
در بسیاری از پروژههای هوش مصنوعی، موفقیت مدلها به حجم بالایی از دادههای برچسبخورده وابسته است. برای مثال، اگر بخواهیم مدلی تصاویر گربه و سگ را تشخیص دهد، باید هزاران تصویر با برچسب دقیق در اختیار آن قرار دهیم. اما تهیه چنین دادههایی همیشه ساده، ارزان یا سریع نیست. یادگیری خودنظارتی (Self-Supervised Learning) روشی است که تلاش میکند این مسئله را حل کند و به مدلها اجازه میدهد بدون نیاز به حجم زیادی از دادههای برچسبخورده، از دادههای خام و بدون برچسب یاد بگیرند.
اهمیت یادگیری خودنظارتی زمانی بیشتر مشخص میشود که بدانیم در بسیاری از پروژهها، جمعآوری داده فراوان ممکن است، اما برچسبگذاری دقیق آن زمانبر، پرهزینه و وابسته به نیروی متخصص است. در این مقاله بررسی میکنیم یادگیری خودنظارتی چیست، چگونه کار میکند، چه تفاوتی با سایر روشهای یادگیری دارد، در چه کاربردهایی استفاده میشود و چگونه میتوان یک نمونه ساده از آن را پیادهسازی کرد.
یادگیری خودنظارتی چیست؟
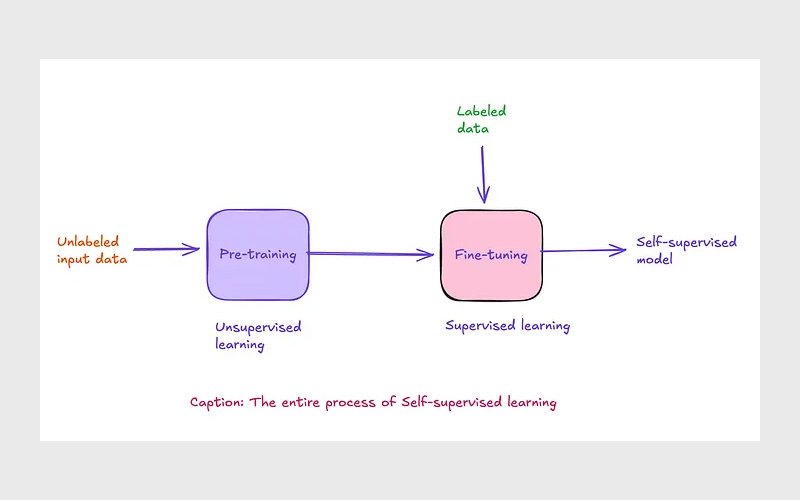
یادگیری خودنظارتی (SSL) یکی از روشهای آموزش مدلهای یادگیری ماشین است که در آن، مدل بدون نیاز به برچسبگذاری انسانی آموزش میبیند. در این رویکرد، بهجای استفاده از دادههای دارای برچسب آماده، خود دادهها منبع تولید سیگنال آموزشی میشوند و مدل تلاش میکند با پیشبینی بخشهای پنهان یا کشف ارتباط میان اجزای داده، الگوهای مهم را یاد بگیرد.
برای درک بهتر، فرض کنید جملهای مانند «امروز هوا بسیار ___ است» در اختیار مدل قرار گیرد. مدل باید کلمه مناسب را حدس بزند. یا در حوزه تصویر، بخشی از یک عکس حذف میشود و مدل تلاش میکند قسمت ازدسترفته را پیشبینی کند. در هر دو مثال، برچسبی توسط انسان تعریف نشده است، اما خود ساختار داده یک مسئله آموزشی ایجاد کرده است.
هدف اصلی یادگیری خودنظارتی، یادگیری نمایشهای مفید از دادههاست؛ یعنی مدل بتواند ویژگیها و روابط پنهان در داده را درک کند و از این دانش در وظایف بعدی مانند طبقهبندی، تشخیص اشیا، ترجمه متن یا تحلیل صوت استفاده کند. به همین دلیل، این روش در سالهای اخیر به یکی از پایههای اصلی مدلهای بزرگ هوش مصنوعی تبدیل شده است.
