
در بسیاری از پروژههای هوش مصنوعی و سیستمهای توصیهگر، نیاز به جستجوی سریع و دقیق در میان میلیونها بردار داده، یک چالش بزرگ است. Qdrant بهعنوان یک پایگاه داده برداری مبتنی بر Rust، این چالش را با ترکیبی از سرعت بالا و قابلیت فیلترگذاری هوشمند روی متادیتا حل میکند. این ویژگیها Qdrant را از سایر پایگاههای برداری متمایز کرده و امکان توسعه سیستمهای جستجوی شبههوشمند و هوش مصنوعی مقیاسپذیر را فراهم میکند.
در این مقاله، به بررسی قابلیتها و معماری Qdrant، نحوه مدیریت دادههای برداری و مزایای آن نسبت به سایر پایگاههای برداری پرداخته میشود. همچنین نمونههایی از کاربردهای عملی و بهترین روشهای استفاده از آن در پروژههای واقعی ارائه خواهد شد تا خواننده درک کاملی از این ابزار پیشرفته پیدا کند.
Qdrant چیست؟
Qdrant یک پایگاه داده برداری است که برای جستجوی سریع و دقیق دادههای پیچیده طراحی شده است. این دادهها میتوانند شامل متن، تصویر یا ویژگیهای استخراجشده از مدلهای هوش مصنوعی باشند و با تبدیل آنها به بردار، امکان مقایسه و پیدا کردن مشابهترین دادهها فراهم میشود. علاوه بر ذخیره بردارها، Qdrant اجازه میدهد اطلاعات تکمیلی مرتبط با هر بردار که به آنها Payload گفته میشود را نگهداری کنید. این اطلاعات به شما کمک میکنند جستجوها دقیقتر شوند و دادههای مفیدی برای کاربران ارائه دهید.
با استفاده از Qdrant، توسعهدهندگان میتوانند سیستمهای جستجو، توصیهگر و برنامههای هوشمند بسازند که سریع، مقیاسپذیر و قابل اعتماد باشند. این پایگاه داده با زبان Rust نوشته شده و از الگوریتمهای پیشرفته برای ایندکسگذاری بردارها استفاده میکند تا حتی با حجم بالای داده، عملکرد ثابتی داشته باشد.
معماری Qdrant به زبان ساده
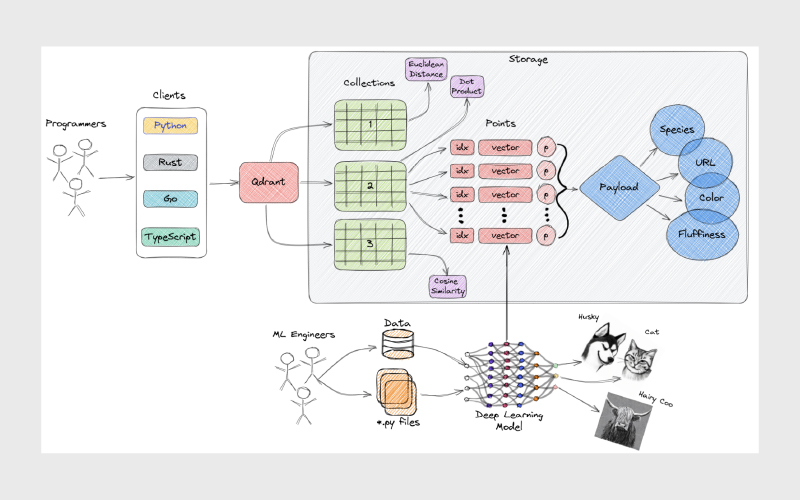
Qdrant برای جستجوی سریع و دقیق میان بردارها طراحی شده است. در مرکز معماری آن، نقاط (Points) قرار دارند؛ هر نقطه شامل یک بردار (Vector) است که میتواند نمایش چندبعدی یک تصویر، متن، صدا یا ویدئو باشد. علاوه بر بردار، هر نقطه میتواند یک شناسه یکتا (id) و Payload داشته باشد؛ Payload شامل اطلاعات تکمیلی است که دقت جستجو را افزایش میدهد و دادههای مفیدی برای کاربران فراهم میکند.
بردارها در مجموعهها (Collections) سازماندهی میشوند. هر مجموعه گروهی از بردارها با ابعاد یکسان است که با یک معیار فاصله (Distance Metric) مشخص قابل مقایسه هستند. معیار فاصله بسته به نوع دادهها و شبکه عصبی که بردارها را تولید کرده است انتخاب میشود و به دقت جستجوی شباهت کمک میکند. Qdrant همچنین امکان استفاده از چند بردار در یک نقطه را فراهم میکند، هرکدام با ابعاد و معیارهای خود، که انعطافپذیری بیشتری به سیستم میدهد.
