
تبدیل متن به صدا (Text-to-Speech یا TTS) یکی از کاربردیترین شاخههای پردازش صوت با هوش مصنوعی است که به سیستمها امکان میدهد متن نوشتاری را به گفتار طبیعی و قابل فهم تبدیل کنند. امروزه این فناوری در دستیارهای صوتی، کتابهای صوتی، سیستمهای پاسخگویی خودکار، آموزش آنلاین، ابزارهای دسترسیپذیری برای نابینایان و حتی تولید محتوای شبکههای اجتماعی استفاده میشود. پیشرفت مدلهای یادگیری عمیق باعث شده کیفیت صدای تولیدشده به شکل قابل توجهی طبیعیتر، احساسیتر و انسانیتر شود؛ بهطوری که در بسیاری از موارد تشخیص صدای مصنوعی از صدای واقعی دشوار شده است.
در این مقاله قرار است فناوری تبدیل متن به صدا با هوش مصنوعی را بررسی کنیم. ابتدا مفهوم و نحوه عملکرد مدلهای Text-to-Speech را توضیح میدهیم، سپس سراغ پیادهسازی عملی با APIهای مدرن مانند OpenAI و Google Cloud میرویم. در ادامه مدلهای مطرح سال ۲۰۲۶ را مقایسه میکنیم، تنظیمات حرفهای مثل انتخاب صدا، کنترل لحن و کیفیت را بررسی میکنیم و در نهایت کاربردهای واقعی و نکات فنی مهم برای توسعهدهندگان را مرور خواهیم کرد. این راهنما طوری نوشته شده که هم برای افراد مبتدی قابل فهم باشد و هم برای توسعهدهندگان حرفهای قابل استفاده.
Text-to-Speech چگونه کار میکند؟
تبدیل متن به گفتار یک فرایند چندمرحلهای است که در آن متن خام به سیگنال صوتی طبیعی تبدیل میشود. سیستمهای مدرن تبدیل متن به صدا مبتنی بر شبکههای عصبی عمیق هستند و نسبت به نسلهای قدیمی، صدایی بسیار طبیعیتر، روانتر و نزدیکتر به گفتار انسانی تولید میکنند. برای درک بهتر عملکرد این سیستمها، لازم است مراحل اصلی این فرآیند را بررسی کنیم.
مراحل اصلی تبدیل متن به صدا
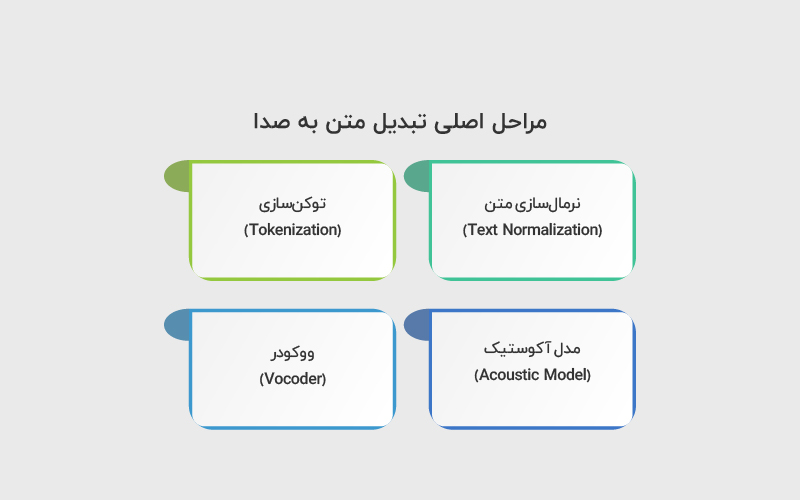
فرایند تبدیل متن به صوت معمولا شامل مراحل زیر است:
- نرمالسازی متن (Text Normalization): در این مرحله، متن ورودی برای پردازش آماده میشود. اعداد به کلمات تبدیل میشوند، مخففها گسترش پیدا میکنند و علائم نگارشی اصلاح میشوند تا مدل بتواند لحن و مکثها را بهتر درک کند. برای مثال عدد 2026 بهصورت نوشتاری کامل تبدیل میشود.
