
با رشد سریع دادهها و افزایش وابستگی ما به موتورهای جستجو، روشهای سنتی جستجو مبتنی بر کلیدواژه دیگر پاسخگوی نیازهای کاربران نیستند. کاربر امروز انتظار دارد که موتور جستجو تنها به تطبیق واژهها اکتفا نکند، بلکه معنای واقعی پرسوجو و حتی نیت پشت آن را درک کند. اینجاست که جستجوی معنایی (Semantic Search) وارد عمل میشود.
جستجوی معنایی با تکیه بر فناوریهایی مانند یادگیری ماشین، پردازش زبان طبیعی (NLP) و جستجوی برداری (Vector Search)، تجربهای هوشمندتر و شهودیتر از جستجو فراهم میکند. این فناوری به توسعهدهندگان امکان میدهد موتورهای جستجویی بسازند که نهتنها کلمات بلکه مفاهیم و ارتباطات بین آنها را نیز درک کنند.
در این مقاله از بلاگ آسا ابتدا با مفاهیم پایهای جستجوی معنایی و تفاوت آن با جستجوی کلیدواژهای آشنا میشویم، سپس کاربردها، مزایا و روشهای پیادهسازی عملی آن در پایتون با استفاده از OpenAI و Pinecone را بررسی خواهیم کرد.
تعریف جستجوی معنایی
جستجوی معنایی یک فناوری موتور جستجو است که هدف آن درک معنای کلمات و عبارات است. در این روش، نتایج جستجو بر اساس مفهوم و معنای پرسوجو ارائه میشوند، نه صرفا بر اساس تطابق واژههای دقیق موجود در متن.
جستجوی معنایی مجموعهای از قابلیتها را شامل میشود که موتور جستجو به کمک آنها میتواند هدف کاربر از جستجو و همچنین بستر و زمینه جستجو را درک کند.
این نوع جستجو برای بهبود کیفیت نتایج طراحی شده است تا زبان طبیعی را دقیقتر و در بستر واقعی آن تفسیر کند. جستجوی معنایی این کار را با تطبیق «هدف کاربر» با «معنای واژهها» انجام میدهد و برای این منظور از فناوریهایی مثل یادگیری ماشین و هوش مصنوعی بهره میگیرد.
جستجوی معنایی چگونه کار میکند؟
جستجوی معنایی بر پایه جستجوی برداری (Vector Search) عمل میکند. این رویکرد باعث میشود موتور جستجو بتواند نتایج را نهتنها بر اساس شباهت ظاهری واژهها، بلکه بر اساس ارتباط مفهومی و نیت کاربر رتبهبندی و ارائه کند.
در جستجوی برداری، اطلاعات قابل جستجو بهصورت بردارهایی از دادهها و مفاهیم مرتبط رمزگذاری میشوند. سپس این بردارها با یکدیگر مقایسه میشوند تا مشخص شود کدام دادهها بیشترین شباهت را دارند.
در عمل، فرایند به این شکل انجام میشود:
۱. وقتی کاربر یک پرسوجو (Query) وارد میکند، موتور جستجو آن را به Embedding تبدیل میکند؛ یعنی نمایش عددی دادهها و زمینههای معنایی مرتبط. این Embeddingها در قالب بردار ذخیره میشوند.
۲. سپس الگوریتم kNN (k-Nearest Neighbors) بردار پرسوجو را با بردارهای موجود در اسناد مقایسه میکند و نزدیکترین همسایهها را شناسایی میکند.
۳. در نهایت، موتور جستجو نتایج را بر اساس ارتباط مفهومی رتبهبندی و ارائه میدهد.
به این ترتیب، جستجوی معنایی میتواند به جای جستجوی ساده مبتنی بر کلیدواژه، نتایجی متناسب با معنی و هدف واقعی کاربر ارائه کند.
مفهوم زمینه (Context) در جستجوی معنایی
در جستجوی معنایی، زمینه (Context) میتواند به هر نوع اطلاعات اضافی اشاره داشته باشد؛ مثل موقعیت جغرافیایی کاربر، زمینه متنی پیرامونی کلمات موجود در پرسوجو یا حتی تاریخچه جستجوهای قبلی کاربر.
جستجوی معنایی با استفاده از این سرنخها تلاش میکند معنای واقعی یک واژه را در بین میلیونها نمونه داده تشخیص دهد. همچنین میتواند واژههایی را که در بسترهای مشابه استفاده میشوند، شناسایی کند.