برای ذخیرهسازی، Qdrant دو روش دارد:
۱. حافظه RAM (In-memory): تمام بردارها در حافظه اصلی نگهداری میشوند و سریعترین روش است.
۲. Memmap: فضایی مجازی ایجاد میشود که به فایل روی دیسک متصل است و دسترسی به دادهها با سرعت مناسبی انجام میشود.
Qdrant با زبان Rust توسعه یافته و از الگوریتم HSNW برای ایندکسگذاری بردارها استفاده میکند تا جستجوی نزدیکترین همسایهها سریع و دقیق باشد. همچنین، با ارائه APIهای متعدد برای Python، TypeScript/JavaScript، Rust و Go، امکان اتصال و استفاده از پایگاه داده در پروژههای مختلف بسیار آسان است.
به زبان ساده، معماری Qdrant ترکیبی از سازماندهی هوشمند بردارها، جستجوی سریع و دقیق، مدیریت اطلاعات تکمیلی (Payload) و انعطافپذیری در ذخیرهسازی است که آن را برای پروژههای هوش مصنوعی و سیستمهای توصیهگر بسیار مناسب میکند.
راهاندازی Qdrant
برای اجرای Qdrant چند حالت مختلف وجود دارد و بسته به حالت انتخابی، تفاوتهای جزئی دیده میشود:
- حالت محلی (Local mode): بدون نیاز به سرور
- استفاده از Docker
- Qdrant Cloud
برای نصب میتوانید از دستور زیر استفاده کنید:
|
1 |
pip install –qU langchain–qdrant |
۱. اطلاعات ورود (Credentials)
اگر میخواهید ردیابی خودکار تماسهای مدل به بهترین شکل انجام شود، میتوانید کلید API LangSmith خود را وارد کنید:
|
1 2 3 |
import os, getpass os.environ[“LANGSMITH_API_KEY”] = getpass.getpass(“کلید API LangSmith خود را وارد کنید: “) os.environ[“LANGSMITH_TRACING”] = “true” |
۲. مقداردهی اولیه (Initialization)
کلاینت پایتون امکان اجرای Qdrant بهصورت محلی و بدون نیاز به سرور را فراهم میکند. این روش برای تست، اشکالزدایی و ذخیره مقدار کمی از بردارها مناسب است. بردارها میتوانند کاملا در حافظه RAM نگهداری شوند یا روی دیسک ذخیره شوند.
حافظه RAM:
در سناریوهای تست یا آزمایشهای سریع، میتوان دادهها را فقط در حافظه نگه داشت تا پس از پایان اسکریپت پاک شوند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from langchain_openai import OpenAIEmbeddings from langchain_qdrant import QdrantVectorStore from qdrant_client import QdrantClient from qdrant_client.http.models import Distance, VectorParams embeddings = OpenAIEmbeddings(model=“text-embedding-3-large”) client = QdrantClient(“:memory:”) client.create_collection( collection_name=“demo_collection”, vectors_config=VectorParams(size=3072, distance=Distance.COSINE), ) vector_store = QdrantVectorStore( client=client, collection_name=“demo_collection”, embedding=embeddings, ) |
ذخیره روی دیسک:
در حالت محلی بدون سرور Qdrant، میتوان بردارها را روی دیسک ذخیره کرد تا بین اجراها حفظ شوند.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
client = QdrantClient(path=“/tmp/langchain_qdrant”) client.create_collection( collection_name=“demo_collection”, vectors_config=VectorParams(size=3072, distance=Distance.COSINE), ) vector_store = QdrantVectorStore( client=client, collection_name=“demo_collection”, embedding=embeddings, ) |
۳. استقرار روی سرور داخلی (On-premise)
چه بخواهید Qdrant را با Docker یا با Kubernetes و Helm chart رسمی راهاندازی کنید، اتصال به آن مشابه است. تنها کافی است URL سرویس را ارائه دهید:
|
1 2 3 4 5 6 7 8 9 |
url = “<—qdrant url here —>” docs = [] # اسناد خود را اینجا قرار دهید qdrant = QdrantVectorStore.from_documents( docs, embeddings, url=url, prefer_grpc=True, collection_name=“my_documents”, ) |
۴. Qdrant Cloud
اگر نمیخواهید مدیریت زیرساخت را خودتان انجام دهید، میتوانید یک خوشه کاملا مدیریتشده روی Qdrant Cloud راهاندازی کنید. یک خوشه رایگان 1GB برای آزمایش در دسترس است.
