
با رشد روزافزون هوش مصنوعی و یادگیری ماشین، نیاز به ابزارهایی برای مدیریت دادههای پیچیده و غیرساختیافته بیش از پیش احساس میشود. دادههای متنی، تصویری، صوتی و حتی دادههای چندرسانهای، دیگر در قالب جداول ساده رابطهای قابل مدیریت نیستند. یکی از فناوریهای نوظهور که نقش کلیدی در این حوزه ایفا میکند، پایگاه داده برداری (Vector Database) است.
این مقاله از بلاگ آسا به بررسی هدف و کارکرد پایگاه داده برداری، معرفی نمونههای شاخص، مکانیزمهای جستجو و در نهایت کاربردهای آن در دنیای واقعی میپردازد.
تعریف و هدف پایگاه داده برداری
پایگاه داده برداری نوعی پایگاه داده تخصصی است که دادهها را بهجای کلیدها و مقادیر سنتی، در قالب بردارهای عددی ذخیره میکند. هر بردار معمولا شامل صدها یا هزاران بُعد است که ویژگیهای داده اصلی را نمایش میدهند.
هدف اصلی این پایگاه دادهها، امکان بازیابی بر اساس شباهت است. بهعنوان مثال، وقتی تصویر یک سگ را به سیستم میدهید، پایگاه داده برداری بهجای جستجو بر اساس برچسب «dog»، نزدیکترین بردارهای مشابه را پیدا میکند که ممکن است شامل تصاویر سگهای دیگر با رنگها، اندازهها و زاویههای متفاوت باشد.
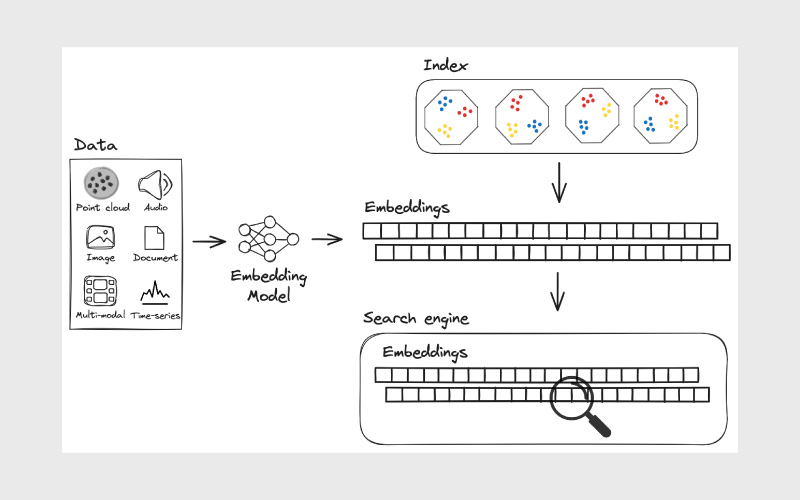
از ویژگیهای کلیدی پایگاه داده برداری:
- سرعت بالا در جستجوی دادههای حجیم حتی در میلیاردها رکورد
- قابلیت مقیاسپذیری برای دادههای چندرسانهای و ترکیبی
- انعطاف در کاربردها از موتورهای جستجو گرفته تا هوش مصنوعی تولیدی
مکانیزم داخلی: Embeddings و جستجوی برداری
پیش از آنکه پایگاه داده برداری معنا پیدا کند، باید مفهوم embedding را درک کنیم.
Embedding روشی است که دادههای پیچیده مانند متن یا تصویر را به یک بردار عددی در فضای چندبعدی تبدیل میکند. این بردار ویژگیهای معنایی و محتوایی داده را فشردهسازی و نمایش میدهد. به عنوان مثال:
- جمله «من به فوتبال علاقه دارم» ممکن است به برداری ۷۶۸ بُعدی تبدیل شود.
- جمله مشابه «بازی فوتبال جذاب است» نیز به برداری نزدیک در همان فضا نگاشته میشود.
فرایند جستجو در پایگاه داده برداری
۱. دادهها (متن، تصویر و غیره) به embedding تبدیل میشوند.
۲. embeddingها در پایگاه داده ذخیره میشوند.
