
در بسیاری از پروژههای مبتنی بر LLM، مخصوصا سیستمهای RAG، مشکل از مدل زبانی نیست؛ از جایی شروع میشود که دادهها باید بازیابی شوند. تیمها اغلب بعد از پیادهسازی اولیه متوجه میشوند پاسخها ناپایدار است، دقت کاهش پیدا میکند یا با افزایش داده، عملکرد سیستم افت میکند. اینجاست که انتخاب نادرست زیرساخت جستوجوی برداری میتواند کل معماری RAG را به بنبست برساند. Pinecone دقیقا در همین نقطه وارد بازی میشود؛ نه بهعنوان یک دیتابیس ساده، بلکه بهعنوان بخشی تعیینکننده از موفقیت یا شکست سیستم.
در این مقاله بررسی میکنیم Pinecone چیست، چرا در معماریهای RAG نقش حیاتی دارد و چه تفاوتی با راهحلهای سادهتر یا لوکال ایجاد میکند. همچنین میبینیم در چه سناریوهایی نبود Pinecone (یا ابزار مشابه حرفهای) باعث افت کیفیت، هزینههای پنهان یا شکست کامل پروژه میشود و در نهایت با یک دید عملی به نحوهی استفاده از آن در کنار LLMها میرسیم.
Pinecone چیست؟
Pinecone یک پایگاه داده برداری مدیریتشده (Fully Managed) است که برای ذخیره، ایندکسگذاری و جستوجوی بردارهای embedding در مقیاس بالا طراحی شده است. این ابزار بهطور خاص برای سیستمهای مبتنی بر LLM و معماری RAG ساخته شده و تمرکز آن روی جستوجوی معنایی سریع و دقیق است.
برخلاف دیتابیسهای عمومی که بعدا قابلیت جستجوی برداری به آنها اضافه شده، Pinecone از ابتدا برای کار با دادههای برداری طراحی شده است. همین موضوع باعث میشود در پروژههایی که کیفیت retrieval اهمیت دارد، عملکرد پایدارتر و قابل پیشبینیتری داشته باشد.

Pinecone چه مشکلی را حل میکند؟
در پروژههای هوش مصنوعی، دادهها معمولا به embedding تبدیل میشوند. چالش اصلی اینجاست که:
- چگونه نزدیکترین دادهها از نظر معنایی پیدا شوند؟
- چگونه این جستوجو با افزایش داده کند نشود؟
- و چگونه سیستم در محیط production پایدار بماند؟
Pinecone این مشکلات را در سطح زیرساخت حل میکند و اجازه میدهد تیم توسعه روی منطق محصول تمرکز کند، نه روی بهینهسازی جستوجو.
چرا Pinecone برای مدلهای زبانی بزرگ (LLMها) مناسب است؟
یکی از مهمترین کاربردهای Pinecone، استفاده در سیستمهای پردازش زبان طبیعی است. Pinecone به شما کمک میکند سیستمهایی بسازید که معنای متن را درک کنند و متون مشابه را بر اساس شباهت معنایی بازیابی کنند.
همین قابلیت، Pinecone را به گزینهای ایدئال برای LLMها تبدیل میکند.
با استفاده از Pinecone میتوانید حافظه بلندمدت به مدلهای زبانی اضافه کنید. مثلا:
- یک مدل عمومی مثل GPT-4 دارید
- دادههای اختصاصی خودتان را داخل Pinecone ذخیره میکنید
- مدل هنگام پاسخگویی، اسناد مرتبط را از دیتابیس برداری بازیابی میکند
این فرایند بخش مهمی از ساخت سیستمهای مبتنی بر LLM و RAG است و امکان شخصیسازی پاسخها را فراهم میکند. همچنین Pinecone بهراحتی با ابزارهایی مثل LangChain یکپارچه میشود که ترکیب چند مدل زبانی و زنجیرههای پردازشی را سادهتر میکند.
تفاوت Pinecone با دیتابیسهای سنتی
دیتابیسهای SQL یا NoSQL برای جستوجوی دقیق (Exact Match) مناسباند، نه جستوجوی معنایی.
در مقابل، Pinecone مستقیما روی بردارهای با ابعاد بالا کار میکند و شباهت مفهومی بین دادهها را مبنای بازیابی قرار میدهد؛ چیزی که برای RAG حیاتی است.
