
در سالهای اخیر، مدلهای زبانی بزرگ یا همان LLMs به یکی از مهمترین دستاوردهای هوش مصنوعی تبدیل شدهاند. این مدلها تنها با درک زبان طبیعی قادرند متن تولید کنند، به پرسشها پاسخ دهند و حتی کد بنویسند. در دنیای توسعه نرمافزار، LLMها در حال تغییر روش کار توسعهدهندگان هستند. اگر میخواهید بدانید که LLM دقیقا چیست و چطور کار میکند، ادامه این مقاله را در مجله آسا از دست ندهید!
LLMs چیست؟
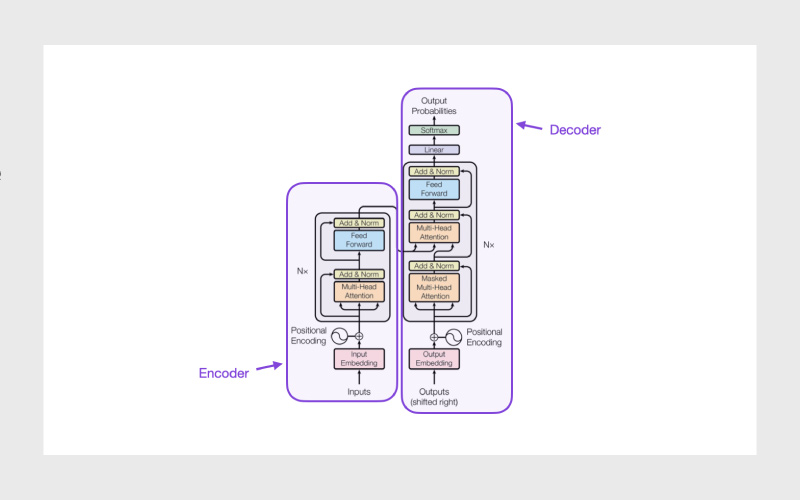
مدلهای زبانی بزرگ یا Large Language Models، مدلهای یادگیری عمیق بسیار بزرگی هستند که با حجم بزرگی از دادهها آموزش دیدهاند. ساختار اصلی این مدلها، معماری ترنسفورمر است. این معماری مجموعهای از شبکههای عصبی است که شامل یک رمزگذار (encoder) و یک رمزگشا (decoder) با قابلیت توجه به خود (self-attention) است. رمزگذار و رمزگشا میتوانند معناهای موجود در یک توالی متنی را استخراج کرده و روابط بین واژهها و عبارات را درک کنند.
ترنسفورمرها قادر به یادگیری بدون نظارت هستند؛ به بیان دقیقتر، این مدلها از طریق یادگیری خودنظارتی (self-learning) آموزش میبینند. در این فرایند، ترنسفورمرها توانایی درک دستور زبان، ساختارهای زبانی و دانش پایهای را کسب میکنند.
برخلاف شبکههای عصبی بازگشتی (RNNs) قدیمی که دادهها را بهصورت ترتیبی پردازش میکردند، ترنسفورمرها میتوانند توالیهای کامل را بهصورت موازی پردازش کنند. این ویژگی به دانشمندان داده اجازه میدهد از قدرت پردازشی GPU برای آموزش مدلهای LLM استفاده کنند و زمان آموزش را بهشکل قابل توجهی کاهش دهند.
معماری شبکه عصبی ترنسفورمر امکان استفاده از مدلهایی با مقیاس بسیار بزرگ، گاهی حتی با صدها میلیارد پارامتر را فراهم میکند. این مدلهای عظیم میتوانند حجم بسیار زیادی از دادهها را پردازش کنند و یاد بگیرند؛ دادههایی که اغلب از اینترنت و منابع بزرگی مثل Common Crawl (با بیش از ۵۰ میلیارد صفحه وب) و ویکیپدیا (با حدود ۵۷ میلیون صفحه) جمعآوری میشوند.
چرا مدلهای زبانی بزرگ اهمیت دارند؟
مدلهای زبانی بزرگ بهطور شگفتانگیزی انعطافپذیرند. تنها یک مدل میتواند کارهای کاملا متفاوتی انجام دهد؛ از پاسخ به سوالات و خلاصهسازی متون گرفته تا ترجمه زبانها و تکمیل جملات. این مدلها ظرفیت آن را دارند که روند تولید محتوا، جستجو در اینترنت و حتی عملکرد دستیارهای مجازی را متحول کنند.
این مدلها گرچه هنوز بینقص نیستند، ولی LLMها توانایی چشمگیری در پیشبینی پاسخها بر پایه ورودیهای محدود نشان دادهاند. در حوزه هوش مصنوعی مولد (Generative AI)، این مدلها میتوانند متنی قابل فهم و طبیعی براساس دستورات زبانی ساده تولید کنند.
