
استنتاج هوش مصنوعی قلب تپنده بیشتر کاربردهای عملی AI است: مرحلهای که در آن مدلِ آموزشدیده، روی دادههای جدید تصمیم میگیرد، پیشبینی میکند و پاسخ میدهد. برای یک تیم فنی، شناخت تفاوت استنتاج با یادگیری ماشین، درک الزامات محاسباتی (CPU/GPU/FPGA/ASIC/TPU) و انتخاب نوع استنتاج مناسب (پویا، دستهای یا جریانی) پیشنیاز طراحی معماری پایدار و کمهزینه است.
در این مقاله با زبانی روشن و فنی، مبانی، مزایا و چالشها، اجزای کلیدی، فرایند گامبهگام و انواع استنتاج را مرور میکنیم تا مسیر پیادهسازی در تولید را برای توسعهدهندگان هموار کنیم.
استنتاج هوش مصنوعی (AI Inference) چیست؟
استنتاج هوش مصنوعی به توانایی مدلهای آموزشدیده هوش مصنوعی برای تشخیص الگوها و نتیجهگیری از دادههایی که قبلا ندیدهاند گفته میشود.
اینفرنس در واقع بخش حیاتی از عملکرد هوش مصنوعی است و پایه بسیاری از کاربردهای پیشرفته آن به حساب میآید؛ از جمله هوش مصنوعی مولد (Generative AI) که قدرت پشت ابزارهایی مثل ChatGPT محسوب میشود. مدلهای هوش مصنوعی برای شبیهسازی شیوه تفکر، استدلال و پاسخگویی انسانها، به همین فرایند استنتاج متکیاند.
فرایند استنتاج از مرحله آموزش مدل آغاز میشود؛ جایی که مدل با استفاده از مجموعه دادههای بزرگ و الگوریتمهای تصمیمگیری آموزش میبیند. این مدلها معمولا بر پایه شبکههای عصبی ساخته میشوند؛ مثل مدلهای زبانی بزرگ (LLMs) که ساختاری مشابه مغز انسان دارند.
برای مثال، مدلی که برای تشخیص چهره طراحی شده، ممکن است با میلیونها تصویر از چهره انسان آموزش داده شود. در نهایت، این مدل یاد میگیرد که ویژگیهایی مثل رنگ چشم، فرم بینی و رنگ مو را تشخیص دهد و از آنها برای شناسایی افراد در تصاویر استفاده کند.
تفاوت استنتاج هوش مصنوعی و یادگیری ماشین
با اینکه استنتاج در هوش مصنوعی و یادگیری ماشین (Machine Learning) مفاهیمی نزدیک به هم هستند اما در دو مرحله متفاوت از چرخه عمر یک مدل هوش مصنوعی قرار میگیرند.
در مرحله یادگیری ماشین، مدل با استفاده از دادههای آموزشی و الگوریتمها بهویژه در فرایند یادگیری نظارتشده (Supervised Learning) یاد میگیرد که چطور مانند انسانها الگوها را تشخیص دهد و بهتدریج دقت خود را بهبود دهد.
اما در مرحله استنتاج، مدل از دانشی که در مرحله آموزش به دست آورده استفاده میکند تا بر اساس دادههای جدید تصمیم بگیرد، پیشبینی کند یا نتیجهگیری انجام دهد.
کاربردهای استنتاج هوش مصنوعی
تقریبا تمام کاربردهای واقعی هوش مصنوعی در دنیای امروز به نوعی به اینفرنس وابستهاند. در ادامه چند نمونه رایج از مهمترین کاربردهای آن را مرور میکنیم:
۱- مدلهای زبانی بزرگ
مدلهایی که با نمونههای متنی آموزش دیدهاند، میتوانند متنهایی را که پیشتر ندیدهاند، تحلیل و تفسیر کنند. بهعنوان مثال، ChatGPT با تکیه بر همین توانایی استنتاج قادر است به پرسشهای متنی جدید پاسخ دهد یا محتوا تولید کند.