تفاوت مهم یادگیری خودنظارتی با یادگیری بدوننظارت (Unsupervised Learning) در این است که در یادگیری خودنظارتی، مدل معمولا یک هدف مشخص برای پیشبینی دارد. به بیان ساده، مدل صرفا داده را خوشهبندی یا دستهبندی نمیکند، بلکه برای حل یک مسئله طراحیشده آموزش میبیند؛ مسئلهای که پاسخ آن از خود داده استخراج میشود.
چرا یادگیری خودنظارتی مهم است؟
یادگیری خودنظارتی زمانی اهمیت پیدا کرد که محدودیت روشهای سنتی آموزش مدلها بیشتر از گذشته نمایان شد. حجم عظیمی از دادههای خام و بدون برچسب هر روز تولید میشود؛ از صفحات وب و شبکههای اجتماعی گرفته تا تصاویر دوربینها، فایلهای صوتی و دادههای سازمانی. یادگیری خودنظارتی راهی فراهم کرد تا مدلها بتوانند از همین دادههای خام برای یادگیری استفاده کنند و وابستگی به دادههای برچسبخورده را کاهش دهند.
یکی دیگر از دلایل مهم رشد این رویکرد، ظهور مدلهای بزرگ و پایه (Foundation Models) بود. مدلهایی مانند GPT، BERT، CLIP و بسیاری از مدلهای بینایی کامپیوتر، ابتدا روی حجم بزرگی از دادههای بدون برچسب با روشهای خودنظارتی آموزش میبینند و سپس برای وظایف خاص بهینهسازی میشوند. این فرایند باعث میشود مدل پیش از ورود به یک مسئله تخصصی، درک عمومی مناسبی از زبان، تصویر یا الگوهای داده به دست آورده باشد.
یادگیری خودنظارتی همچنین از نظر مقیاسپذیری اهمیت زیادی دارد. هرچه داده بیشتری در اختیار باشد، امکان آموزش مدلهای قویتر فراهم میشود، بدون آنکه نیاز باشد همان مقدار داده توسط انسان برچسبگذاری شود. به همین دلیل، بسیاری از پیشرفتهای مهم هوش مصنوعی مدرن بدون استفاده از یادگیری خودنظارتی امکانپذیر نبودند.
یادگیری خودنظارتی چگونه کار میکند؟
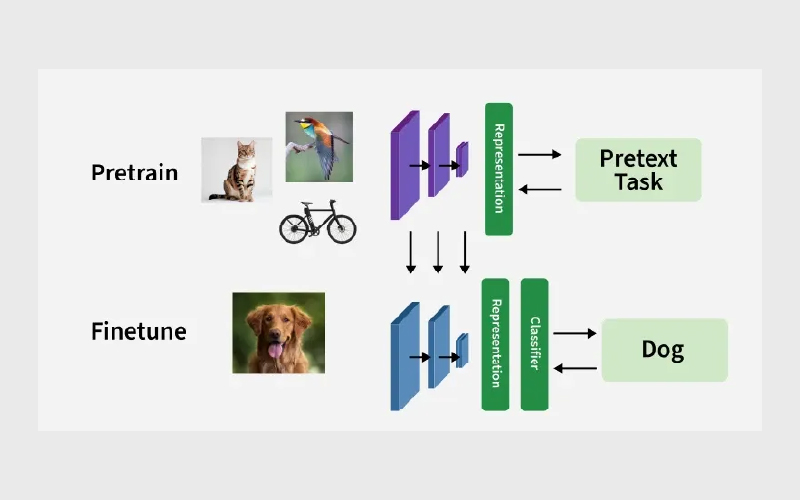
یادگیری خودنظارتی به این صورت عمل میکند که از خود دادهها برای ساخت یک مسئله آموزشی استفاده میشود. بهجای آنکه انسان برای هر نمونه برچسب مشخصی تعیین کند، مدل بخشی از اطلاعات را دریافت میکند و باید بخش دیگر را پیشبینی کند. در این فرایند، مدل بهتدریج الگوها، روابط و ساختارهای پنهان داده را یاد میگیرد و از آن برای وظایف بعدی استفاده میکند.
