با رشد مدلهای زبانی بزرگ و سیستمهای RAG، حجم دادههایی که این مدلها پردازش میکنند بهشدت افزایش یافته است. یکی از چالشهای اصلی در این حوزه، مدیریت و سازماندهی اطلاعات برای دسترسی سریع و دقیق است. تکنیک قطعهبندی (Chunking) با تقسیم دادهها به بخشهای کوچک و قابل مدیریت، این مشکل را برطرف میکند و عملکرد مدلهای زبانی و سیستمهای RAG را بهبود میبخشد.
در این مقاله، به بررسی مفهوم قطعهبندی در زمینه مدلهای زبانی و RAG میپردازیم، مزایای آن را در پردازش و بازیابی اطلاعات توضیح میدهیم و روشهای کاربردی برای پیادهسازی این تکنیک در پروژههای مبتنی بر هوش مصنوعی را ارائه میکنیم.
چانکینگ (Chunking) چیست؟

در زمینه ساخت برنامههای مرتبط با مدلهای زبانی بزرگ (LLM)، قطعهبندی به فرایند تقسیم متنهای بزرگ به بخشهای کوچکتر گفته میشود که به آنها قطعه (Chunk) میگوییم.
این تکنیک پیشپردازشی اهمیت زیادی دارد و به بهینهسازی مرتبط بودن محتوایی که در نهایت در یک پایگاه داده برداری ذخیره میشود، کمک میکند. نکته اصلی در یافتن قطعاتی است که هم به اندازه کافی بزرگ باشند تا اطلاعات معنیدار داشته باشند و هم به اندازه کافی کوچک باشند تا برنامهها با کارایی بالا و پاسخهای سریع برای پردازشهایی مانند RAG داشته باشند.
چرا برنامههای ما به قطعهبندی نیاز دارند؟
دو دلیل اصلی برای ضرورت قطعهبندی در هر برنامهای که از پایگاههای داده برداری یا مدلهای زبانی بزرگ استفاده میکند، وجود دارد:
۱. تضمین اینکه مدلهای embedding بتوانند دادهها را در پنجره زمینهای خود جای دهند.
۲. اطمینان از اینکه خود قطعات شامل اطلاعات لازم برای جستجو هستند.
تمام مدلهای embedding دارای پنجرههای زمینهای (context window) هستند که تعیین میکند چه مقدار اطلاعات به شکل توکن میتواند در یک بردار با اندازه ثابت پردازش شود. اگر این پنجره بیش از حد پر شود، توکنهای اضافی ممکن است قبل از اینکه به بردار تبدیل شوند، قطع شده یا حذف شوند. این مسئله میتواند ضررهایی داشته باشد؛ زیرا ممکن است بخش مهمی از زمینه متن حذف شود و در نتیجه در جستجو نمایش داده نشود.
علاوه بر این، فقط تنظیم اندازه دادهها برای مدل کافی نیست؛ قطعات حاصل باید شامل اطلاعاتی باشند که برای جستجو مرتبط هستند. اگر قطعه شامل مجموعهای از جملات باشد که بدون زمینه معنی ندارند، ممکن است هنگام پرسوجو ظاهر نشوند.
نقش قطعهبندی در جستجوی معنایی
بهعنوان مثال، در جستجوی معنایی (Semantic Search)، یک مجموعه از اسناد را ایندکس میکنیم که هر سند شامل اطلاعات ارزشمند در مورد یک موضوع خاص است. به دلیل نحوه عملکرد مدلهای embedding، این اسناد باید قطعهبندی شوند و تشابه با بردار پرسوجوی ورودی بر اساس مقایسه سطح قطعه تعیین میشود. سپس این قطعات مشابه به کاربر بازگردانده میشوند.
با یافتن یک استراتژی موثر چانکینگ، میتوانیم اطمینان حاصل کنیم که نتایج جستجو بهطور دقیق گستره پرسوجوی کاربر را نشان میدهند.
اگر قطعات بسیار کوچک یا بسیار بزرگ باشند، ممکن است منجر به نتایج جستجوی نادقیق یا از دست رفتن فرصت نمایش محتوای مرتبط شود. یک قانون ساده این است: اگر قطعه متن بدون زمینه اطراف برای یک انسان معنی داشته باشد، برای مدل زبانی هم قابل درک خواهد بود. بنابراین، تعیین اندازه بهینه قطعهها برای اسناد موجود در مجموعه، برای دقت و مرتبط بودن نتایج جستجو حیاتی است.
