
هدوپ (Hadoop) و اسپارک (Spark) دو فریم ورک متن باز هستند که برای نگهداری و پردازش کلان داده یا بیگدیتا استفاده میشوند. این دو فریمورک زیر نظر بنیاد نرمافزاری آپاچی فعالیت دارند. در این مقاله قصد داریم اطلاعات کلی در خصوص هدوپ و اسپارک در اختیار شما قرار دهیم، اما قبل از شروع صحبت درباره این دو فریمورک، بهتر است با بنیاد نرمافزاری آپاچی و مفهوم متن باز آشنا شویم. بنیاد نرمافزاری آپاچی (Apache Software Foundation) که به اختصار ASF نامیده میشود، یک شرکت غیر انتفاعی آمریکایی است که کار اصلی آن پشتیبانی از پروژههای مختلف نرمافزاری آپاچی (Apache) است.
به طور کلی، عنوان متن باز (Open-Source) به این معنا است که کد میتواند آزادانه و توسط هر کسی استفاده شود. فراتر از آن، هر کسی میتواند آن را برای تولید نسخههای سفارشی با هدف مشکلات یا صنایع خاص تغییر دهد. توسعهدهندگان داوطلب و همچنین افرادی که در شرکتها مشغول هستند، نسخههای سفارشی تولید میکنند و به طور مداوم نرمافزار اصلی را اصلاح و بهروزرسانی میکنند و ویژگیها و کارایی بیشتری را به آن اضافه میکنند.
هدوپ (Hadoop) چیست؟
هدوپ با جدا کردن اجزا در سیستمهای توزیعشده در لایههای عملکردی، به ساده کردن و موثر بودن مدیریت و توسعه دادهها کمک میکند. با کمک آن، برنامهنویسان میتوانند بدون تاثیر منفی بر فرآیندهای دیگر اکوسیستم، روی فریم ورکها به صورت گستردهتر کار کنند. کلان داده با حجم بسیار زیاد، ساختارهای داده متفاوت فریم ورکها و ابزارهای سنتی شبکه را تحت الشعاع قرار میدهد. در این موارد استفاده از سختافزارها با کارایی بالا و سرورهای تخصصی میتواند راهگشا باشد، اما آنها انعطافپذیری کمیداشته و هزینه زیادی دارند.
هدوپ قادر به پردازش و ذخیره مقادیر زیادی از دادهها با استفاده از سختافزارهای به هم متصل و مقرون به صرفه است. صدها یا حتی هزاران سرور اختصاصی کمهزینه با هم کار میکنند تا دادهها را در یک اکوسیستم ذخیره و پردازش کنند. آپاچی هدوپ (Apache Hadoop) پلتفرمی است که مجموعهای از کلان دادهها را به صورت توزیع شده مدیریت میکند. این فریمورک از مپردیوس (MapReduce) برای تقسیم دادهها به بلوکها و بعد تبدیل آن به تکهها (Chunks) و در نهایت تبدیل به گرهها یا Node به صورت خوشه (Cluster) استفاده میکند. در نهایت مپ ردیوس دادهها را به صورت موازی در هر گره پردازش میکند تا یک خروجی منحصر به فرد ایجاد کند.

هر ماشین در یک خوشه، دادهها را ذخیره و پردازش میکند. هدوپ، دادهها را با استفاده از HDFS در دیسک ذخیره میکند. این نرمافزار گزینههای مقیاس پذیر و یکپارچه را ارائه میدهد. میتوانید با تنها یک دستگاه شروع کنید و سپس آن را به هزاران دستگاه گسترش داده و هر نوع سختافزار، شرکت یا کالایی را اضافه کنید.
اکوسیستم هدوپ در برابر خطا بسیار مقاوم است. این اکوسیستم برای رسیدن به کارایی بالا به سخت افزار وابسته نیست. همچنین برای جستجوی خرابی در لایههای مختلف نرمافزار ساخته شده است. با تکرار دادهها در یک خوشهبندی، هنگامی که یک قطعه سختافزاری از کار میافتد، هدوپ میتواند بخشهای نامشخص یا گم شده را با کمک دادههای موجود در جاهای دیگر بسازد.
لایههای هدوپ
هدوپ را میتوان به چهار لایه متمایز تقسیم کرد.