- توکنسازی (Tokenization): متن به واحدهای کوچکتر مانند کلمه، زیرکلمه یا کاراکتر تقسیم میشود. بسیاری از مدلهای مدرن مبتنی بر Transformer از روشهای زیرکلمهای استفاده میکنند تا بتوانند واژگان جدید یا ترکیبی را بهتر مدیریت کنند.
- مدل آکوستیک (Acoustic Model): در این مرحله، متن پردازششده به یک نمایش صوتی میانی (معمولا Mel-Spectrogram) تبدیل میشود. مدل یاد میگیرد هر بخش از متن باید چه الگوی فرکانسی و زمانی داشته باشد. این بخش معمولا توسط شبکههای عصبی عمیق پیادهسازی میشود.
- ووکودر (Vocoder): در مرحله نهایی، نمایش طیفی تولیدشده به موج صوتی واقعی (Waveform) تبدیل میشود. کیفیت نهایی صدا تا حد زیادی به عملکرد ووکودر بستگی دارد. ووکودرهای عصبی مدرن توانستهاند کیفیت صدا را به شکل قابل توجهی افزایش دهند.
تفاوت سیستمهای سنتی و عصبی در تبدیل متن به صدا
سیستمهای قدیمی تبدیل متن به گفتار معمولا مبتنی بر کنار هم قرار دادن قطعات ضبطشده صدا بودند. این روش اگرچه قابل استفاده بود، اما خروجی آن حالتی رباتیک و غیرطبیعی داشت و امکان کنترل لحن یا احساس در آن محدود بود.
در مقابل، سیستمهای عصبی (Neural TTS) از مدلهای یادگیری عمیق استفاده میکنند و قادرند گفتاری طبیعیتر تولید کنند. این مدلها میتوانند سرعت، لحن، تاکید و حتی احساسات مختلف را شبیهسازی کنند و تجربه شنیداری بسیار بهتری ارائه دهند.
تحول کیفیت صدا با مدلهای عصبی
پیشرفت بزرگ در حوزه تبدیل متن به صوت با معرفی مدلهای مولد عصبی رخ داد. این مدلها به جای چسباندن قطعات صوتی آماده، موج صدا را به صورت داده خام تولید میکنند. همین رویکرد باعث شد کیفیت خروجی به شکل چشمگیری افزایش یابد و صداها به گفتار انسانی بسیار نزدیک شوند.
امروزه بسیاری از سرویسهای ابری تبدیل متن به صدا از معماریهای پیشرفته مبتنی بر شبکههای عصبی و Transformer استفاده میکنند که علاوه بر کیفیت بالا، قابلیت مقیاسپذیری و پردازش سریع را نیز فراهم میکنند.
اجزای معماری مدلهای مدرن TTS
مدلهای پیشرفته تبدیل متن به گفتار معمولا از اجزای زیر تشکیل میشوند:
- بخش رمزگذار (Encoder) برای پردازش متن
- مکانیزم توجه (Attention) برای همتراز کردن متن و صدا
- بخش رمزگشا (Decoder) برای تولید ویژگیهای صوتی
- ووکودر عصبی برای تولید موج نهایی
استفاده از معماریهای مبتنی بر Transformer باعث شده مدلها بتوانند وابستگیهای طولانی در جمله را بهتر درک کنند و ریتم و آهنگ طبیعیتری تولید کنند.
تعادل بین کیفیت و سرعت
در طراحی سیستمهای تبدیل متن به صدا، همیشه باید بین دو عامل مهم تعادل برقرار شود:
- کیفیت و طبیعی بودن صدا
- میزان تاخیر در تولید صوت
در کاربردهای بلادرنگ مانند دستیارهای صوتی، سرعت تولید اهمیت بالایی دارد. در مقابل، در تولید کتابهای صوتی یا دوبله، کیفیت و طبیعی بودن صدا اولویت بیشتری دارد.