نقش قطعهبندی در برنامههای عاملمحور و RAG
عاملها (Agents) ممکن است برای دسترسی به اطلاعات بهروز از پایگاههای داده، فراخوانی ابزارها، تصمیمگیری و پاسخ به پرسوجوهای کاربر به قطعات اطلاعات نیاز داشته باشند. قطعات بازیابیشده از جستجوها، در طول اجرای برنامه، اطلاعات زمینهای لازم را در اختیار عامل قرار میدهند و پاسخهای او را دقیقتر میکنند.
ما از قطعات embed شده برای ساخت زمینه بر اساس پایگاه دانش در دسترس عامل استفاده میکنیم. این زمینه، پاسخهای عامل را بر اطلاعات معتبر و قابل اعتماد پایهگذاری میکند.
مشابه جستجوی معنایی که برای ارائه خروجیهای قابل استفاده نیاز به استراتژی قطعهبندی مناسب دارد، برنامههای عاملمحور نیز برای پیشروی نیازمند قطعات معنادار اطلاعات هستند. اگر به یک عامل اطلاعات غلط داده شود یا دادهها بدون زمینه کافی ارائه شوند، ممکن است توکنها هدر بروند، اطلاعات خیالی تولید شود یا ابزارهای اشتباه فراخوانی شوند.
نقش قطعهبندی در مدلهای زبانی با زمینه طولانی
در برخی موارد، مانند استفاده از مدلهای o1 یا Claude 4 Sonnet با پنجره زمینه ۲۰۰ هزار توکن، ممکن است اسناد بدون قطعهبندی هم در پنجره زمینه جا شوند. با این حال، استفاده از قطعات بزرگ میتواند زمان پاسخدهی را افزایش داده و هزینههای پردازشی را بالا ببرد.
علاوه بر این، مدلهای embedding و LLM با زمینه طولانی گاهی با مشکل Lost-in-the-Middle مواجه میشوند؛ یعنی اطلاعات مهمی که در میانه اسناد طولانی پنهان شدهاند، حتی اگر در تولید محتوا لحاظ شوند، از دست میروند. راه حل این مشکل، اطمینان از ارسال میزان بهینهای از اطلاعات به LLM پاییندست است که هم زمان پاسخدهی را کاهش میدهد و هم کیفیت خروجی را تضمین میکند.
هنگام انتخاب استراتژی قطعهبندی باید به چه نکاتی توجه کنیم؟
چند عامل در تعیین بهترین استراتژی قطعهبندی نقش دارند و این عوامل بسته به نوع کاربرد متفاوت هستند. برخی نکات کلیدی عبارتاند از:
- نوع دادهای که قرار است قطعهبندی شود چیست؟
آیا با اسناد طولانی مانند مقالات یا کتابها کار میکنید یا محتوای کوتاه مثل توییتها، توضیحات محصول یا پیامهای چت؟ اسناد کوتاه ممکن است نیازی به قطعهبندی نداشته باشند، در حالی که اسناد طولانی ممکن است ساختار خاصی مانند زیرعنوانها یا فصلها داشته باشند که استراتژی قطعهبندی را مشخص میکند.
- از کدام مدل embedding استفاده میکنید؟
مدلهای embedding مختلف ظرفیتهای متفاوتی برای پردازش اطلاعات دارند، بهویژه در حوزههای تخصصی مانند کد، مالی، پزشکی یا حقوقی. روش آموزش مدلها نیز میتواند تاثیر زیادی بر عملکرد آنها داشته باشد. پس از انتخاب مدل مناسب برای حوزه خود، مطمئن شوید که استراتژی قطعهبندی با نوع اسنادی که مدل بر روی آنها آموزش دیده، همخوانی دارد.
- انتظارات شما از طول و پیچیدگی پرسوجوهای کاربران چیست؟
پرسوجوها کوتاه و مشخص هستند یا طولانی و پیچیده؟ این عامل میتواند نحوه قطعهبندی محتوا را تحتتاثیر قرار دهد تا همبستگی بهتری بین پرسوجوی embed شده و قطعات embed شده ایجاد شود.