- لایه ذخیرهسازی پراکنده
- مدیریت منابع خوشهها (Cluster )
- پردازش لایه فریمورک
- رابط برنامهنویسی برنامه
اجزای اصلی هدوپ چیست؟
پروژه آپاچی هدوپ از چهار بخش اصلی تشکیل شده است:
- HDFS:
که مخفف Hadoop Distributed File System بوده و همان سیستمی است که ذخیره مجموعه بزرگی از دادهها را در سراسر یک خوشه در هدوپ مدیریت میکند. HDFS میتواند هم دادههای ساختاربندی شده و هم دادههای بدون ساختار را مدیریت کند. سختافزار ذخیرهسازی میتواند از HDDهای مصرفکننده تا درایوهای شرکت متفاوت باشد.
- MapReduce:
مولفه پردازش اکوسیستم هدوپ با این روش قطعات داده را از HDFS، برای جداسازی وظایف در خوشه اختصاصی قرار میدهد. مپ ردیوس (MapReduce) تکهها را به صورت موازی پردازش میکند تا قطعات را با کمک نتیجه دلخواه ترکیب کند.
- YARN:
یک منبع مذاکره کننده است، اما مسئولیت مدیریت منابع محاسباتی و زمان کارها را هم برعهده دارد.
- Hadoop Common:
شامل مجموعهای از کتابخانهها و ابزارهای کمکی رایج است که سایر ماژولها به آنها وابسته هستند. نام دیگر این ماژول هسته هدوپ است؛ چرا که از تمام اجزای دیگر هدوپ پشتیبانی میکند. ماهیت هدوپ، آن را برای هر کسی که به آن نیاز دارد، قابل دسترس میکند. جامعه متن باز بزرگ است و مسیر را برای پردازش کلان دادههای در دسترس هموار کرده است.

اسپارک (Spark) چیست؟
اسپارک یک فریمورک متن باز است که تعدادی پلتفرم، سیستم و استانداردهای به هم پیوسته را برای پروژههای بیگ دیتا ارائه میدهد. در واقع اسپارک فعالترین پروژه آپاچی در سال گذشته بود. همچنین فعالترین برنامههای متنباز بیگ دیتا با بیش از ۵۰۰ مشارکتکننده از بیش از ۲۰۰ سازمان بود.
این فریمورک میتواند در حالت مستقل یا روی یک ابزار مدیریتی ابر (Cloud) یا خوشه (Cluster) مانند Apache Mesos و سایر پلتفرم ها اجرا شود. اسپارک برای عملکرد سریع طراحی شده است و از رَم (RAM) برای ذخیره و پردازش دادهها استفاده میکند.
اسپارک انواع مختلفی از حجم کاری بیگ دیتا را انجام میدهد. این امر شامل پردازش دستهای MapReduce-like و همچنین پردازش جریان زمان واقعی، یادگیری ماشین، محاسبه گرافها و کوئریهای محاورهای (Interactive Queries) است. با استفاده آسان از APIهای سطح بالا، اسپارک میتواند با بسیاری از کتابخانههای مختلف از جمله PyTorch و TensorFlow ادغام شود.
موتور اسپارک برای بهبود کارایی مپ ردیوس و حفظ مزایای آن ایجاد شده است. حتی اگر اسپارک سیستم فایلی خود را نداشته باشد، باز هم میتواند به دادهها در بسیاری از راهکارهای ذخیرهسازی مختلف دسترسی داشته باشد. ساختار دادهای که اسپارک از آن استفاده میکند، مجموعه داده توزیع شده انعطافپذیر (Resilient Distributed Dataset) یا RDD نامیده میشود.
آپاچی اسپارک از پنج بخش اصلی تشکیل شده است:
- هسته آپاچی اسپارک:
این بخش اساس کل پروژه است. مسئول وظایف ضروری مانند زمانبندی، توزیع وظایف، انجام عملیاتها بر ورودی و خروجی، بازیابی خطا و غیره است.
- Spark Streaming:
این مولفه پردازش جریان دادههای زنده را امکان پذیر میکند. داده ها میتوانند از بسیاری منابع مختلف، از جمله کافکا، Kinesis، Flume و… سرچشمه بگیرند.
- Spark SQL:
اسپارک از این مولفه برای جمعآوری اطلاعات درباره دادههای ساختار یافته و چگونگی پردازش دادهها استفاده میکند.