۲- تحلیل پیشبینانه
وقتی مدلی با دادههای گذشته آموزش دیده و به مرحله استنتاج میرسد، میتواند بر اساس دادههای جدید، پیشبینیهایی دقیق انجام دهد. برای نمونه، در کسبوکارها از استنتاج برای پیشبینی فروش، رفتار مشتری یا روند بازار استفاده میشود.
۳- امنیت ایمیل
مدلهای یادگیری ماشین میتوانند برای شناسایی ایمیلهای اسپم یا حملات فیشینگ تجاری آموزش ببینند. در مرحله استنتاج، این مدلها ایمیلهای دریافتی را تحلیل کرده و با تشخیص الگوهای مشکوک، ایمیلهای مخرب را مسدود میکنند.
۴- خودروهای خودران
استنتاج هوش مصنوعی در سیستمهای رانندگی خودکار نقش کلیدی دارد. مدلهای هوش مصنوعی با استفاده از دادههای حسگرها، دوربینها و نقشهها، در لحظه تصمیم میگیرند و به خودرو اجازه میدهند مسیر را شناسایی، موانع را تشخیص و قوانین رانندگی را رعایت کند.
۵- پژوهش علمی و پزشکی
در پژوهشهای علمی و پزشکی، تحلیل دادهها اهمیت حیاتی دارد. استنتاج هوش مصنوعی میتواند با تجزیه و تحلیل حجم عظیمی از دادههای آزمایشگاهی یا بالینی، الگوها و روابط پنهان را کشف کرده و به نتیجهگیریهای علمی دقیقتر منجر شود.
۶- امور مالی
مدلهایی که با دادههای عملکرد بازار در گذشته آموزش دیدهاند، میتوانند پیشبینیهایی درباره روند آینده بازار ارائه دهند. البته این پیشبینیها تضمینشده نیستند اما میتوانند به تصمیمگیریهای هوشمندانهتر در سرمایهگذاری و مدیریت ریسک کمک کنند.
مزایای استنتاج هوش مصنوعی
اگر مدلهای هوش مصنوعی با مجموعهدادهای قدرتمند و متناسب با کاربردشان آموزش نبینند، کارایی واقعی نخواهند داشت. از آنجا که این فناوری ماهیتی حساس دارد و بهطور گسترده زیر ذرهبین رسانههاست، شرکتها باید در استفاده از آن با دقت و احتیاط عمل کنند.
با این حال، از آنجا که استنتاج هوش مصنوعی در صنایع مختلف کاربرد دارد و میتواند تحول دیجیتال و نوآوری مقیاسپذیر را تسهیل کند، مزایای چشمگیری به همراه دارد:
۱- دقت و صحت بالا
مدلهای هوش مصنوعی با پیشرفت فناوری، روزبهروز دقیقتر و قابلاعتمادتر میشوند. برای مثال، مدلهای زبانی بزرگ (LLM) امروزی میتوانند در انتخاب واژهها، جملهها و ساختارهای دستوری، لحن خاص یک نویسنده مشخص را تقلید کنند.
در حوزه تصویر و ویدیو هم عملکرد مشابهی دارند و میتوانند رنگها و سبکها را طوری انتخاب کنند که احساس، فضا یا سبک هنری خاصی را منتقل کنند.
۲- بهبود کنترل کیفیت
یکی از کاربردهای تازه و هیجانانگیز استنتاج هوش مصنوعی، در زمینه پایش و بازرسی سامانهها است.
مدلهایی که با دادههایی مانند کیفیت آب، الگوهای آبوهوا یا رفتار تجهیزات صنعتی آموزش دیدهاند، امروز برای پایش سلامت دستگاهها و تجهیزات صنعتی در محیط واقعی مورد استفاده قرار میگیرند.
۳- یادگیری رباتیک
رباتهایی که از قابلیت استنتاج هوش مصنوعی بهره میبرند، در صنایع مختلف برای انجام وظایف پیچیده به کار گرفته میشوند. یکی از شناختهشدهترین نمونهها، خودروهای بدون راننده هستند.