معرفی مدلهای مطرح تبدیل متن به گفتار (TTS) در سال 2026
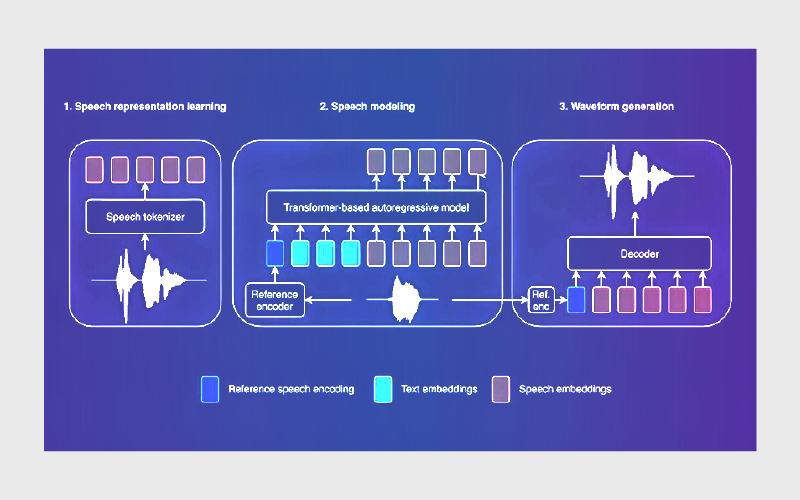
در اکوسیستم «تبدیل متن به گفتار»، مدلها را میتوان در سه دسته اصلی بررسی کرد: مدلهای ارائهشده توسط پلتفرمهای هوش مصنوعی عمومی، مدلهای ابری سازمانی و مدلهای تخصصی بازار که تمرکز آنها بر کیفیت صدای طبیعی و شخصیسازی است. در ادامه، مهمترین گزینههای مطرح بر اساس مستندات رسمی و منابع تحلیلی معرفی میشوند.
مدلهای OpenAI
در مستندات رسمی OpenAI، قابلیت تبدیل متن به صدا از طریق مدلهای خانواده GPT-4o ارائه شده است.
- gpt-4o-mini-tts: مدلی سبک و بهینه برای تولید گفتار طبیعی با تاخیر کم که از طریق API قابل استفاده است. این مدل برای کاربردهایی مانند تولید صدای اپلیکیشنها، دستیارهای صوتی و خوانش متون مناسب است.
- gpt-4o-realtime-preview: مدلی مناسب برای سناریوهای Real-Time که در تعاملهای زنده (مانند رابطهای صوتی بلادرنگ) کاربرد دارد و میتواند همزمان ورودی متنی دریافت کرده و خروجی صوتی تولید کند.
ویژگی کلیدی مدلهای OpenAI:
- کیفیت صدای طبیعی
- پشتیبانی از استریم صوت
- امکان تنظیم فرمت خروجی (مانند mp3 یا wav)
- یکپارچگی آسان با سایر قابلیتهای چندوجهی (Multimodal)
مدلهای Google Cloud
سرویس تبدیل متن به گفتار در Google Cloud چندین خانواده صوتی ارائه میدهد که از نظر کیفیت و معماری متفاوت هستند:
- WaveNet Voices: مبتنی بر معماری WaveNet با کیفیت صدای بسیار طبیعی و مناسب پروژههای حرفهای.
- Neural2 Voices: نسل جدید صداهای عصبی با طبیعیتر بودن لحن و ریتم گفتار نسبت به نسخههای قبلی.
- Standard Voices: نسخههای کلاسیک با هزینه کمتر و کیفیت مناسب برای کاربردهای عمومی.