- Machine Learning Library یا MLlib:
کتابخانه یادگیری ماشینی شامل بسیاری از الگوریتمهای یادگیری ماشین است.هدف MLlib، مقیاسپذیری و در دسترس قرار دادن یادگیری ماشین است.
- GraphX:
شامل مجموعهای از API ها است که برای تسهیل وظایف تجزیه و تحلیل گراف استفاده میشوند.
بیشتر بخوانید: هوش تجاری چیست؟
تفاوتهای کلیدی بین هدوپ و اسپارک
بخشهای زیر به بررسی تفاوتها و شباهتهای اصلی بین این دو چارچوب میپردازند. ما به هدوپ و اسپارک از زاویهای متفاوت و شامل تفاوتهایی مانند هزینه، عملکرد، امنیت و سهولت استفاده، نگاه خواهیم کرد.
|
دستهبندی مقایسه |
هدوپ |
اسپارک |
|
کارایی |
عملکرد کندتری دارد. از دیسکها برای ذخیرهسازی استفاده میکند. به سرعت خواندن و نوشتن دیسک وابسته است. |
عملکرد سریع در حافظه با کاهش عملیات خواندن و نوشتن دیسک |
|
هزینه |
یک پلتفرم متن باز است و هزینه کمتری برای اجرا دارد. از سختافزار مقرون به صرفه استفاده میکند. پیدا کردن متخصصان آموزش دیده هدوپ آسانتر است. |
برای اکتشاف بدون ساختار، در session فضای باز ایجاد میکند. |
|
دادهپردازی |
بهترین پلتفرم برای پردازش دستهای است. از مپ ردیوس (MapReduce) برای تقسیم یک مجموعه بزرگ در یک خوشه برای تجزیه و تحلیل موازی استفاده میکند. |
مناسب برای تجزیه و تحلیل دادههای تکراری Live Streaming برای اجرای عملیات با RDD و DAG کار میکند. |
|
تابآوری در برابر خطا (تلورانس) |
یک سیستم بسیار مقاوم در برابر خطاهاست که دادهها را در سراسر گرهها تکرار میکند و در صورت بروز مشکل از آنها استفاده میکند. |
فرایند ایجاد بلوک RDD را ردیابی میکند و سپس میتواند یک مجموعه داده را در صورت خرابی یک پارتیشن بازسازی کند. اسپارک، برای بازسازی DAG همچنین میتواند از دادهها در سراسر گرهها استفاده کند. |
|
مقیاسپذیری |
به راحتی با افزودن گرهها و دیسکها برای ذخیرهسازی مقیاسپذیر است. از دهها هزار گره بدون محدودیت شناخته شده پشتیبانی میکند. |
مقیاسپذیری در آن کمی چالشبرانگیزتر است؛ زیرا برای محاسبات به رَم متکی است. از هزاران گره در یک خوشه پشتیبانی میکند. |
|
امنیت |
امنیت فوقالعادهای دارد. از ACL، LDAP، SLA، Kerberos و … پشتیبانی میکند. |
امنیت آن کم است و به طور پیش فرض، امنیت خاموش است. برای دستیابی به سطح امنیتی لازم است با هدوپ ادغام شده و به آن متکی است. |
|
سهولت استفاده و زبان برنامهنویسی |
استفاده از هدوپ سختتر است و از زبانهای برنامهنویسی کمتری پشتیبانی میکند. از جاوا یا پایتون برای برنامههای مپ ردیوس استفاده میکند. |
کاربرپسندانهتر است و در حالت پوسته اجازه تعامل میدهد. APIها را میتوان در Scala، Java، Spark SQL، Python و R نوشت. |
|
یادگیری ماشینی |
کندتر از اسپارک است. قطعات داده میتوانند خیلی بزرگ باشند و گلوگاه (Bottleneck) ایجاد کنند. Mahout کتابخانه اصلی است. |
با پردازش در حافظه داخلی، بسیار سریعتر عمل میکند. از MLlib برای محاسبات استفاده میکند. |
|
زمانبندی و مدیریت منابع |
از راهکارهای خارجی استفاده میکند. YARN رایجترین گزینه برای مدیریت منابع است. Oozie برای زمانبندی و گردش کار قابل استفاده است. |
دارای ابزارهای داخلی برای تخصیص منابع، زمانبندی و نظارت است. |
کارایی
در نگاه اول ممکن است مقایسه بین عملکرد هدوپ و اسپارک با توجه به نحوه پردازش دادهها منطقی به نظر نرسد. اما ما میتوانیم عملکرد آن هارا جدا کرده و تصویر روشنی از این که کدام ابزار سریعتر است بدست آوریم. با دسترسی به دادههای ذخیرهشده محلی در هدوپ، HDFS عملکرد کلی را تقویت میکند. با این حال، برای پردازش درون حافظه اسپارک مناسب نیست. طبق ادعای آپاچی، اسپارک در هنگام استفاده از رم برای محاسبات ۱۰۰ برابر سریعتر از هدوپ با مپ ردیوس (MapReduce) است. این تسلط با مرتبسازی دادههای ابر روی دیسکها باقی ماند. اسپارک سه برابر سریعتر است و ده برابر به گرههای کمتری برای پردازش ۱۰۰ ترابایت داده در HDFS نیاز دارد. این معیار برای ثبت رکورد جهانی در سال ۲۰۱۴ کافی بود.