شرکتهایی مانند Tesla، Waymo و Cruise از استنتاج هوش مصنوعی برای آموزش شبکههای عصبی استفاده میکنند تا خودروها بتوانند قوانین رانندگی را درک و رعایت کنند.
۴- یادگیری بدون جهتگیری (Directionless Learning)
در این نوع یادگیری، مدل بدون نیاز به برنامهریزی مستقیم انسانی، از دادهها یاد میگیرد و بهمرور عملکرد خود را بهبود میدهد. به این ترتیب، وابستگی به ورودی انسانی کاهش یافته و هزینه و زمان اجرای سیستم نیز کمتر میشود.
بهعنوان مثال، مدلی که با تصاویر مزارع آموزش دیده، میتواند به کشاورزان کمک کند تا علفهای هرز یا محصولات ناسالم را شناسایی و کنترل کنند.
۵- تصمیمگیری و راهنمایی آگاهانه
یکی از جذابترین کاربردهای استنتاج هوش مصنوعی، توانایی آن در درک ظرافتها و پیچیدگیهای دادهها و ارائه پیشنهاد یا تصمیم مبتنی بر دانش است. بهعنوان نمونه، مدلهایی که بر اساس اصول مالی آموزش دیدهاند، میتوانند پیشنهادهای سرمایهگذاری منطقی ارائه دهند یا فعالیتهای مشکوک به تقلب را شناسایی کنند.
در حوزههای حساستری مانند تشخیص بیماری یا هدایت هواپیما نیز، استنتاج هوش مصنوعی میتواند احتمال خطای انسانی را بهطور چشمگیری کاهش دهد.
۶- توانایی رایانش لبهای (Edge Computing)
ترکیب استنتاج هوش مصنوعی با پردازش در لبه (Edge Computing) این امکان را فراهم میکند که دادهها بهصورت لحظهای و بدون ارسال به مراکز داده پردازش شوند.
این ویژگی در کاربردهایی چون مدیریت موجودی انبارها یا واکنشهای میلیثانیهای در خودروهای خودران حیاتی است و باعث میشود مزایای هوش مصنوعی در عمل، بلادرنگ و کارآمد در دسترس باشند.
چالشهای استنتاج هوش مصنوعی
با وجود مزایای فراوان، استنتاج هوش مصنوعی همچنان یک فناوری نوپا و در حال رشد سریع است و طبیعتا با چالشهایی نیز همراه است. در ادامه، مهمترین موانعی که شرکتها باید پیش از سرمایهگذاری در هوش مصنوعی در نظر بگیرند را مرور میکنیم:
۱- انطباق با قوانین
نظارت و قانونگذاری در حوزه هوش مصنوعی و استنتاج آن کاری دشوار و همواره در حال تغییر است.
یکی از نمونههای مهم، مسئلهی حاکمیت داده (Data Sovereignty) است؛ مفهومی که بیان میکند دادهها باید تحت قوانین کشوری باشند که در آن تولید شدهاند.
برای شرکتهای بینالمللی که دادههای مرتبط با هوش مصنوعی را در چندین کشور جمعآوری، ذخیره و پردازش میکنند، رعایت قوانین متنوع و گاه متضاد هر منطقه، در عین تلاش برای نوآوری و حفظ رقابتپذیری، چالشی جدی محسوب میشود.
۲- کیفیت دادهها
در فرایند آموزش مدلهای هوش مصنوعی، کیفیت دادههای آموزشی نقش تعیینکنندهای در موفقیت مدل دارد. درست مانند انسانی که از یک معلم ضعیف آموزش ببیند، مدلی که با دادههای بیکیفیت آموزش داده شود نیز عملکرد مطلوبی نخواهد داشت.
مجموعهدادهها باید بهدقت برچسبگذاری شوند و ارتباط مستقیم و شفاف با مهارتی که مدل در حال یادگیری آن است داشته باشند. یکی از چالشهای اساسی در دقت استنتاج هوش مصنوعی، انتخاب مدل مناسب و داده آموزشی درست برای آن است.
