
یادگیری تقویتی به آموزش مدلهای یادگیری ماشین برای تصمیمگیری بهتر در یک محیط پیچیده اشاره دارد. این روش از تکنیکهای یادگیری بر اساس آزمونوخطا با تکرارهای متوالی (Iteration) استفاده میکند که در آن هوش مصنوعی بر اساس اقداماتی که انجام میدهد، پاداش یا جریمه دریافت میکند. این روند تا زمانی که توسعهدهنده به نتیجه مورد انتظار خود برسد، ادامه پیدا میکند. در این مقاله از بلاگ آسا به طور کامل در مورد یادگیری تقویتی صحبت میکنیم و این موضوع را به زبان ساده توضیح میدهیم.
یادگیری تقویتی چیست؟
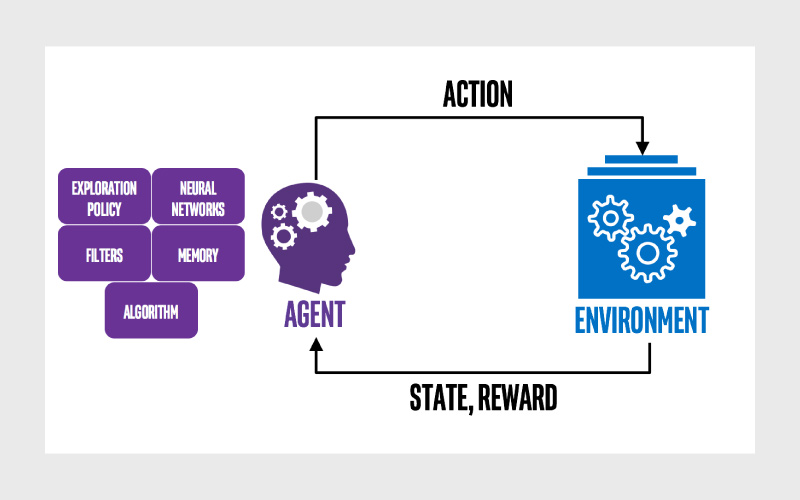
یادگیری تقویتی (Reinforcement Learning) نوعی از آموزش ماشین در ML است که به یک سیستم هوشمند کمک میکند تا اقدامات جدید را تست کند و در صورت شکست، مسیر را تغییر دهد تا در نهایت به عملکرد مورد نظر و صحیح برسد. در این روش برنامههای کامپیوتری از طریق آزمونوخطا، بهترین اقدامات را در یک زمینه خاص انجام میدهند و عملکرد خود را بهینه میکنند.
کامپیوتر بر اساس اقدامات خود بازخورد مثبت یا منفی دریافت میکند و به تدریج یاد میگیرد که چگونه یک کار خاص را کامل کند؛ به عبارتی، یادگیری تقویتی در مورد یادگیری انجام یک رفتار بهینه در یک محیط نرمافزاری برای به دست آوردن حداکثر پاداش است. همانطور که انسانها یاد میگیرند که مهارتها و شخصیت خود را توسعه دهند، ماشینها و نرمافزارها هم از الگوریتمهای یادگیری تقویتی برای تصمیمگیری بهتر استفاده میکنند.
تاریخچه یادگیری تقویتی
یادگیری تقویتی بر اساس روانشناسی رفتاری تعریف شده است که یکی از اصول آن، استفاده از پاداش و تنبیه برای تربیت و ایجاد عادت است. این روش به عنوان یک حوزه از هوش مصنوعی در اواسط قرن بیستم میلادی شکل گرفت. فعالیتهای ریچارد بلمن (Richard Bellman) روی برنامهنویسی پویا در دهه ۵۰ میلادی، پایه ریاضیات یادگیری تقویتی را ایجاد کرد.