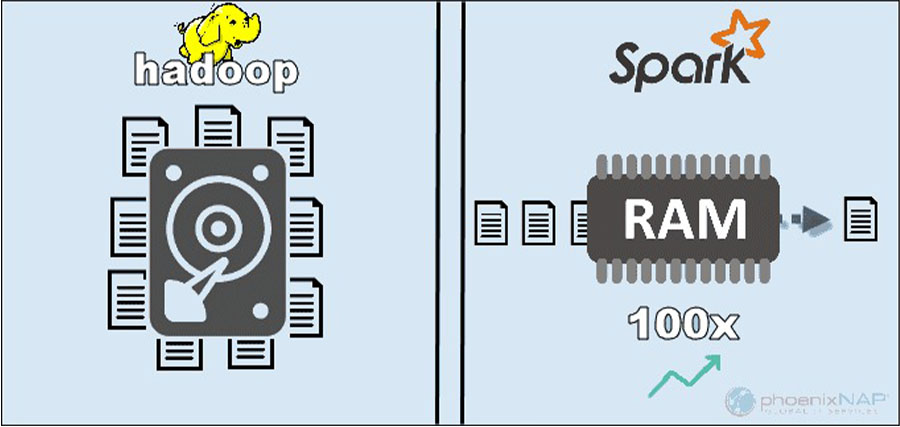
دلیل اصلی برتری اسپارک این است که دادههای میانی را روی دیسک نمیخواند و نمینویسد بلکه از رم (RAM) استفاده میکند. هدوپ دادهها را در بسیاری از منابع مختلف ذخیره میکند و سپس دادهها را به صورت دستهای با استفاده از مپ ردیوس پردازش میکند. با توجه موارد گفته شده ممکن است تصور کنید که میتوان اسپارک را به عنوان برنده مطلق معرفی کرد. اما باید در نظر گرفت که اگر اندازه دادههابزرگتر از رم موجود باشد، هدوپ انتخاب منطقیتری است. نکته دیگری که باید به آن توجه کرد هزینه اجرای این سیستم ها است.
هزینه
برای مقایسه تفاوت هزینه هابین هدوپ و اسپارک باید به سراغ قیمت نرمافزارهای مورد نیاز آنها برویم. هر دو پلتفرم متن باز و کاملا رایگان هستند. با این وجود هزینههای زیرساخت، نگهداری و توسعه باید در نظر گرفته شود تا هزینه کل مالکیت تقریبی (TCO) بدست آید. مهمترین عامل در خصوص هزینه، سخت افزار زیربنایی است که برای اجرای این ابزارها نیاز دارید. از آن جایی که هدوپ برای پردازش دادهها میتواند از هر نوع دیسکی برای ذخیرهسازی استفاده کند، هزینههای اجرایی آن نسبتا پایین است.