- نتایج بازیابیشده چگونه در برنامه شما استفاده خواهند شد؟
آیا برای جستجوی معنایی، پاسخ به پرسش، تولید متن با بازیابی (RAG) یا جریان کاری عاملمحور استفاده میشوند؟ مثلا میزان اطلاعاتی که یک انسان از یک نتیجه جستجو بررسی میکند ممکن است کمتر یا بیشتر از نیاز یک LLM برای تولید پاسخ باشد. این عوامل تعیین میکنند دادهها چگونه باید در پایگاه داده برداری نمایش داده شوند.
پیش از شروع، پاسخ به این پرسشها به شما کمک میکند استراتژی قطعهبندیای انتخاب کنید که تعادلی بین عملکرد و دقت برقرار کند.
embedding محتوای کوتاه و بلند
هنگام embed کردن محتوا، رفتار متفاوتی بسته به کوتاه یا بلند بودن محتوا انتظار میرود:
- وقتی جملهای embed میشود: بردار حاصل روی معنای خاص همان جمله تمرکز دارد. این برای مواردی مانند ردهبندی جملات، سیستمهای پیشنهاددهنده یا برنامههایی که امکان جستجوی خلاصههای کوتاه قبل از پردازش اسناد طولانی را میدهند، مفید است. در این حالت، فرایند جستجو یافتن جملاتی است که از نظر معنا به جملات یا پرسوجوهای ورودی شباهت دارند. اگر هر جمله بهعنوان یک سند مستقل در نظر گرفته شود، نیازی به قطعهبندی نیست.
- وقتی پاراگراف یا سند کامل embed میشود: فرایند embedding هم زمینه کلی متن و هم روابط بین جملات و عبارات را در نظر میگیرد. این میتواند منجر به برداری جامعتر شود که معنای کلی و موضوعات اصلی متن را نشان دهد. از سوی دیگر، اندازه متن بزرگتر ممکن است نویز ایجاد کند یا اهمیت جملات و عبارات فردی را کاهش دهد و یافتن تطابق دقیق هنگام جستجو را دشوار کند. این قطعات برای کاربردهایی مانند پاسخ به پرسش که پاسخ ممکن است چند پاراگراف باشد، مفیدند. بسیاری از برنامههای مدرن هوش مصنوعی با اسناد طولانی کار میکنند که تقریبا همیشه نیاز به قطعهبندی دارند.
پسپردازش قطعات با گسترش قطعه (Chunk Expansion)
مهم است بدانید که به استراتژی قطعهبندی خود محدود نیستید. هنگام پرسوجو از دادههای قطعهبندی شده در یک پایگاه داده برداری، اطلاعات بازیابی شده معمولا قطعات مشابه معنایی برتر هستند. اما کاربران، عاملها یا مدلهای زبانی ممکن است برای تفسیر صحیح قطعه به زمینه بیشتر اطراف آن نیاز داشته باشند.
گسترش قطعه یک روش ساده برای پسپردازش دادههای قطعهبندی شده است. در این روش، قطعات همسایه در یک پنجره برای هر قطعه بازیابی شده گرفته میشوند. بسته به مورد استفاده، قطعات میتوانند به پاراگراف، صفحات یا حتی کل سند گسترش یابند.
استفاده همزمان از یک استراتژی قطعهبندی مناسب و گسترش قطعه در هنگام پرسوجو میتواند جستجوی با تاخیر کم را بدون از دست دادن زمینه تضمین کند.
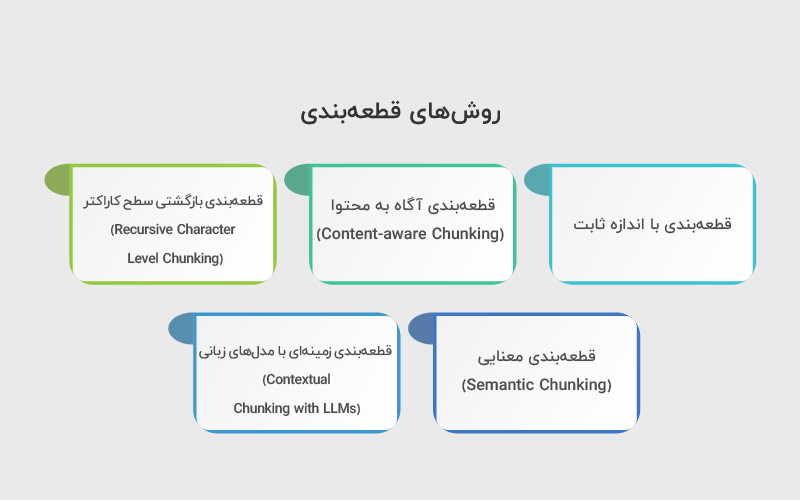
روشهای قطعهبندی
هدف از چانکینگ، بهبود پردازش و بازیابی اطلاعات در مدلهای زبانی و سیستمهای مبتنی بر embedding است. هر روش قطعهبندی نقاط قوت و محدودیتهای خود را دارد و انتخاب مناسب آن به نوع داده، اندازه متن، مدل embedding و کاربرد نهایی بستگی دارد.
