزارش یا مقالهی فنی) |
| GPT-4 (نسخه پایه) | ۸۰۰۰ توکن | حدود ۶۰۰۰ کلمه | کافی برای تحلیل متون متوسط، کدهای کوتاه و وظایف تعاملی ساده |
| GPT-4 (نسخه پیشرفته) | ۳۲۰۰۰ توکن | حدود ۲۴۰۰۰ کلمه | کاربردی برای تحلیل چندین سند همزمان یا خلاصهسازی متون بلند |
| GPT-4 Turbo | ۱۲۸۰۰۰ توکن | حدود ۹۶۰۰۰کلمه | مناسب برای پردازش گزارشهای طولانی، کتابها، یا مجموعهکدهای بزرگ |
| GPT-4.1 (نسخه جدید) | ۱۰۰۰۰۰۰ توکن | حدود ۷۵۰۰۰۰ کلمه | قادر به تحلیل مجموعهای از اسناد، کتابخانههای کد و دادههای سازمانی گسترده |
💡 یادآوری: هر ۱,۰۰۰ توکن تقریبا معادل ۷۵۰ کلمه انگلیسی است، ولی در زبانهایی مانند فارسی ممکن است این عدد اندکی کمتر باشد (حدود ۶۰۰ تا ۷۰۰ کلمه) به دلیل ساختار واژگانی و فاصلهگذاری متفاوت. این یعنی مدلی که پنجرهاش ۱۲۸k توکن است، میتواند تقریبا معادل چندین ده صفحه یا حتی یک کتاب کوچک را در یک درخواست در نظر بگیرد؛ البته با فرض اینکه کل ورودی و خروجی با هم در آن پنجره باشند.

هنگام عبور از ظرفیت پنجره کانتکست چه کنیم؟
مدلها نمیتوانند تمام توکنهای ورودی را حفظ کنند. برای مدیریت این موضوع، از دو روش اصلی استفاده میشود:
- خلاصهسازی خودکار: مدل بخشهای قدیمیتر مکالمه یا متن را به صورت فشرده ذخیره میکند.
- حذف چرخشهای قدیمیتر: در صورت نیاز، اطلاعات کمتر مرتبط یا جزئیات قدیمیتر حذف میشوند تا جا برای دادههای جدید باز شود.
تاثیر هزینه و تاخیر در پنجرههای بزرگتر:
- افزایش پنجره کانتکست باعث افزایش مصرف منابع محاسباتی و زمان پردازش (latency) میشود.
- بنابراین، همیشه یک تعادل بین حجم متن و سرعت پاسخدهی لازم است.
مدلهای OpenAI چگونه متنهای طولانی را خلاصه و فشرده میکنند؟
وقتی حجم متن یا گفتوگو از ظرفیت پنجره کانتکست یک مدل بیشتر شود، مدل نمیتواند تمام ورودی را مستقیما پردازش کند. در چنین شرایطی، OpenAI از مکانیزمی استفاده میکند که ترکیبی از خلاصهسازی پویا (Dynamic Summarization) و فشردهسازی زمینه (Context Compression) است.
به بیان ساده، مدل با نزدیک شدن به محدودیت توکنها، شروع به خلاصهسازی بخشهای قدیمیتر مکالمه میکند. بهجای نگه داشتن تمام جزئیات، آنها را در قالب جملات کوتاهتر یا توصیفهای فشردهتر بازنویسی میکند تا فضای بیشتری برای اطلاعات جدید باقی بماند. برای مثال، اگر در ابتدای گفتوگو چند مرحله توضیح در مورد یک پروژه داده باشید، مدل آن را در ذهن خود بهصورت «کاربر درباره پروژهای در حوزه هوش مصنوعی صحبت کرد» ذخیره میکند، نه تمام جزئیات دقیق کلمات شما.