بهعنوان مثال، جستجوی عبارت «football» در ایالات متحده معمولا به معنای فوتبال آمریکایی است، در حالی که در بریتانیا و بسیاری نقاط دیگر جهان همان واژه به معنای فوتبال (soccer) است. جستجوی معنایی میتواند با توجه به موقعیت جغرافیایی کاربر، تفاوت این دو معنا را تشخیص داده و نتایج مناسب را ارائه دهد.
هدف جستجو کننده (Searcher Intent)
یکی از اهداف اصلی جستجوی معنایی، بهبود تجربه کاربر است. برای این کار، موتور جستجو تلاش میکند نیت واقعی کاربر را تفسیر کند:
- آیا کاربر صرفا به دنبال اطلاعات است؟
- آیا قصد خرید یا انجام یک تراکنش دارد؟
با توجه به پرسوجو و زمینه آن، موتور جستجو نتایج را بر اساس ارتباط و میزان تناسب با نیاز کاربر رتبهبندی میکند.
علاوهبر این، جستجوی معنایی میتواند با تنظیماتی مثل دستهبندی پرسوجو بهتر شود. برای نمونه، اگر کاربر به دنبال محصولات باشد، موتور جستجو میتواند نتایج را طوری مرتب کند که محصولات با بالاترین امتیاز کاربران در صدر لیست و محصولات کمامتیاز در رتبههای پایینتر نمایش داده شوند.
تفاوت جستجوی معنایی و جستجوی مبتنی بر کلیدواژه

تفاوت اصلی میان جستجوی کلیدواژهای (Keyword Search) و جستجوی معنایی (Semantic Search) در نوع تطبیق نتایج است.
- در جستجوی کلیدواژهای، نتایج بر اساس تطابق مستقیم کلمه با کلمه، کلمه با مترادف یا کلمه با واژههای مشابه برگردانده میشوند.
- در مقابل، جستجوی معنایی تلاش میکند نتایج را بر اساس معنای واژهها و نیت کاربر ارائه دهد. به همین دلیل، گاهی ممکن است هیچ تطابق مستقیم واژهای در نتایج وجود نداشته باشد، اما همچنان خروجی به نیاز کاربر نزدیک باشد.
موتورهای جستجوی کلیدواژهای برای بهبود نتایج معمولا از ابزارهایی مثل گسترش پرسوجو (Query Expansion) یا تسهیل پرسوجو (Relaxation) استفاده میکنند. این ابزارها شامل مواردی مانند بهکارگیری مترادفها، حذف برخی کلمات، تحمل خطاهای تایپی، Tokenization و Normalization هستند.
اما جستجوی معنایی با تکیه بر جستجوی برداری میتواند نتایجی را بازگرداند که نه صرفا بر اساس واژهها، بلکه بر اساس مفهوم و ارتباط معنایی با پرسوجو باشند.
برای درک بهتر، به عبارت «chocolate milk» توجه کنید.
یک موتور جستجوی معنایی تفاوت بین «chocolate milk» و «milk chocolate» را درک میکند. با اینکه واژهها یکی هستند، اما ترتیب آنها معنای کاملا متفاوتی ایجاد میکند:
- Milk chocolate به نوعی شکلات اشاره دارد.
- Chocolate milk به نوشیدنی شیرکاکائو اشاره میکند.
ما انسانها بهطور طبیعی این تفاوت را متوجه میشویم؛ جستجوی معنایی هم تلاش میکند همین درک را وارد تجربه جستجو کند؛ چیزی فراتر از محدودیتهای جستجوی سنتی مبتنی بر کلیدواژه.
چرا جستجوی معنایی مهم است؟
اهمیت جستجوی معنایی در این است که امکان یک سطح گستردهتر و عمیقتر از جستجو را فراهم میکند. از آنجا که این روش بر پایه جستجوی برداری عمل میکند، تجربه کاربر در جستجو بسیار مستقیمتر و شهودیتر میشود؛ به این معنا که نتایج نهتنها بر اساس واژههای واردشده، بلکه بر اساس زمینه و نیت پرسوجو ارائه خواهند شد.
الگوریتمهای جستجوی معنایی با گذشت زمان و بر اساس شاخصهای کلیدی عملکرد (KPIs) مانند نرخ تبدیل (Conversion Rate) و نرخ پرش (Bounce Rate) بهبود پیدا میکنند. همین ویژگی باعث میشود جستجوی معنایی به شکل مستمر یاد بگیرد و خروجیهای دقیقتر و مرتبطتری ارائه دهد. نتیجه نهایی این فرایند، افزایش رضایت کاربران است.
نمونههایی از جستجوی معنایی
همانطور که اشاره کردیم جستجوی معنایی نتایج را بر اساس زمینه جغرافیایی کاربر، تاریخچه جستجوهای قبلی و نیت کاربر ارائه میدهد.