هسته اصلی این روش معمولا بر پایه طراحی یک وظیفه پیشآموزشی (Pretext Task) است. این وظیفه یک مسئله مصنوعی اما مفید است که مدل با حل آن، دانش قابل انتقال به دست میآورد. برای مثال، در پردازش زبان طبیعی ممکن است چند کلمه از یک جمله حذف شود و مدل باید آنها را حدس بزند. در حوزه تصویر، بخشی از عکس پوشانده میشود و مدل باید قسمت حذفشده را بازسازی کند. در برخی روشها نیز مدل باید تشخیص دهد که آیا دو تصویر متفاوت، نسخههای تغییریافته از یک تصویر اصلی هستند یا خیر.
پس از حل این وظایف، مدل تنها پاسخ صحیح را حفظ نمیکند، بلکه نمایشهای معناداری از داده میآموزد. منظور از نمایش، بردارها یا ویژگیهایی است که اطلاعات مهم داده را در خود نگه میدارند. این نمایشها میتوانند شامل مفاهیمی مانند شباهت معنایی، ساختار جمله، شکل اشیا یا ارتباط میان اجزای تصویر باشند.
در مرحله بعد، همین مدل آموزشدیده برای وظایف واقعی مورد استفاده قرار میگیرد. برای مثال، مدلی که قبلا با دادههای متنی بهصورت خودنظارتی آموزش دیده، میتواند برای تحلیل احساسات، ترجمه یا پاسخگویی به سوال تنظیم شود. همچنین مدلی که روی تصاویر آموزش دیده است، میتواند در طبقهبندی تصاویر، تشخیص اشیا یا تحلیل پزشکی عملکرد بهتری داشته باشد.
به بیان ساده، یادگیری خودنظارتی ابتدا به مدل کمک میکند دنیا را از دل دادهها بشناسد و سپس این دانش را در مسائل واقعی به کار بگیرد. همین ویژگی باعث شده است این روش به یکی از پایههای اصلی آموزش مدلهای مدرن هوش مصنوعی تبدیل شود.

تفاوت یادگیری خودنظارتی با Supervised و Unsupervised

برای درک بهتر یادگیری خودنظارتی، بهتر است آن را در کنار دو رویکرد رایج دیگر یعنی یادگیری نظارتشده (Supervised Learning) و یادگیری بدوننظارت (Unsupervised Learning) بررسی کنیم. هر سه روش برای آموزش مدلهای هوش مصنوعی استفاده میشوند، اما در نوع داده، نحوه آموزش و هدف نهایی تفاوت دارند.
یادگیری نظارتشده (Supervised Learning)
در یادگیری نظارتشده، مدل با استفاده از دادههای دارای برچسب آموزش میبیند. یعنی برای هر ورودی، پاسخ صحیح از قبل مشخص شده است. برای مثال، اگر مجموعهای از تصاویر گربه و سگ داشته باشیم، هر تصویر با برچسب مربوط به خود همراه است و مدل یاد میگیرد بر اساس این نمونهها تصاویر جدید را دستهبندی کند.
این روش در بسیاری از مسائل عملکرد بسیار خوبی دارد، اما وابستگی شدید آن به دادههای برچسبخورده یکی از چالشهای اصلی محسوب میشود. هرچه مسئله پیچیدهتر باشد، تهیه داده مناسب نیز دشوارتر خواهد شد.