این روند شبیه به نوعی حافظهی کوتاهمدت است که دائما بازنویسی میشود. در نتیجه، هرچه گفتوگو طولانیتر شود، دقت مدل در به خاطر آوردن جزئیات کاهش مییابد. این مسئله همان دلیلی است که گاهی کاربران احساس میکنند ChatGPT در اواسط یک گفتوگوی طولانی «موضوع را فراموش میکند» در واقع مدل اطلاعات را از دست نمیدهد، بلکه آنها را خلاصه کرده تا ظرفیتش تمام نشود.
مدلهای جدیدتر مانند GPT-4 Turbo و GPT-4.1 با استفاده از الگوریتمهای پیشرفتهتر فشردهسازی، قادرند حجم بسیار بیشتری از اطلاعات را بدون افت محسوس در دقت نگه دارند. بهعبارت دیگر، این مدلها نهفقط توکنهای بیشتری میپذیرند، بلکه در نحوه مدیریت و اولویتبندی اطلاعات نیز هوشمندتر عمل میکنند. مثلا GPT-4 Turbo میتواند در تحلیل گفتوگوهای ۱۰۰صفحهای، جزئیات مهم را تشخیص دهد و موارد غیرضروری را فشرده کند تا ارتباط منطقی متن حفظ شود.
این فرایند، پایهی مفهومی چیزی است که کاربران آن را بهاشتباه «حافظهی ChatGPT» مینامند. در حقیقت ChatGPT در سطح مدل هیچ حافظه دائمیای ندارد؛ تنها از فشردهسازی دادهها درون همان جلسه استفاده میکند. قابلیت حافظهی بلندمدت (Memory) در محصولات جدیدتر OpenAI مثل ChatGPT Plus یا Team، در سطح اپلیکیشن و زیرساخت ذخیره میشود، نه در خود مدل زبانی.
کاربردهای عملی و راهکارها برای مدیریت حجم متن در مدلهای OpenAI
کاربردهای عملی و راهکارهای مدیریت ورودیهای طولانی بر اساس بهینهسازی پرامپت، تقسیمبندی محتوا و خلاصهسازی تدریجی شکل گرفتهاند. این روشها کمک میکنند مدل بتواند حجم بیشتری از متن یا داده را بدون افت دقت تحلیل کند و همزمان هزینه و زمان پردازش کنترل شود.
۱. بودجهبندی توکن
محدود کردن تعداد توکنهای ورودی و خروجی در هر تعامل.
- چرا مهم است؟ جلوگیری از پر شدن پنجره کانتکست و اطمینان از اینکه مدل قادر به پردازش اطلاعات کلیدی است.
- نکته عملی: برای یک ورودی طولانی، تعیین کنید چه تعداد توکن برای پاسخ مدل مجاز است (مثلا max_output_tokens = 2000) تا بخشهای حیاتی ورودی حذف نشوند.
۲. تقسیم وظایف و بخشبندی متن (Chunking)
متن یا کد طولانی را به بخشهای منطقی کوچکتر تقسیم کنید و هر بخش را جداگانه تحلیل کنید.
- مزایا:
- کاهش خطای فراموشی جزئیات توسط مدل
- افزایش سرعت پردازش
- امکان مدیریت بهتر توکنها
- نکته عملی: هر بخش را طوری طراحی کنید که مفهوم کامل داشته باشد، سپس خلاصه هر بخش را به بخش بعدی اضافه کنید تا مدل همچنان بتواند زمینه کلی را درک کند.
۳. خلاصههای میانی (Intermediate Summaries)
بعد از پردازش هر بخش، یک خلاصه کوتاه از اطلاعات مهم تولید شود.
- مزایا:
- کاهش حجم اطلاعات برای بخشهای بعدی
- حفظ نکات کلیدی بدون نیاز به پردازش مجدد کل متن
- مثال عملی: اگر یک کتاب ۲۰۰ صفحهای را تحلیل میکنید، هر ۱۰ صفحه را پردازش و خلاصه کنید، سپس خلاصهها را ترکیب کرده و تحلیل نهایی را ایجاد کنید.
