
مدلهای پایه (Foundation Models) نهتنها به دادههای گذشته محدود هستند، بلکه عمدا پاسخهایی تولید میکنند که طبیعی و متنوع به نظر برسند. ترکیب این دو ویژگی میتواند به خروجیهایی منجر شود که با اطمینان بالا ارائه میشوند اما در واقع نادرست یا نامرتبطند. این رفتار را «توهم» (Hallucination) مینامند.
در این مقاله، محدودیتهای مدلهای پایه را بررسی میکنیم و توضیح میدهیم که چگونه رویکرد Retrieval-Augmented Generation یا RAG میتواند این ضعفها را پوشش دهد؛ بهگونهای که سیستمهای چت، موتورهای جستوجو و حتی جریانهای کاری مبتنی بر ایجنت همگی از آن بهرهمند شوند.
محدودیتهای مدلهای پایه

محصولاتی که صرفا بر پایه مدلهای پایه ساخته میشوند، در عین درخشان بودن، نقصهایی جدی دارند؛ چرا که این مدلها با محدودیتهای متعددی مواجهاند:
۱- محدودیت تاریخ بهروزرسانی مدل (Knowledge Cutoff)
وقتی از مدلهای فعلی درباره رویدادهای اخیر سوال میپرسید، مثلا نتیجه بازی NBA هفته گذشته یا نحوه استفاده از قابلیتهای جدید آخرین مدل آیفون، ممکن است با اطمینان کامل پاسخ بدهند اما اطلاعاتشان قدیمی یا حتی کاملا ساختگی باشد؛ همان «توهم»هایی که پیشتر به آن اشاره کردیم.
مدلها روی دیتاستهای عظیمی آموزش میبینند که شامل سالها دانش انسانی و خروجیهای خلاقانهاند: از مخازن کد و کتابها گرفته تا وبسایتها، گفتگوها، مقالات علمی و موارد دیگر. اما پس از پایان فرایند آموزش، این دادهها در یک نقطه زمانی مشخص «فریز» میشوند؛ نقطهای که به آن cutoff گفته میشود.
این توقف زمانی باعث ایجاد شکاف دانشی میشود. در نتیجه، وقتی از مدل درباره تحولات جدید سوال میشود، ممکن است پاسخی تولید کند که از نظر زبانی قانعکننده است اما از نظر واقعیت نادرست.

۲- نبود عمق در دانش حوزههای تخصصی
مدلهای پایه دانش گستردهای دارند اما در حوزههای تخصصی معمولا عمق کافی ندارند. در بسیاری از دامنههای تخصصی، دیتاستهای باکیفیت عمومی یا وجود ندارند یا بسیار محدودند؛ نه الزاما بهدلیل محرمانه بودن، بلکه بهدلیل ماهیت بسیار تخصصی آن حوزه.
برای مثال، یک مدل پزشکی ممکن است درباره آناتومی، بیماریها و تکنیکهای جراحی دانش عمومی خوبی داشته باشد اما در مواجهه با بیماریهای ژنتیکی نادر یا درمانهای نوین دچار ضعف شود. حتی اگر چنین دادههایی بهصورت عمومی در دسترس باشند، ممکن است به اندازهای تکرار نشده باشند که مدل بتواند الگوهای دقیق و قابل اتکایی از آنها بیاموزد. علاوه بر این، تفسیر صحیح چنین دادههایی در فرایند آموزش نیازمند دانش تخصصی سطح بالا است.
این محدودیت میتواند به پاسخهایی منجر شود که ناقص، سطحی یا حتی نامرتبط هستند.
۳- نداشتن دسترسی به دادههای خصوصی یا مالکیتی
در مورد مدلهای عمومی و همهمنظوره، دادههای اختصاصی شما اساسا بهصورت عمومی وجود ندارند و در زمان آموزش مدل در دسترس نبودهاند. این یعنی مدل هیچ شناختی از جزئیات کسبوکار شما ندارد؛ چه فرایندها و سیاستهای داخلی شرکت، چه دادههای پرسنلی یا ایمیلها و چه اسرار تجاری.
و البته این موضوع کاملا منطقی است: اگر چنین دادههایی در فرایند آموزش استفاده میشد، هر کاربری که به مدل دسترسی داشت، بالقوه میتوانست به اطلاعات خصوصی و مالکیتی شرکت شما هم دسترسی پیدا کند. اما نتیجه این محدودیت روشن است: پاسخها ممکن است ناقص یا نامرتبط باشند و در نتیجه، مدل برای کاربردهای سفارشی و بیزینسی شما کارایی محدودی داشته باشد.