از سوی دیگر، اسپارک برای پردازش دادهها در لحظه به محاسبات درون حافظه وابسته است. بنابراین، جابجایی نودها با کمک حافظه رم (RAM) زیاد، هزینه مالکیت را به طور قابلتوجهی افزایش میدهد. نگرانی دیگر هزینه توسعه برنامه است. هدوپ قدیمیتر از اسپارک است و پیدا کردن توسعهدهنده برای این نرمافزار چالش کمتری دارد. با توجه به نکاتی که در بالا گفته شد، میتوان در نظر داشت که شاید زیرساخت هدوپ مقرون به صرفه تر باشد. اما باید توجه داشت که اسپارک دادهها را بسیار سریعتر پردازش میکند. از این رو برای انجام کار مشابه به تعداد کمتری ماشین نیاز دارد.
دادهپردازی
این دو چارچوب داده ها را به روشهای کاملا متفاوتی مدیریت میکنند. اگر چه هدوپ با مپ ردیوس و اسپارک با RDD دادهها را در یک محیط توزیع شده پردازش میکنند، هدوپ برای پردازش دستهای مناسبتر است. در مقابل، اسپارک با پردازش بلادرنگ میدرخشد. هدف هدوپ ذخیره دادهها بر روی دیسکها و سپس تجزیه و تحلیل موازی آنها به صورت دستهای در یک محیط توزیع شده است. مپ ردیوس برای مدیریت حجم وسیعی از دادهها به مقدار زیادی رم نیاز ندارد. هدوپ برای ذخیرهسازی به سختافزار روزمره متکی است و برای پردازش دادههای خطی مناسبترین گزینه است.
اسپارک با مجموعه داده توزیع شده انعطاف پذیر (RED) کار میکند. RDD مجموعهای توزیع شده از عناصر است که در پارتیشنهای روی گرهها در سراسر خوشه ذخیره میشود. اندازه یک RDD معمولا برای این که یک نود آن را مدیریت کند، بزرگ است. بنابراین اسپارک RDDها را با نزدیکترین گرهها تقسیمبندی میکند و عملیات را به صورت موازی انجام میدهد. این سیستم تمام اقدامات انجام شده بر روی یک RDD را با استفاده از یک (Directed Acyclic Graph (DAG ردیابی میکند. با محاسبات درون حافظه و APIهای سطح بالا، اسپارک به طور موثر جریانهای زنده دادههای بدون ساختار را کنترل میکند. علاوه بر این، دادهها در تعداد از پیش تعریف شده پارتیشن ذخیره میشوند. یک گره میتواند به تعداد مورد نیاز پارتیشن داشته باشد، اما یک پارتیشن نمیتواند به گره دیگری گسترش یابد.
تحمل در برابر خطا (تلورانس)
برای مقایسه تاب آوری خطا در هدوپ و اسپارک میتوان گفت، که هر دو سطح قابل قبولی در مدیریت خطاها را ارائه میدهند. همچنین، میتوان گفت که نحوه برخورد آنها در برابر خطا متفاوت است. هدوپ تحمل خطا را به عنوان اساس عملکرد خود دارد. این روش دادهها را چندین بار در طول گرهها تکرار میکند. در صورتی که مشکلی رخ دهد، سیستم کار را با ایجاد بلوکهای گم شده از مکانهای دیگر از سر میگیرد. گرههای اصلی (Master) وضعیت تمام گرههای وابسته (Slave) را ردیابی میکنند و در نهایت اگر یک گره وابسته به پینگهای یک گره اصلی پاسخ ندهد، گره اصلی کارهای معلق را به گره برده دیگری اختصاص میدهد.
اسپارک از بلوکهای RDD برای رسیدن به تلورانس خطا استفاده میکند. این سیستم نحوه ایجاد مجموعهای از داده تغییرناپذیر را ردیابی میکند. سپس در صورت بروز مشکل میتواند فرآیند را مجددا راه اندازی کند. اسپارک میتواند دادهها را در یک خوشه با استفاده از ردیابی DAG از گردش کار بازسازی کند. با کمک این ساختار داده، اسپارک میتواند خرابیهای یک اکوسیستم پردازش داده توزیعشده را مدیریت کند.
مقیاس پذیری
خط بین هدوپ و اسپارک در این بخش تار میشود. هدوپ از HDFS برای مقابله و مدیریت با دادههای بزرگ استفاده میکند. هنگامیکه حجم دادهها به سرعت رشد میکند، هدوپ میتواند به سرعت مقیاس را برای تطبیق با تقاضا تغییر دهد. از آن جایی که اسپارک سیستم فایل خود را ندارد، زمانی که دادهها برای مدیریت خیلی بزرگ هستند باید به HDFS تکیه کند.