یکی از کاربردهای مهم آن شخصیسازی (Personalization) است. در این روش، موتور جستجو با توجه به جستجوها و تعاملات گذشته کاربر، مرتبطترین نتایج را انتخاب و رتبهبندی میکند. علاوه بر این، جستجوی معنایی میتواند بر اساس رفتار سایر کاربران با نتایج مشابه، خروجیها را دوباره مرتب کند.
برای مثال، وقتی عبارت «رستورانها» را جستجو میکنید، موتور جستجو معمولا رستورانهای نزدیک به موقعیت مکانی شما را نمایش میدهد.
با درک بهتر از نیت کاربر، جستجوی معنایی میتواند به پرسوجوهایی مثل:
- «Creuset vs. Staub dutch ovens» نتایجی با تمرکز بر مقایسه محصولات ارائه دهد.
- «best Staub deals» یا «Creuset discounts» را بهعنوان نیت خرید تفسیر کند و نتایجی متناسب با تخفیفها و خرید محصولات نمایش دهد.
مثال دیگر، متن پیشبینیشونده (Predictive Text) است. زمانی که در نوار جستجو شروع به تایپ میکنید، موتور جستجو با کمک جستجوی معنایی پرسوجوی شما را کامل میکند یا عبارات مرتبط را پیشنهاد میدهد. این پیشنهادها بر اساس زمینه، جستجوهای رایج و تاریخچه کاربر ساخته میشوند.
مزایای جستجوی معنایی
جستجوی معنایی هم برای شرکتها و هم برای مشتریان مزایای زیادی دارد و تجربه جستجو را بهبود میدهد.
سادهتر برای مشتریان
بسیاری از مشتریان همیشه نام دقیق محصول یا اصطلاحات تخصصی (Jargon) را به خاطر نمیسپارند. جستجوی معنایی این امکان را میدهد که حتی با پرسوجوهای مبهم هم بتوان به نتایج دقیق رسید.
برای نمونه، کاربر میتواند بخشی از شعر یک ترانه را جستجو کند و به نام اصلی آن ترانه برسد. یا توضیحی کلی درباره یک محصول وارد کند و محصول دقیق را بیابد.
از آنجا که جستجوی معنایی درک خود را بر پایه نیت و زمینه انجام میدهد، تجربه کاربری در سمت مشتری بیشتر شبیه به تعامل انسانی خواهد بود.
مفاهیم قویتر از کلیدواژهها هستند
در جستجوی معنایی، به جای تطبیق ساده کلیدواژهها، مفاهیم با هم مقایسه میشوند. این باعث میشود نتایج دقیقتر باشند.
با استفاده از Embeddingها، هر کلمه بهعنوان یک مفهوم در فضای چندبعدی نمایش داده میشود. برای مثال، کلمه «car» فقط با «car» یا «cars» تطبیق داده نمیشود، بلکه با مفاهیم مرتبطی مثل «driver»، «insurance»، «tires»، «electric» و «hybrid» هم ارتباط دارد.
به این ترتیب، جستجوی معنایی که بر پایه جستجوی برداری است، فراتر از تطبیق کلیدواژهها عمل میکند و به معنای واقعی واژهها دست پیدا میکند.
مزایا برای کسبوکار
درک بهتر از نیت کاربر به موتور جستجو کمک میکند تا نیاز او را دقیقتر پاسخ دهد. این نیت میتواند:
- اطلاعاتی (Informational)
- تراکنشی (Transactional)
- جهتیابی یا ناوبری (Navigational)
- یا تجاری (Commercial) باشد
با تفسیر صحیح نیت، جستجوی معنایی میتواند فروش را افزایش دهد، رضایت مشتری را بالا ببرد و در نتیجه رابطهی کاربر با برند را تقویت کند. این موضوع در نهایت به نفع کسبوکار خواهد بود.