مقیاس این مدلها با میلیاردها پارامتر و کاربردهایی متنوع و گسترده واقعا عظیم است. برای درک بهتر، چند نمونه را با هم بررسی میکنیم:
- مدل GPT-۳ از OpenAI دارای ۱۷۵ میلیارد پارامتر است. نسخه معروف از این مدل با نام ChatGPT میتواند الگوهای موجود در دادهها را شناسایی و خروجیای روان و قابل فهم تولید کند.
- مدل Claude ۲ (با وجود نامشخص بودن اندازه دقیقش) قادر است تا ۱۰۰ هزار توکن را در هر ورودی بپذیرد. این یعنی توانایی پردازش صدها صفحه مستندات فنی یا حتی یک کتاب کامل را دارد.
- Jurassic-۱ از شرکت AI21 با 178 میلیارد پارامتر و واژگان متشکل از ۲۵۰ هزار جزء واژه، قابلیتهای مکالمهای مشابهی را به کاربرانش ارائه میدهد.
- مدل Command از Cohere هم در بیش از ۱۰۰ زبان مختلف عملکرد قابل قبولی دارد.
- LightOn نیز با مدل Paradigm ادعا میکند تواناییهایی فراتر از GPT-۳ ارائه میدهد.
نکته مهم اینجاست که تمامی این مدلها از طریق APIهایی در دسترس توسعهدهندگان قرار دارند و بستری مناسب برای ساخت اپلیکیشنهای نوآورانه مبتنی بر هوش مصنوعی مولد را فراهم میکنند.
مدلهای زبانی بزرگ چطور کار میکنند؟
یکی از عناصر کلیدی در عملکرد LLMs، نحوه بازنمایی واژگان در آنهاست. در روشهای قدیمیتر یادگیری ماشین، هر واژه تنها بهصورت یک عدد در جدول قرار میگرفت. ولی این رویکرد نمیتوانست ارتباط بین واژهها، برای مثال واژههایی با معانی مشابه را تشخیص دهد.
برای رفع این محدودیت، مفهومی بهنام Word embedding معرفی شد. در این روش، هر واژه در فضایی برداری قرار میگیرد؛ بهطوریکه واژههایی با معنای مشابه یا کاربردهای مرتبط، در نزدیکی یکدیگر قرار دارند. این نزدیکی به مدل کمک میکند تا معنای ضمنی واژگان را بهتر درک کند.
ترنسفورمرها با استفاده از این بردارها، ابتدا متن را از طریق بخش رمزگذار به دادههای عددی تبدیل میکنند. این فرایند نهتنها به مدل قابلیت درک واژهها را میدهد، بلکه کمک میکند تا روابط گرامری و ساختاری آنها مثل نقش دستوری را نیز تشخیص دهد.
در ادامه، این درک زبانی در مرحله رمزگشا به کار گرفته میشود تا خروجیای تولید شود که نهتنها از نظر معنا دقیق، بلکه از نظر زبانی هم روان و طبیعی باشد.
کاربرد مدلهای زبانی بزرگ
مدلهای زبانی بزرگ میتوانند برای انجام طیف وسیعی از وظایف آموزش ببینند. یکی از رایجترین کاربردهای آنها، استفاده در هوش مصنوعی مولد است؛ جایی که مدل با دریافت یک پرامپت یا سوال، متنی متناسب تولید میکند. برای مثال، چتبات شناختهشده ChatGPT میتواند مقاله، شعر یا انواع دیگر متنها را در پاسخ به ورودی کاربر تولید کند.
ولی کاربرد LLMها فراتر از تولید متن است. این مدلها میتوانند براساس مجموعه دادههای بزرگ و پیچیده، از جمله زبانهای برنامهنویسی آموزش ببینند. در نتیجه، برخی از آنها به ابزاری قدرتمند برای کمک به برنامهنویسان تبدیل شدهاند؛ برای مثال میتوانند براساس یک توضیح ساده، تابع بنویسند یا با دیدن بخشی از کد، باقی آن را تکمیل کنند.
از جمله مهمترین کاربرد LLMها میتوان به این موارد اشاره کرد:
۱- تولید محتوا (Content production)

مدلهای زبانی بزرگ در تولید محتوای متنی خلاقانه و حرفهای، از جمله نگارش تبلیغات، محتوای وبسایتها، پستهای شبکههای اجتماعی و حتی متون بازاریابی، نقش مهمی دارند. مدلهایی مثل GPT-4o از OpenAI، Claude ۳ از Anthropic و Gemini از گوگل قادر به تولید متون با سبک و لحن متناسب با نیاز کاربر هستند. این مدلها میتوانند متنها را براساس مخاطب هدف (مثلاً رسمی، دوستانه یا طنزآمیز) تنظیم کنند و حتی پیشنهادهایی برای بهبود سبک و وضوح متن ارائه دهند.