نقش Pinecone در معماری RAG
در معماری RAG، کیفیت مرحله retrieval مستقیما روی کیفیت پاسخ LLM اثر میگذارد. اگر داده مرتبط بهدرستی بازیابی نشود، حتی پیشرفتهترین مدل زبانی هم پاسخ دقیقی تولید نخواهد کرد.
بهبود دقت Semantic Search
Pinecone با ایندکسهای بهینهشده برای embeddingها، این امکان را فراهم میکند که:
- مرتبطترین دادهها با سرعت بالا پیدا شوند
- نتایج جستوجو پایدار و قابل تکرار باشند
- کیفیت retrieval با رشد دیتاست افت نکند
استفاده از metadata و namespace
در پروژههای واقعی، داده فقط متن نیست. Pinecone امکان فیلترگذاری بر اساس metadata (مثل منبع، نوع محتوا یا تاریخ) را فراهم میکند.
همچنین با استفاده از namespace میتوان دادههای مربوط به کاربران یا پروژههای مختلف را از هم جدا کرد.
کاهش Hallucination در LLM
Pinecone مستقیما hallucination را حذف نمیکند، اما با بهبود retrieval، احتمال تولید پاسخهای حدسی را کاهش میدهد. وقتی LLM به دادهی مرتبط دسترسی دارد، کمتر مجبور به «حدس زدن» میشود.
چرا Pinecone برای پروژههای RAG حیاتی است؟
بسیاری از پروژههای RAG در مرحلهی prototype خوب کار میکنند اما در production با مشکل مواجه میشوند. دلیل اصلی این شکست معمولا مدل زبانی نیست، بلکه ضعف در لایه vector database است.
مشکل مقیاسپذیری
با افزایش حجم داده:
- جستوجوی لوکال کند میشود
- latency بالا میرود
- تجربه کاربر افت میکند
Pinecone این چالش را با معماری مقیاسپذیر خود برطرف میکند.
کاهش هزینهی LLM
retrieval ضعیف باعث میشود:
- context نامربوط به LLM ارسال شود
- prompt طولانیتر شود
- مصرف token و هزینه افزایش پیدا کند
با بهبود کیفیت retrieval، Pinecone بهصورت غیرمستقیم هزینه استفاده از LLM را کاهش میدهد.
تبدیل RAG از دمو به محصول
Pinecone کمک میکند RAG از یک نمونه آزمایشی جذاب به یک سیستم production-ready تبدیل شود؛ سیستمی که هم قابل اعتماد است و هم قابل توسعه.
ویژگیهای کلیدی Pinecone
بیایید ببینیم چه چیزی Pinecone را به ابزاری کاربردی و محبوب تبدیل کرده است:
سرویس کاملا مدیریتشده (Fully Managed)
Pinecone یک پلتفرم کاملا مدیریتشده است؛ یعنی تمام مسائل مربوط به زیرساخت، نگهداری و مقیاسپذیری را خودش مدیریت میکند. این موضوع باعث میشود توسعهدهندگان بدون درگیری با پیچیدگیهای عملیاتی، روی توسعه و استقرار اپلیکیشنهای یادگیری ماشین تمرکز کنند.
مقیاسپذیری بالا (Scalability)
Pinecone توانایی مدیریت میلیاردها بردار با ابعاد بالا را دارد و از مقیاسپذیری افقی پشتیبانی میکند. به همین دلیل، برای بارهای کاری سنگین و پروژههای بزرگ یادگیری ماشین کاملا مناسب است.
ورود داده بهصورت بلادرنگ (Real-time Data Ingestion)
Pinecone از ingest شدن دادهها بهصورت real-time پشتیبانی میکند. این یعنی میتوانید دادههای جدید را بدون توقف سرویس ذخیره و ایندکس کنید.
جستجوی سریع با تاخیر کم (Low-latency Search)
با استفاده از الگوریتمهای پیشرفته ایندکسگذاری، Pinecone جستجوهای نزدیکترین همسایه (Nearest Neighbor) و جستجوی شباهت را با تاخیر بسیار کم انجام میدهد؛ موضوعی حیاتی برای اپلیکیشنهای حساس به زمان.
یکپارچگی آسان (Seamless Integration)
APIهای Pinecone ساده و شهودی طراحی شدهاند و بهراحتی با جریانهای کاری یادگیری ماشین و پایپلاینهای داده موجود یکپارچه میشوند.
مفاهیم پایه در کار با Pinecone
برای استفاده از Pinecone، قبل از هر چیز باید با مفاهیم پایهای آن آشنا شویم. Pinecone برخلاف دیتابیسهای سنتی، حول محور indexهای برداری طراحی شده و همهچیز از همین نقطه شروع میشود.