۴. استفاده از دستورهای زمینهساز (Contextual Prompts)
قبل از تحلیل هر بخش جدید، خلاصهای کوتاه از بخشهای قبلی به مدل داده شود تا حافظه مصنوعی ایجاد شود.
- مثال عملی: «تا اینجا گفتیم پروژه درباره مدلهای OpenAI است و محدودیت توکنها چگونه بر دقت پاسخ تأثیر میگذارد. حالا بخش دوم متن را تحلیل کن.»
۵. مثالهای کاربردی واقعی
- تحلیل PDF بزرگ:
- PDFهای طولانی را بخشبندی کرده و هر بخش را جداگانه به مدل بدهید.
- خلاصههای میانی بسازید و در نهایت، خلاصهها را ترکیب کنید تا تصویری کامل از کل محتوا داشته باشید.
- تحلیل کدبیس بزرگ:
- کدها را ماژول به ماژول پردازش کنید.
- برای پروژههای چند ماژولی، هر ماژول را جداگانه خلاصه کنید و سپس تحلیل نهایی کل پروژه را تولید کنید.
۶. مدیریت هزینه و کارایی
پنجرههای بزرگتر نیاز به منابع محاسباتی بیشتر و زمان پردازش طولانیتر دارند.
- راهکار:
- توکنهای ورودی و خروجی را محدود کنید.
- ابتدا بخشهای مهم را پردازش کنید و بخشهای کماهمیت را خلاصه یا کنار بگذارید.
- از مدلهای سبکتر برای پردازش بخشهای کوتاه و از مدلهای پرظرفیت برای تحلیلهای کلان استفاده کنید.
۷. ترکیب با روشهای پیشرفته (برای حجم بسیار بزرگ)
- retrieval-based embedding + search:
- اطلاعات بسیار حجیم را ابتدا در یک پایگاه داده ذخیره و ایندکس کنید.
- سپس به مدل تنها بخشهای مرتبط را بدهید.
- مزیت: عبور از محدودیت پنجره کانتکست بدون از دست رفتن دادههای مهم.
بهینهسازی پرامپتها برای متنهای بلند — چگونه دقت مدل را حفظ کنیم؟

وقتی با مدلهایی مثل ChatGPT یا GPT-4 کار میکنیم، هرچه حجم ورودی بیشتر شود، خطر از دست رفتن دقت پاسخها هم افزایش پیدا میکند. دلیل این مسئله همان محدودیت پنجره کانتکست است؛ مدل باید تصمیم بگیرد کدام بخشها را در حافظه موقت نگه دارد و کدام قسمتها را کنار بگذارد. بنابراین، نحوهی نوشتن پرامپتها اهمیت حیاتی پیدا میکند.
۱. تقسیم متن به بخشهای کوچک (Chunking)
محتوا را به بخشهای کوتاه تقسیم کنید و هر بخش را جداگانه تحلیل یا خلاصه کنید. سپس نتایج هر مرحله را در یک پرامپت نهایی ترکیب کنید. این روش کمک میکند مدل تمرکز خود را از دست ندهد و خطاهای مرتبط با فراموشی جزئیات کاهش یابد.
۲. استفاده از دستورهای زمینهساز (Contextual Prompts)
پیش از هر مرحله، خلاصهای کوتاه از آنچه تاکنون گفته شده به مدل ارائه شود. این کار به نوعی حافظه مصنوعی ایجاد میکند و کمک میکند مسیر منطقی تحلیل حفظ شود.
مثال:
«تا اینجا گفتیم که پروژه درباره مدلهای OpenAI است و محدودیت توکنها چگونه بر دقت پاسخ تاثیر میگذارد. حالا این بخش را خلاصه کن.»