یادگیری بدوننظارت (Unsupervised Learning)
در یادگیری بدوننظارت، دادهها برچسب ندارند و مدل تلاش میکند ساختارهای پنهان آنها را کشف کند. برای مثال، خوشهبندی مشتریان بر اساس رفتار خرید یا کاهش ابعاد دادهها از نمونههای رایج این روش هستند.
در این رویکرد، مدل پاسخ مشخصی برای پیشبینی ندارد و بیشتر به دنبال یافتن الگوها، شباهتها یا گروهبندی طبیعی دادههاست.
یادگیری خودنظارتی (Self-Supervised Learning)
یادگیری خودنظارتی را میتوان روشی میان این دو رویکرد دانست. در این روش، دادهها برچسب انسانی ندارند، اما مدل یک هدف مشخص برای یادگیری دارد. این هدف از خود داده تولید میشود. برای مثال، پیشبینی کلمه حذفشده در یک جمله یا بازسازی بخشی از تصویر.
به همین دلیل، مدل بدون نیاز به برچسبگذاری دستی، آموزش هدفمند میبیند و میتواند نمایشهای قدرتمندی از داده ایجاد کند.
تفاوت اصلی این سه رویکرد
| رویکرد | ایده اصلی | نوع داده | نقش برچسب (Label) | هدف مدل | مثال ساده |
| یادگیری نظارتشده (Supervised Learning) | پاسخ صحیح توسط انسان مشخص میشود | دادههای برچسبخورده | وجود دارد و ضروری است | یادگیری نگاشت ورودی به خروجی مشخص | تشخیص اینکه تصویر «گربه» است یا «سگ» |
| یادگیری بدوننظارت (Unsupervised Learning) | مدل خودش ساختار داده را کشف میکند | داده بدون برچسب | وجود ندارد | کشف الگوها، خوشهبندی یا ساختار پنهان داده | گروهبندی مشتریان مشابه بدون دانستن برچسب |
| یادگیری خودنظارتی (Self-Supervised Learning) | برچسب از خود داده تولید میشود | داده خام | بهصورت مصنوعی از داده ساخته میشود | حل یک task مشخص برای یادگیری representation | پیشبینی کلمه بعدی در جمله یا ارتباط تصویر و متن |
روشهای مهم Self-Supervised Learning
در یادگیری خودنظارتی یا Self-Supervised Learning هدف این است که مدل بدون نیاز به labelهای انسانی، از خود داده یاد بگیرد. این کار معمولا با طراحی یک task مصنوعی (pretext task) انجام میشود که مدل را مجبور میکند ساختار پنهان داده را یاد بگیرد.
۱. Contrastive Learning
در این روش، مدل یاد میگیرد بین نمونههای مشابه و غیرمشابه تمایز قائل شود.
- نمونههای مشابه (positive pairs) به هم نزدیک میشوند
- نمونههای غیرمشابه (negative pairs) از هم دور میشوند
این روش پایه بسیاری از مدلهای مدرن بینایی و زبان است و حتی در مدلهایی مثل CLIP هم استفاده شده است.
۲. Autoencoder-based Learning
در این رویکرد، مدل تلاش میکند ورودی را بازسازی کند.
- تصویر یا داده فشرده میشود (encoding)
- سپس دوباره بازسازی میشود (decoding)
هدف این است که مدل representation فشرده و معنادار از داده یاد بگیرد.
۳. Masked Modeling
در این روش بخشی از ورودی مخفی (mask) میشود و مدل باید آن را حدس بزند.
مثال:
- در تصویر: حذف کردن بخشهایی از تصویر
- در متن: حذف کلمات و پیشبینی آنها
این روش در مدلهایی مثل ViT و BERT بسیار استفاده میشود.
آموزش یک مدل Self-Supervised Learning در یادگیری ماشین
برای آموزش یک مدل با قابلیت یادگیری خودنظارتی باید مراحل زیر را دنبال کنید:
مرحله ۱: وارد کردن کتابخانهها و بارگذاری دیتاست
در این مرحله، کتابخانههای مورد نیاز مانند TensorFlow، Keras، NumPy و Matplotlib را وارد میکنیم. همچنین از دیتاست MNIST برای آموزش مدل استفاده میشود.