دهه ۸۰ میلادی دوره مهمی برای یادگیری تقویتی بود. اندرو بارتو (Andrew Barto) و ریچارد ساتون (Richard Sutton) توانستند مفاهیم یادگیری تفاوت زمانی (Temporal difference learning) و یادگیری Q را ایجاد کنند و این مفاهیم پایه و اساس توسعه یادگیری تقویتی را شکل دادند. در طول دهههای بعد هم شاهد پیشرفته در این حوزه بودیم، به طوری که امروز یادگیری تقویتی به عنوان خط مقدم تحقیقات در یادگیری ماشین شناخته میشود.
فرایند یادگیری تقویتی چگونه کار میکند؟

یادگیری تقویتی (RL) به کمک پاداش و تنبیه، رفتار درست یا غلط ماشین را مشخص میکند. مهندسان AI پاداشهایی را تعریف میکنند که با اهداف بلندمدت همسو باشند، به طوری که ماشین یاد بگیرد اقداماتی را انجام دهد که مطلوب و بهینه هستند. یادگیری تقویتی یک چرخه تکراری از کاوش، بازخورد و بهبود است. در ادامه یک مثال از نحوه کار یادگیری تقویتی را آورده شده است:
- تعریف مشکل: برای مثال، ما میخواهیم یک جاروبرقی رباتیک را آموزش دهیم تا به تنهایی یک اتاق را تمیز کند.
- تنظیم محیط: ما یک محیط شبیهسازیشده ایجاد میکنیم که نشاندهنده اتاقی است که جاروبرقی رباتیک در آن کار میکند (با چیدمان مبلمان و سایر وسایل).
- ایجاد عامل: جاروبرقی روباتیک یادگیرنده یا عامل است. ما باید این دستگاه هوشمند را به فناوری مناسب برای رصد محیط مجهز کنیم.
- شروع یادگیری: در ابتدا، جاروبرقی رباتیک اتاق را به طور تصادفی بررسی میکند و ممکن است با مبلمان یا موانع برخورد کند و بخشهایی از اتاق را بیدلیل تمیز کند. سپس اطلاعاتی در مورد اتاق و نحوه عملکرد خود به دست میآورد.
- دریافت بازخورد: پس از هر اقدام، جاروبرقی یک پاداش مثبت یا منفی دریافت میکند که در روند تصمیمگیری آن در آینده تاثیر میگذارد. بهعنوانمثال، اگر با موفقیت از کنار مبلمان عبور کند، یک پاداش مثبت میگیرد. اگر هم یک نقطه خاص را نادیده بگیرید (گوشه اتاقها که معمولا کثیف است)، امتیاز منفی میگیرد.
- بهروزرسانی خطمشی: جاروبرقی رباتیک بر اساس پاداشهایی که دریافت کرده است، تصمیمگیری خود را براساس خطمشیهای جدید به روز میکند تا بیشتر اقدامات مثبت را انجام دهد.
- انجام اصلاحات: جاروبرقی روباتیک به کاوش در اتاق، انجام اقدامات، دریافت بازخورد و بهروزرسانی خطمشی ادامه میدهد. با هر بار تکرار، دانش خود را در مورد اینکه کدام اقدامات راندمان تمیز کردن را به حداکثر میرسانند و از موانع اجتناب میکنند، بهبود میبخشد. دستگاه به تدریج با چیدمان اتاقهای مختلف هم سازگار میشود.
- استقرار اهداف: هنگامی که جاروبرقی رباتیک یک خطمشی موثر را یاد گرفت، از آن برای تمیز کردن اتاق بدون نیاز به نظارت استفاده میکند. به این ترتیب، محصول پس از چندبار تست، وارد بازار میشود تا به دست مصرفکننده برسد.
تقویت مثبت و منفی در یادگیری تقویتی
تقویت مثبت فرکانس یک رفتار را افزایش میدهد، درحالیکه تقویت منفی فرکانس را کم میکند. بهطورکلی، تقویت مثبت رایجترین نوع تقویتی است که در یادگیری تقویتی استفاده میشود، زیرا به عامل کمک میکند تا عملکرد خود را به بهینهترین حالت برساند. این نوع تقویت باعث میشود تا عامل بتواند تغییرات مثبت را یاد بگیرد و آنها را انجام دهد. این موضوع با تقویت مثبت در انسان مشابه است. اگر فرزند کوچک شما یک رفتار خوب را انجام میدهد، با پاداش دادن به او کاری میکنید که آن رفتار درست را بارها تکرار کند.