۳. خلاصهسازی تدریجی (Progressive Summarization)
مدل در هر مرحله یک خلاصه سطح بالاتر تولید میکند که در نهایت تصویری فشرده اما دقیق از کل محتوا ارائه دهد. این روش بهویژه برای مدلهایی با حافظه محدود موثر است.
۴. انتخاب مدل مناسب
حتی با مدلهای قدرتمند مانند GPT-4 Turbo یا GPT-4.1، اگر ورودیها بهدرستی سازماندهی نشوند، احتمال از بین رفتن ارتباط منطقی میان بخشها وجود دارد. کیفیت پرامپت و نحوهی مدیریت ورودیها از صرفا افزایش ظرفیت مدل مهمتر است.
نکات عملی برای توسعهدهندگان
این بخش نکات عملی برای توسعهدهندگان بهطور ویژه به تیمها و افراد فعال در حوزه فناوری کمک میکند تا با محدودیتهای پنجره کانتکست و حجم متن قابل پردازش در مدلهای OpenAI به شکل موثر کار کنند.
- انتخاب مدل مناسب بر اساس حجم سند:
- اگر سند بالای ۱۰k توکن است، از GPT-4 Turbo یا GPT-4.1 استفاده کنید.
- برای متنهای کوتاه، مدلهای سبکتر کافی هستند.
- تقسیم و خلاصهسازی هوشمند:
- متن یا کدهای طولانی را به بخشهای منطقی تقسیم کنید.
- خلاصههای میانی تولید کرده و در پرامپت بعدی استفاده کنید.
- استفاده از ابزارهای پیشرفته برای حجم بسیار بزرگ:
- ترکیب مدلهای زبانی با retrieval-based embedding و جستجوی هوشمند میتواند دادههای بسیار حجیم را مدیریت کند.
- این روش به مدل کمک میکند فقط اطلاعات مرتبط را پردازش کند و از محدودیت پنجره کانتکست عبور نکند.
- مدیریت هزینه و منابع:
- در مدلهای بزرگ، پردازش طولانی یا حجم بالا ممکن است هزینه و زمان زیادی داشته باشد.
- همیشه max_output_tokens و اندازه بخشها را بهینه کنید تا منابع هدر نروند.
جمعبندی
مدیریت حجم متن برای حفظ دقت، بهینهسازی عملکرد و کنترل هزینهها ضروری است. هرچند مدلها با افزایش ظرفیت پنجره کانتکست، مانند GPT-4.1 که تا ۱ میلیون توکن را پشتیبانی میکند، قادر به تحلیل متون بسیار بلند هستند اما طراحی هوشمند پرامپت و تقسیمبندی محتوا همچنان حیاتی است. با پیشرفت مدلها، پنجرهها بزرگتر خواهند شد، اما مهارت در طراحی سیستمها و مدیریت ورودیها همچنان کلید موفقیت خواهد بود.
منابع
سوالات متداول
مدلها برای مدیریت این شرایط از خلاصهسازی خودکار و حذف چرخشهای قدیمیتر استفاده میکنند. به این ترتیب جزئیات کمتر مهم یا بخشهای قدیمیتر فشرده یا حذف میشوند تا جا برای دادههای جدید باز شود.
راهکارهایی مانند تقسیم متن به بخشهای کوچک (Chunking)، خلاصهسازی تدریجی (Progressive Summarization)، و استفاده از دستورهای زمینهساز (Contextual Prompts) کمک میکنند بدون از دست رفتن اطلاعات مهم، ورودیهای طولانی را مدیریت کرد.
GPT-3.5 Turbo: حدود ۱۶,۰۰۰ توکن
GPT-4 پایه: حدود ۸,۰۰۰ تا ۳۲,۰۰۰ توکن
GPT-4 Turbo: حدود ۱۲۸,۰۰۰ توکن
GPT-4.1: حدود ۱,۰۰۰,۰۰۰ توکن

دیدگاهتان را بنویسید