با توجه به این نکات، چند روش رایج برای قطعهبندی وجود دارد که هر کدام برای شرایط خاصی مناسب است:
۱. قطعهبندی با اندازه ثابت
این رایجترین و سادهترین روش برای قطعهبندی است: ما به سادگی تعداد توکنهای هر قطعه را تعیین میکنیم و اسناد خود را بر اساس این تعداد به قطعات با اندازه ثابت تقسیم میکنیم. معمولا این تعداد، حداکثر اندازه پنجره زمینه مدل embedding است (مثلا ۱۰۲۴ برای llama-text-embed-v2 یا ۸۱۹۶ برای text-embedding-3-small). توجه داشته باشید که مدلهای مختلف embedding ممکن است متن را به شکل متفاوتی توکنبندی کنند، بنابراین باید تعداد توکنها را دقیق برآورد کنید.
قطعهبندی با اندازه ثابت در اغلب موارد بهترین گزینه است و توصیه میشود با این روش شروع کرده و فقط در صورت ناکافی بودن آن، روش خود را تغییر دهید.
۲. قطعهبندی آگاه به محتوا (Content-aware Chunking)
هرچند قطعهبندی با اندازه ثابت ساده است، ممکن است ساختار مهم درون اسناد را نادیده بگیرد که میتواند برای تعیین قطعات مرتبط مفید باشد. قطعهبندی آگاه به محتوا به استراتژیهایی گفته میشود که ساختار متن را در نظر میگیرند تا معنای قطعات بهتر حفظ شود.
تقسیمبندی ساده جملات و پاراگرافها
همانطور که قبلا گفتیم، برخی مدلهای embedding برای امبدینگ محتوا در سطح جمله بهینه شدهاند. اما گاهی جملات باید از مجموعه دادههای متنی بزرگ استخراج شوند که از قبل پردازش نشدهاند. در این موارد، استفاده از قطعهبندی جملات ضروری است و روشها و ابزارهای مختلفی برای این کار وجود دارد:
- تقسیمبندی ساده (Naive splitting): سادهترین روش، تقسیم متن بر اساس نقطه (.)، خطوط جدید یا فاصله سفید است.
- NLTK: کتابخانه محبوب پایتون برای کار با دادههای زبانی انسان است. این کتابخانه دارای توکنایزر جملات آموزشدیدهای است که میتواند متن را به جملات تقسیم کند و به ایجاد قطعات معنادار کمک کند.
- spaCy: کتابخانه قدرتمند دیگری برای پردازش زبان طبیعی در پایتون است. spaCy ابزار پیشرفتهای برای تقسیمبندی جملات دارد که متن را به شکل موثر به جملات جداگانه تقسیم میکند و زمینه (context) را در قطعات حفظ میکند.
۳. قطعهبندی بازگشتی سطح کاراکتر (Recursive Character Level Chunking)
کتابخانه LangChain دارای ابزار RecursiveCharacterTextSplitter است که سعی میکند متن را با استفاده از جداکنندهها در یک ترتیب مشخص تقسیم کند. رفتار پیشفرض این ابزار از جداکنندههای [“\n\n”, “\n”, ” “, “”] برای تقسیم پاراگرافها، جملات و کلمات استفاده میکند، بسته به اندازه تعیینشده برای قطعه.
این روش یک راه عالی بین تقسیم همیشه بر اساس یک کاراکتر مشخص و استفاده از تقسیمبندی معناییتر است، در حالی که در صورت امکان اندازه ثابت قطعات را نیز حفظ میکند.
قطعهبندی مبتنی بر ساختار سند
هنگام قطعهبندی اسناد بزرگ مانند PDF، DOCX، HTML، قطعههای کد، فایلهای Markdown و LaTeX، روشهای تخصصی میتوانند ساختار اصلی محتوا را هنگام ایجاد قطعات حفظ کنند.