۴- کاهش اعتماد
مدلها معمولا نمیتوانند برای پاسخ مشخصی که تولید میکنند، منبع یا ارجاع دقیقی ارائه دهند. وقتی پاسخ بدون استناد باشد، کاربر یا باید به آن اعتماد کند یا خودش ادعا را اعتبارسنجی کند.
با توجه به اینکه مدلها روی حجم عظیمی از دادههای عمومی آموزش دیدهاند، این احتمال وجود دارد که خروجی تولیدشده متاثر از منبعی غیرمعتبر باشد. وقتی اطلاعات نادرست، نامرتبط یا بیفایده تولید میشود، کاربران بهتدریج اعتمادشان را به خود مدل از دست میدهند؛ حتی اگر این رفتار ذات معماری و نحوه عملکرد مدلهای پایه باشد.
۵- تولید خروجی ذاتا احتمالاتی است
توهمها اغلب نشانهای از همان محدودیتهایی هستند که پیشتر توضیح دادیم. مدلها روی مجموعهای بسیار متنوع از دادهها آموزش میبینند؛ دادههایی که ممکن است شامل تناقض، خطا و ابهام باشند (در کنار دادههای درست).
به همین دلیل، مدل برای تمام ادامههای ممکن یک جمله، احتمال اختصاص میدهد؛ حتی برای ادامههای اشتباه. با توجه به عواملی مثل تصادفیبودن در نمونهگیری (پارامترهایی مثل temperature و top-k) و همچنین نحوه طراحی پرامپت توسط کاربر (مثلا پرامپت مبهم یا دارای زمینه گمراهکننده)، ممکن است مدل ادامه نادرستی را انتخاب کند. نتیجه، خروجیای است که میتواند شامل توهم باشد.
علاوه بر این، مدلها همیشه بین «دانستن» و «ندانستن» تمایز روشنی قائل نمیشوند و حتی زمانی که پاسخ ناقص، نادرست یا نامرتبط است، با لحنی کاملا مطمئن آن را بیان میکنند.
توهمها میتوانند به رفتارهای ناخواسته و حتی خطرناک منجر شوند. برای مثال، یک گزارش پزشکی نادرست اما بسیار قانعکننده ممکن است باعث تجویز درمانی خطرناک شود یا برعکس، از انجام درمان ضروری جلوگیری کند.
محدودیتهای مدلهای پایه میتوانند مستقیما بر نتایج مالی کسبوکار شما اثر بگذارند و اعتماد کاربران را تضعیف کنند. رویکرد Retrieval-Augmented Generation یا RAG برای پاسخ به همین محدودیتها طراحی شده است.
Retrieval-Augmented Generation چیست؟
RAG، رویکردی است که با استفاده از دادههای معتبر و خارجی، دقت، ارتباط و کارایی خروجی مدل را افزایش میدهد.
ایده اصلی ساده است: بهجای اینکه مدل فقط به دانش درونی خودش تکیه کند، پیش از تولید پاسخ، اطلاعات مرتبط را از یک منبع داده بیرونی بازیابی میکند و آن را در اختیار مدل قرار میدهد.