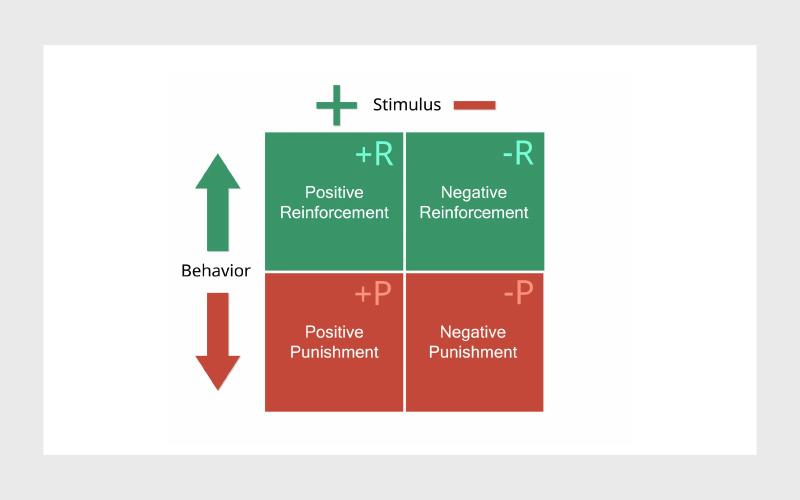
درحالیکه تقویت منفی هم احتمال وقوع یک رفتار بد را افزایش میدهد، برای حفظ حداقل استاندارد عملکردی ضروری است. تقویت منفی در یادگیری تقویتی میتواند یک عامل را از انجام اقدامات نامطلوب دور نگه دارد. بهاینترتیب، عامل میتواند رفتار خود را به مرور زمان تغییر دهید. توجه داشته باشید تقویت مثبت و منفی در یادگیری ماشین اغلب به صورت امتیاز هستند. برای مثال، اگر عامل کار درستی انجام دهد، ۵ امتیاز میگیرد و اگر کار نادرستی انجام دهد، ۵ امتیاز از دست میدهد. عامل به مرور یاد میگیرد که باید امتیاز بیشتری جمع کند تا به نتیجه مطلوب برسد.
انواع یادگیری تقویتی
دو نوع اصلی یادگیری تقویتی شامل یادگیری مبتنی بر ارزش و مبتنی بر خطمشی هستند. در ادامه به این دو مورد اشاره میکنیم:
- الگوریتمهای یادگیری تقویتی مبتنی بر ارزش براساس یک سیستم ارزشگذاری توسعه پیدا کردهاند؛ به این معنا که عامل اقدامی را انتخاب میکند که ارزش بالایی داشته باشد تا امتیاز بیشتری بگیرد.
- الگوریتمهای یادگیری تقویتی مبتنی بر خطمشی براساس دستورالعملها توسعه پیدا کردهاند؛ به این معنی که عامل اقدامی را انتخاب میکند که توسط خطمشی تعیینشده است.
عناصر یادگیری تقویتی
پارامترهای اصلی در یادگیری ماشین شامل یک عامل و محیطی است که عامل در آن کار میکند. برای مثال، عامل میتواند جاروبرقی رباتیک و محیط خانه باشد. جدا از این دو مؤلفه، چند عنصر دیگر وجود دارند که در یادگیری تقویتی مورد نیاز هستند. این عناصر عبارتند از:

- خطمشیها: از خطمشیها برای تعریف رفتار عامل استفاده میشود. این موضوع شامل اجرای دستورالعملهایی است که محیط را به عامل نشان میدهد و واکنش عامل به آن محیط را تعیین میکند.
- پاداشها: پاداش بخش مهمی از فرایند تقویت است. جوایز به عامل کمک میکنند تا به نتایج مطلوب برسد. این پاداشها مبتنی بر امتیاز هستند و عامل به مرور یاد میگیرد که امتیاز بیشتری دریافت کند.