در اینجا تصاویر ارقام MNIST بارگذاری میشوند، اما نکته مهم این است که در این مرحله، برچسبها عمدا نادیده گرفته میشوند؛ چون هدف ما یک task خودنظارتی است، نه یادگیری مستقیم از labels.
سپس مقادیر پیکسلها نرمالسازی میشوند تا بین 0 و 1 قرار بگیرند و در نهایت یک بعد کانال به تصاویر اضافه میشود تا با ورودی CNN سازگار شوند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import tensorflow as tf from tensorflow.keras import layers, models import numpy as np (x_train, _), (x_test, _) = tf.keras.datasets.mnist.load_data() x_train = x_train.astype(‘float32’) / 255. x_test = x_test.astype(‘float32’) / 255. x_train = np.expand_dims(x_train, –1) x_test = np.expand_dims(x_test, –1) x_train_small = x_train[:1000] x_test_small = x_test[:200] |
مرحله ۲: آمادهسازی دیتاست برای Rotation Task
در این مرحله یک task خودنظارتی طراحی میشود: پیشبینی زاویه چرخش تصویر.
چهار زاویه تعریف میشود:
0°، 90°، 180° و 270°
سپس هر تصویر با این زاویهها چرخانده میشود و برچسب مربوط به زاویه به آن اختصاص داده میشود. در واقع مدل یاد میگیرد تشخیص دهد تصویر چقدر چرخانده شده است.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
angles = [0, 90, 180, 270] def rotate_images(images, angles): rotated_images = [] labels = [] for img in images: for i, angle in enumerate(angles): rotated = tf.image.rot90(img, k=angle // 90) rotated_images.append(rotated.numpy()) labels.append(i) return np.array(rotated_images), np.array(labels) x_train_rot, y_train_rot = rotate_images(x_train_small, angles) x_test_rot, y_test_rot = rotate_images(x_test_small, angles) |
مرحله ۳: تعریف و کامپایل مدل CNN برای تشخیص چرخش
در این مرحله یک شبکه عصبی کانولوشنی ساده (CNN) تعریف میشود تا ویژگیهای تصویر را یاد بگیرد.
مدل در خروجی، احتمال تعلق تصویر به یکی از ۴ کلاس (زاویهها) را پیشبینی میکند.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
model = models.Sequential([ layers.Input(shape=(28, 28, 1)), layers.Conv2D(32, 3, activation=‘relu’), layers.MaxPooling2D(), layers.Conv2D(64, 3, activation=‘relu’), layers.MaxPooling2D(), layers.Flatten(), layers.Dense(128, activation=‘relu’), layers.Dense(len(angles), activation=‘softmax’) ]) model.compile(optimizer=‘adam’, loss=‘sparse_categorical_crossentropy’, metrics=[‘accuracy’]) |
مرحله ۴: آموزش مدل روی تصاویر چرخیده
حالا مدل روی task خودنظارتی آموزش داده میشود. هدف این است که مدل یاد بگیرد زاویه چرخش تصویر را پیشبینی کند.
|
1 2 |
model.fit(x_train_rot, y_train_rot, epochs=5, batch_size=64, validation_data=(x_test_rot, y_test_rot)) |
در این مرحله هیچ برچسب واقعی مربوط به عدد (digit label) استفاده نمیشود.
مرحله ۵: نمایش نتایج پیشبینی چرخش
پس از آموزش، مدل روی تصاویر تست اجرا میشود و خروجی آن بررسی میشود.