مزیت اصلی Google Cloud:
- تنوع بالای زبانها و گویشها
- تنظیمات دقیق Pitch، Speaking Rate و Voice Selection
- مناسب برای کاربردهای سازمانی در مقیاس بالا
مدلهای مطرح بازار
بر اساس گزارشهای تحلیلی وبسایت Artificial Analysis، چند ارائهدهنده تخصصی TTS در سال 2026 عملکرد برجستهای دارند:
- ElevenLabs: شناختهشده برای صدای بسیار طبیعی، کلونسازی صدا و کاربردهای تولید محتوای حرفهای.
- PlayHT: تمرکز بر تولید محتوای صوتی برای پادکست و رسانههای دیجیتال.
- Amazon Polly: سرویس تبدیل متن به گفتار ارائهشده توسط AWS با پشتیبانی گسترده از زبانها.
- Microsoft Azure Text to Speech: بخشی از سرویس Azure AI Speech با قابلیتهای سازمانی و امنیت بالا.
این سرویسها معمولا امکاناتی مانند:
- Voice Cloning
- Emotion Control
- SSML Support
- API مبتنی بر REST را ارائه میدهند.
مقایسه OpenAI و Google در تبدیل متن به گفتار (TTS)
هر دو پلتفرم OpenAI و Google Cloud از مدلهای عصبی پیشرفته برای تولید صدای طبیعی استفاده میکنند، اما رویکرد آنها در معماری، نوع مدلها، سطح کنترل توسعهدهنده و یکپارچگی با سایر سرویسهای هوش مصنوعی متفاوت است.
OpenAI تمرکز خود را بر یکپارچگی کامل TTS با مدلهای چندوجهی (Multimodal) قرار داده است؛ بهطوریکه تولید صوت، متن و حتی تصویر میتواند در یک اکوسیستم واحد انجام شود. در مقابل، Google Cloud تمرکز سازمانیتر داشته و تنوع صدای بیشتری همراه با تنظیمات دقیقتری برای کنترل پارامترهای صوتی ارائه میدهد.
در جدول زیر، این دو پلتفرم از جنبههای فنی و کاربردی مقایسه شدهاند:
| معیار | OpenAI TTS | Google Cloud Text-to-Speech |
| کیفیت صدا | صدای طبیعی با مدلهای عصبی پیشرفته، تمرکز بر لحن انسانی و بیان احساسی | صدای طبیعی مبتنی بر WaveNet و مدلهای Neural2 با وضوح بالا |
| پشتیبانی زبان | پشتیبانی از چندین زبان رایج با تمرکز بر کیفیت در زبانهای پرکاربرد | پشتیبانی گسترده از زبانها و گویشهای متعدد در سطح جهانی |
| Latency (تاخیر) | مناسب برای کاربردهای بلادرنگ و API محور | بهینهسازیشده برای مقیاس سازمانی با پاسخگویی سریع |
| قیمتگذاری | مبتنی بر میزان کاراکتر یا توکن مصرفی | مبتنی بر تعداد کاراکتر پردازششده با پلنهای متنوع |
| قابلیت شخصیسازی | امکان انتخاب صدا و تنظیمات خروجی در API | امکان انتخاب نوع صدا، جنسیت، سرعت گفتار و Pitch |
پیادهسازی تبدیل متن به صدا با OpenAI API
در این بخش نحوه استفاده از API رسمی OpenAI برای تبدیل متن به صدا را بررسی میکنیم. این API به شما اجازه میدهد تنها با ارسال یک متن، فایل صوتی طبیعی با کیفیت بالا تولید کنید. پیادهسازی آن ساده است و میتواند در اپلیکیشنهای وب، موبایل یا سیستمهای بکاند استفاده شود.