۳. هنگام جستجو، ورودی کاربر نیز به embedding تبدیل شده و پایگاه داده نزدیکترین بردارها را بر اساس فاصله (distance) پیدا میکند.
- معیارهای رایج فاصله: Cosine Similarity، Euclidean Distance، Dot Product
این مکانیزم باعث میشود به جای جستجوی کلمات دقیق، نتایج بر اساس معنا و شباهت ارائه شوند.
فناوریهای بهینهسازی جستجوی برداری
یکی از چالشهای اصلی در پایگاه داده برداری، مقیاسپذیری و سرعت جستجو است. وقتی ابعاد بالا و دادهها حجیم باشند، جستجوی خطی بسیار پرهزینه خواهد بود. برای حل این مشکل، الگوریتمهای ANN (Approximate Nearest Neighbor Search) استفاده میشوند.
مهمترین الگوریتمها
- LSH (Locality Sensitive Hashing): دادهها را در bucketهای مشابه نگه میدارد تا جستجو سریعتر شود.
- PQ (Product Quantization): فضای برداری را فشردهسازی میکند تا محاسبات سبکتر شوند.
- HNSW (Hierarchical Navigable Small World): دادهها را در قالب گراف چندلایه سازماندهی میکند و یکی از سریعترین روشها برای جستجو در ابعاد بالا است.
ابزارهای پشتیبان
- FAISS (Facebook AI Similarity Search): کتابخانهای متنباز برای جستجوی سریع میان میلیونها یا حتی میلیاردها بردار.
- Annoy و ScaNN: ابزارهای بهینه برای جستجو در سیستمهای مقیاس بزرگ.
پایگاه داده برداری چگونه کار میکند؟
همه ما کمابیش با پایگاههای داده سنتی آشنایی داریم؛ جایی که دادههایی مانند رشتهها، اعداد و سایر مقادیر اسکالر در قالب سطر و ستون ذخیره میشوند. اما پایگاه داده برداری با بردارها کار میکند و به همین دلیل هم در بهینهسازی و هم در نحوه جستجو با پایگاههای سنتی تفاوت اساسی دارد.
در پایگاههای داده سنتی معمولا جستجو بهدنبال تطبیق دقیق یک مقدار با مقدار موجود در بانک اطلاعاتی است. اما در پایگاههای داده برداری، معیار شباهت به کار گرفته میشود تا نزدیکترین بردار به بردار جستجوی ما پیدا شود.
برای این کار، پایگاه داده برداری از مجموعهای از الگوریتمها بهره میگیرد که در دستهی جستجوی تقریبی نزدیکترین همسایه قرار میگیرند. این الگوریتمها با روشهایی مثل هشینگ (Hashing)، کوآنتیزهسازی (Quantization) یا جستجوی مبتنی بر گراف (Graph-based search) روند جستجو را بهینه میکنند.
این الگوریتمها در قالب یک خط لوله پردازشی (Pipeline) کنار هم قرار میگیرند تا هم سرعت بالا و هم دقت مناسبی در بازیابی بردارهای مشابه فراهم کنند. چون نتایج بهصورت تقریبی ارائه میشوند، همیشه یک موازنه میان دقت و سرعت وجود دارد: هر چه نتیجه دقیقتر باشد، جستجو زمان بیشتری خواهد برد. با این حال، سیستمهای خوب میتوانند جستجویی فوقالعاده سریع با دقت نزدیک به کامل ارائه دهند.