ابزارهایی مثل Jasper.ai و Copy.ai از LLMها برای کمک به کسبوکارها در تولید محتوای سریع و بهینه استفاده میکنند. علاوهبر این، قابلیتهایی مثل بازنویسی (paraphrasing) و بهینهسازی برای سئو (SEO) نیز در این ابزارها ادغام شده است.
۲- پاسخگویی از پایگاههای دانش (Knowledge Base Answering)

مدلهای زبانی بزرگ در پاسخگویی به سوالات پیچیده با استفاده از اطلاعات موجود در پایگاههای داده دیجیتال یا منابع متنی بسیار قدرتمند هستند. این قابلیت، که به پردازش زبان طبیعی دانشمحور (KI-NLP) معروف است، در سیستمهای پشتیبانی مشتری، دستیارهای تحقیقاتی و چتباتهای سازمانی کاربرد دارد. برای مثال، مدلهای DeepSeek R۱ و GPT-۴o توانایی استخراج پاسخهای دقیق از اسناد متنی بزرگ را دارند. این مدلها میتوانند اطلاعات را از منابع غیرساختاریافته (مثل مقالات، گزارشها یا کتابها) تحلیل کرده و جوابهایی مرتبط و مستند به شما ارائه دهند.
۳- دستهبندی متنی (Text Classification)
طبقهبندی متن با استفاده از LLMها شامل دستهبندی متون براساس معیارهایی مانند معنا، احساسات یا موضوع است. این قابلیت در تحلیل احساسات مشتریان (sentiment analysis)، شناسایی اسپم، فیلتر کردن محتوای نامناسب و جستجوی اسناد کاربرد دارد. برای مثال، شرکتهای خردهفروشی از LLMها برای تحلیل نظرات مشتریان و شناسایی بازخوردهای مثبت یا منفی استفاده میکنند. همچنین، در حوزههای حقوقی، LLMها برای طبقهبندی اسناد قانونی و استخراج اطلاعات کلیدی به کار میروند.
۴- تولید کد
مدلهای زبانی بزرگ در تولید کد از درخواستهای زبان طبیعی (natural language prompts) بسیار پیشرفته شدهاند. ابزارهایی مانند GitHub Copilot (مبتنی بر Codex و GPT-۴)، Amazon CodeWhisperer و Tabnine از LLMها برای تولید کد در زبانهایی مانند Python، JavaScript، Java، SQL و غیره استفاده میکنند. این ابزارها میتوانند کدهای پیچیده، اسکریپتهای اتوماسیون، کوئریهای پایگاه داده و حتی طراحی رابط کاربری وبسایت را انجام دهند. علاوهبر این، LLMها در رفع اشکال کد (debugging) و پیشنهاد بهبودهای کدنویسی نیز کاربرد دارند.
مدلهای زبانی بزرگ چگونه آموزش داده میشوند؟

مدلهای زبانی بزرگ که بر پایه شبکههای عصبی ترنسفورمر ساخته میشوند، ساختاری بسیار پیچیده و عظیم دارند. این شبکهها شامل لایهها و گرههای متعددی هستند که هر گره در یک لایه به تمام گرههای لایه بعدی متصل است. این اتصالات با وزنها و بایاسهایی همراه میشوند. به این مجموعه یعنی وزنها، بایاسها و embeddingها پارامترهای مدل گفته میشود. در LLMهای مدرن، این پارامترها ممکن است به صدها میلیارد عدد برسند.
اندازه مدل معمولا براساس یک رابطه تجربی میان سه عامل تعیین میشود:
- تعداد پارامترها
- حجم دادههای آموزشی
- ابعاد مدل
فرایند آموزش با استفاده از مجموعهای عظیم از دادههای متنی باکیفیت انجام میشود. در طی آموزش، مدل بارها پارامترهایش را تغییر میدهد تا بتواند بهدرستی توکن بعدی را در یک دنباله متنی پیشبینی کند. این کار از طریق تکنیکی به نام یادگیری خودنظارتی انجام میشود؛ روشی که به مدل کمک میکند تا خودش پارامترها را طوری تنظیم کند که احتمال درست بودن توکن بعدی، حداکثر شود.
پس از طی این مرحله، مدل میتواند با استفاده از مقادیر نسبتا کمی داده آموزشی هدفمند، برای انجام وظایف خاص بهینهسازی شود؛ فرایندی که به آن ریزتنظیم یا Fine-Tuning میگویند.