۱. ساخت Index در Pinecone
Index در Pinecone محلی است که embeddingها داخل آن ذخیره و جستوجو میشوند. هر index برای یک نوع داده یا یک کاربرد مشخص ساخته میشود؛ مثلا یک index برای اسناد پشتیبانی، یا یک index جداگانه برای محتوای بلاگ.
نکته مهم این است که ساخت index معمولا نیاز است فقط یکبار انجام شود و بعد از آن دادهها بهصورت تدریجی به آن اضافه میشوند.
۲. انتخاب Dimension (بُعد بردارها)
Dimension به تعداد مولفههای هر embedding اشاره دارد. این عدد باید دقیقا با مدل embedding شما یکی باشد.
مثلا:
- اگر از مدلهایی با خروجی ۷۶۸ بعدی استفاده میکنید ← dimension = 768
- اگر از embeddingهای ۱۵۳۶ یا ۳۰۷۲ بعدی استفاده شود ← dimension هم باید همان باشد
انتخاب اشتباه dimension باعث میشود دادهها اصلا قابل ذخیره یا جستوجو نباشند. به همین دلیل، Pinecone از همان ابتدا شما را مجبور میکند این تصمیم را آگاهانه بگیرید.
۳. انتخاب Metric (معیار شباهت)
Metric مشخص میکند Pinecone «شباهت» بین بردارها را چگونه محاسبه کند. رایجترین گزینهها عبارتاند از:
- Cosine similarity: مناسب اغلب کاربردهای متنی و جستجوی معنایی
- Dot product: زمانی مفید است که embeddingها نرمالسازی شده باشند
- Euclidean distance: بیشتر در کاربردهای خاص ریاضی یا علمی استفاده میشود
در اغلب پروژههای مبتنی بر LLM و RAG، Cosine انتخاب پیشفرض و امنتری است.
نصب و شروع کار با Pinecone در Python
برای شروع کار با Pinecone، کافی است به وبسایت pinecone.io مراجعه کنید و یک حساب کاربری رایگان بسازید.
پس از ثبتنام موفق، از منوی پنل کاربری وارد بخش API Keys شوید و مقدار Environment و API Key را کپی کنید. این اطلاعات برای کار با کلاینت Python در Pinecone استفاده میشوند.
۱. نصب کلاینت Python
برای استفاده از Pinecone در پایتون، باید کلاینت رسمی آن را نصب کنید:
|
1 |
pip install pinecone–client |
۲. بررسی و تنظیم API Key در Pinecone
برای استفاده از Pinecone در Python، داشتن API Key الزامی است. این کلید را میتوانید از بخش API Keys در کنسول Pinecone دریافت کنید. در همان صفحه، اطلاعات مربوط به environment پروژه نیز نمایش داده میشود.
|
1 2 |
import pinecone pinecone.init(api_key=“API_KEY”, environment=“ENVIRONMENT”) |
۳. ساخت Index در Pinecone
برای ساخت یک index جدید در Pinecone، دستور زیر را اجرا کنید:
|
1 |
pinecone.create_index(“myfirstindex”, dimension=8, metric=“euclidean”) |
به محض اجرای این دستور، یک index جدید در پنل Pinecone شما ایجاد میشود.
۴. افزودن داده و جستوجو در Pinecone
برای اضافهکردن بردارها به index، از عملیات upsert استفاده میشود. این عملیات اگر برداری با همان شناسه وجود داشته باشد آن را بهروزرسانی میکند و در غیر این صورت، بردار جدید اضافه میکند.
|
1 2 3 4 5 6 7 8 9 |
index = pinecone.Index(“myfirstindex”) index.upsert([ (“A”, [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1]), (“B”, [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]), (“C”, [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]), (“D”, [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]), (“E”, [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]) ]) |
پس از اجرای این دستور، بردارها در کنسول Pinecone قابل مشاهده هستند.