این فرایند معمولا از چهار مولفه اصلی تشکیل میشود که در ادامه مقاله با جزئیات بیشتری بررسی خواهند شد:
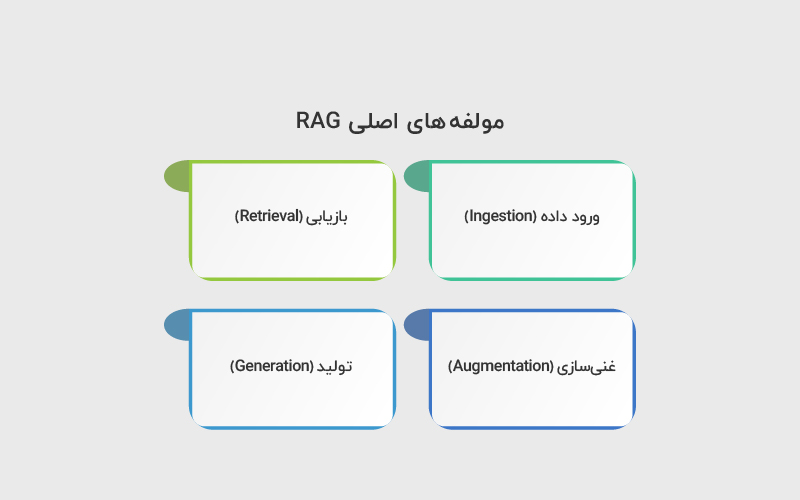
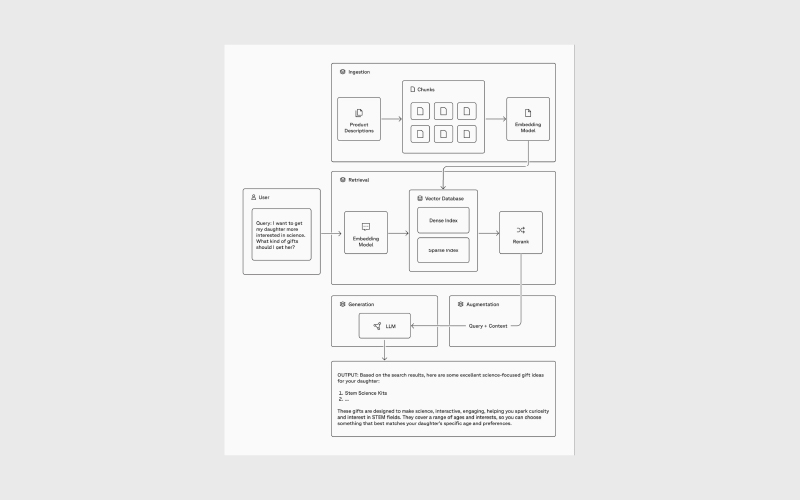
۱. ورود داده (Ingestion)
در این مرحله، دادههای معتبر مانند دادههای اختصاصی شرکت وارد یک منبع داده میشوند. این منبع میتواند مثلا یک پایگاهداده وکتوری مانند Pinecone باشد. به بیان ساده، دانش سازمانی شما به شکلی ساختاریافته و قابل جستوجو ذخیره میشود.
۲. بازیابی (Retrieval)
وقتی کاربر پرسشی مطرح میکند، سیستم دادههای مرتبط را بر اساس آن پرسش از منبع داده خارجی بازیابی میکند. در این مرحله معمولا از جستوجوی وکتوری یا روشهای مشابه برای یافتن نزدیکترین و مرتبطترین اطلاعات استفاده میشود.
۳. غنیسازی (Augmentation)
دادههای بازیابیشده به همراه پرسش کاربر در قالب یک پرامپت ترکیب میشوند. این پرامپت غنیشده، زمینه (context) لازم را برای مدل فراهم میکند تا پاسخ دقیقتری تولید کند. در واقع، مدل حالا بهجای تکیه بر حافظه آموزشی خود، به اطلاعات واقعی و مرتبط با همان پرسش دسترسی دارد.
۴. تولید (Generation)
در نهایت، مدل با استفاده از پرامپت غنیشده خروجی تولید میکند. وجود context بیرونی باعث میشود پاسخ نهایی دقیقتر، مرتبطتر و قابل اتکاتر باشد.
با ترکیب دادههای مرتبط از یک منبع خارجی با پرسش کاربر و ارائه آن به مدل بهعنوان context در مرحله تولید، مدل میتواند از این اطلاعات برای تولید خروجیای دقیقتر و مرتبطتر استفاده کند.
RAG مزایای زیر را فراهم میکند:
- دسترسی به دادههای بلادرنگ و دادههای اختصاصی یا حوزهمحور: امکان وارد کردن دانشی که متناسب با شرایط شماست؛ رویدادهای جاری، اخبار، شبکههای اجتماعی، دادههای مشتریان و دادههای اختصاصی سازمان.
- ایجاد اعتماد: نتایج دقیقتر و مرتبطتر احتمال بیشتری دارند که اعتماد کاربران را جلب کنند و ارجاع به منابع (source citations) امکان بررسی و اعتبارسنجی انسانی را فراهم میکند.
- کنترل بیشتر: کنترل بر اینکه از چه منابعی استفاده شود، دسترسی به دادههای بلادرنگ، مدیریت مجوزهای دسترسی، اعمال guardrailها و الزامات امنیتی و انطباق، قابلیت ردیابی و ارجاع به منبع، انتخاب استراتژیهای بازیابی، مدیریت هزینه و امکان تنظیم هر مولفه بهصورت مستقل از سایر بخشها.