- ارزشها: ارزش نشاندهنده تعداد کل پاداشهایی است که عامل میتواند در آینده برای انجام اقدامات خود در محیط انتظار داشته باشد. اگر عامل به ارزش مورد نظر دست یابد، کار خود را به خوبی انجام داده است.
- مدل محیطی: این مفهوم یک محیط شبیهسازیشده با محیط واقعی است. هدف این است که تاثیر یک محیط بر پاسخ یک عامل مشخص شود. یک مدل محیطی باید با دقت بالایی ایجاد شود.
مزایای یادگیری تقویتی
یادگیری تقویتی در هوش مصنوعی مزایایی دارد که در ادامه به آنها اشاره میکنیم:
- پیچیدگی: از یادگیری تقویتی میتوانیم برای حل مسائل بسیار پیچیده استفاده کنیم. به عنوان مثال، یک برنامه هوش مصنوعی به نام AlphaGo اولین برنامه کامپیوتری بود که یک فرد قهرمان را در بازی چینی باستانی به نام گو (Go) شکست داد و قویترین بازیکن تاریخ این بازی شد.
- سازگاری: یادگیری تقویتی برای محیطهایی مناسب است که در آن نتایج اقدامات به طور دقیق قابل پیشبینی نیستند. این موضوع برای دنیای واقعی که در آن ممکن است بعضی مسائل در طول زمان تغییر کنند مفید است. برای مثال، هوش مصنوعی میتواند از یادگیری تقویتی برای پیشبینی آبوهوا استفاده شود.
- تصمیمگیری مستقل: سیستمهای هوشمند میتوانند به تنهایی و بدون دخالت انسان تصمیمگیری کنند. این سیستمها این امکان را دارند از تجربیات خود بیاموزند و رفتار خود را برای رسیدن به اهداف خاص بهینه کنند. این موضوع میتواند به صرفهجویی در زمان و هزینهها کمک کند.
چالشهای یادگیری تقویتی

با وجود مزایای عملیاتی، این روش چالشهایی هم دارد که اجرای آن را دچار مشکل میکنند:
- آمادهسازی محیط: یکی از چالشهای اصلی در یادگیری تقویتی، آمادهسازی محیط است. برای مدلهای سادهتر، ایجاد محیط میتواند یک فرایند ساده باشد؛ اما این موضوع با مدلهای پیچیده چالشبرانگیزتر خواهد بود، زیرا انتقال مدل از محیط آموزشی به دنیای واقعی دشوار است.
- نیازمند حجم بالای داده: از آنجایی که این روش برای حل مسائل پیچیده استفاده میشود، به طور معمول به حجم عظیمی از دادهها نیاز دارد. با توجه به اینکه محیطها مدام تغییر میکنند، برنامهنویس چندین سناریو را مجسم و کدنویسی میکند. این موضوع باعث افزایش حجم اطلاعات میشود.
- نیاز به سرمایه زیاد: پروژههای پیچیده مربوط به یادگیری تقویتی میتوانند هزینه زیادی به همراه داشته باشند. برای مثال، آزمایش وسایل نقلیه خودران اغلب پرهزینه است، زیرا هر بار نیاز به تست کردن خودرو در یک محیط شبیهسازیشده است؛ بنابراین بار مالی زیادی به همراه دارد.
کاربردهای یادگیری تقویتی
یادگیری تقویتی روشی است که به طور گسترده در صنایع مختلف از جمله ساخت لوازمخانگی هوشمند، گجتهای فناوری، خودروسازی و غیره مورد استفاده قرار میگیرد. در ادامه به دو کاربرد اصلی این روش اشاره میکنیم:
صنعت رباتیک

در محیطهای ساختاریافته مانند خط مونتاژ یک کارخانه تولید خودرو، رباتهایی با رفتارهای از پیش برنامهریزیشده میتوانند با اجرای تسکهای تکراری در خط مونتاژ، نقش موثری در روند کار ایفا کنند. این نوع یادگیری میتواند یک چارچوب و مجموعهای از خطمشیها را برای رباتیک فراهم کند.