- PDF: اسناد PDF شامل هدرها، متن، جدول و بخشهای مختلفی هستند که نیاز به پیشپردازش دارند. LangChain ابزارهای مفیدی برای پردازش این اسناد دارد و Pinecone Assistant نیز میتواند آنها را قطعهبندی و پردازش کند.
- HTML: صفحات وب جمعآوریشده میتوانند تگهایی مانند <p> برای پاراگرافها یا <title> برای عنوانها داشته باشند که برای تقسیمبندی متن مفیدند، مثلا در صفحات محصول یا بلاگها. میتوانید خودتان parser بسازید یا از تقسیمکنندههای LangChain استفاده کنید.
- Markdown: بهعنوان زبان نشانهگذاری سبک است که معمولا برای فرمتبندی متن استفاده میشود. با شناسایی ساختار Markdown (مانند تیترها، لیستها و بلوکهای کد)، میتوانید محتوا را به شکل هوشمندانه بر اساس ساختار و سلسلهمراتب آن تقسیم کنید و قطعات معنایی بهتری ایجاد کنید.
- LaTeX: نوعی از سیستم آمادهسازی سند و زبان نشانهگذاری برای مقالات علمی و اسناد فنی است. با تحلیل دستورات و محیطهای LaTeX، میتوانید قطعاتی ایجاد کنید که سازمان منطقی محتوا (مثل بخشها، زیربخشها و معادلات) را رعایت کنند و نتایج دقیقتر و مرتبطتری به دست آید.
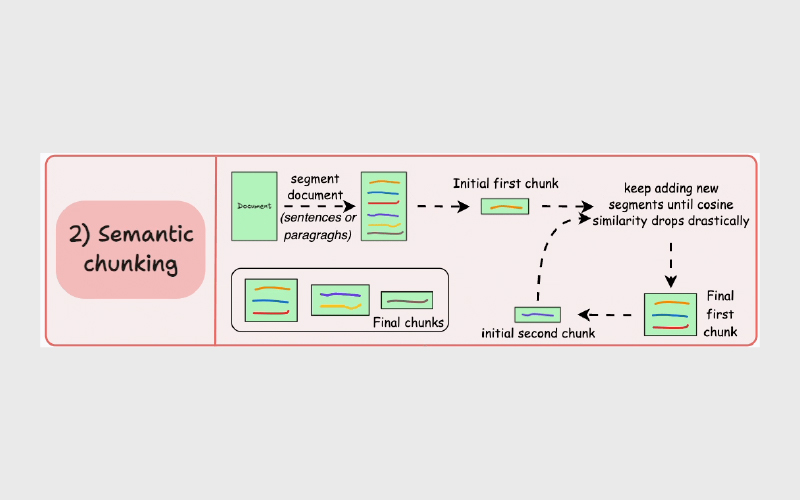
۴. قطعهبندی معنایی (Semantic Chunking)
یک تکنیک تجربی جدید برای قطعهبندی ابتدا توسط Greg Kamradt معرفی شد. در دفترچه یادداشت خود، کامرادت به درستی اشاره میکند که استفاده از یک اندازه ثابت قطعه ممکن است مکانیزمی ساده و ناکافی برای در نظر گرفتن معنای بخشها درون سند باشد. اگر از این روش استفاده کنیم، نمیتوانیم تشخیص دهیم که آیا بخشهای ترکیب شده ارتباط معنایی با یکدیگر دارند یا خیر.
خوشبختانه، اگر شما در حال ساخت یک برنامه با مدلهای زبانی بزرگ هستید، به احتمال زیاد توانایی ایجاد embedding را دارید و embeddingها میتوانند برای استخراج معنایی دادهها مورد استفاده قرار گیرند. این تحلیل معنایی میتواند برای ایجاد قطعاتی استفاده شود که شامل جملاتی با موضوع یا تم مشترک هستند.
قطعهبندی معنایی شامل تقسیم سند به جملات، گروهبندی هر جمله با جملات اطراف آن و تولید embedding برای این گروهها است. با مقایسه فاصله معنایی بین هر گروه و گروه قبلی، میتوان نقاطی که موضوع یا تم تغییر میکند را شناسایی کرد و این نقاط حدود قطعهها را تعیین میکنند.