کاربردها و موارد استفاده از جستجوی معنایی
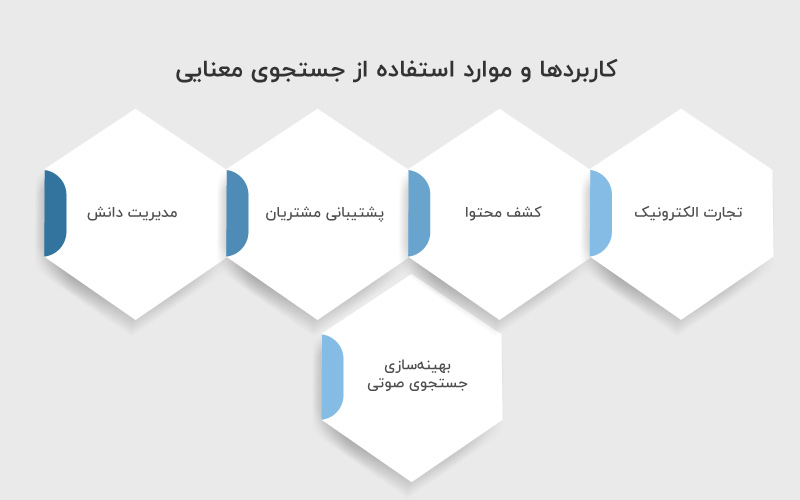
جستجوی معنایی در حوزههای مختلف کاربرد گستردهای دارد و به شکل قابل توجهی باعث افزایش دقت و ارتباط نتایج جستجو میشود:
- تجارت الکترونیک (E-commerce): فروشگاههای آنلاین از جستجوی معنایی برای بهبود کشف محصول استفاده میکنند. با درک نیت پشت پرسوجوی کاربر، پلتفرمهای فروشگاهی میتوانند محصولاتی را نمایش دهند که بیشترین تناسب را با نیاز مشتری دارند؛ حتی اگر پرسوجو مبهم باشد یا از مترادفهایی استفاده شود که در توضیحات محصول وجود ندارند.
- کشف محتوا (Content Discovery): پلتفرمهای محتوایی مانند سایتها یا اپلیکیشنهای ویدئویی و خبری، از جستجوی معنایی برای پیشنهاد مقالهها، ویدئوها و سایر محتواهایی استفاده میکنند که با علایق کاربر و تعاملات قبلی او همراستا هستند؛ حتی اگر همان واژهها در محتوای جستجو شده وجود نداشته باشند.
- پشتیبانی مشتریان (Customer Support): جستجوی معنایی دقت چتباتها و سیستمهای پشتیبانی را افزایش میدهد. این ابزار میتواند پرسشهای کاربران را دقیقتر بفهمد و پاسخهایی متناسب با زمینه و مشکل کاربر ارائه دهد.
- مدیریت دانش (Knowledge Management): در سازمانها، جستجوی معنایی به کارکنان کمک میکند تا اسناد و اطلاعات را سریعتر و دقیقتر پیدا کنند. این موضوع باعث کاهش زمان جستجو و افزایش بهرهوری میشود.
- بهینهسازی جستجوی صوتی (Voice Search Optimization): با رشد روزافزون جستجوهای صوتی، جستجوی معنایی نقشی کلیدی در تفسیر زبان طبیعی و مکالمهای دارد. این توانایی به دستیارهای صوتی کمک میکند تا پاسخهای دقیقتری به پرسشهای کاربران بدهند.
پیادهسازی عملی Semantic Search در پایتون با OpenAI و پایگاهداده برداری Pinecone
۱- ثبتنام در OpenAI و Pinecone
ابتدا در OpenAI حساب بسازید. سپس برای ساخت کلید API به این مسیر بروید: https://platform.openai.com/api-keys و یک API Key جدید ایجاد کنید.
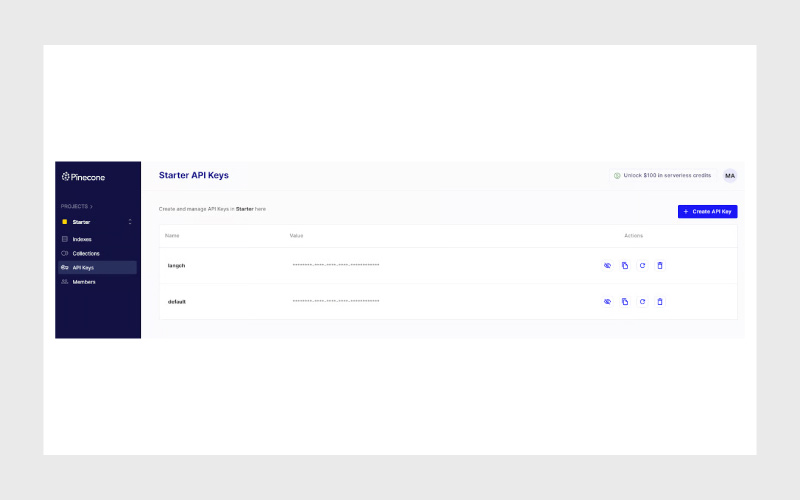
بعد از ورود به حساب Pinecone، به بخش API Keys بروید. در گوشهی سمت راست صفحه میتوانید روی دکمهی Create API Key کلیک کنید تا یک کلید جدید بسازید.