مراحل معمول در پایپلاین یک پایگاه داده برداری
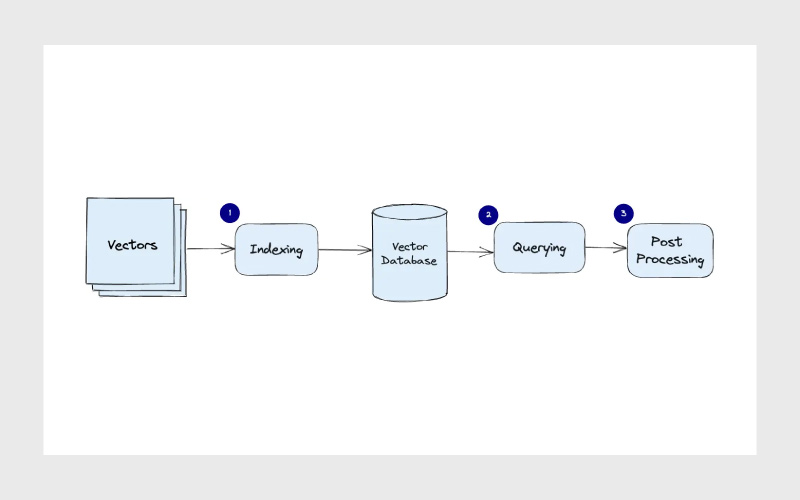
۱. ایندکسگذاری (Indexing): پایگاه داده، بردارها را با استفاده از الگوریتمهایی مثل PQ، LSH یا HNSW ایندکس میکند. این کار باعث میشود دادهها در ساختارهایی قرار گیرند که امکان جستجوی سریعتر را فراهم میکنند.
۲. جستجو (Querying): هنگام ارسال پرسوجو، بردار جستجو با بردارهای ایندکسشده مقایسه میشود تا نزدیکترین همسایهها بر اساس معیار شباهت مشخص شوند.
۳. پردازش نهایی (Post-processing): در برخی موارد، پایگاه داده نتایج اولیه را بازبینی کرده و رتبهبندی مجدد انجام میدهد. این مرحله میتواند شامل استفاده از معیار شباهت دیگری برای مرتبسازی دقیقتر نتایج باشد.
پایگاههای داده برداری معروف
بازار پایگاه داده برداری در سالهای اخیر به شدت رشد کرده و پروژههای مختلفی شکل گرفتهاند. در ادامه به چند نمونه شاخص اشاره میکنیم:
۱. Milvus

نوعی از پایگاه داده متنباز (Open Source) و یکی از اولین پروژههای مطرح در حوزه پایگاه داده برداری است.
ویژگیها:
- مقیاسپذیری بالا با پشتیبانی از دادههای میلیاردی
- پشتیبانی از GPU و CPU برای شتابدهی جستجو
- APIهای ساده برای اتصال به زبانهای مختلف (Python، Java، Go)
- امکان ادغام با چارچوبهای یادگیری ماشین مثل PyTorch و TensorFlow
موارد استفاده:
- جستجوی تصویر و ویدئو
- سیستمهای پیشنهادگر (Recommendation Systems).
- تحلیل دادههای علمی و زیستی
۲. ChromaDB

پایگاه داده برداری متنباز که مخصوص کار با مدلهای زبانی بزرگ (LLMs) طراحی شده است.
ویژگیها:
- تمرکز بر جستجوی معنایی (Semantic Search) برای متن
- قابلیت فیلتر کردن متادیتا و کار با دادههای ترکیبی (متن + تصویر)
- معماری سبک و مناسب برای توسعه سریع نمونه اولیه (Prototyping)
- جامعه کاربری فعال و یکپارچگی خوب با ابزارهای AI
موارد استفاده:
- اپلیکیشنهای RAG (Retrieval-Augmented Generation)
- چتباتهای هوشمند
- جستجوی محتوای چندرسانهای
۳. Weaviate

دیتابیس متنباز و مدولار است.