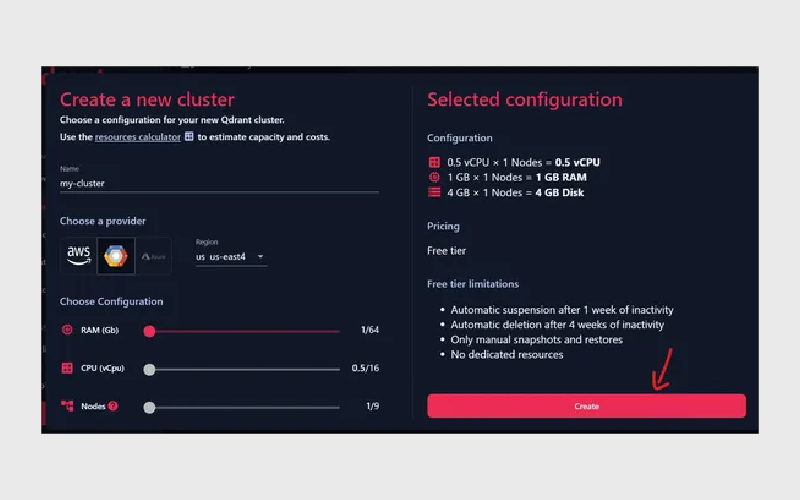
تفاوت اصلی با نسخه مدیریتشده این است که برای امنیت خوشه باید API Key ارائه دهید. میتوانید مقدار آن را در متغیر محیطی QDRANT_API_KEY نیز قرار دهید:
|
1 2 3 4 5 6 7 8 9 10 |
url = “<—qdrant cloud cluster url here —>” api_key = “<—api key here—>” qdrant = QdrantVectorStore.from_documents( docs, embeddings, url=url, prefer_grpc=True, api_key=api_key, collection_name=“my_documents”, ) |
۵. استفاده از Collection موجود
اگر میخواهید بدون بارگذاری مجدد اسناد، به Collection موجود دسترسی داشته باشید:
|
1 2 3 4 5 |
qdrant = QdrantVectorStore.from_existing_collection( embedding=embeddings, collection_name=“my_documents”, url=“http://localhost:6333”, ) |
۶. مدیریت Vector Store
پس از ایجاد Vector Store، میتوانید اسناد را اضافه، حذف یا جستجو کنید:
افزودن سند:
|
1 2 3 4 5 6 7 8 9 10 11 |
from uuid import uuid4 from langchain_core.documents import Document document_1 = Document( page_content=“I had chocolate chip pancakes and scrambled eggs for breakfast this morning.”, metadata={“source”: “tweet”}, ) # اضافه کردن سایر اسناد… documents = [document_1, ...] uuids = [str(uuid4()) for _ in range(len(documents))] vector_store.add_documents(documents=documents, ids=uuids) |
حذف سند:
|
1 |
vector_store.delete(ids=[uuids[–1]]) |
جستجو مستقیم:
|
1 2 3 4 5 |
results = vector_store.similarity_search( “LangChain provides abstractions to make working with LLMs easy”, k=2 ) for res in results: print(f“* {res.page_content} [{res.metadata}]”) |
۷. حالتهای جستجو
QdrantVectorStore سه حالت برای جستجوی شباهت برداری ارائه میدهد:
- Dense Vector Search (پیشفرض)
- Sparse Vector Search
- Hybrid Search
میتوانید با پارامتر retrieval_mode آنها را تنظیم کنید.
کاربردهای پایگاه برداری Qdrant
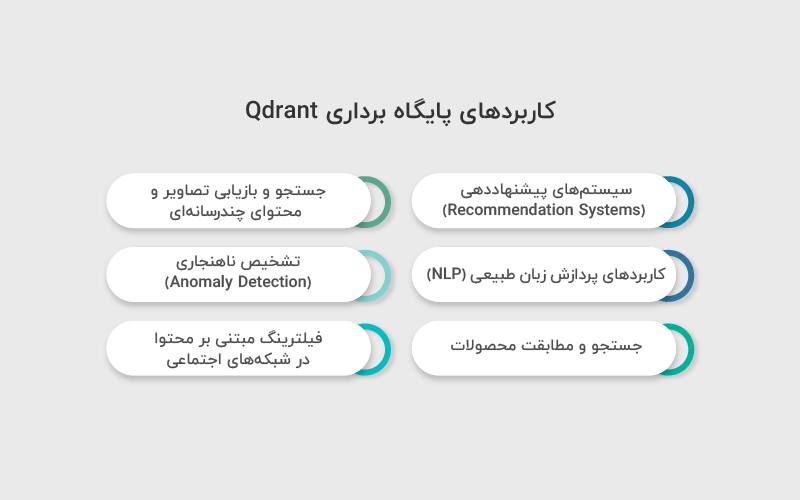
پایگاه داده برداری Qdrant میتواند در زمینههای مختلف کاربرد داشته باشد:
سیستمهای پیشنهاددهی (Recommendation Systems):
Qdrantبا مقایسه و تطبیق دقیق بردارهای چندبعدی میتواند موتورهای پیشنهاددهی را تقویت کند. این ویژگی برای ارائه محتواهای شخصیسازیشده در پلتفرمهایی مانند سرویسهای استریم، فروشگاههای اینترنتی یا شبکههای اجتماعی بسیار مناسب است.