نکات عملی برای توسعهدهندهها:
|
برخلاف OpenAI، در Pinecone لازم نیست همان لحظه کلید را کپی کنید. در ستون Actions یک آیکون کپی وجود دارد که هر زمان بخواهید میتوانید کلید را دوباره کپی کنید. این ویژگی مدیریت کلیدها را سادهتر میکند.
بعد از دریافت کلیدهای API مربوط به OpenAI و Pinecone، آنها را در نوتبوک به متغیرها اختصاص دهید یا با استفاده از ماژول os در پایتون بهعنوان متغیر محیطی تنظیم کنید.
|
1 2 |
OPENAI_API_KEY = ‘…’ PINECONE_API_KEY = ‘…’ |
توضیح کد:
- کد دو متغیر به نامهای OPENAI_API_KEY و PINECONE_API_KEY تعریف میکند.
- به این متغیرها مقادیر رشتهای اختصاص داده شده که با ‘…’ نمایش داده شدهاند.
- این مقادیر در واقع جاینگهدار (Placeholder) برای کلیدهای واقعی OpenAI و Pinecone هستند.
- کلیدهای API برای احراز هویت هنگام اتصال به این سرویسها استفاده میشوند.
۲- نصب کتابخانههای پایتون
برای پیادهسازی این آموزش، باید کتابخانههای زیر را با استفاده از pip نصب کنید.
توجه داشته باشید که باید دقیقا از همین نسخهها استفاده کنید؛ در غیر این صورت کدی که در ادامه میآید اجرا نخواهد شد.
|
1 2 3 |
!pip install pinecone–client==3.0.0 !pip install pinecone–datasets==0.7.0 !pip install openai==0.28 |
توضیح کد:
این کد نسخههای مشخصی از سه پکیج پایتون با استفاده از pip (مدیر بستههای پایتون) را نصب میکند:
- خط اول نسخه 3.0.0 از پکیج pinecone-client را نصب میکند.
- خط دوم نسخه 0.7.0 از پکیج pinecone-datasets را نصب میکند.
- خط سوم نسخه 0.28 از پکیج openai را نصب میکند.
۳- دیتاسِت نمونه
کتابخانه pinecone-datasets شامل چندین مجموعهداده است که از قبل با مدل embedding-ada-002 متعلق به OpenAI امبد (Embed) شدهاند.
در این مثال، از دیتاست wikipedia-simple-text-embedding-ada-002-100K استفاده میکنیم.
از میان ۱۰۰,۰۰۰ سند موجود در این مجموعه، تنها ۵,۰۰۰ سند و امبدینگهای آنها را نمونهگیری خواهیم کرد.
|
1 2 3 4 5 6 7 8 9 |
import pinecone_datasets # load dataset from pinecone dataset = pinecone_datasets.load_dataset(‘wikipedia-simple-text-embedding-ada-002-100K’) # drop metadata column and renamed blob to metadata dataset.documents.drop([‘metadata’], axis=1, inplace=True) dataset.documents.rename(columns={‘blob’: ‘metadata’}, inplace=True) # sample 5k documents dataset.documents.drop(dataset.documents.index[5_000:], inplace=True) dataset.head() |
توضیح کد:
- خط اول کتابخانه pinecone_datasets را ایمپورت میکند که برای بارگذاری دیتاستها استفاده میشود.
- خط بعدی یک دیتاست مشخص از Pinecone با نام wikipedia-simple-text-embedding-ada-002-100K را بارگذاری میکند.
- ستون metadata از دیتاست با استفاده از متد drop حذف میشود.
- ستون blob با استفاده از متد rename به metadata تغییر نام داده میشود.
- دوباره از متد drop استفاده میشود تا دیتاست به ۵۰۰۰ سند اول محدود شود.
- در نهایت، متد head برای نمایش چند ردیف ابتدایی دیتاست فراخوانی میشود.

۴- ایجاد ایندکس در Pinecone
در Pinecone، یک ایندکس (Index) بالاترین واحد سازماندهی برای دادههای برداری محسوب میشود. ایندکس وظیفه ذخیرهسازی بردارها، پردازش پرسوجوها روی بردارهای ذخیرهشده و انجام عملیات مختلف روی دادههای برداری را بر عهده دارد.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from pinecone import Pinecone, ServerlessSpec # configure client pc = Pinecone(api_key=PINECONE_API_KEY) # configure serverless spec spec = ServerlessSpec(cloud=‘aws’, region=‘us-west-2’) # set index name index_name = ‘semantic-search-demo’ # we create a new index pc.create_index( index_name, dimension=1536, # dimensionality of text-embedding-ada-002 metric=‘cosine’, spec=spec ) |
توضیح کد:
- کد با ایمپورت کردن کلاسهای Pinecone و ServerlessSpec از کتابخانه pinecone شروع میشود.