۱. ساخت فایل صوتی از متن (Python)
برای شروع باید کتابخانه رسمی OpenAI را نصب کنید:
|
1 |
pip install —upgrade openai |
سپس میتوانیم با استفاده از مدلهای صوتی، متن را به فایل صوتی تبدیل کنیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from openai import OpenAI client = OpenAI() speech_file_path = “speech.mp3” response = client.audio.speech.create( model=“gpt-4o-mini-tts”, voice=“alloy”, input=“سلام! این یک نمونه تبدیل متن به صدا با OpenAI است.” ) with open(speech_file_path, “wb”) as f: f.write(response.content) print(“Audio file saved successfully.”) |
در این مثال:
مدل gpt-4o-mini-tts برای تولید گفتار استفاده شده
پارامتر voice نوع صدای خروجی را مشخص میکند
خروجی به صورت فایل MP3 ذخیره میشود
۲. تنظیم voice و format
در API تبدیل متن به صوت میتوان ویژگیهای خروجی را کنترل کرد.
انتخاب صدا (Voice)
OpenAI چندین صدای مختلف ارائه میدهد که هرکدام لحن و شخصیت متفاوتی دارند:
|
1 2 3 4 5 |
response = client.audio.speech.create( model=“gpt-4o-mini-tts”, voice=“verse”, input=“این یک صدای متفاوت است.” ) |
تعیین فرمت خروجی
میتوان فرمت فایل خروجی را مشخص کرد (مثلاً mp3 یا wav):
|
1 2 3 4 5 6 |
response = client.audio.speech.create( model=“gpt-4o-mini-tts”, voice=“alloy”, input=“خروجی با فرمت WAV”, format=“wav” ) |
فرمتهای رایج شامل:
- mp3
- wav
- ogg
۳. استفاده در JavaScript
برای استفاده در Node.js ابتدا پکیج رسمی را نصب کنید:
|
1 |
npm install openai |
سپس:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import OpenAI from “openai”; import fs from “fs”; const openai = new OpenAI(); const response = await openai.audio.speech.create({ model: “gpt-4o-mini-tts”, voice: “alloy”, input: “This is a sample text-to-speech conversion.” }); const buffer = Buffer.from(await response.arrayBuffer()); fs.writeFileSync(“speech.mp3”, buffer); console.log(“Audio saved successfully.”); |
این کد متن را به صوت تبدیل کرده و فایل MP3 ایجاد میکند.
۴. پارامترهای مهم API
در استفاده حرفهای از API تبدیل متن به صدا، این پارامترها اهمیت دارند:
- model: تعیین مدل تولید گفتار
- voice: انتخاب نوع صدا
- input: متن ورودی
- format: نوع فایل خروجی
- streaming: برای تولید صوت به صورت بلادرنگ
- sample rate (در برخی تنظیمات پیشرفته)
با استفاده از این پارامترها میتوان کیفیت، سرعت و تجربه شنیداری را متناسب با نیاز پروژه تنظیم کرد.
پیادهسازی تبدیل متن به صدا با Google Cloud
Google Cloud نیز یکی از سرویسهای قدرتمند تبدیل متن به گفتار را ارائه میدهد که از صداهای Neural با کیفیت بالا پشتیبانی میکند.