۳- پیچیدگی دادهها
همانطور که کیفیت دادهها مهم است، پیچیدگی بیش از حد دادهها نیز میتواند موجب افت عملکرد مدلها شود. با یک مثال ساده انسانی: هرچه مفهومی که باید یاد گرفته شود سادهتر باشد، یادگیری نیز سریعتر و دقیقتر خواهد بود.
مدلهایی که برای وظایف سادهتری مثل چتباتهای پشتیبانی مشتری یا دستیارهای سفر مجازی طراحی شدهاند، آموزش سادهتری دارند. اما مدلهایی که در حوزههایی مانند تصویربرداری پزشکی یا مشاوره مالی فعالیت میکنند، به دلیل ماهیت پیچیده دادهها و تصمیمگیری، به منابع آموزشی و محاسباتی بسیار بیشتری نیاز دارند.
۴- نیاز به مهارت و تخصص
با وجود جذابیت و سرعت رشد هوش مصنوعی، توسعه برنامههای کاربردی کارآمد و ایجاد استنتاج دقیق نیازمند دانش تخصصی، تجربه و زمان است. تا زمانی که مسیر آموزش نیروی متخصص با سرعت نوآوری همگام نشود، کارشناسان این حوزه همچنان در تقاضای بالا و با هزینه استخدام زیاد باقی خواهند ماند.
۵- وابستگی به تایوان
حدود ۶۰٪ از نیمههادیهای جهان و ۹۰٪ از تراشههای پیشرفته (از جمله شتابدهندههای هوش مصنوعی مورد نیاز برای استنتاج) در تایوان تولید میشوند.
علاوه بر آن، شرکت Nvidia بهعنوان بزرگترین تولیدکننده سختافزار و نرمافزار هوش مصنوعی در جهان، تقریبا بهطور کامل به شرکت TSMC (Taiwan Semiconductor Manufacturing Corporation) وابسته است. بروز بلایای طبیعی یا بحرانهای ژئوپولیتیکی در این منطقه میتواند روند تولید و توزیع تراشههای حیاتی مورد نیاز برای استنتاج هوش مصنوعی را مختل کند و در مقیاس جهانی، پیامدهای سنگینی داشته باشد.
اجزای کلیدی در استنتاج هوش مصنوعی
استنتاج هوش مصنوعی فرایندی پیچیده است که شامل آموزش مدلهای هوش مصنوعی با مجموعهدادههای مناسب تا زمانی است که بتوانند پاسخهای دقیق و منطقی ارائه دهند. این فرایند بهشدت نیازمند توان پردازشی بالا است و به همین دلیل، به سختافزار و نرمافزارهای تخصصی وابسته است. پیش از آنکه به نحوه آموزش مدلهای هوش مصنوعی برای استنتاج بپردازیم، بیایید با سختافزارهای کلیدی که اجرای این فرایند را ممکن میسازند آشنا شویم:
۱- واحد پردازش مرکزی (Central Processing Unit)
CPU، یا همان پردازندهی مرکزی، هسته اصلی عملکرد هر سیستم کامپیوتری است. در فرایند آموزش و استنتاج هوش مصنوعی، CPU وظیفه دارد سیستمعامل را اجرا کرده و منابع پردازشی مورد نیاز برای آموزش مدلها را مدیریت کند. در واقع CPU نقش هماهنگکننده میان اجزای مختلف سختافزار را بر عهده دارد.
۲- واحد پردازش گرافیکی (Graphics Processing Unit)
GPU یا واحد پردازش گرافیکی در ابتدا برای پردازش تصاویر و گرافیک طراحی شد و در کارتهای گرافیک، مادربوردها و حتی تلفنهای همراه به کار میرود. اما قابلیت مهم آن یعنی پردازش موازی (Parallel Processing) باعث شده که GPU به یکی از ابزارهای اصلی در آموزش مدلهای هوش مصنوعی تبدیل شود.
در بسیاری از سیستمهای مدرن، چندین GPU به یک سیستم متصل میشوند تا قدرت پردازش آن برای آموزش مدلهای بزرگ افزایش یابد.