خوشهها میتوانند به راحتی توان محاسباتی را با اضافه کردن سرورهای بیشتر به شبکه گسترش داده و تقویت کنند. هیچ محدودیتی برای این که چه تعداد سرور میتوانید به هر خوشه اضافه و چه مقدار داده میتوانید پردازش کنید وجود ندارد. برخی از اعداد در محیط اسپارک، ظرفیتی حدود ۸۰۰۰ ماشین با پتابایت داده را تایید میکنند. خوشههای هدوپ هم، مشهور هستند که میتوانند دهها هزار ماشین و نزدیک به یک اگزابایت داده را در خود جای دهند.
سهولت استفاده و زبان برنامهنویسی
اسپارک فریم ورک جدیدتری نسبت به هدوپ است و تعداد متخصصان کمتری دارد؛ اما کاربرپسندانهتر است. اسپارک از چندین زبان در کنار زبان اصلی (Scala) پشتیبانی میکند: جاوا، پایتون، R و SQL و این امکان را به برنامهنویسان میدهد تا از زبان برنامهنویسی که ترجیح میدهند، استفاده کنند. فریمورک هدوپ مبتنی بر جاوا است. دو زبان اصلی برای نوشتن کد مپ ردیوس جاوا یا پایتون هستند. هدوپ حالت تعاملی، برای کمک به کاربران ندارد. با این حال، برای تسهیل نوشتن برنامههای مپ ردیوس و کاهش پیچیدگی با ابزارهای Pig و HIve ادغام میشود.
اسپارک علاوه بر پشتیبانی از APIها به چند زبان برای استفاده نیز راحتتر است و حالت تعاملی بیشتری دارد. شما میتوانید از پوسته اسپارک برای تحلیل تعاملی دادهها با اسکالا یا پایتون استفاده کنید. این پوسته امکان ارائه بازخورد فوری به کوئریها را دارد که استفاده از اسپارک را نسبت به MapReduce Hadoop آسانتر میکند. مورد دیگری که برتری اسپارک را نشان میدهد، این است که برنامهنویسان میتوانند از کد موجود، در صورت امکان استفاده مجدد کنند. با انجام این کار توسعهدهندگان میتوانند زمان توسعه برنامه را کاهش دهند. دادههای تاریخی و جریان میتوانند با هم ترکیب شوند تا این فرآیند حتی موثرتر شود.
امنیت
در مقایسه امنیت بین هدوپ و اسپارک، بدون شک هدوپ برنده خواهد بود. مهمتر از همه، امنیت اسپارک به طور پیش فرض خاموش است. این بدان معناست که اگر با این مشکل مقابله نکنید، تنظیمات شما لو میرود. میتوانید با معرفی احراز هویت از طریق authentication via shared secret or event logging، امنیت اسپارک را بهبود بخشید. با این حال، این برای حجم کاری تولید کافی نیست.
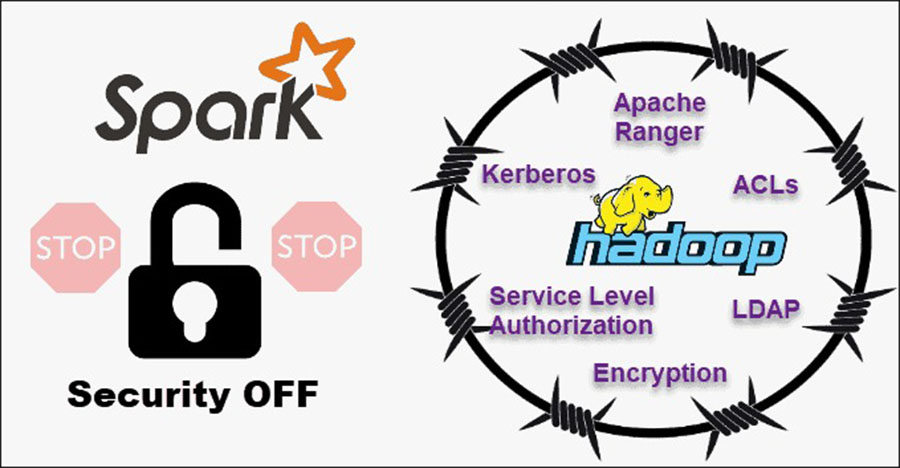
در مقابل، هدوپ با احراز هویت چندگانه و روشهای کنترل دسترسی کار میکند. سختترین شیوه پیادهسازی احراز هویت Kerberos است. اگر پیاده سازی Kerberos سخت و پردردسر باشد، هدوپ از Ranger، LDAP، ACL، inter-node encryption، مجوزهای استاندارد LE روی HDFS و مجوز سطح سرویس هم پشتیبانی میکند. اسپارک میتواند با ادغام شدن با هدوپ به سطح مناسبی از امنیت برسد. به این ترتیب، اسپارک میتواند از تمام روشهای امنیتی در دسترس برای هدوپ و HDFS استفاده کند. علاوه بر این، وقتی که اسپارت در YARN اجرا میشود، شما میتوانید از مزایای روشهای دیگر احراز هویت که در بالا گفته شد هم استفاده کنید.