۱. فعالسازی سرویس
برای استفاده از Google TTS باید:
- در Google Cloud Console پروژه ایجاد کنید
- سرویس Text-to-Speech API را فعال کنید
- یک Service Account ایجاد کرده و فایل JSON کلید را دریافت کنید
متغیر محیطی را تنظیم کنید:
|
1 |
export GOOGLE_APPLICATION_CREDENTIALS=“path/to/your/service-account.json” |
۲. نمونه کد Python
ابتدا کتابخانه را نصب کنید:
|
1 |
pip install google–cloud–texttospeech |
سپس:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from google.cloud import texttospeech client = texttospeech.TextToSpeechClient() input_text = texttospeech.SynthesisInput(text=“سلام، این یک تست تبدیل متن به صدا با گوگل است.”) voice = texttospeech.VoiceSelectionParams( language_code=“fa-IR”, ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL ) audio_config = texttospeech.AudioConfig( audio_encoding=texttospeech.AudioEncoding.MP3 ) response = client.synthesize_speech( input=input_text, voice=voice, audio_config=audio_config ) with open(“google_speech.mp3”, “wb”) as out: out.write(response.audio_content) print(“Audio content written to file.”) |
۳. استفاده از SSML
Google از SSML (Speech Synthesis Markup Language) پشتیبانی میکند که امکان کنترل دقیقتر لحن و مکث را فراهم میکند:
|
1 2 3 4 5 6 7 8 9 |
ssml_text = texttospeech.SynthesisInput( ssml=“”“ <speak> سلام. <break time=”1s“/> این یک نمونه استفاده از SSML است. </speak> ““” ) |
با SSML میتوان:
- مکث ایجاد کرد
- تاکید روی کلمات گذاشت
- سرعت و زیر و بمی صدا را تنظیم کرد
۴. تنظیم Pitch و Speaking Rate
Google اجازه میدهد ویژگیهای صوتی را تنظیم کنید:
|
1 2 3 4 5 |
audio_config = texttospeech.AudioConfig( audio_encoding=texttospeech.AudioEncoding.MP3, speaking_rate=1.2, pitch=2.0 ) |
- speaking_rate: سرعت گفتار (کمتر از ۱ آهستهتر، بیشتر از ۱ سریعتر)
- pitch: زیر و بمی صدا
کاربردهای صنعتی تبدیل متن به گفتار (TTS)
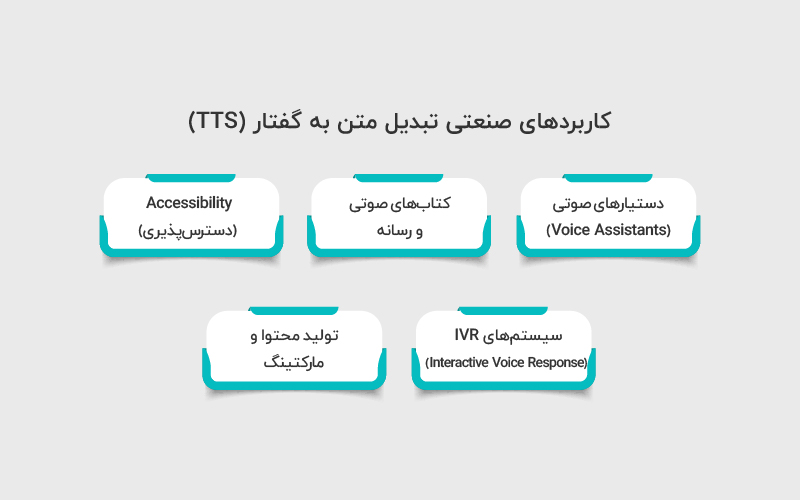
فناوری تبدیل متن به صدا دیگر محدود به خواندن ساده یک متن نیست. امروز به یکی از زیرساختهای کلیدی در محصولات دیجیتال تبدیل شده است.
۱. دستیارهای صوتی (Voice Assistants)
سیستمهای هوشمند مانند چتباتهای صوتی و دستیارهای دیجیتال از TTS برای پاسخگویی طبیعی به کاربر استفاده میکنند.
در این سناریو، متن تولیدشده توسط مدل زبانی به صوت تبدیل میشود و تجربهای مکالمهمحور ایجاد میکند.
۲. کتابهای صوتی و رسانه
پلتفرمهای انتشار کتاب صوتی از مدلهای عصبی برای تولید صدای طبیعی با لحن داستانی استفاده میکنند.
مدلهای جدید امکان:
- کنترل سرعت خواندن
- تنظیم احساس (هیجانی، آرام، رسمی)
- تولید صدای شخصیتهای مختلف
را فراهم کردهاند.
۳. Accessibility (دسترسپذیری)
TTS یکی از مهمترین ابزارها برای افراد کمبینا یا نابینا محسوب میشود.
سیستمهای Screen Reader متن صفحات وب یا اسناد را به صوت تبدیل میکنند و امکان تعامل مستقل با محتوای دیجیتال را فراهم میسازند.