ویژگیها:
- قابلیت اتصال مستقیم به مدلهای یادگیری ماشینی مثل Hugging Face یا OpenAI
- پشتیبانی از جستجوی ترکیبی (Hybrid Search) با بردار + کلیدواژه
- افزونههای مختلف برای پردازش متن، تصویر و صوت
- قابلیت گسترش در محیط ابری یا لوکال
موارد استفاده:
- ساخت سیستمهای Recommendation
- تحلیل متن و دادههای علمی
- RAG در اپلیکیشنهای AI
۴. Pinecone
پایگاه داده برداری مدیریتشده در ابر (Cloud-managed)
ویژگیها:
- تمرکز بر سرویس بدون نیاز به مدیریت زیرساخت
- مقیاسپذیری آسان، بدون نگرانی درباره سرورها یا خوشهها
- API قوی برای یکپارچگی با اپلیکیشنها
- امنیت و مانیتورینگ در سطح سازمانی
موارد استفاده:
- جستجوی برداری در مقیاس بسیار بزرگ
- سازمانهایی که منابع DevOps محدودی دارند
- اپلیکیشنهای تجاری که نیاز به SLA و پشتیبانی رسمی دارند
۵. Qdrant

از انواع دیتابیسهای برداری متنباز و بهینه برای ANN به شمار میرود
ویژگیها:
- طراحیشده برای عملکرد سریع در دادههای حجیم
- پشتیبانی از real-time search
- ادغام با زبانهای مختلف (Rust، Python، JavaScript)
- امکان ذخیرهسازی متادیتا همراه با بردارها
موارد استفاده:
- اپلیکیشنهای آنی (Real-time applications)
- موتورهای جستجو
- سیستمهای پیشنهادگر با دادههای حجیم
کاربردها و نقش پایگاه داده برداری در هوش مصنوعی
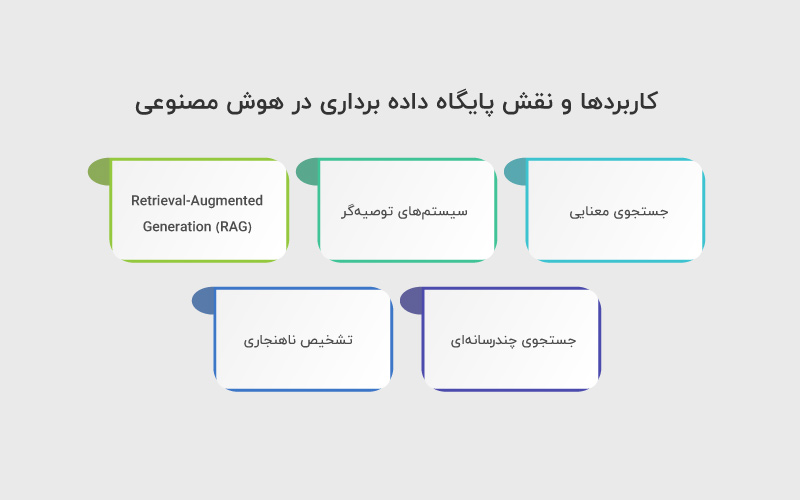
پایگاههای داده برداری در طیف گستردهای از کاربردها نقش دارند:
۱. جستجوی معنایی (Semantic Search)
جایگزین جستجوی سنتی مبتنی بر کلیدواژه. مثلا در یک فروشگاه آنلاین، کاربر با تایپ «کفش برای دویدن در باران» نتایجی دریافت میکند که بر اساس مفهوم نزدیک هستند، نه صرفا تطابق کلمه «کفش».
۲. سیستمهای توصیهگر (Recommendation Systems)
با مقایسه بردار علایق کاربر و بردار محصولات، میتوان پیشنهادهای شخصیسازیشده ارائه داد.
۳. Retrieval-Augmented Generation (RAG)
یکی از مهمترین کاربردها در ترکیب با مدلهای زبانی بزرگ (LLMs). در RAG، پایگاه داده برداری به مدل کمک میکند تا اطلاعات بهروز و مبتنی بر دادههای سازمانی ارائه دهد. این روش خطای «hallucination» را کاهش میدهد.
۴. جستجوی چندرسانهای (Multimodal Search)
کاربر میتواند تصویری آپلود کند و پایگاه داده تصاویر مشابه را بازیابی کند. همین رویکرد در صوت و ویدئو نیز قابل استفاده است.
۵. تشخیص ناهنجاری (Anomaly Detection)
مقایسه بردارهای رفتار عادی با دادههای جدید برای شناسایی فعالیتهای مشکوک (مثل تقلب بانکی).
مزایا و چالشهای پایگاههای برداری
پایگاههای داده برداری امکان جستجوی سریع و دقیق بر اساس شباهت معنایی را فراهم میکنند. برخلاف پایگاههای داده سنتی که بیشتر برای دادههای ساختیافته مناسباند، این نوع پایگاهها برای مدیریت و تحلیل دادههای غیرساختیافته مانند متن، تصویر و صدا طراحی شدهاند.