در مجموع، سه روش اصلی برای بهرهگرفتن از تواناییهای LLMها وجود دارد:
۱. Zero-shot learning: مدل میتواند بدون آموزش خاص، تنها با دریافت یک پرامپت (دستور متنی)، به بسیاری از سوالات پاسخ دهد. گرچه دقت پاسخ بسته به موضوع متفاوت است.
۲. Few-shot learning: با ارائه چند مثال آموزشی مرتبط، عملکرد مدل در همان حوزه خاص بهطور چشمگیری بهبود مییابد.
۳. Fine-tuning: نوعی یادگیری پیشرفتهتر است که در آن مدل پایه با دادههای خاصتر و بیشتر، دوباره آموزش میبیند تا در یک کاربرد مشخص، خروجی بهینهتری ارائه دهد.
مزایا و محدودیتهای LLMs
در این بخش، بهصورت خلاصه و روان به مزایا و محدودیتهای مدلهای زبانی بزرگ میپردازیم.
مزایا:
- پاسخگویی به زبان طبیعی: برخلاف نرمافزارهای سنتی که فقط به ورودیهای خاص و محدود واکنش نشان میدهند، مدلهای زبانی بزرگ میتوانند به سوالات آزاد، پیچیده یا حتی مبهم با زبان انسانی پاسخ دهند.
- انعطافپذیری بالا: LLMها با یک مدل واحد میتوانند کارهای متنوعی مثل ترجمه، خلاصهسازی، تولید محتوا و کدنویسی انجام دهند.
- یادگیری زمینهای (Contextual Understanding): به لطف ساختار ترنسفورمر، این مدلها میتوانند معنای واژهها را در بافت جمله بهتر درک کرده و پاسخهای معنادار تولید کنند.
محدودیتها:
- وابستگی به داده: خروجی مدلها فقط به اندازهی دادههایی که با آن آموزش دیدهاند قابل اعتماد است. اگر دادهها اشتباه یا جهتدار باشند، مدل هم خروجی نادرست ارائه میدهد.
- خطای توهمی (Hallucination): در مواقعی که اطلاعات دقیق در دسترس نیست، ممکن است مدلها «اطلاعات ساختگی» تولید کنند؛ مثلا گزارشی از عملکرد مالی شرکتی که در واقعیت وجود ندارد.
- ریسکهای امنیتی: LLMها ممکن است در برابر ورودیهای مخرب آسیبپذیر باشند. کاربران گاهی دادههای حساس را برای دریافت پاسخ بهتر وارد میکنند، اما این دادهها ممکن است ناخواسته در پاسخهای بعدی به دیگران نمایش داده شوند.
سخن آخر
در یک نگاه کلی، مدلهای زبانی بزرگ (LLMs) مثل ChatGPT، Claude یا Llama، نسل جدیدی از سامانههای هوش مصنوعی هستند که با تکیه بر ساختار ترنسفورمر و میلیاردها پارامتر، توانایی درک و تولید زبان انسانی را به شکلی شگفتانگیز دارند. این مدلها قابلیتهایی نظیر تولید محتوا، ترجمه، دستهبندی متن، پاسخگویی به سوالات و حتی تولید کد را در مقیاسی بیسابقه ممکن کردهاند.
با وجود مزایایی مثل انعطافپذیری، پاسخگویی هوشمند و یادگیری زمینهای، این مدلها همچنان با چالشهایی مثل خطای اطلاعاتی، وابستگی به داده و مسائل امنیتی روبهرو هستند. بااینحال، روند توسعه LLMها نشان میدهد که این فناوری نهتنها آینده تولید محتوا و توسعه نرمافزار را متحول میکند، بلکه مسیر جدیدی برای ارتباط انسان و ماشین ترسیم خواهد کرد.
منابع
cloudflare.com | aws.amazon.com | docs.aws.amazon.com | tabnine.com | copy.ai | jasper.ai
سوالات متداول
با استفاده از ساختار ترنسفورمر و بردارهای چندبُعدی (word embeddings)، این مدلها میتوانند معنی کلمات را در بافت جمله درک کرده و پاسخهایی منطبق با زبان طبیعی تولید کنند.
کمک به نوشتن کد، تولید مستندات فنی، پاسخگویی به سؤالات برنامهنویسی، و حتی طراحی اولیه رابط کاربری یا دستورات SQL.
نه همیشه. چون ممکن است ورودیهای کاربران به صورت ناخواسته در پاسخهای آینده مدل ظاهر شوند، بهتر است از وارد کردن اطلاعات محرمانه خودداری شود.


دیدگاهتان را بنویسید