۴. سیستمهای IVR (Interactive Voice Response)
در مراکز تماس و سیستمهای تلفنی خودکار، به جای استفاده از صدای از پیش ضبطشده، از TTS برای تولید پویا استفاده میشود.
مزیت این روش:
- کاهش هزینه تولید فایلهای صوتی
- بهروزرسانی سریع پیامها
- شخصیسازی پیام برای هر کاربر
۵. تولید محتوا و مارکتینگ
در تولید ویدیوهای آموزشی، تبلیغاتی و شبکههای اجتماعی، TTS امکان تولید سریع نریشن حرفهای را بدون نیاز به گوینده انسانی فراهم میکند.
چالشها و محدودیتهای TTS

با وجود پیشرفتهای چشمگیر، فناوری تبدیل متن به گفتار همچنان با چالشهایی مواجه است.
۱. تاخیر (Latency)
در کاربردهای Real-Time مانند تماسهای زنده یا دستیارهای صوتی، تأخیر پردازش میتواند تجربه کاربری را مختل کند.
مدلهای پیشرفتهتر معمولا پردازش سنگینتری دارند.
۲. مصنوعی بودن لحن
اگرچه مدلهای جدید بسیار طبیعیتر شدهاند، اما در برخی موارد:
- احساسات پیچیده انسانی
- مکثهای طبیعی
- تغییرات ظریف تن صدا
هنوز بهطور کامل بازتولید نمیشوند.
۳. محدودیت زبانی
برخی زبانها و گویشها کیفیت پایینتری نسبت به زبانهای پرکاربرد (مانند انگلیسی) دارند. همچنین پشتیبانی از لهجههای محلی هنوز چالشبرانگیز است.
۴. هزینه پردازش
مدلهای عصبی پیشرفته برای تولید صدای طبیعی نیازمند توان پردازشی بالایی هستند. در مقیاس سازمانی، این موضوع میتواند منجر به هزینه عملیاتی قابل توجه شود.
جمعبندی
تبدیل متن به گفتار دیگر یک فناوری جانبی نیست؛ بلکه به زیرساختی کلیدی در اکوسیستم هوش مصنوعی تبدیل شده است. از دستیارهای صوتی و کتابهای صوتی گرفته تا سیستمهای IVR و تولید محتوای دیجیتال، TTS نقش مهمی در تعامل انسان و ماشین ایفا میکند.
با وجود چالشهایی مانند تاخیر، هزینه پردازش و محدودیتهای زبانی، روند توسعه مدلهای عصبی نشان میدهد که در سالهای آینده شاهد سیستمهایی خواهیم بود که صدایی تقریبا غیرقابلتشخیص از انسان تولید میکنند، آن هم در مقیاس وسیع و بهصورت بلادرنگ.
مسیر آینده TTS، به سمت شخصیسازی، احساسپذیری و ادغام کامل با سیستمهای چندوجهی هوش مصنوعی حرکت میکند؛ جایی که صدا به یکی از اصلیترین رابطهای تعامل دیجیتال تبدیل خواهد شد.
منابع
developers.openai.com | fingoweb.com | docs.cloud.google.com (1), (2)
سوالات متداول
TTS سنتی صدایی مکانیکی و یکنواخت تولید میکرد
TTS مبتنی بر AI صدایی طبیعیتر، با لحن و احساس واقعگرایانه تولید میکند
مدلهای جدید میتوانند مکث، تأکید و حتی احساسات را شبیهسازی کنند.
بله. در بسیاری از سیستمهای پیشرفته میتوان جنسیت صدا، لحن، سرعت گفتار و حتی صدای خاص (Voice Cloning) را تنظیم کرد.
در سیستمهای چندوجهی:
متن تولیدشده توسط مدل زبانی
به صدا تبدیل میشود و تجربه کاربری طبیعیتری ایجاد میکند.


دیدگاهتان را بنویسید