۳- آرایههای دروازهای قابلبرنامهریزی میدانی (Field-Programmable Gate Arrays)
FPGAها نوعی شتابدهنده هوش مصنوعی (AI Accelerator) هستند که میتوانند در سطح سختافزار مجددا برنامهریزی شوند تا برای یک هدف خاص بهینه شوند. برخلاف بسیاری از شتابدهندههای دیگر، FPGAها طراحی منعطفی دارند و اغلب برای پردازش دادهها در لحظه (Real-time Processing) مورد استفاده قرار میگیرند؛ موضوعی که در استنتاج هوش مصنوعی حیاتی است.
این قابلیت برنامهریزی مجدد در سطح سختافزار، امکان سفارشیسازی بسیار بالا را فراهم میکند، اما نیازمند دانش تخصصی عمیقی است.
۴- مدارهای مجتمع با کاربرد خاص (Application-Specific Integrated Circuits)
ASICها نیز نوعی شتابدهنده هوش مصنوعی هستند که برای هدف یا بارکاری خاصی طراحی میشوند؛ مثلا شتابدهندههای WSE-3 شرکت Cerebras که برای یادگیری عمیق (Deep Learning) ساخته شدهاند. ASICها به دانشمندان داده کمک میکنند تا فرایند استنتاج را سریعتر و مقرونبهصرفهتر انجام دهند.
برخلاف FPGAها، ASICها غیرقابل برنامهریزی مجدد هستند اما چون از ابتدا برای یک کاربرد خاص طراحی میشوند، معمولا عملکرد بهتری نسبت به شتابدهندههای چندمنظوره دارند.
یکی از نمونههای مشهور این نوع تراشهها، واحد پردازش تنسور (TPU) شرکت گوگل است که برای یادگیری ماشینی شبکههای عصبی با استفاده از TensorFlow توسعه یافته است.
نحوه عملکرد استنتاج هوش مصنوعی
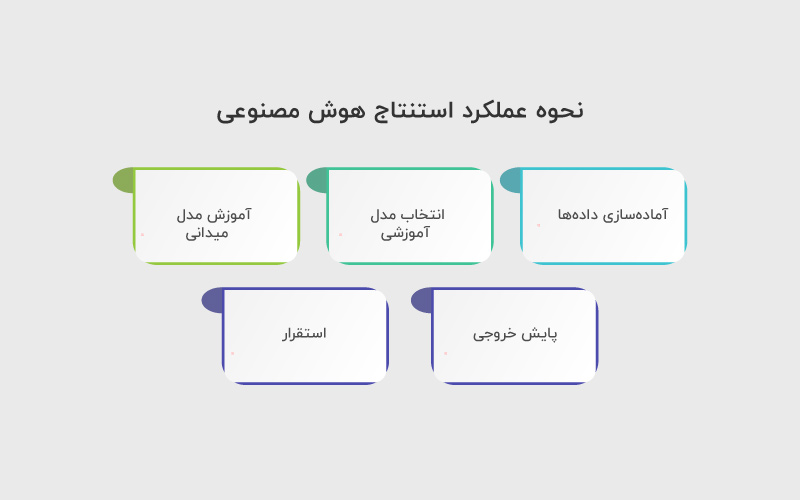
سازمانهایی که قصد دارند در مسیر تحول دیجیتال خود از هوش مصنوعی استفاده کنند، باید با مزایا و چالشهای استنتاج هوش مصنوعی بهخوبی آشنا شوند.
اگر این مراحل را بررسی کردهاید و آماده اجرای واقعی آن هستید، در ادامه پنج گام اصلی برای پیادهسازی موثر استنتاج هوش مصنوعی را میبینید:
۱. آمادهسازی دادهها
آمادهسازی داده، نخستین و حیاتیترین گام برای ساخت مدلهای موثر هوش مصنوعی است. سازمانها میتوانند مجموعهدادههای آموزشی را با استفاده از دادههای داخلی یا خارجی ایجاد کنند و معمولا ترکیب هر دو نوع داده بهترین نتیجه را میدهد. بخش مهم دیگری از این مرحله، پاکسازی دادهها است؛ یعنی حذف دادههای تکراری، رفع ناهماهنگی در قالبها و اطمینان از یکپارچگی دادههای ورودی.