جستجو و بازیابی تصاویر و محتوای چندرسانهای:
با استفاده از توانایی Qdrant در مدیریت بردارهایی که تصاویر و محتوای چندرسانهای را نشان میدهند، میتوان عملکرد جستجو و بازیابی در پایگاههای داده تصاویر یا آرشیوهای چندرسانهای را پیادهسازی کرد.
کاربردهای پردازش زبان طبیعی (NLP):
پشتیبانی Qdrant از Embeddings، آن را برای وظایف NLP ارزشمند میکند؛ مانند جستجوی معنایی، یافتن شباهت بین اسناد و پیشنهاد محتوا در برنامههایی که با حجم بالایی از دادههای متنی سروکار دارند.
تشخیص ناهنجاری (Anomaly Detection):
جستجوی برداری با ابعاد بالا در Qdrant میتواند در سیستمهای تشخیص ناهنجاری کاربرد داشته باشد. با مقایسه بردارهایی که رفتار عادی را نشان میدهند با دادههای ورودی، ناهنجاریها در حوزههایی مانند امنیت شبکه یا پایش صنعتی شناسایی میشوند.
جستجو و مطابقت محصولات:
در پلتفرمهای تجارت الکترونیک، Qdrant میتواند قابلیت جستجوی محصولات را بهبود بخشد. با مطابقت بردارهایی که ویژگیهای محصول را نشان میدهند، پیشنهادهای دقیق و سریع بر اساس ترجیحات کاربران ارائه میشود.
فیلترینگ مبتنی بر محتوا در شبکههای اجتماعی:
جستجوی برداری Qdrant میتواند در شبکههای اجتماعی برای فیلترینگ محتوا بر اساس شباهت بردارها به کار رود. کاربران میتوانند محتواهای مرتبط با علاقه خود را دریافت کنند و در نتیجه تعامل و مشارکت کاربران افزایش مییابد.
جمعبندی
با افزایش نیاز به پردازش و نمایش مؤثر دادهها، Qdrant بهعنوان یک موتور جستجوی شباهت برداری متنباز و پرامکانات، خود را متمایز کرده است. این پایگاه داده با استفاده از زبان Rust که به پایداری و امنیت معروف است ساخته شده و تمامی معیارهای رایج اندازهگیری فاصله را پشتیبانی میکند.
Qdrant امکان فیلتر دقیق نتایج جستجو را نیز فراهم میکند و با معماری ابری و قابلیتهای گسترده خود، مسیر جدیدی در فناوری جستجوی برداری باز میکند. اگرچه این ابزار تازه وارد حوزه پایگاههای برداری است، اما کتابخانههای کاربردی برای زبانهای برنامهنویسی مختلف دارد و سرویس ابری آن بهخوبی با حجم دادهها مقیاسپذیر است.
منابع
analyticsvidhya.com | docs.langchain.com
سوالات متداول
سرعت بالا، پایداری با Rust، پشتیبانی از معیارهای مختلف فاصله و امکان فیلتر پیشرفته، علاوه بر نسخه ابری مقیاسپذیر و کتابخانههای کلاینت متعدد.
سیستمهای پیشنهاددهی
جستجوی تصاویر و محتوای چندرسانهای
پردازش زبان طبیعی و جستجوی معنایی
تشخیص ناهنجاری
جستجوی محصولات در فروشگاههای آنلاین
فیلترینگ محتوا در شبکههای اجتماعی
بله، Qdrant قابلیت اجرا به صورت محلی با تعداد بردار کم یا استفاده از نسخه ابری رایگان ۱ گیگابایتی را دارد.




دیدگاهتان را بنویسید