خودروی خودران
بیشتر خودروها، کامیونها، پهپادها و کشتیهای خودران از الگوریتمهای یادگیری تقویتی در سیستمهای رانندگی خود استفاده میکنند. این نوع یادگیری وظایفی مانند انتخاب بهترین مسیر و پیشبینی حرکت دیگر خودروها را انجام میدهد. این سیستم تضمین میکند که وسیله نقلیه از سریعترین و ایمنترین مسیر برای رسیدن به مقصد بهره میبرد.
الگوریتمهای یادگیری تقویتی
الگوریتمهای مختلفی برای یادگیری تقویتی وجود دارند که در ادامه به آنها اشاره میکنیم:

- یادگیری کیو (Q-Learning): یک الگوریتم بر پایه یادگیری تقویتی است که ارزش انجام یک اقدام خاص را در یک حالت مشخص، تخمین میزند. این روش مقادیر به دست آمده را به طور پیوسته به روز میکند تا به سمت بهینهترین نتایج برود.
- یادگیری عمیق کیو (Deep Q Network): این روش، یادگیری کیو را با شبکههای عصبی عمیق ترکیب میکند و تا برای مسائل پیچیدهتر مناسب شود.
- روشهای گرادیان خطمشی (Policy gradient methods): این روشها به طور مستقیم خطمشی را با پارامترهایی که احتمال دریافت پاداشهای بالاتر را دارند، تطبیق میدهند تا درصد موفقیت افزایش پیدا کند.
تفاوت بین یادگیری تقویتی، یادگیری عمیق و یادگیری تحت نظارت
اگرچه این اصطلاحات تا حدی با هم همپوشانی دارند، اما تفاوتهای واضحی بین سه نوع یادگیری وجود دارد. برای اینکه بتوانید بهطور صحیح از این الگوریتمها و روشها استفاده کنید، باید حتما تفاوت آنها را بدانید. در ادامه به تفاوتهای این روشها اشاره میکنیم:
یادگیری عمیق
یادگیری عمیق (Deep learning) شامل چندین لایه از شبکههای عصبی است که به طور ویژه برای انجام وظایف پیچیده طراحی شدهاند. پایه و اساس ساخت این مدل مغز انسان است، اما بسیار سادهتر از آن کار میکند. شبکههای عصبی ویژگیهای خاصی را یاد میگیرند. هر لایه از نتیجه لایه قبلی به عنوان ورودی استفاده میکند. همچنین کل شبکه به عنوان یک سیستم واحد عمل میکند.
یادگیری تحت نظارت
یادگیری نظارتشده (Supervised Learning) یکی از انواع مهم یادگیری ماشین است که در آن مدلها از دادههای برچسبگذاریشده برای یادگیری و پیشبینی استفاده میکنند. در این روش، مجموعهای از ورودیها به همراه خروجیهای مورد انتظار (برچسبها) به مدل ارائه میشود و مدل تلاش میکند روابط میان آنها را کشف کند. پس از آموزش، مدل میتواند برای دادههای جدید، خروجی مناسب را پیشبینی کند.
کلام آخر
یادگیری تقویتی به توسعهدهندگان کمک میکند تا سیستمهای هوشمندی ایجاد کنند که قادر به یادگیری و سازگاری با محیطهای پویا هستند. این روش ابزاری قدرتمند برای حل طیف وسیعی از مسائل در صنایع مختلف است. بااینحال، چالشهایی نیز به همراه دارد که باید به خوبی مورد بررسی قرار بگیرند. هدف نهایی این است که یادگیری تقویتی بتواند عملکرد سیستمهای مبتنی بر یادگیری ماشین و هوش مصنوعی را ارتقا دهد و دقت کار آنها را بالا ببرد.
منابع:
in.indeed.com | www.scribbr.com | parthsojitra.medium.com | www.unite.ai

دیدگاهتان را بنویسید