۲. انتخاب مدل آموزشی
بعد از آمادهسازی دادهها، نوبت به انتخاب مدل مناسب برای کاربرد مورد نظر میرسد. مدلهای هوش مصنوعی طیفی از ساده تا پیچیده دارند. مدلهای پیچیدهتر میتوانند ورودیهای بیشتری را پردازش کرده و استنتاجهای ظریفتر و دقیقتری ارائه دهند اما در عوض به زمان، هزینه و منابع پردازشی بیشتری نیاز دارند. در این مرحله، شفافسازی نیازهای واقعی پروژه بسیار مهم است تا بتوان تعادلی میان دقت و منابع مصرفی برقرار کرد.
۳. آموزش مدل
برای دستیابی به خروجی مطلوب از یک برنامه هوش مصنوعی، معمولا باید چندین مرحله آموزشی سختگیرانه و تکرارشونده طی شود. با هر مرحله آموزش، دقت مدل در استنتاج افزایش پیدا میکند و در عین حال، میزان منابع پردازشی مورد نیاز (مانند توان محاسباتی یا زمان پاسخ) کاهش پیدا میکند.
زمانی که مدل به بلوغ میرسد، وارد مرحلهای میشود که میتواند از دانستههای خود برای تحلیل دادههای جدید استفاده کند و این همان نقطهای است که مدل عملا شروع به «فکر کردن» میکند.
۴. پایش خروجی
پیش از آنکه مدل وارد مرحله عملیاتی شود، باید خروجیهای آن را از نظر دقت، سوگیری (Bias) و حریم خصوصی دادهها بررسی کرد. به این مرحله پسپردازش (Postprocessing) گفته میشود، جایی که یک فرایند گامبهگام برای اطمینان از صحت و انطباق خروجی مدل تدوین میشود. در این فاز باید مطمئن شوید که مدل رفتار و پاسخهای مورد انتظار شما را ارائه میدهد و مطابق هدف طراحیشده عمل میکند.
۵. استقرار
پس از انجام مراحل کنترل، پایش و اصلاح، مدل آماده استقرار در محیط واقعی کسبوکار است. در این مرحله باید زیرساخت داده و معماری فنی مورد نیاز مدل پیادهسازی شود تا بتواند بهصورت پایدار کار کند.
همچنین، لازم است فرایندهای مدیریت تغییر (Change Management) برای آموزش ذینفعان و کاربران نهایی تدوین شوند تا استفاده از مدل در فعالیتهای روزمره به درستی انجام شود.
انواع استنتاج هوش مصنوعی
بسته به نوع کاربردی که یک سازمان از هوش مصنوعی انتظار دارد، انواع مختلفی از استنتاج وجود دارد که میتوان بین آنها انتخاب کرد. برای مثال، اگر قرار است مدل هوش مصنوعی در یک سیستم اینترنت اشیا (IoT) استفاده شود، نوعی از استنتاج به نام استنتاج جریانی (Streaming Inference) که بر پایه پردازش دادههای لحظهای کار میکند، مناسبتر است.
اما اگر مدل برای تعامل با انسانها طراحی شده باشد مثل چتباتها یا مدلهای زبانی بزرگ نوع استنتاج پویا (Dynamic Inference) یا استنتاج آنلاین (Online Inference) گزینه بهتری خواهد بود.
در ادامه سه نوع اصلی استنتاج هوش مصنوعی و ویژگیهای متمایز هر کدام را بررسی میکنیم:
۱. استنتاج پویا
استنتاج پویا که با نام استنتاج آنلاین نیز شناخته میشود، سریعترین نوع استنتاج است و در محبوبترین برنامههای مبتنی بر مدلهای زبانی بزرگ (LLM) مانند ChatGPT شرکت OpenAI به کار میرود. در این روش، مدل بهصورت بلادرنگ پاسخ و پیشبینی تولید میکند و برای عملکرد موثر به دسترسی سریع به داده و تاخیر بسیار پایین (Low Latency) نیاز دارد.