یادگیری ماشینی
یادگیری ماشین یک فرایند تکراری است که با استفاده از محاسبات درون حافظه به بهترین نحو کار میکند. به همین دلیل، اسپارک ثابت کرده است که یک راهحل سریعتر در این حوزه است. مهمترین دلیل این است که مپ ردیوس در هدوپ، کارها را به وظایف موازی تقسیم میکند که ممکن است برای الگوریتمهای یادگیری ماشین بسیار بزرگ باشند. این فرآیند مشکلات عملکردی، I / O را در این برنامههای هدوپ ایجاد میکند. Mahout library، پلتفرم اصلی یادگیری ماشین در خوشههای هدوپ است.ماهوت برای انجام خوشهبندی و ارائه پیشنهاد به مپ ردیوس متکی است. بنابراین Samsara جایگزین این پروژه شد.
اسپارک با یک کتابخانه یادگیری ماشینی پیش فرض، به نام MLlib، عرضه میشود. این کتابخانه محاسبات تکراری در حافظه ML را اجرا میکند. که شامل ابزارهایی برای اجرای رگرسیون، طبقهبندی، پایدار، ساختن پایپ لاین، ارزیابی و بسیاری موارد دیگر است. اسپارک با MLlib نه برابر سریعتر از Mahout در یک محیط مبتنی بر دیسک هدوپ عمل میکند. هنگامیکه به نتایج کارآمدتری برای یادگیری ماشینی نیاز دارید، اسپارک انتخاب بهتری نسبت به هدوپ است.
زمانبندی و مدیریت منابع
هدوپ امکان زمانبندی داخلی ندارد و از راهکارهای خارجی برای مدیریت منابع و برنامهریزی استفاده میکند. ResourceManager و NodeManager، YARN مسئول مدیریت منابع در یک کلاستر هدوپ هستند. یکی دیگر از ابزارهای در دسترس برای زمانبندی گردش کار، Oozie است. YARN با چگونگی مدیریت برنامههای خاص سروکار ندارد. بلکه تنها به پردازش داشتههای قدرتمند اختصاص مییابد.
مپ ردیوس با افزونههایی مانند Capacity Scheduler و Fair Scheduler کار میکند. این زمانبندیها تضمین میکنند که برنامهها، منابع ضروری را در صورت نیاز دریافت کرده و در عین حال کارایی یک خوشه را حفظ میکنند. Fair Scheduler منابع لازم را در اختیار برنامهها قرار میدهد در عین حال بررسی میکند که در نهایت، همه برنامهها تخصیص منابع یکسانی داشته و منابع لازم را دریافت کنند.
از طرف دیگر اسپارک این عملکردها را در درون خود دارد. زمانبندی DAG مسئول تقسیم عوامل اجرایی به مراحل جزئیتر است. هر مرحله دارای وظایف متعددی است که DAG آنهارا برنامهریزی و اسپارک آنها را اجرایی میکند. Spark Scheduler و Block Manager برنامهریزی، نظارت و توزیع منابع کار و وظایف را در یک خوشه انجام میدهند.
موارد استفاده هدوپ در مقایسه با اسپارک
با مقایسه هدوپ و اسپارک در بخشهای ذکر شده در بالا، میتوانیم چند مورد استفاده را برای هر چارچوب استخراج کنیم.