- مقرونبهصرفه بودن نسبت به گزینههایی مانند آموزش یا بازآموزی مدل اختصاصی، فاینتیونینگ یا ارسال حجم زیادی داده در context window: تولید مدلهای پایه پرهزینه است و ایجاد آنها به دانش تخصصی نیاز دارد؛ فاینتیونینگ نیز همینطور. علاوه بر این، هرچه context بزرگتری برای مدل ارسال شود، هزینه اجرای آن افزایش پیدا میکند.
RAG در پشتیبانی از جریانهای کاری مبتنی بر ایجنت
اما رویکرد سنتی RAG ساده است؛ معمولا شامل یک پایگاهداده وکتوری و یک پرامپت تکمرحلهای (one-shot) است که همراه با context برای مدل ارسال میشود تا خروجی تولید کند. با ظهور ایجنتهای هوش مصنوعی، ایجنتها اکنون نقش تحلیلگر مولفههای اصلی RAG را بر عهده گرفتهاند تا:
- کوئریهای موثرتری بسازند
- به ابزارهای بازیابی بیشتری دسترسی داشته باشند
- دقت و ارتباط context بازیابیشده را ارزیابی کنند
- و با اعمال reasoning، اطلاعات بازیابیشده را اعتبارسنجی کرده و درباره پذیرش یا کنار گذاشتن آن تصمیم بگیرند
این عملیات میتواند توسط یک ایجنت یا مجموعهای از ایجنتها بهعنوان بخشی از یک برنامه بزرگتر و تکرارشونده (iterative) انجام شود.
ایجنتها در نقش ارکستراتور RAG، فرصتهای بیشتری برای بازبینی، اصلاح کوئریها، استدلال و اعتبارسنجی context فراهم میکنند؛ در نتیجه میتوانند تصمیمهای دقیقتر بگیرند، اقدامات آگاهانهتری انجام دهند و خروجیهای دقیقتر و مرتبطتری تولید کنند.
اکنون که با مفهوم RAG آشنا شدیم، بیایید عمیقتر بررسی کنیم که این رویکرد چگونه کار میکند.
Retrieval-Augmented Generation چگونه کار میکند؟
RAG با تکیه بر منابع داده معتبر مانند دادههای اختصاصی، دانش حوزهمحور و اطلاعات بلادرنگ، دقت و ارتباط خروجی LLMها را افزایش میدهد.
اما پیش از آنکه وارد جزئیات فنی شویم، باید دو سوال اساسی را مطرح کنیم: آیا واقعا به RAG نیاز دارید؟ و از کجا متوجه میشوید که سیستم شما درست کار میکند؟
اینجاست که مفهوم ground truth evaluation مطرح میشود. برای استقرار صحیح هر اپلیکیشنی، باید بدانید چه زمانی درست کار میکند. اپلیکیشنهای مبتنی بر هوش مصنوعی هم از این قاعده مستثنا نیستند.
بنابراین تعریف مجموعهای از کوئریها بههمراه پاسخهای مورد انتظارشان، برای ارزیابی عملکرد سیستم ضروری است. نگهداری و بهروزرسانی این مجموعه ارزیابی نیز اهمیت زیادی دارد؛ چون به شما نشان میدهد کجا باید بهبود ایجاد کنید و آیا این بهبودها واقعا موثر بودهاند یا نه.
RAG تنها یکی از روشهای بهینهسازی است. روشهای دیگری هم وجود دارند، مانند بازنویسی کوئری (query rewriting)، گسترش چانکها (chunk expansion)، استفاده از گراف دانش (knowledge graphs) و موارد دیگر.

با داشتن یک baseline مناسب، میتوانید به سراغ پیادهسازی چهار مولفه اصلی RAG بروید:
Ingestion
در پیادهسازی ساده و سنتی RAG، دادهها را از یک پایگاهداده وکتوری مانند Pinecone بازیابی میکنید. در این فرایند از جستوجوی معنایی (semantic search) استفاده میشود تا بهجای تطبیق صرف کلمات کلیدی، معنای واقعی پرسش کاربر تشخیص داده شود و اطلاعات مرتبط بازیابی شود.