از آنجا که پاسخها تقریبا بلافاصله تولید میشوند، معمولا فرصتی برای بازبینی یا تایید خروجی قبل از نمایش به کاربر وجود ندارد. به همین دلیل، بسیاری از سازمانها لایهای از پایش و کنترل کیفیت بین خروجی مدل و کاربر نهایی قرار میدهند تا از صحت و سازگاری نتایج اطمینان حاصل کنند.
۲. استنتاج دستهای
در استنتاج دستهای، مدل با استفاده از مقادیر بزرگی از دادههای ذخیرهشده پیشبینیهای خود را بهصورت آفلاین تولید میکند. در این رویکرد، دادههایی که از قبل جمعآوری شدهاند، به الگوریتمهای یادگیری ماشین اعمال میشوند تا نتایج مورد نظر استخراج شود.
هرچند این نوع استنتاج برای کاربردهایی که به پاسخ لحظهای نیاز دارند مناسب نیست اما برای سناریوهایی مانند داشبوردهای فروش، تحلیل بازاریابی، یا ارزیابی ریسک که دادهها در طول روز یا هفته چند بار بهروزرسانی میشوند، انتخابی عالی است.
۳. استنتاج جریانی
در استنتاج جریانی، دادهها از طریق یک خطلولهی مداوم (Data Pipeline) که معمولا از حسگرها و تجهیزات متصل به اینترنت دریافت میشود، به الگوریتم تغذیه میشوند تا بهصورت پیوسته محاسبه و پیشبینی انجام دهد.
این روش بهویژه در کاربردهای اینترنت اشیا (IoT) اهمیت دارد، مانند سیستمهایی که برای پایش نیروگاهها یا ترافیک شهری از دادههای لحظهای حسگرها استفاده میکنند. استنتاج جریانی این امکان را فراهم میکند که سیستمها بدون وقفه و در زمان واقعی تصمیمگیری کنند.
جمعبندی
برای رساندن یک سیستم هوش مصنوعی از محیط آزمایشگاهی به تولید، صرفِ داشتن یک مدل دقیق کافی نیست؛ کیفیت و تبار داده، انتخاب معماری سختافزاری، نوع استنتاج متناسب با مسئله، پایش پس از استقرار و انطباق با الزامات حریم خصوصی و قوانین، همگی تعیینکنندهاند.
اگر به پاسخ بلادرنگ و تعامل انسان–ماشین نیاز دارید، استنتاج پویا گزینه طبیعی است؛ اگر به پردازش دورهای روی حجمهای بزرگ نیاز دارید، استنتاج دستهای منطقیتر است؛ و اگر با جریان مداوم سنسورها سروکار دارید، استنتاج جریانی در لبه یا ابرِ نزدیک کاراتر خواهد بود.
سوالات متداول
یادگیری ماشین مرحله آموزش مدل با دادههای برچسبدار/بدونبرچسب برای یادگیری الگوهاست؛ استنتاج مرحلهای است که همان مدلِ آموزشدیده روی دادههای جدید خروجی تولید میکند (تصمیم، پیشبینی یا پاسخ).
GPU برای پردازش موازی عمومی و LLMها کارآمد است؛ TPU برای بارهای یادگیری عمیق مبتنی بر TensorFlow بهینه شده؛ FPGA برای تاخیر بسیار کم و سفارشیسازی در لبه مناسب است؛ ASIC برای بارهای خاص با کارایی و بهرهوری انرژی بالاتر اما بدون انعطاف در برنامهریزی مجدد.
تاخیر کمتر، مصرف پهنای باند کمتر و مزایای حریم خصوصی؛ در مقابل، محدودیت توان محاسباتی و بهروزرسانی دشوارتر را باید مدیریت کرد (مدلهای فشرده، کوانتیزهسازی، کش محلی).

دیدگاهتان را بنویسید