موارد استفاده هدوپ عبارتند از:
- پردازش مجموعه دادههای بزرگ در محیطهایی که در آن اندازه دادهها از حافظه موجود فراتر میرود.
- تکمیل کارهایی که در آنها نیازی به نتایج فوری نبوده و زمان یک عامل محدود کننده نیست.
- پردازش دستهای با وظایفی که از عملیات خواندن و نوشتن دیسک بهره میبرند.
- تجزیه و تحلیل دادههای تاریخی و آرشیو
در ادامه به فهرستی از مواردی که استفاده از اسپارک در آنها از هدوپ است، نگاهی خواهیم انداخت:
- تجزیه و تحلیل دادههای جریان در لحظه
- هنگامیکه زمان اهمیت دارد، اسپارک نتایج سریعی را با محاسبات درون حافظه ارائه میدهد.
- مقابله با زنجیرههای عملیات موازی با استفاده از الگوریتمهای تکرار شونده.
- پردازش موازی نمودار برای مدل سازی دادهها.
- همه برنامههای یادگیری ماشین
هدوپ یا اسپارک؟
هدوپ و اسپارک فناوریهایی برای مدیریت دادههای کلان هستند. همچنین، آنها چارچوبهای بسیار متفاوتی در روش مدیریت و پردازش دادهها هستند. با توجه به بخشهای قبلی این مقاله به نظر میرسد که اسپارک برنده قطعی باشد. ممکن است این موضوع تا حدی درست باشد اما باید در نظر گرفت که آنها برای رقابت با یکدیگر ایجاد نشدهاند، بلکه مکمل یکدیگر هستند.
همان طور که قبلا در این مقاله اشاره کردیم، موارد استفادهای وجود دارد که انتخاب یکی از فریمورکهامنطقیتری است. در بیشتر برنامههای کاربردی، هدوپ و اسپارک با هم، بهترین کارایی را دارند. در این جا اسپارک به عنوان جانشین هدوپ در نظر گرفته نمیشود بلکه از ویژگیهای آن برای ایجاد یک اکوسیستم جدید و بهبود یافته استفاده میشود.
با ترکیب این دو، اسپارک میتواند از مزایایی که ندارد، مانند سیستم فایل استفاده کند. هدوپ حجم عظیمی از دادهها را با استفاده از سخت افزارهای مقرون به صرفه ذخیره میکند و بعدا فرایند تجزیه و تحلیل انجام میدهد، در حالی که اسپارک پردازش سریع و در لحظه را برای مدیریت دادههای دریافتی به ارمغان میآورد. بدون هدوپ برنامههای تجاری ممکن است دادههای تاریخی مهمی را که اسپارک مدیریت نمیکند، از دست بدهند.
در این محیط همکاری، اسپارک همچنین از مزایای امنیت و مدیریت منابع هدوپ بهره میبرد. با YARN، خوشهبندی در اسپارک و مدیریت دادهها بسیار آسانتر است. میتوانید به طور خودکار حجم کاری در اسپارک را با استفاده از هر منبع موجود اجرا کنید. سازندگان هدوپ و اسپارک قصد داشتند این دو پلتفرم را با هم سازگار کنند و نتایج بهینهای را برای هر نیاز تجاری خلق کنند.
جمعبندی:
در این مقاله هدوپ و اسپارک را در چندین دسته و ویژگی مقایسه کردیم. هر دو فریمورک نقش مهمیدر برنامههای کاربردی دادههای کلان ایفا میکنند. در حالی که به نظر میرسد اسپارک با توجه به سرعت بیشتر و ویژگیهای کاربر پسندانه خود پلتفرم بهتری است، که بیشتر مورد استفاده است. همچنین در بعضی از موارد استفاده، نیاز به اجرای هدوپ وجود دارند. این امر به ویژه زمانی صادق است که حجم زیادی از دادهها باید تجزیه و تحلیل شوند.
باید در نظر داشت، اسپارک به بودجه بیشتری برای تعمیر و نگهداری نیاز دارد، اما در عین حال به سخت افزار کمتری برای انجام کارهای مشابه هدوپ نیاز دارد. فراموش نکنید که این دو فریمورک هر کدام مزایای خود را داشته و بهترین کارایی را در کنار هم دارند.

دیدگاهتان را بنویسید