- یک نمونه Pinecone به نام pc ایجاد میشود که از کلید API ذخیرهشده در متغیر PINECONE_API_KEY استفاده میکند.
- یک نمونه ServerlessSpec به نام spec ساخته میشود که در آن AWS بهعنوان ارائهدهنده سرویس ابری و us-west-2 بهعنوان منطقه (Region) مشخص شده است.
- یک رشته به نام index_name با مقدار ‘semantic-search-demo’ تعریف میشود تا بهعنوان نام ایندکس استفاده گردد.
- در نهایت، متد create_index از نمونه Pinecone فراخوانی میشود و یک ایندکس جدید با پارامترهای مشخصشده ایجاد میکند.
- خلاصه اینکه کد بالا نمونه Pinecone را مقداردهی اولیه میکند و ایندکسی با نام semantic-search-demo ایجاد میکند.
- در این مرحله، میتوانید این ایندکس را در رابط کاربری (UI) پلتفرم Pinecone نیز مشاهده کنید.
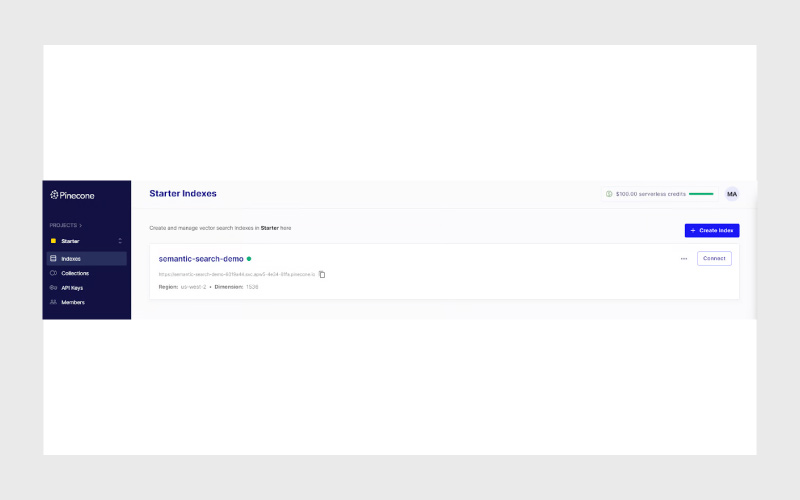
۵- وارد کردن دادهها (Insert Data)
از آنجا که دادههای ما از قبل شامل نمایشهای امبد شده (Embeddings) هستند، میتوانیم مرحله امبد کردن را رد کنیم و مستقیما دادهها را در ایندکس جدیدی که ساختهایم وارد کنیم.
برای مجموعهدادههایی که امبدینگ از پیش آماده ندارند، باید ابتدا داده خام را با استفاده از OpenAI API امبد کنید (برای این کار به مرحله ۶ مراجعه کنید).
|
1 2 3 |
index = pc.Index(index_name) for batch in dataset.iter_documents(batch_size=100): index.upsert(batch) |
توضیح کد:
- خط اول یک نمونه از کلاس Index از ماژول pc ایجاد میکند و نام ایندکس (index_name) را به آن میدهد.
- خط دوم یک حلقه for آغاز میکند که با استفاده از متد iter_documents روی شیء دیتاست پیمایش انجام میدهد.
- متد iter_documents با پارامتر 100 فراخوانی شده است که اندازه بچ (Batch Size) را مشخص میکند.
- داخل حلقه، متد upsert از شیء ایندکس فراخوانی میشود و بچ فعلی بهعنوان آرگومان به آن داده میشود.
- متد upsert اسناد موجود در ایندکس را بهروزرسانی میکند یا اگر وجود نداشته باشند، آنها را وارد (Insert) میکند.
- بعد از اجرای موفق کد، میتوانید دادهها را در رابط کاربری (UI) پلتفرم نیز مشاهده کنید.