در این مرحله چند تصویر بهصورت تصادفی انتخاب میشود و همراه با زاویه واقعی و پیشبینیشده نمایش داده میشود.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import matplotlib.pyplot as plt predictions = model.predict(x_test_rot) num_examples = 5 indices = np.random.choice(len(x_test_rot), num_examples, replace=False) for i, idx in enumerate(indices): img = x_test_rot[idx].squeeze() true_label = y_test_rot[idx] pred_label = np.argmax(predictions[idx]) plt.subplot(1, num_examples, i + 1) plt.imshow(img, cmap=‘gray’) plt.title(f“True: {angles[true_label]}°\nPred: {angles[pred_label]}°”) plt.axis(‘off’) plt.show() |
مرحله ۶: بارگذاری دادههای دارای برچسب برای Fine-tuning
حالا از نسخه اصلی دیتاست MNIST که دارای label است استفاده میکنیم تا مدل را برای task نهایی (تشخیص عدد) fine-tune کنیم.
دادهها نرمالسازی شده و یک زیرمجموعه کوچک برای آموزش سریع انتخاب میشود.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
(x_train_labeled, y_train_labeled), (x_test_labeled, y_test_labeled) = tf.keras.datasets.mnist.load_data() x_train_labeled = x_train_labeled.astype(‘float32’) / 255. x_test_labeled = x_test_labeled.astype(‘float32’) / 255. x_train_labeled = np.expand_dims(x_train_labeled, –1) x_test_labeled = np.expand_dims(x_test_labeled, –1) x_train_fine = x_train_labeled[:1000] y_train_fine = y_train_labeled[:1000] x_test_fine = x_test_labeled[:200] y_test_fine = y_test_labeled[:200] |
مرحله ۷: تغییر مدل و Fine-tuning روی دادههای برچسبدار
در این مرحله:
- لایههای کانولوشن فریز میشوند (یعنی وزنها تغییر نمیکنند)
- لایه خروجی تغییر میکند تا بهجای ۴ کلاس، ۱۰ کلاس عددی را پیشبینی کند
- مدل روی دادههای دارای برچسب آموزش داده میشود
|
1 2 3 4 5 6 7 8 9 10 11 12 |
for layer in model.layers[:–2]: layer.trainable = False model.pop() model.add(layers.Dense(10, activation=‘softmax’)) model.compile(optimizer=‘adam’, loss=‘sparse_categorical_crossentropy’, metrics=[‘accuracy’]) model.fit(x_train_fine, y_train_fine, epochs=5, batch_size=64, validation_data=(x_test_fine, y_test_fine)) |
مرحله ۸: نمایش نتایج مدل بعد از Fine-tuning
در نهایت، مدل روی دادههای تست اجرا میشود تا عملکرد آن در تشخیص ارقام واقعی بررسی شود.
چند تصویر بهصورت تصادفی انتخاب شده و همراه با مقدار واقعی و پیشبینیشده نمایش داده میشود.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
predictions = model.predict(x_test_fine) indices = np.random.choice(len(x_test_fine), 5, replace=False) for i, idx in enumerate(indices): img = x_test_fine[idx].squeeze() true_label = y_test_fine[idx] pred_label = np.argmax(predictions[idx]) plt.subplot(1, 5, i + 1) plt.imshow(img, cmap=‘gray’) plt.title(f“True: {true_label}\nPred: {pred_label}”) plt.axis(‘off’) plt.show() |
مرحله ۹: خروجی

کاربردهای Self-Supervised Learning
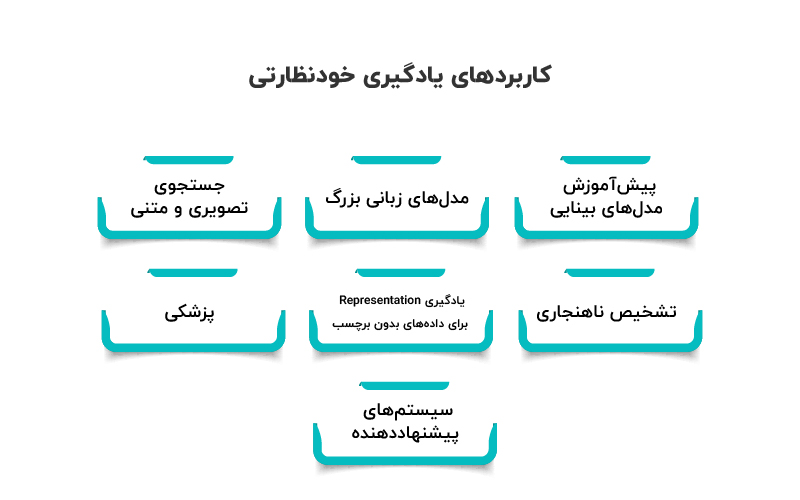
SSL فقط یک تکنیک آزمایشگاهی نیست، بلکه یکی از پایههای اصلی بسیاری از سیستمهای واقعی هوش مصنوعی امروز است. ایده مرکزی SSL این است که مدل بتواند بدون نیاز به برچسب انسانی، از دادههای خام یاد بگیرد و یک «نمایش مفهومی (representation)» قوی از داده بسازد. همین ویژگی باعث شده در چند حوزه مهم بهطور گسترده استفاده شود.