در اینجا از Pinecone بهعنوان مثال استفاده میکنیم اما این مفهوم برای همه پایگاههای داده وکتوری صدق میکند. اما پیش از آنکه بتوانید دادهای را بازیابی کنید، باید آن را وارد سیستم کنید (ingest). مراحل ورود داده به پایگاهداده به این صورت است:
Chunk کردن دادهها
در مرحله ingestion، دادههای معتبر خود را بهصورت وکتور وارد Pinecone میکنید. این دادهها میتوانند ساختاریافته یا غیرساختاریافته باشند؛ مانند متن، فایلهای PDF، ایمیلها، ویکیهای داخلی یا دیتابیسها. پس از پاکسازی دادهها، معمولا لازم است آنها را به بخشهای کوچکتر تقسیم کنید (chunking). یعنی هر سند یا هر واحد داده را به چند قطعه کوچکتر تبدیل میکنید. بسته به نوع داده، نوع پرسشهای کاربران و نحوه استفاده از نتایج در اپلیکیشن، باید استراتژی مناسب برای chunk کردن را انتخاب کنید.
ایجاد بردارهای embedding
در مرحله بعد، با استفاده از یک مدل embedding، هر chunk را به یک embedding تبدیل میکنید و آن را در پایگاهداده وکتوری ذخیره میکنید. مدل embedding نوع خاصی از LLM است که هر قطعه داده را به یک بردار عددی تبدیل میکند؛ برداری که نمایانگر معنای آن داده است. این نمایش عددی به سیستم اجازه میدهد بر اساس شباهت معنایی، آیتمهای مشابه را جستوجو و بازیابی کند.
بارگذاری داده در پایگاهداده وکتوری
پس از تولید بردارها، آنها را در یک پایگاهداده وکتوری بارگذاری میکنید. این مرحله معمولا بهصورت آفلاین انجام میشود و مستقل از جریان کاری کاربر و اجرای اپلیکیشن است. با این حال، اگر دادهها تغییر کنند مثلا موجودی محصولات بهروزرسانی شود، میتوانید ایندکس را در زمان واقعی (real-time) بهروزرسانی کنید تا کاربران به اطلاعات جدید دسترسی داشته باشند.
اکنون که پایگاهداده وکتوری شامل embeddingهای دادههای منبع شماست، مرحله بعدی بازیابی (retrieval) است.
Retrieval
یک رویکرد ساده برای بازیابی، استفاده از جستوجوی معنایی بهتنهایی است. اما با استفاده از جستوجوی هیبرید (hybrid search)، ترکیبی از جستوجوی معنایی با بردارهای dense و جستوجوی واژگانی با بردارهای sparse، میتوانید کیفیت نتایج بازیابی را بیشتر بهبود دهید.
این موضوع زمانی اهمیت پیدا میکند که کاربران همیشه از یک زبان یا عبارت مشخص برای بیان یک موضوع استفاده نمیکنند (جستوجوی معنایی)، یا از اصطلاحات داخلی و حوزهمحور مانند مخففها، نام محصولات یا نام تیمها استفاده میکنند (جستوجوی واژگانی یا مبتنی بر کلمه کلیدی).
در مرحله retrieval، ابتدا از پرسش کاربر یک embedding تولید میکنیم تا آن را با بردارهای ذخیرهشده در پایگاهداده مقایسه کنیم.
در جستوجوی هیبرید، میتوانید یک ایندکس هیبرید واحد را کوئری بزنید یا بهصورت همزمان از یک ایندکس dense و یک ایندکس sparse استفاده کنید. سپس نتایج ترکیب و حذف موارد تکراری میشوند و با استفاده از یک مدل reranking، بر اساس یک امتیاز ارتباط یکپارچه دوباره رتبهبندی میشوند. در نهایت، مرتبطترین نتایج بازگردانده میشوند.
Augmentation
حالا که مرتبطترین نتایج را از مرحله بازیابی دریافت کردهاید، یک پرامپت غنیشده (augmented prompt) میسازید که شامل هم نتایج جستوجو و هم پرسش کاربر است و آن را برای LLM ارسال میکنید. اینجاست که بخش کلیدی ماجرا اتفاق میافتد.
یک نمونه از پرامپت غنیشده میتواند به این شکل باشد:
QUESTION:
<the user’s question>
CONTEXT:
<the search results to use as context>
Using the CONTEXT provided, answer the QUESTION. Keep your answer grounded in the facts of the CONTEXT. If the CONTEXT doesn’t contain the answer to the QUESTION, say you don’t know.