۵. قطعهبندی زمینهای با مدلهای زبانی (Contextual Chunking with LLMs)
گاهی اوقات، قطعهبندی اطلاعات از یک سند بزرگ و پیچیده بدون از دست رفتن کامل زمینه ممکن نیست. این وضعیت زمانی رخ میدهد که اسناد صدها صفحه دارند، موضوعات را بهطور مکرر تغییر میدهند یا نیاز به درک بخشهای مرتبط مختلف دارند. برای حل این مشکل، شرکت Anthropic در سال ۲۰۲۴ مفهوم بازیابی زمینهای (Contextual Retrieval) را معرفی کرد.
Anthropic یک نمونه Claude را با کل سند و قطعه آن راهاندازی کرد تا یک توضیح زمینهای تولید شود. این توضیح به قطعه اضافه شده و سپس embed میشود. توضیح زمینهای کمک میکند تا خلاصه سطح بالای سند در قطعه حفظ شود و این اطلاعات برای پرسوجوهای ورودی قابل دسترس باشد. برای جلوگیری از پردازش هر بار سند، این توضیح در پرامپت برای تمام قطعات لازم کش میشود.
تعیین بهترین استراتژی قطعهبندی
اگر قطعهبندی با اندازه ثابت برای برنامه شما مناسب نیست، نکات زیر میتواند کمککننده باشد:
- انتخاب بازهای از اندازه قطعهها: پس از پیشپردازش دادهها، گام بعدی انتخاب بازهای از اندازههای احتمالی برای تست است. این انتخاب باید ماهیت محتوا (پیام کوتاه یا اسناد طولانی)، مدل embedding مورد استفاده و ظرفیت آن (مثلا محدودیت توکنها) را در نظر بگیرد. هدف، یافتن تعادلی بین حفظ زمینه و دقت است. میتوانید با آزمایش اندازههای مختلف قطعه شروع کنید، شامل قطعات کوچک (مثلا ۱۲۸ یا ۲۵۶ توکن) برای ضبط اطلاعات معنایی دقیق و قطعات بزرگتر (مثلا ۵۱۲ یا ۱۰۲۴ توکن) برای حفظ زمینه بیشتر.
- ارزیابی عملکرد هر اندازه قطعه: برای تست اندازههای مختلف، میتوانید از چند شاخص (index) یا یک شاخص با چند namespace استفاده کنید. با یک مجموعه داده نماینده، embeddingها را برای اندازههای قطعه مورد نظر بسازید و در شاخص ذخیره کنید. سپس یک سری پرسوجو اجرا کنید و کیفیت و عملکرد اندازههای مختلف قطعه را مقایسه کنید. این فرایند معمولا تکراری است تا بهترین اندازه قطعه برای محتوا و پرسوجوهای مورد انتظار تعیین شود.
جمعبندی
قطعهبندی محتوا در اغلب موارد نسبتا ساده به نظر میرسد، اما وقتی وارد مسیرهای پیچیده میشوید ممکن است چالشهایی ایجاد کند. هیچ راه حل یکسانی برای همه موارد وجود ندارد و آنچه برای یک مورد کاربرد دارد، ممکن است برای مورد دیگر مناسب نباشد.
برای شروع آزمایش با استراتژیهای قطعهبندی، میتوانید یک حساب رایگان در Pinecone ایجاد کنید و از دفترچه یادداشتهای نمونه برای پیادهسازی قطعهبندی در جستجوی معنایی، تولید متن با بازیابی (RAG) یا برنامههای عاملمحور استفاده کنید.
منابع
سوالات متداول
قطعهبندی فرایندی است که متن یا سند را به بخشهای کوچکتر تقسیم میکند تا مدلهای زبانی بتوانند اطلاعات را بهتر پردازش و بازیابی کنند. بدون قطعهبندی، اسناد طولانی ممکن است خارج از محدوده پنجره زمینه (context window) مدل باشند یا اطلاعات مهم در میانه متن از دست برود.
اندازه مناسب قطعه به نوع متن، مدل embedding، و کاربرد نهایی بستگی دارد. معمولا آزمایش با چند اندازه مختلف (مثلاً ۱۲۸، ۲۵۶، ۵۱۲ توکن) و ارزیابی کیفیت جستجو یا پاسخها بهترین روش است.
بله. با روشهایی مانند گسترش قطعه (Chunk Expansion) میتوان قطعات بازیابی شده را با بخشهای اطرافشان ترکیب کرد تا زمینه بیشتر و اطلاعات دقیقتری به مدل ارائه شود.


دیدگاهتان را بنویسید