پیشآموزش مدلهای بینایی (Vision Pretraining)
در بینایی کامپیوتری، معمولا قبل از اینکه مدل برای یک task خاص مثل classification یا detection استفاده شود، ابتدا روی حجم بزرگی از دادههای بدون برچسب آموزش داده میشود. این مرحله باعث میشود مدل ویژگیهای عمومی تصویر مثل لبهها، بافتها و ساختارها را یاد بگیرد. بعداً این دانش در taskهای خاص استفاده میشود و نیاز به داده برچسبخورده کمتر میشود.
مدلهای زبانی بزرگ (Large Language Models)
بسیاری از مدلهای زبانی مدرن بر پایه SSL ساخته شدهاند. مثلا مدل یاد میگیرد در یک جمله، کلمه بعدی چیست یا بخشهای حذفشده را حدس بزند. این فرایند باعث میشود مدل بدون نیاز به برچسبگذاری دستی، درک عمیقی از زبان طبیعی پیدا کند.
جستجوی تصویری و متنی
در سیستمهای جستجو، هدف این است که ارتباط بین تصویر و متن یا بین آیتمهای مشابه پیدا شود. SSL کمک میکند مدلها یک فضای embedding مشترک بسازند که در آن مفاهیم مشابه به هم نزدیک باشند. این دقیقا پایه بسیاری از سیستمهای search هوشمند است.
تشخیص ناهنجاری (Anomaly Detection)
در بسیاری از سیستمها، دادههای «عادی» زیاد هستند اما نمونههای غیرعادی کم و ناشناختهاند. SSL کمک میکند مدل الگوی دادههای عادی را یاد بگیرد و هر چیزی که از آن الگو فاصله دارد را بهعنوان anomaly تشخیص دهد.

یادگیری Representation برای دادههای بدون برچسب
یکی از مهمترین کاربردهای SSL همین است: ساخت یک representation قوی از داده بدون نیاز به label. این representation بعدا در taskهای مختلف قابل استفاده است و کیفیت مدل را بهطور قابل توجهی افزایش میدهد.
کاربرد در پزشکی
در حوزه پزشکی، برچسبگذاری داده بسیار سخت و گران است (مثلا تصاویر MRI یا CT). SSL این امکان را میدهد که مدل از دادههای خام بیمارستانها یاد بگیرد و بعدا در تشخیص بیماریها یا تحلیل تصاویر پزشکی استفاده شود.
سیستمهای Recommendation
در سیستمهای پیشنهاددهنده (مثل فیلم، محصول یا محتوا)، SSL کمک میکند الگوهای رفتاری کاربران و شباهت بین آیتمها بدون نیاز به برچسبهای صریح یاد گرفته شود. نتیجه آن پیشنهادهای دقیقتر و شخصیسازیشدهتر است.