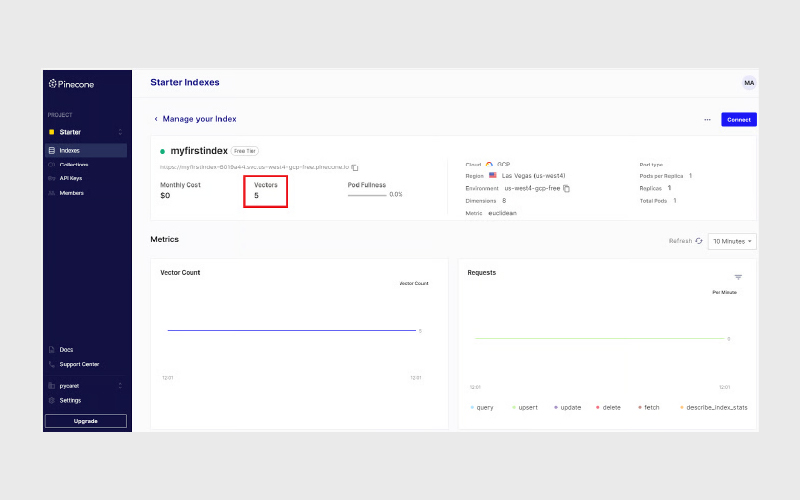
۵. بررسی وضعیت Index
برای مشاهده اطلاعات index، از جمله تعداد بردارها و dimension، میتوانید از دستور زیر استفاده کنید:
|
1 |
index.describe_index_stats() |
خروجی نمونه:
|
1 2 3 4 5 6 |
{ ‘dimension’: 8, ‘index_fullness’: 0.0, ‘namespaces’: {”: {‘vector_count’: 5}}, ‘total_vector_count’: 5 } |
۶. جستوجوی بردارهای مشابه در Pinecone
در مثال زیر، یک بردار ۸بعدی برای پیدا کردن ۳ بردار مشابهتر جستوجو میشود. معیار شباهت همان Euclidean است که هنگام ساخت index انتخاب شده بود.
|
1 2 3 4 5 |
index.query( vector=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3], top_k=3, include_values=True ) |
۷. حذف Index در Pinecone
اگر دیگر به index نیازی ندارید، میتوانید آن را بهصورت کامل حذف کنید:
|
1 |
pinecone.delete_index(“myfirstindex”) |
استفاده عملی از Pinecone در Python (از Upsert تا Query)
بعد از اینکه Pinecone را نصب و index را ایجاد کردیم، وقت آن است که ببینیم در عمل چطور با آن کار میکنیم و دادهها را وارد، جستوجو و مدیریت میکنیم.
۱. اتصال به Pinecone
اولین قدم، برقراری اتصال به سرویس Pinecone است. این اتصال معمولا با استفاده از API Key و مشخصات index انجام میشود و بعد از آن، شما میتوانید عملیات مختلف را روی index انجام دهید.
در این مرحله، Pinecone نقش «موتور جستوجوی برداری» پروژهی شما را بازی میکند.
۲. Upsert: اضافهکردن دادهها
در Pinecone، عملیات درج داده با مفهوم upsert انجام میشود.
Upsert یعنی:
- اگر برداری وجود نداشته باشد ← اضافه شود
- اگر وجود داشته باشد ← بهروزرسانی شود
هر داده معمولا شامل:
- یک id
- یک embedding (بردار عددی)
- و در صورت نیاز metadata (مثل منبع، نوع محتوا یا تاریخ)
این مدل باعث میشود مدیریت دادهها سادهتر و مقیاسپذیرتر باشد.
۳. Query: جستوجوی برداری
Query قلب Pinecone است. در این مرحله:
- یک متن یا ورودی دریافت میشود
- به embedding تبدیل میشود
- Pinecone نزدیکترین بردارها را بر اساس metric انتخابشده پیدا میکند
نتیجهی query معمولا شامل:
- دادههای مشابه
- میزان شباهت (score)
- و metadata مرتبط
در سناریوهای RAG، خروجی Query معمولا مستقیما به مدل زبانی (LLM) داده میشود تا پاسخ نهایی بر اساس دادههای بازیابیشده تولید شود.
۴. استفاده همراه Embeddingها
Pinecone خودش embedding تولید نمیکند؛ بلکه با امبدینگهایی که از مدلهایی مثل OpenAI، Hugging Face یا Sentence Transformers میگیرید کار میکند.
جریان معمول به این شکل است:
- متن ← embedding
- embedding ← Pinecone
- Pinecone ← دادههای مرتبط
- دادههای مرتبط ← LLM
همین تفکیک مسئولیتها باعث شده Pinecone بهراحتی با ابزارهایی مثل LangChain و LlamaIndex یکپارچه شود.
مثال عملی: استفاده از Pinecone بهعنوان Vector Store در LangChain
در این مثال، Pinecone نقش دیتابیس برداری را دارد و LangChain مسئول ساخت embedding، ذخیرهسازی و جستجوی شباهت است. این سناریو یکی از رایجترین الگوها برای پیادهسازی RAG (Retrieval-Augmented Generation) است.