با ارسال همزمان نتایج جستوجو و پرسش کاربر بهعنوان context برای LLM، مدل را ترغیب میکنید که در مرحله تولید بعدی، از اطلاعات دقیقتر و مرتبطترِ بازیابیشده استفاده کند.
Generation
با استفاده از پرامپت غنیشده، LLM اکنون به مرتبطترین و مستندترین اطلاعات موجود در پایگاهداده وکتوری شما دسترسی دارد. به این ترتیب، اپلیکیشن شما میتواند پاسخ دقیقتری به کاربر ارائه دهد و احتمال بروز توهم را کاهش دهد.
اما RAG دیگر صرفا به معنای جستوجوی یک قطعه اطلاعات مناسب برای تکمیل پاسخ مدل نیست.
در رویکرد agentic RAG، مسئله این است که تصمیم بگیریم چه پرسشهایی باید مطرح شوند، از چه ابزارهایی استفاده شود، چه زمانی از آنها استفاده شود و در نهایت چگونه نتایج مختلف با هم تجمیع شوند تا پاسخ نهایی بر پایه اطلاعات معتبر شکل بگیرد.
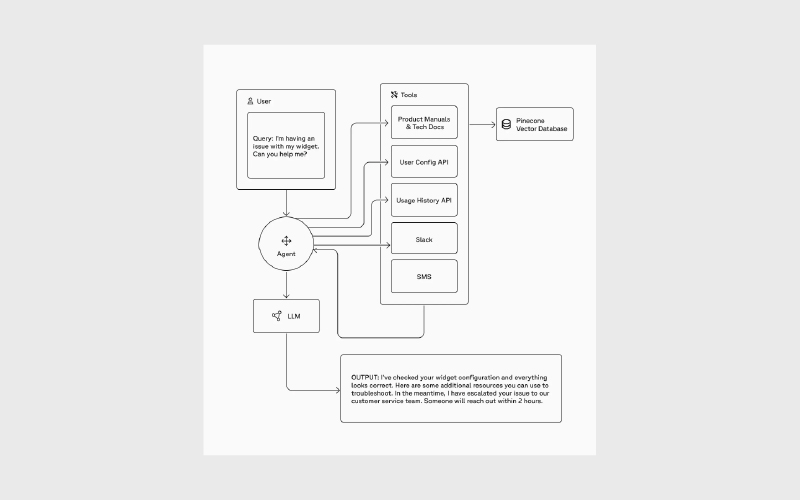
در این نسخه ساده، خود LLM نقش ایجنت را ایفا میکند و تصمیم میگیرد از کدام ابزارهای بازیابی استفاده کند، چه زمانی از آنها استفاده کند و چگونه آن ابزارها را کوئری بزند.
جمعبندی
Retrieval-Augmented Generation از یک واژه پرکاربرد و تبلیغاتی، به یکی از ارکان ضروری اپلیکیشنهای هوش مصنوعی تبدیل شده است. این رویکرد، توانمندی گسترده مدلهای پایه را با دانش معتبر و اختصاصی سازمان شما ترکیب میکند.
با توجه به اینکه ایجنتهای هوش مصنوعی اکنون سناریوهای پیچیدهتری را مدیریت میکنند، از پشتیبانی متخصصانی که با تجهیزات صنعتی پیشرفته کار میکنند گرفته تا ارائه ایجنتهای حوزهمحور در مقیاس وسیع، RAG دیگر فقط یک گزینه در سال ۲۰۲۵ نیست، بلکه یک ضرورت است. ضرورتی برای ساخت اپلیکیشنهای هوش مصنوعی دقیق، مرتبط و مسئولانه که فراتر از بازیابی ساده اطلاعات عمل میکنند.
هرچه ایجنتهای هوش مصنوعی خودمختارتر شوند و جریانهای کاری پیچیدهتری را مدیریت کنند، نیاز بیشتری خواهند داشت که استدلال خود را بر دادههای خصوصی و حوزهمحور شما مبتنی کنند و این دقیقا همان جایی است که RAG وارد میشود.
دیگر سوال این نیست که آیا باید RAG را پیادهسازی کنید یا نه؛ سوال این است که چگونه آن را متناسب با مورد استفاده و نیازهای دادهای منحصربهفرد خود، بهدرستی معماری کنید.
منابع



دیدگاهتان را بنویسید