مزایا و محدودیتهای Self-Supervised Learning
Self-Supervised Learning یکی از مهمترین مزیتهای خود را در حذف وابستگی به دادههای برچسبخورده نشان میدهد. این ویژگی باعث میشود بتوان از حجم عظیم دادههای خام که در دنیای واقعی بهوفور وجود دارد استفاده کرد و مدلهایی با مقیاس بسیار بزرگتر آموزش داد؛ بدون اینکه هزینه و زمان سنگین برچسبگذاری انسانی وجود داشته باشد.
اما در کنار این مزیت مهم، چالشهایی هم وجود دارد. طراحی یک task مناسب (pretext task) همیشه ساده نیست و انتخاب اشتباه میتواند باعث شود مدل representation ضعیفی یاد بگیرد. علاوه بر آن، فرایند آموزش در SSL معمولا پیچیدهتر از روشهای سنتی است و در بسیاری از موارد به منابع محاسباتی قابل توجهی نیاز دارد. همچنین کیفیت نهایی مدل بهشدت به نوع task خودنظارتی وابسته است؛ یعنی اگر مسئله آموزشی خوب طراحی نشود، خروجی مدل هم قابل اعتماد نخواهد بود.
آینده یادگیری خودنظارتی
آینده Self-Supervised Learning بهوضوح به سمت مدلهای عمومیتر و بزرگتر حرکت میکند. بسیاری از foundation modelهای مدرن بر پایه همین رویکرد ساخته شدهاند، جایی که مدلها بدون نیاز به برچسب انسانی، از دادههای خام یاد میگیرند و سپس در طیف وسیعی از وظایف قابل استفاده میشوند.
در آینده نزدیک، انتظار میرود SSL نقش پررنگتری در حذف کامل نیاز به label در بسیاری از حوزهها داشته باشد. همچنین ترکیب آن با multimodal learning (مثل اتصال تصویر، متن و صدا) باعث ایجاد مدلهای هوشمندتر خواهد شد. از طرف دیگر، این رویکرد بهعنوان یکی از پایههای اصلی در ساخت agentهای هوشمند و سیستمهای خودکار آینده نیز مطرح است.
جمعبندی
یادگیری خودنظارتی (SSL) نشان داد که برای آموزش مدلهای هوش مصنوعی لزوما نیازی به دادههای برچسبخورده نیست و میتوان از خود ساختار داده برای یادگیری استفاده کرد. این رویکرد نهتنها هزینه و زمان آمادهسازی داده را کاهش میدهد، بلکه مسیر ساخت مدلهای بزرگ و مقیاسپذیر را هموار کرده است. از پیشآموزش مدلهای بینایی و زبانی گرفته تا سیستمهای جستجو و recommendation، SSL به یکی از پایههای اصلی هوش مصنوعی مدرن تبدیل شده است. در نتیجه، درک این رویکرد برای هر توسعهدهنده یا پژوهشگر حوزه AI یک ضرورت محسوب میشود، نه صرفا یک انتخاب.
منابع
snowflake.com | v7darwin.com | geeksforgeeks.org | rajendran22.medium.com
سوالات متداول
در یادگیری نظارتشده (Supervised)، دادهها باید برچسبگذاری شوند، اما در Self-Supervised مدل خودش از ساختار دادهها برچسب تولید میکند. این موضوع هزینه جمعآوری داده را بهشدت کاهش میدهد.
نه دقیقا. در Unsupervised هدف پیدا کردن الگوهای پنهان است، اما در Self-Supervised یک «وظیفه ساختگی (pretext task)» تعریف میشود تا مدل از روی آن یاد بگیرد.
فریمورکهایی مثل PyTorch، TensorFlow و JAX رایج هستند. همچنین کتابخانههایی مثل Hugging Face Transformers و PyTorch Lightning کار را سادهتر میکنند.
نه، این یک روش آموزش است نه معماری. میتوان آن را روی CNN، Transformer یا مدلهای دیگر اعمال کرد.



دیدگاهتان را بنویسید