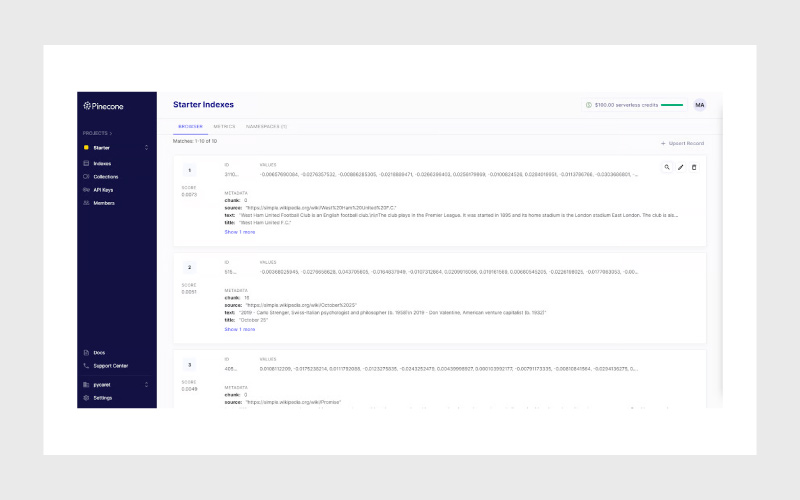

۶- امبد کردن دادههای جدید با استفاده از OpenAI API
هر داده یا پرسوجوی جدید باید با همان مدل امبد شود تا ابعاد برداری (Vector Dimensions) یکسان باقی بمانند. از آنجا که دیتاست ما با مدل text-embedding-ada-002 ساخته شده است، یک تابع تعریف میکنیم که با استفاده از OpenAI API پرسوجوهای جدید را با همین مدل امبد کند.
|
1 2 3 4 5 6 7 8 9 10 11 |
import openai openai.api_key = OPENAI_API_KEY def get_embedding(text_to_embed): # Embed a line of text response = openai.Embedding.create( model= “text-embedding-ada-002”, input=[text_to_embed] ) # Extract the AI output embedding as a list of floats embedding = response[‘data’][0][’embedding’] return embedding |
توضیح کد:
- کد با ایمپورت کردن کتابخانه openai شروع میشود.
- سپس کلید API مربوط به سرویس OpenAI در متغیر OPENAI_API_KEY تنظیم میشود.
- تابعی به نام get_embedding تعریف میشود که یک رشته به نام text_to_embed را بهعنوان ورودی دریافت میکند.
- داخل تابع، یک فراخوانی به OpenAI API انجام میشود تا برای متن ورودی یک Embedding ایجاد کند.
- مدلی که برای امبدینگ استفاده میشود text-embedding-ada-002 است.
- پاسخ بازگشتی از API در متغیری به نام response ذخیره میشود.
- داده امبدینگ (که یک لیست از مقادیر اعشاری است) از پاسخ استخراج شده و در متغیر embedding قرار میگیرد.
- در نهایت، تابع این مقدار embedding را برمیگرداند.
۷- جستجوی پایگاه داده برداری با دادههای جدید
|
1 2 3 4 5 |
query = “What are some easter related events in Western Christianity?” result = get_embedding(query) print(len(result)) print(result) |
توضیح کد:
- یک رشته به نام query تعریف میشود که شامل یک پرسش درباره رویدادهای مرتبط با عید پاک در مسیحیت غربی است.
- تابع get_embedding() با مقدار query بهعنوان آرگومان فراخوانی میشود تا متن به یک بردار (Vector) تبدیل شود.
- نتیجه این تابع در متغیری به نام result ذخیره میشود.
- طول result چاپ میشود که نشاندهنده ابعاد بردار امبدینگ است.
- در نهایت، خود نتیجه (بردار امبدینگ) نیز چاپ میشود.
خروجی:
1536
[0.014745471067726612, -0.03282099589705467, -0.006603493355214596, -0.0025058642495423555,………]
طول متغیر result برابر با ۱۵۳۶ است که دقیقا با بعد (Dimension) مشخصشده هنگام ایجاد ایندکس همخوانی دارد. ارسال یک پرسوجوی جستجو (Search Query) هم بسیار ساده و سرراست است:
|
1 2 |
query_result = index.query(vector=result, top_k=3, include_metadata=True) print(query_result) |
خروجی:
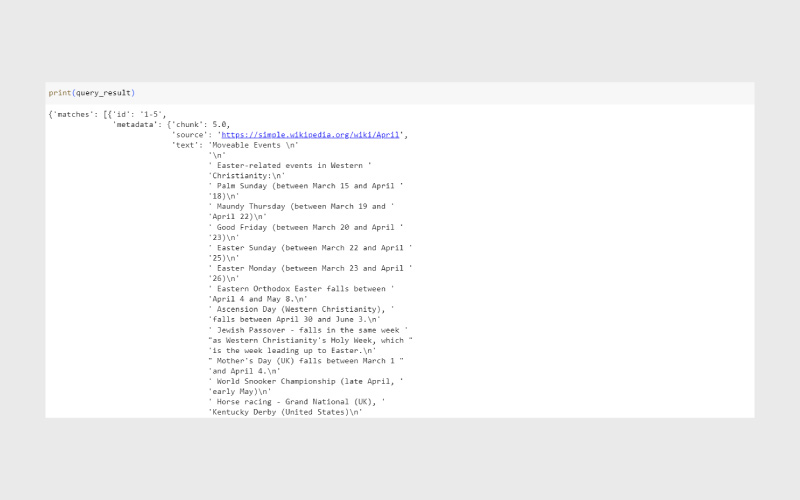
متغیر query_result یک دیکشنری تولید میکند که شامل لیستی از ۳ نتیجه برتر (Top 3 Matches) مرتبط با پرسوجوی کاربر است.