۱. نصب وابستگیها
|
1 |
pip install langchain pinecone–client openai tiktoken |
۲. مقداردهی اولیه Pinecone
|
1 2 3 4 5 6 |
import pinecone pinecone.init( api_key=“PINECONE_API_KEY”, environment=“PINECONE_ENV” ) |
اگر ایندکس از قبل وجود ندارد، آن را ایجاد میکنیم:
|
1 2 3 4 5 |
pinecone.create_index( name=“langchain-demo”, dimension=1536, metric=“cosine” ) |
عدد ۱۵۳۶ مربوط به embeddingهای مدل text-embedding-3-small یا ada-002 است.
۳. ساخت VectorStore با LangChain
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from langchain.vectorstores import Pinecone from langchain.embeddings.openai import OpenAIEmbeddings embeddings = OpenAIEmbeddings() index = pinecone.Index(“langchain-demo”) vectorstore = Pinecone( index=index, embedding=embeddings, text_key=“text” ) |
در این مرحله:
- LangChain embedding میسازد
- Pinecone فقط ذخیره و جستجو میکند
۴. اضافه کردن داده به Pinecone
|
1 2 3 4 5 6 7 |
texts = [ “Pinecone یک دیتابیس برداری برای جستجوی شباهت است.”, “LangChain به سادهسازی کار با LLMها کمک میکند.”, “ترکیب Pinecone و LangChain برای RAG بسیار رایج است.” ] vectorstore.add_texts(texts) |
اینجا:
- متنها embedding میشوند
- بردارها داخل Pinecone ذخیره میشوند
۵. جستجوی برداری (Similarity Search)
|
1 2 3 4 5 6 |
query = “Pinecone چه کاربردی دارد؟” docs = vectorstore.similarity_search(query, k=2) for doc in docs: print(doc.page_content) |
خروجی، مرتبطترین متنها بر اساس شباهت برداری است.
۶. استفاده در زنجیره پرسشوپاسخ (اختیاری)
|
1 2 3 4 5 6 7 8 9 |
from langchain.chains import RetrievalQA from langchain.llms import OpenAI qa_chain = RetrievalQA.from_chain_type( llm=OpenAI(), retriever=vectorstore.as_retriever() ) qa_chain.run(“Pinecone در LangChain چه نقشی دارد؟”) |
در این حالت:
- Pinecone داده مرتبط را پیدا میکند
- LangChain آن را به LLM میدهد
- پاسخ نهایی تولید میشود
جمعبندی
عرضه Pinecone در سال ۲۰۲۱ اتفاق افتاد؛ زمانی که شاید هنوز تب generative AI به اوج نرسیده بود. اما با رشد چشمگیر هوش مصنوعی مولد از نیمه دوم ۲۰۲۲ و افزایش توجه به دیتابیسهای برداری، Pinecone بهسرعت به یکی از رهبران این صنعت تبدیل شد.
در ابتدا، بیشتر کاربردهای Pinecone حول جستجوی معنایی میچرخید. اما امروز دامنه کاربران آن بسیار گستردهتر شده است؛ از علاقهمندان و پژوهشگران گرفته تا مهندسان ML، دیتا ساینتیستها و مهندسان سیستم که روی چتباتها، مدلهای زبانی بزرگ و پروژههای generative AI کار میکنند.
منابع
سوالات متداول
خیر. Pinecone یک سرویس کاملا مدیریتشده است و نیازی به راهاندازی یا نگهداری سرور، ایندکسها یا تنظیمات زیرساختی ندارد.
Pinecone پلن رایگان دارد که برای تست، یادگیری و پروژههای کوچک مناسب است. برای استفاده در مقیاس بزرگ، پلنهای پولی ارائه میدهد.
مهمترین تفاوت Pinecone با گزینههای متنباز:
کاملا مدیریتشده بودن
تمرکز بالا روی مقیاسپذیری و performance
مناسب بودن برای محیطهای production
در حالی که Chroma یا Milvus گزینههای خوبی برای لوکال و پروژههای متنباز هستند.
خیر. Pinecone میتواند embedding مربوط به متن، تصویر، صوت یا هر دادهای که به بردار تبدیل شود را ذخیره و جستجو کند.
بله. Pinecone بهطور خاص برای جستجو با تاخیر کم (low-latency) طراحی شده و در سناریوهای real-time عملکرد بسیار خوبی دارد.


دیدگاهتان را بنویسید