یکی دیگر از مزایای کلیدی آنها یکپارچگی آسان با مدلهای یادگیری ماشین و بهویژه LLMها است، بهگونهای که میتوان مستقیما خروجی مدلها را در قالب embedding ذخیره و جستجو کرد. علاوهبر این، پایگاههای داده برداری از نظر معماری به شکلی طراحی شدهاند که مقیاسپذیری بالایی داشته باشند و حتی در مواجهه با میلیاردها رکورد نیز عملکرد خود را حفظ کنند.
با وجود مزایای متعدد، استفاده از پایگاه داده برداری خالی از چالش نیست. یکی از مهمترین مسائل، انتخاب الگوریتم جستجوی نزدیکترین همسایه (ANN) مناسب است؛ چرا که هر الگوریتم تعادلی میان سرعت و دقت برقرار میکند. همچنین، تولید embeddingها هزینه محاسباتی بالایی دارد و بهویژه در دادههای حجیم میتواند بسیار زمانبر باشد.
در بسیاری از پیادهسازیها نیاز به سختافزارهای قدرتمند مانند GPU یا TPU وجود دارد تا پردازشها در زمان مناسب انجام شوند. از سوی دیگر، نبود یک استاندارد واحد میان پایگاههای داده برداری مختلف باعث میشود مهاجرت یا ادغام بین آنها چالشبرانگیز باشد و تیمها ناچار به یادگیری ابزارها و APIهای متفاوت شوند.
جمعبندی و چشمانداز آینده
پایگاه داده برداری، یکی از اجزای کلیدی در معماری نوین هوش مصنوعی و یادگیری ماشین است. این فناوری امکان بازیابی دادهها را بر اساس معنا بهجای کلیدواژه فراهم میکند و همین امر آن را در حوزههایی مانند RAG، سیستمهای توصیهگر و جستجوی چندرسانهای به یک ابزار ضروری تبدیل کرده است.
چشمانداز آینده نشان میدهد که:
- ادغام پایگاه داده برداری با پایگاههای رابطهای و NoSQL افزایش خواهد یافت.
- بازار این فناوری با رشد سریع مواجه است و پیشبینی میشود بخش مهمی از اکوسیستم هوش مصنوعی را در سالهای آینده تشکیل دهد.
- با پیشرفت در الگوریتمهای ANN و سختافزارهای شتابدهنده، محدودیتهای فعلی در سرعت و هزینه کمتر خواهند شد.
منابع
developers.cloudflare.com | pinecone.io
سوالات متداول
پایگاه داده سنتی دادهها را به صورت جداولی شامل اعداد، رشتهها و مقادیر دقیق ذخیره میکند. اما پایگاه داده برداری (Vector Database) دادهها را به شکل بردارهای چندبعدی ذخیره و مدیریت میکند. این نوع پایگاه داده بهجای جستجوی تطابق دقیق، با استفاده از معیارهای شباهت (مثل کسینوس سیمیلتری یا فاصله اقلیدسی) نزدیکترین بردارها را پیدا میکند. بنابراین، بهویژه در کاربردهایی مثل جستجوی معنایی، پردازش تصویر و دادههای غیرساختاریافته کارایی بالاتری دارد.
بله. بسیاری از سازمانها از Hybrid Database Systems استفاده میکنند که دادههای ساختاریافته (SQL/NoSQL) و غیرساختاریافته (Vector) را با هم مدیریت میکنند. برای مثال میتوان اطلاعات مشتری (نام، ایمیل، شماره) را در یک پایگاه داده رابطهای ذخیره کرد و بردارهای رفتاری یا علایق او را در پایگاه داده برداری نگه داشت. این ترکیب امکان جستجوی دقیق و معنایی را همزمان فراهم میکند.
در سرویسهای ابری، هزینه معمولا بر اساس حجم ذخیرهسازی، تعداد درخواست جستجو، و توان پردازشی (CPU/GPU) محاسبه میشود. این مدل برای پروژههایی که مقیاس آنها قابل پیشبینی نیست یا به سرعت رشد میکنند مناسبتر است.
در مدل On-Premise (نصب محلی)، هزینه بیشتر مربوط به زیرساخت سختافزاری، نگهداری و مدیریت سیستم است. این گزینه برای سازمانهایی که ملاحظات امنیتی و حریم خصوصی سختگیرانه دارند ترجیح داده میشود، اما هزینه اولیه بیشتری دارد.

دیدگاهتان را بنویسید