این نتایج برتر (Top N Matches) میتوانند در وظایف بعدی (Downstream Tasks) استفاده شوند؛ برای مثال:
- ارائه کانتکست برای پرامپتها در سناریوهای Retrieval Augmented Generation (RAG)،
- یا بهکارگیری در ساخت چتباتها (Chatbots).

واژهنامه اصطلاحات مرتبط با جستجوی معنایی
- Embedding (امبدینگ):
نمایش برداری از معنای کلمات است. هر واژه هنگام پردازش برای جستجو به شکل یک بردار عددی در فضای چندبعدی نمایش داده میشود.
- Inverted Index (نمایه معکوس):
یک پایگاه داده است که به موتورهای جستجو امکان بازیابی اطلاعات را میدهد. این ساختار واژهها یا اعداد را به موقعیتشان در یک پایگاه داده یا مجموعهای از اسناد متصل میکند.
- نمایه در سطح سند واژهها را به یک یا چند سند متصل میکند.
- نمایه در سطح واژه محل دقیق واژهها را در داخل یک سند مشخص میکند.
- Natural Language Processing (پردازش زبان طبیعی – NLP):
پردازش زبان طبیعی، زیرشاخهای از علوم کامپیوتر، زبانشناسی و هوش مصنوعی است که به کامپیوترها امکان میدهد زبان انسانی را درک و پردازش کنند.
- Normalization (نرمالسازی):
فرایند تبدیل مقادیر دادههای عددی به یک مقیاس مشترک برای تسهیل پردازش و مقایسه.
- Semantics (معناشناسی):
شاخهای از زبانشناسی و منطق است که با «معنا» سروکار دارد. در علوم کامپیوتر و فلسفه نیز بهعنوان یک زیرشاخه مطرح است.
- Tokenization (توکنیزیشن):
در NLP، فرایند شکستن جملهها به توکنها یا واحدهای کوچکتر اطلاعاتی است. این کار باعث میشود پردازش کامپیوتری سریعتر و دقیقتر انجام شود.
نتیجهگیری
جستجوی معنایی گامی مهم در تکامل موتورهای جستجو و تجربهی کاربری است. برخلاف جستجوی سنتی مبتنی بر کلیدواژه، این فناوری با استفاده از یادگیری ماشین، هوش مصنوعی و جستجوی برداری میتواند معنا و نیت واقعی کاربر را درک کند و نتایجی مرتبطتر ارائه دهد.
مزایای آن تنها به بهبود دقت نتایج ختم نمیشود؛ بلکه باعث افزایش رضایت کاربران، بهبود نرخ تبدیل در کسبوکارها و توسعه ابزارهایی هوشمندتر مانند چتباتها و سیستمهای پیشنهاددهنده میشود.
پیادهسازی آن با ابزارهایی مانند OpenAI و Pinecone نیز ساده و قابل دسترس است و به توسعهدهندگان این امکان را میدهد که بدون نیاز به زیرساختهای پیچیده، موتورهای جستجوی معنایی را در اپلیکیشنها و سرویسهای خود به کار بگیرند. آینده جستجو بدون شک در گرو Semantic Search خواهد بود.
منابع
سوالات متداول
در جستجوی کلیدواژهای تطبیق بر اساس کلمات یا مترادفها انجام میشود اما در جستجوی معنایی معنا و نیت کاربر محور اصلی است؛ حتی اگر کلمات دقیق در محتوا وجود نداشته باشند.
Embedding نمایش عددی کلمات و جملات است که امکان مقایسه معنایی و تشخیص شباهت بین دادهها را فراهم میکند.
خیر. میتوان از مدلهای آماده مانند text-embedding-ada-002 در OpenAI استفاده کرد که بهطور گسترده آموزش دیدهاند.
Pinecone یک پایگاهداده برداری است که امکان ذخیره، جستجو و مدیریت Embeddingها را با سرعت و مقیاس بالا فراهم میکند.
این فناوری با درک بهتر از نیت کاربر باعث بهبود تجربه مشتری، افزایش فروش، کاهش نرخ پرش و تقویت رابطه مشتری با برند میشود.

دیدگاهتان را بنویسید